
Давным-давно наш коллега @novarразместил на Хабре статью с описанием вот такого незатейливого ТЗ, полученного им от потенциального работодателя:
Реализовать класс для задания и расчета времени по расписанию. Расписание задано в стиле crontab (точный формат см. во вложении), требуется находить ближайшие в будущем или прошлом моменты, попадающие в это расписание. Обращаю Ваше внимание, что класс должен быть эффективным и не использовать много памяти и ресурсов даже тогда, когда в расписании задано много значений. Например очень много значений с шагом в одну миллисекунду.
Я бы прошел мимо, и уж тем более не стал бы писать целую статью (!), если бы не несколько но:
тестовое только с виду выглядит простым
автора с его работой работодатель грубо «послал»
автор, а затем и @PsyHaSTe, предложили не самый оптимальный алгоритм
да просто тот случай, когда тестовое зацепило
Хочу предложить алгоритм, приближающийся к O(1) во всех возможных ситуациях, вместо оригинального O(n). Интересующихся прошу под кат.
Ах да. Если вы тот самый работодатель, вот готовый код под ваше ТЗ. Правда на Java, а не на C#. Но вы же не думали, что всё будет так просто?
Исходное задание от работодателя
using System;
namespace Test
{
/// <summary>
/// Класс для задания и расчета времени по расписанию.
/// </summary>
public class Schedule
{
/// <summary>
/// Создает пустой экземпляр, который будет соответствовать
/// расписанию типа "*.*.* * *:*:*.*" (раз в 1 мс).
/// </summary>
public Schedule()
{
}
/// <summary>
/// Создает экземпляр из строки с представлением расписания.
/// </summary>
/// <param name="scheduleString">Строка расписания.
/// Формат строки:
/// yyyy.MM.dd w HH:mm:ss.fff
/// yyyy.MM.dd HH:mm:ss.fff
/// HH:mm:ss.fff
/// yyyy.MM.dd w HH:mm:ss
/// yyyy.MM.dd HH:mm:ss
/// HH:mm:ss
/// Где yyyy - год (2000-2100)
/// MM - месяц (1-12)
/// dd - число месяца (1-31 или 32). 32 означает последнее число месяца
/// w - день недели (0-6). 0 - воскресенье, 6 - суббота
/// HH - часы (0-23)
/// mm - минуты (0-59)
/// ss - секунды (0-59)
/// fff - миллисекунды (0-999). Если не указаны, то 0
/// Каждую часть даты/времени можно задавать в виде списков и диапазонов.
/// Например:
/// 1,2,3-5,10-20/3
/// означает список 1,2,3,4,5,10,13,16,19
/// Дробью задается шаг в списке.
/// Звездочка означает любое возможное значение.
/// Например (для часов):
/// */4
/// означает 0,4,8,12,16,20
/// Вместо списка чисел месяца можно указать 32. Это означает последнее
/// число любого месяца.
/// Пример:
/// *.9.*/2 1-5 10:00:00.000
/// означает 10:00 во все дни с пн. по пт. по нечетным числам в сентябре
/// *:00:00
/// означает начало любого часа
/// *.*.01 01:30:00
/// означает 01:30 по первым числам каждого месяца
/// </param>
public Schedule(string scheduleString)
{
}
/// <summary>
/// Возвращает следующий ближайший к заданному времени момент в расписании или
/// само заданное время, если оно есть в расписании.
/// </summary>
/// <param name="t1">Заданное время</param>
/// <returns>Ближайший момент времени в расписании</returns>
public DateTime NearestEvent(DateTime t1)
{
}
/// <summary>
/// Возвращает предыдущий ближайший к заданному времени момент в расписании или
/// само заданное время, если оно есть в расписании.
/// </summary>
/// <param name="t1">Заданное время</param>
/// <returns>Ближайший момент времени в расписании</returns>
public DateTime NearestPrevEvent(DateTime t1)
{
}
/// <summary>
/// Возвращает следующий момент времени в расписании.
/// </summary>
/// <param name="t1">Время, от которого нужно отступить</param>
/// <returns>Следующий момент времени в расписании</returns>
public DateTime NextEvent(DateTime t1)
{
}
/// <summary>
/// Возвращает предыдущий момент времени в расписании.
/// </summary>
/// <param name="t1">Время, от которого нужно отступить</param>
/// <returns>Предыдущий момент времени в расписании</returns>
public DateTime PrevEvent(DateTime t1)
{
}
}
}Многие не очень любят делать тестовые задания. И ваш покорный слуга – не исключение. Но! Сложные и интересные задачки только раззадоривают программистов! Некоторые – вообще тянут на олимпиадные. А кто из вас не любит такие решать?
На первый взгляд кажется, что всё просто: сделать планировщик «а-ля крон». Вот только несколько нюансов на порядок увеличивают сложность аналогичной задачи.
Наличие в расписание миллисекунд и возможность шага в 1мс(!) А значит придется планировщику работать за гораздо меньшее время.
Требование наиболее оптимального расхода памяти и эффективности (большинство сошлось во мнении, что это для функций из группы NearestEvent)
Волшебная константа 32 – для обозначения последнего дня любого месяца
Нами «любимые» високосные годы
А в чём проблема?
Автор оригинальной честно всё выполнил: реализовал работоспособный класс, написал модульные тесты, просчитал худшее и среднее время выполнения (я усомнюсь, что правильно).
Короче, «полный фарш» и «под ключ». Как минимум, тест на джуна прошел. А то и на мидла. Сомнений нет. Но от ревьювера внезапно пришел крайне едкий комментарий: «Ваш код говно!».
Обидно такое слышать. Тем более, когда потратил 6-8 часов на реализацию. Ведь работает же! В чувствах @novar обратился к нам: «помогите понять: что не правильно?». И жители Хабра откликнулись: раз @PsyHaSTe и, даже, два @cadovvl и три от @mvv-rus.
Реализация от @PsyHaSTe прекрасна. Довольно практично. В меру лаконично. Так пишет промышленный программист с большим опытом. Стиль узнаваем. Мне до него далеко. Но есть проблема: второй автор, сконцентрировавшись на красоте и читабельности кода, совсем забыл про алгоритм.
Следующий участник @cadovvlзабил на парсер (ибо там всё тривиально), и сконцентрировался на алгоритме, технически доведя его до O(1). Как результат, снизил время выполнения с 12мкс до 300-500нс. Единственная слабость нового алгоритма – дни недели. В некоторых случаях они могут существенно его замедлить, вырождаясь в некрасивый O(n).
Наконец, ниже я приведу ещё один алгоритм, который практически не имеет слабых мест и устойчив по времени выполнения. Даже для самых изощрённых расписаний. Но сначала
Немного теории
На Хабре нередко вспыхивают споры: «нужна ли программисту математика?». Я предпочитаю держаться в стороне от бурления говн жарких дискуссий, предпочитая больше коллекционировать для себя примеры, где без математики худо. И это – не компьютерная графика, нейронные сети, звук или видео. Здесь как раз-таки всё и так понятно. А вот это задание – тот самый пример, когда знания математики пригождаются.
Что нам понадобится сегодня? Теория чисел! Нет мы не будем использовать малую теорему Ферма, символы Лежандра или функцию Мёбиуса. Но вот классы вычетов по модулю и некоторое понимание позиционных систем счисления нам пригодятся.
Давайте посмотрим внимательно на дату. Отбросим пока дни недели. Запишем компоненты даты в порядке: год, месяц, день, час, минута, секунда, миллисекунда: YMDhmsn. Формат часто используется на практике (иногда добавляются разделители): базами данных, системами логгирования и прочими. Такая запись позволяет упорядочивать даты по возрастанию/убыванию также легко, как это мы делаем со строками.
Вам ничего не напоминает? Да это же 7-ми разрядное число позиционной системы счисления со специфическими свойствами! Специфика же тут в том, что каждый разряд имеет свое индивидуальное основание и работает в своем, индивидуальном кольце, образованном классом вычетов по модулю. Да и границы вычетов могут начинаться не с 0, как это принято в теории чисел. Ещё и модуль у некоторых разрядов плавающий (день месяца, неделя года).
Например, час принадлежит классу вычетов, образованных модулем 24. Секунды и минуты – классу вычетов по модулю 60.
Математики поправят меня, что у нас не кольца. Ибо операций умножения у нас нет. Зато есть сложение. И мы можем прибавлять или вычитать единицу (любое целое) к любому разряду, получая новые всегда корректные значения дат (доказательство сего факта оставим читателю) .
Кроме того
Возможны операции вычитания двух дат, с получением целых чисел, символизирующих дистанцию между датами (в днях, секундах или миллисекундах – как вам угодно). Можно даже определить и операцию сложения двух дат.
Мало того, такие операции, как и положено в позиционной системе, каскадно влияют на старшие разряды. Если в младшем происходит переполнение, то он возвращается на условный «0» (или на условные «9» при вычитании), а старший также инкрементируется (декрементируется). И по цепочке вверх.
