

Задачи компаний и их потребности в СХД меняются по мере развития. Рынок СХД тоже не стоит на месте. И проверенные 5 лет назад решения могут не тянуть сегодняшних задач. Потратив в общей сложности пару месяцев рабочего времени на выбор, тестирование, внедрение, диагностику и решение различных проблем с СХД QSAN XS1224 решил поделиться своим видением. Мне кажется, что многим это будет интересно. Описываемый период времени — с 2019 года по настоящий момент.
Может показаться, что у меня какие-то претензии к русскоязычной службе поддержки QSAN. На самом деле я им благодарен - несмотря на то, что не все проблемы получилось решить. Парни реально делали все что могли чтобы нам помочь. Спасибо.
1. Почему нам понадобилась новая СХД
Долгое время для системы виртуализации (oVirt) у нас использовалась СХД HP P2000g3. Но производительности ее уже не хватало. А самое главное - после неудачного обновления работала она на одном контроллере. Покупать второй было признано нецелесообразным ввиду морального устаревания.
2. Специфика нагрузки
По статистике со старой СХД получилось следующее. За сутки обрабатывалось около 4ТБ данных ~1200 IOPS. Соотношение чтение/запись - 1/3. Обычно наоборот чтения больше, но у нас статистика дала такой результат. Преимущественно случайная запись. В системе виртуализации крутится пара сотен виртуалок слабо нагруженных большую часть времени. Периодически коллеги гоняют тесты, потом они снова простаивают. В процессе тестов на локальные диски виртуалок (т.е. в итоге на СХД) пишутся логи и трейсы, которые потом подчищаются скриптовой обвязкой.
3. Выбери меня, выбери меня...
На основании данных о нагрузке сформировали требования к СХД. Получилось следующее
Рабочий объем - 40+ ТБ
IOPS - 3000+
Интерфейс - iSCSI 10G или FC 16G
И тут возникла мысль - «горячих» данных немного, а не попробовать ли конфигурацию с относительно медленными, но емкими NL-SAS дисками и SSD в качестве кэша?
Рассматривались несколько вариантов: Lenovo, Huawei, QSAN, Dell… В итоге по совокупности факторов остановились на QSAN. Поддержка SSD Cache была еще в нескольких моделях, но только для чтения. А тут еще интересное предложение «купи СХД и получи лицензию SSD Cache+Auto Tiering бесплатно».
4. Конфигурация
В течение месяца прибыла СХД QSAN XS1224. Два контроллера, Active-Active, по 2 интерфейса iSCSI 10Gb/s и FC 16Gb/s на каждом контроллере. 13 NL-SAS HDD ST10000NM0096 (10TB) и 2 SSD WUSTR6432ASS204 3.2TB.
СХД смонтировали в стойку. Firmware сразу обновили до последней на тот момент 1.4.2 (build 201910151200).
Для тестирования использовался сервер Supermicro X11DDW-L
CPU 2 x Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz, RAM 256GB
Ethernet 10Gb/s - PE310G2I50-T Server Adapter Dual Port Copper 10 Gigabit Ethernet PCI Express Server Adapter Intel® X550-AT2 Based
FC 16Gb/s - Qlogic QLE2672-E HD8310405-25 16Gbps Dual Port FC
5. Тестирование. Что мы хотели проверить
Целями тестирования было определено следующее:
Проверить производительность на разных типах интерфейсов (FC 16G/iSCSI 10G) с использованием MPIO и без;
Протестировать различные варианты конфигурации RAID;
Проверить работу SSD Cache;
-
Выбрать конфигурацию RAID для использования в системе виртуализации на основании полученных результатов.
Задачи всеми средствами выжать максимум скорости не стояло.
5.1 Пара слов о методике тестирования
За основу была взята отличная статья https://habr.com/ru/post/154235
Если коротко:
Используем тест fio. Разумеется с параметром direct. ioengine=libaio;
Метрика — IOPS;
Latency во время теста должна быть в разумных пределах (10 мс).
Нагрузка, которую создает тест, при прочих фиксированных настройках определяется параметром iodepth (глубина очереди). Т.е. мы измеряем значение IOPS при таком значении iodepth, чтобы latency оставалась в заданных пределах.
Судя по документации fio, в новых версиях появилась возможность автоматического подбора IO depth под заданное значение latency. Но у меня оно почему-то не заработало. Поэтому значения iodepth я подбирал вручную (использовал собственный скрипт-обертку для fio).
Далее если не оговорено явно, параметры теста следующие: 100% random read (или random write) блоком 4k. Для MPIO использовался стандартный для linux multipathd, path_grouping_policy multibus, path_selector round-robin 0.
Тестовый том объемом 1TB предварительно записывался мусором из /dev/urandom.
Кэш записи для тома в режиме write-back. Read ahead выключен. На random read мелким блоком он будет только мешать.
На всякий случай информация об ОС:
CentOS Linux release 7.7.1908 (Core)
Kernel 3.10.0-1062.4.1.el7.x86_64
i40e native 2.8.10-k
qla2xxx native 10.00.00.12.07.7-k
fio-3.7-1.el7.x86_64
5.2 Интерфейсы подключения
Собираем RAID0 из 1 SSD и измеряем производительность при подключении через iSCSI 10G и FC 16G. Подключение напрямую к серверу, без коммутаторов.
