
Привет, Хабр! Уже не раз поднимали тему распознавания паспортов, и даже заявляли о том, что тема закрыта.
Вопрос в том, что даже сейчас паспорта продолжают распознавать в ручном режиме - в тех же банках на потоке этим может заниматься целый отдел. Аргумент - все системы выдают ошибки.
В этом материале хочу рассказать про нейросеть, которую написали как часть решения для оцифровки паспортов. Систему ориентировали на конкретный бизнес-результат - качество распознавания выше 99%. Дело здесь не только в технологиях или уникальном коде, но и в облачном сервисе, к которому подключена краудсорсинговая платформа.
Новая нейросеть “схватывает” разворот паспорта и выдает результат в течение 2-5 секунд. 95 процентов информации распознаётся с точностью 99 процентов. Случаи неуверенного распознавания отправляются на ручную проверку удаленно подключенному (не на стороне заказчика) оператору верификации данных, информация приходит ему в деперсонализированном виде.
Массив для обучения сети составил 500 тыс. синтетических паспортных разворотов + провели тест на 20 тысячах реальных документов. Размер сети - около 16 млн. параметров. Таким образом, в домашних условиях написать что-то аналогичное вряд ли удастся без похожего дата-сета для обучения. Здесь просто расскажем о state-of-the-art решении для бизнес-задач.
На разработку нейронки у разработчика московской компании "Биорг" Михаила Захарова ушло 2 недели.
Средства разработки
Сеть написана на Python с применением фреймворка PyTorch — одного из самых гибких инструментов, используя который можно глубже исследовать любой предмет.
С чего начинали: от алгоритмов к нейросетям
Предыдущая система распознавания паспортов работала на основе алгоритмов. Они успешно справлялись с 50-60 процентами всех полей на страницах паспорта. Согласно классическому подходу, алгоритмы разбивали страницу на линии, где искали слова. На каждый этап работы нужен был свой собственный алгоритм.
Однако любой нестандартный случай приводил к сбою в работе алгоритма, который анализировал страницу в соответствии с заложенными правилами. Отсюда и столь низкий процент распознавания. Мешали «шумы»: нетривиальное расположение слов, блики, тени и т.д.
На вход старой системе поступали две довернутые зоны интереса паспорта в grayscale поочередно. Сначала происходила предобработка зон (убирались блики, замазывался орёл, морфологические предобработки). Затем определялись строки, каждая строка разбивалась на слова. Оценивалось общее расположение (gemoetric layout) найденного текста, которое сверялось с заранее известным шаблоном паспорта.
Строки находили и разбивали на слова с помощью классических методов компьютерного зрения. Каждое слово распознавалось отдельно с помощью нейронной сети C-RNN CTC.
End-To-End
Задачей было повысить качество автоматического распознавания паспортов и сократить время на обработку документа.
Чтобы улучшить систему, в которой очень много частей, нужно потратить много времени на каждую отдельную часть. Куча работы, чтобы поднять производительность всего на 2%? Вместо этого сделали единую нейросеть, которой не нужно подставлять костыли, дописывать алгоритмы, разделять задачи и т.д..
Она сама определяет и распознавает слова, соотносит их со значениями полей документа.
Когда сеть умеет “читать”, ей легче ориентироваться, где и что написано, труднее это спутать, например, с водяным знаком, другим символом.
Original zamysel
Архитектурно нейросеть устроена как инструменты для распознавания отдельных слов. Небольшой набор трюков подсмотрели на примере нейронок для обработки аудио и видеопотоков.
Общая архитектура:
1. Срез сверточной нейронной сети для извлечения признаков из изображения.
2. Модуль non-local neural network block, осуществляющий некоторую форму self-attention на входной feature map, позволяя обращать внимание на разные части изображения для формирования признаков. Подробная схема устройства этого модуля:
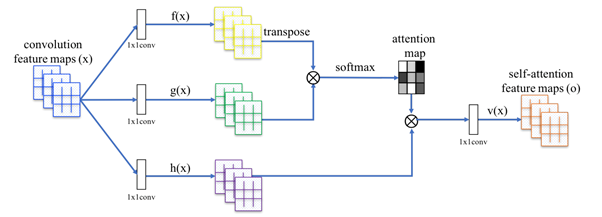
После всех преобразований self-attention feature maps(o) умножаются на некоторый “gate variable” выучиваемый параметр и складываются (residual connection) с convolution feature maps (x).
3. Для добавления location awareness в саму модель используется техника добавления к feature map по глубине one-hot координат каждого пикселя.
4. Полученные таким образом признаки отправляются в transformer decoder с multi-headed attention между самим декодером и энкодер репрезентациями (cnn feature maps).
Модуль машинного обучения
Сеть сама ознакомилась с десятком тысяч примеров, вычислила закономерности (паттерны) и научилась находить слова на скане документа.
Проблема была в том, что эти слова не были соотнесены с какими-то полями паспорта (алгоритм, напротив, сам соотносил найденные слова с полями). Без этого оцифровать документ невозможно. Чтобы научить нейронку соотносить слова и поля, запустили процесс машинного обучения.
Полмиллиона паспортов для обучения
Сначала нейросеть около двух дней обучали на синтетических данных. Это были сгенерированные значения, которые не относились к реальным документам, но имели все атрибуты настоящих данных с разворота паспорта: разные шрифты, масштабы, раскладку текста. Всего около 500 000 синтетических разворотов паспортов.
Для закрепления пройденного потребовался ещё один день.
Тестировали решение уже на настоящих документах, используя датасет из 20 тысяч реальных паспортных разворотов.
Можно прямо сказать, что без такого объёмного погружения в материал нейросеть никогда бы не научилась хорошо считывать документы, несмотря на все доработки.
В итоге
Нейросеть забирает страницу целиком, хотя на этапе распознавания это для неё просто изображение. То есть она ещё не знает, что там за слова, к каким категориям они относятся т.д. Она сама определяет фамилию-имя-отчество и т.д., другие значения.
Нейросеть - часть общего решения. Она работает в “облаке” и объединена с сервисом верификации данных силами человека. То есть, если она что-то не распознала или забраковала, ошибку проверяет оператор-человек. Это даёт итоговый результат распознавания выше 99 процентов.
Что почитать:
Attention-based Extraction of Structured Information from Street View Imagery 1704.03549.pdf (arxiv.org)
Non-local Neural Networks 1711.07971.pdf (arxiv.org)
Attention Is All You Need 1706.03762.pdf (arxiv.org)
Комментарии (8)

