
Для того, чтобы ускорить тестирование крупных приложений, как правило, проверки вручную сочетают с автотестами. После их прогона QA или SDET-специалисты разбирают успешные и «упавшие» тесты – их нужно проверить вручную и зафиксировать результаты, например, в Confluence.
Рассмотрим на примере, как можно ускорить экспорт этих данных, если вы работаете с некоммерческой версией Allure Framework. При использовании Allure-EE такие доработки не нужны – информацию по ручному прохождению кейсов можно хранить в самих отчетах.

В описанном ниже кейсе мы работали с Allure, поскольку этот инструмент использовался и на других подпроектах заказчика. При этом шапка таблицы создавалась из шаблона, а данные для каждого автотеста приходилось вручную копировать из Allure-отчета. При большом количестве упавших автотестов этот процесс становился трудоемким и занимал достаточно много времени. Мы решили автоматизировать его и разработали утилиту, с помощью которой создавалась таблица, уже заполненная необходимыми данными из Allure-отчета.
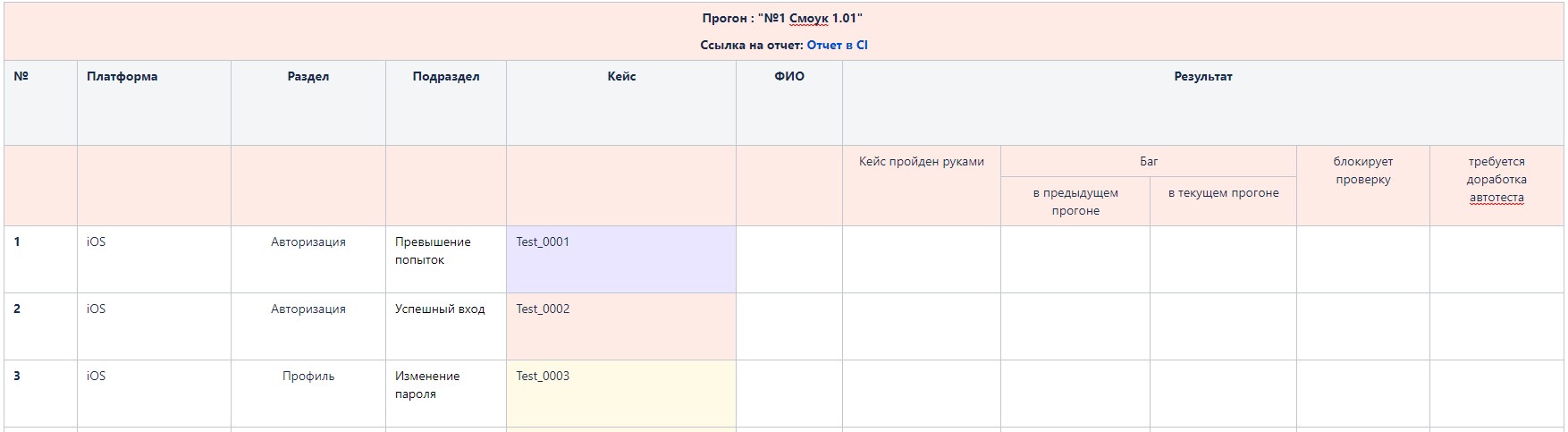
Задачи, которые нам требовалось решить:
Найти и структурировать необходимые данные из json-файлов, которые создает Allure.
Сгенерировать html-код таблицы, используя полученные ранее данные.
Создать таблицу в Confluence с помощью POST-запроса, в теле которого передать html-код таблицы.
Получение данных из json-файлов
Json-файлы с которыми мы будем работать, находятся в каталоге allure-report\data\test-cases
Для каждого автотеста создается отдельный json-файл с информацией по его прохождению. Это достаточно большой файл, который содержит все шаги автотеста, поэтому в статье мы не будем приводить его полностью. Нас интересуют такие параметры:
"status" : "failed”,
"name" : "Test_0001",
{
"name" : "epic",
"value" : "iOS"
},
{
"name" : "feature",
"value" : "Авторизация"
},
{
"name" : "story",
"value" : "Превышение попыток"
}Эти данные будем размещать во 2 - 5 колонках таблицы, используя определенные цвета для заливки фона ячеек. Статус автотеста может иметь несколько значений: "failed" (выделяем красным), "unknown" (фиолетовый), "broken" (желтый), "skipped" (серый).
Создадим два класса с моделями. Для генерации моделей удобно использовать IntelliJ IDEA плагин RoboPOJOGenerator. Также обратимся к Lombok, чтобы не создавать методы геттеры.
import com.google.gson.annotations.SerializedName;
import lombok.Getter;
import java.util.List;
@Getter
public class TestCase {
private String epic;
private String feature;
private String story;
@SerializedName("name")
private String name;
@SerializedName("status")
private String status;
@SerializedName("labels")
private List<LabelsItem> labels;
public void initLabels() {
if (labels != null) {
for (LabelsItem labelsItem : labels) {
switch (labelsItem.getName()) {
case "epic" : epic = labelsItem.getValue();
break;
case "feature" : feature = labelsItem.getValue();
break;
case "story" : story = labelsItem.getValue();
}
}
}
}
}
import com.google.gson.annotations.SerializedName;
import lombok.Getter;
@Getter
public class LabelsItem {
@SerializedName("name")
private String name;
@SerializedName("value")
private String value;
}Создадим метод, который будет получать эти параметры из json-файла. Преобразовывать json в класс модели будем при помощи Gson.