Первые результаты с нативным модулем qla2xxx оказались ощутимо меньше ожидаемых:
FC 16G без MPIO.
Random read, 4k - avg. latency 7.9ms, bw 266 MB/s, avg. IOPS 64866
Random write, 4k - avg. latency 7.7ms, bw 273 MB/s, avg. IOPS 66570
FC 16G с MPIO (второй FC линк подключен ко второму контроллеру СХД).
Random read, 4k - avg. latency 5.3ms, bw 397 MB/s, avg. IOPS 96985
Random write, 4k - avg. latency 4.9ms, bw 427 MB/s, avg. IOPS 104134
Выяснилось, что при работе теста одно ядро CPU загружается на 100%. На нем обрабатываются прерывания от FC адаптера. В CentOS 7 появился параметр модуля qla2xxx - ql2xmqsupport. При выставлении в 1 создает дополнительные очереди. На тот момент в RHEL7 данная возможность шла в статусе technological preview. Есть баг BZ#1414957 - снижение производительности.
Кроме того выяснилось, что в системе с двумя контроллерами работа с диском через preferred контроллер оказывается ощутимо быстрее.
Результаты со включенным ql2xmqsupport.
FC 16G без MPIO
Random read, 4k - avg. latency 7.6ms, bw 275MB/s, avg. IOPS 67248
Random write, 4k - avg. latency 5.9ms, bw 355MB/s, avg. IOPS 86739
FC 16G с MPIO
Random read, 4k - avg. latency 4.2ms, bw 502MB/s, avg. IOPS 122477
Random write, 4k - avg. latency 4.3ms, bw 485MB/s, avg. IOPS 118325
Увеличение параметра iodepth уже не давало прироста IOPS. Любопытно, что без MPIO запись получилась быстрее чтения. Я списал это на особенности работы qla2xxx с ql2xmqsupport.
Теперь с iSCSI. Заодно посмотрим, как повлияет включение jumbo frames (MTU 9000).
ISCSI 10G без MPIO.
Jumbo off, random read, 4k - avg. latency 8ms, bw 130MB/s, avg. IOPS 31851
Jumbo off, random write, 4k - avg. latency 7.6ms, bw 137MB/s, avg. IOPS 33443
Jumbo 9000, random read, 4k - avg. latency 8.9ms, bw 117MB/s, avg. IOPS 28578
Jumbo 9000, random write, 4k - avg. latency 6.8ms, bw 152MB/s, avg. IOPS 37204
ISCSI 10G c MPIO.
Jumbo off, random read, 4k - avg. latency 8.8ms, bw 237MB/s, avg. IOPS 57867
Jumbo off, random write, 4k - avg. latency 8.1ms, bw 258MB/s, avg. IOPS 62999
Jumbo 9000, random read, 4k - avg. latency 8.5ms, bw 244MB/s, avg. IOPS 59677
Jumbo 9000, random write, 4k - avg. latency 8.1ms, bw 258MB/s, avg. IOPS 63074
Результат в целом ожидаем: iSCSI 10G примерно соответствует по производительности FC 8G. А у нас FC 16G, так что разница в скорости в ~2 раза вполне закономерна. Включение jumbo frames дает падение производительности без MPIO. Вероятно latency увеличивается.
5.3 Типы RAID. Их преимущества и недостатки. Странности с RAID10
Далее все тесты при подключении по FC 16G. Поскольку HDD значительно медленнее SSD, а стабильность работы qla2xxx с включенным ql2xmqsupport под вопросом далее тестируем без ql2xmqsupport.
5.3.1 Конфигурация пула: 12 NL-SAS HDD ST10000NM0096 10TB в RAID 10. Thick provisioned.
Без MPIO
Random read, 4k - avg. latency 9.5ms, bw 3428kB/s, avg. IOPS 836
Random write, 4k - avg. Latency 9.4ms, bw 13.8MB/s, avg. IOPS 3366
С MPIO
Random read, 4k - avg. latency 10.3ms, bw 3158kB/s, avg. IOPS 770
Random write, 4k - avg. latency 9.6ms, bw 13.6MB/s, avg. IOPS 3328
Очень низкая скорость чтения с RAID10. И если высокую скорость записи еще можно объяснить какими-то оптимизациями, кэшем, NCQ и т. п. то с чтением пришлось разбираться.
И это первая особенность СХД QSAN, а точнее реализации RAID10 от QSAN.
Для томов в пуле RAID10 чтение идет только с нечетных дисков в пуле. Это хорошо видно по графикам производительности в web-интерфейсе СХД.