Некоторые разряды имеют имена собственные (месяцы, дни недели). Но главное свойство позиционной системы у них сохраняется: «цифры» разрядов упорядочены на «числовой» оси; представлены в множестве только один раз; все «цифры» различны.
Задачи для самостоятельного решения
Задание № 1. Приведите примеры известных вам действующих систем счисления с нестандартными основаниями != 2, 8, 10, 16…, и разными основаниями в разрядах.
Задание № 2. Простройте формулу, которая приводит произвольное число «дата» к десятичному представлению в натуральных числах.
Всё это и делает нашу дату, именно числом позиционной системы счисления! Пусть и с «особенностями». А что дает нам такое знание?
Во-первых, правило сравнения, аналогичное правилу сравнения обычных многоразрядных чисел.
Как мы сравниваем многоразрядные числа в позиционной системе счисления? Двигаемся от старшего к младшему до тех пор, пока сравниваемые разряды эквивалентны. Если не эквивалентны – можно заканчивать: результат сравнения первых расходящихся разрядов и есть результат сравнения чисел в целом. На младшие разряды можно не смотреть (пусть читатель вновь докажет это самостоятельно, решив задание № 2).
Для семиразрядных чисел нам потребуется в худшем случае 7 проверок. Отлично. Учтём.
Во-вторых, правила сложения и вычитания.
Как происходит сложение какого-либо разряда с единицей? Да так же, как и с обычными натуральными числами. Но если в разряде происходит переполнение, то он возвращается на условный «0» (минимум), а при вычитании – на условные «9» (максимум); более старший же разряд инкрементируется / декрементируется. И по цепочке вверх.
Но повторимся: переполнение влияет на разряды выше, не трогая младшие. Этот незатейливый факт мы отметим, и используем позже в алгоритме поиска.
Инкремент семиразрядных чисел заставит в худшем случае выполнить 7 операций сложения.
Итак, у нас «наклёвывается» алгоритм, с худшей сложностью 14 операций (сравнить/сложить). Очень неплохо.
Новый алгоритм
Если бы наша задача была в том, чтобы только сравнить две даты и вернуть на 1 мс большую / меньшую, то проблем бы не было. Но наша исходная задача несколько сложнее. То что, у даты в некоторых разрядах модуль плавает – это пол беды. У нас есть ещё и расписание, которое «фильтрует» некоторые цифры в разрядах. И не всякая «валидная» дата становится «валидной» с таким фильтром. Переводя на язык множеств – совокупность дат, принадлежащих расписанию, является подмножеством всех возможных дат.
Нам нужно, как-то хитро научиться работать с цифрами разрядов. А именно:
определять, что цифра не вышла за допустимые границы своего «кольца» (принадлежит множеству)
определять, что цифра принадлежит допустимым значениям расписания (принадлежит подмножеству)
возвращать следующее и предыдущее значение с учетом расписания и флаг переполнения
И если мы решим эти задачи, то операция поиска ближайших (или равных) дат в расписании сведется к сравнению или инкременту чисел нашей нестандартной позиционной системы счисления! Ну а число таких операций мы уже подсчитали – 14 в худшем случае.
Проще говоря, нам нужен функционал, который можно описать таким интерфейсом:
interface DateElementMatcher
{
// проверяет соответствие элемента календаря расписанию
bool match(int value);
// проверяет, не выходит ли значение за рамки элемента
bool inBounds(int value);
// получение следующего значения элемента календаря и флаг переполнения
(bool, int) getNext(int value);
// получение предыдующего значения элемента календаря и флаг переполнения
(bool, int) getPrev(int value);
}Я буду далее называть класс, реализующий данный интерфейс – матчером.
Есть правда, ещё одна сложность, с которой мы столкнёмся – количество вариантов, которым может быть задано расписание каждого элемента. Напомним, что значения элемента могут быть даны через запятую списком как отдельных чисел (10,11,12), так и их диапазонов (10-12,15-17,20-23), так и диапазонов с шагом (1-10/3,20-29/2). Помимо этого есть ещё диапазон звездочка (*) и звездочка с шагом (*/4). Только звездочка всегда задается вне списка (ибо покрывает весь диапазон значений).
Каждый способ задания расписания имеет свои особенности, позволяющие быстро решать задачи интерфейса DateElementMatcher.
Ну например, если расписание элемента задано в форме */4, то, например функция матчинга и поиска следующего значения упрощается до модульной арифметики:
match = function (x) => x % 4 == 0
next = function(x) => x - (x % 4) + 4
Согласитесь, это много лучше, чем проверять и искать по массиву. Сложность обоих операций – О(1).
Про расписание, заданное одним единственным числом или звездочкой – и говорить не приходится. Эти же операции вообще вырождаются в простое сравнение и инкремент. Про значения, заданные в форме интервала, тоже говорить не стоит. Всё тривиально.
Пусть RangedMatcher - это матчер, который мы сделаем вот для таких простых расписаний.
Чуть сложнее с расписаниями, заданными списками: 10,15-18,20-26/3,*/17. Тут нам придется выбирать, какую структуру оптимальнее всего использовать: простой массив (Array) или битовая карта (BitMap), хеш-таблица (HashMap), двуноправленный сортированный список на основе дерева (NavigableSet) или тупо комбинированный список из RangedMatcher (по такому пути пошел @cadovvl). Каждый из них имеет свои минусы и плюсы и должен быть применен «к месту», с учетом прожорливости по памяти и быстродействию.
Автор оригинальной статьи выбрал Array для всех ситуаций, включая тривиальные. Что не совсем оптимально по памяти и скорости. Я же предлагаю подойти к вопросу выбора матчера более щепетильно.
Например, диапазон 0-59 можно представить 60-байтным массивом, а можно 64-битной переменной. Операция проверки значения будет эквивалентна операции проверки бита, но вот поиск ближайших придется вести в цикле. Здесь сложность матчинга О(1), а получение ближайшего – О(n).
Вроде бы хорошо. Вот только O(n) для поиска ближайшего. А можно за О(1)? Можно. Для этого нам придется построить свою хеш-мапу на основе 64-битной переменной с двумя дополнительными массивами: массив индексов следующих элементов (next) и массив индексов предыдущих допустимых элементов (prev).
Суть проста. Пусть для расписания «1,3,4,51» в минутах нас просят найти ближайшее большее значение для 9-й минуты. Мы обращаемся к 9-му элементу массива next и сразу получаем готовый результат 51. Сложность О(1). Если выделить для каждого индекса 1 байт, то нам понадобиться максимум 120 байт на все возможные значения. Не так плохо. Но это сработает только для: дней, месяцев, минут, секунд, часов.
Для миллисекунд, с их возможным коварным разбросом значений 0-1000, лучше вернуться к BitMap и NavigableSet. Ну и для годов тоже. Хотя в реальности год вряд ли будет задаваться хитрее, чем *.
Вначале проектирования, я был уверен, что BitMap хорошо подойдет для случаев, когда покрытие диапазона возможных значений составит не менее 20% (каждый пятый); тогда цикл поиска следующего значений совершал бы в среднем не более 5 итераций (при условии однородности заполнения). А когда число возможных значений в списке меньше (или есть неоднородности), то я думал, что лучше использовать NavigableSet (дерево). И действительно, первый имеет сложность на поиск ближайшего O(N), а дерево – O(log N).
Внезапно, оказалось, что BitMap уделывает NavigableSet во всех случах. Даже когда в 1000-й карте только 1 бит установлен! На практике (для дерева) в этом убедился и @lam0x86. Так что от матчера типа «дерево» пришлось отказаться. Это выявили специальные бенчмарки.
А почему дерево друг медленнее списка?
Всё дело в накладных расходах на совершение операции выборки и поиска. Для битовой карты выборка значения (матчинг) сводится к вычислению адреса ячейки карты, чтению одной ячейки и проверки в ней соответствующего бита. Безусловно, поиск, в отличие от матчинга, реализуется тут циклом. Но в цикле мы работаем с одной ячейкой памяти; и можем сразу пропускать нулевые (не содержащие бит) значения, фактически делая шаг на 64.
А вот сортированный двунаправленный список «рандомно скачет по памяти» как при выборке одного значения, так и при поиске следующего. В итоге скорость произвольного доступа к памяти сказывается на быстродействии: дерево проигрывает тупому массиву.
Нет, конечно, если бы у нас был диапазон значений на 2 порядка больше, то дерево бы выигрывало. Но опять же при определенном проценте покрытий возможных значений. При плотном заполнении, битовая карта снова была бы на высоте.
