
В этот раз в черновик нового стандарта C++23 добавили весьма полезные и вкусные новинки:
operator[](int, int, int)- монадические интерфейсы для
std::optional std::move_only_functionstd::basic_string::resize_and_overwrite- больше гетерогенных перегрузок для ассоциативных контейнеров
-
std::views::zipиzip_transform,adjacent,adjacent_transform
Подробности об этих и других (даже более интересных!) вещах, а также о том, что за диаграмма стоит в шапке, ждут вас под катом.
Многомерный operator[]
При разработке класса многомерного спана
std::mdspan комитет столкнулся с проблемой многомерного индексирования. На примере массива с пятью измерениями:auto raw = std::make_unique<int[]>(3*4*5*6*7);
std::mdspan<int, 3, 4, 5, 6, 7> array{raw.get()};
array(1, 2, 3, 4, 5) = 42; // выглядит ужасно
array[{1, 2, 3, 4, 5}] = 42; // очень непонятно и неприятно писать
array[1][2][3][4][5] = 42; // чуть лучше, но под капотом творится просто жуть
Чтобы не делать таких безобразий (и по просьбам разработчиков математических библиотек) в C++ был добавлен многомерный
operator[] (P2128). Его можно перегружать для любых типов, что позволяет делать принципиально новые интерфейсы:enum class Volume: std::size_t{};
class Library {
// ...
public
Book operator[](std::u8string_view book_name, Volume volume) const;
};
// ...
Library lenin_library{};
auto book = lenin_library[u8"Большая советская энциклопедия", Volume{14}];
Read(book);Монадические интерфейсы для std::optional
Если вы не знаете, что такое «монады» — не расстраивайтесь
std::optional (P0798):auto MonadicOptional(std::optional<std::size_t> value) {
return value
.transform([](std::size_t value) { return value - 40uz; })
.or_else([]() { return 7uz; })
.and_then([](std::size_t value) { return std::string(value, '-'); })
;
}
assert(MonadicOptional(42) == '--');
assert(MonadicOptional(std::nullopt) == '-------');
Функция
auto optional::transform(F&& f) возвращает std::optional{f(*this)} при непустом this; иначе вернёт std::nullopt. Функция optional optional::or_else(F&& f) возвращает f() при пустом this; иначе вернёт this->value(). Функция auto optional::and_then(F&& f) возвращает f(this->value()) при непустом this; иначе вернёт дефолтно сконструированную переменную типа decltype(f(*this)).Итого: с новыми функциями нет необходимости писать проверки на пустоту
std::optional, чтобы выполнить преобразования хранящихся в нём данных.std::move_only_function
Со времён C++11, когда move-семантика только появилась, прошло уже 10 лет. За это время многие библиотеки стали требовать C++11, в них появились классы без поддержки копирования (только перемещения, только
std::move!), а порой и без поддержки перемещения.И тут заметили проблему: type-erased-контейнеры
std::function и std::any требуют копируемости хранимого типа. Иначе получаем ошибку компиляции.Фикс подоспел к С++23, приняли
std::move_only_function (P0288), который не требует конструкторов копирования и перемещения. Теперь, если ваш алгоритм не требует, чтобы функтор копировался, просто принимайте на вход новый тип данных:void example_usage(std::move_only_function<void()> f);
// Передавать только перемещаемые функции — ОК
example_usage([ptr = std::make_unique<int>(42)](){ /*...*/ });
// Неперемещаемые — тоже ОК
struct non_movable {
mutable std::mutex mtx;
void operator()() noexcept { std::unique_lock lock{mtx}; /*...*/ }
};
example_usage(std::in_place<non_movable>);
Кстати,
std::move_only_function работает и с явным указанием noexcept, так что можно требовать не кидающие функторы от вызывающего кода, просто написав std::move_only_function<void() noexcept>.Что же касается требования копируемости в
std::any, мы в РГ21 планируем заняться этой проблемой, присоединяйтесь к обсуждениям, благо такой тип есть у нас в Яндекс Go, во фреймворке userver.basic_string::resize_and_overwrite
Для любителей сильнее оптимизировать код в C++23 добавили возможность увеличить размер строки и сразу проинициализировать новые символы (P1072):
extern "C" {
int compress(void* out, size_t* out_size, const void* in, size_t in_size);
}
std::string CompressWrapper(std::string_view input) {
std::string compressed;
compressed.resize_and_overwrite(input.size(), [input](char* buf, std::size_t n) noexcept {
std::size_t compressed_size = n;
auto is_ok = compress(buf, &compressed_size, input.data(), input.size());
assert(is_ok);
return compressed_size;
});
return compressed;
}Результат будет аналогичен следующему коду:
extern "C" {
int compress(void* out, size_t* out_size, const void* in, size_t in_size);
}
std::string CompressWrapper(std::string_view input) {
std::string compressed(input.size(), '\0');
std::size_t compressed_size = compressed.size();
auto is_ok = compress(compressed.data(), &compressed_size, input.data(), input.size());
assert(is_ok);
compressed.resize(compressed_size);
return compressed;
}'\0'. Уже после этого произойдёт вызов compress. Ну а в первом примере лямбда работает с незанулённым буфером, мы фактически избегаем вызова memset( compressed.data(), compressed.size(), '\0');.Больше гетерогенных методов
Маленькая, но очень приятная новость: ассоциативные контейнеры в C++23 обзавелись гетерогенными перегрузками методов
erase и extract. Теперь можно удалять и извлекать ноды, используя ключи, отличные от шаблонных параметров контейнера:std::set<std::u8string, std::less<>> da_set;
// ...
std::u8string_view key{u8"Я не std::u8string!"};
da_set.find(key); // OK начиная с C++14
da_set.erase(key); // OK начиная с C++23
График, показывающий прирост производительности при использовании новых методов, как раз вынесен в шапку этого поста. Больше графиков и детали можно найти в самом предложении: P2077. Большое спасибо нашим ребятам из Intel за отлично проделанную работу!
zip, zip_transform, adjacent, adjacent_transform
Ranges обзавелись новыми view для «склеивания» элементов диапазона (P2321):
std::vector v1 = {1, 2};
std::vector v2 = {'a', 'b', 'c'};
std::vector v3 = {3, 4, 5, 6, 7, 8};
auto result0 = std::views::zip(v1, v2); // {(1, 'a'), (2, 'b')}
auto result1 = std::views::zip_transform(std::multiplies(), v1, v3); // {3, 8}
auto result2 = v2 | std::views::pairwise; // {('a', 'b'), ('b', 'c')}
auto result3 = v3 | std::views::pairwise_transform(std::plus()); // {7, 9, 11, 13, 15}
auto result4 = v3 | std::views::adjacent<3>; // {(3, 4, 5), (4, 5, 6), (5, 6, 7), (6, 7, 8)}
Не стоит забывать, что ranges — ленивые:
- Если вы, например, из
result3запросите только первые два элемента, то оставшиеся элементы считываться не будут. - Если переменная
v3будет уничтожена, то нельзя пользоватьсяresult1,result3,result4и всеми их копиями.
Транзакционная память
Комитет уже делал подход к транзакционной памяти Transactional TS, и этот подход показал себя совершенно несостоятельным: в стандарт вносилось слишком много правок, приходилось переделывать стандартную библиотеку, порой дублируя функции.
Поэтому решили сделать новый подход! Простой и элегантный:
class TwoInts {
public:
TwoInts() = default;
TwoInts(const TwoInts&) = delete;
TwoInts& operator=(const TwoInts&) = delete;
void SetA(int value) const { atomic do { a_ = value; } }
int GetA() const { atomic do { return a_; } }
void SetB(int value) const { atomic do { b_ = value; } }
int GetB() const { atomic do { return b_; } }
int Max() {
atomic do {
return a_ < b_ ? b_ : a_;
}
}
private:
int a_{0};
int b_{0};
};
Новый подход всё ещё экспериментальный, в ближайшее время он будет выпущен в виде TS, основанного на P2066.
- Нет способа понять, как будет соптимизирован атомарный блок (будет ли в нём мьютекс?).
- Если атомарный блок деградирует до мьютекса, то будет один мьютекс для всех атомарных блоков, а это быстро станет узким местом в коде.
- Добавляется множество новых не диагностируемых способов получить UB.
Получение std::stacktrace из исключения
От РГ21 есть замечательное предложение Stacktrace from exception, которое позволяет получить стектрейс из любого исключения без модификации кода, который выкидывает это исключение:
void foo(std::string_view key);
void bar(std::string_view key);
int main() {
try {
foo("test1");
bar("test2");
} catch (const std::exception& exc) {
std::stacktrace trace = std::stacktrace::from_current_exception(); // <---
std::cerr << "Caught exception: " << exc.what() << ", trace:\n" << trace;
}
}Такой пример может вывести следующее:
Caught exception: map::at, trace:
0# get_data_from_config(std::string_view) at /home/axolm/basic.cpp:600
1# bar(std::string_view) at /home/axolm/basic.cpp:6
2# main at /home/axolm/basic.cpp:17Если честно, я не верил, что комитет успеет принять эту идею в C++23. Но внезапно предложение понравилось многим комитетским старожилам, и появился шанс успеть втащить его в стандарт на одном из заседаний 2021 года, которые будут последними перед feature freeze.
Итоги и feature freeze
На дизайн новых идей до feature freeze у нас осталось около 16 двухчасовых собраний. Networking и Executors навряд ли успеют, как и примитивы для работы с корутинами. Но не надо расстраиваться, есть шансы увидеть pattern matching,
std::mdspan, std::flat_set, std::flat_map, std::static_vector, constexpr cmath и некоторые другие полезные вещи.Кстати, 15-18 ноября состоится конференция C++ Russia, где можно будет узнать новости о развитии C++ и пообщаться с многими представителями комитета.
Комментарии (424)

Antervis
05.10.2021 11:52+1Нет способа понять, как будет соптимизирован атомарный блок (будет ли в нём мьютекс?)
я правильно понимаю, что в конкретном примере он точно должен быть, т.к. TwoInts не выровнен по 8, что в общем случае не дает атомарно прочитать оба инта сразу?
А в остальном... ну ладно, ждем pattern matching

antoshkka Автор
05.10.2021 12:10Зависит от платформы и возможностей компилятора, есть подозрение что мьютекс будет использоваться не во всех функциях класса.

a-tk
05.10.2021 12:02+3Глядишь к C++29 довезут монадические интерфейсы для всего остального типа expected и ranges...
antoshkka Автор
05.10.2021 12:05+5Чтобы довезти монадические интерфейсы до std::expected, надо сначала донести expected до std :)
Кстати, есть шанс, что это случится в C++23.

mapron
05.10.2021 22:32+2Ну такое, я надеялся что static exceptions получат дорогу и std::expected городить уже не будут. Я же ведь правильно понимаю, что при их наличии в языке, expected не дает ощутимых преимуществ? (я понимаю что можно выдумать применение, я про то что это перестает соответстовать критериям Страуструпа)

AnthonyMikh
07.10.2021 16:04+1Я же ведь правильно понимаю, что при их наличии в языке, expected не дает ощутимых преимуществ?
Неправильно.
expectedпозволяет вызвать функцию, которая потенциально завершается ошибкой, и при это не требует разбираться с ошибкой незамедлительно, а даёт возможность отреагировать на ошибку позднее.

tangro
05.10.2021 13:46+9Глядишь к С++39 довезут trim/tokenize/split/replace для std::string. Вон .contains в С++23 довезли же, так что прогресс есть.
antoshkka Автор
05.10.2021 14:02+4Их не довезли, потому что вы их не предложили, значит вам оно и не надо :-\
Предложение может написать и направить в комитет каждый. Даже специальную русскоязычную группу сделали, чтобы упростить и без того простой процесс. Так что если хотите увидеть replace|tockenize - пишите прототип и proposal, помочь всегда рады в https://stdcpp.ru/proposals/ и в чатике https://t.me/ProCxx
P.S.: split есть начиная с C++20.
tangro
05.10.2021 17:18+4Конечно, оно мне не надо, у меня есть свои и чужие библиотеки для всего подобного. Просто была мысль что это, возможно, надо комитету С++. Ну, например, чтобы питонщики и джаваскриптисты наконец перестали смеяться с плюсов из-за таких глупостей.

KanuTaH
05.10.2021 17:30+2Непонятно, почему комитет должен учитывать хотелки людей, которые на C++ не пишут, притом что людям, которые на C++ пишут, это, по-видимому, не нужно (пропозалов же нет, потому что хватает "своих и чужих библиотек" - я не ерничаю, лично мне тоже хватает библиотек, но и претензий к комитету в стиле "а что люди скажут" я при этом не предъявляю).
tangro
05.10.2021 17:48+21Очень даже понятно почему. Студент первого курса или школьник спрашивает как заменить подстроку на JS и получает ответ:
"Hello".replaceAll("Hello", "world");Тот же студент задаёт такой же вопрос о С++ и получает:
Совет взять boost/QT/MFC/Framework_X, разобраться со всеми его зависимостями и нюансами и вызвать метод оттуда
Совет использовать регулярные выражения
Пример кода на 8 строк с циклом, find и replace, где можно ошибиться в 15 местах.
А дальше как в том комиксе известном "а ну его к чёрту, буду джаваскриптистом". А потом мы удивляемся почему вокруг каждый первый мессенджер, текстовый редактор и аудиплеер - это эмбеднутый Хромиум, жрущий по 2 гига ОЗУ для показа трёх строк текста.
Antervis
05.10.2021 21:47в джаваскрипте чет тоже до недавних пор самые лучшие способы написать
replaceAll("foo", "bar")были либоs.replace(/foo/d, "bar")либоs.split("foo").join("bar").mapron
05.10.2021 22:36+4да просто сейчас даже взять задачу «взять строку, разбить по точкам и преобразовать в вектор интов», например «10.10.0.1».
Для её реализации требуются глубокие знания текущих rangeй и с наскоку написать так просто ничего не получится.
(кто думает что я херню выдумываю и все там «изян», воть — www.open-std.org/jtc1/sc22/wg21/docs/papers/2021/p2210r2.html )Antervis
06.10.2021 00:24Для её реализации требуются глубокие знания текущих rangeй и с наскоку написать так просто ничего не получится.
попробовал с наскоку написать, действительно сложно - интерфейс from_chars пришлось таки на cppreference проверять, всё-таки не пользовался им ни разу, обычно под рукой есть обертки. А вот написать
vector<int> vec; for (int i : "10.10.0.1"sv | ranges::views::split('.') | ranges::views::transform([](auto rv) { string_view s(rv.begin(), rv.end()); // тут конвертация s в int return res; })) vec.push_back(i);не составило труда, потребовалась лишь пара подсказок компилятора (печатал в годболте) что то что я ищу не в том неймспейсе. Из "глубоких знаний" почему split возвращает не string_view (хотя проще даже без него), и то, что в ranges в с++20 не добавили метод материализации контейнера (тогда было бы еще проще). Можно было бы еще через back_inserter написать, но зачем выпендриваться?
кто думает что я херню выдумываю и все там «изян», воть
всё-таки та бумага решает проблему того, что ленивое вычисление split не шибко хорошо сочетается с input iterator'ами, а не ту, которую вы пытаетесь привести здесь.
mapron
06.10.2021 07:19+3Теперь сравните с тем что есть в Qt:
for (QString s: str.split('.'))
v << s.toInt();
после этого никак решение которое вы написали, не выглядит newbiew-friendly. Я не говорю что С++ отстой или что ranges не нужны, я говорю что до сих пор мы не пришли к тому что простые операции делаются просто интуитивно.
Просто делается сложно. И сложное сложно. Но последнее зачастую сильно проще чем в других языках. Это даёт облегчение)Antervis
06.10.2021 10:13Теперь сравните с тем что есть в Qt:
давайте сравним: Qt версия делает на N + log(N) аллокаций больше, то есть выразительность в ущерб производительности. Соответственно, такой версии split не место в стандарте.
Но что еще важнее, Qt это всё еще плюсы. На плюсах вы всегда можете написать библиотеку с любым желаемым соотношением выразительности/производительности, а новички всегда могут начать изучать с++ с того же Qt
mapron
06.10.2021 10:16+7Вы правда думаете что в 99% мне не наплевать на эти аллокации?
В стандартной библиотеке дофига классов которые можно написать более оптимально. stl не является самой оптимальной реализацией контейнеров, это лишь «достаточно оптимальной» чтобы подходить большинству.
Мне не нравится ситуция что новички начинают С++ с Qt, появляется концепция «программистов Qt» которые не знают С++

ncwca
07.10.2021 01:04+1Вы правда думаете что в 99% мне не наплевать на эти аллокации?
Просто qt - это случайность, когда люди вместо js/c#/java попали в мир C++ и непонятно что здесь делают, когда есть языки которым by-design плевать на все эти аллокации и если плевать, то нужно писать на них.
Наличие в stl какой-то неоптимальности ничего не значит и ничего не оправдывает. Это не более чем демогогический приём вида "ну если где-то что-то решено не полностью - решать что-то не имеет смысла".
Если нельзя вымыть себя оптимально - это не значит, что нужно не мыться. И что мытый равен не мытому, либо не особо от него отличается в силу того, что мытый не стирилен.
mapron
07.10.2021 04:08Если нельзя вымыть себя оптимально — это не значит, что нужно не мыться.
Спасибо, отличный афоризм!

0xd34df00d
07.10.2021 19:06+2давайте сравним: Qt версия делает на N + log(N) аллокаций больше, то есть выразительность в ущерб производительности. Соответственно, такой версии split не место в стандарте.
Если вы поменяете
splitнаsplitRef(и заменитеQStringнаauto, конечно), то куте-версия будет делать где-то между O(logN) и O(1) аллокаций больше (преаллоцировать буфер никто не мешает).
antoshkka Автор
06.10.2021 14:29Теперь сравните с тем что есть в Qt:
for (QString s: str.split('.'))
v << s.toInt();Так и в C++23 это есть, если лишние аллокации ок:
for (auto s: str | split('.')) v << std::stoi(std::string{s});
mapron
06.10.2021 14:30Благодарствую) мне правда еще пяток лет придется подождать пока С++20 дойдут до меня (увы), а так буду знать что будущее светлое где-то рядом)
Antervis
06.10.2021 16:02Вы правда думаете что в 99% мне не наплевать на эти аллокации?
Конечно же нет. Однако такие API противоречат самой сути с++ как zerocost-oriented языка. В конце концов, вы всегда можете написать неэффективный код на эффективном языке, но не наоборот.
В стандартной библиотеке дофига классов которые можно написать более оптимально
а можете привести пару примеров? Так, чтобы альтернативная реализация могла бы быть безусловно лучше, без опускания части требований/гарантий.
Так и в C++23 это есть, если лишние аллокации ок:
боюсь std::string{s} (где s - subrange<const char*, const char*>) не скомпилится.

svr_91
06.10.2021 16:22как zerocost-oriented языка
Ну вот в exception добавили stacktrace и он стал еще менее zerocost, чем даже был до этого
а можете привести пару примеров?
ifstream? initializer_list без возможности move?
К томуже чем split с N + log(N) аллокаций не zero-cost? Не использую - не плачу
Antervis
06.10.2021 19:35Ну вот в exception добавили stacktrace и он стал еще менее zerocost, чем даже был до этого
stacktrace не добавляет накладных расходов при создании исключения, только при вызове stacktrace::current.
ifstream? initializer_list без возможности move?
"Так, чтобы альтернативная реализация могла бы быть безусловно лучше, без опускания части требований/гарантий."

Gordon01
06.10.2021 17:04+2Rust:
let vec: Vec<i32> = "10.10.0.1".split('.') .map(|s| s.parse().unwrap()) .collect();Интересно было бы еще сравнить перф.
Antervis
06.10.2021 18:01+1Интересно было бы еще сравнить перф.
не шибко то и интересно - ваш код будет падать на любом некорректном вводе.
Gordon01
06.10.2021 18:17+1эм, а где в условии про это говорилось?
вы вообще даже конвертацию строки в число не написали
ncwca
07.10.2021 01:11Это предполагается. Этим различаются исключения и попытка походить на них через unwrap. Очевидно, что обработка ошибки нужна. С исключениями я могу её игнорировать, потому что исключения уже механизм являются механизмом для пробраса ошибки через нелокальных переходы.
В ситуации с "без исключений" такого механизма нет. И любой unwrap просто попытка спрятать проблему "под ковёр" авось никто не заметит.
Есть from_chars.

Fenex
07.10.2021 05:29+1`Result` это не исключения и не попытка на них походить. Это однозначное значение, которое описывает либо успех операции со значением (или без такового), либо провал с описанием что пошло не так (опять же, возможно и без самого описания).
Впрочем, вот чуть подправленный код с возвратом `Option` — для случая если нам не нужно знать в каком месте вводные данные некорректные.pub fn parse_ip(ip: &str) -> Option<Vec<u8>> { ip .split('.') .map(|s| s.parse()) .try_fold(vec![], |mut acc, octet| { octet.map(|item| { acc.push(item); Some(acc) }).ok().flatten() }) }
А если всё таки надо знать номер проблемного октета адреса, то достаточно добавить `enumerate()` перед `try_fold`. По идеи, надо сделать дополнительно проверку на количество октетов адреса, но её я опущу.
ncwca
07.10.2021 14:51-3Resultэто не исключения и не попытка на них походить.Я даже не знаю кому вы отвечаете. Каждый раз как ответ - так попытка подменить тезис. Где я писал, что какой-то там result это попытка? Я писал о том, что try/unwrap и прочее - это попытки. А сам result никому не интересен.
Хотя, если посмотреть глубже, result родился как именно что попытка походить на исключения. Исполнение с исключениями, и вообще за рамками ФП - имеет множество обратных путей, как минимум два.
Если мы берём обычный код с одним путём возврата, то монады не более чем попытка эмулировать несколько путей в одном. Это такое максимальное наивное мультиплексирование, чтобы выглядить как дяди с исключения. Хотя в рамках фп развивались, в том числе, и исключения. Но они не настолько примитивные и как результат - это не модно.
Про назначение кода я не понимаю. Что он должен показывать? Что код стал куда более страшный? Это лишь подтверждает мой тезис, что unwrap призван скрыть это.
А если всё таки надо знать номер проблемного октета адреса, то достаточно добавить
enumerate()передtry_fold.Ну это прям совсем некрасиво - зачем так нагло обмазывать? И чем мне этот
enumerate поможет? Ничем. Там нету того, что это ошибку будет пробрасывать. Там есть вектор + bool, условно. И да -это максимально тупо(когда как вектор уже может быть пустым, т.е. в нём есть дополнительное состояние).Более там места ни для чего нет. Читающие могут вернуться к моему тезисы "весь код последователей раста и reuslt - враньё, подлог и манипуляция". Здесь мы видим очередной пример.
Случайно тот факт, что этот номер проблемного октета нужно не просто получить, но и передать - потерялся. И проблема здесь в том, что это не случайно.
0xd34df00d
07.10.2021 19:52+3Но они не настолько примитивные
Что в монадах примитивного? Ну, кроме того, что UB при попытке засунуть код с экзепшонами в параллельные алгоритмы получить можно, а с монадами — нет? Или что рассуждать о коде с экзепшонами сложно, а о монадическом — просто?
и как результат — это не модно.
Да нет, просто их в типах не видно, поэтому их и не любят. А монады — видно, поэтому их любят. ФП — это про типы и контроль эффектов.
ncwca
07.10.2021 23:54Что в монадах примитивного?
Всё, я описал выше. Мы должны искать не то, что "примитивное" - оно такое всё по умолчанию. А как раз таки то, что там не примитивное. И это должен показывать не я.
Ну, кроме того, что UB при попытке засунуть код с экзепшонами в параллельные алгоритмы получить можно, а с монадами — нет?
Можно. Здесь происходит не более чем манипуляция. А давайте мы возьмём ситуацию с шарингом и без. А ещё без учёта эффективности, хотя о ней потом расскажем.
Если исключения никак от друг друга не завися, как и остальная логика - никаких УБ нет. Исключения никак не накладывают каких-то требований на это. Если мы добавить в монады подобное - там будет такая же возможность УБ.
Да нет, просто их в типах не видно, поэтому их и не любят.
Максимальная чушь о которой я писал здесь уже несколько. Какие-то типа там существуют, только в максимально примитивных случаях. Далее начинается треш и угар.
Дам задачу. Дан раст, даны десятки разных множеств ошибок. Эти ошибки разной длинны и прочее. Есть множество функций, Которые возвращают ошибки из разных множеств. Дана логика, которая использует эти функции. Ваша задача показать мне примеры такую логику.
Реализовать "типы" для исключения использующихся в настолько примитивном контексте как монады - ничего не стоит. Их там не по другим причинам, описанным мною выше. Ничего из этого никакие монады не решают.
ФП — это про типы и контроль эффектов.
Это не ФП. Это новая мантра, которая появилась недавно, когда с прошлой стало всё плохо.
0xd34df00d
08.10.2021 01:25+4Всё, я описал выше. Мы должны искать не то, что "примитивное" — оно такое всё по умолчанию. А как раз таки то, что там не примитивное. И это должен показывать не я.
Выбирайте одно из двух продолжений спора в вашем стиле, а то мне лень:
- Я записываю вам слив.
- Я постулирую примитивность исключений по умолчанию, а вы доказывайте, что они непримитивные.
Если исключения никак от друг друга не завися, как и остальная логика — никаких УБ нет.
Напомните, знаток C++, что будет, если в
std::transform(std::execution::par, ...)функтор кинет исключение?Да, извините, не UB, а std::terminate — совсем другая разница, кидать экзепшоны из параллельных алгоритмов можно!
Если мы добавить в монады подобное — там будет такая же возможность УБ.
Откуда? С чего бы? Зачем вызывать UB (или, ладно, std::terminate) если монадическое вычисление вернуло Left?
Максимальная чушь о которой я писал здесь уже несколько. Какие-то типа там существуют, только в максимально примитивных случаях. Далее начинается треш и угар.
Настоятельно рекомендую перестать обобщать свой опыт и посмотреть на языки с нормальными системами типов?
Дам задачу. Дан раст, даны десятки разных множеств ошибок.
Не умею в раст, извините, поэтому буду на хачкеле, если вы не против.
Эти ошибки разной длинны и прочее. Есть множество функций, Которые возвращают ошибки из разных множеств. Дана логика, которая использует эти функции. Ваша задача показать мне примеры такую логику.
Ну очень просто (хотя я не знаю, что такое длина ошибки, ну да ладно). Каждая такая функция имеет тип вроде
fooN :: (Injectable ErrorTypeN e, MonadError e m) => ... -> m TyNи любая комбинация их имеет тип вроде
doSomething :: (Injectable ErrorType1 e, Injectable ErrorType2 e, ..., MonadError e m) => ... -> m Ty doSomething = do r1 <- foo1 arg1 foo2 arg2 arg3 r1 ...(этот тип можно даже не писать, компилятор его сам выведет).
Потом вы объявляете
data AllErrors = E1 ErrorType1 | E2 ErrorType2 | ... deriving (Generic, Injectable ErrorType1, Injectable ErrorType2, ...)и просто вызываете
doSomethingв контексте, ожидающем значение типаEither AllErrors Ty.Всё.
ncwca
08.10.2021 11:13-5Хоть я и зарёкся отвечать на подобное.
Я постулирую примитивность исключений по умолчанию, а вы доказывайте, что они непримитивные.
Поиграем. Показываю мат в один ход. Вот маленький кусок исключений - https://github.com/libunwind/libunwind, берёте раст и показываете кусок реализации примитивной монадной херни. Уровня хотя бы этого.
Напомните, знаток C++, что будет, если в
std::transform(std::execution::par,Это не C++, а мусор. К исключениям не имеет никакого отношения.
Откуда? С чего бы? Зачем вызывать UB (или, ладно, std::terminate) если монадическое вычисление вернуло Left?
Очень плохо. Никакое terminate там ненужно. Попытка выдать какой-то нюанс реализации в какой-то мусорной си с классами херни за свойства исключения.
И да, сообщаю, никакие треды ничего не возвращают и возвращать не могут. Вся коммуникация происходит отдельно, в том числе и через общую память. Как результат эта коммуникация может иметь какие-то проблемы в реализации.
Я переоценил оппонента и думал, что он мне расскажет о чём-то подобном. Если же он сливается на существующую магическую передачу, то никаких проблем с передачей исключений нет. Очевидно, как и любая другая коммуникация между тредами - они должны быть сведены до этой коммуникации. Точно так же как ваша скриптуха должна быть сведена к ней же.
Как поймать и заново кинуть исключение написано на каждом заборе и с этим проблем быть не должно, надеюсь.
Настоятельно рекомендую перестать обобщать свой опыт и посмотреть на языки с нормальными системами типов?
Настоятельно рекомендую не проецировать пропаганду и свою ограниченность на других, в том числе и другие языки. Система типов того же хаскеля - примитивный мусор.
doSomething :: (Injectable ErrorType1 e, Injectable ErrorType2 e, ..., MonadError e m) => ... -> m Ty doSomething = do r1 <- foo1 arg1 foo2 arg2 arg3 r1 ...Что это за мусор? она должна иметь пустую сигнатуру, а не этот бездарный мусор. Как это происходит в исключениях.
(этот тип можно даже не писать, компилятор его сам выведет).
Нет, очевидно. Скриптуха не может в вывод типов. Выпиливайте от туда гц, динамический диспатч, рантайм и прочий мусор.
Потом вы объявляете
Я не должен ничего объявлять. Я заранее об этом писал, что этот мусор ничего выводить не может и требует перепаковки всех типов ошибок.
и просто вызываете
doSomethingв контексте, ожидающем значение типаEither AllErrors Ty.Это самый мусорный мусор который можно придумать - общий глобальный тип. Причём закрытый, если он открытый - это так же мусор, о чём я писал.
Далее, с этим мусором я буду обязан проверять все возможные в программе типы ошибок каждый раз.
Далее, я не смогу сделать if(e != a) { return e;} - этот мусор не исключит a из списка ошибок.
И это только самое начало. И конечно же, меня не интересуют портянки на маргинальной тормозной гц-скриптухи.
0xd34df00d
08.10.2021 20:11+3Это не C++
«Знатока» C++ опять ткнули мордой в лужу, «знаток» C++ опять отмазывается офигительными историями о том, что кусок стандартной библиотеки C++ с поведением, описанным в стандарте C++, не является C++.
а мусор. К исключениям не имеет никакого отношения.
Описывается поведение при кидании исключения, но к исключениям это не имеет никакого отношения. Ясно-понятно.
Показываю мат в один ход. Вот маленький кусок исключений — https://github.com/libunwind/libunwind, берёте раст и показываете кусок реализации примитивной монадной херни. Уровня хотя бы этого.
Для вас сложность реализации является что ли показателем непримитивности? Ну тогда, конечно, да, тогда заодно и понятно, почему вам так гцц нравится — там же есть reload.c. Думаю, ни в одном другом компиляторе другого нет.
Попытка выдать какой-то нюанс реализации в какой-то мусорной си с классами херни за свойства исключения.
Это не нюансы реализации, а определение стандарта.
И да, сообщаю, никакие треды ничего не возвращают и возвращать не могут. Вся коммуникация происходит отдельно, в том числе и через общую память. Как результат эта коммуникация может иметь какие-то проблемы в реализации.
Вы даже неспособны подняться с уровня абстракции ОС-тредов на уровень абстракции вычислений, выполняющихся в том или ином контексте. Это уже даже в плюсах осилили с экзекуторами и корутинами, догоняйте.
Что это за мусор? она должна иметь пустую сигнатуру, а не этот бездарный мусор. Как это происходит в исключениях.
С чего бы? Она именно должна иметь в сигнатуре перечисление того, как именно она может упасть, что она и делает. Весь смысл всей этой монадической мутотени — чтобы ошибки было видно в типах.
Нет, очевидно. Скриптуха не может в вывод типов.
Вы совсем упоролись?
Далее, с этим мусором я буду обязан проверять все возможные в программе типы ошибок каждый раз.
Ура, первое замечание по существу, я уж боялся, что не дойдём. Ну раз вы перешли из начальной группы в подготовительную, вот вам ссылка.
На типах там можно сделать довольно продвинутую магию. Теперь жду от вас решения проблемы в плюсах «как посмотреть на функцию, и понять, какие ошибки она может кинуть».
0xd34df00d
09.10.2021 01:22+2Кстати тут уже не так понятно
А так всё хорошо начиналосьНу усложнение задачи иногда требует усложнения выразительных средств, да. Впрочем, в подавляющем большинстве случаев вся эта мутотень с расширяемыми на уровне типов ошибками оказывается ненужной, и достаточно обычного
MonadError.Все же привычнее когда у аргументов функции есть имена.
Вам в агду или идрис.

technic93
09.10.2021 05:19MonadError это фиксированный тип ошибки? Или обычно туда кладут просто строку, которую надо в конечном итоге отобразить в качестве ошибки?
0xd34df00d
09.10.2021 07:49+1Не, это
MonadError e m, просто возможность сказать «любая монада, реализующая возможность сообщить об ошибке типаe». Строкой или чем-то подобным часто и ограничиваются, да.
technic93
09.10.2021 15:07Получается как и в расте подход, а копродактом только в комментариях можно щеголять :)
0xd34df00d
09.10.2021 18:24+2Почему только в комментариях?
Если я пишу конечное приложение, а не библиотеку, и если оно, например, не особо крупное, то зачем мне там вся эта ерунда с копроизведениями?

Starche
09.10.2021 21:59+2let vec: Result<Vec<i32>, _> = "10.10.0.1".split('.') .map(|s| s.parse()) .collect();Можно и без unwrap, только vec будет типа Result. Дальше уж вам решать, что делать с этим Result, можно вверх выкинуть через
?, можно в Option сконвертировать через.ok(), можно обработать ошибку через паттерн-матчинг
Antervis
07.10.2021 12:06эм, а где в условии про это говорилось?
вы вообще даже конвертацию строки в число не написали
я писал свой сниппет с целью показать, что никакие "глубокие знания ренджей" не нужны, и, надеюсь, с этой задачей справился. Я нарочно опустил парсинг, т.к. он бы лишь увеличил сниппет, не преследуя эту цель. Вы же написали свой сниппет преследуя цель продемонстрировать какой раст красивый/хороший/лаконичный на фоне с++, спрятав в нём панику. И моя претензия даже не в том, что production-ready сниппет на расте должен выглядеть иначе, а в том, что писать код запихивая обработку ошибок под ковер в принципе не стоит ни в одном из языков.
Gordon01
07.10.2021 12:30Так уж и быть:
let vec: Vec<i32> = "10.10.0.1".split('.') .map(|s| // тут конвертация s в int ).collect();
ncwca
07.10.2021 14:53Это не может работать без исключений. В C++( в любом языке, при наличии+привычности исключений) так делать можно, а вот в расте нельзя.
0xd34df00d
07.10.2021 19:49+1Не обязательно, достаточно монадической обработки. Просто вернётся не массив интов, а
Either(или чего там в расте) из массива интов либо ошибки.
ncwca
07.10.2021 23:56Не обязательно, достаточно монадической обработки.
Там уже она была и с этим позорищем никто, в том числе автор коммента, позориться не хочет. Поэтому максимально пытается уйти от этого.
technic93
08.10.2021 01:55+1Нет, надо map заменять на mapM или чего там у вас в хаскеле? Или try_fold в расте, как написали выше. Нельзя написать простой код и сказать что он выкинет исключение если нужно. Надо подготовить окружающий код для начала.
В этом была суть обсуждения, что просто оставить комментарий "тут парсится число" можно только если предполагается ошибки кидать через исключения, что не требует дополнительных церемоний вокруг.
0xd34df00d
08.10.2021 02:13+3Нет, надо map заменять на mapM или чего там у вас в хаскеле?
Да,
mapMв данном случае.И? Это плохо? Сразу видно, что отображение с эффектом, хорошо же, и при этом всё так же немногословно. Или код с
mapсильно проще кода сmapM?Плюс, я раста-то не знаю, но почитываю на досуге, например, блог fpcomplete, и они там энное время назад писали вот ровно про такую возможность ошибок, правда, слегка на другом примере. Код получается тоже предельно простым:
fn main() { let myvec = vec![1, 2, 3, 4, 5, 6]; let new_vec = myvec .into_iter() .map(|x| { if x > 5 { Err("Not allowed to double big numbers") } else { Ok(x * 2) } }) .collect::<Result<Vec<_>, _>>(); match new_vec { Ok(new_vec) => println!("{:?}", new_vec), Err(e) => println!("{}", e), } }В расте даже буковку
Mдописывать не надо, там магия трейтов сама работает.В этом была суть обсуждения, что просто оставить комментарий "тут парсится число" можно только если предполагается ошибки кидать через исключения, что не требует дополнительных церемоний вокруг.
А если перед вами функция с типом
Read a => String -> Maybe a, вам даже комментарий оставлять не нужно.
technic93
08.10.2021 02:32Да, я про фишку с collect знал, но оставил как упражнение читателю :)
Не про тот комментарий речь шла, но вы свою рекламу типов все равно вставили =)
Только в Maybe нету информации об ошибки. И о том что вектору может не хватить памяти.
0xd34df00d
08.10.2021 02:41+1Только в Maybe нету информации об ошибки. И о том что вектору может не хватить памяти.
Ну будет
Either ParseError a, принципиальной разницы нет.И о том что вектору может не хватить памяти.
Ну будет у вас
insert :: a -> Vec a -> Either MemoryError (Vec a). Неудобно, но для тех применений, где возможность вставки в любой мелкий вектор может закончиться неудачно из-за нехватки памяти, важно.
technic93
08.10.2021 02:58Мы же там ИП адресс в вектор парсили так что надо MemoryError + ParseError делать, как вы там выше показывали. Или мемори ошибку игнорировать.
0xd34df00d
08.10.2021 03:24+2В плюсах был пропозал, чтобы ошибки выделения мелкой памяти вообще игнорировать и тупо завершать программу. Разумный для 99.9% случаев применения плюсов, я бы сказал.

