
Привет, Хабр! Меня зовут Кирилл Шеховцов, и я технический лидер в SberCloud. Сегодня расскажу, как быстро интегрировать пайплайн Continuous Integration/Continuous Delivery (CI/CD) и продуктовый подход к проектированию приложений в облаке SberCloud.Advanced. Эта обзорная статья будет полезна начинающим ИТ-специалистам и предпринимателям, которые только осваивают работу в облаке. Я составил материал в виде пошаговой инструкции, которой могут воспользоваться как крупные, так и небольшие команды разработчиков.

Что нам потребуется
Работа над проектом в рамках CI/CD включает семь этапов: написание кода, сборку, тестирование, релиз, развертывание, поддержку и мониторинг, плюс — планирование доработок. Благодаря неразрывному алгоритму, методология позволяет команде выпускать обновления для приложений в течение нескольких недель и даже дней. При классическом подходе на это могут уходить месяцы. Поэтому задействуем CI/CD.
Мы будем работать с сервисами SberCloud.Advanced — пара слов о каждом из них:
FunctionGraph — позволяет размещать и запускать код в бессерверной среде по заданному триггеру, автоматически масштабируется.
API Gateway — единая точка входа в наш бэкенд для API.
Cloud Container Engine — для управления приложениями в среде Kubernetes.
Software Repository for Container — хранилище образов docker-контейнеров.
Cloud Performance Test Service — позволяет проводить нагрузочное тестирование.
Писать демонстрационное приложение будем на React, в частности, используем свежеустановленный Next.js (установить его можно при помощи npx create-next-app@latest). Для того, чтобы у приложения появился бэкенд, воспользуемся FunctionGraph, а также протестируем наше приложение при помощи Cloud Performance Test Service.
Переходим к коду
Первым делом откроем среду разработки и установим зависимости. Для этого в консоли выполним команду npm i. Таким образом, наше приложение проинициализировалось.

После инициализации приложение можно запустить локально и разместить код в репозитории. В данном случае его структура стандартна для Next.js-приложений, а единственное дополнение, которое я внес — dockerfile с инструкциями по сборке.
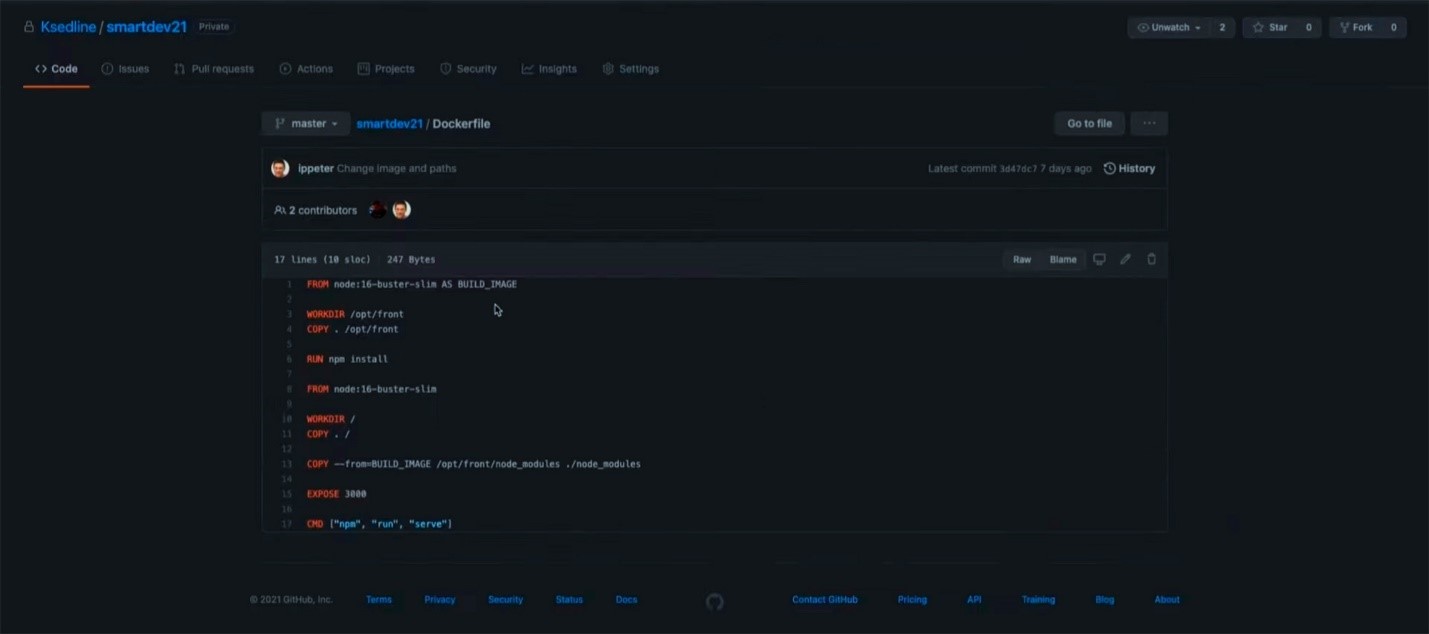
В этом docker-файле я отметил, что приложение будет работать со средой node:16-buster-slim. Затем указал рабочую директорию инструкцией WORKDIR и скопировал все содержимое данного приложения директорию /opt/front. Далее, установил зависимости командой RUN и вновь обратился к среде node:16-buster-slim: фактически я использую многоэтапную сборку (multi-stage build). Этот шаг помогает сократить размер финального образа, так как по умолчанию NODE-зависимости «тянут» за собой достаточно большое количество дополнительных зависимостей (так называемые peerDependencies). Повторное обращение к инструкции FROM позволяет сократить число ненужных объектов в финальном образе. Так, мы подключаем только те зависимости, которые нужны для запуска приложения. Обращаться к нему мы будем через порт 3000.
Перейдем к настройке Jenkins. Его я развернул в Elastic Cloud Service в облаке SberCloud. В разделе, который называется «Управление исходным кодом» подключаем нашу git-среду — указываем ссылку на наш репозиторий smartdev21.git. В качестве типа подключения выбираем HTTPS, хотя есть и другие варианты — SSL или SSH.