Итак, я предлагаю реализовать всего 3 типа матчеров:
RangedMatcher – для простых расписаний, заданных одиночным числом или диапазоном, или диапазоном с шагом или звездочкой или звездочкой с шагом;
HashMapMatcher – для списков расписаний, заданных для дней, месяцев, минут, секунд, часов;
BitMapMatcher – для списков расписаний, заданных для года и миллисекунд.
На самом деле
В финальном коде, я в целях оптимизации разделил RangedMatcher на: ConstantMatcher, IntervalMatcher и RangedMatcher. А для дней месяца еще и DayOfMonthProxyMatcher, учитывающий переполнения месяца и волшебную константу 32. Но это уже нюансы.
Итак. Есть 3 эффективные стратегии работы с элементами дат. Применим магию ООП: для каждой стратегии – свой матчер с единым интерфейсом. Тогда основной алгоритм поиска дат в расписании мы можем написать так:
Берем текущую дату и по-разрядно от старшего к младшему проверяем на соответствие расписанию (функция match нашего интерфейса) до тех пор пока есть соответствие. Здесь мы либо упрёмся в миллисекунды (за 7 шагов), либо выйдем раньше, ибо !match.
Если на 1м этапе проверка не прошла, мы просим матчер найти ближайшее (функции next/prev). Если таковое есть – сбрасываем остальные разряды нашего числа на условный «0» (или «9») и возвращаем полученную дату. Если нету – сообщаем, что у нас «переполнение» и переходим к п. 3.
Если у нас хоть раз произошло «переполнение» в каком-то разряде, мы поступаем следующим образом: переходим к старшему разряду, сбрасывая все младшие на «0» («9»), и пытаемся прибавить/отнять единицу к старшему разряду (функции next/prev матчера). Здесь мы либо получим готовый результат, который возвращаем, либо опять переполнение. Повторим п. 3 до самого старшего разряда (7 шагов).
Наконец вспомним про миллисекунды. Добравшись до них в п. 1, мы либо сразу возвращаем полученную дату (если нам можно вернуть эквивалентную), либо увеличиваем их на единицу (next/prev). Если у нас не было переполнения – сразу возвращаем итоговый результат. Если было – идем к п. 3.
Вот теперь всё готово для реализации нового алгоритма.
Относительно особых дат
В техническом задание не указано, как поступать для ситуаций, когда задано расписание, например *.*.29? Если год не високосный, а «на носу» февраль, то что возвращать: 1 марта (ака 29-е февраля) или 29 марта? Я принял решение, что возвращаемое значение должно в точности соответствовать расписанию. Если стоит 29-е, то 29-е должно и возвращаться. Тем более, что это не расходится с теми 3-мя реализациями, которые уже были представлены на Хабре. Кстати, аналогичная ситуация произойдет и с расписанием *.*.31 для любых месяцев, в которых меньшее число дней.
Теперь про високосные секунды. Эти вещи алгоритмически не вычисляются (в отличие от 29 февраля). Там астрономы собираются и, по результатам наблюдений, коллективно устанавливают, добавлять ли в этом году в самом его конце лишнюю секунду к последнему часу или, наоборот, вычесть. А значит, предусмотреть в алгоритме планировщика високосные секунды невозможно. Но давайте обыграем возможные ситуации.
Положим в расписании задано время *:*:30-59. Внешняя функция, вызывающая наш планировщик получила текущую системную дату, которая была синхронизирована с мировым временем и мы имеем такое: 23:59:60.000. Т.е. та самая високосная секунда +1. Но выше мы уже определили: что в расписании указано, то и допустимо. Поэтому секунда с номером 60 недопустима. Возвращаем дату следующего события, на секунду больше: +1 00:00:00.000.
Теперь положим, что внешняя функция получила системную дату 23:59:58.000. И в этом году 58 – максимально возможное число секунд (отняли високосную секунду). Планировщик вернет следующее время, как и положено по расписанию: 23:59:59.000. Вот только оно невалидно. Но будет ли это проблемой? Нет. Календарная система вашего языка программирования автоматом её сконвертирует в валидную дату: +1 00:00:00.000.
Это же правило будет работать и при переходе на летнее/зимнее время.
От слов к делу
С учетом вышеизложенного, центральный алгоритм поиска даты следующего события из расписания выглядит так:
private Date findEvent(Date date, SearchMode mode)
{
GregorianCalendar calendar = new GregorianCalendar();
calendar.setTime(date);
CalendarDigits digits = new CalendarDigits(pool, calendar, mode.toZero());
while ( isCanSearchDown(digits, calendar, mode.canEqual()) )
{
digits.next();
}
return calendar.asDate();
}
private boolean isCanSearchDown(CalendarDigits digit, GregCalendar calendar, boolean canEqual)
{
int value = digit.getValue(); // текущая цифра календаря
if ( digit.isBelow(value) ) // текущее значение цифры календаря ниже минимально возможной границы в расписании
{
digit.initialize(); // сбросим на «0» эту и младшие цифры
return false; // и завершим поиск
}
if ( digit.isAbove(value) ) // текущее значение цифры календаря выше максимально возможной границы в расписании
{
digit.prev(); // перейдем к более старшему разряду, увеличим его на 1, а младшие сбросим
digit.increment();
return false; // и завершим поиск
}
// текущее значение в пределах границ; но всё ещё может не соответствовать расписанию
if ( digit.match(value) && calendar.isCorrect() ) // соответствует
{
boolean isLast = digit.isLast();
// если это самая младшая цифра календаря (миллисекунды), и нам разрешено вернуть эквивалентную исходной дату, закончили поиск
if ( isLast && canEqual ) return false;
// продолжаем поиск для младших разрядов
if ( !isLast ) return true;
}
// текущее значение цифры в пределах границ; но не соответствует расписанию
digit.increment();// получим следующее значение для цифры из расписания, а младшие сбросим на «0»
return false; // и завершим поиск
}Смотрите, каким элегантным стал наш поиск. Да это цикл. Но он имеет фиксированное число итераций: 7 вперед. Определяется это, как вы догадались, числом цифр календаря. Были бы микросекунды, ничего бы не поменялось. Ну 8 итераций.
Можно было бы вообще развернуть цикл в линию. Но это привело бы к дублированию кода. Теперь вы понимаете, что цикл здесь не потому, что он требуется алгоритмом, а для того сократить код?
Хорошо. Но мы пока обошли вопрос: а как быть с расписанием дней недели?
Как верно заметил @cadovvl, дни недели находятся на одном уровне с датой и не влияют на время. Т.е. время как бы само по себе, а дата – отдельно.
Я решил, что лучший вариант – это, после завершения основного цикла поиска даты, выполнить дополнительный поиск подбора подходящего дня недели:
private Date findEvent(Date date, SearchMode mode)
{
GregorianCalendar calendar = new GregorianCalendar();
calendar.setTime(date);
CalendarDigits digits = new CalendarDigits(pool, calendar, mode.toZero());
while ( isCanSearchDown(digits, calendar, mode.canEqual()) )
{
digits.next();
}
return fixWeekDay(digits, mode);
}
private Date fixWeekDay(CalendarDigits digits, SearchMode mode)
{
Calendar calendar = digits.getCalendar();
CalendarElement element = new CalendarElement(Calendar.DAY_OF_WEEK, calendar);
while ( !weekDay.match( calendar.get(Calendar.DAY_OF_WEEK), element ) )
{
digits.gotoDay(); // перейдем к цифре «день месяца»
digits.increment(mode.toZero());// и сделаем инкремент до следующего значения из расписания
} // пока день недели не сойдется с расписанием
return digits.getAsDate();
}Да это цикл. Но как говорил @cadovvl – это другое. Хотя.. я бы тут поспорил. Почему? Читайте ниже.
Битва алгоритмов
Думаю, что именно за выбранный алгоритм @novarполучил крайне низкую оценку. Задача решена им тупо "в лоб". Выбранный способ поиска дат прост до безобразия. Вся реализация, как и просили – в одном классе. Несколько громоздко, зато удобно. Но не торопитесь делать поспешных выводов.
Во-первых, он делал это задание при соискании работы по вечерам: а нужно было в ограниченный срок представить работающее решение. Да и заявку подавал не только в одно место.
Во-вторых, не смотря на простоту, алгоритм @novarустойчив. Мой же потребовал специальных усилий для стабилизации результатов на всяких 29-х февраля, хаков и трюков (см. реализацию класса CalendarDigits из пакета com.habr.cron.ilya).
Наконец, задача только выглядит как гипотеза Коллатца. А эффективное решение найти оказалось не просто.
Временная сложность выполнения алгоритма от @novar и @PsyHaSTeсоставляет O(N). Это хорошо видно на графиках зависимости времени выполнения функции getNextEvent от входного аргумента, при его последовательном приращении:
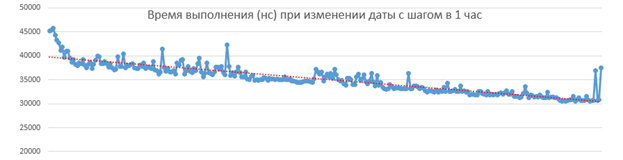