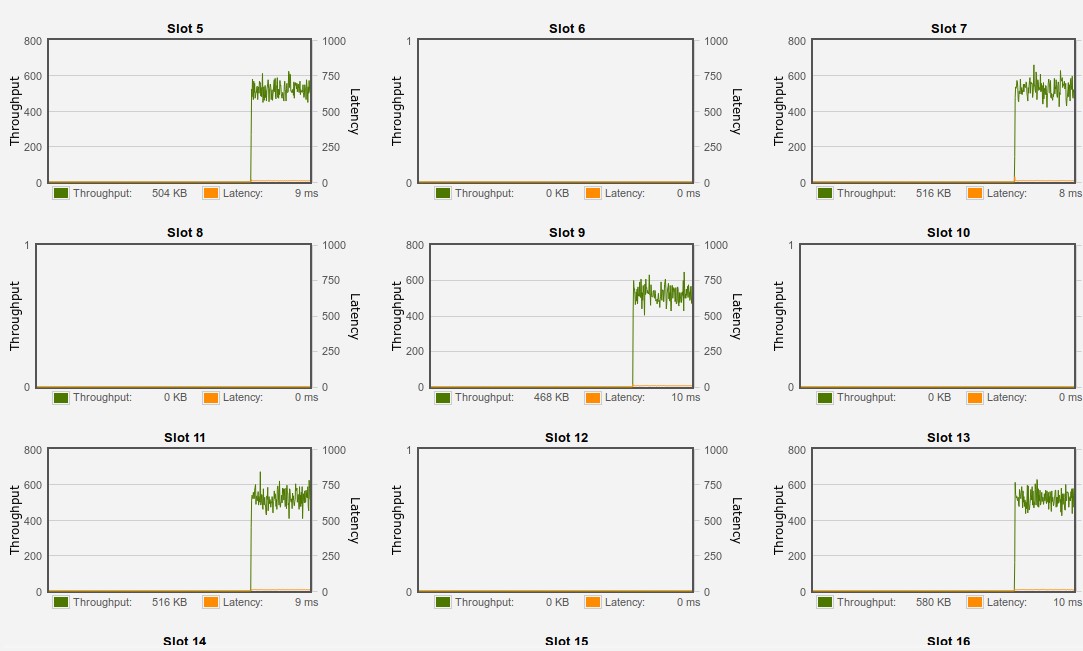
Есть один способ это обойти — использовать thick provisioned пул и при создании тома выбрать Full Erase данным. Если вы увеличите том в дальнейшем, чтение с добавленного места будет также использовать только нечетные диски. Немного забегая вперед, если добавить к тому SSD кэш, то баг проявляется даже если был выбран параметр Full Erase.
Результаты для тома, инициализированного с Full Erase:
Random read, 4k - avg. latency 10.3ms, bw 6352 kB/s, avg. IOPS 1550
Описание проблемы было отправлено в поддержку QSAN в ноябре 2019. Проблему подтвердили. Летом 2021 я еще раз уточнил статус обращения и получил ответ в духе: «О проблеме известно давно, но без изменения внутренней логики это не исправить. Даже примерных сроков решения нет.»
5.3.2 Конфигурация пула: 12 NL-SAS HDD ST10000NM0096 10TB в RAID 6 (одна группа). Thick provisioned.
По результатам теста RAID10 видно, что MPIO не дает прироста производительности (упираемся в диски). Далее тесты HDD без MPIO.
Random read, 4k - avg. latency 9.8ms, bw 6643kB/s, avg. IOPS 1621
Random write, 4k - avg. latency 8.7ms, bw 3761kB/s, avg. IOPS 918
И это провал. Запись почти в 4 раза медленнее. А у нас, напомню, ¾ нагрузки именно запись.
5.3.3 Конфигурация пула: 12+1 spare NL-SAS HDD ST10000NM0096 10TB в RAID 6EE (одна группа). Thick provisioned.
Еще одна интересная поддерживаемая конфигурация пула — RAID6EE. То есть RAID6 с активным Spare.
Random read, 4k - avg. latency 9.4ms, bw 6923kB/s, avg. IOPS 1690
Random write, 4k - avg. latency 7ms, bw 4606kB/s, avg. IOPS 1124
Прирост производительности при случайном чтении получился чуть более 4 процентов. На самом деле неплохо, даже если просто суммировать IOPS-ы максимум, что можно ожидать это прирост производительности примерно на 8 процентов.
С тестом random write тут возможно что-то не так. Статью я пишу постфактум, на основании своих комментариев к задаче в YouTrack. В других тестах прирост IOPS для RAID6EE по сравнению с RAID6 скромнее. Но в имеющихся результатах разный iodepth (здесь iodepth 8). А повторить тест я не могу поскольку СХД под нагрузкой. Результат с iodepth 16:
Random write 4k, avg. latency 16.3ms, bw 4018kB/s, IOPS 980
Итак, RAID 6EE в 3 с лишним раза медленнее RAID10 на запись.
5.4 SSD-Cache. Ради чего все затевалось
Чтобы использовать SSD Cache требуется отдельная лицензия (мы получили ее по акции).
Работа QSAN SSD Cache достаточно подробно описана в документации к SANOS 4.0. Кроме того существует XCubeSAN Series White Paper - SSD Cache 2.0.
Итак:
Кэш может использоваться как read only (в этом случае достаточно одного SSD), так и read-write (минимум 2 SSD).
Параметры SSD Cache pool:
Cache Block Size - размер блока. 1-4MB
Populate-on-read Threshold - 1-4
-
Populate-on-write Threshold - 1-4
3. Дисковое пространство на HDD и место в SSD Cache разбивается на блоки размером Cache Block Size.
