
Вот уже в который раз хочется поднять тему многопоточного программирования. Сейчас я попытаюсь донести мысль, что если посмотреть на эту тему под другим - более простым, как мне кажется, углом, то она не будет казаться такой сложной и неприступной для начинающих. В этой статье будет минимум формализма и известных (и не очень) терминов.
Откуда ноги растут
В начале 2000-х годов наблюдалось замедление скорости роста производительности процессоров. К 2005 году увеличение тактовой частоты процессора практически остановилось. Сейчас мы можем вспомнить 2010 год и выход Intel Core i5-680 с тактовой частотой 3,60 ГГц. Прошло десять лет и сейчас можно приобрести Intel Core i9-10850K с частотой от 3,60 до 5,20 ГГц. Разница, как можно заметить, невелика. Этот пример очень синтетический и примитивный, но он наглядно показывает скорость и направление развития современных процессоров. Конечно, производительность процессора зависит не только от тактовой частоты, а еще и от других параметров - размера и количества кэшей, частоты шины, типа сокета и так далее. И зачастую, особенно на боевых машинах, оказывается, что выгоднее взять процессор с более низкой тактовой частотой.

Что делать?
Когда вертикальное масштабирование (качественный рост) приходит к своему пику и ждет очередной революции, в дело вступает горизонтальное масштабирование (количественный рост). Решение было простым, сделать из одного процессора несколько. Так появились многоядерные процессоры.
Ядра процессора должны с чем-то работать, выполнять команды и куда-то складывать результат. Такое место называется память. Чтобы смоделировать память, мы можем представить ее как очень длинный массив данных, где индекс массива это адрес.
Представим, что мы обладаем общей памятью и ядрами в количестве N штук.

Операций, которые можно выполнять с памятью, всего две - чтение по адресу(индексу) и запись по адресу(индексу) (как будто мы работаем с массивом). Пока что будем считать, что операции с памятью выполняются сразу и без каких-либо задержек.
Поток
К сожалению, придется ввести еще один термин, без него никак не получится перейти к многопоточному программированию.
Пусть ядро - это станок на заводе, тогда поток - это рабочий, который за ним работает. У каждого рабочего есть набор задач, которые он должен выполнить - это исходный код. Пока что будем считать, что исходный код исполняется по порядку, это значит, что операция 1 гарантировано выполнится до операции 2, операция 2 до операции 3 и так далее.
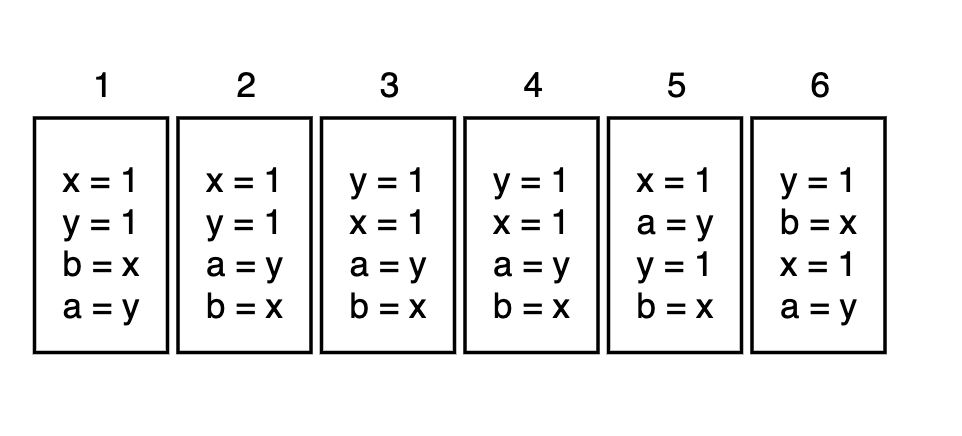
int a = 0 // операция 1, выполнится самая первая
int b = 0 // операция 2, выполнится после операции 1
a = a + b // операция 3, выполнится после операций 1 и 2
b = a + a // операция 4, выполнится после всех операцийДавайте попробуем решить простую задачу. Какие варианты пар (a, b) возможны после завершения исполнения обоих потоков, положитесь на свою интуицию, стоит рассмотреть даже самые, казалось бы, невозможные варианты:

Ответ
Пусть поток 1 выполнился полностью, а поток 2 еще не стартовал. Тогда в результате будет пара (0, 1)
Аналогично, поток 2 выполнился полностью, а поток 1 еще не стартовал. Тогда в результате будет пара (1, 0).
Во всех остальных случаях (0, 0)
Случая (1, 1) быть не может, так как хотя бы один поток перед своим завершением обнулит какую-то переменную.
В итоге получается [ (0, 1), (1, 0), (0, 0) ]
Как вы могли догадаться, понимание результата работы многопоточного кода сводится к рассмотрению всех вариантов его исполнения. В данном случае формально такая модель исполнения называется моделью последовательной консистентности (sequential consistency, SC).
Согласно данной модели, любой результат исполнения многопоточной программы может быть получен как последовательное исполнение некоторого чередования инструкций потоков этой программы. (Предполагается, что чередование сохраняет порядок между инструкциями, относящимися к одному потоку.)
К сожалению, настоящие программы оперируют не двумя переменными и не только пишут в память, но еще и читают ее. Попробуйте решить следующий пример, тут немного сложнее:

Ответ
Всего существует 6 вариантов исполнения. 1 - 4 варианты дадут результат (1, 1), 5 вариант даст результат (0, 1), 6 вариант даст результат (1, 0).

Многопоточность была бы простой если бы все закончилось здесь.
Конец?
К сожалению, или к счастью, это еще не конец. На процессорах самых популярных архитектур - x86, Arm, Power PC и Alpha, исполнение предложенного выше примера может быть другим - возможен результат (0, 0).
Пруфы
#include <stdio.h>
#include <pthread.h>
int x, y, a, b;
void* thread1(void* unused) {
x = 1;
a = y;
return NULL;
}
void* thread2(void* unused) {
y = 1;
b = x;
return NULL;
}
int main() {
int i = 0;
while (1) {
x = 0;
y = 0;
a = 0;
b = 0;
pthread_t tid1;
pthread_attr_t attr1;
pthread_t tid2;
pthread_attr_t attr2;
pthread_attr_init(&attr1);
pthread_attr_init(&attr2);
pthread_create(&tid1, &attr1, thread1, NULL);
pthread_create(&tid2, &attr2, thread2, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
i++;
if(a == 0 && b == 0) {
break;
}
}
printf("Iterations: %d\n", i);
return 0;
}
Код на языке C рано или поздно завершается, хотя в модели SC не должен.
Это не вписывается в модель SC (sequential consistency), поскольку не существует такого исполнения, которое бы привело к результату (0, 0). Выше мы допустили, что "операции с памятью выполняются сразу и без каких-либо задержек". Но для современных процессоров это совсем не так.
Если вы разрабатываете ПО, вы часто сталкиваетесь с таким термином как кэш. Удобно копить результат и лишний раз не обращаться к удаленному ресурсу. База данных для сервера, это как оперативная память для процессора. Ходить в нее дорого-далеко-долго (кому что больше нравится). Куда удобнее прочитать один раз, положить в кэш и при повторном чтении читать из кэша. Тоже самое и с записью. Например вы используете в своей программе запись в лог и вам не всегда хочется писать каждое сообщение сразу в файл, вы можете их хранить некоторое время в памяти, а потом при накоплении какого-то количества записать их за один раз.
Сейчас мы разберем (в качестве модели) архитектуру x86.

Кэш для чтения, буфер записи (англ. Store Buffer) для записи - все просто.
1. Процессор всегда читает из кэша
2. Если в кэше такого адреса не найдено, процессор идет в память и копирует его в кэш и читает из кэша.
3. Процессор всегда пишет в буфер записи.
4. При записи нового значения в буфер запись происходит и в кэш.
5. Записи из буфера попадают в память.
Все хорошо, когда мы живем в мире одного ядра. Но когда ядер несколько начинаются вопросы.
Ядро 1 прочитало переменную f в кэш, ядро 2 изменило переменную f. Как ядро 1 узнает о изменении переменной?
Пока что, в нашей модели, никакой синхронизации между ядрами у нас нет. Так и сломался наш пример, возьмем вариант исполнения 1 (во вкладке ответ):
x = 1 // запись попала в буфер записи (не в память)
y = 1 // запись попала в буфер записи (не в память)
b = x // в кэше потока 2 значения нет, читаем из памяти 0
a = y // в кэше потока 1 значения нет, читаем из памяти 0
В ответе (0, 0)Мы хотим вернуть нашему примеру исполнение, чтобы он согласовывался с моделью SC - интуитивно понятной моделью.
Барьеры
Для начала хочу затронуть тему инвалидации значений кэша. Чтобы не углубляться, значение в кэше ядра инвалидируется (значение становится "неактульным"), если изменяется (операция записи в store buffer) в другом ядре. Процесс инвалидации определяется протоколом когеренции кэшей (для x86 Intel это MESI), сейчас это не важно. Попробуем ответить на вопрос поставленные выше.
Ядро 1 прочитало переменную f в кэш, ядро 2 изменило переменную f. Как ядро 1 узнает о изменении переменной?
Например в данном случае, переменная f в кэше ядра 1 будет инвалидирована, при изменении в ядре 2. Как только мы попробуем прочитать инвалидированную переменную, чтение будет произведено из памяти (то есть значение будет актуальным).
Но так как инвалидировать значение переменной при каждом изменении в другом ядре очень дорого, запрос на инвалидацию попадает в очередь других ядер и переменная будет инвалидирована в удобный для ядра момент времени (то есть инвалидация переменной при изменении в другом ядре происходит не сразу, и ядро, обладающее старым значением, думает, что можно брать значение из кэша, если оно там есть).
Та же ситуация возникает и с store buffer, процессор записывает данные в память, когда ему будет удобно (но запрос на инвалидацию отправляется мгновенно). Подробнее взаимодействие протокола когеренции кэшей и барьеров я постараюсь раскрыть в следующей статье, а пока картинка.