А вот такие же графики предлагаемого алгоритма:



Как видно, наклон усредненной линии ближе к горизонту, что свидетельствует о том, что мы приблизились к сложности O(1), стабилизировав скорость работы.
Давайте приведу сравнительные замеры по алгоритмам (в моем проекте вы можете запустить соответствующий «бенчмарк» из пакета speed):
[NoVar] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 120500 nsec
[Ilya] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 3749 nsec
[NoVar] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 1070 nsec
[Ilya] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 1207 nsec
[NoVar] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2001.01.01 00:00:00.000 - 6713 nsec
[Ilya] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2001.01.01 00:00:00.000 - 2383 nsec
[NoVar] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2080.05.05 12:00:00.000 - 13310 nsec
[Ilya] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2080.05.05 12:00:00.000 - 3948 nsec
[NoVar] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 207159 nsec
[Ilya] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 3584 nsec
[NoVar] 2100.12.31 23:59:59.999 2080.05.05 00:00:00.000 - 141051 nsec
[Ilya] 2100.12.31 23:59:59.999 2080.05.05 00:00:00.000 - 4075 nsecДисклеймер
Сразу хочу оговориться, что цифры условные и отличаются от замеров других авторов. Это замеры на «моей» машине и на другом языке программирования (автор делал на C#, я на Java). Мне пришлось реализовать алгоритм автора как есть, но с небольшими отличиями, обусловленными спецификой работы GregorianCalendar. Но всё же тенденция видна: сильная зависимость времени выполнения от входной даты у алгоритма @novar В то время, как новый алгоритм устойчив.
Как и ожидалось, новый алгоритм поиска ближайшей даты значительно опережает по скорости оригинальный авторский от @novar и @PsyHaSTe. Время выполнения в некоторых (не самых крайних) случаях сократилось со 120 мкс до 1-4 мкс на моём 3Гц процессоре. Не плохо, подумал я. Собственно, этого и следовало ожидать: алгоритмическая оптимизация дает самый большой выигрыш по скорости.
Подобная реализация алгоритма от @cadovvl была в среднем до 12 раз быстрее. Но я подумал: "Это же C++! Чего с ним тягаться?". На чистом ассемблере, мне удалось бы свести алгоритм к считанным тактам, и тогда я вышел бы на десятки наносекунд. Только на нём можно точно спрогнозировать время выполнения вашей функции, когда можешь точно посчитать такты. А вот с Java предсказывать что-либо очень трудно. Разброс в измерениях одной и той же функции такой, что тут в пору верить во влияние фаз луны и популяций перепелов.
Но я вам скажу: рано пить «Боржоми» и праздновать победу.
Белая магия оптимизаций
Но вот незадача. В одном случае @novarвсегда был быстрее моего алгоритма: когда ближайшая дата на 1 мс меньше текущей.
Странно, оба алгоритма совершали одинаковое число проверок (7 - мой, 9 - от @novar). Казалось бы, мой алгоритм должен быть даже чуть быстрее. Ну хоть капелюшку. Но нет, замеры убедительно показывали, что @novarвсегда "уделывал" меня. Вот результаты типичного прогона:
[NoVar] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 1070 nsec
[Ilya] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 1207 nsecПризнаться, это закусывало. А что если подобный кейс будет самым частым? Получается простая реализация "уделывает" непростую? Стоило ли тратить время, проводить исследования, писать эту статью? Всё пропало. Да и вообще, как это алгоритм O(N) уделывает O(1)? Непорядок!
Тогда я стал выяснять, на что тратится время больше всего. С профайлером возиться не стал; поступил проще: просто отключал те части кода, которые считал подозрительными.
Странно, но на время выполнения функции эти манипуляции вообще никак не влияли. Ну т.е. как-то влияли, но из-за разбросов в измерениях этого было не видно. JVM она такая. Я уже было отчаялся, но затем, полностью отключил алгоритм поиска, тупо возвращая входную дату. Сюрприз меня поджидал не там, где я его караулил. Даже после такого наглого хода, моя функция, по-сути ни делая ничего, тратила столько же времени, что и раньше! Как так? Магия?
Не совсем. Я закоментировал не весь код функции. Остался вот такой "безобидный" кусочек:
Calendar calendar = new GregorianCalendar();
calendar.setTime(time);Вот это да! Оказалось, что львиную долю времени исполнения отъедала родная java-имплементация Грегорианского календаря (GregorianCalendar)! А собственно, почему бы и нет?
Дело в том, что вы не можете в Java создать экземпляр грегорианского календаря, сразу же инициализировав его требуемой датой. Вначале он инициализируется системной датой, потом уже той, которой вы захотите. Ну такой вот интерфейс. Но при инициализации датой, календарь «распаковывает» её unix-представление в поля: year, month... Получается он делает это дважды. Ещё и медленно. А потом, при выходе из моей функции, ещё и обратно «упаковывает» себя в дату. Вот где падала производительность!
Сделав свою, более упрощенную имплементацию календаря, корректно работающую в пределах 2000-2100 годов, удалось повысить скорость в 7-8 раз! Теперь среднее время выполнения функции getNextEvent упало до 500 нс. Не плохо. Получается моя имплементация Schedule догнала по скорости имплементацию от @cadovvl. И это очень круто, скажу я вам. Ибо, кто бы что не говорил, старый добрый C++ куда быстрее Java, с её непредсказуемым GC и халатным обращением с памятью. Java приближается по скорости к C/C++ только в специально подогнанных (синтетических) тестах. А тут реальный кейс. И даже не простой.
[Ilya] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 3584 nsec
[Optimized] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 432 nsec
[Ilya] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 1134 nsecs
[Optimized] *.*.* *:*:*.* 2021.30.09 12:00:00.002 - 472 nsec
[Ilya] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2001.01.01 00:00:00.000 - 2250 nsec
[Optimized] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2001.01.01 00:00:00.000 - 482 nsec
[Ilya] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2080.05.05 12:00:00.000 - 3719 nsec
[Optimized] *.4.6,7 * *:*:*.1,2,3-5,10-20/3 2080.05.05 12:00:00.000 - 472 nsec
[Ilya] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 3406 nsec
[Optimized] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 472 nsec
[Ilya] 2100.12.31 23:59:59.999 2080.05.05 00:00:00.000 - 3617 nsec
[Optimized] 2100.12.31 23:59:59.999 2080.05.05 00:00:00.000 - 465 nsecЧёрная магия оптимизаций
Некоторым, возможно показалось, что предложенный алгоритм не имеет худшего случая? Нет, чёрт возьми, имеет. Проклятые дни недели! Из-за них мой алгоритм (равно как и алгоритм от @cadovvl), всё-таки мог запросто выродиться в некрасивый O(n). С соответствующим замедлением. Вот типичный бенчмарк:
[NoVar] *.02.29 6 12:00:00 2021.01.01 12:00:00.000 - 806678 nsec ожидалось 02.29.2048 г.
[Ilya] *.02.29 6 12:00:00 2021.01.01 12:00:00.000 - 90104 nsec – упс! В 180 раз больше времени!
Проблема с днями недели в том, что они выпадают из стройной картины позиционного числа. Они находятся на уровне с днями и влияют на всю дату целиком (но не на время).
Ещё примеры неудобных расписаний
Положим есть расписание: «*.1,10.5-26/7 1 12:00:00». (январь и октябрь, числа 5, 12, 19, 26, по понедельникам). Особенность его в том, что не так много лет, когда на понедельник в январе и октябре выпадает на числа 5, 12, 19, 26. Вот эти годы – 2026, 2032 (здесь только январь), 2037 и так далее (дистанция 5-6 лет тут не спроста; попробуйте это доказать самостоятельно). Как будет работать наш алгоритм поиска ближайшей или равной даты?
Пусть исходная дата равна 05.10.2021 12:00:00.000. Мой алгоритм дойдет до миллисекунд (7 итераций) и вернет эту дату. Но тут в дело вступит проверка на день недели. У нас вторник. А нужен понедельник. Промах! Мы снова вернемся к необходимости инкрементировать день месяца. Следующий день – ровно через неделю, вторник 7-е. Опять промах. И так 3 раза, после чего мы выходим на 5-е ноября. Ноябрь не наш месяц – наш следующий январь, но уже 22-го года. Промежуточный итог – 05.01.2022, и 5 «лишних» итераций.
Далее снова проверяем. Год подходит под расписание. Месяц да. День тоже. Но день недели вновь не тот: среда! И так по кругу.
Ладно, чтобы вас не утомлять скажу сразу, нам в таком варианте придется сделать 23(!) итерации (можно убедиться, выполняя код в отладчике по шагам). О как! И это дополнительно к первоначальным 7-ми. А можно ещё придумать такое расписание, что мы выйдем на 600-700 итераций. Но нам потребуется задавать такие годы, которые сознательно игнорируют «подходящие». Пример такого расписания был приведён в бенчмарке выше.
Конечно, этот пример синтетический. Вряд ли кто в здравом уме выберет такое неудачное расписание, которое срабатывает редко. Скорее всего там будут играть с миллисекундами (раз требование было). Но как знать? Тем более алгоритм есть алгоритм. Он должен быть устойчивым для всех случаев.
А вот вам более реальный пример. Положим, некий человек запланировал расписание: раз в неделю каждую пятницу, начиная с 1-го числа. Тупой бот «с его слов» так и записал *.*.*/7 5 12:00:00. И не учел "безмозглый", что дни 1, 8, 15, 22, 29 должны выпадать строго на пятницу.
А фишка в том, что в 2021-м году только октябрь месяц обладает такими свойствами. Ближайший месяц с таким графиком – апрель 2022, а за ним июль 2022. Чтобы до них добраться, стартуя, например с 01.11.2021, нам нужно перебрать все 5 дат октября (они подходят под расписание, но зарубаются по дням недели), потом ноября, перейти к новому году, и опять в каждом месяце перебрать по 5 дат, пока не доберемся до 01.04.2022.
Итого: 25 итераций. Чувствуете? Запахло циклом. От чего ушли, к тому и вернулись. Долбанные дни недели!
А что если бы мы могли сразу ответить на вопрос: а есть ли в текущем месяце (или даже году!) хотя бы одна дата, выпадающая на выбранный расписанием день недели? Но как сделать такую проверку сразу и без цикла? Я решил прибегнуть к битовой магии.
Расписание дней недели мы можем уместить в 7-ми битах, отмечая единицами выбранные дни недели. Положим, воскресенье - нулевой бит, понедельник - первый, суббота - шестой. Тогда для расписания * получим 1111111b, для */2 - 1010101b. Для пятницы - 0100000b.
Расписание дней месяца тоже можно представить в виде 7-битной карты дней недели, на которые они выпадают. Главное привести эту карту к такому состоянию, чтобы 1-е число месяца выпадало на правильный день недели.
К примеру, для того же сентября 2021-го при расписании «*.*.5-26/7 1 12:00:00» эта карта выглядела бы так: 0001000b (все дни выпали на среду), а для октября 0100000b (всё на пятницу), ну и для ноября 0000010b (все на понедельник). Причем такую карту можно вычислить заранее (при конструировании Schedule), а к текущему месяцу приводить элементарным круговым сдвигом на нужное кол-во бит.
А вот теперь битовая магия: сложив две такие карты через AND мы НЕ получим 0 в том и только в том случае, когда месяц содержит по крайней мере 1 дату, выпадающую на планируемый день недели. По оставшимся битам можно даже вычислить какой именно день месяца нужно взять.
Для этого можно написать нетривиальную функцию. Но я поступил проще - циклом. Да это цикл. Но как говорил @cadovvl- "это другое". В самом худшем случае мы сделаем не более 6 итераций (на практике меньше). И это будет быстрее, чем нетривиальная функция. И это будет последний цикл.
Самое главное, что одной операцией AND мы сможем сразу же отсеять бесперспективные месяцы. И возвращаясь к примеру расписания ранее, нам понадобится перебрать 5 месяцев (т.е. выполнить 5 таких AND и 5 сдвигов), чтобы добраться до апреля. 5 операций проверки вместо 25. Не плохо.
Аналогичную карту можно завести для целого года, чтобы махом отсеивать бесперспективные годы. Мало ли, пользователь задаст расписание на 29-е февраля в субботу (забыв, что такое бывает крайне редко). Например, такое случится в 2020-м, а потом только 2048-м. Но это уже экзотика. Просто, если мы хотим максимально приблизить скорость алгоритма к O(1), то нам понадобится обработать и такие "крайние" ситуации.
Проделав подобные манипуляции, реимплементировав Григорианский календарь, выполнив иные мелкие оптимизации (в результате которых удалось избавиться от "паразитного кода", имитировавшего бурную деятельность) мне удалось не только повысить скорость своего алгоритма, сведя время до 500 нс, но и стабилизировать время даже на сложных расписаниях. Я выделил оптимизированный вариант в пакет com.habr.cron.dev.
Вот, например, бенчмарки для таких случаев:
[NoVar] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 120500 nsec
[Ilya] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 3749 nsec
[Optimized] */4.01.01 12:00:00.000 2012.01.01 12:00:00.001 - 600 nsec
[NoVar] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 207159 nsec
[Ilya] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 3584 nsec
[Optimized] 2100.12.31 23:59:59.999 2000.01.01 00:00:00.000 - 481 nsec
[NoVar] *.02.29 6 12:00:00 2021.01.01 12:00:00.000 - 806678 nsec
[Ilya] *.02.29 6 12:00:00 2021.01.01 12:00:00.000 - 90104 nsec
[Optimized] *.02.29 6 12:00:00 2021.01.01 12:00:00.000 - 1278 nsecА вот графики оптимизированного варианта:



За пределами ТЗ
А можно ли ещё быстрее?
@cadovvl заметил, что его реализация обладает интересным побочным свойством: возможностью быстрой генерации следующих дат в расписании.
Действительно, предложенный им алгоритм работает через машину состояний. И глупо не использовать это для оптимизации. Единственный недостаток алгоритма @cadovvl – мутабельность и, как следствие, не многопоточность. Добавление простой защиты от racecondition может существенно снизить скорость выполнения. Нужно делать класс Schedule иммутабельным изначально. А это уже чуть иной подход.
Моя реализация Schedule изначально планировалась как Thread-Safe (привычка писать под веб-сервера). Но она в итоге по скорости приблизилась к реализации от @cadovvl (даже без учета хаков с днями неделей и битовыми картами для списков диапазонов). Поэтому было интересно посмотреть, а какой прирост скорости будет, если тоже сделать свой генератор. Тем более, что хотелось по максимуму выполнить ещё одно требование заказчика: минимальный расход памяти.
Я немного изменил интерфейс Schedule, продиктованный ТЗ, снабдив его функцией getEventsGenerator, возвращающей интерфейс:
interface ScheduleEventsGenerator
{
/**
* @return the date of last event
*/
Date last();
/**
* @return the date of next event after last
*/
Date next();
/**
* @return string presentation of source schedule
*/
String schedule();
}Генератор получился мутабельным (из-за использования машины состояний), но с нулевым расходом памяти. А это для Java вообще подвиг. Ну и крайне быстрым, конечно же. Единственно, что создается в генераторе – экземпляр класса Date при выходе из функции next().
Теперь можно было использовать планировщик расписания так:
Schedule schedule = new Schedule("ваше расписание");
ScheduleEventsGenerator generator = schedule.getEventsGenerator(начальная дата, направление поиска);
List<Date> events = new ArrayList();
for (int i = 0; i < сколько_нужно_расписаний_наперед; i++)
{
events.add( generator.next() );
}Созданные объекты schedule и generator можно выбросить. Кеширование generator чревато, из-за его мутабельности.
Хотя, если вам нужна истинная многопоточность, можно использовать Schedule как и задумывал заказчик. В скорости потери будут не сильные, зато потокобезопасно, можно кэшировать. Самое главное преимущество генератора – ультра-скорость и экономия памяти. Так что есть с чего выбрать.
Вот бенчмарки генератора:
[Gen] *:*:*.* [17.11.2021 14:00:00.001 .. 17.11.2021 14:01:40.001] - 76 nsec
[Gen] *:*:*.*/5 [17.11.2021 14:00:00.000 .. 17.11.2021 14:08:20.000] - 91 nsec
[Gen] *:*:* [17.11.2021 14:00:00.000 .. 18.11.2021 17:46:40.000] - 87 nsec
[Gen] *.1,10.5-26/7 1 12:*:*.320 [01.01.2000 00:00:00.000 .. 26.01.2026 12:46:39.320] - 120 nsec
[Gen] *.*.31 3 12:*:* [01.01.2000 00:00:00.000 .. 31.03.2027 12:46:39.000] - 111 nsecИтак, если вы тот самый работодатель виновник сего торжества, и провокатор появления 4-х статей на Хабре вот готовый оптимизированный проект под ваше ТЗ. Я его выкладываю под BSD лицензией. Мало ли, вдруг ещё кому пригодится. Всё очень хорошо оттестировано (каждая мелочь), промерено. Думаю, быстрее - только на C++ или ассемблере.
Напоследок скажу, что существует способ быстрого поиска пересечения требуемого дня недели с допустимыми датами из расписания без использования циклов вообще, приводя алгоритм к чистому O(1). Но поля данного фолианта слишком узки… а мне надо закругляться. Так что, пусть поиск такого алгоритма будет домашним заданием для читателя.
Передаю эстафету следующему участнику, подводя такие итоги:
Первый участник @novar сконцентрировался на экономии памяти; но написал код так, что память не экономится, а времени тратится прилично; зато всё в одном классе; удобно;
Второй участник @PsyHaSTe сконцентрировался на красоте кода и парсере; код вышел компактным, красивым; но центральный алгоритм так и остался: без изменений, – медленным;
Третий участник @cadovvlсфокусировался на алгоритме: его код вышел максимально быстрым; правда имеет худшие случаи; не смертельно; код не потерял в наглядности и читабельности; недостаток – отсутствие многопоточности;
Четвертый участник (это я) сфокусировался на поиске священного Грааля O(1); но код существенно раздул доведя до целого пакета; без пояснений в виде отдельной статьи на Хабре, в нём разобраться сложно; О(1) почти достиг, скорость увеличилась в несколько раз, время снизилось до 400нс.
Ваш ход?
Благодарности и ссылки:
Благодарю @novar, @PsyHaSTe и @cadovvl за их прекрасные статьи. Благодарю потенциального работодателя за любезно предоставленное интересное тестовое задание. Пусть даже у них с работником до сих пор так и не сложилось.
Особая благодарность и плюс в карму @cadovvlза найденный баг.
Ссылка на решение от @novar и @PsyHaSTe
Ссылка на решение от автора статьи. И готовый production-код.
Я буду искренне рад, если мой код пригодится и вам.
Комментарии (57)