4. При чтении если такой блок считывается Populate-on-read Threshold раз, этот блок переносится в SSD Cache. Очевидно, что к блоку привязан счетчик обращений и, видимо, таймер. Последующие чтения берут блок уже из SSD Cache.
5. При записи блок пишется в SSD Cache. Write threshold при этом похоже не используется (оно для read only кэша - будут ли записываемые данные сохранятся в кэше).
Из нескольких тестовых прогонов стало ясно, что:
Изменить размер кэша SSD для тестов никак нельзя. Определяется размером SSD.
На RAID 10 при добавлении SSD Cache баг чтения только с нечетных дисков воспроизводится независимо от того использовали Full Erase при инициализации или нет. Отключаем SSD кэш для тома и чтение снова начинает проходить со всех дисков (Full-Erase том).
Прочитал весь том (1ТБ) в /dev/null. При этом он весь уместился в SSD кэш. При чтении скорость как с SSD. HDD не используются вообще.
При записи нескольких десятков гигабайт (в этот момент все данные с тома сидят в SSD read cache - это важно!) данные пишутся только в SSD кэш. После этого где-то минут через 10 данные начинают сбрасываться на HDD.
-
После сброса SSD кэша (Disable/Enable) на RAID 10 при записи блоком 4к наблюдаю нагрузку на нечетные HDD в пуле, диски в SSD кэше и низкую скорость. Дело в том, что контроллер оперирует блоками размером Cache Block Size (1MB минимум). Т.е. при записи 4к блока на самом деле происходит следующее.
При прогреве кэша это будет давать лишнюю нагрузку. А самое главное абсолютно непонятно как это количественно протестировать.
Если используем полностью случайное распределение и размер тома намного (в 10 раз) больше, чем SSD Cache имеем следующее:
HDD в SSD кэш считывается Cache Block Size данных.
Блок 4к данных в кэше меняется на то, что мы записали.
При случайном чтении мелким блоком разницы в производительности почти нет, или имеем незначительное снижение скорости (тем большее, чем меньше значение Populate-on-read Threshold). Происходит следующее: при считывании маленького блока (1 или более раз в зависимости от Populate-on-read Threshold) считывается в SSD Cache целиком Cache Block Size (1-4МБ). После чего запросы к этому блоку будут обращаться к SSD. Но если размер тома в 10 раз больше, чем SSD Cache, прирост производительности не будет больше 10%. И его полностью съест overhead на чтение большого блока с HDD на SSD.
При случайной записи мелким блоком в первые 10 минут (задержка перед началом сброса данных из SSD Cache на HDD если к данным больше не было обращений) все выглядит прекрасно - фактически запись мелким блоком превращается в чтение c HDD большим блоком.
А вот через 10 минут начинается сброс SSD кэша на HDD большим блоком. И производительность резко падает.
Замечание: fio по умолчанию использует одно и то же начальное значение для генератора случайных чисел. Т.е. при с каждом запуске идет обращение к одним и тем же секторам. Что в случае с SSD Cache дает неверные результаты. См. параметр randrepeat.
Таким образом, для теста SSD Cache будет важно не только соотношение R/W, кол-во IOPS и т.п., но и распределение I/O по блокам тома.
А время прогрева кэша делает такое тестирование неприемлемо долгим.
Оценка ситуации методом 3П (палец-пол-потолок), консультации с коллегами, и тот факт, что «горячих» данных у нас относительно немного привели к двум выводам:
На нашей нагрузке SSD наверняка даст ощутимый прирост скорости, но измерить его на синтетических тестах не представляется возможным;
А давайте запустим СХД в работу, мигрируем на нее часть виртуалок, соберем статистику по latency, а потом включим SSD Cache и будем сравнивать именно latency для оценки эффективности SSD Cache.
5.5 Auto-Tiering
В целом есть общие черты с SSD Cache. Начиная с того, что для использования требуется отдельная лицензия.
Auto-tiering пул состоит из нескольких групп дисков. Место в пуле делится на блоки по 1ГБ, называемые Sub-LUN. Для каждого Sub-LUN собирается статистика. Полученное значение раз в сутки делится пополам. По расписанию выполняется задача, выполняющая перемещение "горячих" данных на более быструю группу, а редко используемых данных на медленную.
По умолчанию с auto-tiering используется thin-provisioning. Thick-provisioned пул можно конвертировать в auto-tiering путем добавления группы с более высоким тиром. Однако доступное место в пуле в случае использования thick-provisioning не увеличится (для thin-provisioning объем групп дисков в auto-tiering пуле суммируется). Конвертация необратима, т.е. удалить группу дисков высокого тира из auto-tiering пула уже нельзя.
Конвертация занимает довольно длительное время. При этом никакого способа посмотреть прогресс нет.
Существует несколько политик, из которых наиболее любопытна Start Highest then Auto Tiering. Т.е. новые данные пишутся на самые быстрые диски. А затем работает стандартный auto-tiering. В процессе конвертации thick-пула в auto-tiering политика работать не будет. Я потратил довольно много времени, пытаясь понять, почему данные пишутся на HDD хотя выбрано Start Highest then Auto Tiering.
В служебных целях резервируется 10% места на группах дисков всех тиров кроме самого низкого.
Раз в час обсчитывается промежуточная статистика Auto-tiering.