eao197
08.10.2021 06:52Разумный для 99.9% случаев применения плюсов, я бы сказал.
Ну откуда, ну вот откуда у кучи людей такая убежденность, что в 99.9% ошибка выделения памяти фатальна? И почему 99.9%, а не 98.8% или 97.7%?
Блин, такое ощущение, что об инструменте с чрезвычайно широким спектром применения рассуждают люди-снежинки с шорами "мне не нужно, значит никому не нужно", "я так вижу" и "имею мнение".
0xd34df00d
08.10.2021 07:01+3Ну откуда, ну вот откуда у кучи людей такая убежденность, что в 99.9% ошибка выделения памяти фатальна?
Потому что там, где памяти много, ошибку в
std::string s { "hello world, rust suxxx, c++ rulezzz" }никто не обрабатывает, и экзепшон оно кинет скорее потому, что программист своими корявыми руками проехался по внутренним стуктурам хипманагера, чем из-за того, что памяти не хватило. Единственный класс ошибок, который там обрабатывается — когда вы выделяете 100500 мегабайт на обработку картинок, кручение матриц и прочее, что происходит явно и изолированно, в отличие от создания строк для условного UI.
А там, где памяти мало и корректная работа важна (а не только светодиодами помигать) — там её выделяют примерно перед началом основной работы, и если её выделить не удалось, то железка тупо не запускается.И почему 99.9%, а не 98.8% или 97.7%?
Извините, пересчитал оценку — вынужден поправиться, там на самом деле 99.84%.
Блин, такое ощущение, что об инструменте с чрезвычайно широким спектром применения рассуждают люди-снежинки с шорами "мне не нужно, значит никому не нужно", "я так вижу" и "имею мнение".
Для демонстрации того, как надо, основываясь на вашем соседнем комментарии, предоставьте, пожалуйста, адекватную и обоснованную оценку востребованности хаскеля и идриса, которую нельзя было бы списать этими аргументами.
eao197
08.10.2021 07:42+2Потому что там, где памяти много, ошибку в
std::string s { "hello world, rust suxxx, c++ rulezzz" }никто не обрабатываетС такими аргументами спорить невозможно. "никто не обрабатывает" и все, я сказал.
Подобных утверждателей можно отправлять в пешее эротическое с простым обоснованием: в вашем говнокоде вы можете делать все, что вам заблагорассудится, но почему ваши взгляды на то, как следует писать код, следует распространять на всех?
Тут ведь просто: если на уровне стандарта языка закрепят, что теперь вместо bad_alloc будет гарантированный terminate, то это затронет вообще всех. Вообще.
При этом уже сейчас верователи в то, что маленькие аллокации не могут привести к bad_alloc-у (а так же верователи в то, что после bad_alloc-а жизни нет) могут получить нужный им эффект сделав свой собственный new_handler. Совершенно не мешая всем остальным.
Но нет, нужно бегать и кричать, что bad_alloc -- это все в 99.9 или 99.84% случаев. Почтому что я самый умный и у меня куча разнообразных проектов за плечами.
предоставьте, пожалуйста, адекватную и обоснованную оценку востребованности хаскеля и идриса, которую нельзя было бы списать этими аргументами.
Посмотрите хотя бы на количество и объемы проектов на разных языках на гитхабе.
0xd34df00d
08.10.2021 07:58+2Подобных утверждателей можно отправлять в пешее эротическое с простым обоснованием: в вашем говнокоде вы можете делать все, что вам заблагорассудится, но почему ваши взгляды на то, как следует писать код, следует распространять на всех?
Приведёте хотя бы один пример проекта под десктоп, в котором подобные случаи консистентно и адекватно (ну то есть не
catch (const std::bad_alloc&) { std::cout << "ouch" << std::endl; abort(); }) обрабатываются? Желательно, чтобы автор не погиб под получающейся кучей кода и выдал при этом что-то полезное.у меня куча разнообразных проектов за плечами.
Именно. Если в финансовом коде с 30-летней историей оно не обрабатывается, в HFT с 5-летней историей оно не обрабатывается, в скучном десктопном софте уровня KDE оно не обрабатывается, в прошивках для автономных автомобилей не обрабатывается (ну там всё заранее выделяется просто), етц — по этим данным, наверное, можно составить некоторое впечатление о распространённых практиках?
Посмотрите хотя бы на количество и объемы проектов на разных языках на гитхабе.
Прикольно. Там упомянутые вами рядом как нижняя грань нужности ruby стоят на пятом месте, а плюсы — на седьмом (то есть, ниже ruby). Более того, плюсы — вторые по потере доли рыночка (хуже дела только у go), а упомянутые вами руби растут как грибы после дождя (и лучше дела только у джавы, ну и скала ещё плюс-минус там же на уровне погрешности).
Мне прям интересно, как вы теперь съедете с темы.
eao197
08.10.2021 08:06+1Приведёте хотя бы один пример проекта под десктоп, в котором подобные случаи консистентно и адекватно
Вы сами выдумываете проблемы, а затем я за вас их должен решать? С херали, пардон муа?
Представьте себе прокси-сервер, например, (или MQ-шный брокер, или СУБД сервер). С каждым подключением связано свое собственное состояние. В какой-то момент при модификации этого состояния возникает bad_alloc. Нет проблем, чистим то, что связано с этим подключением и отрубаем конкретное подключение. Остальное продолжает работать.
етц — по этим данным, наверное, можно составить некоторое впечатление о распространённых практиках?
О распространенных практиках в этих областях -- да.
Мне прям интересно, как вы теперь съедете с темы.
С какой темы, простите? Вот что я говорил:
Скорость работы компилятора Go -- это проблема целой индустрии. Скорость работы компилятора C++ -- это так же проблема целой индустрии. Как и скорость работы компилятора Java.
А вот с какой скоростью компилируются Haskell с Idris-ом... Ну вас это может и волнует.
Таки да, Haskell и Idris-ом волнует исчезающе малое количество программистов. Так было и в 2005, и в 2016, и в 2021.
0xd34df00d
08.10.2021 08:11Представьте себе прокси-сервер, например, (или MQ-шный брокер, или СУБД сервер). С каждым подключением связано свое собственное состояние. В какой-то момент при модификации этого состояния возникает bad_alloc. Нет проблем, чистим то, что связано с этим подключением и отрубаем конкретное подключение. Остальное продолжает работать.
Какую долю среди всех проектов составляют СУБД-сервера и message broker'ы?
О распространенных практиках в этих областях — да.
Я понимаю, что брокеров пишется примерно столько же, сколько десктопных поделок на плюсах (хотя это может быть и неиронично уже), но всё же, имейте совесть.
С какой темы, простите?
Со сравнения с рубями и использования статистики гитхаба для этого.
eao197
08.10.2021 08:23Какую долю среди всех проектов составляют СУБД-сервера и message broker'ы?
А почему вы у меня это спрашиваете? Это во-первых.
Во-вторых, если даже эти проекты составляют 1% от всего, что разрабатывается на C++, то почему этому 1% нужно навязывать что-то? Тем более, что нужное вам поведение вы уже сейчас получаете через set_new_handler без влияния вообще на кого-либо.
но всё же, имейте совесть.
Еще раз повторю: перестаньте смотреть на мир через шоры "мне не нужно, значит никому не нужно".
Со сравнения с рубями и использования статистики гитхаба для этого.
А вы выключите дурочку и вернитесь назад, к тому, откуда вообще это взялось. А взялось с утверждения о значимости скорости работы компиляторов отдельных языков на индустрию. И о том, что Хаскель с Идрисом мало кому интересен.
Пока что все именно так. Как бы вы не пытались заболтать меня левыми претензиями.
0xd34df00d
08.10.2021 08:32Во-вторых, если даже эти проекты составляют 1% от всего, что разрабатывается на C++, то почему этому 1% нужно навязывать что-то?
Потому что язык без навязываний есть только один — машинные коды.
Тем более, что нужное вам поведение вы уже сейчас получаете через set_new_handler без влияния вообще на кого-либо.
Да дело не в возможности реализации поведения, а в том, что нужно ли оно вообще на практике или нет.
А вы выключите дурочку и вернитесь назад, к тому, откуда вообще это взялось.
Понимаю, как в том анекдоте, не прокатило.
eao197
08.10.2021 08:39Понимаю, как в том анекдоте, не прокатило.
Т.е. по сути сказать нечего. ЧТД.
Это всего вашего комментария касается.
0xd34df00d
08.10.2021 08:48+3— Хаскель нинужно.
— Как численно измерить, что нинужно, раз вы так апеллируете к объективности?
— Он даже до рубей по популярности не добрался.
— Как это объективно измерить?
— Ну вот на гитхабе рейтинг языков и проектов.
— Но там и плюсы стремительно сливают и уже проигрывают тем же рубям.
— Ой вы меня заболтали выключите дурочку претензии левые.Что тут скажешь?
eao197
08.10.2021 08:54Скажу:
я не утверждал, что Хаскель нинужно. Речь шла про то, что его влияние на индустрию минимально и, поэтому, приведение в пример компилятора Хаскеля (и, тем более, компилятора Idris-а) не имеет большого смысла;
то, что по статистике github-а плюсы сливают по полярности Ruby, никак не соотносится с вопросом о том, достиг ли Хаскель популярности/востребованности Ruby.
Откуда следует, что вы занимаетесь демагогией, подтасовкой и заменами тезисов, плюс не отвечаете за свои слова. С чем вас и поздравляю.
0xd34df00d
08.10.2021 09:02+1Но, простите мне мой французский, LOR-овский жаргон в этом конкретном случае одно образцовое нинужно соревнуется с другим образцовым нинужно.
я не утверждал, что Хаскель нинужноЛан.
то, что по статистике github-а плюсы сливают по полярности Ruby, никак не соотносится с вопросом о том, достиг ли Хаскель популярности/востребованности Ruby.
Вы же спросили
С чего бы? За посление 5 лет Хаскель догнал по востребованности хотя бы Ruby?
в контексте популярности и (ни)нужности языка.
Оставьте эти методы для устного общения, где ваши предыдущие высказывания недоступны.
eao197
08.10.2021 09:07в контексте популярности и (ни)нужности языка.
Контекст был несколько другой.
ваши предыдущие высказывания недоступны.
Так вернитесь и перечитайте, хватит передергивать и извращать чужие слова. Если уж за свои ответить не можете.
0xd34df00d
08.10.2021 09:12+1Контекст был несколько другой.
Мне серьёзно надо цитировать вас, и что это было вашим ответом на то, что ваши шутки про нинужность хаскеля устарели (то есть, как следствие, доказательством нинужности)?
eao197
08.10.2021 10:09Вы лучше прочитайте написанное мной еще раз. Акцент не на шутках про нинужность, акцент на то, что призводительность компилятора Хаскеля волнует мизерное количество разработчиков (по сравнению с оным количеством для Java, C++, Go). И раз вы с этим не согласны (а вы, как я понял не согласны), то вам же не составит труда показать, что востребованность/популярность Хаскеля догнала хотя бы Ruby. Не составит же, да?
technic93
08.10.2021 15:45Какую долю среди всех проектов составляют СУБД-сервера и message broker'ы?
Достаточную, вот вам пример когда нужно отлавливать исключения в ядре асинхроного фреймворка раста https://github.com/tokio-rs/tokio/search?q=catch_unwind
Если вы замените всё на abort() то вас проклянут..
ncwca
08.10.2021 11:17fn main() { let myvec = vec![1, 2, 3, 4, 5, 6]; let new_vec = myvec .into_iter() .map(|x| { if x > 5 { Err("Not allowed to double big numbers") } else { Ok(x * 2) } }) .collect::<Result<Vec<_>, _>>(); match new_vec { Ok(new_vec) => println!("{:?}", new_vec), Err(e) => println!("{}", e), } }Боже, это позорище. Этот расчёт на те, что все вокруг идиоты и не заметят фокусы.
Если кому непонятно в чём проблема. Этот мусор не является полиморфным. Т.е. если мы добавим туда ещё какое-то Err(123), либо что-то типа того - оно сломается нахрен.
И починить это можно будет только создав мусорный enum где-то там. Создавать его нужно на каждую функцию. Потому что у каждой функции свой уникальный набор ошибок.
0xd34df00d
08.10.2021 20:20+2Единственный фокус здесь — ваш сдвиг goalpost'ов. Изначально речь шла о том, как обрабатывать ошибки в задаче «преобразовать последовательность строк в числа». У вас тут внезапно появились какие-то новые ошибки и претензии к тому, что придётся написать немного кода ради статической безопасности.
Но я не против, давайте поговорим о добавлении исключений. Напомните, что будет, если вы сделаете
throw 123;в коде, где до всего мейна включительно нетcatch (int)? Даже ваше родимое RAII не факт что спасёт, потому что раскрутка стека для непойманных исключений — implementation-defined. Ну или как говорит [except.terminate]/2:In the situation where no matching handler is found, it is implementation-defined whether or not the stack is unwound before std::terminate is invoked.
Или это тоже мусор, а не C++, и к исключениям отношения не имеет?
ncwca
09.10.2021 01:44-3Изначально речь шла о том, как обрабатывать ошибки в задаче «преобразовать последовательность строк в числа».
Нет. Это лишь пример того, что даже в такой примитивной задаче мусор пасует. А код, который выдаёт адепт за решение - не работает.
У вас тут внезапно появились какие-то новые ошибки
Да, потому что в реальности тип ошибки не один. То, что пропагандист пытается всё свести к одному типу, где проблем нет(даже в си нет. Там даже полиморфизм ненужен).
что придётся написать немного кода ради статической безопасности.
Пропагандисты уверяли, что кода нет и его писать ненужно. В том числе и данный, когда выдавал фейк за реализацию.
Вот посмотрите на эту херню от пропагандиста:
fn main() { let myvec = vec![1, 2, 3, 4, 5, 6]; let new_vec = myvec .into_iter() .map(|x| { if x > 5 { Err("Not allowed to double big numbers") } else { Ok(x * 2) } }) .collect::<Result<Vec<_>, _>>(); match new_vec { Ok(new_vec) => println!("{:?}", new_vec), Err(e) => println!("{}", e), } }Как думаете, почему он убрал парсинг? Почему он сейчас несёт чушь "речь шла о преобразовании", но где у него преобразование? Вы видите?
А теперь прочитайте то, что я писал на тему его статеек. Он не способен даже не то что этой реальности противоречить - он противоречит даже тому, что писал. И пишет сейчас.
Потому что если туда добавить парсинг, то у нас будет как минимум 2 ошибки. И то если парсинг возвращает лишь один тип.
Т.е. даже в рамках этой задачи максимально удобной пропагандисту - он потерялся и запутался в своих же методичках.
Напомните, что будет, если вы сделаете
throw 123;в коде, где до всего мейна включительно нетcatch (int)? Даже ваше родимое RAII не факт что спасёт, потому что раскрутка стека для непойманных исключений — implementation-defined. Ну или как говорит [except.terminate]/2:Эту и другую чушь мне даже комментировать лень. Смотирте как он скачет с те мы на тему. Как он пытается хоть что-то в гугле найти. Даже не понимания что это и зачем.
Если кому непонятно как родилась эта его чушь. Он заучил где-то "кидать что-то без базы std::exception нельзя". Решил козырнуть этим как "смотри, нельзя поймать".
Потом погуглил про catch(int) и понял, что опозориться. Потом где-то увидел, что не пойманное исключение какая-то проблема.
Во-первых никакой проблемы нет. C++ - это implementation-defined. Если какой-то пропагандист вам несёт иное - просите с него iso defined поведения в его скриптухе. В ответ получаете рыдание и слепую ненависть.
Во-вторых, какое такое raii и как оно должно спасти? Исключение это, в том числе, нелокальный переход. Нелокальный переход куда-либо в астрал - произойти не может.
Если оно происходит в астрал - программа уже не существует. Нет определено место с которого будет продолжено исполнение. Поэтому то, что что-то там падает - вполне ожидаемое и адекватное поведение. Другого там быть не может.
Что хотел сказать данный пропагандист? Просто несёт и перепащивает херню из интерната. В надежде на то, что никто ничего не поймёт.
0xd34df00d
09.10.2021 02:10+3Да, потому что в реальности тип ошибки не один. То, что пропагандист пытается всё свести к одному типу, где проблем нет(даже в си нет. Там даже полиморфизм ненужен).
Эту и другую чушь мне даже комментировать лень. Смотирте как он скачет с те мы на тему. Как он пытается хоть что-то в гугле найти. Даже не понимания что это и зачем.
Как думаете, почему он убрал парсинг? Почему он сейчас несёт чушь "речь шла о преобразовании", но где у него преобразование? Вы видите?
Во-первых, я не пропагандист раста, вы там в пылу ненависти ко всем неосиляторам Настоящего C++ уже путаете оппонентов.
Во-вторых, я ничего не убирал, а скопипастил код из блога, который видел год назад — потому что раст читать могу, а писать на нём — нет.Если кому непонятно как родилась эта его чушь.
Телепат из вас так себе. Например, какая здесь связь? «Потом погуглил про catch(int) и понял, что опозориться. Потом где-то увидел, что не пойманное исключение какая-то проблема.»
Просто, в отличие от вас я ковырял, как устроены экзепшоны в C++, и знаю, что любое кинутое исключение должно быть поймано хотя бы в
main, иначе будет задница.Во-первых никакой проблемы нет. C++ — это implementation-defined.
И с реализациями, которые на самом деле не вызывают деструкторы в таком случае, я сталкивался. И они полностью (в этом) соответствуют стандарту, даже багрепорт не откроешь, увы.
Если какой-то пропагандист вам несёт иное — просите с него iso defined поведения в его скриптухе. В ответ получаете рыдание и слепую ненависть.
Зачем? Шильдик ISO наделяет что-то магическими свойствами только у папуасов. Мне абсолютно плевать, пусть там хоть три шильдика ISO, если соответствующий стандарт допускает хрень. У вас магическое мышление как оно есть.
Во-вторых, какое такое raii и как оно должно спасти?
Ну там, я не знаю, откатить транзакцию у сервера БД (да, я понимаю, что в вашем мире БД нинужно), записать буферы в файл (снова понимаю, что настоящие C++-ники в вашем мире не пишут в файлы, а пишут факториалы на темплейтах, но всё же есть и ненастоящие).
Если вы случайно кинули исключение, которое вы нигде не ловите, то всё, самая хвалёная, самая ключевая часть подхода C++ к управлению ресурсами отваливается, вылетает в трубу, оказывается совершенно ненужной. Отличный язык, прекрасный, ничего не скажешь.
Но да, раст хуже — ведь он даст по рукам, придётся дописать код, после чего всё будет работать. Не получится списать недели на поиск бага, job security под угрозой.
Нелокальный переход куда-либо в астрал — произойти не может.
Вы поразительно необразованы для апологета C++. Для того, чтобы починить это поведение, достаточно завернуть
mainвtry { ... } catch (...) { throw; }Переход в астрал есть? Есть. Адекватная раскрутка стека при этом есть? Да, есть, теперь это гарантируется стандартом.
Проваливайте-ка вы и прекращайте тратить время окружающих. Вы не знаете плюсы, не знаете их философию, не знаете, что встречается на практике. Вы нахватались каких-то отрывочных знаний по верхам и потом с ними раз-два в год, под осенне-весеннее обострение вашей шизофрении, прибегаете на хабр/лор/етц и пишете очередные офигительные истории. Не надо так.
ncwca
07.10.2021 01:07-4Лучше нунжно - это будет максимально фатально для вас. Просто в силу того, что в С++ есть полиморфизм и вот этот костыль:
Vec<i32> ненужен. Да и этот .collect(); тоже. да и этот .iter - тоже.Не говоря уже о том, что в векторе нет RA бесплатного, а в итераторах его нет никакого.
Gordon01
07.10.2021 03:33Я понимаю, что вы не осилили итераторы, но зачем писать об этом на весь хабр?
Пишите на своих плюсах, упарывайтесь шаблонами, ООП, исключениями и другой дрянью.
А я буду писать на расте, только ради того, чтобы в работе никогда не сталкиваться с такими людьми как вы. И это стоит дороже, чем любые плюшки языка.Вы забыли еще написать, что "без unsafe ничего полезного не напишешь". Слабо троллите. Почитайте методички, что ли.
ncwca
07.10.2021 14:57-1Что там в итераторах в расте осиливать? Там итераторы уровня жаваскрипта, максимально примитивное next-убожество. И если в жаваскрипте это ещё понять можно, то вот в расте нет.
В C++ были и развивались итераторы практически со всём из зарождения. Их возможности и классификация куда лучше, шире и больше. Говорить используя убогую пародию адепту оригинала - это максимально смешно.

DarkEld3r
07.10.2021 11:43+1Просто в силу того, что в С++ есть полиморфизм и вот этот костыль: Vec ненужен
Возможно, я чего-то не понял, но разве в С++ не нужно указывать тип контейнера, если требуется создать его из диапазона? Как это может работать?
Gordon01
07.10.2021 11:54-2Да это типичные мечты плюсовика: что вот-вот, буквально еще пара версий и можно будет написать
auto auto(auto auto) { auto; }Но в реальности код на современных плюсах выглядит примерно так:
$??s:;s:s;;$?::s;;=]=>%-{<-|}<&|`{;;y; -/:-@[-`{-};`-{/" -;;s;;$_;seeГлавное погромче кричать раст — говно и тогда auto придет быстрее
ncwca
07.10.2021 14:35-2Возможно, я чего-то не понял, но разве в С++ не нужно указывать тип контейнера, если требуется создать его из диапазона? Как это может работать?
Ненужно, потому что ненужны контейнеры. Я об этом там же написал. И ничего там не требуется - это неболее чем попытка манипулировать. Контейнер там - это костыль, а не необходимость.
В C++ же такой необходимости нет. Как результат никакого контейнера там и тормозов, конечно же, не будет.
DarkEld3r
08.10.2021 07:06В коде выше (на С++ контейнер) был, но ок — не нужен так не нужен. Задача была разобрать строку в набор интов, так? И что с ними делать дальше? Просто если в С++ результат в контейнер не нужен, то он не будет нужен и в расте. Ну или я не понял аргумента.
ncwca
08.10.2021 16:10-3Просто если в С++ результат в контейнер не нужен, то он не будет нужен и в расте. Ну или я не понял аргумента.
Нужен. Вы не понимаете того о чём говорите.
И ведь я уже объяснил почему. В расте нет полиморфизма - итератор это мусор, который может только в последовательный доступ. Так же мы не может писать обобщённый код в этой примитивной скриптухи, поэтому мы обязаны хардкодить типы.
Если в C++ мы можем написать auto, то в скриптухе нет.
Именно поэтому в скриптухах везде и всюду collect и нигде не используются итераторы. Потому что а) они не полиморфны, б) язык максимально примитивен и не может вообще, либо каким-либо приемлемым образом выражать обобщённую логику.
ncwca
05.10.2021 21:59+2Какая-то очень странная логика. А вам не кажется, что у языков нет как такового потребления, производительности и всего проче, что любят им приписывать? Чем отличается тот же C++ и js? Только тем, относительно потребления памяти/производительности, какие возможности даёт язык программисту, но как и любые другие возможности - возможность никак не выражается напрямую в потребительских качествах. Нужен тот, кто ею воспользуется и это качество создаст.
В данно же случае наличие
"Hello".replaceAll("Hello", "world") является тем, следствием чего является "жрущий по 2 гига". Сведя другой язык к тому же, даже если не язык, а программистов - одно без другого не работает, причину я описал выше.Пблема с "взять либу" максимально вывсосана из пальца. 95% программирования на жс и подобных языках сводится к использованию либ. Большая часть из которых лефтпады.
"ой нуйдёт" - он уйдёт, если ему без разницы на те самые "2 гига"", а так же если если у него нет необходимых компетенций. Если что-либо иначе - для него
replaceAll практически не существует.Больше скажу - C++, наверное, самый выразительный язык из всех. Я не видел языка другого, который бы позволял упоковывать столько семантики в столь компактные/красивые языковые коснтуркции.
Но, эта выразительность требует недюжего понимания, умений и способностей. И нет, не потому, что это C++. Просто, в отличии от других, C++ действительно пытается думать о тех самых "2 гига". Создать кое как работающую абстракцию, которая игнорирует все проблемы - просто. Создать абстракцию, которая выжает минимальное количество смысла - просто.
Создать же что-то за рамками этого - сложно. C++ здесь первопроходет. Самое важное - в идеале эти абстракции не должн позволить существованию
replaceAll.В каком случае эта операция будет, как минимум, эффективна(неэффективность самой задачи выношу за скобки - её там нет)? Когда мы заменяем одну строку на другую. Нам нужны две операции. Поиск слайса и реплейс над слайсом, где уже гарантируется, что мы не изменим что-то за границами слайса. И C++ движется в эту сторону.
Конечно же, под C++ я имею ввиду некие C++ будущего в вакууме. Это не тоже самое, что обычное во многом врайт-онли си с классами. Оно всё тот же сишный подход не переродившийся в новом качестве, как C++.

MooNDeaR
05.10.2021 22:32+5Я не видел языка другого, который бы позволял упоковывать столько семантики в столь компактные/красивые языковые коснтуркции.
Кхе-кхе... Haskell... Кхе-кхе)
ncwca
07.10.2021 00:59-3Нет, очевидно. Никакого зерокоста, выразительности и прочего. Нагромождение рандомных символов - это не выразительность.
0xd34df00d
07.10.2021 19:59+2Зерокоста там действительно нет (но его на самом деле нигде нет, вам нужно и в плюсах точно так же заботиться о том, чтобы достаточно умный компилятор соптимизировал ваш код), а вот списывать выразительность со счетов из-за отсылок к рандомным символам в треде о плюсах — это достаточно иронично.
ncwca
08.10.2021 00:11-2но его на самом деле нигде нет, вам нужно и в плюсах точно так же заботиться о том, чтобы достаточно умный компилятор соптимизировал ваш код
Есть. Манипуляция заключается в том, что раз у нас есть компилятор в обоих случаях и нам нужно думать - значит разницы никакой нет.
Только она есть. Компилятору важно то, какой код будет. C++ оптимизируется - хаскель-лапша нет. Только в максимально примитивных специально подобранных случаях, когда компилятор способен преобразовать мусорный код во что-то более адекватное. И это работает для чего угодно. Это работает так для любой скриптухи.
Далее возникает другая проблема. Код, который нужен, условно, компилятору - как он соотносится с тем, что принято/привычно писать на языке. Что возможно/удобно на нём писать. И окажется, что даже самый подобранный кейс, с максимальным количеством вранья и манипуляций - не работает.
Можете почитать его статьи и откровения в них. Где в одной он соревновался с максимально дефолтной лапшой на C++ в подложном кейсе. Пыхтел там не один день, если не одну неделю, обмазываясь ансейфами, массивами и прочим. Чтобы родить "я получил быстрее" и получить его лишь потому, что всё перепутал.
С другой его статьёй такая же история. Максимально мусорная и специально подобранная задача. Никакого понимания как и что работает. После его победа начала сливать. После там началась эпопея с атомиками. Он обещал показать победу на атомиках, но что-то этого до сих пор не случилось.
а вот списывать выразительность со счетов из-за отсылок к рандомным символам в треде о плюсах — это достаточно иронично.
В C++ нет и не было нагромождений рандомных символов.
Опять попытка вранья и манипуляций в надежде, что группа поддержки заминусует неугодного. И нужно лишь создать видимость аргуементации.
Наличие символов в C++ никак ничего не значит. Символы есть практически во всех языках. Нам важно то насколько удобны эти символы и как они выглядят и как используются. И сколько семантики полезной код использующий их выражает.
0xd34df00d
08.10.2021 02:08+2C++ оптимизируется — хаскель-лапша нет. Только в максимально примитивных специально подобранных случаях, когда компилятор способен преобразовать мусорный код во что-то более адекватное.
Учитывая разницу между уровнями абстракции — эт скорее плюсовая лапша не очень оптимизируется. Во всех языках для получения адекватной производительности нужно писать под компилятор, магии нет.
Пыхтел там не один день, если не одну неделю
Да не один месяц сразу, чего уж.
обмазываясь ансейфами
Довольно странно это слышать со стороны плюсов, где вообще всё — ансейф, где сейф-множества, проверяемого компилятором, просто нет как класса.
Или вы из тех, для кого
vector::unsafeElemAt(int i) { return arr_[i]; }хуже чем
vector::operator[](int i) { return arr_[i]; }потому, что в первом случае есть слово ансейф?
массивами и прочим.
Чем плохо? Разрушает ваши иллюзии, что код на хаскеле обязан быть только со списками? Я думал, мы избавились от них в прошлые разы.
В C++ нет и не было нагромождений рандомных символов.
Рандомных символов нет даже в перле, конечно. Не подменяйте тезис.
Нам важно то насколько удобны эти символы и как они выглядят и как используются. И сколько семантики полезной код использующий их выражает.
Да, лучше написать лапшу из
std::optional, как в исходном постеauto MonadicOptional(std::optional<std::size_t> value) { return value .transform([](std::size_t value) { return value - 40uz; }) .or_else([]() { return 7uz; }) .and_then([](std::size_t value) { return std::string(value, '-'); }) ; }и учить API каждого конкретного частного случая, чем единожды понять, что значат стандартные
<&>,<|>и>>=, применимые к любому функтору, alternative и монаде соответственно.Очень удобно.
ncwca
08.10.2021 11:31-2Учитывая разницу между уровнями абстракции — эт скорее плюсовая лапша не очень оптимизируется. Во всех языках для получения адекватной производительности нужно писать под компилятор, магии нет.
Смотрим на это максимально нелепое враньё. Опять же, очередной мат в один ход.
Идём сюда: https://habr.com/ru/post/483864/
Берём его "код" на С++. Смотрим:
size_t lev_dist(const std::string& s1, const std::string& s2) { const auto m = s1.size(); const auto n = s2.size(); std::vector<int64_t> v0; v0.resize(n + 1); std::iota(v0.begin(), v0.end(), 0); auto v1 = v0; for (size_t i = 0; i < m; ++i) { v1[0] = i + 1; for (size_t j = 0; j < n; ++j) { auto delCost = v0[j + 1] + 1; auto insCost = v1[j] + 1; auto substCost = s1[i] == s2[j] ? v0[j] : (v0[j] + 1); v1[j + 1] = std::min({ delCost, insCost, substCost }); } std::swap(v0, v1); } return v0[n]; }Это эталонная лапша. Никакой даже попытки писать "под компилятор" не было и нет.
Смотрим его хаскель-лапшу.
import qualified Data.ByteString as BS import qualified Data.Vector.Unboxed as V import Data.List levenshteinDistance :: BS.ByteString -> BS.ByteString -> Int levenshteinDistance s1 s2 = foldl' outer (V.generate (n + 1) id) [0 .. m - 1] V.! n where m = BS.length s1 n = BS.length s2 outer v0 i = V.constructN (n + 1) ctr where s1char = s1 `BS.index` i ctr v1 | V.length v1 == 0 = i + 1 ctr v1 = min (substCost + substCostBase) $ 1 + min delCost insCost where j = V.length v1 delCost = v0 V.! j insCost = v1 V.! (j - 1) substCostBase = v0 V.! (j - 1) substCost = if s1char == s2 `BS.index` (j - 1) then 0 else 1Здесь он уже наврал про "наивная". Он не использовал хаскель-примитивы и прочую херню, а сразу пастил крестовые векторы.
Ладно, сделаем скидку на это. Адепт любой херни готов отрицать что угодно в пользу своей веры. Примем то, что массивы, мутабельностотсь и прочее - это хаскель.
Заходим на сайт и читаем:
An advanced, purely functional programming language
Да, это именно так и работает.
Смотрим примеры, которые нам суют в лицо:
23 * 36 or reverse "hello" or foldr (:) [] [1,2,3]ой, а что это? Неужели списочек. А где же вектор?
У C++ нет никакого сайта, но я вас уверяю - откройте любой туториал и там будет вектор. Именно вектор. Именно вектор является базовой сущность, что сишки, что С++. Вернее не вектор, а массив.
Теперь можете прочитать его куллстори и те портянки, что он рожал в процессе. Чего он добивался своими приключениями? Попытки подражать производительности C++. И да, не нужно обмазываться - никакое C++ он там не победил. Он опять всё перепутал.
Потом посмотрите на тот мусор, что он родил. Видите там уровень абстракции? Нет. Видите там количество синтаксического мусора? да. Видите там в случае с C++ каких-то изменений код под компилятор? Нет.
Таким образом ладно, что его лозунги противоречат этой реальности - похрен на реальность. Он противоречит даже тому, что сам наблюдает и о чём пишет.
Это первый признак фанатика.
0xd34df00d
08.10.2021 20:29+3Это эталонная лапша. Никакой даже попытки писать "под компилятор" не было и нет.
Однако, разные компиляторы оптимизируют
std::min({ delCost, insCost, substCost });по-разному, причём, в зависимости от порядка. Так что даже простейшая лапша требует заточки под компилятор, и от малейшего дуновения ломается.Он не использовал хаскель-примитивы и прочую херню, а сразу пастил крестовые векторы.
Какие крестовые векторы? Где вы там кресты увидели?
ой, а что это? Неужели списочек. А где же вектор?
И что? Любой библиотеки, которой нет в примерах на главной странице, теперь не являются языком?
У C++ нет никакого сайта, но я вас уверяю — откройте любой туториал и там будет вектор. Именно вектор.
Натягивание совы на глобус и подмена тезиса. Если мы будем брать только то, что пишут в туториалах, то ваш тезис о темплейтах рассыпется в труху.
Потом посмотрите на тот мусор, что он родил. Видите там уровень абстракции? Нет. Видите там количество синтаксического мусора? да. Видите там в случае с C++ каких-то изменений код под компилятор? Нет.
При этом вы приводите версию, которая обгоняет плюсы. Версия, где всё чисто и с нулевой мутабельностью — как раз посередине между плюсовым кодом, собранным gcc, и собранным clang'ом (причём clang быстрее).
Вранье, подгонка тезисов и неумение читать с вашей стороны.
technic93
09.10.2021 01:00-1как раз посередине между плюсовым кодом, собранным gcc, и собранным clang'ом
А теперь запустите на других данных и будет на первом месте gcc потом clang, потом хаскель. То что вам в одном случае из ста очень "повезло" с данными и с расстановкой бранчей шлангом, -- не позволяет делать какие-то обобщения.
Можно сделать вывод что Хаскель не вносит серьезных дополнительных расходов в код написанный на unsafe+ST, но это небольшое достижение, потому что и питон-jit и js, как показали бенчмарки в комментариях, точно так же не вносят.
Но плюс питона что код получается ближе к привычной алгоритмической записи. Когда мне нужно заботится о корректности индексов, потому что мы пишем ансейф, удобнее читать
v[i]вместоv `V.unsafeIndex` i.
0xd34df00d
09.10.2021 01:27+1Можно сделать вывод что Хаскель не вносит серьезных дополнительных расходов в код написанный на unsafe+ST
unsafe + ST там вообще обгоняет плюсы. Из того, что вы написали, можно сделать вывод, что чистый иммутабельный хаскель с отключёнными проверками на выход за границы массивов не вносит дополнительных расходов в код.
это небольшое достижение, потому что и питон-jit и js, как показали бенчмарки в комментариях, точно так же не вносят.
JS там в три раза медленее ЕМНИП. Ну так себе «не вносит».
Когда мне нужно заботится о корректности индексов, потому что мы пишем ансейф, удобнее читать v[i] вместо v
V.unsafeIndexi.Ну так напишите перед этим всем
(!) = V.unsafeIndexи используйте
v ! i, почти как с библиотечным оператором.Это ж исключительно вопрос дефолтов — сделать, чтобы приятнее и быстрее было писать код с проверками или без них. Ну, как в C++ STL
operator[]без проверок, аatс проверками, а в кутях — наоборот.
technic93
09.10.2021 05:40Если локально можно переопределить операторы, то это хорошо.
А по поводу скорости, во первых емнип чистый хаскель без ансейф не обгоняет даже на ваших везучих данных. А на более реалистичных данных с отсутствием таких очевидных ближних корреляций, он не обгоняет никогда.
Хотя наверное можно настроить ллвм чтобы он генерировал такой же универсальный код как гцц. А, ещё там разница в скорости от архитектуры зависла раза в полтора.
Вроде на тему ваших замеров мы обсудили все что можно, не охото по второму разу проговаривать. А про ансейф индексы уже и в контексте раста проговорено стопицот раз.
0xd34df00d
09.10.2021 07:57+1А по поводу скорости, во первых емнип чистый хаскель без ансейф не обгоняет даже на ваших везучих данных.
Ну там он уже посередине — примерно 120% времени работы от бейзлайна плюсов, при этом тот же плюсовый код в зависимости от компилятора (типа смены на gcc) начинает работать за 160-320% времени.
А, ещё там разница в скорости от архитектуры зависла раза в полтора.
Если мы архитектуру начнём обсуждать, то можно вообще потонуть.
А про ансейф индексы уже и в контексте раста проговорено стопицот раз.
Было бы круто хотя бы подвижки иметь в сторону dependent rust :]
technic93
09.10.2021 15:26120% это хороший результат для кода без ансейфа
то можно вообще потонуть.
Зачем тонуть если ответ сводится к отличию в одной строчке спецификации cmov между Haswell и Skylake?
в зависимости от компилятора
Зачем вы так упорно это повторяете, когда там зависимость по данным+компилятор - вместо просто компилятор, плюс можно прогнать с pgo и тогда зависимость от компилятора уйдёт совсем.
ncwca
09.10.2021 02:01-1Однако, разные компиляторы оптимизируют
std::min({ delCost, insCost, substCost });по-разному, причём, в зависимости от порядка. Так что даже простейшая лапша требует заточки под компилятор, и от малейшего дуновения ломается.Полнейшая чушь и вообще не имеет отношения к теме. Есть факт. Код не заточенный под компилятор на C++ - быстрый. Код "не заточенный"(это враньё и я объяснил почему) на скриптухе - медленный.
А то, что там у дефолтного не заточенного кода разная производительность - это ничего не значит. И ничего не меняет. Вернее это даже не то что "не заточенный" - это мусорный код. А мусор и не должен нормально работать.
У производительности нет никакой заточки на компилятор. Заточка на компилятор есть у мусора, потому что нормальному коду компилятор не нужен.
Какие крестовые векторы? Где вы там кресты увидели?
Векторый, который данный адепт и его скриптуха перепастили из C++.
И что? Любой библиотеки, которой нет в примерах на главной странице, теперь не являются языком?
Нет, есть базовый подход и базовые сущности языка. Никакой библиотеки здесь нет. Есть базовые типы для C++ - они работают. Есть базовые типы для скриптухи - это бездарный мусор.
А то, что пропагандист взял либу в которую перепастили базовые типы из C++ - ничего не меняет.
Натягивание совы на глобус и подмена тезиса. Если мы будем брать только то, что пишут в туториалах, то ваш тезис о темплейтах рассыпется в труху.
Опять же, максимально позорная херня. вектор уже сам темплейтный. Это наследник stl, а t там не значит "тормозная скриптуха".
И да, ничего из этого не меняет базовые концепции языка. Даже в мусорной stdlib крестов практически нет си с классами. А те, что есть - это наследие 90 годов.
При этом вы приводите версию, которая обгоняет плюсы. Версия, где всё чисто и с нулевой мутабельностью — как раз посередине между плюсовым кодом, собранным gcc, и собранным clang'ом (причём clang быстрее).
Она ничего не обгоняет. Просто кто-то пропагадист, который ничего не понимает. Увидел какую-то херню и побежал делать далекоидущие выводы.
Пропагадист собирал свой скриптушный мусор llvm и почему-то сравнивает его не с llvm? С чего вдруг? Потому что пропагандист хочет вас обмануть.
Он увидел какое-то поведение где gcc использует другие дефолты. Дефолты для более современных процессоров. Дефолты которые дают возможность коду работать без оглядки на входящие данные.
Он взял старый процессор, взял подложны данные, взял эту разницу между компиляторами. Взял один из компиляторов, который прикрутили к его скриптухи, потому что свой компилятор скриптуха написать не в состоянии. Только какой-то примитивный мусор.
А после ещё учтите то, что несёт этот(и другие) пропагадисты относительно C++. Что на скриптухе есть гц, нет уб, хайлевел. Писать в 10 раз проще. Чинить багов нужно в 100 раз меньше.
При этом сливали и сливают llvm. Даже в том виде, в котором он был изначально. Ненужно слушать их пропагандисткую чушь про "ну в ллвм все вкладывают, а нам только дайте бабок" - это старая сказка для бедных.
Почему академическому проекту на C++ и для C++ дали зелёный свет, дали бабок и дали развиваться. Казалось бы - у тебя такая же производительность, кода писать лучше. Ты иллита, а не какой-то там крестовик. Ну дак напиши llvm, у тебя невероятно конкурентное преимущество. Но нет.
0xd34df00d
09.10.2021 02:11+2Векторый, который данный адепт и его скриптуха перепастили из C++.
Пруф на то, что это перепощено из C++.
antoshkka Автор
09.10.2021 10:09Однако, разные компиляторы оптимизируют
std::min({ delCost, insCost, substCost });по-разномуДва самых популярных компилятора генерируют практически одинаковый код https://godbolt.org/z/d3s1bnrje
Можете пожалуйста привести пример, где два разных компилятора какого-нибудь другого языка программирования, выдают схожий код?
0xd34df00d
09.10.2021 10:27+2Два самых популярных компилятора генерируют практически одинаковый код
Тогда дело было в этом — ЕМНИП в чуть более сложной функции, где кроме
std::minбыло что-то ещё, clang спиллил регистры на стек.Можете пожалуйста привести пример, где два разных компилятора какого-нибудь другого языка программирования, выдают схожий код?
Понимаю, к чему вы клоните. Цель «много эквивалентных компиляторов», конечно, хорошая (хотя неочевидно — зачем распылять усилия, в конце концов, если выхлоп компиляторов схожий?), но на практике от неё немало проблем.
ncwca
08.10.2021 11:56-1Ах да, отвечу на остальное.
Заметит как он съезжает с темы. Я привожу конкретные его факапы, конкретные тезисы, реальнные примеры, которые противоречат его лозунгам. Он же всё игнорирует. Отшутился про месяц. И да - это не шутка.
Довольно странно это слышать со стороны плюсов, где вообще всё — ансейф, где сейф-множества, проверяемого компилятором, просто нет как класса.
Просто посмотрите на это. Посмотрите на это непробиваемое упорство, как он отрицая реальность тулит свою методичку.
Первое - никакого сейф-множества нигде не существует. И никакой компилятор его не проверяет. Компилятор проверяет лишь то, чтобы ты не вышел за пределы этого множества.
Скриптуха слишком примитивна, чтобы что-то гарантировать. Само по себе сейф-множество безопасно не потому, что что-то там гарнатирует - это всё чушь пропагандистская. А потому что в этом множестве попросту нет опасных ситуаций.
Очевидно, что есть у тебя нет произвольного доступа к памяти, то у тебя и проблем нет с безопасностью. Но есть проблемы с возможностями и производтельностью.
Поэтому как только ему понадобилось посоревноваться с крестами даже в такой примитивной херне - он тут же побежал обмазываться ансейфов.
И ансейф там не весь код лишь потому, что он холодный. Если бы производительность напрямую зависела от каждого куска его лапши равномерно - унего бы в каждой строчке было бы по 10 ансейфов.
По поводу крестов. Заметим как он пытается на кресты натянуть свою методичку, но это так не работает. Кресты нигде не заявляли, что они сейф и прочая чушь. Поэтому они могут быть сайф, а могут быть ансейф - хоть чем угодно.
Ты же заявлял это, и ты должен этому соответствовать. А кресты нет. И то, что работает для тебя - не работает для крестов. Потому что вы в разных условиях.
Так же сообщу ещё об одной пропагандисткой методички - это "вообще всё — ансейф". Это полнейшая чушь. Объясняю фокус.
Есть безопасный код, есть опасный. В любом языке независимо от наличия там safe/unsafe - этот код есть.
Наличие safe/unsafe лишь позволяет ЯВНО разграничивать этот код, который обычно разграничен неявно.
Но что делает этот пропагандист? Он подменяет "всё неявно" на "всё не". Это полная чушь.
Так же, как и любой фанатик он подмену контекста и расширение области определения понятий. Что такое safe/unsafe и прочая чушь? Это локальная для данной группы классификация. Существует ли она за пределами мира их фантазий? Нет. И никогда не существовала.
Но что делает пропагандист? Он пытается требовать с других своих фантазий. Он требует с левых языков какой-то интеграции в его шизо-классификацию.
Очевидно, что в рамках этой шизо-классификации он может что угодно определять. Введи завтра в C++ safe/unsafe - они всё равно будут орать "там ничего нет", потому что определения разные.
Чем плохо? Разрушает ваши иллюзии, что код на хаскеле обязан быть только со списками? Я думал, мы избавились от них в прошлые разы.
Обязан. Никакой такой иллюзии нет. Здесь пропагандист сам придумал херню и сам её развеял.
Хаскель, как и любая другая фп-скриптуха никогда не предполагала и не предполагает наличие массивов.
Очевидно, что сектанты очень сильно позоряться, когда начинают использовать свои нативные структуры данных. Потому что они мусор.
И очевидно, что каждый пойдёт рассказывать, что он родился с массивов. И массив - это и есть фп.
Рандомных символов нет даже в перле, конечно. Не подменяйте тезис.
Были. Никакой тезис я подменять не могу - я его создал и он звучал так изначально.
Хаскель - это помойка из рандомных сиволов. Бессистемная херня.
То, что эти символы имеют какой-то там смысл - это ничего не значит. Очевидно, что смысл они иметь будут. Только смысл этот будет рандомный и существующие только в отдельно для донной группы одарённых.
Как дизайнился хаскель? Рандом сгенерировал наборы символов. Далее каждому этому рандому была назначена какая-то семантика. И в этом проблема.
Возьмите любой язык, и просто реплейсом замените одни символы на произвольные. Все символы остались. Но языка нет. Символы так же имеют смысл. Но току с этого?
Да, лучше написать лапшу из
std::optional, как в исходном постеКакой ещё, нахрен,
std::optional? Зачем мне этот мусор?и учить API каждого конкретного частного случая, чем единожды понять, что значат стандартные
<&>,<|>и>>=, применимые к любому функтору, alternative и монаде соответственно.Там нечего понимать. Заметим как пропагандист опять тулит нам свою методичку уровня "ты просто не понял".
Проблема в том, что не хочу жрать говно. Оно выглядит как говно. Она является говном. И уж читать <&>, а уж тем более писать этот мусор я не хочу.
0xd34df00d
08.10.2021 20:34+1> Первое — никакого сейф-множества нигде не существует.
> Компилятор проверяет лишь то, чтобы ты не вышел за пределы этого множества.
Так не существует или компилятор проверяет?
А вообще компилятор (вернее, его тайпчекерная часть) для этого и нужна — чтобы проверять.
> Очевидно, что есть у тебя нет произвольного доступа к памяти, то у тебя и проблем нет с безопасностью. Но есть проблемы с возможностями и производтельностью.
Ага, произвольный доступ к элементам массива есть, но произвольного доступа к памяти нет, ок.
Кстати, если вы такой пурист, его и в плюсах нет за счёт pointer provenance и прочих подобных вещей.
> Если бы производительность напрямую зависела от каждого куска его лапши равномерно — унего бы в каждой строчке было бы по 10 ансейфов.
Если бы у бабушки… Оказывается, что не нужно по 10 ансейфов.
> Хаскель, как и любая другая фп-скриптуха никогда не предполагала и не предполагает наличие массивов.
Враньё, массивы не имеют никакого отношения к не-ФПшности. ФП вполне может быть с массивами, с мутабельностью и так далее. ФП — это про типы, и всё.
> Как дизайнился хаскель? Рандом сгенерировал наборы символов.
Серьёзно?
> Какой ещё, нахрен, std::optional? Зачем мне этот мусор?
Не знаю, вы же на плюсах зачем-то пишете.
> Заметим как пропагандист опять тулит нам свою методичку уровня «ты просто не понял».
Так я у вас учусь. У вас же все вокруг плюсы не поняли, и только вы понимаете, как на плюсах надо писать, и что исключения — это не плюсы, и `std::transform` — не плюсы, и `std::optional` — это не плюсы, а плюсы — это только то, что вам удобно в данный момент.
> Проблема в том, что не хочу жрать говно. Оно выглядит как говно. Она является говном.
Ты ж на плюсах пишешь, куда уж дальше?
MooNDeaR
09.10.2021 16:58+2Всё-таки завидую твоему терпению :) Я сдался на втором комментарии.
Удивительно то, что у человека его собственные слова перед глаазми, но он не находит в них ничего фанатичного. Зато назвать других фанатиками - это всегда можно.
PavelZhigulin
07.10.2021 21:05+1Зерокост плюсов нефига не зерокост, как тут уже заметили. К тому же за него приходится платить временем разработки и когнитивной сложностью.
На счёт рандомных символов - в хаскелле как раз-таки почти ни одного рандомного символа :D Потому что язык конструкциями оч похож на язык математики. Я вообще не математик, вообще признаюсь честно хаскелль так и не осилил по-настоящему, но влюбился в него как в несбыточную мечту :)
ncwca
08.10.2021 00:18-2Зерокост плюсов нефига не зерокост, как тут уже заметили.
Где заметили, кто заметил?
К тому же за него приходится платить временем разработки и когнитивной сложностью.
Максимально нелепые заходы. Очевидно, что что-то более сложное требует больше усилий. Вам срочно нужно вернуться в пещеры, зачем вам жизнь с когнитивной сложность? Зачем тратить на приготовлений той же еды столько времени. Месяца, года, если можно жрать корешки?
И да, плата так не работает. Просто на разных уровнях разные люди. Для одних что-то сложно, а для других нормально. Зачем грести всех под одну гребёнку?
На счёт рандомных символов - в хаскелле как раз-таки почти ни одного рандомного символа :D
Да, это сразу видно. Символы выбирались осмысленно.
Потому что язык конструкциями оч похож на язык математики.
А математика это не набор рандомных символов под чистую слившая программированию. Это прям образец дизайна нужно срочно на ней писать код. Только почему-то не пишут, почему же? Да и никаким образом оно не похоже.
PavelZhigulin
09.10.2021 05:01+1Только почему-то не пишут, почему же?
Потому что Haskell - чисто академический язык. Как и все языки, что возвели какую-то идею в абсолют. И всё же он значительно повлиял на множество языков, которые стащили из него идеи/конструкции. На идеях из этого языка держится Scala, на которой-таки пишут. Много вещей в Rust - берут начало из Haskell. Да те же концепты из С++20 - это суть тайпклассы из Haskell.
А математика это не набор рандомных символов под чистую слившая программированию
Даже не знаю как с этим спорить) Ответ ведь зависит что мы пытаемся сделать. Выразительность языка математики сложно переоценить - это оч мощный и универсальный инструмент, рекомендую освоить. Но да, формочку на нём не напишешь. И все же, это не делает замечание о том, что Haskell - это набор случайных символов верным. На фоне синтаксических конструкций С++ (особенно раннего С++, до С++17) - Haskell образец логичности :)
Для одних что-то сложно, а для других нормально
С++ мой основной язык программирования уже 8 лет. Я могу сказать, что я знаю С++. Но даже мне сложно, когда речь заходит за шаблонный код. Скажем концепция тех же ниблоидов требует не так много кода, но чтобы объяснить новичку логику работы ниблоидов, нужно поям реально лекцию на полтора часа устраивать) Получается когнитивная нагрузка на одну строчку кода - колоссальная.
Очевидно, что что-то более сложное требует больше усилий
Проблема С++ в том, что на нём даже что-то простое требует очень много усилий) Особенно если брать плюсы до С++17.
ncwca
09.10.2021 05:51-3Я там написал жести, но судя вашим дальнейшим тезисам -в вас есть адекватность. Да, вы не можете признаться, что вы пишите на си с классами, мало что знаете о С++ и об используемых в них концепция. В том числе и концептам. Но вы хоть признаётесь, что сложно шаблонами. В отличии от всяких 0x-болтунов.
По поводу шаблонов. Вам сложны не шаблоны. Вам сложен полиморфизм. Полиморфизм как концепция не влезает в голу практически никому. Особенно есть он знаком со всякими хаскелями и прочими бездарными огрызками.
Точно так же как людям не влезает в голову концепция параллелизма. Что в первом случае они могут лить мыслить мономорфно, что во втором они могут мылсить лишь скалярно и последовательно. И полиморфизм из скриптухи - это мономорфная херня, хоть и пропаганда выдаёт её за полиморфизм.
Поэтому никаким образом концепты в C++ не могут являться каким-то порождением хаскеля просто в силу своей природы. Ладно технически и реально они никак с этим мусором не соотносятся, поэтому как максимум вы можете говорить об идеях, но нет - вас обманули.
Вы можете попытаться рассказать мне о своих представлениях о концептах и том, каким образом они, по вашему мнения, связаны с хаскелем.
В любом случае это будет наивной ретрансляцией пропаганды уже в силу того, что никаких концептов не существует. Концепты - это базовое свойство C++-модели, которые там были всегда.
Концепты, о которых выслышали имеют две основные фичи. Первая - это сериализация sfinae. Т.е. C++ dy-deisgn может интроспектить код и сериализовывать факт его успешного формироания, допустим, в true/false.
Это не что-то новое. Это то, что всегда было и есть. Просто оно стало явным.
Далее, это предикаты существования полиморфных сущностей, либо ограничения области определения этих сущностей.
Всё это всегда было в C++. C++ определяет автоматически факт существования сущесности попыткой её применения. С древних времён возможности C++ здесь зарезаны.
С++ может оценивать, если мы говорим о тех же функциях, функцию в целом, либо её сигнатуру. Разделение функции/сигнатуры - это бездарный мусор, но он работал когда-то когда создавался С++ и его модель не была полностью сформировано. Поэтому мы живём с этим легаси.
Поэтому для нас существует необходимость выноса инвариантов на уровень сигнатуры. Эти инварианты - это предикаты её существования. У наб есть "сформировано - да/нет" => сущность существует? да/нет.
Использование предполагает варианты. Допустим нам, обычно, удобнее инварианты описать во вне. А далее этот инвариант задать как предикат.
Ведь язык всё равно работает именно с предикатами. С логикой есть/нет, булевой. Вот концепты просто обобщают это - вводя в язык отдельную сущность - предикат. Она существовала всегда. Но не была специфицирована, была как бы неявной.
Всё, ничего этого в хаскеле нет. Там совершенно другая, мусорая примитивная система типов и пародия на полиморфизм.
Концепты - это механизмы ограничения полиморфизма. Этого полиморфизма в этой скриптухи в принципе нет.
То, что вам пропаганда выдаёт как какие-то тайп-классы и прочий мусор - не имеет никакого отношения к полиморфизму. Работает иначе и совершенно другая концепция.
0xd34df00d
09.10.2021 08:02+3Вот бы в 2021-м считать нормальный параметрический полиморфизм пародией на полиморфизм, а придуманный в плюсах набор костылей, чтобы можно было написать
vector<T>и при этом не сломать механизм выбора перегрузок — настоящим полиморфизмом.
MooNDeaR
09.10.2021 23:05Мужик, да ты безумен :) Пожалуй, оставлю тебя вариться в собственном безумии одного.
0xd34df00d
09.10.2021 07:59+2Потому что Haskell — чисто академический язык.
Да нифига он уже не чисто академический, увы. В 2005-м он был таким, да, в 2010-м — возможно, но сейчас там уже сильно неакадемическая функция полезности при принятии решений о дальнейшем развитии языка.
MooNDeaR
09.10.2021 17:08Мне сложно прокоментировать готовность языка к продакшену, не слежу особо за развитием языка последние годы и можно сказать даже не использовал его толком никогда для настоящих дел. Последний раз я что-то осмысленное пытался на Haskell написать в 2016-м, но в итоге это кончилось тем, что я начал читать статьи по теории множеств, а затем были попытки даже осилить учебник :) Программу так и не написал)
Мои слова об "академичности" основаны на том, что в Москве по запросу Haskell Developer на HH только 23 вакансии выдаёт (против 2103 для С++ Developer). Причем я даже не читал их, возможно в некоторых его просто желательно знать, не более. Насколько я помню, ты проживаешь в США, там ситуация может быть другой. Тем не менее мне картина видится такой, что почти никто не использует Haskell в качестве языка для бизнеса.
technic93
09.10.2021 17:57Но ведь аксиоматическая теория множеств из классической математики, это (афаик) не то что применяется в теории типов. И знать ни одну из этих теорий для программирования необязательно.
0xd34df00d
09.10.2021 18:33+1Тащем, да, «перед написанием хелловорлдов на хаскеле надо зашарить теорию типов и теоркат» — стандартное заблуждение.
MooNDeaR
09.10.2021 23:12Классно когда ты это заранее знаешь)) А если математического образования нет, то видишь ты что функция принимает Monoid и сразу вопрос в голове: "что ты такое вообще?". А в чём разница между Group и Semigroup? Приятно, наверное, когда все эти знания тебе в универе вбили)) А когда нет, приходится сидеть и читать.
0xd34df00d
09.10.2021 23:52+1А если математического образования нет, то видишь ты что функция принимает Monoid и сразу вопрос в голове: "что ты такое вообще?"
Это — такой интерфейс, который имеет такие-то правила.
Ну, точно так же, как не нужно никакого формального описания ООП, чтобы научиться понимать «это — синглтон», «напиши фабрику» или «тут надо декоратор присобачить». Некая концепция, работающая по некоторым правилам (куда более чётким, чем ООПшные, кстати), только и всего.
А в чём разница между Group и Semigroup?
Куда более очевидная, чем между декоратором и фасадом :]
MooNDeaR
10.10.2021 07:34Это — такой интерфейс, который имеет такие-то правила.
Может быть я сам себя утешаю, но боюсь я бы никогда не стал тем, кем стал, если бы меня удовлетворяли поверхностные ответы на вопросы. Мой мозг не даёт мне остановиться, пока я не раскорываю ответы на вопросы "откуда это взялось?" и "какими свойствами оно обладает?" :)
technic93
10.10.2021 14:45Это нужно чтобы знать как cделать ту же свёртку. Коммутирует операция сложения или нет, есть ли нейтральный элемент?Просто в хаскель используют математическую терминологию в названиях тайпклассов, но это общее свойство алгоритмов. Например про такую классическую структуру как дерево отрезков можно говорить используя термин моноида - тот который из алгебры а не (помилуйте) теорката.
В группе же есть ещё дополнительное требование обратного елемента, но где это нужно сейчас не придумаю.
0xd34df00d
10.10.2021 19:53+2откуда это взялось?
Оказалось, что это достаточно мощная абстракция, чтобы она была полезной, и достаточно слабая, чтобы её можно было обобщить на кучу разных конкретных случаев. Как и всё в математике, тащем.
какими свойствами оно обладает?
А это прям в описании написано:
A type a is a
Monoidif it provides an associative function (<>) that lets you combine any two values of type a into one, and a neutral element (mempty) such thata <> mempty == mempty <> a == aПро свёртку рядом хорошо вспомнили — например, в описании
std::reduceестьThe behavior is non-deterministic if binary_op is not associative or not commutative.
просто это не называют «коммутативной полугруппой», а требования все те же.
MooNDeaR
09.10.2021 17:09Прошу пояснить, в чём разница. Я искренне не понимаю. Они выполняют одну и ту же функцию.
ncwca
09.10.2021 17:14-1Нет, очевидно. Никакую одну функцию они не выполняют. И уж тем более из одной функции никак не следует это.
Выполняет ли конь и трамвай одну функцию? Является ли трамвай конём? Здесь срочно нужно чинить методичку.
Самое удивительное здесь то, что пациент ничего не зная утверждает(а он именно утверждает - это не вопрос, хоть он и пытается выдать его за него).
technic93
09.10.2021 17:53Для начала надо понять что темплейты плюсов отличаются от типов хаскеля, соответственно дальше всё работает тоже по-разному.
Тайпкласы в самом простом случае это скорее интерфейсы из джавы, но с возможностью разделить реализации интерфейсов и объявления класса. А в сложном случае всё отличается.
0xd34df00d
09.10.2021 18:33+2Если упрощать, то разница вот в чём.
Основная функция концептов — синтаксический сахар для отбрасывания неподходящих перегрузок функций.
Основная функция тайпклассов — формализация API типов (или комбинаций типов для мультипараметрических тайпклассов), чтобы можно было писать полиморфные по этим типам функции.Разница в том, что компилятор плюсов не проверяет, что вы пользуетесь в теле функции только тем, что следует из её констрейнтов, а компилятор хаскеля (раста, идриса…) — проверяет. Плюс, принадлежность типа тайпклассу нужно указывать явно, а концепту — нет.
Изначальные концепты из середины нулевых были куда ближе к тайпклассам, чем concepts lite, но в комитете решили, что концепты — слооожна, и решили ограничиться lite.
PavelZhigulin
10.10.2021 11:32+1Разница в том, что компилятор плюсов не проверяет, что вы пользуетесь в теле функции только тем, что следует из её констрейнтов,
Какое-то безумие, зачем они тогда нужны? Я полагал, что это был основной смысл ради чего их ввели - чтобы шаблонный код было понятным, чтобы автодополнение там можно было прикрутить. Что именно мешало так сделать, это же логично?
ncwca
10.10.2021 12:00-3Без относительно той чуши, что он написал. У шаблонов нет никаких проблем с "понятным". Никогда никакого подобного запроса нет, а те, кто об об этом вопрошают - не понимают не шаблоны, а полиморфизм.
чтобы автодополнение там можно было прикрутить
Они итак прикручивается, для этого никакие концепты не нужны. Это ведь не скриптуха.
Что именно мешало так сделать, это же логично?
То, что это полиморфный язык. Если попроще, то никакие тайпклассы и прочий мусор ненужны для той чуши, которую вам несёт пропаганда.
Генерики работают через стирание типов. Чтобы использовать свойства стёртого типа - их нужно аннотировать типом. Для этого и служат всякие тайпклассы/трейты/интерфейсы и прочие подобные сущности.
Каждая из этих херней мономорфна, когда в том же расте пишется
T: A; x: T- то любой доступ к x производится через интерфейс A. Этот А мономорфен, т.е. на все типы там один интерфейс.Подобная модель максимально примитивна и не требует тайпчекинга. Так же она максимально просто ложится на вывод типов из фп и прочей скриптухи, потому как этот вывод типов не может в полиморфизм by-design.
Т.е. если C++ нужно протайпчекать всё, проверить действительно ли что-то соответствует чему-то. А так же типы не ограничены одним интерфейсом.
То вот в скриптухи ничего этого делать ненужно. Вы сами аннотируете любой тип интерфейсом. И только тогда нужно проверить, что он соответствует. Проверка там максимально тупая - достаточно просто сравнения сигнатур+имени. Сигнатуры там максимально примитивны.
Внутри самих генериков так же ничего тайпчекать ненужно. Просто проверяется есть ли нужное свойство у интерфейса.
Когда вы передаёте что-либо в генерик-функцию проверка ещё более тривиальна - просто посмотреть список того, что имплементировано для типа. Есть ли там такой же интерфейс.
В С++ есть подобная модель - это виртуальные методы + базовые классы в качестве интерфейсов.
Подобная модель ваяется любым студентов на коленке. Крестовая же модель настолько сложна, что её реализовать для него уже в принципе невозможно. А именно подобные и пишут всякие хаскели/расты.
Аналогичная ситуация с тем же синтаксисом в C/C++. Распарсить синтаксис хаскеля, раста и прочей скриптухи - с этой задачей справивиться любой студент. Там грамматика максимально примитивная, нет какой-либо контексто-зависимости, либо сложной контексто-зависимости.
Распарсить же даже сишный синтаксис достаточно нетривиально. Не говоря уже о крестовом. Именно поэтому вы не увидите ничего, кроме паскалятины, в любых академических поделках. Да и 99% языков.
Именно потому, что это проще. Именно потому, что это доступно. Это единственная и основная причина. Всё остальное - оправдания.
0xd34df00d
10.10.2021 20:03+3Полная чушь и хватание по верхам.
Генерики работают через стирание типов.
Причём тут генерики, если мы обсуждаем хаскелевский полиморфизм? Полиморфизм не работает через стирание типа, компилятор вполне счастливо мономорфизирует полиморфные функции в точке подстановки конкретного типа, точно так же, как и в плюсах — просто тайпчекинг функции происходит до такой подстановки, а не после.
Чтобы использовать свойства стёртого типа — их нужно аннотировать типом.
Нет, аннотировать нужно для того, чтобы компилятор мог отдельно протайпчекать функцию до подстановки конкретного типа. Это же не плюсовые макросы на стероидах aka темплейты :]
Этот А мономорфен, т.е. на все типы там один интерфейс.
И что? В плюсах на все типы, которые подставляются в функцию, тоже одна функция (синтаксически, в коде).
Так же она максимально просто ложится на вывод типов из фп и прочей скриптухи, потому как этот вывод типов не может в полиморфизм by-design.
ML'исты и rank-2 polymorphism смотрят на вас с некоторым удивлением.
Сигнатуры там максимально примитивны.
В плюсы уже завезли хотя бы инъективные семейства типов? Плюсы уже научились хотя бы не обделываться от вывода типов в
template<typename T> struct Identity { typename type = T; }; template<typename T> void foo(Identity<T>)?
Крестовая же модель настолько сложна, что её реализовать для него уже в принципе невозможно.
Сложна и не нужна. Не нужна такая сложность, эти темплейты не имеют смысла, в адекватно (а не случайно) придуманном языке они не решают ничего, что решается обычным, нормальным параметрическим полиморфизмом.
Там грамматика максимально примитивная, нет какой-либо контексто-зависимости, либо сложной контексто-зависимости.
Ужс, компилятор сможет прожевать код быстрее и выдать адекватное сообщение об ошибке. Недопустимо!
Распарсить же даже сишный синтаксис достаточно нетривиально. Не говоря уже о крестовом. Именно поэтому вы не увидите ничего, кроме паскалятины, в любых академических поделках. Да и 99% языков.
Настолько мастурбировать на сложность саму по себе, даже если она приводит к тому, что до адекватных сообщений об ошибках понадобилось пердеть 20 лет — это просто край.
Я не понимаю, для вас лучше тот язык, который сам по себе сложнее, и на котором сложнее писать? Да пишите тогда на malbolge, зачем останавливаться на плюсах?
0xd34df00d
10.10.2021 19:54+1Мешало, что это слишком сложно. Можно повспоминать обсуждения оригинальных концептов этак 15-летней давности, там будет конкретика.
ncwca
10.10.2021 20:29-3Концепты времён 0x были максимально примитивным мусором. Сложно там было то, что они были убожество + вводили всякую рантайм-херню.
Про то, что там были какие-то проверки до - это полнейшая чушь. Там был специальный костыль, который позволял из концепта получить базовый класс, которым уже после наследовать.
Но даже тогда это понималась за полнейший треш и предлагалось ввести всё это автоматически во время инстанцирования.
Так же, тогда ещё не был сформирован С++. Была предпринята попытка описывать интерфейсы как в бездарной скриптухи - т.е. через сигнатуры.
Как только появилось auto/decltype и сформировался язык в современном виде. Сразу стало понятно, что сигнатуры мусорные работают только в помойной скриптухи.
Какая-нибудь универсальный сигнатура с деклтайпами и прочим - создаёт невозможную для описания сигнатуру. Попробуйте написать сигнатуру для какой-то сложной функции - это невозможно.
Поэтому описание интерфейсов декларативны. Мы не описываем сигнатуры как в бездарной скриптухе, а просто использует что-то так, как оно должно использоваться.
Кстати, этот пример максимально показателен. Генерики/интерфейсы в скриптухе обусловлены только одним - её бездарностью и примитивностью. И когда С++ был таким же оно пыталось использовать те же подходы.
И не потому, что скриптуха. А потому что оно примитивное и вариант там один.
0xd34df00d
10.10.2021 20:36+3Концепты времён 0x были максимально примитивным мусором.
Это даже несерьёзно.
Царская логика: взяли примитивный мусор, выкинули из него 90% фич и возможностей и получили мощнейший инструмент.
ncwca
10.10.2021 21:05-3Это даже несерьёзно.
Типичный слив.
Царская логика: взяли примитивный мусор, выкинули из него 90% фич и возможностей и получили мощнейший инструмент.
Какие фичи? Рассуждения уровня слышал звон? Перечисляй 90%.