Xeldos
17.11.2021 09:39+8> Можно даже определить и операцию сложения двух дат.
Мне всё-таки кажется, что нельзя. И не видел я лично нигде такого. К точке можно прибавить интервал. А как к точке прибавить точку?..
Aelliari
17.11.2021 09:59+1Хм, сложение дат? Microsoft Excel точно умеет прибавлять к датам числа, а вот Гугл таблицы складывают и вычитают даты возращая число дней
P.S. исправил изначально написанную неточную информацию
Xeldos
17.11.2021 10:51+7Прибавить к дате интервал — это понятно. Вычесть две даты и получить интервал — тоже понятно. Что получается в результате «сложения двух дат»?
Aelliari
17.11.2021 11:41-5Число, количество дней между датами

dopusteam
17.11.2021 12:21+7Чем это отличается от вычитания дат?
Aelliari
17.11.2021 13:59+1Оставляя верхний комментарий я допустил ошибку пиша про разность дат, хотя речь шла о сумме. Но Гугл таблицы все равно умеют их складывать. Алгоритм мне не очевиден и пока я на работе - нет времени подумать над их механизмом. На выходе - число

masai
17.11.2021 15:28+1И правда. Похоже, он хранит дату как число дней, прошедших от 30.12.1899, а при сложении просто эти количества дней складывает.

EnigMan
17.11.2021 16:16Excel делает именно так. Очень удобно считать разность дат, либо дату через заданное число дней.
Xeldos
17.11.2021 17:27+2> число дней, прошедших от 30.12.1899
О, у меня в проекте чья-то светлая голова так даты хранила. С какой болью я всё это вырезал и переводил на нормальную арифметику дат…
masai
17.11.2021 12:28+5Нмкто не запрещает так сделать, конечно, но это не то, что ожидаешь от сложения.
Если сложение возвращает количество дней, то оно, например, не будет ассоциативным:
(4 января + 3 января) + 1 января = 1 + 1 января = 2 января.
4 января + (3 января + 1 января) = 4 января + 2 = 6 января.
Алгебраистов, конечно, не испугать неассоциативным сложением, совпадающим с вычитанием, но тут эта операция выглядит лишней.

lagduck
17.11.2021 13:53Если рассматривать дату как интервал между собственно этой датой и нулевой датой - точкой отсчета, то любые две даты вполне хорошо складываются. Можно прямо в столбик, поразрядно, как обычное 7-значное число (в представлении в системе счисления со специальными основаниями, как описано в статье), с инкрементом старшего разряда и сбросом младшего при переполнении младшего.

MUTbKA98
17.11.2021 10:14+2А что насчет алгоритма с предрасчетом N следующих точек во времени и запоминании их в циклическом буфере (очевидно, что сложность при этом абсолютно минимальная - 1 арифметическая операция и спячка), а предрасчет выполняется в отдельном низкоприоритетном потоке, когда кол-во оставшихся точек становится меньше некоего X или кол-во времени, оставшегося до последней рассчитаной точки, становится меньше чем T?
Goodwinnew
17.11.2021 10:50+7Интересно, а кого вообще ищет работодатель с такими тестовыми заданиями?
Можно обратить внимание, что в статье автор использует математику, проводит сравнения и прочее = получает лучший результат. И автором статьи проделана достаточно большая и сложная работа.
Это полноценное решение технической задачи:
получить результат (работа алгоритма)
оптимизировать получение результатам (в данном случае по времени)
Т.е. работодатель в тестовом задании на проверку уровня знаний кандидата хочет получить реально работающее решение для сложной задачи?
Процесс разработки у заказчика так построен - что бы сразу программист писал эффективный и правильный код? Замена тестирования (решения сложной задачи) на талантливого программиста? Пусть сразу сделает на отлично?
Какая то опасная стратегия у заказчика. ИМХО.
korsetlr473
17.11.2021 11:04в 1 млскнду ? это сколькже ваша программа жрет процессорного времени ? наверно в топе ....
врагу не пожелаешь такую использовать

alexeishch
17.11.2021 11:26+12Вообще тестовые задания, требующие больше 1-2 часов разработки должны оплачиваться.
Сколько вы часов на эту задачу потратили? В месяце 20 рабочих дней, в дне - 8 часов. Вот и подсчитайте на сколько денег вас пытается нагреть будущий "работодатель". По этой причине нормальный работодатель может вам два варианта предложить:
1. Тестовое задание + NDA + символическая оплата за него в 300-400$
2. Специфические для языка проверки + задачки с leetcode и ему подобныеВсё остальное - это как минимум не уважение чужого труда

waxtah
17.11.2021 17:24Да изначально говорить «
Ваш код говно!», особенно без аргументов тоже - не уважение. Что же касается задачи - она весьма интересная.

mayorovp
17.11.2021 11:53+3Сначала небольшое уточнение. Дата никак не может быть числом в позиционной системе счисления из-за того, что в месяце переменное число дней. И "разряды" даты не являются элементами кольца вычетов, потому что 59+1 в кольце вычетов по модулю 60 даст честный 0 без всякого флага переноса. К счастью, на алгоритм ни одна из этих ошибок не повлияли, ведь алгоритму достаточно лексикографического порядка.
По поводу же битмапы против дерева. Пожалуйста, добавьте в сравнение производительности простой упорядоченный массив диапазонов, с двоичным поиском по нему. Асимптотика тут должна быть как у дерева, но накладных расходов будет меньше.