Перемещение данных между тирами выполняется по расписанию. Можно задать время, продолжительность и приоритет (высокий, средний и низкий) переноса данных.
Auto-tiering использовать не предполагалось, поскольку SSD кэш казался более «перспективным». Поэтому тесты проводились лишь с целью посмотреть, как будут работать разные типы пулов (thin/thick provisioned) и разные политики.
Проверил, как работает free space reclamation в thin-пулах (требуется перезапись свободного места нулями, discard не поддерживается).
Интересной особенностью стало то, что если создать thick-provisioned пул RAID10, в нем том, инициализированный с Full Erase, а затем конвертировать пул в auto-tiering, то, в отличие от использования SSD Cache, баг чтения только с нечетных дисков в пуле не воспроизводится.
5.6 Тесты комплекса Видеопортал
Пользуясь моментом, на этом же оборудовании провели нагрузочное тестирование системы Видеопортал. Сервер VP-GW получал N потоков по 1Mbit/s, эмулирующих камеры видеонаблюдения, и писал их в архив.
Конфигурация СХД: Thick-provisioned пул RAID10 со включенным SSD Cache, том инициализирован Full Erase, подключение по FC 16G, с MPIO.
Тестами занимался не я, поэтому из результатов сохранилась только утилизация диска:
700 камер — 85% утилизации.
750 камер — 90% утилизации.
5.7 Выводы по результатам тестирования
Было протестировано еще несколько конфигураций пула. RAID 5, RAID 5EE, RAID 60, RAID 60EE. В целом результаты получились ожидаемые.

RAID 5/5EE по скорости записи занял промежуточное положение между RAID 10 и RAID 6/6EE.
Rebuild в RAID EE действительно происходит быстрее. Для пула RAID 6EE и единственного тома (thick provisioned) объемом 30TB EE-Rebuild занял около 4 часов.
При увеличении размера тестового тома с 1 до 30 TB результаты тестов случайного чтения/записи становятся хуже на 20-30%. Возможно это связано с большей амплитудой движения головок HDD. Как бы то ни было, случайная запись на RAID 6/6EE страдает.
RAID 60/60EE оказывается еще медленнее чем RAID 6/6EE. 6 дисков в группе слишком мало.
Интересная возможность: СХД запоминает и ведет историю созданных на ней томов. И позволяет восстановить их параметры, если том был случайно удален (также это похоже единственный способ починить том, если несколько на дисков в пуле сделать Free - просто удаляем полностью пул с томами и восстанавливаем конфигурацию). LUN Mappings, разумеется, слетают.
При восстановлении таким образом RAID EE все EE spare просто включаются в пул. Получаем RAID EE без EE spare дисков зато большего объема. За данные в таком случае не уверен. Отчет в QSAN так и забыл написать. Через резервное копирование и восстановление конфигурации томов работает нормально.
Еще одна особенность: для тома может быть создан LUN Mapping или на iSCSI или на FC. Оба одновременно нельзя.
На основании полученных данных было принято решение использовать thick provisioned пул RAID10. Тома инициализировать Full Erase. Включение SSD Cache оставить на потом, когда соберем статистику (latency в первую очередь) под рабочей нагрузкой.
6. Запуск в работу. Конфигурация
Ноды системы виртуализации подключались по iSCSI 10G.
Коммутаторы Huawei S6720-32CI-SI (медные порты 10G Ethernet).
Конфигурация в целом стандартная для подключения СХД к нескольким серверам, но, памятуя об определенных странностях еще в oVirt 3.4 при подключении к iSCSI storage с MPIO, я каждый коммутатор подключил к «своему» контроллеру СХД с использованием агрегации линков 802.3ad (LACP). XS1224 это умеет.
На паре новых нод была настроена загрузка по iSCSI с томов на СХД. В процессе нашел баг в dracut: на двухпортовых сетевушках dracut поднимает автоматически только один интерфейс: тот, который использовался для загрузки (PRIMARY). Скрипт проверяет значение /sys/firmware/ibft/ethernet*/flags, если бит 1 не установлен интерфейс пропускается. Это напрочь ломает multipath (MPIO).
https://github.com/dracutdevs/dracut/pull/724 приняли , но в RHEL он кажется пока не попал.
Временный фикс:
При установке настраиваем второй интерфейс вручную, чтобы активировался multipath (возможно, можно пропустить, но пока не проверял).
В установленной ОС выполнить.
# sed -i.bak -re 's/^([[:space:]]*\(\( \$flags & 2 \)\) \|\| continue)/#\1/' /usr/lib/dracut/modules.d/40network/net-lib.sh
# dracut -fДалее все стандартно: подготовили план миграции, скрипт ansible, выполняющий останов VM, перенос диска, запуск и проверку доступности VM. Настроили снапшоты для тома с важными VM, мониторинг и т.п. И приступили к переносу виртуалок.
7. Проблемы
А теперь попытаюсь рассказать, с какими проблемами мы столкнулись при эксплуатации СХД, как их диагностировали и как с ними справлялись. Первой ласточкой стали необъяснимые задержки IO операций, на которые нам пожаловались пользователи. С момента запуска СХД в работу прошло почти полгода, а мы перенесли лишь около трети виртуалок… Правда firmware уже успели обновить до 1.4.3.