В выпадающем списке поля Credentials выберем данные учетной записи, необходимой для подключения к репозиторию с контейнером.

Далее, настроим работу триггеров, являющихся неотъемлемой частью CI/CD-пайплайна. Они реагируют на изменения в master-ветке, чтобы Jenkins автоматически производил сборку кода. В блоке «Триггеры сборки» установим галочку напротив пункта «Опрашивать SCM об изменениях» и в поле ниже пропишем следующее условие: * 10-19 * * 1-5. Оно означает, что система будет просматривать репозиторий на наличие изменений с 10 часов утра до 19 часов вечера с понедельника по пятницу, то есть каждый рабочий день.

Сразу после этого отметим галочкой пункты Delete workspace before build starts и Use secret. Первая настройка укажет системе очищать наше рабочее пространство перед каждой новой сборкой, а вторая — запретит вывод токенов или паролей в логи.
Далее прописываем в Jenkins имя пользователя и пароль от контейнера с нашим приложением.

На этой же странице задаем последовательность shell-команд для этой операции. Первая команда осуществляет сборку:
docker build -t smartdev: $BUILD_NUMBERВторой набор команд отправляет образ в облачный репозиторий – сервис SWR, Software Repository – с адресом в нашем облаке:
docker tag smartdev:$BUILD_NUMBER swr.ru-moscow-1.hc.sbercloud.ru/devconf/smartdev:$BUILD_NUMBER
docker login -u ru-moscow-1@$SWR_USER -p $SWR_PASS https://swr.ru-moscow-1.hc.sbercloud.ru
docker push swr.ru-moscow-1.hc.sbercloud.ru/devconf/smartdev:$BUILD_NUMBER
docker logout
Наконец, третья команда обновляет приложение, развернутое в Kubernetes (сервис ССЕ, Cloud Container Engine), устанавливая новый образ контейнера:
kubectl set image deployment/smartdev21 container-0=100.125.13.65:20202/devconf/smartdev:$BUILD_NUMBER Функция FunctionGraph
В нашем приложении создадим функцию из FunctionGraph. Первым делом на панели управления SberCloud.Advanced выбираем одноименный пункт во вкладке Computing.

Чтобы создать новую функцию, в открывшемся окне нажимаем Create Function (правый верхний угол).