/**
* Получает данные из json файла
*
* @param path путь к папке с файлами
* @return данные из json файла
*/
public static TestCase readTestCasesJson(String path) {
try (Stream<String> stream = Files.lines(Paths.get(path))) {
String text = stream.reduce("", String::concat);
return new Gson().fromJson(text, TestCase.class);
} catch (IOException e) {
throw new RuntimeException(e.getMessage());
}
}Для получения списка всех json-файлов воспользуемся следующим методом:
/**
* Получает список названий файлов в папке
*
* @param path путь к папке с файлами
* @return список названий файлов
* @throws IOException ошибка доступа к данным
*/
public static List<Path> getFilesInFolder(String path) throws IOException {
return Files.walk(Paths.get(path))
.filter(Files::isRegularFile)
.collect(Collectors.toList());
}Теперь создадим метод, который будет собирать данные по всем упавшим тестам.
/**
* Получает данные по всем упавшим
*
* @param paths путь к папке с файлами
* @return список с данными по упавшим тестам
*/
public static List<TestCase> getTestCasesDataInFolder(List<Path> paths) {
List<TestCase> testCases = new ArrayList<>();
TestCase testCase;
for (Path path : paths) {
testCase = readTestCasesJson(path.toString());
if (!testCase.getStatus().equals("passed") ) {
testCase.initLabels();
testCases.add(testCase);
}
}
return testCases;
}Генерация таблицы
Далее создадим метод, который будет получать информацию по автотестам для всех статусов, сортировать их и создавать таблицу в формате html.
/**
* Формирует html код таблицы
*
* @param testCasesPath путь к папке с json файлами отчета
* @param link ссылка на прогон в CI
* @param name название прогона
* @return строка с html кодом таблицы
* @throws IOException ошибка доступа к данным
*/
public static String createTableBody(String testCasesPath, String link, String name) throws IOException {
List<Path> filesPath = getFilesInFolder(testCasesPath);
List<TestCase> tests = getTestCasesDataInFolder(filesPath);
List<TestCase> notPassed = tests.stream()
.sorted(Comparator.comparing(TestCase::getStatus)
.thenComparing(TestCase::getEpic, nullsFirst(naturalOrder()))
.thenComparing(TestCase::getFeature, nullsFirst(naturalOrder()))
.thenComparing(TestCase::getStory, nullsFirst(naturalOrder()))
.thenComparing(TestCase::getName, nullsFirst(naturalOrder())))
.collect(Collectors.toList());
String lines = createTableLines(notPassed);
return (format(TABLE_HEADER, name, link, link) + lines + TABLE_TAIL).replace("\"", "\\\"");
}Для формирования строк таблицы используем следующий метод:
/**
* Формирует строки таблицы в Confluence
*
* @param testsCases список упавших тестов
* @return html код строк таблицы
*/
private static String createTableLines(List<TestCase> testsCases) {
StringBuilder result = new StringBuilder();
String colorValue = "";
for (TestCase test : testsCases) {
colorValue = getColorValue(test.getStatus());
result.append(
format(
TABLE_LINE,
++testNumber,
Strings.isNotNullAndNotEmpty(test.getEpic()) ? test.getEpic() : " ",
Strings.isNotNullAndNotEmpty(test.getFeature()) ? test.getFeature() : " ",
Strings.isNotNullAndNotEmpty(test.getStory()) ? test.getStory() : " ",
colorValue,
getColorName(test.getStatus()),
colorValue,
test.getName()
)
);
}
return result.toString();
}Для создания html-кода таблицы проще всего скопировать код из шаблона в Confluence и подставить нужные значения в определенные места с помощью функции format().
Сначала формируем хедер таблицы. После поочередно добавляем строки. Последней добавляем строку с тегами, закрывающими таблицу. Таким образом, мы сформируем html-код таблицы, который передадим в теле запроса.
Создание таблицы с помощью POST-запроса
Для создания таблицы с помощью запросов используем документацию Confluence REST API.