7.1 Задержки IO и как мы их победили
Настроенный мониторинг проблем не показывал. Но он собирал статистику с самой СХД через Web. А пользователи жаловались на задержки по нескольку секунд.
В недоумении я запустил на виртуалке такой однострочник (читаем случайный сектор и если dd будет отрабатывать более 1 секунды выводим текущее время и сколько времени заняло выполнение)
while :; do T=$(dd if=/dev/$DEV of=/dev/null count=1 skip=$(($RANDOM$RANDOM$RANDOM % 10485760)) 2>&1 | tail -1 | awk '{print $6}') ; [[ $T =~ ^0, ]] || echo "`date` $T" ; sleep 1 ; doneА на следующий день увидел такую картину:
Пт окт 23 02:23:59 MSK 2020 1,4242
Пт окт 23 08:30:52 MSK 2020 4,49554
Пт окт 23 11:32:40 MSK 2020 9,37445
Кроме того, удалось поймать ситуацию, когда задержки случались одновременно на нескольких нодах oVirt. В логах СХД постоянно появлялись сообщения об iSCSI connect/disconnect с уровнем INFO.
Собрав всю возможную информацию, включая дампы iSCSI в момент проблемы, я завел обращение в поддержку на https://support.qsan.su и на следующий же день получил набор рекомендаций.
Первым делом переделали подключение коммутаторов к СХД, убрав агрегацию линков с LACP и переделав подключение на MPIO. В процессе перегрузили СХД (oVirt пришлось полностью останавливать, но увы, он не умеет штатно делать перенастройку подключения к storage domain. Пришлось лезть в БД ovirt-engine и править непосредственно там. После перезагрузки задержки стали проявляться реже и максимум на 1-2 секунды.
Кроме того, выключили jumbo frames, заменили все патчкорды на Cat.6, а на коммутаторах настроили tail-drop-profile (больше HUAWEI S6720-32C-SI-AC ничего не умеют). Примерно так:
qos tail-drop-profile TDP-SAN
qos queue 0 max-length 512 green max-length 256
qos queue 0 max-buffer 4096 green max-buffer 2048
qos tail-drop-profile TDP-HOSTS
qos queue 0 max-length 256 green max-length 128
qos queue 0 max-buffer 2048 green max-buffer 1024И обновили firmware контроллеров СХД до 1.4.6.
Не уверен, что именно из этого помогло, но задержки пропали. И впору бы радоваться, но обновление 1.4.6 сломало загрузку с iSCSI и две ноды oVirt не могли загрузиться.
7.2 Чиним iSCSI boot
При загрузке iSCSI BIOS сетевого адаптера (PE310G2I50-T Dual Port Copper 10G на базе Intel® X550-AT2) видел LUN, но категорически не хотел с него грузиться. Черный экран, мигающий курсор и сообщение Read Error минут через 5. Быстро загрузился с Live Ubuntu, apt install open-iscsi, discover, login — все работает. А грузиться не хочет.
Можно было бы попробовать откатить версию firmware, но я уже запустил большую часть виртуалок...
Нашел пару HDD, поставил в сервера, перенес систему с тома iSCSI на локальный диск, запустился. И снова тесты, дампы, разные версии iSCSI firmware для Intel® X550-AT2, обращение в поддержку. Загрузка по FC работала, что характерно.
В итоге проблему локализовали. Затрагивала она сетевые платы Intel (по крайней мере с Qlogic загрузка iSCSI работала). Исправление вошло в firmware 2.0.1, которое вышло только в июне 2021 года.
7.3 SSD-Cache. Кончился
К июню месяцу перенос VM со старой СХД был наконец завершен. Появился новый проект, под него создали еще несколько виртуалок, нагрузка возросла и latency на disk IO стала заметно расти. Самое время включить SSD Cache и сравнить, насколько станет быстрее. Что и было сделано 6 июля.
Результат превзошел ожидания. Все просто летало.
А тут еще обновление 2.0.1 подоспело, с исправлением загрузки по iSCSI, которое я, пользуясь выходными, и установил 10 июля.
Все уже поняли к чему я веду? В понедельник 12 июля все сломалось. Визуально SSD кэш работал, в нем даже оставалось свободное место, но задержки были по 200мс.
Помогло выключение SSD кэша и включение его обратно. При выключении все данные из кэша сбрасываются на HDD. А это почти 3 ТБ. Процесс сброса занял почти сутки. Задержки IO при этом были по 500 мс. После включения все снова летало.
Привычно собрал диагностику, написал обращение в поддержку: «Обновление 2.0.1 как-то криво работает с SSD Cache». А 20 числа ситуация повторилась. И возникло подозрение, что обновление тут не при чем, а дело в самом SSD Cache. А именно — в нем кончилось место.
Хотя в статистике по использованию SSD Cache суммарно используемый объем меньше, чем размер SSD, понятно, что где-то нужно хранить сервисную информацию. Вероятно она и занимает оставшееся место.
Что произойдет если в SSD кэше не останется места?
Предположим пишем 1 сектор. Он попадет сразу на SSD. Но поскольку места там нет, его нужно будет освободить. Как? Например, сбросить мало используемый блок на HDD. Минимальный размер блока 1 MB. Пишем 1MB на HDD. Сколько это IOPS? 4 или 8? Потом нужно считать 1 MB с HDD в SSD кэш. Еще 4 или 8 IOPS.