Появится страница, на которой нам нужно прописать название функции — в моем случае это smartdev21. В поле Runtime выбираем среду выполнения, пусть это будет версия Node.js 12.13.

В конце страницы вы можете видеть небольшое окно, напоминающее среду разработки. Здесь уже сформирован код express-приложения (в терминологии Node.js). По умолчанию к нему на вход поступают переменные event и context. Нам они не нужны, поэтому мы их заменим.
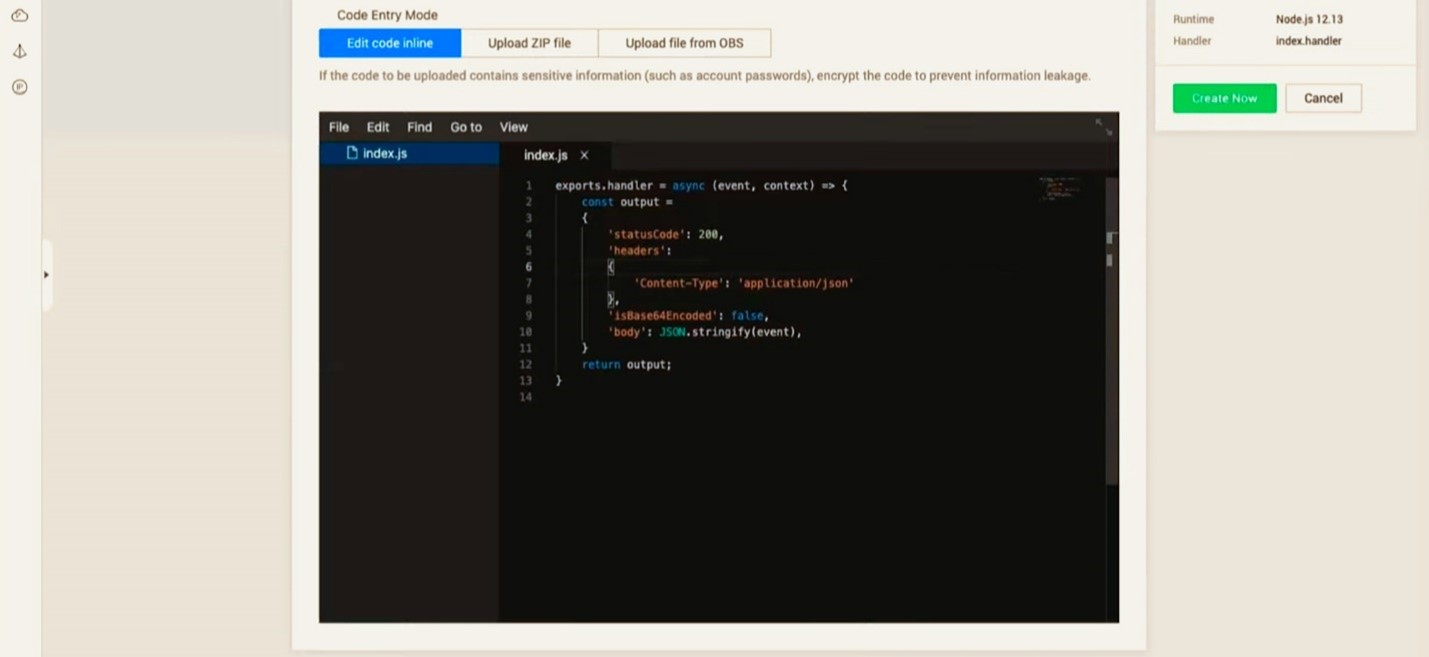
Пропишем в операторе JSON.stringify следующую строчку — response: Math.random(). Она генерирует случайное числовое значение. В рамках туториала условимся, что это будет единственной задачей создаваемой нами функции.