crackedmind
05.10.2021 14:58+4Ну split есть в ranges, плюс его пофиксили https://github.com/cplusplus/papers/issues/912
antoshkka Автор
05.10.2021 16:00Он уже тюринг полный, и рекурсия есть (например, через рекурсивное подключение одного и того же хедера). Полностью тема раскрывается здесь

sergegers
05.10.2021 17:18Я бы выбросил с удовольствием boost.preprocessor, если бы была интроспекция типов. Как там с ней дела?

gridem
07.10.2021 08:48+2Пока на препроцессоре приходится делать то, что нельзя никакими другими вещами, его нужно развивать и дополнять. Говорить про то, что препроцессор лучше оставить таким, какой есть - очень странное утверждение. Хочется тогда узнать, а что взамен? Если взамен - ничего, то это самый плохой ответ, который может быть. Лучше пойти навстречу пожеланиям и добавить улучшений в него.
То, что есть в boost PP - это такие костыли и грабли, про которые лучше не вспоминать.
crackedmind
05.10.2021 12:22+4А так же:
добавили поддержку препроцессорных директив elifdef elifndef из С23
раздепрекейтили сишные хедеры
использование алиасов в init-statementfor (using T = int; T e : v)
и еще всякоеantoshkka Автор
05.10.2021 12:29+2Фича elifdef elifndef из С23 - ужасна:
не надо развивать препроцессор
читаемость - так себе
нет возможности/смысла использовать их при написании переносимого кода
они крайне редко нужны
Протащили только ради совместимости с C.
PavelZhigulin
07.10.2021 21:11+1Препроцессор стоило бы развивать в сторону макросов Rust, потому что иметь средство кодогенерации интегрированное в язык и совместимое с отладчиком и IDE - это очень удобно.
Другое дело, что это отдельная фича вообще параллельная текущей макросне.
ncwca
08.10.2021 00:22-2Да, макросы раста максимально совместимы с ide.
По поводу кодогенерации - это работает не так. Раст это максимально примитивный язык, который ничего без кодогенерации не может. Где-то в районе го. Сишка туда же, но сишка совершенно другой язык. Да, в какой-то степени это можно сказать и го, но лишь в какой-то.
C++ нет. Раст не способен даже принтф и вектор выразить.
AnthonyMikh
08.10.2021 13:15+1Раст это максимально примитивный язык, который ничего без кодогенерации не может.
Но тем не менее в C++ потребовалось новый spaceship operator ввести, чтобы не писать по шесть примитивных функций, а в Rust просто используют дерайвы.
ncwca
08.10.2021 14:15-1Но тем не менее в C++ потребовалось новый spaceship operator ввести
И?
а в Rust просто используют дерайвы.
Просто используют мусор. Очевидно, что там будут дерайвы и прочие костыли вместо языка, потому что языка нет. Это не является преимуществом.
К тому же, даже если мы примем за эту хероню за что-то равное =default - да, здесь нужно починить методичку. spaceship operator это совершенно новая операция по аналогии с memcmp из сишки.
То даже с учётом этого - это ничего не значит. Постоянно в расте появляются новые дерайвы. И когда-то и этих не существовало. Следует ли этого что-то? Нет.
AnthonyMikh
08.10.2021 15:52То даже с учётом этого — это ничего не значит. Постоянно в расте появляются новые дерайвы. И когда-то и этих не существовало. Следует ли этого что-то? Нет.
Таки следует. Если бы derive-макроса для PartialOrd не было бы, мне было бы достаточно один раз написать библиотеку для того, чтобы выводить реализацию, а не ждать, пока аналогичный функционал внесут в язык.
ncwca
08.10.2021 16:18-1Таки следует.
Нет.
Если бы derive-макроса для PartialOrd не было бы, мне было бы достаточно один раз написать библиотеку для того
Вы даже не представляете насколько ваши представления ограничены. В C++ Эта макросня мусорная в принципе ненужна. Я подробнее разберу это в следующем посте.
К тому же, это уже максимальный слив. Произошёл факап с <=> - куда всё потерялось. Продолжилась нестись херня.
Ещё раз повторяю. PartialOrd и прочий примитивный убогий мусор к теме отношения не имеет. <=> существует не потому, что никто не мог его реализовать в либе. Я даже не знаю как комментировать эту нелепую чушь.
<=> - это оператор. В скриптухе либой никаким образом новый оператор в язык не добавить. Это первое.
<=> - это контракт между всему пользователями. Если каждый будет валять своё бездарное PartialOrd дерьмо, то она нахрен ненужно, потому что будет у каждого своё и несовместимо.
Почему что не адепт раста, то какой-то бот, который несёт херню? Какой-то бот, который неспособен воспринимать элементарные вещи. Который рпосто спамит тебе херню, которая опровергает на раз.

ElleSolomina
08.10.2021 03:40не надо развивать препроцессор
Статическая рефлексия — нету. А мне часто приходится имена сущностей в шаблоне из кусочков собирать на этапе компиляции, без препроцессора никак ;)

cdriper
05.10.2021 13:05+12Это история о том, что можно пачками добавлять мелкие, ничего не меняющие фичи, вместо того, чтобы наконец-то сделать reflection.
antoshkka Автор
05.10.2021 13:32+4Скорее история про то, что всем не угодишь. Только-только добавили Modules, Ranges, Coroutines, Concepts... но кто-то ждал совсем других новинок.
Я вот например flat_set и stacktrace жду сильно больше чем operator[] (int.int). А вот математикам и физикам второе зачастую сильно важнее чем, например, flat_set
ncwca
05.10.2021 22:17+5Скорее даже про то, что сидеть в core сложно и заниматься его развитием тоже. Зачем, допустим, тащить те же ренжи в стандарт? Как результат мы имеем огрызок применимость которого крайне сомнительно. И ещё 10 лет его будут реализовывать. Единственное здесь преимущество - то, что мы получим новую реализацию от той же stdc++ в отличии от того ужаса, что есть сейчас. Текущую реализацию оправдать можно - она всё же PoC пытающийся работать на старых версиях языка.
Аналогично с flat_set - это элементарный адептор поверх вектора. Зачем он в стандарте? Чтобы что?
stacktrace уже более адекватно. Это всё же рантайм языка.
operator[] (int.int)- это именно кор и этим и нужно заниматься. Уж тем более не в пользу элементарных обёрток, который уже давно есть.Решение, как мне кажется, здесь макисмально простое. Отделить язык от stdlib, в качестве stdlib оставить только то, что напрямую взаимодействует с языком. Какое-нибудь coro/initializer_list и прочее. Развивать эту stdlib вне языка. Как результат ненужно будет ждать пару 10 лет для очередной обёртки в пару строк. Привет contains.
Её же можно использовтаь в качестве референсной реализации, если кто-то заходит сделать свою. Её же можно использовать и для протипирования, чтобы эти прототипы не валялись где попало.
antoshkka Автор
05.10.2021 22:48+6Кажется что вы только что изобрели Boost. Только он тоже не всем нравится :)

allcreater
05.10.2021 13:34+3Прошу прощения, что-то взгрустнулось:
При всём уважении к Комитету, корутины(ну хотя бы awaitable future и generator!) в стандартной библиотеке всё ещё не завезли, контракты пока тоже идут лесом, до reflexpr тем более дело не дошло…
Безусловно, все свежие фичи вполне себе полезные, но почему-то пока совсем не вызывают былого ощущения «наконец-то добавили то, чего больше всего не хватало».
В любом случае, огромное спасибо за статью, и особенно — за нелегкое и местами неблагодарное(при появлении комментаторов вроде меня :) ) дело работы над стандартом!
PS: за паттерн матчинг всё прощу, и другие фичи вызывают надежду — дождаться бы.antoshkka Автор
05.10.2021 13:49А какие именно вещи вызывали у вас ощущение «наконец-то добавили то, чего больше всего не хватало» ?
allcreater
05.10.2021 14:01+7* в 11ом — лямбды, move-семантика, масштабное расширение стандартной библиотеки
* в 14ом — допиленные лямбды, гетерогенный поиск в упорядоченных map и set
* в 17ом — filesystem, структурированные байндинги, string_view, variant, optional, параллельные алгоритмы
* в 20ом — корутины, концепты, трёхстороннее сравнение, span, диапазоны
Комитет сделал за последние десять лет столько классных штук, что хочется больше и больше.
Впрочем, всё действительно сильно зависит от использования, и все действительно ждут разного. У меня ожидания и реальность разошлись впервые, и это всё равно очень здорово.
AndDav
05.10.2021 13:51+3А еще непосредственно в язык были добавлены auto(x) и "Deducing this". 2 фичи, нужные 0.1% пользователей, но усложняющие (добавляющие избыточность) в язык для всех. "Deducing this" в этом смысле, полный караул,
auto(x)чуть менее страшно, простоautoтеперь может встречаться еще в одном контексте.
Lazerate
05.10.2021 14:27+1Разве их кто-то добавил?
AndDav
05.10.2021 14:34https://github.com/cplusplus/papers/issues/293#issuecomment-922673270 (plenary-approved)
https://github.com/cplusplus/papers/issues/115#issuecomment-890138335 (plenary-approved)
antoshkka Автор
05.10.2021 14:47+3Да, как раз на этой встрече добавили. В посте не освещал, так что хоть тут немного расскажу:
auto(x) - встроенный в язык способ сделать decay + copy значения, другими словами что-то наподобие
decay_t<decltype(x)>{x};. Как верно заметили, не самая востребованная вещь"Deducing this" - позволяет писать функции с шаблонным this. Теперь можно написать
template <class Self> decltype(auto) value(this Self&&) { return std::forward<Self>(*this).value_; }и получать const& , & и && ссылки на value_ в зависимости от константности this. Так же получили возможность делать рекурсивные лямбды[](this auto self, int n) -> int { return (n <= 1) ? 1 : n * self(n-1); + };
Lazerate
05.10.2021 15:31+2За вторым наблюдал, классно, что приняли. Я думал языковые фичи уже не принимают. Но если всё же принимают, возможно, есть шанс, что ещё войдёт это: https://wg21.link/p1061r1?
Мне кажется, очень полезная возможность, в свете отсутствия особых подвижек в сторону статической рефлексии.
А что насчёт судьбы нетворкинга? Если я не ошибаюсь, плановая встреча с его обсуждением была как раз в этот понедельник.
antoshkka Автор
05.10.2021 16:02+1p1061r1 недавно обсуждали, если небольшие шансы увидеть в C++23
Networking активно обсуждается, что будет - непонятно. Комитет всё ещё хочет универсальные executors, с которыми должен будет работать Networking... но пока не выходит
Gordon01
05.10.2021 16:37+6Всегда было интересно, неужели некоторые люди и правда считают вот это
template <class Self> decltype(auto) value(this Self&&) { return std::forward<Self>(*this).value_; } [](this auto self, int n) -> int { return (n <= 1) ? 1 : n * self(n-1); + };читаемым?
Я дико извиняюсь, но кажется, что perl с обильным использованием регулярок был прекрасным и читаемым по сравнению с современным c++sergegers
05.10.2021 17:24+1Ну это же для обощённого кода. У меня полно таких мест, где первая строчка бы пригодилась.
AndDav
05.10.2021 19:32+1В первом примере ошибка, такой код не скомпилируется. Должно быть
template<class Self> decltype(auto) value(this Self&& self) { return forward<Self>(self).value_; }Или, на мой вкус чуть читаемей, так:
template<class Self> decltype(auto) value(this Self&& self) { return forward_like<Self>(self.value_); }Вместо
decltype(auto)тоже скорее всего можно написать явный тип, просто не зная что-такоеvalue_сложно сказать какой. Так что, если не записывать в одну строку, то все не так страшно.
ncwca
05.10.2021 22:52template <class Self> decltype(auto) value(this Self&&) { return std::forward<Self>(*this).value_; }Темплейт здесь ненужен - уже давно есть неявные темплейты с auto, *this - так же. Указателей здесь никаких нет.
Наличие
std::forward<Self> - это последствия сишной базы. С этим ничего не поделать пока C++ не перестанет быть для большинства тем на чём пишутся либы, код которых никто никогда не видет, но использует в си с классами.http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1221r0.html - это и подобны начинания зарубают.decltype(auto) value(this auto &&) { return ((decltype(this))this).value_; }[](this auto self, int n) -> int { return (n <= 1) ? 1 : n * self(n-1); + }; - self это базовый паттерн для рекурсивных лямбд. -> int - это бесполезная мода. Множество языков и их последователей для которых не реаизован, либо не реализован вывод типа возврата, создают среду хейта вывода типов.Так же - этот пример максимально не показательный. Это можно похакать через
std::function<int(int)> self = [](int n) -> int { return (n <= 1) ? 1 : n * self(n-1); + };Но, если мы начнём писать настоящий С++-код, т.е. полиморфный код. Сигнатура будет всегда сводится к
auto(auto ...)и никая std::function не может. Именно здесь и возникает проблемы - мы никак не можем написать это иначе. И нам нужно будет сделать обёртку и заслать туда руками этот self.И не следует забывать, что сложность данного кода обусловлена не C++, а его семантикой. Вы не сможете показать подобный код на другом языке. Если он и будет проще, то в ущерб смыслу. А выразительность это и есть количество смысла(желательного воспринимаемого) на единицу визуального/мысленного объёма.
Допустим, практически нигде нет полиморфизма, не вдаваясь в подробности, по ссылкам/значениями. Мы можете написать либо f(int x), либо f(int & x). Когда как в C++ - это десятки разных функций, которые описаны одной. Очевидно, что всё это ненужно в случае, когда этого нет. Но когда этого нет нет и тех свойств, которым обладает код на C++. И издесь либо/либо.

Ritan
05.10.2021 18:12+1По поводу #2. Какая жесть. По сути внутри таких функций мы получаем новый диалект c++ в котором больше нет this, так ещё и текущий объект больше не является указателем.
Туда же добавляются вопросы по поводу вариантов вида
virtual void foo(this Base self);
Т.е. такая функция, будучи вызванной на наследнике будет делать неявный slicing.
А сколько лучей радости будет от разработчиков библиотек, где теперь нужно будет отличать указатели на функции от указателей на методы и от не-совсем-но-почти-указателей-на-функции, которые нельзя вызывать как функции
AndDav
05.10.2021 19:37Я, как ясно из корневого комментария тоже отрицательно отношусь к этому proposal-у, но все-таки, давайте критиковать обоснованно.
virtual functions с explicit this запрещены, так что неявный slicing нам не грозит.
С указателями на функции вроде бы тоже никакой путаницы нет, в этом смысле функции с explicit this ведут себя как статические, для них же никого не напрягает, что указатели это не member-pointers.
ncwca
05.10.2021 23:04-2Мы уже имеем новый диалект, который называется C++ и то, как пишут на нём(дилекте) код. А есть другой диалект C++, который наследник си с классами. Со всеми этими virtual/this и прочим.
Поэтому те люди, которые пишут на новом диалекте абсолютно без разницы на то что там будет для тех, кто пишет на старом. И им, в с свою очередь, на тех, кто пишет на новом.
При этом. Последователи нового диалекта не мешают никак последователям старого, но последователи старого всегда мешают новым. У вас никто не забирает ваш this и никто не заставляет пользоваться новым. Почему у вас всегда своё сводится к "запрещать" и "не давать"?
А сколько лучей радости будет от разработчиков библиотек
Для тех, кому это ненужно - пусть не поддерживают. Никаких же проблем нет с теми же корутинами. Что там функция не совсем функция и return из неё не совсем reutrn.
Просто нужно пойти дальше и форкнуть функции. Если так хочется, чтобы новое не попало в старый код. Это решит множество проблем.
Но здесь есть фундаментальная проблема. Та, по которой последователи старого ведут себя подобным образом. Он хотят использовать библитеки и фишки, которые реализованы новом кодом и подходами, которым они хотят запрещать. Они очень яро блюдут совместимость, чтобы не остаться 1на1 со своим virtual. Это максимально порочная практика и рано или подхно груз легаси что-то сломает в умах последователей нового.
Ritan
05.10.2021 23:37+2Вы видимо никогда не писали глубоко шаблонный код, когда хочешь-не-хочешь, а поддерживать очередной новый вид функции всё равно придётся.
Если вам так хочется всё взять сломать и построить дивный новый мир - вам прямой путь в rust, zig, D и ещё миллион языков, которыми (почти) никто не пользуется.
рано или подхно груз легаси что-то сломает в умах последователей нового.
Если умы "последователей нового" настолько слабенькие, что их ломает груз легаси, то почему они пишут не на js?

gotozero
06.10.2021 19:54+2Интересно, как у вас rust стал "(почти) никто не пользуется".
Из всех самых больших вендоров софта(гугл\эпл\майки etc) ни осталось ниодного, кто не высказался бы в пользу раста как замену плюсам.
Нет спора о том, что такой большой багаж легаси, что уже написан на плюсах никуда не деть и жить нам с этим еще долго, но давайте посмотрим правде в глаза.
Раст метит в ядро линукса в каком-то виде и даже сам Торвальдс не сильно сопротивляется. А плюсам там никогда не бывать.ncwca
07.10.2021 01:30-1Из всех самых больших вендоров софта(гугл\эпл\майки etc) ни осталось ниодного, кто не высказался бы в пользу раста как замену плюсам.
Никто никуда ничего не заменяет, а едет на поезде моды. Каждый код там появляется новый убийца C++.
К тому же, нужно понимать, что никаких гуглов нет. В гугле есть разные люди, разные комманды и прочее. Там используется всё. И то, что кто-то там высказался за раст(в основном потому, что если он за него не выскажется его отнимут от кормушки).
Ценность мнения кого угодно, кто прямо, либо косвенно зависит(особенно материально) практически ничего не стоит. Да, нанятый растовик в гугле будет говорить "раст ненужен - увольте меня побыстрее". Каждый защищает и создаёт себе кормушку.
но давайте посмотрим правде в глаза.
Если мы убираем легаси из уравнения - все сразу же ломается для раста. Потому что 98% проблема C++ связаны не с тем C++, которым он является в настоящем времени.
Раст метит в ядро линукса в каком-то виде и даже сам Торвальдс не сильно сопротивляется.
Нет ничего подобное - это ретрансляция пропаганды.
А плюсам там никогда не бывать.
Неправда. Вы не знаете что было с С++, почему их там нет. И чем отличается С++ от раста.
Если проще, то раст готов отказаться от чего угодно, быть чего угодно лишь бы получить хоть что-то. Лишь бы у пропаганды была возможность сказать "раст есть", а в каком виде и прочее.
За примерами ходить далеко ненужно. Можете посмотреть на то позорище, которое происходит сейчас с эпопей "в ядро". Просто всё выкидывают, все лозунги забываются.
Пацники круто, "у нас С++-исключения", "у нас result и pm" и прочее и прочее. А что сейчас? Паники выпиливаются, все фичи выпиливаются, result выпиливается и заменяется на int. Какие-то тайплевел тоже идёт нахрен.
Тот пример "драйвера реального" максимальное позорище.
В ситуации с C++ такого не было. C++ пытался внедриться полность, а не каким-то огрызком. С исключениями, со своим рантаймом. Полноценно.
И если мы сделаем из С++ такую же Ш, когда мы можем отказываться от чего угодно и прочее, то он будет в ядре застра же. Я вам больше скажу - вам сейчас ничего не мешает писать на С++ без рантайма в ядре. Никакой "поддержки" со стороны ядра для этого ненужно.
И за "внедрение" раста выдаётся то самое, что ничего не стоит. Т.к. раст просто кусок фронта для С/С++-компилятора, то он сам собою интегрируется с си. Там ничего делать ненужно и никто ничего делать не будет.
Всё сводится к добавлению вызывалки раст-кода в билдер ядра. И то так, как нужно ядру, а не расту.
Всё эти истории с ядром не более пиар-проект рассчитаные в основном на тех, кто мало что знает и понимает в теме.
gotozero
07.10.2021 11:34+2Если мы убираем легаси из уравнения — все сразу же ломается для раста. Потому что 98% проблема C++ связаны не с тем C++, которым он является в настоящем времени.
Ага, эту манцу мы слыхали, только есть небольшая проблема — этому не бывать. Никто не будет выкидывать совместимость. Это не считая миллиона других проблем, но не будем об этом, мы же не шарим.Неправда. Вы не знаете что было с С++, почему их там нет. И чем отличается С++ от раста.
Нет ничего подобное — это ретрансляция пропаганды.
И если мы сделаем из С++ такую же Ш, когда мы можем отказываться от чего угодно и прочее, то он будет в ядре застра же.
Ну хоршо, я ничего не знаю. Вы один у нас самый знающий. У вас не пропаганда, а у них пропаганда. Жалковато выглядит или смешно.
А теперь давайте посмотрим, что же говорит сам Линус.
«C++ can’t solve the problem of the C language at all, it will only make things worse. This is a really bad language.»
Упс, цитата то новая. Дальше с такими оголтелыми фанатами смысла вести диалог не вижу. Почитайте что-ли для начала всю «пропаганду», а потом идите позориться на люди.
Вы точно так же, только в очень жалком виде защищаете плюсы, ибо заинтересованы в job security. В чем обвиняете обратную сторону.
И все ваши аргументы выглядят как аргументы школьника, который уже обгадился, но признать мужества не хватает.Gordon01
07.10.2021 12:02Забавно, конечно, что чел действительно скорее всего заинтересован в job security, но поступает совершенно контрпродуктивно, показывая, какими в реальности являются фанатики плюсов.
gotozero
07.10.2021 12:11Что особенно странно, учитывая, что переход из плюсов в раст наверное самый простой из всех возможных.
Да и не обязательно рассматривать это как переход. Раст точно такой же инструмент, как и другие, в ящике любого программиста.
Тут скорее всего влияет то, что инфоповод насыщенный и у некоторых стадия отрицания вылезает как первая реакция.
Связано это скорее всего со слабой личностью человека.
Там где адекватный человек видит возможности, трус видит угрозу.
Gordon01
07.10.2021 12:39Да просто плохой программист, наверняка из госухи, который кроме с++ в жизни больше ничего не пробовал.
eao197
07.10.2021 13:15+6Этот чел очень похож на LOR-овского Царя (и, подозреваю, им и является). Не стоит по его поведению судить о всех разработчиках C++. Тем самым не придется по вашему поведению делать выводы о всех разработчиках на Rust-е.
KanuTaH
07.10.2021 14:11+1Знаете, Царя все-таки интересно бывает почитать, и я сейчас попытаюсь объяснить - почему. Он пишет сбивчиво, в несколько агрессивной манере, и многое из того, что он пишет - как минимум спорно, это так, но он хотя бы пишет свои мысли. Почитать любого человека, который излагает свои мысли, всегда интересно, будь это, так сказать, поклонник C++ или Rust или чего угодно (особенно если он поработает над стилем изложения). В то же время, как противоположность, существуют пропагандисты/евангелисты/etc, которые оперируют главным образом чужими мыслями - "гугл сказал", "майки сказали", "торвальдс сказал", вот их читать (и что-то с ними обсуждать) - совершенно не интересно. Позволю себе небольшую шутливую цитату из Мухина для иллюстрации:
Про виды спора
Представим – в комнате душно, нужна вентиляция. Можно установить вытяжной вентилятор, работающий от электродвигателя, А можно – вытяжную трубу, которая будет отсасывать воздух из комнаты за счет разницы его плотности в доме и на улице. Допустим, есть сторонники той и другой системы вентиляции, и они решили выяснить истину в споре.
Первый тип спора назовем инженерным.
– Надо ставить вентилятор, Это дешевле, чем монтировать трубу.
– Да, труба дороже, но она не потребует затрат на эксплуатацию, а вентилятор будет потреблять электроэнергию,
– Зато тяга трубы непостоянна и зависит от погоды, а тяга вентилятора более надежна.
– Тягу можно регулировать, зато в трубе практически нет ничего, что может выйти из строя. Она чрезвычайно надежна…
И так далее. Обратите внимание – предметом спора постоянно остается вентиляция. Так спорить могут люди, представляющие ее суть. И не имеет значения ни их образование, ни партийная принадлежность, ни личностные качества. Их интересует лишь вентиляция, причем заинтересованы выбрать наилучший вариант. В таком споре действительно может родиться истина.
Второй тип следует назвать бюрократическим, и выглядит он так.
– Надо ставить электрический вентилятор потому, что Ленин сказал: коммунизм – это советская власть плюс электрификация.
– Нет, поставим трубу так, как Ленин сказал, что капитализм вылетит в трубу.
– Надо ставить вентилятор, так как он вертится, а Галилей сказал, что «она все-таки вертится!».
– Поставим трубу, как США на Аляску проложили нефтепровод, а США – это очень цивилизованная страна...
И так далее. Если вы обратили внимание, в данном случае даже непонятно, кто спорит: на первый взгляд, оппоненты, а, по сути – Ленин с Галилеем, которые вряд ли бы спорили, применяя такие доводы. Возможно, Ленин с Галилеем знали толк в вентиляции, но знают ли о ней что-нибудь сами спорщики? Да, у них неплохая память, однако еще лучше – у простого магнитофона (он может точно воспроизвести то, что на нем раньше записали), не говоря уже об ЭВМ. Ни о какой истине в этом споре говорить не приходится, так как для спорщиков главное не истина, а показ своей мудрости.
Вот Царь все-таки спорит, применяя первый тип спора, а отдельные поклонники раста - исключительно второй.