Отсюда и тормоза. Ситуацию могла бы исправить некая настройка, позволяющая управлять агрессивностью сброса SSD кэша на HDD. Но ничего такого нет.
Судя по документации на SANOS 4.0
Flush Write Data to HDD Volume
In SSD read-write cache, the write data will be flushed to the HDD volume in the following situations.
Flush data to the HDD volumes before the SSD cache pool is deleted.
Flush data to the HDD volumes before the related volume is disabled.
Flush data when the system is idle.
Вопрос, как определяется это «system is idle». По результатам общения с поддержкой удалось выяснить что:
Если блок попал в кэш, то может там находиться, пока достаточно свободного места для новых блоков. Если система не сильно нагружена, то редко используемые блоки будут удаляться (в случае read cache) или сбрасываться на диски (в случае write cache). Понятие idle определяется внутренними алгоритмами. К сожалению, подробного описания на этот счет нет.
Подведем итоги. Если у вас много случайной записи и система сильно нагружена QSAN SSD Write Cache непригоден к использованию. Возможно, дело тут в паттернах нагрузки и это нам так повезло, но сильно на него рассчитывать не стоит.
И это в самом деле печально, ведь, судя по графикам производительности с СХД, при нормальной работе SSD кэша нагрузка на HDD минимальна. Если бы часть данных с SSD сбрасывать на них не дожидаясь пока место в кэше закончится…
Тут я и вспомнил про Auto-Tiering. Почти тот-же SSD кэш, просто логика немного другая.
7.4 Auto-Tiering. Подождите с вашим IO, мне надо подумать...
Ну и пусть не получилось с SSD Cache. Есть же Auto-tiering. Пусть ночью перекидывает данные и подтормаживает, зато днем с политикой Start Highest then Auto Tiering все будет летать. Заодно в данном случае не воспроизводится баг с RAID10. Сказано — сделано. И вроде все быстро. Но через пару дней в логах oVirt я заметил сообщения вида:
Storage domain ... experienced a high latency of 6.07162 seconds from host …И снова расчехляем скрипт, читающий случайный сектор раз в секунду и видим следующее:
Одна нода
Thu Aug 12 13:37:39 MSK 2021 5.89858
Thu Aug 12 14:37:43 MSK 2021 6.29794
Вторая нода
Чтв Авг 12 13:37:39 MSK 2021 1,24253
Чтв Авг 12 14:37:43 MSK 2021 1,38901
И так стабильно раз в час.
Правда, судя по всему, из виртуалок это не так заметно (может проявляется так явно только при чтении с дисков нижнего тира).
Описываю ситуацию поддержке и получаю ответ:
В лабе удалось поймать такой же эффект, как и у вас. После анализа выяснилось, что в такие моменты СХД производит анализ собранной статистики для осуществления Auto Tiering. Поэтому небольшой всплеск latency, увы, возможен.
Предложенный вариант решения (отключение auto-tiering для части томов) нас не устроил. Пока взяли таймаут. На удивление пользователи не осаждают нас с вопросами: «Почему все так тормозит?». Возможно, привыкли.
7.5 Пути назад нет
Я уже писал ранее, сейчас просто напомню, что убрать уровень из пула со включенным auto-tiering нельзя. SSD там застряли навсегда. Тлен и безысходность...
8. Выводы
Нам хотелось за умеренные деньги получить систему хранения данных одновременно и емкую и быструю. Почти получилось. Остается только надеяться, что найденные проблемы в будущем исправят.
СХД QSAN XS1224 - очень интересный продукт, но к сожалению оставляет впечатление какой-то незаконченности…
И если меня сейчас спросят: «Мы хотим СХД, у нас много случайной записи, но All-Flash для нас слишком круто. Что нам выбрать?» я скорее предложу какое-то максимально простое решение с SFF дисками на 10k RPM. Без вот этого вот всего.
В общем, последую рекомендации из старорусской берестяной грамоты № 35. То есть «не оригинальничай», «будь как все», «не выпендривайcя» - и будет счастье.
Комментарии (16)

Lonesome
10.11.2021 22:38+1Интересный опыт… Как то возникает ощущение, что вы приключения любите. Была у нас где то с 2010 по 2015 EMC cx4-120 с sad кэшем. Купили, включили, через пять лет заменили (продление поддержки не стоило своих денег) на EMC VNX 5200 с tiering’ом. Потом появился требовательный сервис, и через два года добавили ssd полку (они как раз резко подешевели). В этом году и ее заменили на PureStorage. После перевода в production, никакие настройки вообще никогда не трогаем. Только LUNы создаём или расширяем.

alex103
11.11.2021 06:21В общем, последую рекомендации из старорусской берестяной грамоты № 35.
Я так и знал, что монголо-татары тут не причем..!!!

yoz
11.11.2021 12:58СХД за пределами брендов основной старейшей «кучки» производителей — лотерея. Вы вытянули не выигрышный билетик, не повезло.