Далее, добавим в код обработку CORS-запросов, так как наше приложение работает по HTTPS в среде localhost. В блоке headers укажем название заголовка: Access-Controll-Allow-Origin и присвоим ему значение ‘*’. Такой подход позволит нам принимать заголовки со всех адресов. Далее, нажимаем на Create Now, на чем заканчиваем описание функции FunctionGraph.
В окне только что сформированной функции есть вкладка Configuration. В ней вы можете добавить описание, увеличить объем оперативной памяти или установить таймаут на выполнение. Однако в настоящий момент нас интересует вкладка Triggers, где мы подключим триггер. Переходим в неё и нажимаем Create Trigger.
В выпадающем меню выбираем тип триггера — API Gateway, и даем ему имя. Я решил оставить предложенное системой по умолчанию. В этом же окне в поле Security Authentication ставим значение None, чтобы отключить авторизацию. Я это делаю исключительно в демонстрационных целях, чтобы упростить дальнейшую настройку — на реальной системе, разумеется, так делать нельзя. На практике чаще всего применяют авторизацию через App или IAM.

После нажатия на клавишу OK, в правом верхнем углу появится уведомление об успешном создании триггера — он отобразится на главном экране. В строке URL показан адрес нашей функции.

Если сейчас вставить его в адресную строку браузера, на странице появится надпись response со случайным числом.
Передаем данные из FunctionGraph в React
Вернемся в среду разработки и настроим импорт двух хуков — useEffect и useState. Первый позволяет выполнять сторонние эффекты внутри компонентов React, а второй позволяет управлять состоянием.
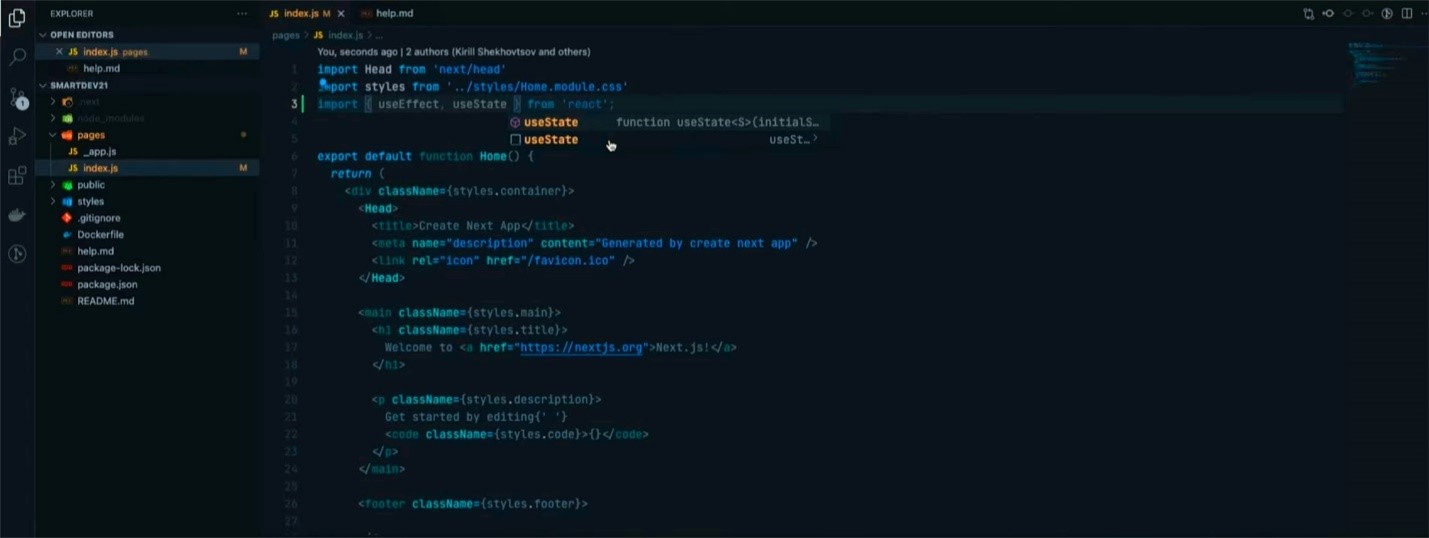
Импортируем useEffect с помощью import. Эта функция в качестве параметра будет получать массив зависимостей. Если мы изменим его значение, то сработает хук useEffect. Далее, добавляем state с названием data. Прописываем его как [data, setData], а базовое значение устанавливаем в null при помощи useState.