TargetSan
07.10.2021 14:31+3Вот Царь все-таки спорит, применяя первый тип спора, а отдельные поклонники раста — исключительно второй.
Не берусь утверждать про Царя, но конкретно ncwca имеет свойство начинать громогласно орать про манипуляции, как только ему указываешь на его неправоту. Подобное поведение и крайне похожий стиль были замечены в аналогичных статьях в конце 2019го.
ncwca
08.10.2021 00:27-2Опять потоки вранья. И каждый подобный настолько нагло врёт. Давайте воспроизведём его схему.
"ты неправ, потому что вася сказал" - "какой вася? Кому сказал, куда сказал? Почему? Почему ты припёр сюда васю? Вася говорил о том, о чём говорил я? Нет. Ты это сказал - не вася. Зачем ты манипулируешь?" - "ой, какой ты плохой - сразу начал говорить про манипуляции".
Т.е. боты привыкли действовать так. Сказать "ты не прав потому что гладиолус" и всё, ты должен сразу это признать. Ведь это именно что указание на неправоту, а нелепая попытка забалтывания и манипуляций.
Следуй тому, чему сказали мы. Верь в то, что сказали мы. У тебя нет права что-то решать.
gotozero
07.10.2021 14:17+2Разумеется. Я бы даже не удивился, если бы к плюсам он никакого отношения не имеет.
Вот кстати новые интересные цитаты про раст, из интервью, посвященное 30-ти летию Linux на прошлой неделе, от самого.
Для понимания статуса.the first language I saw which looked like this might actually be a solution
Probably next year, we’ll start seeing some first intrepid modules being written in Rust, and maybe being integrated in the mainline kernel.
eao197
07.10.2021 14:26Можно порадоваться за Rust... Но, боюсь, растоманы не понимают простой вещи: не смотря на наличие Rust-а уже существующие кодовые базы на C++ никуда не денутся. Как и не перестанут стартовать новые проекты на C++ (хотя бы потому, что дешево сделать это, если вы будете переиспользовать 100500 уже существующих библиотек на C++ и чистом C). А значит будут люди, которые будут вынуждены продолжать писать на C++. И этим людям интересно обсуждать проблемы C++ и способы решения проблем C++.
А вовсе не то, что в Rust-е этих проблем нет. Да и вообще проблем нет. И будущее у него яркое и безоблачное. И волосы он делает шелковистыми. Более того, он возвращает волосы тем, кто их потерял. И еще...
Так вот, все эти достоинства Rust, какими бы они не были, в разговоре о C++ могут быть интересны разве что с точки зрения того, как действительно полезные фичи перенести в C++ (вроде того, как if constexpr появился в C++ явно содранным с D-шного static if-а).
Но что-то я не заметил, чтобы Rust здесь упоминался именно в таком ключе. Может не туда смотрел?
PS. К Rust-у сам отношусь скептически, но без негатива. И даже был бы не против сами повелосипедить на Rust-е за чужие деньги, но пока что область интересов лежит в области C++.
gotozero
07.10.2021 15:18+2Как и не перестанут стартовать новые проекты на C++ (хотя бы потому, что дешево сделать это, если вы будете переиспользовать 100500 уже существующих библиотек на C++ и чистом C)
С чистыми Си как раз проблем для использования из раста никаких нет. Полагаю, они on par в этом отношении.
А если нет, то будут окончательно, когда допилят gcc для раста. А все крутые и стоящие проекты на плюсах так же выставляют С ffi. Именно новые проекты начинать на плюсах сейчас будут особо осторожно. О чем и пишут статьи ребята из майкрософта и гугла собственно.
Но речь шла за это:rust, zig, D и ещё миллион языков, которыми (почти) никто не пользуется.
Нет ничего подобное — это ретрансляция пропаганды.
В ситуации с C++ такого не было. C++ пытался внедриться полность, а не каким-то огрызком. С исключениями, со своим рантаймом. Полноценно.
Появление раста в mainline kernel это миллиарды девайсов автоматически. А учитывая adoption rate во всяких ит-гигантах, "(почти) не используется никем" — выглядит как отрицание надвигающейся реальности.
0xd34df00d
07.10.2021 20:15+3Как и не перестанут стартовать новые проекты на C++ (хотя бы потому, что дешево сделать это, если вы будете переиспользовать 100500 уже существующих библиотек на C++ и чистом C)
Про раст не могу ничего сказать, я им не интересовался за пределами ленивого листания rust by example, но по опыту написания всякой ерунды на хаскеле — ну вот не встречался я с такой ситуацией, когда хотелось сказать «да ну нафиг, зачем я это только начал писать на хаскеле, вот писал бы на плюсах — воспользовался бы библиотекой X и решил бы проблему Y в три строки». А вот обратное было кучу раз, хотя решал я разные задачи, от компиляторов и тайпчекеров до банальных опердней, перекладывающих жсончики.
eao197
07.10.2021 20:23Из перечисленного вами на C++ в последние 15 лет не стал бы делать ничего. Ну, может быть для компилятора бы выбрал, если бы у этого компилятора были высокие требования к производительности/ресурсоемкости.
Ну и сам комментарий непонятен. Типа, мне не нужно, значит никому не нужно? Вот уж не ожидал такого захода от столь опытного человека.
0xd34df00d
07.10.2021 20:53+1Компиляторы становятся быстрее скорее из-за более адекватных алгоритмов, чем от специфики языка. Например, идрис 2, написанный на идрисе, на порядок-другой быстрее идриса 1, написанного на хаскеле, хотя в числодробилках компилятор хаскеля выдаёт минимум на порядок более быстрый код (а чаще — на порядки). Но это так, к слову.
Типа, мне не нужно, значит никому не нужно?
Нет, типа мне не нужно в очень широком диапазоне проектов, и я не представляю, кому и зачем нужно. Ну, то есть, я серьёзно не могу придумать достаточное количество проектов (чтобы это не было потребностью уровня кобола), не привязанных к конкретной компании и её внутренней кухне (там и так много административных факторов), для которого наличие плюсовых библиотек было бы решающим фактором.
eao197
07.10.2021 21:11-1Компиляторы становятся быстрее скорее из-за более адекватных алгоритмов, чем от специфики языка. Например, идрис 2, написанный на идрисе, на порядок-другой быстрее идриса 1, написанного на хаскеле, хотя в числодробилках компилятор хаскеля выдаёт минимум на порядок более быстрый код (а чаще — на порядки).
Вот честно не понял, какой пример вы здесь привели и для чего. Но, простите мне мой французский, LOR-овский жаргон в этом конкретном случае одно образцовое нинужно соревнуется с другим образцовым нинужно.
Скорость работы компилятора Go -- это проблема целой индустрии. Скорость работы компилятора C++ -- это так же проблема целой индустрии. Как и скорость работы компилятора Java.
А вот с какой скоростью компилируются Haskell с Idris-ом... Ну вас это может и волнует.
я не представляю, кому и зачем нужно
Не представляете. Ok. И что? От того, что вы не представляете что-то изменится или что?
0xd34df00d
07.10.2021 21:14+2А вот с какой скоростью компилируются Haskell с Idris-ом… Ну вас это может и волнует.
Идрис-то да, а вот про хаскель у вас шутеечки устарели примерно в 2016-м.
Не представляете. Ok. И что? От того, что вы не представляете что-то изменится или что?
Считайте это ненавязчивым приглашением поделиться конкретными сценариями, где это бы роляло.
eao197
07.10.2021 21:32-1а вот про хаскель у вас шутеечки устарели примерно в 2016-м.
С чего бы? За посление 5 лет Хаскель догнал по востребованности хотя бы Ruby?
Считайте это ненавязчивым приглашением поделиться
А зачем это мне? В моей реальности пару месяцев назад к нам постучался заказчик и высказался в духе "Вот у меня есть такие-то наработки и я хотел бы, чтобы вы взяли вот это и вот это и сварганили бы для меня вот такое вот, сможете?" Все это C++ и чистый C, плюс наши собственные разработки (опять же на C++).
Не вижу смысла кого-то на интернет-площадке убеждать в том, что такие вещи происходят. И что на C++ можно делать проекты без особой боли и разочарований.
0xd34df00d
07.10.2021 22:57+2С чего бы? За посление 5 лет Хаскель догнал по востребованности хотя бы Ruby?
ХЗ про востребованность, но работу что там, что там найти несложно.
А зачем это мне?
Чтобы общение сводилось не только к перекидыванию тезисами, но и к их обсуждению.
В моей реальности пару месяцев назад к нам постучался заказчик и высказался в духе "Вот у меня есть такие-то наработки и я хотел бы, чтобы вы взяли вот это и вот это и сварганили бы для меня вот такое вот, сможете?"
Так а почему этот заказчик начал свои наработки пилить на плюсах?
И что на C++ можно делать проекты без особой боли и разочарований.
Не верю. Постоянная, жгучая боль и ломота в пальцах. Не как на питоне, конечно, но всё же.
eao197
08.10.2021 07:01-1ХЗ про востребованность
Например, в наших палестинах (РБ) у Хаскеля востребованность никакая. Даже по сравнению с Ruby. И, может быть, для одного-двух хаскелистов работа найдется. Но не для сотни. В отличии от Ruby.
Чтобы общение сводилось не только к перекидыванию тезисами
Тогда ваш исходный комментарий никак этому не способствует. В нем только ваши личные ощущения. И мне непонятны, как минимум, две вещи: зачем это было высказано именно мне и какая реакция ожидается от меня? Так что если вы хотите обсуждения, то начните с себя, пожалуйста.
Так а почему этот заказчик начал свои наработки пилить на плюсах?
Мне вот совершенно без разницы.
Не верю.
Дело ваше. Я года с 2013 на разных площадках в Рунете пытаюсь развенчивать мифы о C++. Уже, мягко говоря, задолбался. Простите, но заходить на (N+1) круг не буду.
Постоянная, жгучая боль и ломота в пальцах.
-- Доктор, когда я ковыряюсь гвоздем в ухе, то мне больно...
-- А вы не делайте так!
0xd34df00d
08.10.2021 07:14+1Например, в наших палестинах (РБ) у Хаскеля востребованность никакая.
Ну про это я писал рядом.
Тогда ваш исходный комментарий никак этому не способствует. В нем только ваши личные ощущения. И мне непонятны, как минимум, две вещи: зачем это было высказано именно мне и какая реакция ожидается от меня? Так что если вы хотите обсуждения, то начните с себя, пожалуйста.
Окей, начну с себя прямым вопросом вам на ваш тезис: можете привести таковые примеры, когда 100500 имеющихся библиотек не существуют для других языков? Желательно без обоснований в стиле «к нам тут пришёл чувак, который уже что-то наваял, поэтому мы назовём это библиотекой».
Мне вот совершенно без разницы.
Тогда зачем вы вообще приводите этот пример?
Дело ваше. Я года с 2013 на разных площадках в Рунете пытаюсь развенчивать мифы о C++. Уже, мягко говоря, задолбался. Простите, но заходить на (N+1) круг не буду.
Когда надо писать руками дебаговое отображение на экран вместо
deriving (Show)— это боль. Когда нет репла, и просто поиграться с кодом невозможно — это боль. Когда писать надо руками хешеры — боль. Сериализация в жсон (или в БД) — боль. Рекурсивная беготня по гетерогенным деревьям — боль. Когда надо писать, блин, операторы сравнения — это снова боль (ну, да, в 2020-м году, наконец, это починили, успех, великий прорыв, но у меня уже артрит развился за прошлые 17 лет работы с плюсами, да и всё прочее-то всё равно надо писать).Ладно писать, читать чужой код — тоже боль. В типах ничего не видно, нихрена не понятно, модифицируется ли глобальное состояние или нет, можно ли удалить вызов этой функции или нет, может ли она вообще влиять на то, что мне надо починить в коде прямо сейчас, или нет. Впрочем, языков, где типы помогают, мало — на окамле у меня, например, были аналогичные боли.
Да и без этого всего UB на UB и UB погоняет (я ещё не встречал ни одного проекта без этого).
Собирать чужой код — боль. Если взять настоящий C++ а-ля Царь, чтобы прям темплейтами по самые уши обмазаться, а не это ваше си с классами позорное — так оно компиляется минутами даже без оптимизаций, и это снова боль. Ну Царю-то пофиг, понятное дело, он дальше 50-строчных хелловорлдов не уходил.
Боль, боль, боль, боль, боль. Лучше, чем в C, конечно, или там, не знаю, в коболе-фортране, но боль.
А вы не делайте так!
Так я и перестал писать на плюсах.
eao197
08.10.2021 07:50Ну про это я писал рядом.
Рядом -- это где?
Окей, начну с себя прямым вопросом вам на ваш тезис: можете привести таковые примеры, когда 100500 имеющихся библиотек не существуют для других языков?
Во-первых, вы задаете не тот вопрос. Дело не в том, что 100500 библиотек есть для разных языков. Дело в том, что обычно есть команда с неким бэкграундом. И команда берется за новый проект исходя из тех навыков, которые у них есть. Например, это команда C++ников. И они видят, что, условно, 70% потребностей можно закрыть с использованием уже имеющихся библиотек. В этом случае можно брать C++ и не париться.
Во-вторых, если вы уж хотите поиграть вы эту игру, то давайте сравним, например, количество и качество кроссплатформенных GUI библиотек для C++, Rust-а и Хаскеля.
Желательно без обоснований в стиле «к нам тут пришёл чувак, который уже что-то наваял, поэтому мы назовём это библиотекой».
Дурака валять перестаньте.
Когда нет репла, и просто поиграться с кодом невозможно — это боль.
Все понятно.
0xd34df00d
08.10.2021 08:03+2Рядом — это где?
Неважно, мы там уже обсуждаем, тут эту нить обсуждения можно дропнуть.
Во-вторых, если вы уж хотите поиграть вы эту игру, то давайте сравним, например, количество и качество кроссплатформенных GUI библиотек для C++, Rust-а и Хаскеля.
А чего не парсер-комбинаторов?
Дурака валять перестаньте.
Ну ок, тогда без намёков скажу: у вас там circular reasoning.
Все понятно.
Что понятно?
И по другим пунктам вопросов нет?
eao197
08.10.2021 08:17А чего не парсер-комбинаторов?
Потому что мне они не нужны. Соответственно, если бы пришлось плотно работать с парсерами, то C++ для задачи был бы не подходящим языком даже не смотря на наличие для него 100500 библиотек по другим направлениям. И, касательно парсеров, C++ был бы плохим выбором не только из-за отсутствия таких библиотек, но и потому, что C++ не очень подходит для обработки того, что получается в результате разбора. Те самые гетерогенные структуры, о которых вы говорили в другом комментарии.
Что понятно?
Скажем так, понятен ваш подход к разработке.
И по другим пунктам вопросов нет?
Нет. Тут ситуация такая: один человек смотрит на дубовую столешницу и видит уникальный узор, а другой -- полчища микроорганизмов на ее поверхности, среди которых множество болезнетворных, а некоторые прямо могут привести к тяжелым заболеваниям.
У меня нет намерения доказывать, что C++ хорош и напрочь лишен недостатков. Это не так.
Но вот писать на C++ можно без боли и сожалений. Хотя бы потому, что во многих случаях все то, что вы описали, не имеет серьезного значения. А что-то, вроде repl-а, бесполезно от слова совсем.
0xd34df00d
08.10.2021 08:27+1Потому что мне они не нужны.
Иронично.
Не, я не спорю, что есть какое-то легаси, которого на плюсах больше. Ну так это для любого языка верно, вроде того же кобола, или вот мой сокурсник на своей кафедре какую-то фортранолапшу-симуляцию допиливал.
Скажем так, понятен ваш подход к разработке.
Ой, а если без намёков, что с ним?
Хотя бы потому, что во многих случаях все то, что вы описали, не имеет серьезного значения.
Только код раздувается в разы, но это мелочи, конечно.
eao197
08.10.2021 08:37Иронично.
Никакой иронии.
Полагаю, проблема в том, что мое высказывание про том, что новые проекты на C++ начинают (в том числе) из-за того, что есть существующие библиотеки, с которыми разработка пойдет сильно дешевле, вы восприняли как высказывание о том, что это верно для любых проектов в любых прикладных областях.
Так вот, это не так. Поскольку прежде чем говорить о библиотеках, нужно сперва решить вопрос о применимости C++ вообще. А C++ в современных условиях применим если:
сама предметная область для C++ подходит (например, это что-то околосистемное или связанное с тяжелой математикой, или требуется хороший кроссплатформенный GUI, или реальное время);
мы располагаем ресурсами, которые владеют C++.
Если эти факторы сложились благополучно и есть библиотеки, которые способны закрыть значительную часть потребностей, то да, наличие готовых плюсовых и/или чисто Сишных библиотек -- серьезный фактор.
Ой, а если без намёков, что с ним?
Во-первых, он не нужен.
Во-вторых, он присущ людям с определенным складом мысли. По опыту, таким людям ФП гораздо ближе. И они начинают писать на С++ не так, как следовало бы, пытаясь использовать C++ не как C++.
Только код раздувается в разы, но это мелочи, конечно.
Вынужден сказать банальность: это зависит от того, какую задачу вы решаете. И какие качества пытаетесь заложить в решение.
0xd34df00d
08.10.2021 08:47+1Во-первых, он не нужен.
Смешно.
Во-вторых, он присущ людям с определенным складом мысли. По опыту, таким людям ФП гораздо ближе. И они начинают писать на С++ не так, как следовало бы, пытаясь использовать C++ не как C++.
Какая разница? Это возможность быстро запустить или проверить какой-то кусок кода (потенциально не ваш), посмотреть на тип сложного выражения, и так далее.
eao197
08.10.2021 08:57+2Смешно.
Печально. Но вы вряд ли понимаете почему.
Какая разница?
Большая. Например, будет ли человек получать удовольствие от своей повседневной работы. Или будет страдать, выгорит и напишет большую статью о том, как он настрадался. А потом будет бегать и уверять в том, что кроме страданий ничего нет. Будучи так себе демагогом.
0xd34df00d
08.10.2021 09:03+2Печально. Но вы вряд ли понимаете почему.
Да не, просто вы так долго топили за субъективность понятия ненужности, а тут...
Например, будет ли человек получать удовольствие от своей повседневной работы. Или будет страдать, выгорит и напишет большую статью о том, как он настрадался.
Мне было в кайф писать на плюсах, пока у меня за это не было ответственности. А писать на плюсах безUBово невозможно.
ncwca
08.10.2021 16:02-2Когда надо писать руками дебаговое отображение на экран вместо
deriving (Show)— это боль.Ничего писать ненужно. В скриптухе нет ничего, кроме таплов и агрегатов. Таплы dy-design выводятся без написания, агрегты аналогично. Есть
__builtin_dump_struct, есть mg.К тому же, здесь происходит попытка манипулировать. Дело в том, что скриптуха не способна выражать обобщённый код. Т.е. все эти deriving и тысячи прочей херни нужны не потому, почему они нужны С++.C++ они нужны для агрегатов, потому что у него нет средств интроспекции. Т.е. ему нужна просто карта агрегата.
Скриптухе нужна кодогенерация та, которая решает задачу именно того же отображения. Именно поэтому там
deriving (Show). В противном случае ничего даже указывать ненужно.Получить карту агрегата в C++ можно банальным макрос, через который можно определить агрегат. Лишних символов там будет не больше, чем в скриптухе.
Когда нет репла, и просто поиграться с кодом невозможно — это боль.
constexpr - есть репл. Тайплевел - есть репл. К тому же, есть cling.
Сериализация в жсон (или в БД) — боль.
В js вообще жсон нативный, и? Очевидно, что если пытаться писать на C++ скриптушный мусор - будут проблемы. Для него есть жаваскрипт.
В C++ никакая сериализация, а уж тем более в жсон ненужна.
Когда надо писать, блин, операторы сравнения — это снова боль (ну, да, в 2020-м году, наконец, это починили, успех, великий прорыв, но у меня уже артрит развился за прошлые 17 лет работы с плюсами, да и всё прочее-то всё равно надо писать).
Опять нелепое враньё. C++ ненужно писать никакие операторы, просто понимание и умения данного персонажа находятся где-то в районе дна.
C++ может выражать обобщённое сравнение. Для таплов - ничего писать ненужно. Для агрегатов - нужна только карта.
Далее печатание, сериализация, жсон, сравнения и прочая чушь - пишется ровно один раз. Но да, C++ виноват в том, что кто-то не осилил.
Ладно писать, читать чужой код — тоже боль. В типах ничего не видно, нихрена не понятно, модифицируется ли глобальное состояние или нет, можно ли удалить вызов этой функции или нет, может ли она вообще влиять на то, что мне надо починить в коде прямо сейчас, или нет. Впрочем, языков, где типы помогают, мало — на окамле у меня, например, были аналогичные боли.
Полнейший нелепый поток шизофазии. Никакие типы ненужно видеть. Это не мусорная скриптуха. Видеть что, чтобы что? К тому же - их видно.
Видеть в шаблонах? Там типы такие, что адепт их никогда не прочитает даже. В рядовой лапше, который пишет и видел данный персонаж - никаких проблем с видением типов нет.
Про какую-то херню "можно ли убрать" - просто заучил методичку про чистоту и только что проблему придумал. Никто никогда никакие глобалы не трогает, а если трогает это очевидно.
Я не видел ни разу, чтобы кто-то что-то трогал, либо существовал какой-то неочевидный код не зависящий от контекста.
Ещё раз. Функция либо завязана на контексте и тогда её никак выпилить нельзя. Либо нет и она элементарна. Т.е. вопроса "можно ли выпилить" никогда не возникает.
Да и без этого всего UB на UB и UB погоняет (я ещё не встречал ни одного проекта без этого).
Никакого УБ в C++ не существует. Альтернатива скриптухи - это один компилятор. Там сразу уходят нахрен все УБ.
Далее, сами УБ есть везде. Это базовое свойство реальности. В скриптухе нет УБ не потому, что их нет. А потому, что на ней пишут примитивный мусор.
Если прикрутить к C++ гц, боундекинг, не использовать указатели и прочую хейрню - никакого УБ там никогда не будет. Просто обычно к C++-коду предъявляются какие-то требования, куда большие нежели к скриптушному мусору - требование к которому лишь одно - лишь бы хоть как-то работал.
И именно эти требования заставляют использовать всякий лоулевел и ручное управление. Ты не можешь сделать тоже самое в скриптухе и как-то защитить от УБ.
Если взять настоящий C++ а-ля Царь, чтобы прям темплейтами по самые уши обмазаться, а не это ваше си с классами позорное — так оно компиляется минутами даже без оптимизаций, и это снова боль.
Полнейшая и нелепая чушь. Не покажет ни одной подобной компиляции.
Тот мусор, что подобный адепт способен написать - компилируется со скоростью десятки/сотня тысяч строк в секунду. Минута - это портянка на миллионы строк. Никогда у него кода столько не будет.
Ну Царю-то пофиг, понятное дело, он дальше 50-строчных хелловорлдов не уходил.
Боль, боль, боль, боль, боль. Лучше, чем в C, конечно, или там, не знаю, в коболе-фортране, но боль.
Да, да.
Так я и перестал писать на плюсах.
И не писал никогда. Пиши честно - не состоялся как крестовик. Не смог конкурировать с лучшими. Решил подхалявить там, где минимальная конкуренция. Во всякой маргинальной херне - там одни подобные неосиляторы. И в этой битве 150 эшелона уже можно биться.
Ну и напиши любой мусор уровня "C++ говно" - набегут табуны сектантов и будут плюсовать. Спрос на хейт крестов гиганский. Обида гигантская. Не состоялся ни один ты. Не выдержал конкуренции ни один ты.
Быть в авангарде человеческого капитала - сложно. А быть первый парнем на деревне - просто. Ты сделал свой выбор.
ncwca
07.10.2021 15:15Ага, эту манцу мы слыхали, только есть небольшая проблема — этому не бывать. Никто не будет выкидывать совместимость. Это не считая миллиона других проблем, но не будем об этом, мы же не шарим.
Меня пытаются бить убогой "манцу". Наивно надеясь, что тот лозунг, что человек где-то слышал - сработает против меня.
Но проблема в том, что нет. Эта мантра предполагает принятие того, что я отрицаю. Нужно лучше подбирать методичку.
Если не очевидно - всё просто. Если мы предполагаем, что "это не бывать", то никакого раста не существует. А если он существует и пытается где-то оппонировать крестам, то там уже есть возможность "этому бывать".
Максимально детский мат. Ждём обновления методички.
Ну хоршо, я ничего не знаю. Вы один у нас самый знающий. У вас не пропаганда, а у них пропаганда. Жалковато выглядит или смешно.
Эти детские заходы "раз я не знаю - значит никто не знает". То, что вы ничего не знаете и ретранслируете пропаганду - никак не означает, что самый знающий я, либо только я. Это лишь означает, что не знающий вы.
«C++ can’t solve the problem of the C language at all, it will only make things worse. This is a really bad language.»
А вот здесь у вас всё совсем плохо. Против меня это не работает по двум причина, как минимум.
Первое - я не являюсь адептом крестов. Я являюсь их хейтером. Вы можете спросить у появившихся тут падших в прошлых битвах со мною. Почему же они меня ненавидят.
Второе, то что я называю C++ не имеет никакого отношения к C++. И то, что называет C++ линус не имеет никакого отношения к тому, что я называю C++. А то, что линус называет C++, называет "a really bad language" я называю немного иначе. А как - лучше этого не знать.
Вы точно так же, только в очень жалком виде защищаете плюсы, ибо заинтересованы в job security.
Практический каждый раст-адепт - это борец на фронте job security. Моя job никакого отношения не имеет к C++ и никак от них не зависит.
В чем обвиняете обратную сторону.
И все ваши аргументы выглядят как аргументы школьника, который уже обгадился, но признать мужества не хватает.Да, обгадился я, а методичка поломалась у вас. Основания есть у меня, а у вас мусорные цитатки и агитки, которые вы даже правильно подобрать не можете.
А уж если мы будем разбираться в том кто и от чего зависит - лучше этого не делать, ведь результат очевиден. Посмотрите на бывалых. Они куда опытнее вас. Видите какие-то заходы про "адепт С++", "ты зависишь от С++" с их стороны? Правильно, не видите и не увидите. Потому что они, будучи зависимыми сами, знают и понимаю где свои, а где чужие.
Не туда воюете.
gotozero
07.10.2021 15:36+2Так никто и не воюет. Просто предлагаю следовать фактам.
Если Линус говорит, что ожидаем в следующем году появление раста в mainline kernel, то я не понимаю, почему вы называете это пропагандой, слабостью языка, что поступился принципами, чтобы появиться в ядре и прочие вялые набросы.Второе, то что я называю C++ не имеет никакого отношения к C++. И то, что называет C++ линус не имеет никакого отношения к тому, что я называю C++.
Видите в чем проблема. У вас своя альтернативная реальность, где вы выделили для себя некое подмножество C++ и считаете что он решает все проблемы.
Только есть проблема — весь остальной мир под С++ понимает и остальной сабсет языка и парадигм и туллчейнов, что вы решили выкинуть.
Как я и говорю, тут нет смысла спорить и уж тем более аппелировать к авторитетам, потому, как все, хоть сколь-либо стоящие авторитеты свое мнение высказали.
AnthonyMikh
07.10.2021 16:30А, ну как обычно, стоило Царя прижать за хвост, как он сразу начинает вопить про методичку, и C++-де не C++, и вообще он не адепт, а хейтер, а все остальные — безголовые школьники без собственного мнения.
Вы можете спросить у появившихся тут падших в прошлых битвах со мною.
падших в прошлых битвах со мноюЕщё и эго раздутое сверх всякой меры.
ncwca
07.10.2021 18:09-1Я не хочу опять срываться. Все мои тезисы известны многим, включая данного персонажа. Они были формулированы ещё до того как он вообще где-либо появился. И не менялись никогда.
Но он будет врать, его задача даже не то что обмануть тех, кто наших отношений не знает. Ему просто нужно легализован набеги ботвы на мою карму.
Мне лень искать переписки, говно о том, что там рука руку моет. Что хайп это единственное, про что будут читать его откровения. У меня же никакой выгодны в моих действиях для меня нет. Одни убытки.
Про то как он постоянно клянчит денюжку я тоже говорить не буду. Но для выгоды пишу я. Защищаю себя я. С++ нужен мне. Да, да.
Ещё и эго раздутое сверх всякой меры.
Как можно забыть. Ты не можешь раст-ботву считать неправыми и спорить с ней. Ты обязан молиться на неё. Куда тебе.
все остальные — безголовые школьники без собственного мнения.
Просто вчитайтесь в этой. Как каждый бот повторяет одну и ту же херню. Ты отвечаешь одному - она уходит и приходит новый. Приходит и повторяет ту же херню на которую ты ответил.
TargetSan
07.10.2021 21:04+1Вы можете спросить у появившихся тут падших в прошлых битвах со мною.
Ну и эго у вас… Вам, видимо, не приходило в голову, что людей просто утомляет пытаться отвечать на поток взаимоисключающих параграфов вроде
то что я называю C++ не имеет никакого отношения к C++
а также оскорбления, наезды и поток неконструктива про "методички" и им подобное. Вы никого не победили, а просто перестали быть интересны. За два года вы не поменялись и ничему не научились.
Antervis
07.10.2021 15:41+3Ага, эту манцу мы слыхали, только есть небольшая проблема — этому не бывать. Никто не будет выкидывать совместимость. Это не считая миллиона других проблем, но не будем об этом, мы же не шарим.
подскажите, как у вас смешались понятия "совместимость" и "легаси"? Да, существует старый код на старом плюсовом диалекте, новый код пишут на новом диалекте, в чем проблема-то? Рано или поздно код на расте тоже отлежится, завоняет и станет легаси, это если раст не вымрет. Вы будете ждать этого чтобы поменять свою точку зрения, или можете сразу, дальновидно, поменять её с учетом такой перспективы?
А теперь давайте посмотрим, что же говорит сам Линус.
да, давайте подкреплять свой беспочвенный хейт цитированием хейтера, известного своей неадекватностью, который свой хейт ничем никогда не обосновывал, ведь именно так действуют думающие люди... нет, конечно же. Хотите конструктивной дискуссии - вносите конструктив, анализ, и объективные аргументы. Пока что вы лишь перевбрасываете чужие вбросы
ncwca
07.10.2021 18:24+3Нет там никакой смеси понятий. Есть базовая методичка, которую он ретранслирует. Там есть лозунг "С++ - легаси, нового С++ нет". Потому что единственное, что они могут - это соревноваться с С++ из девяностых годов. И то враньём.
Но методичка это предполагает от нас того, что присуще многим крестовикам, которые подобны раст адептам и защищают лишь свою кормушку. Она будут доказывать всем, что С++ - это легаси из 90х годов и другого нет.
При этом, заметим. Эти два явления не могут существовать вместе. Нельзя пытаться куда-то внедрить раст, где всё залочено на легаси С++. Это не имеет смысла.
Но пропаганда знает, что это чушь. Но она так же знает, что эта чушь выгодна некоей группе крестовиков. И таким образом боты одни поддерживают альтернативную реальность для других, а те, в свою очередь, в обратную сторону.
Поэтому мы всегда должны форсировать равные условия для сравнения. Если мы сравнивает раст и С++ - мы должны сравнивать это в одинаковых условиях.
Можем ли внедрить раст туда, повторюсь, где нельзя писать ни на чём, кроме С++-легаси? Нет. Это невозможно.
Можно ли его внедрить туда, где никакого легаси нет? Да. Можно ли туда внедрить любой диалект С++? Да. Любой другой язык? Да. Всё, мы сломали методичку.
Пока что вы лишь перевбрасываете чужие вбросы
Это не вброс. си с классами действительно не решает каких-либо проблем си. Вернее какие-то решает, но создаёт новых столько, что они компенсируют все преимущества. Я об этом много писал ранее.
Здесь данный пропагандист нам просто пытается внушить нужное ему понимание вопроса. Вернее нужное его методичке.
C++ существует в разных качествах. И один С++ не равен другому. Точно так же спроси линуса про "стандартный си" - он назовёт его дерьмом. Следует ли из этого то, что си дерьмо?
Нет, просто у него, как и у любого адекватного человека своё понимание вопроса. И для него не существуют языка в том качестве, котором они существуют для целей антрикрестовой пропаганды.
Нужно лишь не давать пропагандистам забирать у нас возможность определять смыслы. Ведь заметим, что пропагандист не делегирует это линусу, как он пытается это выставить. Он сам пытается определить, что C++ линуса это то, что понимаю под С++, либо кто-либо ещё. Он ведь не приносит нам цитаты линуса о том, что он понимает под С++, а так же какие проблемы он в нём видим.
Ведь далее мы можем пойти и посмотреть - соотносится ли то, что пишу, допустим, я с тем, что она называет плохим. И нет.
Даже если таких цитат нет, то очевидно, что здесь имеется ввиду общепринятое понимание. Т.е. си с классами из 90х. Ни я, ни кто-либо из адекватных крестовиков это за С++ не считает.
gotozero
07.10.2021 23:48И один С++ не равен другому.
Вот в этом и проблема. Иногда на столько не равен, что приводит к большим ошибкам в большой кодовой базе.
Это и есть основная претензия.
Вы считаете, что ваш С++ правильный, а 100 других контрибьюторов считают что их. А они вообще лохи, которые не разобрались.
Человеческий фактор дерьмо, а не C++.
А покуда вы не можете заставить всех быть одинаковыми, то вывод очевиден.
ncwca
08.10.2021 16:28-2Вот в этом и проблема. Иногда на столько не равен, что приводит к большим ошибкам в большой кодовой базе.
Глупости. Это свойство чего угодно. Да, в бесполезной маргинальной скриптухи в которой нет ничего, кроме фантиков и дешёвого хайп - таких проблем нет.
Хотя нет - они есть. Даже в рамках этой скриптухи кто-то сидит на найтли и обмазываеться очередной перепастой с C++, а другой сидит на какой-то древней версии.
Вы считаете, что ваш С++ правильный, а 100 других контрибьюторов считают что их.
Нет. Правильный именно мой и все считают, что правильный он.
А они вообще лохи, которые не разобрались.
Человеческий фактор дерьмо, а не C++.Вы плохо себе представляете что такое C++ и зачем он существует. 98% C++-кода - это интеграция со скриптухой.
Вот возьмём скрипутуху типа раста. Вся "сложность" его реализации состоит из огрызков C++-логики. Почему раст может существовать?
Правильно, потому что C++ специально себя ограничивает. Чтобы подобное убожество, чтобы подобные люди, которые ни на что не способны - могли хоть как-то компилятор родить.
Аналогично со всем остальным. Пистоны, жавы, шарпы, жаваскрипты, расты - тысячи их. Каждая их этих скриптух написана на С++. Каждая их этих скриптух живёт внутри экосистемы написанной на С++, внутри рантайма написанного на С++.
Именно поэтому и существует си с классами. Чтобы интегрировать со скриптухой. И каждый, кто на нём пишет это понимает. Но никто с этим не может ничего поделать. Потому как проблема не в С++.
Если бы весь этот код писался на C++, если бы все эти апи писались бы на C++ - их бы никто использовать не мог. Ни один язык не может выразить то, что может выразить C++. C++ нельзя ни с чем связать в силу его невероятной выразительности.
Поэтому единственное место где C++ может существовать - это библитеки для си с классами. А так же отдельные проекты на С++, которые практически нет. В силу ограниченности ресурсов. Если завтра все адепты C++ начнут писать код для C++ - весь мир схлопнется. Раст сдохнет первым. Всё сдохнет нахрен.
gotozero
08.10.2021 16:57Нет. Правильный именно мой и все считают, что правильный он.
Ой, мамочка родная. А вы проверялись у психиатра?
Я без иронии и издевательств, если вы сейчас не тролите и на серьезных «щах» такое заявляете, то сходите все же ко врачу.
gotozero
08.10.2021 17:09Ну извините. Если вы заявляете, что вы Наполеон, то у любого человека будет к вам два вопроса: «вы торт или полководец?»
А из рекомендаций только один — сходить проверить голову. И я говорю это по доброте душевной, а не потому, что хочу выставить вас в плохом свете или не дай бог издеваюсь над больным человеком.
Antervis
08.10.2021 18:18+1А из рекомендаций только один — сходить проверить голову. И я говорю это по доброте душевной, а не потому, что хочу выставить вас в плохом свете или не дай бог издеваюсь над больным человеком.
я конечно понимаю, что скомпилировать поток сознания ncwca еще сложнее чем плюсы, но как бы парадоксально это ни звучало, тут я с ним соглашусь. Нюанс в том, что вот эта проблема:
Вы считаете, что ваш С++ правильный, а 100 других контрибьюторов считают что их
потихоньку отмирает т.к. в современных плюсах народ постепенно приближается к некоторому единому стилю, с редкими domain-specific оговорками. Тот же гугл, например, отказался в своих гайдлайнах от правил наподобие "не используйте mutable references". Да, я согласен, это всё еще не обязательный линтер который на каждый кривой отступ будет посылать к чертовой бабушке, но тем не менее того разброда и шатания, что был лет 20 назад, в новых кодобазах не встретишь.
technic93
09.10.2021 00:28-1Полагаю что доктор вы ещё более компетентный чем программист. Как хорошо что на хабре такие много профильные специалисты! Прямо каждый раз радуюсь, и диагноз поставят, и
говнокодить научат.
gotozero
09.10.2021 02:02+1Поищите по странице(ctrl+f) слово «эго» и прочие ответы.
Тут не надо быть врачем.
«Если все вокруг вас воняют говном, вероятно это вы обосрались»(цит. примерная)
technic93
09.10.2021 05:57-1Если не брать в рассмотрение другие реплики царя, конкретно тут у вас проблема с логикой.
Представьте ситуацию. Человек заявляет что земля круглая. На что вы отвечаете, вообще-то говоря есть другие версии, - кое кто считает что она плоская.
Так вот, абсолютно нормально ответить, что моя версия правильная, а другие полный бред. Так что не спешите записывать других в сумасшедших.
DarkEld3r
07.10.2021 11:55+1За примерами ходить далеко ненужно. Можете посмотреть на то позорище, которое происходит сейчас с эпопей "в ядро". Просто всё выкидывают, все лозунги забываются.
Пацники круто, "у нас С++-исключения", "у нас result и pm" и прочее и прочее. А что сейчас? Паники выпиливаются, все фичи выпиливаются, result выпиливается и заменяется на int. Какие-то тайплевел тоже идёт нахрен.О чём речь? Где резалты выкидываются в пользу интов? Насколько я вижу, резалты вполне остаются. Или куда смотреть надо?
ncwca
07.10.2021 15:35-1О чём речь? Где резалты выкидываются в пользу интов?
Там сообщено где. В том, что показывалось как код для ядра.
О чём речь? Где резалты выкидываются в пользу интов?
Это огрызок, который ничего не значит. Проблема там не в этом. Засунуть в result можно что угодно, а далее в примере написать ?. Проблема в том как мержить типы ошибок из разных либ, разных наборов и прочее.
И да - это только начало приключений. Перепащивать везде try-позорище даже минимально не решает проблему. Потому что raii-объекты могут вкладываться друг в друга.
А далее там будет вектор, а в нём какая-то кастомная структура. А там ещё вектор, а там ещё бокс. Удачи обмазываться всё try, чтобы это хоть как-то работало.
Здесь нужно понять, что все эти try_ - это пыль в глаза неофитов, которые не понимают масштаба проблемы. Чтобы написать новые методички вида "у нас есть try_ - мы не позорище", а далее всё оставить как есть.
Starche
09.10.2021 22:25Проблема в том как мержить типы ошибок из разных либ, разных наборов и прочее.
Я на расте написал только тетрис и уже знаю, что это вообще не проблема. Просто возьмите anyhow.
там будет вектор, а в нём какая-то кастомная структура. А там ещё вектор, а там ещё бокс. Удачи обмазываться всё try, чтобы это хоть как-то работало.
Там не try надо обмазываться, а монадическими методами. Вот как в C++ появляется and_then/or_else, только в расте всего этого больше, оно плотно интегрировано в язык, и в сочетании с трейтами позволяет довольно ёмко выражать свои желания.
ncwca
10.10.2021 04:59-2Эти фанатики с нулевыми познаниями в вопросе, но которые придут и тебе расскажут, что ты не прав.
Просто возьмите anyhow.
А у вас есть понимание того, что вы только что умножили всех спорщиков на ноль и признали мою правоту? Осознайте это.
То, что вы линкуете - это dyn err, т.е. это то о чём я говорил. Что в реальном коде адепт раста будет использовать dyn err и затирать типы, тем самым умножив на ноль методичку result-адептов.
Так бывает, когда ты максимально ангажирован и когда на тебя оказывает максимальная влияние пропаганды. И ты чёрное называешь белым. Споришь с тем, приводишь то, что на самом деле опровергает твои же тезисы и тех, кого ты поддерживаешь.
Интересно. Как это повлияет на тебя, когда ты осознаешь это. Если осознаешь. Можешь в личку написать свои переживания. Я никому не расскажу - мне просто интересно.
Starche
10.10.2021 15:48Через anyhow вы типы оборачиваете, а не затираете, тип ошибки можно восстановить. Я могу согласиться, что это работает не очень удобно, поэтому есть и другой вариант.
Можно описать свой собственный большой enum с ошибками, и задать правила конвертации всех возможных в него. С такими правилами
?будет работать автоматически из библиотечных ошибок в ваши, и при этом у вас всегда перед глазами будет полный список вообще всех ошибок, которые могут вылезти.В реальных проектах как раз второй подход и используется. Например https://github.com/openethereum/openethereum/blob/main/crates/accounts/ethstore/src/error.rs
ncwca
10.10.2021 16:19Нет, anyhow именно затирает типы. Восстановить тип исключения вы тоже можете. Я не понимаю, зачем вы все пытаетесь оправдываться? Есть чёткий критерий - вы либо следуете ему, либо нет.
Можно описать свой собственный большой enum с ошибками, и задать правила конвертации всех возможных в него.
Зачем вы мне пытаетесь рассказывать то, что максимально очевидно, что максимально тупо. И самое важное это то, что этот вариант был описан мною выше.
Почему вы говорите со мною с позиции будто вы что-то знаете а я нет?
По поводу этого ахренительно решения - это полный и тотальный мусор. Во-первых с таким же успехом вы можете создать глобальный общий тип для исключений и кидать везде его. Это уже умножает все рассуждения на ноль.
Во-вторых - это подтверждает мой тезис, что изначальная системы мусор. Что никакой типизации нет. Никакого паттрн-матичинга нет. Никакого тайпсейфа нет. И вы родили то, что используется в сишке уже тысячи лет. И это максимально тупое решение.
Третье, как уже выше сказано - в данной модели мы не можем обработать какую-то ошибку выше. Она всё равно останется в типе.
Каждая функция у нас возвращает все возможные типы ошибок. Даже те, которые она никогда не кидает. Здесь сразу же ломается методички result-адептов на тему известности списка ошибок, которые кидает функция. Т.е. мы знаем типы ошибок, которые кидает что угодно, но не конкретная функция.
Как результат наш код не имеет какой-то изоляции. Мы обязаны все ошибки заносить себе. Допустим, у нас есть какая-то функция foo из одного модуля и bar из другого. Мы не можем вызвать foo из bar. Мы будем обязаны захардкодить bar за глобальный тип. Тем самым потерять любую изоляцию.
Ошибок эти может быть миллион. Да, максимально удобно смотреть на помойку из сотен ошибок. Из всей программы и из всех либ.
ncwca
10.10.2021 16:21-2При это подобные куллстори ещё кое как работали бы в C++, но в расте - примитивной скриптухи с убогой системой типов. Да и даже в рамках С++ это был бы максимальный мусор, а в расте это х10 мусор.
technic93
10.10.2021 17:51вы типы оборачиваете, а не затираете, тип ошибки можно восстановить.
Затереть тип - имеется ввиду из системы типов и из компайл-тайма - это общепринятый термин (type erasure) для С++ (мы же в комментариях под статьей про С++ правда?).
Это происходит для виртуальных методов или dyn Trait или интрефейсов. Собственно востанавливается оно через dynamic_cast(c++)/downcast(rust)/instanceof(java) соответсвенно, но уже без паттерн-матчинга.
Starche
10.10.2021 18:03Спасибо за пояснение по терминологии. Хоть это ничего и не меняет в обсуждении, но мне не помешает для общего развития
ncwca
10.10.2021 08:27-1А ещё раз объясню проблему. Всё же авось на одного человека понимающего будет больше.
result как концепция, т.е. моданы как более общий случай - взялись в стародавние времена в ФП. Очевидно, что это не было чем-то новым - индустрия этим пользовалась с момента своего зарождения, но дело не в этом.
Дак вот в фп есть фундаментальная проблема - это отсутствие такого понятия как "поток управления". фп-логика как бы плоская, ну по крайней мере так должно быть.
Именно обусловленный этой проблемой был сделан выбор в пользу монад и прочего. Хотя, на самом деле, в фп так же развились исключения как концепция. Конечно, всё было спрятано в кишки, но всё же. И result считался, да и считается хернёй.
Но мы имеем дело с сектантами. Им сказали result -и теперь они всем и себе пытаются доказать, что они не рабы. И что result - это лучше из лучше.
Дак вот, они, конечно же не будут ссылаться на реальные и проблемы и никакие фундаментальные противоречия в ФП. Поэтому им спущена только одна методичка - это "тайплевел-безопасность".
Т.е. если выбрасывая исключения мы не знаем то, какой тип там был. То используя result - мы это как бы знаем.
Здесь есть первая манипуляция. Дело в том, что все фп-язык - это позорная скриптуха. Там гц и rtti.
Допустим, какое-то std::exception - это не тайпсейф, а вот тоже самое для какой-нибудь скриптухи - уже нет. Типичное "это другое".
Поэтому пропагандисты часто начинают тебе рассказывать про throw 123, просто "а что будет, если ты не написать try{}catch" и прочее. Очевидно, что это полнейшая чушь. Потому что throw 123 никто не использует без знания того, что делает. А забыть try{}catch блок невозможно.
Т.е. перед тем, как спорить на эту тему - ты должен потребовать сектанта доказать, что каждый его тип закрыт. Допустим, какой-нибудь тайпкласс не является закрытым типом. Является тем же самым std::exception. Здесь расчёт идёт на то, что мало кому интересна маргинальная скриптуха и никто разбираться не будет что там.
Дак вот, то на что ты ссылаешься - это именно открытый тип. А именно открытые типы в исключениях и хейтит пропаганда.
Так же, пропагандисты попытаются тебе внушать что-то типа "там открытый тип потому что не осилили. Потому что слабая система типов" и прочая бездарная чушь. Всё это не имеет никакого отношения к реальности.
Дело в том, что закрытые имеют множество проблем. И именно из-за этих проблем их не используют в исключениях, а не по тем причинам, которые тебе пытаются впарить пропагандисты.
Именно поэтому ты в расте пошёл и используй result взял открытый тип. Хотя исключений у тебя нет. "слабой системы типов" нет.
result на закрытых типах требует максимально убого пердолинга. Либо действительно мощной системы типов. В скриптухах её, очевидно, нет.
Но никто не мешает добавить весь этот пердолинг в исключения. И много где это добавлено. В той же жава, свифте и прочих. Даже в C++ были зачатки этого. Но т.к. это максимально неюзабельное дерьмо - его выпилили.
Поэтому сама постановка вопроса неправильная. Она не имеет смысла, потому что типизация никак не зависит от наличия/отсутствия исключений. А нет её в исключений потому, что они более мощные. И статически подобное нигде не типизируется.
Так же нужно ещё понимать разницу между индустриальными языками и сектантскими. Сектант готов мириться с чем угодно ради своей веры. Он будет тебе врать, усираться. Он будет сам везде использовать открытые типы, но доказывать другое. Либо он будет страдать, но доказывать остальные обратное.
Индустрия же так не работает. Здесь всё обусловлено эффективностью. Если что-то создаёт проблем больше, чем решает - это не используют. Именно поэтому здесь нет того дерьма, что сектанты тебе будут выдавать за ахренительные фичи.
Starche
10.10.2021 16:10Индустрия же так не работает. Здесь всё обусловлено эффективностью. Если что-то создаёт проблем больше, чем решает - это не используют.
В принципе этого тезиса достаточно. Добавлю, что эффективность это что-то среднее между "удобством программиста" и "количеством багов". Остальное же, о чём вы говорите - это субъективные рассуждения об удобстве, только почему-то ваше удобство - оно правильное, а удобство остальных - это фанатизм и методички.
За сим раскланиваюсь, у меня нет цели вас переубедить, я лишь оставил пару комментов о реальных, а не выдуманных вами возможностях работы с ошибками для тех, кто возможно доберётся сюда почитать
0xd34df00d
10.10.2021 20:08+3Дак вот, они, конечно же не будут ссылаться на реальные и проблемы и никакие фундаментальные противоречия в ФП.
Ну так раскройте нам всем глаза, наконец, сошлитесь на эти фундаментальные противоречия в ФП.
Там гц и rtti.
Про раст не знаю, а в хаскеле нет rtti (только если вы явно не попросите через
deriving (Data, Typeable)и прочие подобные вещи).Поэтому пропагандисты часто начинают тебе рассказывать про throw 123, просто "а что будет, если ты не написать try{}catch" и прочее. Очевидно, что это полнейшая чушь. Потому что throw 123 никто не использует без знания того, что делает.
Но ведь вы не знаете, что делаете, не знаете, как работают исключения, за которые вы тут агитируете, но при этом пишете
throw 123и другим предлагаете.А забыть try{}catch блок невозможно.
Ага, компилятор небось ругнётся?
ncwca
07.10.2021 01:15-2Вы видимо никогда не писали глубоко шаблонный код, когда хочешь-не-хочешь, а поддерживать очередной новый вид функции всё равно придётся.
Примеры написанного вами "глубого шаблонного кода" посмотерь можно? Который что-то там поддерживает.
Если вам так хочется всё взять сломать и построить дивный новый мир
Он уже сломан и он уже строится.
Если умы "последователей нового" настолько слабенькие, что их ломает груз легаси, то почему они пишут не на js?
Каким образом к тебе относится слабость? Есть предел для человека, когда он готов терпеть мусор, а когда нет. Со слабостью это никак не связано. Наоборот. Чем более слабый человек - тем больше мусора он может терпеть.
И да, они уже пишут на С++.
MooNDeaR
06.10.2021 10:20Почитал про deducing this. Просто мечта хозяйки. Как давно я чего-то такого ждал. Какая же дичь писать все эти &, const& и пр. ПОСЛЕ объявления семантики метода. Тот кто это придумал был знатный наркоман.
eao197
06.10.2021 19:52+1"Deducing this" - позволяет писать функции с шаблонным this.
Решаются важные проблемы. Но решаются так, что складывается впечатление, что новых важных проблем добавляют не меньше. По крайней мере я в корне не согласен с оптимизмом авторов предложения о том, что не ожидается сложностей с обучением этой фичи.
Если не браться решать сразу кучу проблем (т.е. и избежания дублирования при перегрузках методов, и ковариантности* возвращаемого значения (случай с CRTP), и рекурсивных лямбд), то более читабельным выглядел бы такой подход (для примера с builder pattern):
struct builder { decltype(*this) a() auto(this) { ...; return *this; } decltype(*this) b() auto(this) { ...; return *this; } ... }; struct special : builder { decltype(*this) d() auto(this) { ...; return *this; } ... };По крайней мере здесь разные куски отвечают за решение разных проблем:
decltype(*this) говорит о том, что нам нужна ковариантность возвращаемого значения;
auto(this) говорит о том, что автоматически нужно выводить метод для &, const &, && и const &&.
У меня лично такой подход вызвал бы гораздо меньше сомнений в том что a) я сам это лучше пойму и b) что смогу кому-нибудь внятно объяснить что это и зачем.
Но авторы предложения явно гораздо умнее и меня и подавляющего большинства пользователей C++, поэтому они исходят из своего представления о простоте.
* вроде бы с термином не ошибся, смысл в том, что метод может вернуть ссылку на производный тип.
eao197
07.10.2021 13:27Ну или как альтернативный вариант, который позволяет делать разные перегрузки для иммутабельных и мутабельных методов:
class params { int limit_; ... public: // Иммутабельный геттер. [[nodiscard]] int limit() for(const &, const &&) noexcept { return limit_; } // Мутабельный сеттер. Может использоваться если params // применяется в стиле builder pattern. decltype(*this) limit(int v) for(&,&&) { if(v < -10 || v > 40) throw std::invalid_argument{...}; limit_ = v; return *this; } };TargetSan
07.10.2021 14:37+3С моей скромной т.з. стоило тогда уж озаботиться нормальными extension methods. Это бы решило и кейз deducing this, и столь желаемый многими (мной тоже, не скрою) UFCS.
eao197
07.10.2021 14:42С моей скромной т.з. стоило тогда уж озаботиться нормальными extension methods.
Очень может быть.
antoshkka Автор
07.10.2021 16:06UFCS на паузе
Если знаете как оживить предложение или у вас есть альтернативный подход, позволяющий достичь схожего результата - пожалуйста расскажите о нём.
TargetSan
08.10.2021 13:44-1Подскажите пожалуйста, а есть где-то в природе up-to-date собрание текущих пропозалов по этой теме и обсуждений по ним? Особенно хотелось бы почитать обсуждения. Потому что мне известны только оригинальный пропозал с симметричным UFCS (за авторством, кажется, Страуструпа) и более простой асимметричный.