ess1980 Автор
11.11.2021 14:43+1Оно и с брендами - без гарантии. Со старой СХД HP P2000 после обновления firmware штатной утилитой вместо контроллеров получили 2 "кирпича". Вероятно по причине того, что ревизии контроллеров отличались. До этого дважды успешно обновлял через загрузку образа firmware по FTP.

NoOne
12.11.2021 02:06Поддержка что ответила? Заменили контроллер?
ess1980 Автор
12.11.2021 13:43P2000 приобреталась в 2012 году. К 2019 и гарантия и поддержка закончились. В поддержке HP предложили купить новый контроллер, но цена и сроки поставки нас не устроили.
Нашли на авито Б/У контроллер, купили в один день, обновили на ту-же версию firmware (деталей не помню уже, по моему обновленная прошивка на midplane не работала со старой в контроллере), запустились. Конфигурация хранится в midplane, поэтому все поднялось и обошлось без потери данных.
NoOne
12.11.2021 21:31Если что, поддержка ещё не закончилась даже в 21 году. Но если она не была куплена на тот момент, то вопросов нет

blokhinaleks
11.11.2021 14:46Проверяли ли тот факт, что два контроллера действительно "Active-Active"? Был опыт тестирования СХД, которая также заявлена "Active-Active", но при выдёргивании активного контроллера диски на хостах были недоступны 43-45 секунд, а официальный саппорт сказал "там на .... странице написано, что все сервисы (которые располагают свои данные на СХД) должны быть настроены на таймаут по диску 90 секунд, соответственно 45 секунд переключения не является проблемой". Поэтому перед покупкой лучше взять у вендора/интегратора аналогичный девайс на тест. Если "нет возможности предоставить", то лучше не связываться с таким оборудованием. Хорошие СХД всегда дают попробовать. Кроме того, это даёт возможность проверить не только синтетическими тестами, а реальной нагрузкой.
ess1980 Автор
11.11.2021 15:07Действительно Active-Active. Правда контроллеры на горячую не выдергивали, но при обновлении firmware контроллеры обновляются и перегружаются по очереди. Лаг на IO при этом получился около 10 секунд. Значение по умолчанию для scsi timeout в linux 30 секунд.
blokhinaleks
11.11.2021 23:16Если лаг есть, значит всё же второй пассивный. При этом очень странно, что при обновлении, когда ребут штатный, СХД не передала корректно управление второму контроллеру.
Timeout iSCSI то 30 секунд, но приложения, которые там хранят данные, могут быть разные и не все из них выдержат. Нормальный Activ-Active - когда под хорошей нагрузкой выдёргиваешь контроллер и единственное, по чём это заметно - это запись в логе, что часть путей потерялись.
ess1980 Автор
12.11.2021 14:42Я допускаю, что в лабораторных условиях возможно "под хорошей нагрузкой выдёргиваешь контроллер и единственное, по чём это заметно - это запись в логе". В реальности "есть один нюанс...". Даже не один.
Во первых как быстро сервер будет определять что MPIO путь потерялся. Если контроллер "выключился" он уже не ответит. Т.е. тут будет некий таймаут. Сильно меньше секунды его не сделать. Иначе при любом повышении нагрузки будут ложные срабатывания и пути будут теряться. Если в какой-то момент они потеряются все получим IO error. Multipathd тюнить я не пробовал - 10 секунд для нас некритично.
Во вторых XS1224 не поддерживает диски SAS dual port. Т.е. в один момент времени с дисками работает только один контроллер (есть настройка preferred controller для пула). Если preferred controller выходит из строя второй должен понять, что первый не отвечает и начать сам работать с дисками. Это напоминает HA кластер и сильно уменьшить таймаут тут тоже не получится - будут ложные переключения.
Строго говоря, стоило бы называть Active-Active только конфигурации с SAS DP. Но что поделаешь, маркетинг... Снаружи то MPIO работает - не подкопаешься.
Другой разговор, что работает оно похоже за счет того, что второй контроллер запросы от сервера редиректит на preferred controller.
Я тестировал на SSD есть ли разница через какой контроллер сервер подключен к СХД - с preferred controller получалсь до 40% быстрее. Правда это а) было на firmware 1.4.2 - может что-то уже поменялось. б) c HDD будет незаметно - раньше упремся в производительность дисков.

Skilline
12.11.2021 14:12Евгений, спасибо вам за такой подробный и профессиональный обзор нашего оборудования. Для вендора и для нас, как их дистрибьютера, очень важна обратная связь от конечных пользователей наших решений. Сожалеем, что вам пришлось столкнуться с рядом проблем, и не все ваши ожидания оправдались. С вашей помощью мы станем лучше)).
Всегда открыты для любых ваших вопросов, комментариев и готовы помочь с решением проблем через службу поддержки support.qsan.su.
ess1980 Автор
12.11.2021 15:45+1Еще раз спасибо за помощь в решении проблем и за то, что читали длинные портянки с описанием и диагностикой).
Надеюсь со временем все мелкие недочеты будут устранены. Как говорится: "Путь наш извилист, но перспективы наши светлые".
nsemenoff
Получился настоящий детектив от системного администратора - хоть текст и длинный, но все равно хочется дочитать и узнать, чем закончилось
ess1980 Автор
Спасибо. Если статья окажется полезной я буду рад - не зря писал.