Далее, в useEffect используем fetch. Это интерфейс для работы с web-запросами, который пришел на замену AJAX или XHR. Далее, нам необходимо получить из нашего API Gateway значение res — это ответ функции fetch. Если он придет в формате JSON, то его нужно расшифровать и привести к JS-объекту с помощью return res.json(). Наконец, осталось выполнить then, и установить объект как setData.
Добавим в наш код обработку ошибок — отлавливать нештатные ситуации будем с помощью анонимной функции catch. Чтобы вывести информацию о сбое в консоль, пропишем console.error, а setData присвоим сообщение ошибки. Если такого сообщения нет, будем получать его из поля err?.error.

Вы могли заметить, что я использовал символы ‘?’. Это — синтаксис в JS, реализующий операцию опциональной последовательности. Она позволяет получить значение свойства, находящегося на любом уровне вложенности в цепочке связанных между собой объектов. Таким образом, если запись err?.message вернет нам null или undefined, мы перейдем к отображению ошибки. Чтобы перестраховаться, я также добавил вывод фразы «Непредвиденная ошибка» на тот случай, если причина сбоя окажется неизвестна.
Нам осталось в блоке code запросить из data наш response — именно так назывался ключ в FunctionGraph, куда мы записали случайное математическое значение. Если он по какой-то причине отсутствует, выводим сообщение об ошибке.

Проверим работу кода, запустим его на локальном сервере. Страница браузера поприветствует нас следующим сообщением:

Переходим к релизу
Теперь зальем наш код в репозиторий и проведем релиз. Для этого в консоли среды разработки прописываем git-коммит с флагом -am, обозначающим все модифицированные файлы, и даем ему название (в моем случае это Update).

Далее, при помощи команды git push отправляем их в репозиторий.
Перейдем в Jenkins и посмотрим на состояние сборки. Идем в «Историю сборок». Прежде чем информация отобразится в панели управления («Состояние сборников»), нужно дождаться срабатывания триггера (он действует на интервале 1–5 минут).

Если мы кликнем на её название — devconf, то увидим подробности о ходе загрузки.

По клику на новую сборку откроется окно со свойствами.

В меню «Вывод консоли» можно следить за прогрессом загрузки и обработки в реальном времени.

Спустя какое-то время, в конце текстового фида появится надпись SUCCESS. Это означает, что отправка кода в docker завершена успешно.

В этот момент произойдет так называемый «прогрев» приложения Next.js, и на какое-то время оно станет недоступным. Дело в том, что приложение проходит этап предварительной сборки, прежде чем дойти до пользователя. Разумеется, в реальной продуктовой разработке такая ситуация недопустима, поэтому там более сложные подходы, например, «сине-зеленые» сборки. Это сборки, которые можно менять местами при релизе, таким образом, в случае недоступности одной сборки – будет отображаться другая сборка. Этот подход также комбинируют вместе с георезвированием.
Пока идет сборка, посмотрим, как выглядит серверная инфраструктура в облаке. Для этого в меню платформы SberCloud.Advanced выбираем пункт Elastic Cloud Server.

Откроется список запущенных приложений — тут есть воркеры выполняющие сборки в Jenkins, виртуальная машина для самого Jenkins’а (ecs-jenkins) и дополнительные машины, участвующие в сборках (они поднимаются автоматически).

Но вернемся к нашему приложению. Сборка завершена, приложение развернуто на нашем Elastic Cloud Service, а также функция из FunctionGraph возвращает нам случайное значение.

Протестируем приложение
Для этого воспользуемся сервисом для нагрузочного тестирования в облаке SberCloud.Advanced — Cloud Performance Test Service.

В меню слева представлены несколько вариантов тестов: JMeter с поддержкой jar-скриптов, а также CPTS для запуска проектов внутри среды. Для примера воспользуемся последним вариантом, нажимаем на соответствующий пункт меню, а затем — на Create Test Project. Во всплывающем окне прописываем только название проекта (smartdev).

Он отобразился на главном экране, теперь настроим его. Кликаем по проекту, затем по Add Task, чтобы добавить задачу.

Во всплывающем окне прописываем название — smartdev-test — и подтверждаем действие.

Задача появилась в главном окне, на её выполнение уже выделен определенный объем ресурсов. Теперь нужно добавить кейсы.

Для этого нажимаем большую кнопку Add Case. Во всплывающем окне указываем его название — smartdev_test_case.