sergeypid
26.10.2021 16:46+1Как вы сильно завуалировали visual transformers... На выходе Вашей модели получается прямо поток символов типа "Фамилия -- Иванов --- Дата рождения -- 01.01.2005 --- EOS ? По-моему, это шикарная разработка, особенно за 2 недели! Спасибо за статью.

Drayden
26.10.2021 18:39+1Заинтересовался статьей, полезная тема! Не могли бы вы уточнить - текст полей паспорта тоже извлекается (как именно текст для поиска)?
Или извлекаются только участки изображения в виде растра?

mishazakharov
01.11.2021 12:06+1Участки изображения в виде растра не извлекаются. Сеть принимает на вход изображение страницы паспорта и выдает текст полей с соответствующей страницы паспорта.
Drayden
01.11.2021 14:06Т.е. механизм OCR и механизм поиска положения полей - это одна сеть, одна архитектура? Или в системе две подсистемы - OCR и поиск, и они работают одна после другой?
AlexeyALV
А облако частное? 20000 реальных паспортов - это все клиенты? Как там с персональными данными?
XadrZ Автор
20 000 реальных паспортов - это клиенты, Вы правы. Нейронку тестировали в ходе реального проекта. Инфраструктура по ФЗ-152. Гостированный криптоканал для передачи данных. Регистрация в реестре оператора обработки ПДн. С персональными данными всё в порядке.