oficsu
09.10.2021 00:33+1Есть репозиторий на github, но там не полное собрание, кажется. И единственное из обсуждений, что там можно увидеть — результаты голосований по некоторым возникающим вопросам
По UFCS, насколько я помню, сейчас все сдались, не найдя способов реализации без слома большей части существующей мировой кодовой базы и в моду начало входить использование свободных функций и функциональных объектов вместо методов. Например, какой-нибудь условныйstd::ranges::beginсам может разобраться, привести массив к указателю, вызватьa.begin()илиbegin(a)
eao197
09.10.2021 14:04+1В процессе разговора подумалось, что не обязательно даже ключевое слово for использовать. Можно просто квалификаторы через запятую перечислять:
class params { int limit_; ... public: // Иммутабельный геттер. [[nodiscard]] int limit() const &, const && noexcept { return limit_; } // Мутабельный сеттер. Может использоваться если params // применяется в стиле builder pattern. decltype(*this) limit(int v) &, && { if(v < -10 || v > 40) throw std::invalid_argument{...}; limit_ = v; return *this; } };
oficsu
07.10.2021 22:48-1то более читабельным выглядел бы такой подход
Я бы поспорил о его читаемости, но это неконструктивно. Давайте посмотрим на проблему с другой стороны
Вы считаете, что стоит решить одну проблему, не усложняя излишне семантику языка. Но обратите внимание, как для решения единственной узкой проблемы, вы добавили/изменили целую пачку языковых правил, добавив очередные исключения в то, как мы понимаем код: добавилосьauto(this), но что важнее —decltype(*this). Если я верно понял ход ваших мыслей, то итоговый тип может быть&/const&/&&/const&&/… Раньше в языке не было примеров, чтобы разыменованный указатель был отличен от lvalue. Вы добавили новый диалект языка, который нужно помнить, но который применим в одном единственном случае. Теперь, новые программисты, знакомящиеся с C++, ради узкой задачи будут вынуждены учить особые магические правила, которых и без того излишне много
А теперь представьте, что мы захотим решать более широкий круг задач, которые уже решает эта бумага. Не сомневайтесь, отсутствие инструмента рано или поздно станет болью и сообщество придёт к тому, что инструмент нужен. Мы будем добавлять по специальной, нерасширяемой конструкции на каждый чих вместо единого синтаксиса, действующего по единым правилам в соответствии с другими знакомыми нам частями языка? Как скоро язык превратится в помойку из специализированных синтаксических хаков, решающих частные задачи?
Да, универсальный подход часто сложен в дизайне и реализации, часто несёт повышенную когнитивную нагрузку, но такой подход приводит к тому, что язык становится возможно понимать, а не заучивать, единые правила позволяют это. К сожалению, не все принятые решения в C++ следовали этой идее. Мы имеем множество частных инструментов, которые рано или поздно оборачивались проблемами — например, каждый раз, когда добавляется новый вид инициализации, решается частная проблема. Каждый из них решает одну свою проблему и делает это иногда даже хорошо. Но ни один из них не решает проблему инициализации, ведь в современном C++ проблемой инициализации является её предсказуемость ¯\_(ツ)_/¯. И теперь у нас их больше двадцати видов, каждая с собственным уникальным поведением, это уже предмет шуток в сообществе
Я бы ещё хотел добавить, что не стоит C++ рассматривать как язык программирования. Пусть это и сложный, но это конструктор собственного диалекта C++, позволяющего решать именно ваши задачи. Ведь у всех задачи разные. И хороший конструктор не терпит частных решений — он должен стремиться к универсальности даже в ущерб простоте, в рамках разумного, конечноeao197
08.10.2021 07:26+1Простите мне грубость, но ваш комментарий в целом лишен смысла потому, что в нем заключено принципиально важное противоречие. И почему вы его не увидели, я не представляю.
Вы обвиняете меня в том, что я ввожу в язык новые конструкции и, по вашему, это плохо. При этом вы почему-то упускаете из вида, что:
Мы здесь критикуем предложение, которое эти самые новые конструкции в язык добавляет. Причем конструкции, которых раньше не было в принципе. Появляется новый вид "методов", который и не метод класса, и не статический метод класса. Почитайте раздел пропозала, в котором обсуждаются указатели на эти новые виды методов. Это совершенно новая сущность, которая похожа и на одно, и на второе. Но другое.
Вся история развития языка C++ -- это добавление в него новых конструкций, которых там не было. Пространства имен, исключения, шаблоны, концепты, модули, constexpr/constinit/consteval.
Так что ваш комментарий выглядит как классический ВНПЭД.
При этом вы не поняли смысла моего комментария. Он был не в том, чтобы сказать: "Да нет, в пропозале херню придумали. На самом деле вот как нужно было!"
Смысл моего комментария был: "Спасибо, конечно, что придумали решение для важных проблем. Но придуманное решение выглядит сильно так себе. И с его изучением точно будут проблемы, не нужно себя обманывать. А корень зла видится в том, что одним махом захотели решить сразу несколько проблем".
К сожалению, с C++ складывается ситуация, в которой сложно критиковать то, что получается у комитета. Т.к. люди работают на общественных началах, проделывают огромный объем работы, двигают язык вперед и снабжают всех нас новыми и полезными штуками. Ну вот, честно, рука не поднимается говорить в адрес людей, занимающихся развитием стандарта чего-то плохого.
Но, имхо, сложность языка уже превышает возможности большей половины действующих программистов на C++. И если мне, который пользуется C++ уже почти 30 лет, еще хоть как-то удавалось до недавнего времени более-менее осваивать новое (за счет того, что при выходе нового стандарта нужно заучить относительно небольшую дельту нового), да и то с каждым новым стандартом это все сложнее и сложнее... А вот как учить современному C++ новичков с нуля... Не представляю. Особенно людей, для которых важнее их предметная область, а не особенности C++.
Так что, опять же, имхо, в C++ уже пора начать говорить: "Ну, OK. Очень круто получилось. Но настолько сложно, что ну его на..."
что язык становится возможно понимать, а не заучивать
Я вот нихера не понимаю, почему где-то нужно std::move(x) и без указания типа x. А где-то нужно std::forward<A>(x). Пришлось просто заучить.
oficsu
08.10.2021 23:50Вы обвиняете меня в том, что я ввожу в язык новые конструкции и, по вашему, это плохо
Нет, не совсем. Вы в своём примере вводите много языковых конструкций, имеющих собственную логику (кажется, уместнее рассмотреть это под вашим следующим сообщением), отличную от всего остального языка, но решающих минимальный набор проблем. Теперь представьте, что нам потребуется решать больше проблем (те, которые решаются в предложении). Мы будем добавлять больше частных фич, отличных от остального языка и не взаимодействующих друг с другом, получая экспоненциальный рост числа фич? Выучить это определённо будет невозможно (это уже сложно, ведь так?)
В то же время, автор предложения вводит одну новую языковую конструкцию (thisна месте концепта) и решает этим целый ряд задач, полностью переиспользуя существующую логику forwarding references — мы по тому же принципу работаем с любыми другими параметрами функции. Наоборот, до этого момента была специальная конструкция для перегрузки поthis, которая с этим предложением может стать менее распространённой, а позже и вовсе исчезнуть, пусть и спустя долгое время
Да, я видел предложение и видел, что автор предлагает указатель на такой метод считать указателем на свободную функцию. Меня это несколько смущает, но, кажется, что за этим стоит довольно убедительная мотивация — это даёт больше возможностей и с таким указателем проще работать, поэтому я готов на такой компромиссСмысл моего комментария был… А корень зла видится в том, что одним махом захотели решить сразу несколько проблем
Да нет, я понял смысл вашего комментария. Однако вы рассматриваете одно конкретное предложение, теряя из виду дизайн и консистентность языка в целом
То, что одним этим предложением удачно решаются ещё несколько проблем без дополнительных ухищрений и сами собой — на мой взгляд, наоборот, говорит об удачности решения. Конечно же, автор бумаги мог бы намеренно прописать дополнительные условия, препятствующие решениям таких задач. Но рано или поздно этого бы захотелось ещё кому-то и требования всё-равно ослабили бы
Как я уже указал, дизайн языка нужно разрабатывать так, чтобы язык можно было меньше учить и больше понимать — он должен иметь больше похожих и знакомых для программиста конструкций и механизмов, ведь частные решения, как я указал выше, невозможно понять (на то они и частные) и при большом их числе — невозможно выучитьНо, имхо, сложность языка уже превышает возможности большей половины действующих программистов на C++
Да, именно поэтому в последнее время принимается всё больше и больше решений, упрощающих повседневное использование языка. Да, при этом комитет обычно не может убрать более сложные конструкции, которые уже есть — часть из них являются фундаментальными основами языка, часть из них просто трудно удалить из соображений совместимости
Но благодаря этим изменениям, для среднего C++ программиста, работающего с новым кодом сложность как раз падает — не нужно гадать, как правильно написать цикл с итераторами — у нас есть range-based loop, вместо написания структуры для одного конкретного случая у нас есть лямбды, сautoи structured bindings не нужно копипастить длинные и непонятные типы (неправильное указание которых либо приведёт к лишним копированиям, либо сгенерирует тонну непонятных сообщений об ошибке), сconstexpr ifможно выбросить целые перегрузки функций без гадания, как написать мистическийenable_if, spaceship operator позволяет уменьшить копипасту в 6 раз, корутины позволяют избавиться от тонны лапши в коде, концепты позволяют не гадать, как организовать SFINAE на перегрузке функции одновременно с этим повышая выразительность кодаА вот как учить современному C++ новичков с нуля… Не представляю
Я начал знакомство с языком где-то после 14 стандарта. С тех пор вышел сравнительно небольшой по объему C++17 и очень большой C++20. Изучение языка на тот момент не оказалось значительно трудным. Какое-то время ушло на то, чтобы в целом понять форвард семантику, и пришлось приложить немало усилий, чтобы понять корутины в целом. Многие вещи из области метапрограммирования на шаблонах изучались довольно быстро и с интересом. Но новичку это даже не требуется. Практика показывает, что и среднестатистическому опытному C++ программисту это не требуется
Так что как для новичка, больше ничего из синтаксиса и механик C++ у меня не вызвало серьёзных сложностей. Трудности обычно возникают при решении прикладных задач или с написанием хорошего кода. Но в последнем C++ не уникален и, наоборот, старается решать эти проблемы постепенноОсобенно людей, для которых важнее их предметная область, а не особенности C++
Полагаю, в тех случаях, когда используется C++, предметная область уже сложна сама по себе, C++ ситуацию усугубляет не столь сильно, как вам кажется. Опять же, значительная часть сложности скрывается за удобными интерфейсами различных библиотек. Да, эти библиотеки писать не просто — сложные вещи всегда делать не простоЯ вот нихера не понимаю, почему где-то нужно std::move(x) и без указания типа x. А где-то нужно std::forward<A>(x). Пришлось просто заучить
Нужно просто понимать, чтоstd::moveбезусловно приведёт свой аргумент к rvalue заставив при копировании вызвать оператор перемещения, а не копирования. Это нужно когда вы хотите переместить значение, никакой мистики
Аstd::forwardсделаетstatic_cast<A&&>(a). Обратите внимание,Aможет содержать в себе иconstи/или&), поэтому здесь сработает сжатие ссылок и это не каст к rvalue, как в предыдущем случае. Так что это выражение скаститaлибо к lvalue, либо к rvalue в зависимости от его реального типа. Можно записать и иначе —static_cast<decltype(a)>(a). Согласитесь, с последней формой записи вся мистика пропала из выражения? Это нужно в том случае, когда вы не знаете реальный типa, чтобы принять решение о том, должны ли мы переместить или только скопировать объект
Рекомендую ознакомиться с этой серией статейTargetSan
09.10.2021 00:38-1Это нужно в том случае, когда вы не знаете реальный тип
a,Не совсем верно. Это нужно потому, что любое именованное значение автоматом передаётся как lvalue, даже если это rvalue reference. А вот результат функции ни к чему не приводится. Таким образом, применение функции-прокладки std::forward позволяет обойти это ограничение системы типов.
oficsu
09.10.2021 00:59Да, и это тоже. Если честно, я не захотел поднимать эту тему, чтобы не рыться в источниках ради поиска исходной мотивации именно такой семантики потому что я сам не уверен, что понимаю её причины, но всё же подозреваю, что такое поведение появилось не на ровном месте
TargetSan
09.10.2021 01:39-1Судя по https://en.cppreference.com/w/c/language/value_category, это наследие С.
0xd34df00d
09.10.2021 01:21+1Да, добавляется сахар, который экономит ресурс клавиатуры, но понимания он требует столько же.
Но благодаря этим изменениям, для среднего C++ программиста, работающего с новым кодом сложность как раз падает — не нужно гадать, как правильно написать цикл с итераторами — у нас есть range-based loop
Нужно — не забывайте, что менять контейнер во время итерации всё ещё нельзя, если это совершенно недиагностируемо компилятором инвалидирует итераторы. То есть, гадать, как писать циклы с итераторами, всё ещё нужно, просто для этого добавилось сахарка.
с auto и structured bindings не нужно копипастить длинные и непонятные типы (неправильное указание которых либо приведёт к лишним копированиям, либо сгенерирует тонну непонятных сообщений об ошибке)
При этом надо понимать, как работает вывод типов для auto, чтобы аналогично не было лишних копирований.
Для structured bindings тоже надо понимать, что именно значитconst auto&вconst auto& [a, b, c] = ..., и чем они отличаются от обычных переменных (нельзя захватывать в лямбды, например).с constexpr if можно выбросить целые перегрузки функций без гадания, как написать мистический enable_if, spaceship operator позволяет уменьшить копипасту в 6 раз, корутины позволяют избавиться от тонны лапши в коде, концепты позволяют не гадать, как организовать SFINAE на перегрузке функции одновременно с этим повышая выразительность кода
Я бы сказал, что средний C++-программист не обмазывается
if constexprи концептами.oficsu
09.10.2021 07:33+1Нужно — не забывайте, что менять контейнер во время итерации всё ещё нельзя
Итераторы всё же являются довольно глубокой концепцией, и на первых шагах знакомства с C++ проще запомнить магическую конструкциюfor(auto&& v: vec)с запретом на модификацию контейнера, чем постигнуть всю философию итераторов в теории и на практике. Так что я всё ещё считаю, что эта конструкция снижает порог входаи чем они отличаются от обычных переменных (нельзя захватывать в лямбды, например)
К счастью, это недоразумение починили в C++20Я бы сказал, что средний C++-программист не обмазывается if constexpr и концептами.
А вот читать их ему в какой-то момент после ошибки компиляции придётся и концепты здесь немного, но будут легче в понимании в сравнении с экзотическими конструкциями на SFINAE
technic93
09.10.2021 06:06Я сам иногда с этим форвард путаюсь, но если сделать
static_cast<decltype(a)>(a)то это ничего не даст, наверное вы хотели тут написать std::forward.oficsu
09.10.2021 06:30+1Нет, я не хотел написать
std::forward, выражениеaпринципиально отличается отstatic_cast<decltype(a)>(a)с точки зрения языка, вот пример того, как эта конструкция меняет поведение программыtechnic93
09.10.2021 13:08Точно, я перепутал ситуацию когда имеем
template<typename T> auto f(T&& t) { g(std::forward<T>(t)); }Тут у
Tбудет тип без rvalue ссылки, иforwardеё добавит. Но вdecltypeтип ссылки действительно всегда остаётся.
eao197
09.10.2021 07:38Вы в своём примере вводите много языковых конструкций, имеющих собственную логику (кажется, уместнее рассмотреть это под вашим следующим сообщением)
Две, если быть точным. И не новые конструкции, а возможность использовать уже существующие конструкции в новых местах.
Ничуть не хуже, чем объяснять человеку, в чем разница между двумя этими шаблонными методами:
struct demo { template<typename T> auto f(T a, int b, int c) {...} template<typename T> auto g(this T a, int b, int c) {...} };Это же так привычно, что у нас this появляется уже не в теле метода, а в списке формальных параметров. И обязательно первым (а почему только первым? Апатамушта). И что у нас для g три формальных параметра, а по факту внутри их всего два. И что раньше у нас this был указателем на объект, для которого метод вызван, а сейчас это может быть уже и указателем на копию объекта (т.е. по факту у нас еще и неявное копирование, а C++ же так давно не обвиняли в том, что в нем слишком много происходит "под капотом"). И что в итоге у нас f и g -- это вроде как методы demo, но указатели на них разные. Ну логично же и привычно.
Я вот вас читаю и прямо истинно верую, что все это понять и
проститьзапомнить гораздо проще, чем понять смысл decltype(*this) на месте типа возвращаемого значения или for(const &, const &&) после списка формальных аргументов.Вас, кстати, не смутило, что теперь в C++ можно [[nodiscard]] перед типом возвращаемого значения записывать? Ведь новый элемент языка же сделали, которого раньше не было.
В общем, если это не классическое ВНПЭД, то уж не знаю, что это.
Мы будем добавлять больше частных фич, отличных от остального языка и не взаимодействующих друг с другом, получая экспоненциальный рост числа фич?
На мой взгляд, нужно искать компромисс: что-то должно решаться введением новых элементов языка (типа атрибутов, fold expression или range-based for), что-то может быть получено переиспользованием существующих элементов. Конкретно в случае deducing this решение получилось крайне спорным.
концепты позволяют не гадать, как организовать SFINAE на перегрузке функции одновременно с этим повышая выразительность кода
Вот да, упоминание SFINAE как раз к месту. Это же яркий пример того, как одним механизмом пытались решить сразу несколько проблем. Как вам результат, не заляпались?
Я начал знакомство с языком где-то после 14 стандарта. С тех пор вышел сравнительно небольшой по объему C++17 и очень большой C++20. Изучение языка на тот момент не оказалось значительно трудным.
Вот это отрадно, возможно, в своих предположениях я слишком пессиместичен.
Нужно просто понимать, что
std::moveСудя по дальнейшему обсуждению этой темы ниже в комментариях, у вас самого с пониманием сложности.
Но проблема в не в этом. Образно говоря, ситуация такая, что для входа на кухню нужно сделать сальто вперед с разбегом в два шага. И вы стараетесь мне объяснить, почему именно сальто вперед и почему именно два шага, а не с места или с трех шагов. Ведь очень же важно понимать глубинные причины, ведь сальто же не просто так, были же причины.
Тогда как меня не интересует все это, если перед входом на кухню нужно сальто, ну OK, заучу и доведу до автоматизма.
Но ключевой вопрос в том: а почему нельзя просто взять и зайти?
Возвращаясь к C++: по большому счету мне фиолетово, почему потребовалось делать move и forward функциями стандартной библиотеки и что именно у них внутри. Есть необходимость сделать forwarding, значит здесь нужен forward. Если необходимость переместить объект, значит здесь нужен move. И я бы хотел иметь просто forward и move, без необходимости разбираться с (A&& -> A&) и прочей лабудой.
oficsu
09.10.2021 09:23-1Ничуть не хуже, чем объяснять человеку, в чем разница между двумя этими шаблонными методами
Считаете ли вы, что объяснить function ref-qualifiers или шаблоны просто (здесь я в том числе подразумеваю forwarding references)? А если программист знаком с последними, то в чём конкретно состоит сложность объяснения разницы между этими двумя шаблонами? Я вижу относительную сложность только в том, что вTможет оказаться тип-наследник. Но то, что в шаблоне может оказаться совершенно неожиданный тип не должно удивлять того, кто знаком с шаблонами — всё как с обычными параметрами функцииа почему только первым?
Потому что это привычная многим программистам концепция. Возьмите для примера Python, гдеselfтоже первыйИ что у нас для g три формальных параметра, а по факту внутри их всего два
Я вижу три, не подскажите, в чём я заблуждаюсь?
И даже наоборот, это сейчас нужно вдаваться в подробности и объяснять, чтоthisу нас является неявным параметром, который не указан, но он есть — просто запомните, что здесь не как у обычных функцийможет быть уже и указателем на копию объекта
Не может. Условныйselfможет быть копией объекта. Да, как и любой обычный параметр функцииИ что в итоге у нас f и g — это вроде как методы demo, но указатели на них разные
Да, методы, но уfкакой-то очень странный и сложно устроенный указатель, а уg— самая обычная функция. Последнее привычнее и удобнее в использовании, не правда ли?Вас, кстати, не смутило, что теперь в C++ можно [[nodiscard]]
Нет, не смутило. Во-первых, это совершенно новая концепция в языке, существующая до этого только в implementation-defined виде. Не удивительно что её синтаксис особенный. А ещё не смутило ввиду убедительной мотивации от авторов предложения. И заметьте, в сущности, это одна фича, решающая ряд проблем, чем не может похвастаться ваш примерНа мой взгляд, нужно искать компромисс
И, кажется, эта бумага и является компромиссом. Мы получили более простой вид методов, ведущих себя как обычные функции, но и при том лишённые возможности быть объявленными как виртуальныечто-то должно решаться введением новых элементов языка (типа атрибутов, fold expression или range-based for)
Вы апеллируете к тому, что fold expression и range-based for были новыми элементами, но обратите внимание, что fold expression похож по своей семантике на pack expansion, а значит привычен пользователю, range-based for похож не только наfor, но и наfor inиз других языков, что тоже упрощает вход. Deducing this тоже похож — во первых, на другие языки, во-вторых, на собственные же свободные функции. А на что похож ваш пример? Какой опыт программисту упростит понимание вашего примера?Вот да, упоминание SFINAE как раз к месту. Это же яркий пример того, как одним механизмом пытались решить сразу несколько проблем
Вот только дело в том, что… нет, не пытались, это получилось случайно и случайно открытые мощные возможности SFINAE оказались востребованными у программистов. Но исходная мотивация такого поведения была несколько проще и решалась иная проблема, а потому я считаю это сравнение неудачным и воздержусь от его комментированияСудя по дальнейшему обсуждению этой темы ниже в комментариях, у вас самого с пониманием сложности.
В таком случае, прошу указать мне на конкретные проблемы с пониманием, чтобы я мог счесть этот аргументом убедительным, а не argumentum ad hominemОбразно говоря, ситуация такая, что для входа на кухню нужно сделать сальто вперед с разбегом в два шага
Я предпочту отказаться от комментирования аналогий. Они красивы, ярки, но мой опыт дискуссий показывает, что такой спор очень быстро перестаёт быть конструктивным и перетекает в область бесконечного спора о корректности самих аналогий и терминов, а не по существуИ я бы хотел иметь просто forward и move, без необходимости разбираться с (A&& -> A&) и прочей лабудой.
Не пробовали оставить идею на stdcpp.ru и получить фидбек? Быть может, мы получим желаемое вами поведение уже в следующем стандарте?eao197
09.10.2021 10:05+1Считаете ли вы, что объяснить function ref-qualifiers или шаблоны просто (здесь я в том числе подразумеваю forwarding references)?
Не уверен, что понял вопрос. Объяснять ref-qualifiers не просто. Объяснять людям шаблоны не просто.
А если программист знаком с последними, то в чём конкретно состоит сложность объяснения разницы между этими двумя шаблонами?
В том, что эта разница внезапно появилась. Ее не было, а тут хоба! И принципиально новая фича, которая нужна, образно, в 10% случаев. Но знать про нее придется всем. Более того, как уже замечали в комментариях, теперь перед любым разработчиком встанет выбор: когда нужно написать шаблонный метод класса, то в каком синтаксисе это делать и почему?
Потому что это привычная многим программистам концепция.
В C++ до сих пор этой концепции, к счастью, не было. К несчастью, она теперь появляется. А обоснование: апатамушта. Патамушта авторы пропозала умнее 90% рядовых пользователей языка и им сложно понять как кто-то не может понять таких простых вещей.
Возьмите для примера Python, где
selfтоже первыйВозьмем. Редкое говно. По ряду причин, в том числе и из-за необходимости передавать this в метод явным образом. В C++ такой херни раньше не было, и это было хорошо. Но все хорошее когда-нибудь заканчивается.
Тут можно было бы поговорить о том, почему C++ если и заимствует что-то из других языков, то делает это либо недостаточно хорошо (static if из D в виде кастрата if constexpr в C++), либо заимствует откровенную лажу (вроде self из Python), либо игнорирует уже проверенные решения (типа рефлексии и текстовых mixin-ов из D, или let rec из OCaml-а (может быть такой маркер решил бы проблему рекурсивных лямбд проще?)). Но это будет уже слишком.
Я вижу три, не подскажите, в чём я заблуждаюсь?
В том, что видите три. Их два.
И даже наоборот, это сейчас нужно вдаваться в подробности и объяснять, что
thisу нас является неявным параметром, который не указан, но он есть — просто запомните, что здесь не как у обычных функцийНаличие неявного this -- это фундаментальная фича языка. С нее начинается изучение ООП в C++. Если человек не может освоить this, то это из той же категории, как неспособность освоить указатели или понять чем ссылка отличается от указателя (кстати, такие люди все еще используют C++).
И вот это самую фундаментальную особенность C++ теперь отводят в сторону и говорят: кроме неявного this нам теперь нужен еще и явный. Просто потому, что мы придумали, как одной новой фичей закрыть сразу несколько проблем, которые были актуальны для 10% пользователей языка.
Да, методы, но у
fкакой-то очень странный и сложно устроенный указатель, а уg— самая обычная функция. Последнее привычнее и удобнее в использовании, не правда ли?Не правда. В C++ уже есть устоявшееся понятие -- указатель на функцию-член. И уже давно всем привычно, что это не тоже самое, что указатель на функцию. И уже давно все привыкли к тому, какой код нужно написать для работы с указателями на функции-члены.
А теперь у нас появляется еще один тип указателя на функцию-член. Но он не такой, как предыдущий. Он почти что указатель на обычную функцию. Но все-таки указатель на функцию-член.
Зоопарк разных сущностей в C++ еще недостаточно полон, этот пробел нужно устранить.
Нет, не смутило.
Ok, ВНПЭД.
И, кажется, эта бумага и является компромиссом.
Если не ошибаюсь, тут уже несколько человек высказалось в духе, что получилось как-то слишком уж мудрено. И мой поинт в том, что C++ достиг такой стадии развития, когда к подобным высказыванием стоит относиться не как к жалобам старпёров-ниасиляторов, а как к предупреждению о том, что C++ повторяет путь PL/1.
Вы апеллируете к тому, что fold expression и range-based for были новыми элементами, но обратите внимание
Обратите внимание, что вы согласны принимать новые элементы, когда это нравится вам.
Deducing this тоже похож — во первых, на другие языки, во-вторых, на собственные же свободные функции.
Похожесть на другие языки -- так себе аргумент, т.к. мы говорим во что превращается C++, а не другие языки. Если кому-то хочется превратить C++ в Python, то нет проблем. Но не удивляйтесь когда вам прямо скажут: да ну нах это говно.
Во-вторых, похоже-то оно похоже, но вот свободной функцией не является. Это метод, но другой. И тут рекурсия на зоопарк, который еще недостаточно полон.
Я предпочту отказаться от комментирования аналогий.
Подозреваю, что вы просто не поняли о чем идет речь.
Судя по этому слишком длинному обсуждению вы таки не поняли в чем была суть. Поэтому повторю еще раз, другими словами: добавление подобных неоднозначных фич в язык неизбежно будет вести к увеличению количества недовольных текущим путем развития языка. А посему неплохо было бы новые фичи, которые хотят добавить в язык, оценивать гораздо более жестко, чем это происходит сейчас.
Пожалуй, на этом можно и закончить. Нет смысла заходить на очередной круг.
oficsu
09.10.2021 11:11-1Не уверен, что понял вопрос. Объяснять ref-qualifiers не просто. Объяснять людям шаблоны не просто.
Верно, потому что они не только сами по себе сложны, но ещё и решают сложную задачу — perfect forwarding
Поэтому, когда вы пробуете заявить, что новая конструкция сложна — её сложность не стоит оценивать в отрыве от решаемой задачи. Объяснить вышеуказанную конструкцию совсем не сложно в контексте forwarding references, которые пользователю ещё раньше встретятся в контексте perfect forwarding
В то же время, ваше предложение потребует весь тот же набор знаний на входе, но не сможет их использовать, как основу для формирования новых знаний ввиду того, что создаёт новые специфичные конструкцииВ том, что эта разница внезапно появилась. Ее не было, а тут хоба! И принципиально новая фича, которая нужна, образно, в 10% случаев
А теперь сравните это с ref-qualifiers или своим примером, где при рассмотрении разница точно так же появляется, но в значительно больших объемах и/или с совершенно отличными синтаксическими конструкциями без обоснования, зачем они нужны
Если вша позиция выражается в «оставить только ref-qualifiers потому что я не хочу дополнительно переучиваться на новый, хоть и более консистентный с языком механизм» — с такой позицией ничего нового добавлять в язык и не нужно вовсе. Понимаю такую точку зрения, но вы лично всегда можете остаться на устаревшей версии языка, а не задерживать его развитиеНаличие неявного this — это фундаментальная фича языка
Нет, это просто особенность дизайна, которую поставили под сомнение в данном предложении. А теперь и в стандартеС нее начинается изучение ООП в C++
Вместе с предыдущим предложением и далее — argumentum ad antiquitatem, вы не можете взять произвольную логическую уловку и использовать её как аргументкоторые были актуальны для 10% пользователей языка.
Вам не кажется, что 10% программистов на C++ — это крайне внушительное число? А с учётом того, что код именно этих программистов в конечном итоге обычно будет вызываться из программ рядовых программистов — это куда более значимая часть сообщества и проблемыOk, ВНПЭД.
Я попрошу аргументировать по существу, поскольку я постарался дать максимально убедительную аргументацию, почему этот случай мной интерпретируется иначе. Если вы не согласны с аргументацией — укажите на ошибки в нейОбратите внимание, что вы согласны принимать новые элементы, когда это нравится вам.
Они мне нравятся, когда используют понятные и уже знакомые программистам механизмы из этого или других языков, или даже расширяют их, снижая тем самым порог входа. Так же, я готов принять новые конструкции, если они фундаментально меняют взаимодействие с языком (лямбды, концепты, модули, spaceship operator) или имеют совершенно новую семантику (атрибуты)Похожесть на другие языки — так себе аргумент, т.к. мы говорим во что превращается C++, а не другие языки
Дизайн языка — сложная задача, и бежать, не оглядываясь на существующие практики и на реальность (популярность решений в других языках) глупо. Если вы хотите создать сложный язык, затрудняющий переход на него ещё и опытным программистам других языков — ваше право, но не удивляйтесь, если на него откажутся переходить новые программисты из соседних сфер и он превратится постепенно в COBOL из-за отсутствия развитиядобавление подобных неоднозначных фич в язык неизбежно будет вести к увеличению количества недовольных текущим путем развития языка
Насколько я могу судить, у нас всего три возможных варианта, каждый со своими преимуществами и недостатками:- не добавлять фичи — можно, но вы постепенно растеряете тех участников языка, которые создают значимую часть библиотек для остальной части пользователей, я не рассматриваю это как вариант, который можно выбрать, поэтому не вижу смысла в вашей апелляции к этому невозможному варианту;
- добавлять более простые фичи — на вашем примере это оказалось неудачным подходом, имеющим значительные недостатки, что я и пытался донести выше, я открыт к обсуждению этого варианта, но пока что не увидел убедительных аргументов в его пользу от вас;
- добавлять такие фичи — вы верно указали на некоторые недостатки подхода, но предыдущие два пункта не являются адекватной его альтернативой
А посему неплохо было бы новые фичи, которые хотят добавить в язык, оценивать гораздо более жестко, чем это происходит сейчас
Стоит заметить, что такие фичи и рассматривают довольно жёстко, некоторые из них не принимаются десятилетиями, многократно упрощаясь перед попаданием в стандарт языка. Просто, вероятно, не является эта фича на взгляд комитета неудачной, как считаете вы
eao197
09.10.2021 11:38+1Придется разбить ответ на несколько комментариев.
Объяснить вышеуказанную конструкцию совсем не сложно в контексте forwarding references, которые пользователю ещё раньше встретятся в контексте perfect forwarding
В большинстве сценариев использования языка пользователю не нужны ни forwarding references, ни perfect forwarding. Для многих сами эти понятия -- это уже матан какой-то.
Я бы предпочел язык, который действительно делает простые вещи простыми, а сложные возможными. Но не так, как это на протяжении многих лет было в C++: простые вещи можно сделать через сложные понятия.
Например, как определить, если ли у типа метод с определенной сигнатурой? Есть ли у нас в type_traits простой инструмент типа has_method?
Вроде бы все еще нет.
В C++98 эту проверку нужно было делать вручную. Причем кодом, до которого простой смертный сам бы ни в жисть не додумался бы. В C++14 это уже сделать проще. Но все равно для многих пользователей это высший пилотаж, если пытать сделать самому, а не скопипастить откуда-то.
По поводу ref-qualified. Я не согласен с вашей точкой зрения о том, что это находится в контексте forwarding references.
Для меня все это растет из первых версий C++, в которых появилось понятие константности и стало можно передавать объекты по константной ссылке/указателю. Как раз то, что до сих пор выгодно отличает C++ от многих конкурентов.
Если у нас есть константность, то логично иметь разные методы для const- и не-const объектов. Вот и получаем первое приближение к ref-qualified.
В какой-то момент в C++ появляется понятие rvalue. Которого очень не хватало для написания лаконичного, но эффективного кода.
Но если у нас есть rvalue, то значит пространство вариантов у нас расширяется: логичным образом у нас могут быть const- и не-const-объекты, плюс временные объекты (rvalue). Следовательно, логично иметь возможность делать варианты методов для const-, не-const- и rvalue-случаев.
Однако, это ведет к взрыву количества методов, которые мы должны написать в некоторых случаях. Например, при работе с builder pattern. Типа:
class params { public: params & limit(int v) & {...} params && limit(int v) && {...} params & wait_time(seconds v) & {...} params && wait_time(seconds v) && {...} ... };Применение это находит даже без каких-либо фокусов с forwarding:
class complex_object { public: explicit complex_object(params p) {...} ... }; complex_object obj{ params{}.limit(10).wait_time(5s) };Частью этой проблемы является то, что в большинстве случаев подобные методы-сеттеры будут одинаковыми. И методы-геттеры (которые для const &, const &&) тоже.
Следовательно, нам нужно избежать написания одного и того же кода.
И тут у нас возникает дилемма. Мы можем либо явно указать, что компилятор должен сделать именно это. Отсюда и мои фантазии на счет for после списка аргументов.
Либо мы можем переиспользовать шаблоны. Ну типа шаблоны же для подобных целей. А то, что это будут уже не совсем такие шаблоны. И вообще у нас появится новый вид функций-членов.
Я бы хотел видеть использование первого подхода. Т.к. неочевидных вещей в C++ и так хватает.
И нет, я не вижу здесь никакой связи с каким-либо forwarding-ом.
oficsu
09.10.2021 12:15В большинстве сценариев использования языка пользователю не нужны ни forwarding references, ни perfect forwarding. Для многих сами эти понятия — это уже матан какой-то.
Я бы предпочел язык, который действительно делает простые вещи простыми, а сложные возможными.
Но язык и так решает сложные вещи возможными путями. Так уж случилось, что C++ оказался удачен для решения преимущественно сложных задач. А если вы хотите ещё и решать сложные проблемы просто — это очень и очень сложно. Как минимум, нужно чтобы кто-то придумал такие решение, но почему-то в них часто находятся существенные изъяны и они отклоняютсяНапример, как определить, если ли у типа метод с определенной сигнатурой? Есть ли у нас в type_traits простой инструмент типа has_method?
В C++20 это выглядит вот так:
requires (A a) { a.foo(); }И нет, я не вижу здесь никакой связи с каким-либо forwarding-ом.
Вероятно, именно в этом наш взгляд на проблему принципиально отличается. Шаблоны уже созданы, чтобы решать проблему ручной копипасты, т.е. того же, для чего вы предложили for после списка аргументов. А forwarding references уже используются для уменьшения копипасты конкретно в случаях перегрузки по константности и value category. Я думаю, что программист столкнётся раньше с проблемой написания правильного конструктора, поддерживающего копирование и перемещение, чем метода. А там он уже познакомится с forwarding references. Но по странной воле случая, для произвольного аргумента у нас есть forwarding references, а дляthisне было. Теперь будет
Я бы сказал, это не новый синтаксис из предложения какой-то особенный и привносит что-то новое, наоборот, в нём ничего нового нет, это старый дизайн языка имел особенный магический и при том ограниченный синтаксис, по умолчанию позволяющий вызвать lvalue метод на rvalue объекте, нарушая семантику операции
Просто к старой форме записи добавили более логичную, консистентную и мощную на базе уже существующего и знакомого синтаксиса
eao197
09.10.2021 12:28+1Пожалуйста, не нужно мне рассказывать для чего и как получился C++.
requires (A a) { a.foo(); }
И сколько пришлось этого ждать? Что делать тем, кто не сможет перейти на C++20 в ближайшие лет пять? Можно ли это использовать совместно с if constexpr?
Шаблоны уже созданы, чтобы решать проблему ручной копипасты, т.е. того же, для чего вы предложили for после списка аргументов.
В корне не согласен. Шаблоны нужны для написания алгоритмов, которые работают схожим образом для разных типов данных. Плюс возможность тонко настроить эти алгоритмы под конкретные типы.
Я предложил for как средство борьбы с комбинаторным взрывом, который образовался из-за появления в языке целой кучи ref-qualifiers.
И мне не нравится, когда шаблоны пытаются применить для решения другой проблемы. Просто потому что "ну мы же и так через шаблоны с копипастой боремся".
А forwarding references уже используются для уменьшения копипасты конкретно в случаях перегрузки по константности и value category.
Ага, но вы здесь путаете причину и следствие. Forwarding был предназначен для другого. Но, за неимением лучшего, его начали применять для борьбы с копипастов из-за наличия ref-qualifiers. И теперь вам начинает казаться, что ноги растут из forwarding. Но это всего лишь зашоренность на привычных вам вещах.
Просто к старой форме записи добавили более логичную, консистентную и мощную на базе уже существующего и знакомого синтаксиса
А теперь сделайте усилие и поймите, что предлагается не делать больше подобных экспериментов с C++. Потому что старое никуда не денется, но еще и нового говнеца сверху набросят. И жить придется не только с тем, к чему все привыкли, но и со всем новым.
oficsu
09.10.2021 13:09В корне не согласен. Шаблоны нужны для написания алгоритмов, которые работают схожим образом для разных типов данных. Плюс возможность тонко настроить эти алгоритмы под конкретные типы.
Но разве метод, перегруженный поthisне представляет из себя пример именно такого алгоритма?Forwarding был предназначен для другого
А не могли бы вы сделать небольшой экскурс в их историю, я сходу не смог найти их исходное предназначениеАга, но вы здесь путаете причину и следствие. Forwarding был предназначен для другого. Но, за неимением лучшего
Хорошо, я допускаю такую точку зрения, но это значит, что нам теперь нужно подходить к вопросу основательно и решать не только проблему перегрузки методов поthis, но и любых функций по произвольному из аргументов. И решение должно быть консистентно, чтобы при этом не так сильно усложнить язык. Я пока не знаком с идеей, как это должно выглядетьА теперь сделайте усилие и поймите, что предлагается не делать больше подобных экспериментов с C++
Но это только вы сочли предложение экспериментом. Автор же посчитал его вполне законченной идеей. Как скоро можно перейти от стадии эксперимента к законченной идее и принятию в стандарт?
eao197
09.10.2021 13:22Но разве метод, перегруженный по
thisне представляет из себя пример именно такого алгоритма?Нет, здесь нет разнотипных данных. Один и тот же алгоритм применяется к одним и тем же данным одного и того же типа.
А не могли бы вы сделать небольшой экскурс в их историю, я сходу не смог найти их исходное предназначение
ЕМНИП, это нужно было в шаблонах когда параметры шаблонного метода/функции/конструктора нужно было без потерь прокинуть куда-то дальше. Типа:
template<typename T> class demo { T v_; public: template<typename Y> demo(Y && y) : v_(y) // (1) {} ... };Вот в точке (1) нам и нужен forwarding.
и решать не только проблему перегрузки методов по
this, но и любых функций по произвольному из аргументовМне совершенно непонятно как одно следует из другого.
Автор же посчитал его вполне законченной идеей.
...чтобы вынести на публику. Это как писатель, который решает, что его роман закончен. Тогда как издатель запросто может решить, что еще не пришло время для публикации этого романа.
Как скоро можно перейти от стадии эксперимента к законченной идее и принятию в стандарт?
ХЗ. Вряд ли есть единый рецепт.
oficsu
09.10.2021 13:29ЕМНИП, это нужно было в шаблонах когда параметры шаблонного метода/функции/конструктора нужно было без потерь прокинуть куда-то дальше. Типа
Но ведь это и есть решаемая предложением проблема. При вызове метода наthis, нам точно так же иногда требуется внутри прокинуть неявный параметр this куда-то. То же самое, как и для обычного параметра. Отдельно пример сand_thenя уже привёл, комитет, видимо, посчитал, что таких примеров достаточноЭто как писатель, который решает, что его роман закончен. Тогда как издатель запросто может решить, что еще не пришло время для публикации этого романа
Но если верить сообщению выше, то «издатель» в лице комитета таки решил, что время «публикации» настало
eao197
09.10.2021 13:58Но ведь это и есть решаемая предложением проблема.
Во-первых, не совсем. Проблема perfect forwarding давно решена (пусть и многословно). Решается другая проблема, а именно как бороться с копипастой из-за ref-quilifires. И заодно еще несколько. Отсюда и так себе решение.
Во-вторых, возможно, проблема именно в том, что на нее смотрят как на forwarding для this.
Но если верить сообщению выше, то «издатель» в лице комитета таки решил, что время «публикации» настало
Отсюда и претензия: "издателю" стоит быть построже. А то возникает вопрос доверия к издателю.
0xd34df00d
09.10.2021 18:45+1Но язык и так решает сложные вещи возможными путями. Так уж случилось, что C++ оказался удачен для решения преимущественно сложных задач.
Не надо путать intrinsic complexity задачи со сложностью языка, одно не требует другого.
Да и с этим вашим тезисом я бы поспорил — чем C++ сегодня (а не 20 лет назад) хорош для решения сложных задач, и каких? Я не отрицаю этим утверждением, что таких задач нет, но просто сначала бы хотелось синхронизировать терминологию.
oficsu
10.10.2021 12:57Изначально я подразумевал не столько конкретные прикладные задачи, сколько создание различных DSL и фреймворков для других программистов
Мне кажется, довольно широкие возможности плюсов в этом плане одновременно с возможностью писать относительно производительный код заметно повлияли на их популярность. И было бы хорошо, будь заниматься этим ещё и просто, но мне кажется, в дизайн языка придётся вложиться несоизмеримо больше в сравнении с существующей сложностью языка
Да, сейчас есть языки, которые сумели взять на себя часть задач плюсов, при этом имея лучший языковой дизайн, но мне кажется, что в этом направлении миру ещё очень долгий путь предстоит
0xd34df00d
10.10.2021 20:17+2Только ведь на плюсах это делать максимально неудобно. DSL для парсинга — ну давайте сравним boost.spirit (или вашу либу на выбор) и любой из -parsec'ов для хаскеля. DSL для каких-нибудь параллелизуемых вычислений в терминах матриц — ну давайте сравним, ээ, да даже не знаю что на плюсах, с repa или accelerate (последнее даже вам само сгенерит код под GPU).
То есть, да, 20 лет назад плюсы были единственным языком, на котором можно было написать что-то вроде blitz++ и гордиться, что обгоняешь фортран со всеми этими expression templates. Но это было 20 лет назад.
eao197
10.10.2021 21:00+1Я подобные разговоры (с разными вариациями, но чаще всего про превосходство Haskell-я везде и во всем) регулярно слышу года с 2006, если не с 2005-го. Но пока еще не встретил ни одного человека, который бы внятно объяснил, почему Haskell все еще не вытеснил C++ вообще.
0xd34df00d
10.10.2021 21:18+2Исключительно вопрос стереотипов о языке.
Почитайте тут же статьи и комменты студентов об образовании — в половине найдёте «учат какому-то старпёрскому C++, кому он вообще сегодня нужен», в другой половине будет «переусложнённое неюзабельное гэ, вот мы перешли на гошку и счастливы».
Вот и с хаскелем так же.
0xd34df00d
10.10.2021 21:36+1Я искренне надеюсь, что через 15 лет он вообще сдохнет, и вместо него будут нормальные языки, где те же завтипы прикручены сразу, а не сбоку через 30 лет после существования языка.
eao197
09.10.2021 11:55с такой позицией ничего нового добавлять в язык и не нужно вовсе.
Во-первых, позиция не такая. Давайте добавлять новое осторожно и желательно не так, чтобы новая фича хитрым образом решала кучу разных проблем. Т.к. последствия сложно предсказать. Примеры в прошлом уже были: открытие метапрограммирования на шаблонах и SFINAE. Пора бы уже учиться на ошибках.
Понимаю такую точку зрения, но вы лично всегда можете остаться на устаревшей версии языка, а не задерживать его развитие
Во-вторых, давайте вы не будете говорить людям что им делать. Тогда людям не придется говорить куда вам следует отправиться.
Нет, это просто особенность дизайна, которую поставили под сомнение в данном предложении. А теперь и в стандарте
И с какого бодуна?
Есть же понятие эргономика, принцип наименьшего удивления и т.д. Золотое правило в программировании: "Работает? Не трогай".
Вот и this -- он есть давно, он работает, к нему все привыкли. С освоением у некоторых есть сложности, но они преодолеваемы. Но нет, давайте переделаем, давно ничего не ломали.
Вам не кажется, что 10% программистов на C++ — это крайне внушительное число?
Более того, волею судьбы я вхожу в их число. Но думаю, что мнение 10% можно пожертвовать, чтобы сделать жизнь оставшихся 90% проще. Лично я готов выписывать руками перегрузки для &, &&, const & и const &&, но не заучивать наличие еще и новых шаблонных методов.
Вот с ковариантностью возвращаемого значения все гораздо хуже :(
Я попрошу аргументировать по существу
Это невозможно. Ибо мы здесь изначально говорим о вкусовщине. Вы говорите:
Так же, я готов принять новые конструкции, если они фундаментально меняют взаимодействие с языком (лямбды, концепты, модули, spaceship operator) или имеют совершенно новую семантику (атрибуты)
Но при этом для вас for(const &, const &&) неприемлем, хотя здесь все гораздо проще, чем со spaceship operator.
Это ни что иное, как классическое "вы не понимаете".
что я и пытался донести выше
У вас не получилось.
я открыт к обсуждению этого варианта
Этого не видно. Потому что вы не можете смирится с тем, что на какие-то вещи можно смотреть по новому. Вот для вас decltype(*this) в качестве типа возвращаемого значения почему-то плотно ассоциируется с decltype(*this) в теле метода. А использование for(const &, const &&) после списка аргументов -- это неправомочное применение уже существующей конструкции.
Это какие-то догмы, которые вы не можете поставить под сомнение.
Ну и главное: нет моего варианта, это лишь наброски фантазий, которые призывают задуматься о том, что можно по другому. Но зачем же искать другое, когда уже есть то, что вы освоили и с чем смирились?
oficsu
09.10.2021 12:36Давайте добавлять новое осторожно и желательно не так, чтобы новая фича хитрым образом решала кучу разных проблем. Т.к. последствия сложно предсказать. Примеры в прошлом уже были: открытие метапрограммирования на шаблонах и SFINAE
Но SFINAE-то было фичей, решающей именно что одну задачу. И именно сейчас авторы предложения рассмотрели большее число возможных последствий, которые приходят с новой фичей и постарались их предсказать. Например, её сочетание с виртуальными методами посчитали слишком непредсказуемым на текущий момент и отложили в сторону, чтобы случайно не усугубить ситуацию. Часть же из последствий посчитали скорее полезными, чем вреднымипринцип наименьшего удивления
Но именно старое поведение нарушает его в современных реалиях, где весь код обмазан шаблонами«Работает? Не трогай»
Считаю это наименее удачным аргументом где бы то ни былоБолее того, волею судьбы я вхожу в их число. Но думаю, что мнение 10% можно пожертвовать, чтобы сделать жизнь оставшихся 90% проще. Лично я готов выписывать руками перегрузки для &, &&, const & и const &&, но не заучивать наличие еще и новых шаблонных методов.
Не могли бы вы дописать их дляstd::filesystem::path::operator string_type()? Так уж оказалось, что авторы стандартной библиотеки, в отличие от вас, не могут, не хотят или просто утомились и забылиНо при этом для вас for(const &, const &&) неприемлем, хотя здесь все гораздо проще, чем со spaceship operator
Проще как абстрактная идея в контексте C++20, но сложнее в сравнении с обсуждаемым предложением в стандартэто неправомочное применение уже существующей конструкции
Нет, это не так и точнее я аргументацию постарался выразить в вышенет моего варианта, это лишь наброски фантазий, которые призывают задуматься о том, что можно по другому
Да, можно и я указал, что часть ваших аргументов актуальна. Но я не нахожу способа сделать по другому, который был бы проще предложения, даже актуальное поведение языка, выражающее то же самое, я нахожу более сложным. И если я не могу найти, то единственное, что можете вы — помочь его поискать, но ваши наброски имеют в своей сути недостатки, на которые я и стараюсь указать в ходе диалога
eao197
09.10.2021 12:44+1Но SFINAE-то было фичей, решающей именно что одну задачу.
SFINAE было фичей? Мне всегда казалось, что это был костыль из имеющихся палок дабы не придумывать что-то нормальное.
Собственно, deducing this выглядит так же. Типа у нас тут накопилось, поэтому фекальнодендронным методом сейчас слепим решение из того, что уже имеем в языке.
Считаю это наименее удачным аргументом где бы то ни было
Ну и зря. У меня, после 30 лет в программизме, к этой народной мудрости намного больше уважения.
Не могли бы вы дописать их для
std::filesystem::path::operator string_type()?И кто за это заплатит?
И если я не могу найти, то единственное, что можете вы — помочь его поискать
Нет, не единственное. Еще можно сказать: получилось так себе, давайте воздержимся, возможно, со временем будет придумано что-то получше.
Опять же, история с концептами показывает, что такой подход вполне себе работает.
oficsu
09.10.2021 12:53SFINAE было фичей? Мне всегда казалось, что это был костыль из имеющихся палок дабы не придумывать что-то нормальное.
Да, для решения проблемы, для которой использовали SFINAE, очень давно задумывались концепты. Так уж получилось, что их очень сильно упростили и они попали только в C++20, хотя и были на пороге стандартизации ещё в 2009 году
oficsu
09.10.2021 12:58И кто за это заплатит?
Значит, вы готовы решать сложные задачи за оплату и при этом желаете препятствовать развитию языка, которое упрощает эту работу для других?
И, естественно, ваша позиция выглядит именно как отказ упрощать, а не как попытка выбрать другой, более удачный способ решения, ведь вы не готовы предложить другой успешный вариант решения, всё, что вы можете — давать наброски, которые пока что не выдерживают критики на мой взглядвозможно, со временем будет придумано что-то получше.
Как долго нужно выждать?
eao197
09.10.2021 13:13Значит, вы готовы решать сложные задачи за оплату и при этом желаете препятствовать развитию языка, которое упрощает эту работу для других?
Давайте называть вещи своими именами: развитием языка занимаются люди, которые могу себе это позволить.
У меня такой возможности нет.
Как долго нужно выждать?
А кто-то торопит? Ну вот над концептами работали полтора десятка лет. На фоне возраста C++ это вполне нормально.
Тогда как модули, которые лепили (как мне показалось) наспех, получились каким-то переусложненным уродством. Да еще и сомнительной полезности. Да еще и усложняющие жизнь тем, кто использовал свои доморощенные системы сборки.
Или вот Networking TS и Executors. Нужно ли торопить с их принятием? Сильно сомневаюсь.
oficsu
09.10.2021 13:20Мне кажется, всё дело в том, что с концептами, Networking TS и Executors есть обсуждения, разногласия и понимание несовершенства тех или иных частей предложения именно внутри комитета — идёт активный диалог. И в таком случае, конечно же торопить не стоит
Но в случае с deducing this, кажется, все были согласны с предложением. Возможно, потому что именно люди из состава комитета чаще сталкиваются с проблемой и посчитали её, во-первых, достойной решения, во-вторых, достойной решения именно в таком виде, не найдя убедительной аргументации для отклонения предложения
eao197
09.10.2021 13:54Возможно, потому что именно люди из состава комитета чаще сталкиваются с проблемой и посчитали её, во-первых, достойной решения
Люди из комитета, во-первых, сильно умнее и опытнее подавляющего большинства C++ разработчиков. Им сложно понять, что у кого-то могут быть серьезные проблемы с пониманием их замыслов.
Во-вторых, сильно сомневаюсь, чтобы людям из комитета приходилось длительное время жить на предыдущих стандартах. Когда ты все время на переднем крае, то вряд ли ты осознаешь, чем живут люди, которые вынуждены пользоваться C++11, а то и C++98.
Antervis
11.10.2021 18:21+1Когда ты все время на переднем крае, то вряд ли ты осознаешь, чем живут люди, которые вынуждены пользоваться C++11, а то и C++98.
во-первых, комитет регулярно проводит опросы, во-вторых, условный с++23 не поможет человеку, застрявшему на с++03, по той же причине, по которой ему не помогли с++11/14/17/20
eao197
11.10.2021 19:00Не знаю, что вы вкладываете в "не поможет". Я вел речь о том, что люди из комитета могут не отдавать себе отчета о том, что для человека "застрявшего" в C++03 переход на C++20/23 может выглядеть как переход на совсем другой язык программирования.
И, с учетом множества текущих факторов, для кого-то выбор между "изучать C++ заново" и "изучать Rust заново" будет отнюдь не в пользу C++.
Если текущая ситуация всех устраивает, то нет проблем. Видимо, приток "свежей крови" в C++ настолько велик, что отток тех, кого подзадалбывает заучивать пачки новых граблей, можно не принимать во внимание.
PS. "Застрявшими" могут быть и не по своей воле. А потому, что в их распоряжении компиляторов с поддержкой новых стандартов может и не быть.
technic93
11.10.2021 19:26распоряжении компиляторов с поддержкой новых стандартов может и не быть
Раст есть на подмножестве платформ где есть clang. Тех кто застрял раст уж точно не спасёт.
eao197
11.10.2021 19:30Могут быть и ситуации, когда в компании куплен, условно VS2015, и покупать новую версию компания не собирается.
Из прошлого опыта: заказчик из крупнейшего российского банка в 2008-2009 годах продолжал использовать Visual C++ 6.0 (которая года 1998 выпуска) и на вопросы "А почему бы вам не обновить VC++?" невозмутимо отвечал "А нам незачем".
Antervis
11.10.2021 23:00+1люди из комитета могут не отдавать себе отчета о том, что для человека "застрявшего" в C++03 переход на C++20/23 может выглядеть как переход на совсем другой язык программирования.
И, с учетом множества текущих факторов, для кого-то выбор между "изучать C++ заново" и "изучать Rust заново" будет отнюдь не в пользу C++.
вот мне прям сложно верится в человека, который 10 лет не желал обновить знания об инструменте, которым он денежку зарабатывает, потом захотел наверстать упущенное, столкнулся со сложностями решил, что изучать нововведения уже известного ему языка сложнее, чем изучать абсолютно новый язык.
Из прошлого опыта: заказчик из крупнейшего российского банка в 2008-2009 годах продолжал использовать Visual C++ 6.0 (которая года 1998 выпуска) и на вопросы "А почему бы вам не обновить VC++?" невозмутимо отвечал "А нам незачем".
таким объяснять надо. А то их так и будет всё устраивать, пока народ не начнет повально уходить на меньшую зарплату.
eao197
12.10.2021 07:29+1что изучать нововведения уже известного ему языка сложнее, чем изучать абсолютно новый язык.
Во-первых, таки да, изучать C++20 после C++11 -- это как будто изучать новый язык.
Во-вторых, давайте чуть переформулируем ваши слова: изучать нововведения уже известного языка практически так же сложно, как изучать абсолютно новый язык, но при этом практически не дает никаких конкурентных преимуществ на современном рынке.
TargetSan
09.10.2021 00:50Я вот нихера не понимаю, почему где-то нужно
std::move(x)и без указания типа x. А где-то нужноstd::forward<A>(x). Пришлось просто заучить.В обоих случаях необходимость функций-прокладок вызвана тем, что любое именованное значение будет восприниматься как lvalue. Даже если x — rvalue reference. Подозреваю, это тяжёлое наследие С. Чего не происходит с результатом функции. Поэтому, кстати, есть отдельно
auto a = foo()иdecltype(auto) a = foo(). При этом std::move всегда превращает аргумент в rvalue reference, поэтому ему не требуется подсовывать тип под нос явно. А вот сstd::forwardинтересней. Он используется в основном при perfect forwarding и должен вернуть аргумент ровно того типа, которого он был. Однако из-за особенностей системы типов, в т.ч. "сжатия ссылок" (A & && -> A &) и толкования всего именованного как lvalue, мы опять же теряем часть информации о типе при передаче его куда-либо. Чтобы воспользоваться магией функции-прокладки, мы должны откуда-то подсунуть ей тип. Именно поэтому пишется именноstd::forward<A>(a). A берётся из типов-параметров. Подозреваю, можно было бы писатьstd::forward>decltype(a)>(a), но первый вариант банально короче.oficsu
09.10.2021 01:04Подозреваю, можно было бы писать
Да, это сработает корректно и такое поведение даже получило некоторое распространение сstd::forward<decltype(a)>(a)autoаргументами лямбд в C++14 и, возможно, получит большее распространение в C++20, где такой синтаксис стал разрешён для любых шаблонов функций
eao197
08.10.2021 07:32Если я верно понял ход ваших мыслей, то итоговый тип может быть
&/const&/&&/const&&/… Раньше в языке не было примеров, чтобы разыменованный указатель был отличен от lvalue.Вот эту часть вообще не понял.
В языке уже есть подобный механизм:
#include <type_traits> struct demo { decltype(auto) f() const { return *this; } decltype(auto) g() { return *this; } }; int main() { demo d; static_assert(std::is_same_v<const demo &, decltype(d.f())>); static_assert(std::is_same_v<demo &, decltype(d.g())>); }oficsu
09.10.2021 00:02Я указывал на вполне конкретную конструкции
*thisиdecltype(*this)вместе с ней, написанную в коде. Значит, типом этого выражения будетbuilder&,builder&&,builder const&илиbuilder const&&, верно?
Но сейчасdecltype(*this)может раскрыться только в ссылку на lvalue. Потому что любой указатель разыменовывается в lvalue. А с вашим предложением, при разыменовании указателяthis, мы можем получитьbuilder&&. Но это совершенно новое поведение для языка. Т.е. вы в язык добавили помимо явно указанной новой конструкцииauto(this)ещё и новое поведение для указателей. Появляются логичные вопросы — аthisон что, особый теперь (ведь раньше единственной его особенностью была неявность определения)? Этого не понять, только заучить конкретный случай? Или не особый, но другие указатели тоже могут разыменовываться в rvalue? А при каких обстоятельствах? А как это использовать с пользой? А как получить такое поведение? А как его избежать?
Кроме того, я сразу замечу, что уже существующая в языке конструкцияdecltype(auto)мне не нравится по тем же самым причинамeao197
09.10.2021 07:46А с вашим предложением, при разыменовании указателя
this, мы можем получитьbuilder&&Вообще-то там нет обычного разыменования this. Там decltype(*this) указывается в качестве типа возвращаемого значения.
И да, мне кажется нелогичным вот такое в современном C++:
struct demo { demo&& f() && { ... return std::move(*this); } };Т.е. какие причины стоят за необходимости писать return std::move(*this) я понимаю, но логичности это не добавляет.
oficsu
09.10.2021 09:26Там decltype(*this) указывается в качестве типа возвращаемого значения.
А как ваше предложение работает в теле метода? Что если мы не возвращаем значение, а хотим определить переменную того же типа внутри метода? А чем будет делать просто*thisвнутри метода? То же, что и раньше? тогда*thisне будет иметь ничего общего сdecltype(*this)? Нам только запомнить такую особенность?eao197
09.10.2021 10:20+1А как ваше предложение работает в теле метода?
Нет моего предложения. Есть мнение о том, что придумали заумную штуку, которую рядовые пользователи языка будут осваивать с трудом. И попытка показать, что если не стремиться одним решением закрыть кучу проблем (еще раз ткну вас в SFINAE как в яркий пример), то можно попробовать найти более понятное для обычных программистов решение.
И был приведен пример. Лично мне кажется, что вот это:
void f() for(const &, const &&) {...}объяснить рядовому программисту будет проще, чем вот это:
template<typename T> void f(this const & self) {...}потому что вариант for может читаться "в лоб": эта реализация f() должна быть сгенерирована компилятором для вариантов const & и const &&.
Возможно, я заблуждаюсь.
А чем будет делать просто
*thisвнутри метода?В языке уже есть decltype(auto), которое задается в виде типа возвращаемого значения. И оно не имеет отношения к тому, что именно делается внутри метода/функции. Точно так же decltype(*this) на этом же месте будет иметь собственный смысл.
Если вас так напрягает decltype(*this), то можно сделать новое ключевое слово co_variant:
co_variant(*this) f() { return *this; }co_variant(*this) означает, что будет возвращена ссылка на ковариантный тип, а co_variant(this) -- что указатель. Можно даже без this: co_variant(&), co_variant(const &), co_variant(&&), co_variant(const *).
Ничуть не хуже co_await, co_return и co_yield. Тем более что это явное решение проблемы, для которой раньше решения не было.
И да, это так же на мой субъективный взгляд будет гораздо понятнее, чем вариант из пропозала по deducing this.
oficsu
09.10.2021 11:39И попытка показать, что если не стремиться одним решением закрыть кучу проблем (еще раз ткну вас в SFINAE как в яркий пример), то можно попробовать найти более понятное для обычных программистов решение.
Но вы не показали, как можно попробовать найти более понятое решение, ведь до этого вы не предложили ничего:А как ваше предложение работает в теле метода?
Нет моего предложения
Кроме того, вы опять обращаетесь к подмене тезиса и апеллируете к SFINAE — инструменту изначально не задуманному, для решений тех задач, для которых его применили. Да, это неудачный дизайн, но это плохая аналогия для deducing this, который целенаправленно намерен решить ряд проблем, а не делает это случайнообъяснить рядовому программисту будет проще, чем вот это:
Опять же, вы пытаетесь объяснять проблему, возникающую преимущественно на стыке с perfect forwarding программисту, не знакомому с perfect forwarding и гордо объявляете, что ваша конструкция понятна программисту, который не будет её писать. Нет, конструкция должна быть понятна в контексте, проблема которого решается. И программисту, понимающему проблему perfect forwarding, эта конструкция будет понятна и знакома
Кроме того, вы допустили ошибку в коде:
Он будет выглядеть на самом деле вот так:template<typename T> void f(this const & self) {...}template<typename T> void f(this MySpecificType const & self) {...}
Это больше похоже на обычный метод с обычным параметром, только помеченным словомthisи содержит меньше непонятногоВ языке уже есть decltype(auto)
И это пример ужасного дизайна, непохожего ни на чтоТочно так же decltype(*this) на этом же месте будет иметь собственный смысл.
Если вас так напрягает decltype(*this), то можно сделать новое ключевое слово co_variant:co_variant(*this) f() { return *this; }
Допустим, я переписал код вот так:co_variant(*this) MyType::f() { g(*this); return ???; }
Во-первых, мы вообще-то, не обязательно и хотим делать возврат, значит, вариант с возвращаемым типом нам не подойдёт.
Во-вторых, дляMyType&&, будет объект, на котором вызван метод, скопирован вgили перемещён?
Если будет перемещён, то это поменяло смысл кода, позволив указателю разыменоваться в rvalue, на что я и указал ранее как пример неконсистентности
Если не будет, то этот пример не решает ту же проблему, что стояла перед авторами предложения
eao197
09.10.2021 12:13Но вы не показали, как можно попробовать найти более понятое решение, ведь до этого вы не предложили ничего
Мне нужно в десятый раз повторить, в чем был смысл моего комментария, серьезно?
Кроме того, вы опять обращаетесь к подмене тезиса и апеллируете к SFINAE
Я апеллирую к истории, уроки которой, похоже, старательно пускают по известному половому органу. "Нам не дано предугадать, как наше слово отзовется". Вот пока что история C++ именно такая: сперва сделают что-то, затем учатся ходить по граблям. Метапрограммирование на шаблонах, SFINAE, throw(), export templates, uniform initialization syntax, structured binding и lambda capture lists, std::function и лябды с захватом unique_ptr, std::function и noexcept в сигнатурах функций, ...
Предлагается решение, которое выглядит так, как будто нас всех ждет еще множество удивительных открытий. Поэтому тут некоторые (включая меня) и говорят "Астанавитесь!" Ибо ну пора бы уже поумнеть.
И это пример ужасного дизайна, непохожего ни на что
Тем не менее, он закрывает дыру с тем, что просто auto в качестве возвращаемого значения не позволяет возвращать ссылки. И это уже отлито в граните, к этому уже привыкли.
Во-первых, мы вообще-то, не обязательно и хотим делать возврат, значит, вариант с возвращаемым типом нам не подойдёт.
Если вам не нужен возврат, то не пишите co_variant(*this). Напишите void в качестве возвращаемого значения.
Во-вторых, для
MyType&&, будет объект, на котором вызван метод, скопирован вgили перемещён?Если мы говорим про вот этот код:
co_variant(*this) MyType::f() { g(*this); return ???; }То здесь внутри MyType::f у this будет тип MyType*.
Соответственно, что произойдет с this после вызова g зависит полностью от сигнатуры и содержимого g.
Если пытаться отталкиваться от моих набросков, и рассмотреть такой код:
co_variant(*this) MyType::f() for(&, const &, &&, const &&) { g(*this); return *this; }То внутри MyType::f тип this будет либо MyType* (для случаев & и &&), либо const MyType* (для случаев & и &&).
Либо же, если предположить, что внутри f() нам так же нужно знать, какой же актуальный тип у объекта (что не факт, что можно разрешать), то или ActualType* (для &, &&), или const ActualType* (для const &, const &&).
oficsu
09.10.2021 12:48Если честно, я не увидел, что такое
ActualTypeи чем принципиально отличается отMyTypeСоответственно, что произойдет с this после вызова g зависит полностью от сигнатуры и содержимого g.
Ноgможет иметь реализацию одновременно и для lvalue и более эффективную для rvalue. В идеале хотелось бы выбрать наиболее оптимальную из допустимых
Я это к тому, что предложение позволяет писать такой код:template <typename T> class optional { // ... template <typename Self, typename F> constexpr auto and_then(this Self&& self, F&& f) { using val = decltype(( forward<Self>(self).m_value)); using result = invoke_result_t<F, val>; static_assert( is_optional<result>::value, "F must return an optional"); return this->has_value() ? invoke(forward<F>(f), forward<Self>(self).m_value) : nullopt; } // ... };
где нам совершенно точно нужно, чтобыselfумел быть в том числе иMyType&&, но разыменовать*thisв rvalue для этого нельзя в текущих правилах языка
eao197
09.10.2021 13:03Если честно, я не увидел, что такое
ActualTypeи чем принципиально отличается отMyTypestruct basic_params { int limit_; co_variant(*this) limit(int v) for(&,&&) { limit_ = v; return *this; // (1) } ... }; struct my_params : public basic_params { seconds wait_time_; co_variant(*this) wait_time(seconds v) for(&,&&) { wait_time_ = v; return *this; } ... }; struct your_params : public basic_params { int signals_mask_; co_variant(*this) signals_mask(int v) for(&,&&) { signals_mask_ = v; return *this; } }; my_params{}.limit(10).wait_time(5s); // (2) your_params{}.limit(10) .signals_mask(SIGINT|SIGQUIT); // (3)В точке (1) будет определяться реальный тип, для которого был вызван метод. Т.е. в (2) это будет my_params&&, а в (3) -- your_params&&.
eao197
09.10.2021 13:07Я это к тому, что предложение позволяет писать такой код:
Я бы предпочел в таких случаях писать все-таки не одну реализацию, а три: для const &, & и &&. Или может быть даже две -- для const & и &&, т.к. не вижу смысла в отдельных реализациях для & (сводится к const &) и для const && (чем это отличается от const&?).
Но, самое важное, очень бы хотелось бы избавиться от синтаксического оверхэда вида:
using val = decltype(( forward<Self>(self).m_value)); ... return this->has_value() ? invoke(forward<F>(f), forward<Self>(self).m_value) : nullopt;Все эти приседания с forward-ами -- это просто трэш какой-то.
oficsu
06.10.2021 01:21Я считаю, что вы абсолютно неправы касательно deducing this. Это одна из тех фич, которая нужна буквально в любом generic коде без оговорок. Дело в том, что у нас сейчас в языке очень сильно расходится семантика для полей и методов, взгляните:
std::forward<decltype(foo)>(foo).bar // и std::forward<decltype(foo)>(foo).baz()
В первой строчке категория значения поля корректно и автоматически наследуется от объекта, его содержащего. Но во втором случае этого не происходит по умолчанию, что порождает некорректную семантику, а иногда и наблюдаемое поведение. А чтобы заставить код работать правильно, сейчас мы должны явно скопипастить тело функции как минимум 3 раза дляconst&,&и&&версий*this. И это невероятно утомляет разработчиков, этим никто не хочет заниматься и не занимается на практике — даже в стандартной библиотеке отсутствуют rvalue ref-qualifiers там, где они могли бы оказаться полезны. Так по итогу проигрывают все, включая обычных пользователей
Т.е. мы получаем менее качественные библиотеки, предоставляемые конечным пользователям — методы имеют некорректную семантику и делают лишние копирования на пустом месте (см.std::filesystem::path::operator string_type())
Перепиши мы код стандартной библиотеки на основе синтаксиса, предложенного в этой бумаге — мы автоматически и по умолчанию получим корректную семантику везде и это очень важно
Так что да, верно. Непосредственно писать этот код нужно очень малой части C++ программистов, но он при этом косвенно затрагивает буквально каждого пользователя — как концепты улучшают жизнь обычных программистов, позволяя упростить написание качественного библиотечного кода с понятными диагностиками, используемого ими, deducing this обеспечивает корректную семантику такого шаблонного кода по умолчанию, местами обеспечивая ещё и автоматические оптимизации, убирая копирование. При этом, да, сам пользователь может и не подозревать, что за этим стоит какой-то deducing this
Если мы однажды в развитии языка начнём ориентироваться лишь на 99.9% процентов пользователей — однажды мы уберём и шаблоны, ведь они нужны лишь той самой одной десятой процентаAndDav
06.10.2021 08:03А чтобы заставить код работать правильно, сейчас мы должны явно скопипастить тело функции как минимум 3 раза для
const&,&и&&версий*this.,Позволю себе слегка не согласиться -- если нужно 3, а не 2 перегрузки, т.е. мы хотим и
&ссылку тоже предоставить, то обычно (не всегда) можно быть проще и сделать поле публичным вместо getter-ов.Перепиши мы код стандартной библиотеки на основе синтаксиса, предложенного в этой бумаге — мы автоматически и по умолчанию получим корректную семантику везде и это очень важно
Чтобы принять решение "вместо обычного нешаблонного getter-а мы будем писать шаблонную функцию с deducing this" все-таки надо задуматься, о том что в этом месте это полезно и пользы больше чем вреда, так что "автоматически" не получится. А если все равно задумываться, то и добавить
&&-перегрузку большой проблемой не будет. Более того, с практической точки зрения, принятие "Deducing this" в C++23 никак не поможет починить существующие классы стандартной библиотеки, такие какstd::filesystem::pathпотому что во-первых, они должны компилироваться в C++17-режиме, а во-вторых, ради ABI-stability нельзя отрефакторить non-template перегрузки в template.... как концепты улучшают жизнь обычных программистов, позволяя упростить написание качественного библиотечного кода...
По-моему, есть существенная разница с концептами -- последние не дублируют существовавшие до них языковые механизмы (не считая SFINAE-хаков вроде enable_if и void_t, по которым никто скучать не будет). Еще одно отличие от концептов, что в теории они могут использоваться и совсем в прикладном коде. Скажем, писать
std::vector<std::uint64_t>::const_iterator beg = myvec.begin();кажется слишком длинным, а в записи
auto beg = myvec.begin();кому-то не хватает информации о типе
beg, в таком случаеIterator auto beg = myvec.begin();может показаться золотой серединой. Правда, пока не прошло достаточно времени, чтобы сказать, пользуется ли такой стиль популярностью на практике.
Непосредственно писать этот код нужно очень малой части C++ программистов, но он при этом косвенно затрагивает буквально каждого пользователя...
Не соглашусь, с тем что только косвенно. Explicit this это прямо новый способ писать member functions, позволяющий отказаться от function ref- and cv-qualifiers. Если бы он был в языке с самого начала, то и отдельный синтаксис для static methods был бы не нужен, и даже, можно пойти еще дальше, и ключевое слово this. В общем я предвижу глобальный раскол по стилю написания member functions (что, согласитесь, существенная часть кода на C++), который мне кажется куда серьезнее, чем войны между
остро-/тупо- конечникамиадептами trailing/non-trailing return type, east/west const и т.д.При этом, очевидно, иметь в языке одну фичу (explicit this) лучше чем несколько (function ref- and cv-qualifiers, static methods, keyword this, ...) ну и бонусом те преимущества, что дает нам "Deducing this" proposal, так что если делать язык с 0, то надо идти именно по этому пути, как и сделали в Rust-е. Но добавлять explicit this сверху всего того, что уже есть в C++, по моему мнению принесет больше вреда, чем пользы.
Ну и сверху бонусом "задачка" -- напоминание о том, что языковые фичи интерферируют, и добавляя все новые и новые есть риск завалить язык под их тяжестью:
struct X {}; struct Y { bool operator == (this X, Y); }; void test(X x, Y y) { x == y; // должен ли этот код компилироваться? }oficsu
06.10.2021 17:54Позволю себе слегка не согласиться — если нужно 3, а не 2 перегрузки, т.е. мы хотим и & ссылку тоже предоставить, то обычно (не всегда) можно быть проще и сделать поле публичным вместо getter-ов.
Речь не всегда идёт в контексте геттеров, это не обязательно возврат поля. Это даже не всегда имеет что-то общее с возвратом значения из метода. У нас не должно быть особой необходимости иметь заведомо некорректную семантику по умолчанию (вызов lvalue-версии метода на rvalue-объекте), как это происходит сейчас. С предложенной бумагой, если вдруг начать весь код писать, используя эту фичу, код будет корректен практически по умолчанию и никому хуже от этого точно не станет, но выиграют всеА если все равно задумываться, то и добавить &&-перегрузку большой проблемой не будет.
Однако же, пример, приведённый мной показывает, что не всё так просто и её иногда просто забывают. Либо оставляют на потом, не зная, не понимая, где и кому эта перегрузка понадобится. Я склоняюсь к тому, что написать на автомате уже почти привычную всем конструкцию видаstd::forward<decltype(self)>(self)и получить универсально работающий код проще, чем принимать решение о необходимости скопировать тело и обдумывать, какой из кастов применить к*thisв конкретно этой перегрузке и как отстрелить себе по-меньше ног сconst_cast, и даже бездумное копирование вышеуказанной конструкции вряд ли где-то что-то серьёзно сломаетпринятие «Deducing this» в C++23 никак не поможет починить существующие классы стандартной библиотеки, такие как std::filesystem::path потому что во-первых, они должны компилироваться в C++17-режиме, а во-вторых, ради ABI-stability нельзя отрефакторить non-template перегрузки в template.
Да, это я понимаю. Однако, новый код можно будет начинать писать с использованием этой бумаги и он будет лишён проблемы, возникавшей с классами до C++23По-моему, есть существенная разница с концептами — последние не дублируют существовавшие до них языковые механизмы (не считая SFINAE-хаков вроде enable_if и void_t, по которым никто скучать не будет)
Всё же, концепты по большей части дублируют имевшийся ранее функционал. Думаю, эту тему можно обсудить отдельно. И да, мы, может, по таким механизмам и не будем скучать… Но этот же аргумент применим и в случае deducing this — кто будет скучать по ref-qualified member functions в C++23, когда для них будет более удобный и менее бойлерплейтный аналог, не нарушающий DRY?Еще одно отличие от концептов, что в теории они могут использоваться и совсем в прикладном коде.
Я не осведомлён о практике применения такого подхода, поэтому не могу произвести каких-то сравнений. Могу только предположить, что deducing this также найдёт своё место в редком прикладном коде, пытающемся оптимизировать копирования в своих методахпозволяющий отказаться от function ref- and cv-qualifiers
Во многом, следующий абзац будет про субъективные вкусовые предпочтения, полагаю, не лишено смысла указать моё личное отношение, однако, ввиду отсутствия какой-то объективности в этом вопросе, я не вижу смысла развивать эту тему.
Честно сказать, я считаю старый синтаксис ужасным монстром сродни другим причудам cdecl. Многие, впервые сталкиваясь с ним, даже не могут понять, что перед ними. Ещё сложнее узнать заранее о том, что такой синтаксис есть и что он позволяет делать нечто полезное. О возможности принять forward reference многие узнают довольно быстро, видя чужой код или знакомясь с ним в различных источниках. А вот возможность проделать то же самое с*thisостаётся тёмным уголком C++ даже для некоторых опытных пользователей. Также, ключевое словоthisв предложенном синтаксисе банально облегчит поиск информации в сети по сравнению с ref qualifiersВ общем я предвижу глобальный раскол по стилю написания member functions, который мне кажется куда серьезнее
Мне кажется, что это вопросы одного порядка, и ничего глобально не изменится — просто добавится немного текста в стайлгайды. Полагаю, произойдёт ровно то же самое, что было с trailing return type — стандартом останется старый синтаксис, а новый будет использован только в тех случаях, где он действительно имеет преимущества — их немало и они рассмотрены в бумаге. Если кто-то предпочтёт новый синтаксис везде как более эстетически приятный? Кажется, наш язык во многом про свободу выбора, не вижу смысла препятствовать этомуx == y; // должен ли этот код компилироваться?
На всякий случай, для начала я процитирую кусочек предложения по deducing this:This paper does not propose any changes to overload resolution. Мы можем заключить, что идеологически, со внешнй стороны по отношению к классу, методы объявленные с использованием нового синтаксиса неразличимы со старыми методами — так что для указанной строки в принципе ничего не могло поменяться
На самом деле, серьёзная семантическая ошибка была допущена выше, когда вы объявили, что метод классаYпринимает в качествеthisтипX. В предложении рассмотрен такой пример. Он признан бессмысленным (такой метод в чём-то схож сoperator void(), который никогда не вызывается) и бесполезным, поскольку он просто не может быть найден через unqualified name lookup. Меня несколько смущает, что в бумаге предложено оставить это как есть и отказаться от необходимости ошибки компиляции в этом случае — это может оставить простор для каких-то нетривиальных языковых хаков на мой взгляд, но в чём-то я и согласен с автором — незачем осмысливать заведомо бессмысленный пример кода, проще забить на него, пока он не мешаетAndDav
06.10.2021 19:04Я склоняюсь к тому, что написать на автомате уже почти привычную всем конструкцию вида
std::forward<decltype(self)>(self)и получить универсально работающий код проще, чем принимать решение о необходимости скопировать тело...Написание на автомате приведет к тому, что вместе с
const &и&&будет объявляться еще и&перегрузка, а этого часто нужно избегать (нарушение инкапсуляции). Пример --std::stringstream::str(). Так что нет, deducing this это не волшебная пилюля, позволяющая не думая получать корректный код.В предложении рассмотрен такой пример. Он признан бессмысленным (такой метод в чём-то схож с
operator void(), который никогда не вызывается) и бесполезным, поскольку он просто не может быть найден через unqualified name lookup.Все так для почти всех методов, но я не просто так использовал
operator ==: для него есть дополнительная стадия lookup (reversed operators), в которой резолвитсяy == xвместоx == y. В этой стадии мы, очевидно, заглянем в member-ы классаY.К чему я это все -- наивно думать, что добавление в C++ такой существенной новой вещи как "semi-static member functions" не приведет к никаким новым странным corner-cases. "This paper does not propose any changes to overload resolution" это намерение авторов, а что получится узнаем. spaceship operator тоже задумывался как не меняющий поведение никакого старого кода, а на практике случался миллион breaking changes.
В целом у нас расхождение по принципу оптимист/пессимист. Вы верите, что новые возможности будут использоваться только во благо, а мой опыт подсказывает, что получится как всегда (ну или как много раз было в C++).
oficsu
06.10.2021 19:42Все так для почти всех методов, но я не просто так использовал operator ==: для него есть дополнительная стадия lookup (reversed operators), в которой резолвится y == x вместо x == y. В этой стадии мы, очевидно, заглянем в member-ы класса Y.
Мне кажется логичным, что даже этот случай не должен нарушать оговоренную явно семантику. Если текущий вординг по случайности допускает такой вызов, я был бы за исправление вординга в соответствии с непосредственными намерениями авторов. Ну, а ещё, мне больше по вкусу запретить саму возможность определения такой операции сравнения внутриY, честно говоря
Я действительно смотрю на предложение очень оптимистично и рассматриваю его не как ещё одну неконсистентность, а, наоборот, как шанс на унификацию — можно будет постепенно убрать особый синтаксис для function ref-qualifiers, сделав код «более обычным». Я даже не уверен, что это станет большой трудностью с учётом того, что их применение — сравнительно редкий случай в текущем виде
AnthonyMikh
07.10.2021 16:39spaceship operator тоже задумывался как не меняющий поведение никакого старого кода, а на практике случался миллион breaking changes.
Так, а вот про это можно поподробнее?
AndDav
07.10.2021 23:41+2AnthonyMikh
08.10.2021 13:30Спасибо за примеры
0xd34df00d
08.10.2021 23:47+4Ещё в копилку, недавно приводил пример в другом треде — в C++20 разрешили частично инициализировать некоторые классы типов из скобочек, поэтому для
struct S { int a; int b; }; template<typename T, typename = decltype(T(int {}))> bool isCpp20Impl(int) { return true; } template<typename T> bool isCpp20Impl(...) { return false; } bool isCpp20() { return isCpp20Impl<S>(0); }isCpp20вернётtrueпри сборке C++20-компилятором, иfalseпри сборке C++17-компилятором.Понятно, что на практике это выливается в веселье с внезапным выбором не тех перегрузок в богатом темплейтами кодами.
oficsu
09.10.2021 00:15А есть практические примеры сломанных перегрузок из-за этого? Неужели кто-то где-то выбрал конструкцию
decltype(T(int {}))в ролиenable_if_t<false>? Или я не учёл какие-то более сложные примеры?0xd34df00d
09.10.2021 00:46+4А есть практические примеры сломанных перегрузок из-за этого?
Да, я сам-то об этом эффекте узнал, когда ко мне несколько месяцев назад приятель обратился с просьбой помочь с проблемой, что у них «компилятор сломался» после апгрейда на новый стандарт.
Неужели кто-то где-то выбрал конструкцию decltype(T(int {})) в роли enable_if_t<false>? Или я не учёл какие-то более сложные примеры?
Да, например, так раньше нередко проверяли, есть ли явно определённый конструктор, принимающий данные конкретные аргументы. Теперь этот код сработает не только на типы с таким конструктором, но и на типы-агрегаты, у которых, ну, так повезло, первые члены расположены в том же порядке и имеют тот же тип.
technic93
09.10.2021 20:43Если тип агрегат можно частично инициализировать, так чтобы это вызвало проблемы, то надо чинить объявления этого типа.
0xd34df00d
09.10.2021 21:59Проблема в том, что здесь тупо по-тихому вызывается другая функция, даже если частичная инициализация агрегата не ломает инварианты.
technic93
09.10.2021 22:14Было бы интересно более полный пример увидеть. Зачем знать явный конструктор или нет? И как решилось, выяснили что это знать не обязательно и перегружать лучше по другому совйству, или как?
0xd34df00d
10.10.2021 00:27+2Если совсем вкратце, там была какая-то наркоманская версия DI через передачу variadic pack'а со всеми нужными в конструктор объекта, и, так совпало, было соглашение, что если конструктор определён, то он сам сделает всю нужную логику по регистрации объекта где-то ещё, а если не определён, то объект надо зарегистрировать руками. Соответственно, агрегаты, которым везло быть совместимыми с конструктором, не регистрировались.
Как решили — не знаю, я там сбоку был как типа чувак со стороны от проекта.
0xd34df00d
10.10.2021 20:42+1Нет, тривиальность там совсем-совсем ни при чём.
Другой пример, который я обсуждал с другим товарищем — если вы знакомы с Qt, там управление памятью идёт через иерархию
QObject'ов. У отнаследованного отQObject'а объекта может быть отнаследованный отQObjectродитель, и когда умирает родитель, он прибьёт всех своих детей.Тогда, например, легко представить себе некий обобщённый библиотечный код, который отвечает за создание объектов и проверяет, принимает ли конструктор объекта
QObject*(что может быть сделано через тот жеis_constructible_v<T, QObject*>— пусть для простоты никаких других аргументов конструкторы принимать не могут). Если такой конструктор найден, то мы просто создаём объект с нужным родителем, и он там сам управляется по части памяти и времени жизни. Если не найден — библиотечный код регистрирует объект у себя внутри и прибивает его когда надо.Теперь, если вам не повезло иметь структуру
struct S { QObject *field; ...; };, то раньше она корректно регистрировалась и убивалась, а теперь это утечка памяти как минимум.
technic93
10.10.2021 21:13+1В первом пример вы создали договоренность о том, что у объектов может быть сайд-эффект в конструкторе, то это значит что он куда-то там регистрирует. Если же он просто берёт аргументы и копи/мув инициализирует ими поля, то значит его надо регистрировать вручную. Так что как по мне как раз тривиальность тут то что надо.
Если в объекте `QObject*` который сам заботится о своей памяти, то не надо его выставлять публичным полем. Не видел ни одного Qt класса где QObject* public, так что это совсем за уши притянуто.
0xd34df00d
10.10.2021 21:19Если в объекте
QObject*который сам заботится о своей памяти, то не надо его выставлять публичным полем. Не видел ни одного Qt класса где QObject* public, так что это совсем за уши притянуто.Так в том и дело, что он не заботится, что просто так повезло иметь какой-то указатель первым полем.
technic93
10.10.2021 21:43Создайте статические методы createAuto() createManaged(), в С++ как раз конструкторы сделали чтобы быть по возможности универсальными, если вы не хотите то не используйте их.
Вообще рекомендация по возможности использовать фигурные скобки для инициализации уже вроде как давно есть, так что я даже и не знал что через проверку на
T(...)можно что то узнать было.Но вы скажете что метод
createAutoтоже мог случайно оказаться. Ну тот уже только наследоваться от тегов, чтобы было по аналогии с номинативной типизацией.
П.С. вначале отправилось случайно раньше времени - новый редактор это какое то издевательство :(
0xd34df00d
10.10.2021 22:05+2Вы говорите, как это починить, а я говорю про то, что абсолютно валидный код, не нарушающий никакие стандарты, внезапно от смены стандарта начинает работать по-другому. Не ломается при компиляции, а начинает работать по-другому. И это ужасно. Даже если код изначально был с душком.
technic93
10.10.2021 22:25Для такого даже новую версию включать не надо, по-моему это проблема любой перегрузки/специализации при обновлении либы из зависимостей. В хаскель я так понимаю тоже параметричность не всегда есть, например в той ссылке про копродакты было какое-то подобие специализации. Как с этим обстоят дела?
0xd34df00d
11.10.2021 01:42+1Для такого даже новую версию включать не надо, по-моему это проблема любой перегрузки/специализации при обновлении либы из зависимостей.
Да, поэтому ровно этот пример я привёл в комментариях к статье о том, что не надо делать
using namespace.В хаскель я так понимаю тоже параметричность не всегда есть, например в той ссылке про копродакты было какое-то подобие специализации. Как с этим обстоят дела?
Параметричность в хаскеле есть всегда, просто когда вы пишете
class C a where method :: a -> SomeTy foo :: C a => a -> ...это с хорошей точностью эквивалентно
foo :: a -> (a -> SomeTy) -> ...Тайпклассы по большому счёту и являются словарём методов, который неявно туда-сюда передаётся и выводится из контекста по некоторым правилам.
Так вот, понятное дело, что когда вы передаёте не только объект какого-то типа, но и функцию, работающую над этим типом, то эта функция может делать что угодно. Параметричность в этом случае значит только то, что ваша
fooвызывает одни и те же методы классаCнад переданным объектом.
technic93
11.10.2021 02:04Я имел ввиду когда есть
instance C anyinstance C special, синтаксис конкретный не знаю, но такая вот перегрузка тайплевел функций (или?).
Antervis
11.10.2021 13:56+1Тогда, например, легко представить себе некий обобщённый библиотечный код, который отвечает за создание объектов и проверяет, принимает ли конструктор объекта
QObject*(что может быть сделано через тот жеis_constructible_v<T, QObject*>— пусть для простоты никаких других аргументов конструкторы принимать не могут)ну блин, конструируемость от
QObject*не является ни необходимым, ни достаточным условием QObject'а, нуженstd::is_base_of_v<QObject, T>. Емнип даже не все QObject'ы умеют конструироваться только лишь от parent указателя
0xd34df00d
11.10.2021 19:23+1Уффф. Код по текущему стандарту валиден? Валиден. Поведение с новым стандартом меняется? Меняется. Плохо? Я считаю, что да.
Давайте случай попроще: нужно ли менять парсинг
a < b < cс текущего(a < b) < cна что-то питонячье уровняa < b && b < c? Код, который это сломает по-тихому в рантайме, тоже существует.
Antervis
09.10.2021 13:31-1isCpp20вернётtrueпри сборке C++20-компилятором, иfalseпри сборке C++17-компилятором.Ваш пример можно упростить до
std::is_constructible_v<S, int>. Весьма логично, что при добавлении в язык нового функционала, SFINAE, проверяющий против этого функционала, начнет работать иначе. А еще логично что избежать такой проблемы без эпох, которых в плюсах нет, невозможно. Ну или любого другого механизма прибивания версии языка к коду гвоздями. Да и не только в плюсах.0xd34df00d
09.10.2021 18:52А еще логично что избежать такой проблемы без эпох, которых в плюсах нет, невозможно.
Можно, например, не добавлять функциональность, ломающую имеющийся код, причём по-тихому, в рантайме. Кажется, когда-то в C++ это ценили.
Antervis
09.10.2021 21:26-1В данном случае это тождественно "не добавлять новую функциональность вообще", и я комментом выше объяснил почему. По такой же логике можно было бы обижаться на комитет за сломавшийся с++03 код, называющий переменные noexcept и constexpr.
0xd34df00d
09.10.2021 22:01+2Да ё-моё. Я явно пишу про поломки
по-тихому, в рантайме
Вы в ответ вспоминаете про
noexceptиconstexpr, которые приводят к ошибке компиляции, да ещё и пишете что-то про то, что это та же логика. Как так?
Antervis
09.10.2021 23:18+1Вы в ответ вспоминаете про
noexceptиconstexpr, которые приводят к ошибке компиляции, да ещё и пишете что-то про то, что это та же логика.Во-первых, sfinae в принципе работает через проверку скомпилируется та или иная конструкция или нет, перегрузки с ошибкой компиляции не выбираются. Так ваш снипеет и переводит ошибку компиляции в рантайм - до c++20 конструкция
S(1)просто не соберется. Во-вторых, с точки зрения моего изначального аргумента даже не важно, что там за ошибки, компиляции или рантайма. Попробую его перефразировать: если исходить из установки, что на любое изменения языка обязательно найдется существующий код, зависящий от этого изменения, и его нельзя ломать, то развивать язык становится невозможно.Просто представьте себя на месте человека из комитета, и поймете, что ваша претензия сейчас сродни плачу вредного ребенка.
0xd34df00d
09.10.2021 23:54+2Это какое-то адовое натягивание совы на глобус.
Есть три класса изменений: те, которые не приводят к смене поведения; те, которые приводят к ошибке компиляции; и те, которые приводят к изменению поведения в рантайме. Вот первое — идеально (но не всегда возможно), второе — вполне нормально и приемлемо, а третье — это ад.
То, что в данном конкретном случае речь идёт о sfinae, который как-то связан с ошибками компиляции (в основном наличием слова «ошибка» и там, и там), не играет вообще никакой роли.
Просто представьте себя на месте человека из комитета, и поймете, что ваша претензия сейчас сродни плачу вредного ребенка.
Ежу понятно, что лучше функции Бесселя запилить, чем это всё.
Antervis
10.10.2021 00:30Есть три класса изменений: те, которые не приводят к смене поведения; те, которые приводят к ошибке компиляции; и те, которые приводят к изменению поведения в рантайме
я вам еще раз объясняю - первое невозможно без эпох, а второе, из-за sfinae, является подмножеством третьего. И ваш конкретный случай - когда второе перетекло в третье, как раз посредством sfinae. И соответственно вот это утверждение:
То, что в данном конкретном случае речь идёт о sfinae, который как-то связан с ошибками компиляции (в основном наличием слова «ошибка» и там, и там), не играет вообще никакой роли.
в корне неверно для вашего же конкретного случая. Блин, да даже по определению, в с++17 у вас substitution failure of T with S is not an error, в с++20 substitution success.
0xd34df00d
10.10.2021 20:34+2а второе, из-за sfinae, является подмножеством третьего
Чисто технически, кстати, нет, но неважно.
И ваш конкретный случай — когда второе перетекло в третье, как раз посредством sfinae.
Это просто означает, что авторы языка очень сильно себе усложнили работу по добавлению новых фич, только и всего. Впрочем, это не новость.
в корне неверно для вашего же конкретного случая.
Всё, что меня волнует — могу ли я быть уверен, что после апгрейда компилятора и исправления ошибок компиляции мой код будет работать так, как ожидается, и могу ли я смело раскатывать его в прод или нет (если код написан без UB, конечно, что уже само по себе мощное требование, но снова неважно). Если не могу — то это уровень так любимой Царём скриптухи, это уровень питона и жс. Обсуждать, сфинае в этом виновато, фигае или особенности архитектуры PDP-11, просочившиеся в современный стандарт — очень интересно, конечно, но это можно обсуждать и для тех языков, на которых не пишешь, а писать на тех, где эта уверенность есть.
Antervis
10.10.2021 22:50у вас после споров с царем лес за деревьями потерялся, ну что ж, будем помогать искать?
Чисто технически, кстати, нет, но неважно.
фактически, да, и это важно. SFINAE позволяет проверить корректность любой языковой конструкции, в т.ч. тех, которые еще не ввели в язык. Приведенная вами проблема является следствием мощности инструмента, а не ограниченности, никакой "скриптухой" тут и не пахнет, да и вообще оставьте царскую риторику, она вам не идет.
Всё, что меня волнует — могу ли я быть уверен, что после апгрейда компилятора и исправления ошибок компиляции мой код будет работать так, как ожидается, и могу ли я смело раскатывать его в прод или нет
Обсуждаемый код работал в точности так, как был написан - менял поведение при изменении стандарта языка. Абсолютно аналогично вы могли написать
#if __cplusplus > 202002L #define true false #endifи потом жаловаться что ничего не работает
0xd34df00d
11.10.2021 01:53+1фактически, да, и это важно. SFINAE позволяет проверить корректность любой языковой конструкции, в т.ч. тех, которые еще не ввели в язык.
Это не то же самое, что поднять любую ошибку компиляции на уровень софтовых ошибок.
Приведенная вами проблема является следствием мощности инструмента
Сложности, а не мощности. Наличие двух разных способов инициализировать объект — это не мощность, это чистая и совершенно не нужная (кроме как по соображениям легаси) сложность. Почему нельзя было сразу использовать обычные скобочки для инициализации всего? Зачем потребовалось городить цирк с uniform initialization syntax, который затем оказался недостаточно uniform, поэтому теперь мы уже 10 лет героически пытаемся свести два разных синтаксиса вместе?
А разгадка проста —
безблагодатностьпроцесс разработки языка C++ не имеет ни плана, ни теоретических основ под собой, это чистое throw some shit against the wall to see what sticks. Кто-то написал пропозал, который решает какую-то текущую проблему, вроде норм, вроде не ломает ничего (ну, о чём вы могли подумать за полчаса-час обсуждения пропозала) — ок, голосуем, принимаем.Обсуждаемый код работал в точности так, как был написан — менял поведение при изменении стандарта языка.
Стандарт, который позволяет таковые изменения (без явного цирка с
#ifdef, как вы ниже приводите), имеет баги. Комитет, который считает, что это норма и ничего с этим делать не надо, надо расформировать.Абсолютно аналогично вы могли написать
На всякий случай переспрошу — вы серьёзно утверждаете, что
#if __cplusplus > 202002L #define true false #endifи SFINAE по
decltype(T(int{}))— это вещи одного порядка?
ncwca
11.10.2021 04:49-1Мне просто интересно - кто ЦА данного персонажа? Он ведь даже в логику на уровне начальной школы не может.
и SFINAE по
О пишет что-то по sfinae, ладно он нихрена не понимает что это и как работает. Какие-то лозунги уровня qt-джуна есть, не более.
Но даже максимально далёкий от C++ человек знает чем по сути является sfinae в данном контексте - это механизм интроспекции кода.
А теперь просто подумайте о том какую чушь он несёт. Он обвиняет сфинае как механизм интроспекции кода за то, что он ловит изменение семантики языка.
Это, наверное, сложно. Представьте что у вас есть механизм возвращающий тип возврата функции, допусти get_return_type(f); Есть в языке функция foo, которая возвращает int. Пациент где-то зарадкодил этот int, а после у функции поменяли возвращаемый тип на size_t и get_return_type(foo) стал возвращать size_t.
И теперь пациент обвиняет get_return_type в том, что он не возвращает старый тип. Хотя он делает то, что нужно.
А почему он несёт подобную херню? Потому что это адепт с магическим сознанием. Он взял из интернета какой-то лозунг. Взял своё нелепое представление о sfinae. Т.е. для него это какая-то магия, которая непонятно что делает.
Как в ситуации get_return_type(foo) - он просто спастил это из интернета и воспринимает как "всегда возвращает int". Ему там неважно что и почему. В его пустом сознании это просто алиас на инт. А когда он перестал быть интом - у него возникли проблемы. Противоречия именно между его представления и реальность. При этом в реальности противоречий они есть лишь в его методичке.
0xd34df00d
11.10.2021 05:27Он обвиняет сфинае как механизм интроспекции кода за то, что он ловит изменение семантики языка.
Нет, я обвиняю новый стандарт языка, что он меняет семантику кода так, что это не является ошибкой компиляции и проявляется только в рантайме. Разница понятна?
get_return_type(f);
Вы с таким пафосом рассказываете про плюсы, а в очередной раз как доходит до дела, так вы демонстрируете своё их незнание. SFINAE предназначен не только и не столько для вывода возвращаемых значений функции (хотя в до-C++11-ые времена так чаще всего делали SFINAE — обновите свои методички). И инты тут тоже ни при чём — вы даже не можете понять, что тут это аргумент конструктора, а не какое-то там возвращаемое значение.
Взял своё нелепое представление о sfinae. Т.е. для него это какая-то магия, которая непонятно что делает.
Да нет, как раз понятно что.
Просто идея использовать SFINAE для выбора функций, и оставлять это не на задворках плюсового фольклора (как та известная тема с компилтайм-счётчиками), а добавлять фичи в стандарт для этого, рекомендовать это, и так далее — она, ну, она плохая. Ровно потому, что потом становится тяжело расширять язык, чтобы не сломать ненароком старый код, который при этом, замечу, абсолютно валиден.
Комитет сам себе выстрелил тут в ногу. Очередной кусок известной субстанции брошен на стену, вроде прилипло — ну и хорошо, принимаем в стандарт. А что там будет через 5-10-15 лет — а да и пофигу.
ncwca
11.10.2021 05:58-2SFINAE предназначен не только и не столько для вывода возвращаемых значений функции (хотя в до-C++11-ые времена так чаще всего делали SFINAE — обновите свои методички).
На этом можно закончить. Здесь без диагноза не обойтись.
Читаем что я писал:
Представьте что у вас есть механизм возвращающий тип возврата функции, допусти get_return_type(f);
И что перед этим:
Но даже максимально далёкий от C++ человек знает чем по сути является sfinae в данном контексте - это механизм интроспекции кода.
Здесь где-то сказано, что сфинае является неким механизмом, механизмом А. Далее я сообщил, что представим, что есть другой механизм, возвращающий тип возврата функции. Я привёл в пример другой механизм, которого даже в C++ не существует, потому как функция в C++ не может возвращать тип. И в принципе такого механизма нет, даже если бы и могли.
Далее там даже есть:
Как в ситуации get_return_type(foo)
Здесь идёт явно противопоставление двух ситуаций. Т.е. никаким образом имея хоть что-то в голове невозможно вывести то, что я где-то связывал эти два явления и сообщал о том, что get_return_type это сфинае.
Он просто несёт рандомную херню. Максимальную чушь.
0xd34df00d
11.10.2021 06:34Так про то и речь — ваши примеры не имеют никакого смысла и являются прямой подменой тезиса.
На этом можно закончить. Здесь без диагноза не обойтись.
То есть, как это всё работало до C++11, вы не знаете? Ну ок, буду иметь в виду и не буду приводить смущающие вас примеры, хорошо.
Он просто несёт рандомную херню. Максимальную чушь.
У вас котёнкодверцевые аналогии, чего вы хотели?
ncwca
11.10.2021 07:10-2Так про то и речь — ваши примеры не имеют никакого смысла и являются прямой подменой тезиса.
Ну зачем же так позориться. Я понимаю, что группа поддержки меня заминусует в любом случае, а никто даже разбираться не будет, но.
Если они являются подменой и смысла не имеют, то зачем вы наделяли их смыслов, утверждая, что что я утверждал "вывод типа возврата - это сфинае". Как так вышло? Вначале было одно, а когда я доказал несостоятельность этих обвинений вдруг смысл потерялся? Как же так?
Далее пошла типичная игра в отрицание. Примеры не примеры. "вы всё врёти" и прочие куллстори. Почему, в чём? Он попытался один раз, не смог и всё? Можно об этом забыть.
Мой пример максимально корректен. Именно поэтому против него ничего не выдвигается. Только нелепые оправдания.
То есть, как это всё работало до C++11, вы не знаете? Ну ок, буду иметь в виду и не буду приводить смущающие вас примеры, хорошо.
Типичная методичка "да ты ничего не знаешь". Самое интересное, что вначале он рассказывал "да оно никак не связано", теперь вдруг начал уже доказывать связь. Там нужно определиться. Есть связь, либо нет.
К тому же, даже если бы там была какая-то связь - её нет. Это не более чем нелепая попытка придумать оправдание. Потому что пример взят отдельный. Никакой связи не предполагающий. Любы попытки вывести эту связь - мало того, что не имеют смысла - являются не более чем попыткой забалтывания.
У вас котёнкодверцевые аналогии, чего вы хотели?
Да, да. Это оказывается я виноват в том, что он нёс чушь. Для тех, кто хочет поиграться может задать ему вопрос "если ты утверждаешь, что связь есть. Ты её нашёл потому что мои аналогии плохи - продемонстрируй ту логическую цепочку, которая привела тебя к "вывод типа возврата - сфина"?".
Я вам уверяю - он тут же потеряется. Потому что ответа нет и быть не может. Он просто приучен нести любую херню, потому что есть группа поддержки которая будет мня минусовать в любом случае, а его плюсовать в любом случае.
Поэтому он будет орать "идиот" и прочее, обвиняя меня в том, что я назвал его "адептом" и это его оскорбило. Да.
0xd34df00d
11.10.2021 07:41+1Если они являются подменой и смысла не имеют, то зачем вы наделяли их смыслов, утверждая, что что я утверждал "вывод типа возврата — это сфинае".
Это не наделяет их смыслом. Невозможно наделить смыслом то, чего нет. Игра в демагогию и софистику.
Самое интересное, что вначале он рассказывал "да оно никак не связано", теперь вдруг начал уже доказывать связь. Там нужно определиться. Есть связь, либо нет.
А связи нет. Но связь, которая есть, очень простая. Он где-то что-то слышал про SFINAE и побежал в гугл искать про SFINAE. Нагуглился туториал из бородатого 2003-го. «О, тут что-то про возвращаемые типы, енамы какие-то, это сложно, многоточия ещё, ну его, а вот типы я понимаю, напишу ща про функцию с возвращаемым типом!» И бросился писать за клавиатуру о возвращаемых типах. Надо что-то указать, что-то совершенно абсурдное, ведь только абсурдными аналогиями плюсофанатик по своим методичкам может обосновать свою пропагандистскую позицию.
Ты её нашёл потому что мои аналогии плохи — продемонстрируй ту логическую цепочку, которая привела тебя к "вывод типа возврата — сфина"?".
Я доказал, что смысла и логики в ваших словах нет, как я могу привести логическую цепочку, кусочком которой это являлось бы?
Он просто приучен нести любую херню
Я просто тренирую нейросеть :]
eao197
11.10.2021 07:10А разгадка проста —
безблагодатностьпроцесс разработки языка C++ не имеет ни плана, ни теоретических основ под собойЭта фраза, а так же высказанные ране вами надежды о том, что C++ сдохнет в ближайшие 15 лет, наводят на мысли, что сильно оторваны от реальной жизни и тупо не понимаете как все развивается вне вашего уютного манямирка.
0xd34df00d
11.10.2021 07:34+2Мне казалось, было очевидно, что я в том комментарии говорил о хаскеле, так как отвечал на комментарий, упоминавший только хаскель, поэтому с интерпретацией «он» не должно было быть проблем, однако вы их (эти проблемы) нашли.
Как вы на плюсах с таким отношением к указателям пишете?
Впрочем, мне было бы интересно услышать про теоретические основы, лежащие в, ээ, основе языка C++.
eao197
11.10.2021 07:45-1Мне казалось, было очевидно, что я в том комментарии говорил о хаскеле
Вам казалось.
Вы когда будете другим людям что-то писать, то постарайтесь думать о том, а смогут ли эти другие люди вас понять. Не все настолько умны, как вы, кто-то и "от сохи". Кроме того, вы неспособны держать контекст разговора глубже одного предыдущего сообщения, поэтому вам кажется, что ваш комментарий можно трактовать только относительно Haskell-я.
Так вы, оказывается, в течении 15 лет предрекали смерть Haskell-ю? Вот это поворот.
Впрочем, мне было бы интересно услышать про теоретические основы, лежащие в, ээ, основе языка C++.
Вы правильно дали характеристику процессу развития C++. Но, похоже, что вы считаете, что на практике должно было бы быть по другому. И в этом как раз ваша оторванность от жизни. В случае с действительно востребованными языками, да еще и применяющимися для столь широкого спектра задач, так не бывает. Да и не может быть.
0xd34df00d
11.10.2021 07:55+1Так вы, оказывается, в течении 15 лет предрекали смерть Haskell-ю? Вот это поворот.
Это вряд ли, 15 лет назад я про него и не слышал. Но смерть я предрекаю последние года два-три, да (но при этом всё равно считаю, что это на порядки лучше ваших плюсов).
Вы правильно дали характеристику процессу развития C++. Но, похоже, что вы считаете, что на практике должно было бы быть по другому.
Не должно быть никак на практике. Долженствование подразумевает некоторую объективное благо, а его нет.
Просто, ну, есть некоторые процессы, и есть их закономерные результаты. Закономерный результат процесса развития плюсов — что язык становится практически невозможно развивать без ломания старого кода. В этом тоже нет ничего плохого — я вот агду минорно обновил с 2.6.1 на 2.6.2, и у меня две леммы отвалились, пришлось передоказывать. Но плюсы-то вроде как стремятся этого избегать. А, тьфу ты, кстати, да, аналогия-то некорректная, леммы ведь в компилтайме отвалились, но неважно.
Наверное, естественный путь — сколько-то эволюционировать, сколько-то быть на пике, а потом уступить дорогу молодым.
eao197
11.10.2021 08:11-1Но смерть я предрекаю последние года два-три, да (но при этом всё равно считаю, что это на порядки лучше ваших плюсов).
Полагаю, в вашей вселенной нормально говорить, что плюсы говно по сравнению с языком, который по вашему же мнению, должен сдохнуть.
Это как если бы фермер рассматривал несколько моделей тракторов перед покупкой. И тут некий разочарованный жизнью эксперт говорит "Вот это откровенное говно. А вот этот сильно получше, но его производителю я сам желаю сдохнуть в течении ближайших лет". При этом фермеру нужно чтобы этот трактор, минимум, лет 15 проработал, а потом еще лет 15 для него должны быть запчасти на рынке.
Закономерный результат процесса развития плюсов — что язык становится практически невозможно развивать без ломания старого кода.
Это уже было при принятии C++98 и C++11.
Наверное, естественный путь — сколько-то эволюционировать, сколько-то быть на пике, а потом уступить дорогу молодым.
Вот я и говорю, вы имеете слабое представление о том, как события развиваются в реальной жизни.
0xd34df00d
11.10.2021 08:26+1Полагаю, в вашей вселенной нормально говорить, что плюсы говно по сравнению с языком, который по вашему же мнению, должен сдохнуть.
Не понимаю вашего удивления. Ровно поэтому на плюсах я перестал писать совсем, а на хаскеле что-то иногда пописываю.
Это как если бы фермер [...]
Странная аналогия, ну да ладно. Других тракторов-то либо просто нет, либо за ними надо ехать на другой конец страны. Проще купить сейчас, а там посмотрим, что будет.
Или вы серьёзно учите один язык раз в 15 лет?
А вот этот сильно получше, но его производителю я сам желаю сдохнуть в течении ближайших лет
Отдельно отмечу, что я не желаю никому сдохнуть. Я желаю, чтобы появились и развились более годные альтернативы, и чтобы язык скатился в нишу легаси прочих специфичных вещей как следствие, а не сам по себе.
Вот я и говорю, вы имеете слабое представление о том, как события развиваются в реальной жизни.
Один тут уже меня томит рассказами про полиморфизм, так хоть вы не томите, расскажите, как оно на самом деле. И, особенно, почему плюсы не уступят эту самую дорогу в обозримом будущем для любого нового проекта, если вычесть фактор «у нас легаси-система на плюсах», «менеджмент стремается юзать не-плюсы» и «я уже знаю плюсы, а $lang — скриптуха, даже изучать не буду».
eao197
11.10.2021 08:37-1Не понимаю вашего удивления.
Это потому, что мы по разному на мир смотрим.
Или вы серьёзно учите один язык раз в 15 лет?
Я не вижу смысла учить язык просто ради того, чтобы учить язык. Языки -- это инструменты, которые с разной степени годности подходят к той или иной предметной области. Если мне нужно сделать проект в новой предметной области и я вижу, что мой текущий набор инструментов не подходит, то тогда озабочусь поиском новых. Либо, если буду видеть, что в моей же области появились подходы, которые ускоряют и удешевляют разработку, то это повод изучить что-то новое.
Я желаю, чтобы появились и развились более годные альтернативы, и чтобы язык скатился в нишу легаси прочих специфичных вещей как следствие, а не сам по себе.
Это какие-то тонкие различия в цветах и запахах известной субстанции.
хоть вы не томите, расскажите, как оно на самом деле
На самом деле вы сильно недооцениваете a) фактор наличия легаси и b) человеческий фактор.
По поводу человеческого фактора буквально на днях мне попался хороший доклад о том, как оно бывает на самом-то деле: https://www.youtube.com/watch?v=7EMhj8B2V4YИменно так и происходит, когда обычные люди решают обычные задачи посредством привычных инструментов за обычную зарплату работая на дядю.
0xd34df00d
11.10.2021 08:50+2Я не вижу смысла учить язык просто ради того, чтобы учить язык.
Новые языки дают новые точки зрения на разработку ПО (или на формальные доказательства, или на что хотите, смотря какие языки). Это расширение кругозора, это полезно.
Если мне нужно сделать проект в новой предметной области и я вижу, что мой текущий набор инструментов не подходит, то тогда озабочусь поиском новых. Либо, если буду видеть, что в моей же области появились подходы, которые ускоряют и удешевляют разработку, то это повод изучить что-то новое.
Так для того, чтобы это всё увидеть достаточно рано, нужно ковырять другие языки.
Для того, чтобы понять, что писать компиляторы-тайпчекеры на плюсах — не лучшая идея, мне потребовалось написать игрушечный язык на другом языке. Для того, чтобы понять, что доказывать некоторые вещи на идрисе — не лучшая идея, мне потребовалось пописать (и почитать) немного кода на агде.
Это какие-то тонкие различия в цветах и запахах известной субстанции.
Ну это как разница между «я хочу кушать» и «я хочу идти в магазин за едой».
На самом деле вы сильно недооцениваете a) фактор наличия легаси и b) человеческий фактор.
Понятно, что они есть, но мы же вольны выбирать, с кем мы работаем. Практика показывает, что чем меньше легаси и человеческого фактора, тем интереснее работать.
Но, конечно, у всех разные представления об интересе, и что интересно мне, может быть неинтересно вам, и наоборот. Правда, моя личная практика показывает, что тем, кому неинтересны всякие языки, зачастую неинтересны и новые стандарты.
eao197
11.10.2021 09:02-1Новые языки дают новые точки зрения на разработку ПО
Побочным эффектом, например, могут стать попытки писать на C++, как на Haskell-е. Неокрепшие умы не всегда понимают, что подходы из одного языка нельзя бездумно переносить на другие языки.
Собственно, ваше разочарование плюсами является лишним тому подтверждением.
Так для того, чтобы это всё увидеть достаточно рано, нужно ковырять другие языки.
Ковырять не значит учить.
Для того, чтобы понять, что писать компиляторы-тайпчекеры на плюсах — не лучшая идея, мне потребовалось написать игрушечный язык на другом языке.
А большинству C++разработчиков и не приходится тайп-чекеры на плюсах писать, прикиньте. Ну вот вообще.
Понятно, что они есть, но мы же вольны выбирать, с кем мы работаем. Практика показывает, что чем меньше легаси и человеческого фактора, тем интереснее работать.
Это до тех пор, пока вам интересно порхать с места на место. Но даже в таком случае рано или поздно вы можете дорасти до человека, на котором лежит ответственность за большой и существующий продукт. Который у вас никогда не будет возможности полностью переписать ни на чем другом. Но который уже приносит прибыль и должен будет приносить прибыль и дальше.
А может быть вы когда-нибудь сами станете владельцем собственного продукта, в который вы вложите кучу собственного времени и кучу собственных денег. И у вас будет четкое осознание того, что нельзя это вот так вот просто переписать с языка X на язык Y просто потому, что язык Y сейчас более привлекателен, чем X.
0xd34df00d
11.10.2021 10:07+2Побочным эффектом, например, могут стать попытки писать на C++, как на Haskell-е. Неокрепшие умы не всегда понимают, что подходы из одного языка нельзя бездумно переносить на другие языки.
Ну это уже что-то сорокинское. Нельзя народ наш-богоносец выбором смущать!
Собственно, ваше разочарование плюсами является лишним тому подтверждением.
Только писал я на них до этого под два десятка лет, за деньги — больше десятка. Ну как-то не оч влазит в вашу теорию.
А большинству C++разработчиков и не приходится тайп-чекеры на плюсах писать, прикиньте. Ну вот вообще.
Предыдущие наши попытки выяснить, что же пишет большинство разработчиков, закончились не очень удачно, ну да ладно.
А может быть вы когда-нибудь сами станете владельцем собственного продукта, в который вы вложите кучу собственного времени и кучу собственных денег. И у вас будет четкое осознание того, что нельзя это вот так вот просто переписать с языка X на язык Y просто потому, что язык Y сейчас более привлекателен, чем X.
Вы подменяете тезис. Никто не говорит о том, чтобы бросаться и что-то переписывать, ни в коем случае. Речь исключительно о том, какой язык выбирать для нового проекта. И я, собственно, буду стараться выбирать язык под задачу, только и всего.
Соответственно, если этот проект изначально мой, то нет никаких проблем. А иначе вот это вот
Но даже в таком случае рано или поздно вы можете дорасти до человека, на котором лежит ответственность за большой и существующий продукт.
означает, что на вас навесили легаси (опционально с лычкой синиор легаси девелопера и специалиста по коре бизнес фиче). Не хотелось бы до такого дорасти.
eao197
11.10.2021 10:20-1Нельзя народ наш-богоносец выбором смущать!
Когда-то мне казалось, что нельзя быть умным идиотом. Но чем больше общаюсь со специалистами в интернете, тем больше убеждаюсь, что был сильно не прав.
Только писал я на них до этого под два десятка лет, за деньги — больше десятка. Ну как-то не оч влазит в вашу теорию.
Это вам так кажется. Ваш мир рухнул, когда вы увидели, что где-то не так, как в плюсах, а сделать в плюсах точно так же, у вас не выйдет ну никак. То, что вы до этого нормально жили в C++ двадцать лет не играет роли. Это могло быть и 5 лет, и 35 лет.
Предыдущие наши попытки выяснить, что же пишет большинство разработчиков, закончились не очень удачно, ну да ладно.
Таких попыток не было. Была попытка выяснить у вас, догнал ли Хаскель по востребованности/популярности хотя бы Руби, но вы ожидаемо слились.
Вы подменяете тезис.
Вам так кажется.
Речь исключительно о том, какой язык выбирать для нового проекта.
Вы всерьез считаете, что новые все проекты стартуют с полного нуля без опоры на то, что эта же команда (или ключевые люди из команды) делали раньше?
Да полноте, нельзя же быть настолько оторванным от жизни вне темы возможностей языков программирования.
И я, собственно, буду стараться выбирать язык под задачу, только и всего.
Ну вот у вас была задача сделать HTTP-прокси. Появилась задача сделать SMTP-прокси. Которая сменилась задачей сделать BGP-прокси. А потом появилась задача сделать проксирующую обертку вокруг ODBC-драйвера.
Вы правда думаете, что это все настолько разные задачи, чтобы выбирать принципиально разные ЯП?
Или вы считаете, что только вы настолько умны, чтобы понимать, что C++ вряд ли будет хорош для написания компилятора какого-то узкоспециализированного языка, а Ruby вряд ли будет хорош для тяжелых вычислений на HPC кластере? Нет, правда?
означает, что на вас навесили легаси (опционально с лычкой синиор легаси девелопера и специалиста по коре бизнес фиче).
Или то, что вы выросли из разработчика в руководители разработки. И на вас навесили лычки менеджера.
Другой вопрос нужно ли это лично вам. Но кому-то из нынешних разработчиков это точно нужно. А у кого-то это может произойти и без особого желания.
Не хотелось бы до такого дорасти.
Тут уж выбор ваш. Но вот те, кто дорастут, они и будут принимать окончательное решение, какие технологии будут использоваться.
0xd34df00d
11.10.2021 19:39+2Когда-то мне казалось, что нельзя быть умным идиотом. Но чем больше общаюсь со специалистами в интернете, тем больше убеждаюсь, что был сильно не прав.
Вы говорите, что в изучении новых языков есть негативный побочный эффект — люди не смогут с тем же удовольствием писать на старых, выгорят и уйдут. Как ещё это интерпретировать?
Это вам так кажется. Ваш мир рухнул, когда вы увидели, что где-то не так, как в плюсах, а сделать в плюсах точно так же, у вас не выйдет ну никак. То, что вы до этого нормально жили в C++ двадцать лет не играет роли. Это могло быть и 5 лет, и 35 лет.
Из вас телепат тоже так себе.
Поначалу я писал код с низкой
социальнойответственностью — сначала это был вообще личный попенсорс, потом — какие-то вычислительные мелкие штуки, какой-то proof of concept NLP-движка для стартапа, всякое такое, и на первые лет 10-12 этого хватало. Ну упадёт, ну и хрен с ним, потом починим.Потом я устроился на работу в большую-большую финансовую компанию (которая, кстати, весьма представлена в Комитете, ну да ладно), и там от падения кода была печаль, звонки в три ночи и всё такое. Мне это не очень понравилось, но уровень среднего программиста там был, если честно, так себе, поэтому то, что стабильный код, которому можно доверять, писать не получается, меня не удивляло.
Однако, потом я устроился на работу во всякий трейдинг, где были одни из топовых людей, с которыми я вообще общался, и у них тоже что-то периодически падало, ломалось, и, короче, не получалось писать стабильный код, которому можно доверять. А ещё я там и в language lawyer'изм ударился, потому что несколько болезненных багов после апгрейда компилятора неделями пришлось отлавливать, когда новые версии начали оптимизировать чуть более агрессивно.
И тогда на меня как-то снизошло осознание, что на плюсах вообще, патологически невозможно писать код, которому можно было бы доверять, у которого не стрёмно было бы обновлять компилятор, и так далее. Для этого нужны сверхлюди и сверхресурсы.Так что дело не в том, что на хаскеле я могу там какими-то значочками сократить что-то и тут красиво применить анаморфизм, а там — катаморфизм, а в плюсах — не могу. Дело в том, что в плюсах я просто не могу доверять коду и себе. Впрочем, в каком-то смысле вы правы — в хаскеле-то я могу доверять коду и себе чуть больше, поэтому, конечно, в каком-то смысле это попадает под ваше «не получилось писать как на хаскеле». Но не думаю, что это плохо.
Была попытка выяснить у вас, догнал ли Хаскель по востребованности/популярности хотя бы Руби, но вы ожидаемо слились.
Ну как хотите.
Ваша логика: если хаскель не догнал руби, то он заведомо нинужно. Это значит, что вы считаете, что догнать руби — это необходимое условие того, чтобы язык воспринимать серьёзно. Но плюсы тоже не догнали руби (ну, вернее, упали позади них), что значит, что плюсы тоже нельзя воспринимать серьёзно. Так как воспринимать серьёзно всё-таки можно, это значит, что ваш аргумент бредов.
Вы всерьез считаете, что новые все проекты стартуют с полного нуля без опоры на то, что эта же команда (или ключевые люди из команды) делали раньше?
Ну вот у меня был проект по DSL'ю для того же трейдинга — там одни плюсисты были, но вполне норм мне было взять и начать делать его на хаскеле, потому что компиляторы и прочие кодогенераторы проще делать на хаскеле, и все это понимали. В чём тут проблема?
Или то, что вы выросли из разработчика в руководители разработки. И на вас навесили лычки менеджера.
Как только разговор пойдёт о навешивании этой лычки, я уволюсь нафиг. Спасибо, не хочу быть менеджером.
Тут уж выбор ваш. Но вот те, кто дорастут, они и будут принимать окончательное решение, какие технологии будут использоваться.
Вы забываете, что у меня тоже есть выбор, на кого работать.
eao197
11.10.2021 21:23-2Вы говорите, что в изучении новых языков есть негативный побочный эффект — люди не смогут с тем же удовольствием писать на старых, выгорят и уйдут. Как ещё это интерпретировать?
Так, что вы не понимаете о чем речь. А речь не об удовольствии, а о том, что написанный такими любителями прекрасного, в лучшем случае не будет понятен другим членам команды. В худшем -- будет жрать память, или CPU, или компилироваться 10 минут вместо 10 секунд.
Из вас телепат тоже так себе.
Пока что вы ведете себя именно так, как и ожидается.
Сотни команд (если не тысячи) пишут на С++ софт, работающий и в в 24/7, и в mission-critical. И все сталкиваются с такими же проблемами, как и вы. Ничего, справляются как-то, не пишут пространные простыни про выгорание, не прибегают затем в комментарии рассказать как им C++ нагадил в шаровары.
К слову, я больше 10 лет работал в условиях, когда могли поднять среди ночи (и поднимали). Так что вы не единственный, кто имеет такой опыт.
Ваша логика: если хаскель не догнал руби, то он заведомо нинужно.
Моя логика: Хаскель мало кому нужен, поэтому пример со скоростью работы написанного на Хаскеле компилятора мало кому интересен, значит не показателен. Ну или вы таки сможете развеять мои сомнения на счет популярности Хаскеля.
В чём тут проблема?
ХЗ, вы стали говорить не пойми что. Я вам про то, что если сейчас выбирают C++ для новых проектов, то вовсе не потому, что люди больше ничего другого не знают или не имеют выбора. А вот что вы мне в ответ -- не понятно.
Как и пассаж про то, что если C++ менее популярен, чем Ruby, то C++ не следует рассматривать. Здесь статья про C++. Поэтому здесь С++ изначально в центре внимания.
Вы забываете, что у меня тоже есть выбор, на кого работать.
Да уже пофиг на вас, право слово.
0xd34df00d
12.10.2021 04:28+2А речь не об удовольствии, а о том, что написанный такими любителями прекрасного, в лучшем случае не будет понятен другим членам команды. В худшем — будет жрать память, или CPU, или компилироваться 10 минут вместо 10 секунд.
Это верно вообще для любого языка. Я видел код от новичков в C++ (или от датасайентистов, которые кроме питона ничего не трогали), который обладал всеми этими свойствами.
Сотни команд (если не тысячи) пишут на С++ софт, работающий и в в 24/7, и в mission-critical. И все сталкиваются с такими же проблемами, как и вы. Ничего, справляются как-то
Ага, знаем, как. Не обновляют компиляторы никогда, например (и до сих пор сидят на C++03), собирают код с
-O0(иначе тупой бажный компилятор ломает их гениальный код), имеют совершенно безумные time to market, и так далее.Спасибо, но я не хочу так жить.
К слову, я больше 10 лет работал в условиях, когда могли поднять среди ночи (и поднимали). Так что вы не единственный, кто имеет такой опыт.
И как, понравилось? Мне — не очень.
Моя логика
Стоп, давайте по маленьким шажкам. Ваш вопрос про ruby был к чему?
Я вам про то, что если сейчас выбирают C++ для новых проектов, то вовсе не потому, что люди больше ничего другого не знают или не имеют выбора.
А дальше какие-то магические пасы руками и экивоки в сторону «ну опираются же на прошлый опыт». Ага, очень понятно.
eao197
12.10.2021 07:25-1Это верно вообще для любого языка.
Именно. На C++ нужно писать как на C++, на Ruby -- как на Ruby, на Haskell -- как на Haskell. Попытки попрограммировать на языке X как на языке Y чреваты. Поэтому заявления о том, что "изучение других языков позволяет вам программировать лучше" не так однозначно, как это может показаться.
У изучения других языков есть другие достоинства, вроде расширения кругозора, тренировки мозгов и расширения бэкгроунда, за счет которого затем проще будет сменить инструментарий. Но вот говорить именно о том, что изучать X стоит чтобы лучше программировать на Y -- это не от большого ума, а скорее от отсутствия опыта.
Ага, знаем, как.
Отучаемся говорить за всех (c).
Спасибо, но я не хочу так жить.
Да с вами уже все понятно, лично вы уже нисколько не интересны. Включая даже ваши знания языков программирования.
И как, понравилось?
Нормально. Все проблемы были либо от недостаточного тестирования, либо от просчетов в организации техподдержки. Самый эпичный же звонок среди ночи был вызван проблемами в коде заказчика, который хотел свалить их на нас не желая разбираться с собственным кодом.
Ваше поведение напоминает попытку задать вопрос сантехнику "ну что, нравится тебе в говне копаться?" или автослесарю "ну что, нравится тебе, когда ты весь в масле?", или терапевту-стоматологу "ну что, нравиться тебе, когда приходится лечить пациентов с гнилыми зубами?"
Это издержки профессии, которые становятся известны вот буквально с первых дней (а некоторые можно предположить еще и до начала работы). И если вы, столкнувшись с реальностью, четко решили для себя, что этот мир не для вас, то нафига вы приносите свое драгоценное мнение в разговор сантехников, которые обсуждают как проще менять трубы канализации в хрущевке возрастом 40 лет?
Ваш вопрос про ruby был к чему?
Я сказал, что если бы мне нужно было написать компилятор, к которому были бы серьезные требования к производительности и/или ресурсоемкости, то тогда бы рассмотрел C++ в качестве варианта.
На что вы привели в пример компиляторы Idris-а и Haskell-я.
На это я сказал, что оба эти языка мало кому нужны, поэтому приведение их в пример может быть интересно разве что если тот же Haskell догнал по популярности/востребованности хотя бы Ruby.
А дальше какие-то магические пасы руками и экивоки в сторону «ну опираются же на прошлый опыт». Ага, очень понятно.
Ну что ж поделать. Вы демонстрируете удивительную способность не понимать простых вещей как только разговор перемещается за пределы языков программирования.
0xd34df00d
12.10.2021 08:12+3У изучения других языков есть другие достоинства, вроде расширения кругозора, тренировки мозгов и расширения бэкгроунда, за счет которого затем проще будет сменить инструментарий. Но вот говорить именно о том, что изучать X стоит чтобы лучше программировать на Y — это не от большого ума, а скорее от отсутствия опыта.
Но ведь это правда так, потому что это формирует более полную картину мира, так сказать. А писать неэффективный код на плюсах можно хоть после хаскеля, хоть после Александреску.
Это издержки профессии, которые становятся известны вот буквально с первых дней (а некоторые можно предположить еще и до начала работы). И если вы, столкнувшись с реальностью, четко решили для себя, что этот мир не для вас, то нафига вы приносите свое драгоценное мнение в разговор сантехников, которые обсуждают как проще менять трубы канализации в хрущевке возрастом 40 лет?
Да потому что эти сантехники разве что не гордятся, что они по колено в говне, и не делают ничего для того, чтобы этого говна в их жизни было меньше.
если тот же Haskell догнал по популярности/востребованности хотя бы Ruby.
Я повторяю в сотый раз — ок, хаскель не догнал руби, хаскель нинужен, замечательно. Но и плюсы тоже уступили ruby, плюсы теперь тоже не нужны? Или это очень выборочный критерий и применяется только к тем языкам, которые вам не нравятся?
eao197
12.10.2021 08:28-1Но ведь это правда так, потому что это формирует более полную картину мира, так сказать.
Это половина правды, вот в чем проблема. А может и не половина, а меньше.
А писать неэффективный код на плюсах можно хоть после хаскеля, хоть после Александреску.
Неэффективность -- это только часть проблемы, далеко не самая страшная. Гораздо страшнее, когда написанный любителем прекрасного код не воспринимается коллегами. Вплоть до заявлений "я эти испражнения в прекрасном сопровождать не буду".
А да, вас же проблемы менеджмента не интересуют. Вы же когда с таким говном столкнетесь, то просто смените место работы. А решения о том, что делать с тем, что уже есть, но переписать с нуля невозможно, придется применять людям с менее тонкой душевной организацией.
и не делают ничего для того, чтобы этого говна в их жизни было меньше.
Сантехники делают свою работу. Просто она изначально связана с говном в трубах и говна этого меньше не становится, и не может.
Так же и C++ники: да, говна вокруг полно, да, особо заменить пока нечем (было), да, стараемся выбраться из этого с минимальными потерями. Обычная работа, кто-то и ее должен делать.
Но и плюсы тоже уступили ruby, плюсы теперь тоже не нужны?
В большинстве случаев -- не нужны. Но там, где они еще нужны, там противопоставлять плюсам Хаскель несколько странно.
Еще более странно кивать в сторону Хаскеля в разговоре о том, как можно сделать будущую версию C++ лучше. Особенно если кивки эти из категории "пусть сдохнут оба и чем быстрее, тем лучше".
0xd34df00d
12.10.2021 20:44+3Гораздо страшнее, когда написанный любителем прекрасного код не воспринимается коллегами. Вплоть до заявлений "я эти испражнения в прекрасном сопровождать не буду".
И это снова верно для Александреску. Или если вы вдруг обчитаетесь раннего Саттера и начнёте везде угорать по exception safety, даже там, где это не надо. Что ж теперь, не читать их?
Вы же когда с таким говном столкнетесь, то просто смените место работы. А решения о том, что делать с тем, что уже есть, но переписать с нуля невозможно, придется применять людям с менее тонкой душевной организацией.
Легаси, QED.
Так же и C++ники: да, говна вокруг полно, да, особо заменить пока нечем (было), да, стараемся выбраться из этого с минимальными потерями. Обычная работа, кто-то и ее должен делать.
Если бы мне кто 15-20 лет назад сказал, что на плюсах принципиально невозможно писать код, которому можно доверять, то я бы действительно некоторые решения в жизни принял бы иначе.
Antervis
11.10.2021 19:59-1Это не то же самое, что поднять любую ошибку компиляции на уровень софтовых ошибок.
это даже не просто "абсолютно то же самое", это блин "оно самое". Вы буквально говорите о коде, поведение которого зависит от наличия ошибки компиляции определенного сниппета.
Почему нельзя было сразу использовать обычные скобочки для инициализации всего?
Надо было обойти MVP
На всякий случай переспрошу — вы серьёзно утверждаете, что <мина через ifdef> и SFINAE по <просто самый обычный SFINAE, никакого "по"> — это вещи одного порядка?
да, я серьезно это утверждаю. И единственная причина почему вам кажется это абсурдным - вы совершенно не понимаете/принимаете мою аргументацию. Ладно, давайте еще раз попробуем, вот вы вроде в ладах с математикой там, формальной логикой, верно? Аксиома A: SFINAE позволяет проверить примерно любую языковую конструкцию на компилируемость. Аксиома B: изменения в языке ведут к изменению компилируемости тех или иных языковых конструкций. Из B следует C: для любого изменения языка может существовать такая конструкция, поведение которой поменяется, тоже аксиома. Из A и C следует, что для любого изменения языка может существовать такая SFINAE проверка, поведение которой поменяется. Еще раз: для любого изменения. Соответственно, чтобы не ломать совсем никакой код, нужно всего навсего не менять язык. А еще компилятор и среду исполнения. Всё это вы можете организовать для себя сами.
Единственный способ обойти это, как я уже сказал, эпохи, механизм, который отсутствует не только в с++.
0xd34df00d
12.10.2021 04:24+2это даже не просто "абсолютно то же самое", это блин "оно самое"
Очевидно, что нет. SFINAE не проверяет тела функций, например, и ошибка в теле функции даже в SFINAE-контексте (или какой там правильный термин) будет hard error.
Надо было обойти MVP
MVP работает только для академических языков. Для языков, которые предполагается использовать в продакшене, «ну мы тут выкатим MVP и посмотрим, а там переделаем, если что» — это какой-то бред.
Аксиома A: SFINAE позволяет проверить примерно любую языковую конструкцию на компилируемость.
Неверно:
template<typename T, typename = int T> void foo()является жёсткой ошибкой. Поэтому, кстати, добавление фичи, которая сделает
int Tкорректным выражением в этом контексте (что бы оно ни значило) заведомо не сломает никакой существующий компилируемый код.Вы, конечно, можете сказать, что для конструкции нужно больше слов, в decltype там её завернуть (но здесь это не поможет), и так далее, но тогда я попрошу вас дать алгоритм построения SFINAE-выражения, проверяющего любое данное выражение на компилируемость.
Из A и C следует, что для любого изменения языка может существовать такая SFINAE проверка, поведение которой поменяется.
Кстати, само по себе интересный тезис. Покажете SFINAE-проверку на валидность конструкции
explicit(boolean-expr), поведение которой сломается при апгрейде с C++17 на C++20?
technic93
12.10.2021 10:21+1Вроде мы уже договорились что это не имеет отношения к обновлению 17 до 20. Т.е. просто добавили ещё один конструктор неявный, такая же проблема была бы при добавлении любого метода
if constexpr (requires { vec.foo(); }) { // this is ok because vector doesn't have method foo trigger_ub(); }Но да, с инициализацией в старых плюсах перемудрили, похоже что была смесь из кастрированных си агрегатов и конструкторов. Если мы хотим теперь пофиксить это не меняя поведения, то единственный вариант это ввести новое ключевое слово для новой универсальной инициализации, что тоже не прикольно. Хотя по итогу это опять нифига не универсально потому что я не могу сделать
make_unique(.x = 10, .y = 20).Собственно даже была пометка к этому изменению (p0960) что мол ломает ваш пример со сфинае. Но какой-то список потенциальных проблем походу комитет не ведёт, а надо бы.
А вообще не может ли быть такой ситуции в другом языке, где есть специализация, и какой-то
derivingили макрос стал добавлять новую реализацию к классу, и в результате перегрузка по этой реализации изменилась для этого класса?
0xd34df00d
12.10.2021 20:09+1Вроде мы уже договорились что это не имеет отношения к обновлению 17 до 20. Т.е. просто добавили ещё один конструктор неявный, такая же проблема была бы при добавлении любого метода
У меня нет проблем с тем, что стандарт добавляет новые методы в код, которым владеет стандарт (то есть, в стандартную библиотеку). Но лично меня немного смутило бы, если бы стандарт добавил новые методы в код, которым владею я. А вас?
А вообще не может ли быть такой ситуции в другом языке, где есть специализация, и какой-то deriving или макрос стал добавлять новую реализацию к классу, и в результате перегрузка по этой реализации изменилась для этого класса?
Обратите внимание — пользовательский код поменялся, а не стандарт языка. Принципиальная разница.
technic93
12.10.2021 21:47пользовательский код поменялся
Так я имею ввиду не пользовательский код как раз, а макрос какой-то из библиотеки. Как работает derive я не знаю. (Кстати как он работает? не смог найти простыми словами).
добавил новые методы в код, которым владею
Да, тут более неявно, потому что конструкторы генерируются автоматически в ряде случаев. Но даже если бы они генерировались бы более явно, через какой аттрибут
[[std::define_aggregate_constructors]], тогда это уже код которым вы владете или сдт-либа?
Antervis
12.10.2021 11:24+1Очевидно, что нет. SFINAE не проверяет тела функций, например, и ошибка в теле функции даже в SFINAE-контексте (или какой там правильный термин) будет hard error.
SFINAE проверяет ровно то, что передали в контекст подстановки. Если в этом контексте есть ошибка - подстановка провалится.
MVP работает только для академических языков. Для языков, которые предполагается использовать в продакшене, «ну мы тут выкатим MVP и посмотрим, а там переделаем, если что» — это какой-то бред.
это не тот mvp который вы ищете, я про most vexing parse.
Неверно: <blablabla> является жёсткой ошибкой
Покажете SFINAE-проверку на валидность конструкции
explicit(boolean-expr)вы опять невнимательно прочитали, причем, шутки ради, тот кусок, который сами же и процитировали. Давайте еще раз: "Аксиома A: SFINAE позволяет проверить примерно любую языковую конструкцию на компилируемость". Я конечно сам виноват, опять опустил пару казалось бы очевидных вещей, но уход в глубокие частности, не имеющие абсолютно никакого отношения к контексту спора, вас никак не красит и доказать вашу точку зрения не помогает. Разница между "начала компилироваться конструкция
S(1)" и "начала компилироваться конструкцияint T" не так существенна, как вы пытаетесь выдать. Как минимум потому, что ограничивать изменения языка по принципу покрытия SFINAE глупо. Особенно когда ваш пример проблемы построен на некорректном предусловии.
0xd34df00d
12.10.2021 20:14+2SFINAE проверяет ровно то, что передали в контекст подстановки. Если в этом контексте есть ошибка — подстановка провалится.
Нет.
template<typename T> auto foo() { return typename T::inner {}; } template<typename T, typename = decltype(foo<T>())> bool sfinae(int) { return true; } template<typename T> bool sfinae(float) { return false; } int main() { return sfinae<int>(0); }счастливо вам даст жёсткую ошибку, а не
return false;.это не тот mvp который вы ищете, я про most vexing parse.
А зачем его обходить? Поменяли бы поведение, мы ж уже выяснили, что это не проблема. Так бы заодно и начинающим удобнее было.
Аксиома A: SFINAE позволяет проверить примерно любую языковую конструкцию на компилируемость
Я не готов обсуждать аксиоматику с таким уровнем формализма.
Я конечно сам виноват, опять опустил пару казалось бы очевидных вещей, но уход в глубокие частности, не имеющие абсолютно никакого отношения к контексту спора, вас никак не красит и доказать вашу точку зрения не помогает.
Да нет, очень просто: новые синтаксические конструкции SFINAE добавлять не мешает. Сделайте новый синтаксис для инициализации поверх какого-нибудь
<| arg1, arg2, ... |>, и никакое имеющееся SFINAE никакую семантику тут не поймает.Как минимум потому, что ограничивать изменения языка по принципу покрытия SFINAE глупо.
Глупо одновременно пропагандировать SFINAE, требовать изменения компилируемости ранее синтаксически корректных конструкций и утверждать, что C++ заботится о сохранении поведения программ при смене стандарта. Эти три вещи несовместны, одну придётся вычеркнуть. Скажите, наконец, что C++ более не заботится о сохранении семантики программы при апгрейде, и не будет ни у кого никаких вопросов, в конце концов.
Antervis
12.10.2021 21:01У меня нет проблем с тем, что стандарт добавляет новые методы в код, которым владеет стандарт (то есть, в стандартную библиотеку). Но лично меня немного смутило бы, если бы стандарт добавил новые методы в код, которым владею я. А вас?
так пользовательский код зависит от стандартного... вот например в с++20 добавили
std::string::starts_with, а значит поменялся пользовательский код, диспатчащий по наличиюT::starts_with. Значит ли это, что метод не стоило добавлять?Нет. <сниппет> счастливо вам даст жёсткую ошибку, а не
return false;а в кошерном SFINAE
return false, как же так?А зачем его обходить? Поменяли бы поведение, мы ж уже выяснили, что это не проблема. Так бы заодно и начинающим удобнее было.
то, что вы где-то у себя выяснили, всё еще имеет весьма опосредственное и натянутое отношение к действительности.
Да нет, очень просто: новые синтаксические конструкции SFINAE добавлять не мешает
а изменения нужны, и не только посредством новых синтаксических конструкций. Вы очень старательно упускаете тот нюанс что в с++17
S(1)не компилировался.Эти три вещи несовместны, одну придётся вычеркнуть.
хорошо, одну вещь я таки наконец-то доказал, аллелуйа. Теперь осталось доказать что доля кода, поведение которого зависит от компилируемости будущих синтаксических конструкций, ничтожно мала, и вы будете еще на шаг ближе к пониманию истины.
Скажите, наконец, что C++ более не заботится о сохранении семантики программы при апгрейде, и не будет ни у кого никаких вопросов, в конце концов.
я утверждаю, что с++ обеспечивает тот уровень обратной совместимости, который можно сохранить попутно обновляя язык.
Я не готов обсуждать аксиоматику с таким уровнем формализма.
тогда поднимайте белый флаг
AnthonyMikh
12.10.2021 18:57+2MVP работает только для академических языков. Для языков, которые предполагается использовать в продакшене, «ну мы тут выкатим MVP и посмотрим, а там переделаем, если что» — это какой-то бред.
Для Rust и nightly как-то работает.
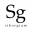
Siborgium
11.10.2021 10:38>> ломающую имеющийся код
А что вы хотели от релиза, в котором явно задекларировали решение сломать много и разом? Могли бы и еще больше сломать, жаль, не сломали.
Неужели кто-то обещал вам безболезненную миграцию? Решение о миграции принимали вы сами, решать возможные проблемы должны были быть готовы.
antoshkka Автор
11.10.2021 10:39+1Вы о каком релизе и о какой декларации говорите? Поделитесь пожалуйста ссылкой, я ни о чём подобном не слышал
Siborgium
11.10.2021 13:24+1Очевидно, речь про "релиз" (публикацию, если вам угодно -- в интернете "release" используется вполне успешно) С++20. Комментарий набирал в спешке, поэтому несколько раскрою.
Каждый новый стандарт изменяет язык, убирая некоторые его элементы и меняя поведение некоторых остающихся. Каждое такое изменение делает потенциально невозможным перенос кодовой базы на новый стандарт.
С++20 это "мажорный" релиз, в который вошло значительное число как принципиально новых (для языка) фич, так и изменений существующих [1]. Сравните, например, со списком изменений С++17 [2]. В каком-то смысле С++20 можно сравнить с С++11 по масштабу вносимых изменений.
В С++20 было предложено сломать ABI [3] [4]. Хотя комитет отклонил это предложение, у него (предложения) было много сторонников [5] [6]. Это, на мой взгляд, свидетельствует о натуре С++20 -- эта версия стандарта виделась как возможность разом реализовать накопившуюся потребность в изменениях. Реализовать до конца не получилось, но опять же, сравните масштабы С++17 и С++20.
Изменение, сломавшее кодовую базу @0xd34df00d, является побочным эффектом унификации фигурных и круглых скобок в конструкторах. Я регулярно использую try_emplace и emplace_back, и невозможность конструировать объекты так, как я конструировал бы их "руками" сильно раздражала.
И хотя я погорячился с "явно задекларировали", мысль вполне ясна -- С++20 просто обязан был сломать кодовую базу, и странно ожидать обратного.
[1] http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p2131r0.html
[2] https://isocpp.org/files/papers/p0636r0.html
[3] http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p2028r0.pdf
[4] http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p1863r1.pdf
0xd34df00d
11.10.2021 19:46+2Ещё раз, если упрощать ответ на ваш вопрос «что вы хотели» — я хочу, чтобы меня не будили в три ночи звонками о том, что прод упал.
Когда все изменения при апгрейде компилятора (или стандарта, неважно) выявляются в процессе компиляции, на моей рабочей машине, это норм, я этого ожидаю и я к этому готов. Когда мне после апгрейда с gcc 6 на gcc 9 потребовалось 2-4 недели вычищать gcc'измы, которые новым компилятором не воспринимались, меня это устраивало — я был к этому готов, делал это в рабочее время в комфорте рабочего кресла и отсутствии спешки. Более того, это было даже прикольно, потому что я узнал кое-что новое про некоторые крайние случаи поведения языка вроде особенностей интерпретации injected name в разных контекстах в шаблонных классах. Когда же поведение кода меняется по-тихому, и это невозможно выяснить на вашей рабочей машине, то это печально.
Не, можно, конечно, обложить всё тестами (включая то, что вызывается правильная функция, когда надо), но это уже питонизм какой-то. Компилятор нам боженька дал не для того, чтобы мы его работу дублировали подобным видом тестов.
Siborgium
13.10.2021 18:04+2> Когда мне после апгрейда с gcc 6 на gcc 9 потребовалось 2-4 недели вычищать gcc'измы, которые новым компилятором не воспринимались, меня это устраивало
>Когда же поведение кода меняется по-тихому, и это невозможно выяснить на вашей рабочей машине, то это печально.
Так это вас устраивает, или нет? Я спрашиваю, потому что с gcc 6 до gcc 9 было внесено достаточно изменений, молча меняющих поведение кода. Процитирую, например, изменение, внесенное в gcc 8:
>The value of the C++11
alignofoperator has been corrected to match C_Alignof(minimum alignment) rather than GNU__alignof__(preferred alignment); on ia32 targets this means thatalignof(double)is now 4 rather than 8. Code that wants the preferred alignment should use__alignof__instead.Обе эти цитаты описывают ситуацию, в которой поведение кода меняется по-тихому, просто в одном случае вы зависите от этого поведения, и поэтому это вас больно ударило, а в другом -- нет, и вы этого даже не заметили.