Переходим к конфигуратору запросов — нажимаем на Add Request.

В открывшемся окне будет обширное количество настроек. Тут можно выбрать тип протокола — например, доступны тесты по TCP, UDP, скоро появится поддержка WEBSOCKET. В поле Request Mode мы можем сконфигурировать метод тестирования, а чуть ниже — указать время на выполнение. Я переименую запрос в smartdev-request, но остальные настройки оставлю без изменений. Также вставлю ссылку нашего опубликованного приложения в качестве источника тестирования — в поле Request URL.

При желании в этом же окне можно отметить, хотим мы получать cookies или нет, и при необходимости указать заголовки. Мы с ними работать не будем, поэтому я нажму Delete.
Подтверждаем формирование запроса, осталось добавить фазу. Она определяет, каким нагрузкам будет подвергнуто приложение. В рамках этого туториала я остановлюсь на одной. Кликаем Add Phase.

В первом поле окна создания фазы прописываем имя — Stage-Smartdev-Phase1. Если переключить флажок Gradient Increment, система будет увеличивать нагрузку постепенно. В противном случае она начнет «бомбардировать» приложение всеми запросами сразу. За их количество отвечает настройка Concurrent User — предположим, что у нас 100 пользователей. На тестирование выделим три минуты.

Созданный нами тест появится сразу после нажатия на кнопку ОК. Теперь его нужно запустить — нажимаем Start и переходим к выбору ресурсов.

Во всплывающем окне выберем пункт меню «extranet». Этого должно хватить для демонстрации возможностей системы, однако для проведения серьезных стресс-тестов вам, скорее всего, придется сформировать собственный пул в Kubernetes.

Когда тест запущен, откроем dashboard’ы и взглянем на логи. На отображение первых данных у системы может уйти до десяти секунд.

На изображении выше в блоке Maximum Response Time видно, каким образом делится нагрузка. Эти шкалы отражают, сколько миллисекунд понадобилось на получение ответа от приложения. На графиках показан рост нагрузки и количество успешных тестов.
Отмечу, что отчеты всех тестов позже будут доступны в офлайн-режиме — во вкладке Offline Reports. Также в облаке SberCloud есть инструмент Intelligent Analysis, который позволяет подключить к отчетам аналитику и получить более глубокие инсайты.

Теперь если мы вернемся в настройки FunctionGraph, то увидим, что в окне мониторинга (вкладка Functions — Monitoring) отобразились метрики.

Что в итоге
Мы разработали простое приложение, которое умеет забирать данные из двух источников, складывать их и выводить результат на страничке браузера. Сделали мы это достаточно быстро — при должной сноровке можно уложиться в обеденный перерыв. Экономия времени достигается за счет облачных сервисов с большим количеством автоматизированных конфигураторов.
При этом мы настроили полный CI/CD-пайплайн, благодаря которому поддерживать наше приложение в дальнейшем будет достаточно просто. Отмечу, что подобный алгоритм разработки может быть излишне сложным для маленьких команд, однако затраты непременно себя окупят, если проект вдруг начнет разрастаться. CI/CD помогает исключить влияние человеческого фактора на разработку — когда админ пишет большое количество команд вручную, глаз «замыливается» и легко сделать опечатку. В данном случае мы развернули простой вариант CI/CD при помощи системы Jenkins, а в облаке сборку выполняют автоматизированные PaaS/IaaS-сервисы — они это делают быстрее и точнее.
В то же время последовательность действий CI/CD можно улучшать практически до бесконечности. Например, для нашего примера стоит решить проблему с отключением приложения в момент сборки. На реальном проекте такое недопустимо, так как клиентам важна отказоустойчивость. Исправить ситуацию можно несколькими способами — например, использовать «сине-зеленые билды», которые периодически меняются друг с другом. Реализовать такой подход на практике можно с помощью контейнеров — достаточно сформировать два инстанса приложения и переключать их, когда одно уходит на обновление. Также можно добавить больше тестов — реализовать не только внешнее юнит-тестирование, но и дописать несколько проверок прямо в коде приложения. Наконец, можно внедрить TypeScript — в будущем он позволит сэкономить время на переиспользовании типов внутри приложения.