Для начала создадим в Confluence пустую страницу, которую будем использовать для нашего генератора таблиц. Так нам будет удобно отправлять запросы к странице с определенным id (пусть это будет 123456789), который можно посмотреть в адресе самой страницы https://***.ru/pages/viewpage.action?pageId=123456789
Для того чтобы сохранить новую таблицу, нам нужно узнать текущую версию страницы. Для этого используем GET запрос https://***.ru/rest/api/content/123456789?expand=version
Для работы с api используем RestAssured https://rest-assured.io/
И создадим метод для получения номера следующей версии страницы
/**
* Получает версию таблицы в Confluence
*
* @param url адрес страницы
* @param login логин от учетки Confluence
* @param password пароль от учетки Confluence
* @return номер следующей версии страницы
*/
public static int getNextPageVersion(String url, String login, String password) {
int result = RestAssured
.given()
.auth()
.preemptive()
.basic(login, password)
.get(url)
.jsonPath().get("version.number");
return result + 1;
}Для создания таблицы используем POST-запрос https://***.ru/rest/api/content/123456789/ с телом:
{
"body": {
"storage": {
"value": "наш html код таблицы",
"representation": "storage"
}
},
"type": "page",
"title": "Генератор таблиц",
"version": {
"number": "100"
}
}Здесь мы указываем заголовок страницы, html-код самой таблицы и номер новой версии страницы. Так будет выглядеть метод:
/**
* Создает таблицу в Confluence
*
* @param url адрес страницы
* @param login логин от учетки Confluence
* @param password пароль от учетки Confluence
* @param table html код таблицы
* @param title Название страницы
* @param pageVersion Версия страницы
*/
public static void createConfluenceTable(String url, String login, String password, String table, String title, int pageVersion) {
String TABLE_BODY = "{\n" +
" \"body\": {\n" +
" \"storage\": {\n" +
" \"value\": \"%s\",\n" +
" \"representation\": \"storage\"\n" +
" }\n" +
" },\n" +
"\n" +
" \"type\": \"page\",\n" +
" \"title\": \"%s\",\n" +
"\n" +
" \"version\": {\n" +
" \"number\": \"%s\"\n" +
" }\n" +
"}";
RestAssured
.given()
.auth()
.preemptive()
.basic(login, password)
.header("Content-Type", "application/json")
.header("Connection", "keep-alive")
.body(format(TABLE_BODY, table, title, pageVersion))
.when()
.put(url)
.then()
.statusCode(200);
}И главный метод для выполнения программы:
import utils.RequestExecutor;
import java.io.IOException;
import java.util.Scanner;
import static utils.TableGenerator.createTableBody;
public class App {
public static void main(String[] args) throws IOException {
//Путь до папки с отчетом
String PATH = "C:\\Users\\User\\Desktop\\allure-report\\data\\test-cases";
//Название страницы в Confluence
String TITLE = "Генератор таблиц iOS";
//Название таблицы
String NAME = ": \"№1 Смоук 1.01\"";
//Ссылка на отчет в CI
String LINK = "Отчет в CI";
//Запрос для получения номера текущей версии страницы в Confluence
String URL_GET = "https://***.ru/rest/api/content/123456789?expand=version";
//Запрос для создания таблицы в Confluence
String URL_POST = "https://***.ru/rest/api/content/123456789/";
System.out.println("Для подключения к учетной записи Confluence");
Scanner in = new Scanner(System.in);
System.out.print("Введите логин: ");
String login = in.nextLine();
System.out.print("Введите пароль: ");
String password = in.nextLine();
RequestExecutor.createConfluenceTable(
URL_POST,
login,
password,
createTableBody(PATH, LINK, NAME),
TITLE,
RequestExecutor.getNextPageVersion(URL_GET, login, password)
);
}
}Заключение
За счет того, что мы автоматизировали работу с отчетами, в нашем проекте удалось сделать тестирование быстрее и проще:
QA-специалисты смогли оперативно приступать к разбору отчетов, не затрачивая время на ручное создание таблиц и перенос данных из Allure-отчета.
Снизилась вероятность ошибок, которые могли возникнуть при ручном переносе данных из Allure-отчета в таблицу.
Работать с данными в таблице стало удобнее.
В рамках проекта тестирование проводили на трех платформах: web, Android и iOS. Генератором таблиц первоначально пользовались только мобильные команды, при этом веб-команда уже к следующему регрессу оценила их опыт и тоже начала пользоваться предложенным методом.
Полный код к статье доступен на GitHub.
Спасибо за внимание! Надеемся, что наш опыт был вам полезен.
Комментарии (4)

darkgrow
15.11.2021 09:27Добрый день. Пример отличный, но есть 2 вопроса. 1 - в папку результатов так же складываются все аттачи, но фильтрации к сожалению нет. 2 - информация по багу последнего падения, так же можно забирать из этого json, и не нужно заполнять в ручную.

SSul Автор
15.11.2021 11:01Здравствуйте. В статье мы привели немного упрощенный фрагмент кода, на практике в каждом проекте будут свои настройки. В частности, в нашем проекте была отдельная папка для attachments, поэтому мы не обращались к фильтрации. По второму вопросу — согласны, во многих проектах это бывает необходимо.
andriychuk94
Странно, но у меня почемуто не хочет генерировать.
SSul Автор
Добрый день! Обратите внимание, чтобы запустить приведенный код, нужно указать свои пути к папке отчета и нужным страницам в Confluence. Вы не могли бы написать чуть подробнее о том, какая была проблема и какие ошибки?