KaminskyIlya Автор
18.11.2021 00:14Я попробую и позже опубликую в проекте CronHabrDemo. На всякий случай, опишите подробнее предлагаемую Вами структуру. Чтобы у нас не было расхождений во взаимопонимании.
Но у меня есть подозрение, что битмап снова выиграет, ибо упорядоченный массив диапазонов заставит "скакать" по памяти, что сильно сказывается на производительности.
mayorovp
18.11.2021 01:19+3Чтобы не "скакать" по памяти, можно сделать отдельные массивы для начала диапазона и окончания (поиск будет только по первому массиву идти).
Структура какая-то такаяclass BitMapMatcher implements DigitMatcher { private final int[] mins, maxs; // инициализацию как-нибудь сами private int search(int value) { // пишу реализацию сам, потому что у стандартного алгоритма возвращаемое значение убогое int left = -1, right = mins.length - 1; while (left < right) { int i = (left + right + 1) / 2; // да, я знаю про переполнение, но тут никогда не будет более 500 элементов if (mins[i] <= value) left = i; else right = i-1; } return left; } public boolean match(int value) { int index = search(value); return index > -1 && value <= maxs[index]; } public int getNext(int value) { int index = search(value); if (index > -1 && value < maxs[index]) return value+1; if (index+1 < mins.length) return mins[index+1]; // тут нечего возвращать } public int getPrev(int value) { int index = search(value); if (index > -1 && value > mins[index]) return value-1; if (index > 0) return mins[index-1]; // тут нечего возвращать } }KaminskyIlya Автор
18.11.2021 05:24+2Сделал Ваш реализацию. Скоро залью на гит. По предварительным прогонам такой класс хорошо обгоняет битмап на поиске (1:4), но чуть проигрывает на матчинге (20%). Гонял для расписания миллисекунд "1-10,12-18,21-30,941-1000".
А Вы крут, если в комментариях способны написать код, который сразу работает) Я думал: концепт, а-н нет - рабочая версия) Мой почтение.
Я думал изначально реализовать подобный класс, но отказался по следующим причинам:
диапазоны должны быть упорядочены по возрастанию
диапазоны не должны пересекаться
диапазоны должны быть заданы без шага
Но с другой стороны:
их можно отсортировать, после парсинга, когда построили модель
их можно объединять, если отказаться от шага != 1
если не отказываться от шага != 1, то тогда забить на п. 2
Нужно промерить при разных комбинациях расписания: процент заполнения, степень покрытия и "кучкования" значений. Найти оптимальные значения, при которых данный класс станет выгоднее.
В принципе, да, можно запилить.
mayorovp
18.11.2021 10:35Рабочий? Там в методе getPrev надо не
mins[index-1], аmaxs[index-1]возвращать было :-(Забивать на непересекающиеся диапазоны нельзя, алгоритму они требуются. Проще представить каждый диапазон с шагом как серию диапазонов длины 1. Ну и если диапазонов получается где-то более 100 (число взято с потолка, как N / log N) — есть смысл перейти на битовую карту.
KaminskyIlya Автор
18.11.2021 23:32Я про ваш бинарный поиск) У меня всегда с ним не складывалось: с первого раза без ошибок написать не могу. Хотя часто применяю. А getPrev вылез бы на тестах, которые я пока не стал делать, удовлетворившись getNext для замеров скорости.
Я предварительно погонял новый класс сравнивая с BitMap. Что хочу сказать? При интервалах свыше 10-ти, уверено начинает лидировать битмап. При интервалах от 2-х до 4-х ваш класс сильно обгоняет битмап на поиске, но чуть проигрывает на матчинге. Другое кол-во ещё не гонял.
Найти параметры, при которых можно уверенно сказать, что тут лучше битмап, а тут нет - трудно.
На производительность обоих классов влияют:
процент заполнения всего диапазона значениями (например, для "0-99,900-999" - 20%)
количество диапазонов в списке (два, как в примере выше, четыре: "1-3,50-79,100-200,800-810")
распределение ("кучкование") чисел по диапазону (если они распределены равномерно, и средняя длина пробега от одного значения до другого скажем от 3-х до 5-ти, то битмапа выигрывает)
Так что тут ситуация: "и хочется, и колется". Можно скрестить ужа с ёжом: объединить классы HashMapMatcher и BitMapMatcher. У первого O(1) на поиск и матчинг. Но ограничение по длине диапазона (чтобы уместить в одну 64-битную переменную).
Если интересно, я чуть позже опубликую на гитхабе классы, которыми измерял. Чтобы Вы могли сами проверить. А то вдруг я просчитался.
KaminskyIlya Автор
19.11.2021 08:00Ветка list-matcher https://github.com/KaminskyIlya/HabrCronDemo/tree/list-matcher

cadovvl
17.11.2021 12:56+4Обидка. Я забил на парсер не потому что "там всё тривиально", а потому что
Ну, парсера не будет. На этом этапе я уже достаточно сильно подустал, да и не думаю, что смогу здесь сделать какую-то революцию.
Зачем так передергивать?
cadovvl
17.11.2021 14:00+16Перечитаю чуть позже, но взглядом по диагонали - откуда в моем решении взялось O(n) понять не могу.
// Increment until valid date while (bool(*this) && !is_valid_date()) { increment_date(); }У этого цикла максимум 9 итераций в феврале с неудачным днем недели. Полагаю, вы сделали подобные вычисления в своем
В самом худшем случае мы сделаем не более 6 итераций (на практике меньше).
И вообще в статье есть какая-то какая-то мешанина с теоретической оценкой сложности алгоритма (O - символика ландау) и тесты с бенчмарками.
Оценка сложности имеет смысл только при потенциально бесконечном росте объема входных данных. Это оценка скорости роста худшего времени работы алгоритма в зависимости объема входных данных. 7 раз это тоже O(n), где n - количество дней недели, и раз у нас не предвидится рост количества дней недели, то и подобный анализ не имеет смысла.Касательно всего остального: скачал ваш репозиторий, сделал вот такой тест:
Schedule schedule = new Schedule("2021.*.23-27,29 0-3,5 12:00:00.1"); SimpleDateFormat f = new SimpleDateFormat("dd.MM.yyyy HH:mm:ss.SSS"); f.setTimeZone(TimeZone.getTimeZone("UTC")); Date date = f.parse("24.02.2021 11:00:00.000");Первые 5 дат:
26.02.2021 12:00:00.001
28.02.2021 12:00:00.001
23.03.2021 12:00:00.001
24.03.2021 12:00:00.001
26.03.2021 12:00:00.001Однако 28 число не подходит под расписание. В вашем коде есть ошибки. Это просто первый пример, на который можно наткнуться при диагональном прочтении кода.
Тем не менее, заметка как минимум достойна внимания, с большим удовольствием прочитаю ее досконально, когда будет время. Спасибо за труд!
Andy_U
17.11.2021 16:28+3Вот еще случай для тестирования - так называемые дополнительные секунды: https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BF%D0%BE%D0%BB%D0%BD%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%B5%D0%BA%D1%83%D0%BD%D0%B4%D0%B0
cadovvl
17.11.2021 19:11+3Что упоминалось, кстати, еще у @PsyHaSTe.
Но в примере, который я привел, нет вообще ничего неординарного - обычный февраль...
У меня просто с самого начала закралось подозрение, что метод целиком не рабочий. Но чтобы сделать такое смелое заявление, нужно очень хорошо разобраться, что именно зашито внутри. Поэтому я быстро сконструировал контрпример, и пока успокоился.
Отдельные проблемы с лишними секундами можно будет потом пофиксить, если в целом концепция рабочая. Хотя от "священного Грааля" ожидаешь большего.
KaminskyIlya Автор
18.11.2021 00:01+3Коллега, Вы изумительны! Прочитать по диагонали статью, до конца не разобравшись в коде, найти ошибку! Снимаю шляпу.
Исправил: ошибка была в классе LastDayOfMonthProxy:
public boolean hasNext(int value) { return value < getHigh() }public boolean hasNext(int value) { return value < getHigh() && match(getNext(value)); }Уже после публикации статьи, прочитывая код нашел ещё одну ошибку. Как говорил @PsyHaSTe "копипаста - зло".
Исправлю, опубликую фикс.
KaminskyIlya Автор
18.11.2021 00:21откуда в моем решении взялось O(n) понять не могу.
Допускаю, что где-то промахнулся в своих изысканиях. Не смог реализовать ваш алгоритм, ибо специфика C++.
А попробуйте, пожалуйста, такие расписания:
"*.02.29 6 12:00:00" для даты "01.01.2021 12:00:00.000" (ожидается "29.02.2048 12:00:00.000")
"*.*.27-32/2 1 12:14:34" для даты 31.01.2021 12:14:33.177 (ожидается "29.03.2021 12:14:34.000")
"*.*.20-32/5 5 12:14:34" для даты "31.01.2021 12:14:33.177" (ожидается "30.04.2021 12:14:34.000")
И померьте скорость, увеличивая начальную дату с шагом в секунду/миллисекунду/час.
cadovvl
18.11.2021 01:00Как будет время - обязательно гляну. Заодно статью прочитаю нормально.
Кажется я понял что имеется ввиду под O(n), надо будет посмотреть, какой это эффект дает на практике.
TakashiNord
17.11.2021 14:37в который раз убеждаюсь, что какие то не адекватные работодатели.
тестовое задание - это минимум задачка из универа, по лабораторной, для всего остального есть ТК. А не "дипломный проект" как у автора выше.

kemsky
17.11.2021 15:54Интересная задача, согласен, даже хочется попробовать свои силы, пока у меня есть один вопрос по условию.
В расписании можно задавать интервалы с шагом, например 10-20/4 или */5, и мне кажется для пользователя будет вполне естественно задать любое количество пересекающихся интервалов с шагом, например так 10-20/4, 15-19/2, */5, судя по коду в статье эта ситуация не поддерживается.
KaminskyIlya Автор
18.11.2021 00:25Поддерживается. Есть, например, такой тест: "*.*.* * *:*:*.1,2,3-5,10-20/3". Посмотрите все тесты.
Для таких случаев используются HashMapMatcher и BitMapMatcher.

screwer
17.11.2021 17:02-1Не читал ни условий задания, ни решений. Но вот наличие аж 7ми проверок заставила написать этот комментарий.
Берём 64битное число 1-ms интервалов, прошедших с даты X (кто-то может уже подчерг схожесть с SYTEM_TIME из мира windows). Парсим даты в него. Всё!
Сравнение - одна операция. Определение длительности между двумя датами - тоже одна операция. Текущее время - число тиков с момента старта системы, приведенное к выбранной базе.