ncr
05.10.2021 13:53basic_string::resize_and_overwrite
Willing to solve this for string without solving it for vectorSF F N A SA 6 9 2 1 0
Рукалицо.
0# get_data_from_config(std::string_view) at /home/axolm/basic.cpp:600 1# bar(std::string_view) at /home/axolm/basic.cpp:6 2# main at /home/axolm/basic.cpp:17
А где вся эта роскошь (имена функций, файлов, номера строк и т.п.) будет храниться, прямо в бинарнике?
antoshkka Автор
05.10.2021 14:04А где вся эта роскошь (имена функций, файлов, номера строк и т.п.) будет храниться, прямо в бинарнике?
Они там уже хранятся, в дебажных символах и таблицах экспорта
ncr
05.10.2021 15:16+3Они там уже хранятся, в дебажных символах и таблицах экспорта
Дебажные символы как бы в дебажных билдах. Можно, конечно, и в релизе включить, но видеть вместо условно трех мегабайт тридцать радости мало. Если std::stacktrace будет использовать внешние pdb — ок, но если ради трейса надо будет таскать внутри кода полный комплект символов, то это ой, проще выключить и пользоваться дальше всяким platform specific. А из таблиц экспорта вообще много не вытащишь.
antoshkka Автор
05.10.2021 16:05+2Да, работа с отдельно стоящими pdb возможна и реализована в протитипе