Mingun
17.11.2021 19:03+3Явно, что не читали. У вас нету двух дат. У вас есть расписание и начальная дата, и вам надо сгенерировать следующую дату. И в чём вам здесь поможет 64-битное число?
screwer
17.11.2021 19:23-3Прибавлю необходимую дельту - результат готов. Одна операция. Результат можно сравнивать в дальнейшем также одной операцией (наступило ли событие)
Какой смысл хранить и оперировать с датами в человеко-читаемом формате ? Чем хуже монотонное число тиков ?

WVitek
17.11.2021 19:47-2Делал давно что-то вроде RTOS для 80186-совместимых контроллеров, именно INT64-счетчик миллисекунд от старта системы был удобен для планировщика.
Для отложенных событий (обычно это было пробуждение заданного потока в заданный момент времени) вычисляется будущее время срабатывания и соответствующая запись добавляется в сортированный по возрастанию времени список. Вот соответствующий старый код, не особо читаемый.
В таймерной функции планировщика просто в цикле, пока время первой записи списка <= текущему времени, отрабатываем и удаляем голову списка (например, пробуждаем все потоки, которые должны проснуться в текущую миллисекунду). С частотой 1000Гц нормально всё планировалось на не особо быстром CPU.
Арифметика же на датах - это, имхо, скорее академическая задача, чем то, что нужно реализовывать на практике.
Gutt
17.11.2021 19:50+3Так ведь в задаче весь цимус в том, что нужно как-то перевести птичий язык крона в юникстайм, с учётом високосных годов, часовых поясов, коррекций UTC и прочего ада. Если была бы задача складывания двух интов, то проблемы бы не было.
WVitek
17.11.2021 20:55+1Я к тому, что в практической задаче, наверное, следовало бы вынести сложную арифметику дат из цикла/таймера планировщика, и работать с сортированным списком int64-таймстампов следующих срабатываний записей. При срабатывании записи вычислять время следующего её срабатывания и опять добавлять в список.
Тогда каждый тик планировщика обычно обходился бы в O(1) и не потребовалась бы сверхоптимизация арифметики дат.
Описанный в исходной задаче API видится избыточным и ограничивающим достижимую производительность, ведь для реальной задачи реализации высокопроизводительного планировщика, имхо, хватило бы одного метода вида "получить DateTime следующего срабатывания по заданной маске относительно текущего DateTime".
Если рассматривать как чисто академическую задачу - тогда вопросов никаких)Gutt
17.11.2021 21:56Полностью поддерживаю, реальный планировщик, разумеется, должен питаться рафинированными таймстемпами, а парсер в реальном мире может быть сколь угодно медленным в пределах разумного. В задании ведь ни слова о том, что нужно очень быстро парсить крон.
Mingun
17.11.2021 22:55+1Откуда, когда и как получать этот сортированный список int64-таймстампов? Вы в момент создания расписания не знаете начальной даты, от которой считать следующую надо. А расписание может генерировать событие каждую миллисекунду. Предлагаете весь этот неопределённый диапазон в памяти держать?
получить DateTime следующего срабатывания по заданной маске относительно текущего DateTime
То есть, вместо того, чтобы один раз распарсить строку расписания при создании объекта расписания вы предлагаете делать это при каждом тике? Что-то не вижу в таком подходе ничего высокопроизводительного.
При срабатывании записи вычислять время следующего её срабатывания и опять добавлять в список.
Сюрприз, ровно об этом эта и (почти) все предыдущие статьи и были :)

czz
18.11.2021 01:10Откуда, когда и как получать этот сортированный список int64-таймстампов? Вы в момент создания расписания не знаете начальной даты, от которой считать следующую надо.
В конце каждого дня просчитывать на следующий день.
WraithOW
18.11.2021 12:10+2Несложная арифметика подсказывает, что при точности в 1мс в сутках 86 400 000 возможных таймстампов, при использовании int64, то есть 8 байт на запись, получаем в худшем случае 691 200 000 байт для описания одного дня, и это только для одного события. Планировщик, который жрет память гигабайтами, каеф.
czz
18.11.2021 13:51Для таймстампа хватит 4 байт, если он относительный. Можно предрасчитывать на минуту — 60000 таймстампов по 2 байта, уже не так плохо.
Вообще вы правы, конечно, задача в посте поставлена так, что в ней нет никаких ограничений. В реальном мире было бы понятно, что это за события, сколько их на самом деле будет. Если это реально система, генерирующая события с миллисекундной частотой по миллиону расписаний, то скорее всего, на нее не пожалели бы памяти, чтобы сделать ее максимально реалтаймовой.
gorilych
18.11.2021 09:08-1А расписание может генерировать событие каждую миллисекунду
Зачем? Постановка задачи тупая. Если вам нужен быстрый крон, то он должен знать момент события, а не вычислять его каждый раз. А точные моменты из расписания должны вычисляться заранее, тогда уже особо не надо время экономить. Эта задача - пример плохого проектирования ПО.
KaminskyIlya Автор
18.11.2021 00:31+1Для этого есть генератор (см. конец статьи). Судя по бенчмаркам - генерирует следующее значение за 100нс. Но это, повторюсь, на моем компьютере и это Java, а не ассемблер.
Обратите внимание, что getNextEvent работает в среднем за 500нс, а next() у генератора, использующего точно такой же алгоритм - за 100нс.
Очередное подтверждение, что производительность сильно падает на Григорианском календаре, который я уже и так оптимизировал, пожертвовав некоторой точностью.


csl
17.11.2021 22:40+1Если в посте подразумевался порядок по датам публикаций, то он таков (одна статья вами пропущена https://habr.com/ru/post/587748/ ?): @novar, @PsyHaSTe, @cadovvl, @mvv-rus

mvv-rus
18.11.2021 05:23+2Справедливости ради: моя статья — она чисто про парсер. С этой статьей пересечений по материалу практически нет. Ну, не считая, что она про ту же тестовую задачу.
PS Надеюсь-таки побороть свою лень и дописать еще одну статью на ту же тему — про решение того же тестового в стиле «старого доброго ООП». Точнее, само решение практически сделано и даже лежит на Github. Если кому-нибудь интересно, могу дать ссылку: там уже не полработы, а почти вся работа сделана, так что можно уже всем показывать. Но та статья посвящена другому аспекту кода — простоте, краткости и потенциальной расширяемости (ибо подозреваю, что именно это работодатель на самом деле и хотел увидеть в решении), а потому там про бенчмарки ничего нет. Про оптимизацию на уровне алгоритма — немного есть, но без цифр об оптимизации говорить смысла нет.

Deosis
18.11.2021 15:25+2Положим в расписании задано время *:*:30-59. Внешняя функция, вызывающая наш планировщик получила текущую системную дату, которая была синхронизирована с мировым временем и мы имеем такое: 23:59:60.000. Т.е. та самая високосная секунда +1. Но выше мы уже определили: что в расписании указано, то и допустимо. Поэтому секунда с номером 60 недопустима. Возвращаем дату следующего события, на секунду больше: +1 00:00:00.000.
Но расписание требует секунды от 30 до 59, а вы возвращаете 0.
KaminskyIlya Автор
18.11.2021 23:48А вот подловили) Я ошибся, конечно. По расписанию правильнее вернуть +1 00:00:30.000. И мой алгоритм вернёт, и реализации других авторов - вернут ровно тоже.
Если использовать родную реализацию Грегорианского календаря в C# и Java (javascript, php), они вам не позволят установить 60-ю секунду: автоматически приведут дату к следующему часу. На этом у некоторых в javascript основана техника определения максимальной даты в месяце: устанавливаем 0-е марта и, вуаля, получаем последний день февраля.
В моей кастомной имплементации календаря, можно установить 60-ю секунду. Но тут сработает матчер расписания, заставив сбросить на "ноль". А нулем у нас здесь будет "30".
cepera_ang
Монументально. Читая подобные разборы, мне каждый раз кажется, что мне никогда не стать "настоящим" разработчиком, потому что у меня никогда не хватит терпения подобным образом заморочиться над любой задачей, особенно случайно услышанной где-нибудь на хабре.