hiewpoint
05.10.2021 15:41Полные пути от корня ФС, а не от корня проекта выглядят ужасно. Мы в своём не очень большом проекте через constexpr функции вытаскиваем чистые имена файлов исходников без путей из __FILE__, чтобы не писать эти простыни при логировании, не тащить их в ёлку и т.д. Для большого проекта было бы актуальнее вытащить путь от его корня. Для stacktraces придётся патчить компилятор?
antoshkka Автор
05.10.2021 16:15Патчить компилятор нет нужды, в большинстве из них уже есть опция -fdebug-prefix-map
TargetSan
05.10.2021 15:39+1Стектрейсы это конечно замечательно. Меня, правда, смущает полнейшее игнорирование потребностей тех областей, где исключения отключены полностью и принудительно. Это, к примеру, Qt (кор не гарантирует, продвигаемый ими QML гарантированно ломается) и Unreal Engine. Нет ни expected, ни каких-то расширений эргономики, которые позволили бы реализовать аналог макроса try! из Rust.
antoshkka Автор
05.10.2021 16:12Если вам не нравятся монадические интерфейсы из C++23, то можно сделать свои монадические интерфейсы на основе корутин %)
Ну а std::expected на подходе, в прошлую пятницу LWG как раз ревьюила текст для включения в стандарт. Шансы успеть к C++23 есть.
allcreater
05.10.2021 16:25+1Вот примерно чего-то такого лично я и ожидал от C++23, если честно =)
Кстати, std::expected тоже не хватало, здорово, что им занимаются.
TargetSan
05.10.2021 16:39За новость про expected спасибо. Касательно же монадического интерфейса через корутины, мне это сильно напоминает традиционное в С++ использование фич не по назначению.

kovserg
05.10.2021 18:49А никакого механизма не добавили что бы было явно видно какую версию надо C++ исходному файлу. Например во первых строка писать что-то типа:
#include <atleast-c++23> ...
Или что бы наложить ограничения на допустимые фичи#include <limit-with-c++11> ...
А то чем дальше тем зоопарк всё шире.hiewpoint
05.10.2021 21:13Это невозможно, к сожалению. Разработчики компиляторов выкатывают разные фичи стандартов как задолго до их утверждения, так и много позже. Более того, сам компилятор может уже поддерживать все фичи стандарта, а библиотеки с ним — всё ещё нет. Например, стандарт С++11 сказал, что std::list::size() должен иметь сложность O(1), gcc 4.8 начал полностью поддерживать С++11, а в std::list::size() продолжал иметь сложность O(N) (RHEL7/CentOS7 с таким gcc поставлялись).
Antervis
10.10.2021 03:25Проблема не в этом - прикрутить версию реализации к версии стандарта наоборот было бы проще и правильнее, чем в некоторых конфигурациях предоставлять несовместимую стандарту реализацию.
Рассмотрим такой вариант: язык версионирован, и в двух версиях различается реализация какого-то класса
std::foo. Казалось бы, всё просто - в одном режиме будетusing cpp_23::foo;а в другом -using cpp_26::foo;Нюанс в том, что разработчикам компиляторов придется не только поддерживать обе версии класса, но еще и писать конвертации/interop между ними. Это приведет к экспоненциальному росту сложности поддержки от числа изменений, чего разработчики компиляторов естественно не хотят

domix32
06.10.2021 13:33Есть вариант покрыть концептам/статик ассертами которые будут чекать версию, например. Только это надо сделать кому-то. Плюс пора уже начинать переходить на модули вместо инклюдов.
ncwca
05.10.2021 23:23которые позволили бы реализовать аналог макроса try! из Rust
А как там у rust с эргономикой исключений? Странно сравнивать язык, который предполагает наличие исключений с тем, кто предполагает их отсутвие.
Хотя, на самом деле, с try в расте всё очень прохо, потому как много раишных объектов взятых из С++, которые не предполагают существования без исключений. Поэтому большинство ошибок никак не обрабатываются и триггерят паники.
Аналогично try практически не работает без dyn box, не говоря уже об оверхеде на каждый вызов. Аллокатор же не особо более предсказуемый, нежели расркутка стека. Без dyn box там какая-либо эргономика отсутвует как класс.
Сам же result элементарен и зачем его тащить в язык? Чтобы что? Делать новые интерфейсы с ним? Ни на что в текущей stdlib это не повляет. Для кода вне языка есть библиотеки.
Особенно в контексте Qt/Unreal Engine это выглядит максимально нелепо. Почему библиотеки не решают создаваемые ими проблемы? Почему вы не спрашиватее с них, а требуете это от языка?
Альтенативой исключений без исключений могут быть только статические исключение. Это фича языка и её действительно можно требовать. Правда её нет ни в одном мейнтримном языке, поэтому предъявить за это нельзя.
? в язык никогда не затащат, надеюсь. Это не более чем костыль. В языке нет expr, которые влияют на поток управления. Если их вводить, то вводить нормально и это ящик пандоры. Лупхолы здесь покажуться детской игрушкой.
Превращать язык в помойку, в которую суют что угодно бессистемно лишь бы код без исключений не выглядел максимально страшно в глазах неофитов в рекламных агитках.
TargetSan
06.10.2021 13:28+4А как там у rust с эргономикой исключений? Странно сравнивать язык, который предполагает наличие исключений с тем, кто предполагает их отсутвие.
В Rust целенаправленно отказались от исключений, по многим причинам. Проблема С++ не в наличии исключений, а в отсутствии единого вменяемого способа обрабатывать ошибки без них. Про
std::error_codeможете не говорить, это довольно примитивный механизм обработки ошибок из платформенных API.Хотя, на самом деле, с try в расте всё очень прохо, потому как много раишных объектов взятых из С++, которые не предполагают существования без исключений.
У С++ нет монополии на те же векторы, хеш-таблицы и подобные объекты. И исключения не являются единственным способом обработать ошибки.
Поэтому большинство ошибок никак не обрабатываются и триггерят паники.
Пруфов, что их именно большинств, конечно, не будет?
Аналогично try практически не работает без dyn box, не говоря уже об оверхеде на каждый вызов. Аллокатор же не особо более предсказуемый, нежели расркутка стека. Без dyn box там какая-либо эргономика отсутвует как класс.
try это вообще не про dyn box. try это всего лишь макрос для сокращения шаблонного кода вида "unwrap value or return error". И аллокатор для обработки ошибок в общем случае не требуется.
Сам же result элементарен и зачем его тащить в язык? Чтобы что? Делать новые интерфейсы с ним? Ни на что в текущей stdlib это не повляет. Для кода вне языка есть библиотеки.
Он нужен прежде всего как common ground для библиотек. Единый тип для возврата либо результата операции, либо информации об ошибке.
Особенно в контексте Qt/Unreal Engine это выглядит максимально нелепо. Почему библиотеки не решают создаваемые ими проблемы? Почему вы не спрашиватее с них, а требуете это от языка?
Хотелось бы спросить, но это проекты с чертовски долгой историей. Qt 1.0 релизнулся в 1995м, до первого стандарта. Первый релиз Unreal (не Engine) состоялся в 1998м.
Альтенативой исключений без исключений могут быть только статические исключение. Это фича языка и её действительно можно требовать. Правда её нет ни в одном мейнтримном языке, поэтому предъявить за это нельзя.
Статические исключения — по сути реализация Either/Result на уровне ABI вместо системы типов. Их нет в других мейнстримных языках именно потому, что все желающие используют Either или аналоги. Спроектированы они таким образом чтобы работать с конструкторами и другими сущностями, которые физически ничего не могут вернуть. Ну и мимикрия под обычные исключения как бонус.
? в язык никогда не затащат, надеюсь. Это не более чем костыль. В языке нет expr, которые влияют на поток управления.
Для С++ согласен, будет костылём. Да и не надо в общем-то. А вот expr, влияющие на поток управления, в С++ уже есть. Почитайте про throw в выражениях.
Если их вводить, то вводить нормально и это ящик пандоры. Лупхолы здесь покажуться детской игрушкой.
Насчёт вводить норально — полностью согласен. Я бы предпочёл GCC expression blocks в какой-то форме. А вот насчёт ящика пандоры — как же тогда функциональные и околофункцинальные языки живут?
Превращать язык в помойку, в которую суют что угодно бессистемно
Почему бессистемно? No-exceptions код это вполне себе распространённый случай, который комитет довольно долго игнорировал. Зато зета-функцию Римана добавили, вот уж нужная всем на свете штука!
лишь бы код без исключений не выглядел максимально страшно в глазах неофитов в рекламных агитках.
Неофитов, знаете ли, тоже надо привлекать. Чтобы через 10-20 лет было кому писать. У С++ и так не самая плавная, мягко говоря, кривая обучения.
ncwca
07.10.2021 02:03-1В Rust целенаправленно отказались от исключений, по многим причинам.
Нет. И да, они не отказались. Потому как притащенное из C++-раи без них не работает. В расте есть C++-исключения.
Отказ там произошёл по той причине, то это сложно. А далее уже каждый расскажет, что выбор у него был.
Проблема С++ не в наличии исключений, а в отсутствии единого вменяемого способа обрабатывать ошибки без них.
Это не проблема. Эту проблему придумали вы.
Про
std::error_codeможете не говорить, это довольно примитивный механизм обработки ошибок из платформенных API.Ничем не отличается от раста. Разве что не засунули в структурку. Хотя в послденее время уже суют. Не суют, правда, в юнион, чтобы не ловить оверхед при игнорировании ошибок.
У С++ нет монополии на те же векторы, хеш-таблицы и подобные объекты. И исключения не являются единственным способом обработать ошибки.
Здесь происходит попытка подмены контекста. Я говорил про раишные векторы и прочее, а теперь мне рассказывают про какие-то "векторы".
Для raii исключения являются единственным способом обработки ошибок. Именно поэтому в расте есть исключения и именно поэтому никакие ошибки там без исключений не обрабатываются.
Пруфов, что их именно большинств, конечно, не будет?
box/vector - любые операции. Что угодно раишное.
try это вообще не про dyn box. try это всего лишь макрос для сокращения шаблонного кода вида "unwrap value or return error". И аллокатор для обработки ошибок в общем случае не требуется.
Опять манипуляции. Происходит попытка подмены тезисы. Я нигде не говорил что dyn box это про try.
Происходит попытка показать, что я там не знаю что такое try и мне тут рассказывают очевидные вещи. Очевидно, что это враньё и доказывается это очнеь просто:
? в язык никогда не затащат, надеюсь. Это не более чем костыль. В языке нет expr, которые влияют на поток управления.
? - это костыль, чтобы try не выглядел как страшно. Это синоним в данном случае. Из "влияют на поток управления" следует и if и return, потому как они явлются управляющими конструкция.
Далее ещё одна манипуляция направленая на тех, кто мало знаком с темой и на последоватей раста, которые будут безусловно плюсовать любые базовые лозунги. Для первых я посню, со вторым разговаривать бессмысленно.
У нас есть две библиотеки, каждая из которых имеет свой enum err, пусть это будет erra|errb. Далее мы пишем функцию, внутри которой мы получаем return erra; и return errb; одновременно.
Врасте нет выовда типов для возврата, а даже если бы и был - это не поможет. Мы никак не можем два разных енума свести к одному типу. Всё, мы не можем ничего с этим делать. Раст здесь заканчивается.
Именно поэтому вы можете пойти и посмотреть реальный код на расте. Там везде будет либо dyn err, либо () вместо ошибки. Либо будут использовать ошибки только из одного закрытого типа.
И эта проблема никак не решаема. Мы можем попытаться обмазываться хаками, которые будут сливать руками разные enum в один новый, потом генерировать конвертацию из всех других enum в новый. И каждый раз нам нужно будет перечислять все enum. И чем больше вложенность, чем больше разных библиотек и прочего - там больше проблем. Там будут десятки разных enum.
Аналогично мы никак не сможем передатаь этот новый enum как старый. Нам нужно будет сделать конверсию. Автоматически мы её сделать не сможем, потому что происходит приведение к более узкому типу. Нужно будет опять что-то колхозить, писать лишний мусор, либо опять unwrap.
При этом о какой эргономики речи не идёт - это будет треш и угор, которым никто не сможет пользоваться. Примерно тоже самое, чтоб было с checked exception в С++. Всё эти "откровения" уже давно изучены и их проблемы поняты.
Для тех кому интересно как оно выглядит - может посмотреть на жаву. Где чуть ли не каждую функцию оборачивают в try{}catch, чтобы сужать типы исключений.
У исключений используется открытый тип. Именно поэтому мы можем возвращать любые типы исключений с одним интерфейсом. В расте это dyn.
В ситуации с исключениями у нас есть некий магический сторедж, где хранится наш тип исключения. В result такого нет. Нам нужно где-то его хранить. Хранить в err неизвестный тип неизвестной длинны мы не можем. Здесь и нужен box. Можно попытаться убрать dyn используя в качестве памяти память самого err. Но тогда err нужно делать большим, но не забываем, что result - это union, а размер его равен размеру самого большего элемента. И каждый раз мы будем копировать этот гигантский юнион, даже если мы возвращаем из функции int.
Далее манипуляций ещё больше. Мне достаточно и этих.
TargetSan
07.10.2021 11:41+4Нет. И да, они не отказались.
Они отказались. Паника спокойно переключается в режим abort.
Потому как притащенное из C++-раи без них не работает. В расте есть C++-исключения.
А вот здесь ошибаетесь вы. RAII ортогонально исключениям и прекрасно живёт без них. Можете посмотреть на тот же Qt, не дружащий с исключениями и использующий RAII в хвост и в гриву.
Отказ там произошёл по той причине, то это сложно. А далее уже каждый расскажет, что выбор у него был.
Да, это сложно. Для вас это сюрприз? Исключения требуют того самого волшебного хранилища для своих данных. Требуют дополнительных секций и лэндинг падов в коде функций для корректной раскрутки стека. И всё это должно присутствовать в т.ч. в стороннем коде, через который эти исключения могут пролететь. Открытость набора типов приводит к обязательности RTTI, который раздувает бинарники и тоже далеко не всем нравится.
Это не проблема. Эту проблему придумали вы.
То-то я вижу в разных библиотеках коды возврата из функций, out-параметры (ау, std::filesystem), специальные методы в типах под код ошибки (ау, std::basic_ios), глобальные переменные с теми же кодами ошибки (ау, std::errno), глобальные и per-function коллбэки, получающие информацию об ошибке (stdlib, на удивление, не отметилась) и много чего ещё.
Ничем не отличается от раста. Разве что не засунули в структурку. Хотя в послденее время уже суют. Не суют, правда, в юнион, чтобы не ловить оверхед при игнорировании ошибок.
Смысл Either и подобных как раз в возможности однозначно вернуть либо результат, либо ошибку. Без возможности вытащить вторую половину.
Здесь происходит попытка подмены контекста. Я говорил про раишные векторы и прочее, а теперь мне рассказывают про какие-то "векторы".
Для raii исключения являются единственным способом обработки ошибок. Именно поэтому в расте есть исключения и именно поэтому никакие ошибки там без исключений не обрабатываются.Вектор всегда вектор, написан он с учётом RAII или нет. Про ортогональность RAII и исключений ответил выше.
box/vector — любые операции. Что угодно раишное.
Т.е. пруфов таки не будет. Голословное утверждение, так и запишем.
Опять манипуляции. Происходит попытка подмены тезисы. Я нигде не говорил что dyn box это про try.
Происходит попытка показать, что я там не знаю что такое try и мне тут рассказывают очевидные вещи. Очевидно, что это враньё и доказывается это очнеь просто:Какой-то вы нервный.
? в язык никогда не затащат, надеюсь. Это не более чем костыль. В языке нет expr, которые влияют на поток управления.
? — это костыль, чтобы try не выглядел как страшно. Это синоним в данном случае. Из "влияют на поток управления" следует и if и return, потому как они явлются управляющими конструкция.
Вы сначала говорите об expressions, а потом резко перескакиваете на statements. Кто теперь занимается подменой? Для других читателей оставлю ссылку, о чём я говорил: https://en.cppreference.com/w/cpp/language/throw. Озаглавлено throw expression. Т.е. throw является выражением, и при этом влияет на поток управления. Для сравнения, return является statement. https://en.cppreference.com/w/cpp/language/return
Далее ещё одна манипуляция направленая на тех, кто мало знаком с темой и на последоватей раста, которые будут безусловно плюсовать любые базовые лозунги. Для первых я посню, со вторым разговаривать бессмысленно.
Вы промахнулись, мой основной язык С++.
У нас есть две библиотеки, каждая из которых имеет свой enum err, пусть это будет erra|errb. Далее мы пишем функцию, внутри которой мы получаем return erra; и return errb; одновременно.
Врасте нет выовда типов для возврата,Это утверждение не относится к теме, однако отвечу: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=c4792aaa4e85980bdb40e70298aee9a3
Для parse тип возвращаемого значения вполне себе выводится.а даже если бы и был — это не поможет. Мы никак не можем два разных енума свести к одному типу. Всё, мы не можем ничего с этим делать. Раст здесь заканчивается.
Мы можем спокойно создать errC с двумя вариантами, в одном errA, в другом errB.
Именно поэтому вы можете пойти и посмотреть реальный код на расте. Там везде будет либо dyn err, либо () вместо ошибки. Либо будут использовать ошибки только из одного закрытого типа.
Вообще-то для библиотеки обычно создают один энам, описывающий то, что называют "ошибка доменной области". Который как раз описывает весь набор возможных ошибок, которые может выплюнуть библиотека. Будут там внутри вложенные ошибки более низких уровней — зависит от того, нужны они или нет. В библиотеках с Сшным интерфейсом, написанных на С++, так и делают.
И эта проблема никак не решаема. Мы можем попытаться обмазываться хаками, которые будут сливать руками разные enum в один новый, потом генерировать конвертацию из всех других enum в новый. И каждый раз нам нужно будет перечислять все enum. И чем больше вложенность, чем больше разных библиотек и прочего — там больше проблем. Там будут десятки разных enum.
Без использования вложенных исключений вы получите прилетающую непонятно откуда какую-нибудь invalid argument. А с ними получите либо цепочку исключений, без возможности выбрать как её составлять (и с чертовски кривым кодом по размотке этой цепочки), либо почти точно такой же толстенный тип, содержащий всю необходимую информацию. И да, бонусом в каждом месте, где нужно будет добавить контекст, будет try-catch ручками.
Аналогично мы никак не сможем передатаь этот новый enum как старый. Нам нужно будет сделать конверсию. Автоматически мы её сделать не сможем, потому что происходит приведение к более узкому типу. Нужно будет опять что-то колхозить, писать лишний мусор, либо опять unwrap.
https://doc.rust-lang.org/std/convert/trait.From.html. Достаточно описать преобразование один раз, и? либо try будут делать автоматичеки.
При этом о какой эргономики речи не идёт — это будет треш и угор, которым никто не сможет пользоваться. Примерно тоже самое, чтоб было с checked exception в С++.
Exception specifications. Потому что так же не были нормально вписаны в систему типов, как и в Java. Была точно та же проблема с отсутствием автоматического преобразования. Которое и не могло быть реализовано в С++.
Всё эти "откровения" уже давно изучены и их проблемы поняты.
Для тех кому интересно как оно выглядит — может посмотреть на жаву. Где чуть ли не каждую функцию оборачивают в try{}catch, чтобы сужать типы исключений.Да. Потому что исключения там вписаны в систему типов криво. Нельзя быть, к примеру, generic по типу исключения. Много чего нельзя.
У исключений используется открытый тип. Именно поэтому мы можем возвращать любые типы исключений с одним интерфейсом. В расте это dyn.
В случае С++ это вообще всё, включая int, bool. Спасибо, не надо.
В ситуации с исключениями у нас есть некий магический сторедж,
Ага. Good luck ABI compatibility.
где хранится наш тип исключения. В result такого нет. Нам нужно где-то его хранить. Хранить в err неизвестный тип неизвестной длинны мы не можем. Здесь и нужен box. Можно попытаться убрать dyn используя в качестве памяти память самого err. Но тогда err нужно делать большим, но не забываем, что result — это union, а размер его равен размеру самого большего элемента. И каждый раз мы будем копировать этот гигантский юнион, даже если мы возвращаем из функции int.
Вот здесь мы подобрались к сути, отлично. Но дело в том, что в случае с Result у вас есть выбор — держать десяток вложенных энамов, "ужимать" лишние или выделять на куче. А в случае с исключениями выбора нет. ABI фиксирован, но при этом никак не специфицирован.
Далее манипуляций ещё больше. Мне достаточно и этих.
Пока что ими отличились в основном вы.
ncwca
07.10.2021 16:14Они отказались. Паника спокойно переключается в режим abort.
Кто и где отказался? abort - это крестовый режим -fno-exception/noexpect из llvm - nounwind и прочее. Куда там они отказались? А то, что они есть в C++(если бы не было - никакой раст бы никуда и никогда даже флажка такого не имел) значит, что С++ отказался от исключений?
А вот здесь ошибаетесь вы. RAII ортогонально исключениям и прекрасно живёт без них. Можете посмотреть на тот же Qt, не дружащий с исключениями и использующий RAII в хвост и в гриву.
Нет, raii не существуют без исключений. Мне лень даже комментировать это позорище, особенно в ситуации когда даже здесь уже обсуждали try_ и прочий мусор.
In case memory allocation fails, QVector will use the Q_CHECK_PTR macro, which will throw a
std::bad_allocexception if the application is being compiled with exception support. If exceptions are disabled, then running out of memory is undefined behavior.Использующий. Без исключений. Уб, либо
std::bad_alloc.Сообщаю ещё раз. раии можно использовать без исключений, но тогда обрабатывать ошибки невозможно. Раии не предполагает иного. В С++ даже нету механизмов вернуть ошибку из конструктора. Как и в раст-перепасте с С++.
Да, это сложно. Для вас это сюрприз? Исключения требуют того самого волшебного хранилища для своих данных. Требуют дополнительных секций и лэндинг падов в коде функций для корректной раскрутки стека. И всё это должно присутствовать в т.ч. в стороннем коде, через который эти исключения могут пролететь.
Какое отношение это имеет к огрызку фронтенда? Сложно оно не поэтому, потому как это сложность не имеет никакого отношения к расту, очевидно.
Открытость набора типов приводит к обязательности RTTI, который раздувает бинарники и тоже далеко не всем нравится.
Да, раздутый бинарник всем мешает, но и им не мешает раст. Ведь методички там и работают - неси чушь, которая противоречит твоему же существованию.
То-то я вижу в разных библиотеках коды возврата из функций, out-параметры (ау, std::filesystem), специальные методы в типах под код ошибки (ау, std::basic_ios), глобальные переменные с теми же кодами ошибки (ау, std::errno), глобальные и per-function коллбэки, получающие информацию об ошибке (stdlib, на удивление, не отметилась) и много чего ещё.
Каждый новый тезис всё более и более нелепый. Во-первых, наличие чего-то не является проблемой. Во-вторых, с чего там должен быть убогий result-мусор тормозящий? С чего подход должен быть везде один, если в разных случаях разные подходы могут быть удобнее/эффективнее.
basic_ios - это максимально позорище, потому что там нет никакого возврата. Это состояние объекта result тут никаким боком неприменим.
std::errno - никакого отношения к C++ не имеет. К тому же, даже errno не такой тормозной мусор как result. Оно позволяет без потери производительности игнорировать ошибки. В отличии от мусорного result.
Смысл Either и подобных как раз в возможности однозначно вернуть либо результат, либо ошибку. Без возможности вытащить вторую половину.
Опять какая-то чушь. Мною итак написано, что там юнион. Зачем это повторять? И я назвал причину, почему юнион не делают.
Вектор всегда вектор, написан он с учётом RAII или нет. Про ортогональность RAII и исключений ответил выше.
Нет, очевидно.
Т.е. пруфов таки не будет. Голословное утверждение, так и запишем.
А ну совсем клоунада пошла. Каких пруфов? https://doc.rust-lang.org/std/vec/struct.Vec.html - первая ссылка в гугле, открываем. Смотрим:
let mut vec = Vec::new(); vec.push(1); vec.push(2);Вторая строчка - не получить ошибку из push. Следующая - аналогично. Либо падаем, либо исключения. Без исключения ошибку не получить - только ловить панику/исключение.
let mut vec = vec![1, 2, 3]; vec.push(4); assert_eq!(vec, [1, 2, 3, 4]);Здесь аналогично. Всё кидает исключения. Везде без них ошибку не получить. Разве что ассер не кидает.
Даже vec[n] кидает исключение. Без него ошибку не получить. И что же, где здесь result? Где вектор без исключений и с ошибками? Ой, нету?
Ладно, меня эти потоки бреда утомили. Там уже всё с экспертом понятно на qt.

Voronar
07.10.2021 22:12ncwca
08.10.2021 00:31И?
This is a nightly-only experimental API.
Им специально впилили эту нерабочую чушь, чтобы они бегали и везде её линковали. Какое отношение она имеет к вопросу? Никакого.
Само существование этого мусора уже говорит о моей правоте. Мало того, но я сам говорил об этом мусоре. Зачем мне о нём сообщать? Чтобы что?
technic93
08.10.2021 02:53Текущая кодовая база на расте это компромис о том, что такие ошибки обрабатывать не надо. Поэтому они не засоряют сигнатуры методов. Точно так же и с доступом к элементу вектора. Если бы абсолютно везде в коде использовался бы try_чтототам(), то выглядели бы все хайлевел апи очень неприятно.
Кроме того result медленнее исключения на happy-path, так что короме страшного кода ещё бы добавились тормоза.
Но иногда нужно обрабатывать подобные ошибки на самом верхнем уровне. Тогда гарантий по типам что вы про них "не забудете" нету, и багованя корутина может обвалить весь процесс веб сервера. Для этого задействуется механизм исключений из ллвм, который там есть от С++.
А вот эти try_ методы добавили в том числе для ядра, но в ядре и так пишут с сишными кодами возврата. Так что там ситуация в этом плане не сильно изменится.

Daddy_Cool
06.10.2021 00:02-1Много лет хочется ^ вместо pow(), поскольку пишу всякую математику. Тут как-то было даже обсуждение как сделать что-то такое, но всё уперлось в проблему приоритетов операций в выражении.
a-tk
06.10.2021 08:34+2Занято под xor же.
hiewpoint
06.10.2021 13:39+1Проблема там не в том, что занято, оператор перегрузить можно в C++, а в том, что у операции возведения в степень в математике самый высокий приоритет, а в C/C++ у хоr — очень низкий. 5+6^7 == 5 + (6^7) в математике, но 5+6^7 == (5 + 6)^7 в C/C++.
Было бы интересно, если бы заодно с перегрузкой операторов давали перегружать operator precedence…
Эта история чем-то похожа на историю с многомерными индексами. Ради них в C++20 «сломали» другой оператор — запятую. До С++20 этот оператор не работал только в вызовах функций и в списках инициализации, а в C++20 он перестал работать ещё и в вызове оператора [], т.е. по C++17 можно было написать a[b=1, c]=1 эквивалентное {b=1; a[c]=1;} начиная с C++20 для этого же стало нужно писать a[(b=1, c)]=1; а начиная с С++23 выражение a[b=1, c]=1 будет означать {b=1; a[b][c]=1}.a-tk
07.10.2021 08:30+3[вздох]Честно говоря лучше бы оператор запятая не работал совсем нигде.[/вздох]
Я не припомню ни одного проекта за 20 лет, где я использовал бы этот оператор. Один раз было желание его использовать для списочной инициализации наподобие initializer_list, но лет за 5 до его появления, но от этой идеи в итоге отказался.

shybovycha
06.10.2021 01:16+2Возможно не самое популярное мнение, но почему комитет не обратит внимание на метрики навроде того какие инструменты используются чаще всего и какие фичи они предлагают? Понимаю, возможно слишком много работы чтобы завезти в стандарт то что уже решается другими инструментами. Но как я понимаю, это же можно сказать про в принципе любые из перечисленых изменений.
Так навскидку: boost уже много лет решает много чего и вроде как является если не стандартом, то best practice. То же можно и сказать про CMake (package / dependency management и система сборки - это скорее наболевшее). Так почему бы их (хотя бы частично - отдельные фичи) не взять в стандарт?

encyclopedist
06.10.2021 10:49+1Так почему бы их (хотя бы частично - отдельные фичи) не взять в стандарт?
Это происходит постояно. В списке фич в этом посте многие были вначале опробованы как раз в Boost

Porohovnik
06.10.2021 10:51Так и делают. std::filesysteam почти без изменений перекачивал из boost в std. А вот Cmake это система сборки, и она не должна не каким образом включатся в язык. Это же просто прога, со своим языком...

IGR2014
06.10.2021 16:01+1Господи, если опять не подвезут constexpr-математику, я психану и начну разрабатывать собственный язык с блекджеком и constexpr'ом!
Я знаю что проблема в поддержке совместимости со старыми реализациями где был глобальный флаг ошибки, который нельзя было реализовать в constexpr, но так ли нам это нужно в 2021-м?!
antoshkka Автор
06.10.2021 17:18Некоторые люди из комитета говорили, что им ну очень нужно, у них всё формулы работают только с правильным округлением. Правда потом они очень удивлялись, что округление на самом деле не работает во многих их формулах, так как компилятор оптимизирует с использованием дефолтного округления https://godbolt.org/z/KKavdE
Надеюсь что здравый смысл возобладает и constexpr cmath будет
Voronar
07.10.2021 22:18С появлением ranges по-моему очень не хватает функции `std::ranges::to`, которая материализует диапазон в контейнер.
https://timur.audio/how-to-make-a-container-from-a-c20-range

alexeiz
08.10.2021 09:02move_only_function - почему такое длинное имя для класса, который предполагается использовать практически везде вместо std::function? Никакой заботы об "эргономичности" стандартной библиотеки. Можно было назвать mo_function, например, по аналогии с readonly - ro.
oficsu
09.10.2021 00:19Вероятно, в связи с тем, что аббревиатура ro имеет крайне широкое распространение и не только в мире C++, а mo многие(все?) увидят впервые? Многие стайлгайды запрещают введение новых аббревиатур с потолка и в этом есть смысл
alexeiz
09.10.2021 03:37Гнилая отмазка. Причем тут стайлгайды? У людей в коммитете нет своих мозгов, и они должны следовать каким-то васянским стайлгайдам?
ncwca
09.10.2021 10:45-2Это показатель силы. Уменьшение идентификаторов - это не более чем попытка убогих языков создать видимую компактность своего кода.
Возьмём какой-то раст. Это максимально страшное невыразительное чудовище. Но используй идентификаторы в 2-3 символа мы можем визуально скрыть эту жопу.
Я когда-то ради интереса переписывал C++-код используя имена из раста и прочих. Дак там не только людям, но и самим пропагандистам срывало методичку.
Такая же ситуация с каким-нибудь хаскелем. Максимально убогий треш, который скрывается ущербным форматирование, тысячей рандомных символов и прочим.
В реально же абсолютно насрать на то, как там длинна идентификаторов. Пишутся они mof+энтер, как и любую другое название.
И самое важное. C++ позволяет, в отличии от всякого убожества, очень просто вводить алиасы. Для каких-нибудь лямбд это делается максимально очевидно. Для функций нужно лямбду/функцию писать, но в С++ есть pf.
В каком-нибудь расте и другой пародии на языки - вы обязаны будите перепастить столько лапши, что можно сразу повесится. Именно поэтому там это проблема. Здесь же нет. Ненужно реализации те приносить сюда.
Xadok
Спустя годы мы наконец получим стектрейс из исключений
svr_91
Выброс исключений станет медленнее? Или там какой-то хитрый механизм?
antoshkka Автор
Там есть рантайм (и по идее compile time) рубильник, чтобы не собирать трейсы при выкидывании исключений.
Пробовали на своей кодовой базе, сбор трейса замедлили наше приложение на 0.5%. Но мы кидаем мало исключений и патчили рантайм со сломом ABI. Вряд ли именно так будут делать в GCC, так что цифры скорее всего будут другими.
cdriper
Вообще это против идеологии языка, ты не должен платить за то, чего не используешь.
antoshkka Автор
Если не используете - то просто не включаете, и не платите
TargetSan
Маленькая проблемка. В С++ как языке и стандарте нет такого понятия как отключаемые фичи. К примеру, любой проект, написанный с отключенными исключениями, по сути не соответствует стандарту. Так что если хотите оставаться в рамках стандарта, платить будете всегда. Как и за RTTI.
antoshkka Автор
В стандарте есть много способов сделать фичу отключаемой - от описания фичи таким образом, что она может ничего не делать, до помечания её как implemntation defined. Исключения и RTTI отключаемыми фичами не являются.
Что же касается исключений и трейсов, то там прям в стандартную библиотеку добавляется метод для включения функционала:
void this_thread::set_capture_stacktraces_at_throw(bool enable = true) noexcept;flx0
Интересно, а -fno-exceptions и -fno-rtti в компиляторах — это что? Как так получилось что тот С++, который в стандарте, и тот С++, который компилируется — это два разных языка?
TargetSan
Причин, думаю, несколько.
Одна — эти флаги появились либо когда стандарта не было как класса (первый — ЕМНИП С++98), либо во времена, когда на точное соответствие стандарту все радостно забивали. Напомню, что MSVC перестал противоречить стандарту только в последних версиях Visual Studio 2017, а это что-то около 2019го года.
Другая причина — в момент появления исключений и RTTI (середина 90х) они давали нагрузку на размер бинарника и перформанс, которая тогда была неприемлема. Тот же Qt до сих пор по факту не является exception-neutral.
Вообще же, три из наиболее широко используемых сейчас компилятора (MSVC, GCC, CLang; про ICC не скажу) реализуют не чистый стандарт, а диалекты-надмножества, причём каждый своё.
antoshkka Автор
-fno-exceptions и -fno-rtti - это несовместимые со стандартом расширения/сужения.
В стандарт же эту возможность никто не протащил, т.к. на практике оно работает совсем не так как ожидается. Например, noexcept для методов автоматически не проставляется из-за того, что где-то внутри метода может быть вызов функции из сторонней библиотеки, которая может кинуть исключение. Были попытки, но авторы потом сами убеждались, что получается фигня какая-то.