Понятно, что "удобно" понятие неопределенное и не дает никаких гарантий. А мы хотим их получить. Для таких случаев в процессорах x86 и Arm (а также и в других) предусмотрены специальные инструкции - барьеры памяти.
load memory fence - выполнит все накопленные запросы на инвалидацию. Этот барьер гарантирует, что все последующие операции load не будут выполнятся до завершения load memory fence.
store memory fence - записать накопленные в буфере записи данные в память. Этот барьер гарантирует, что все последующие операции store не будут выполнятся до завершения store memory fence.
Добавим на рисунок места применения барьеров

Тогда, чтобы исключить результат (0, 0) в нашем примере, нужно придумать, куда и какие именно барьеры поставить (барьер это инструкция, для простоты можно считать его вызовом функции - например store_memory_barrier(), и добавить до/после какой-либо строки).
Замечание-ответ
Простым решением конечно же будет являться такое добавление барьеров. После записи x и y необходимо, чтобы они попали в память. А перед чтением x и y нужно обновить кэш.

Но, подумайте, можно ли избежать лишнего добавления барьера, поскольку каждый барьер останавливает поток пока не обновится кэш или не запишется буфер записи. Если вы пишете конкурентный код, каждый барьер может оказывать решающее значение на производительность.
Окончательный ответ
Попробуем раскрутить простое решение
1) Можем ли мы убрать store barrier? - не можем, тогда значения x и y навечно(в нашей модели) останутся в буфере записи.
2) Можем ли убрать load barrier? - не можем, тогда инвалидация значений значений может еще не произойти (ядро "не увидит" изменения других ядер).
Представляю рабочий вариант(решение через добавление обоих барьеров), который корректно будет исполнятся в любом случае (вариант на процессоре x86).
Рабочий пример
#include <stdio.h>
#include <pthread.h>
int x, y, a, b;
void* thread1(void* unused) {
x = 1;
// store barrier
__asm__ __volatile__ ("sfence" ::: "memory");
// load barrier
__asm__ __volatile__ ("lfence" ::: "memory");
a = y;
return NULL;
}
void* thread2(void* unused) {
y = 1;
// store barrier
__asm__ __volatile__ ("sfence" ::: "memory");
// load barrier
__asm__ __volatile__ ("lfence" ::: "memory");
b = x;
return NULL;
}
int main() {
int i = 0;
while (1) {
x = 0;
y = 0;
a = 0;
b = 0;
// store barrier - для честности эксперимента
__asm__ __volatile__ ("sfence" ::: "memory");
pthread_t tid1;
pthread_attr_t attr1;
pthread_t tid2;
pthread_attr_t attr2;
pthread_attr_init(&attr1);
pthread_attr_init(&attr2);
pthread_create(&tid1, &attr1, thread1, NULL);
pthread_create(&tid2, &attr2, thread2, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
i++;
// load barrier - для честности эксперимента
__asm__ __volatile__ ("lfence" ::: "memory");
if(a == 0 && b == 0) {
break;
}
}
printf("Iterations: %d\n", i);
return 0;
}
Код скомпилирован с ключом -O0 (отключение оптимизаций)
Если Вам удалось понять содержимое статьи, то любые другие элементы многопоточного программирования дадутся Вам намного легче.
Конец
Если Вы сталкиваетесь с многопоточностью впервые, скорее всего с первого и даже с третьего раза Вам будет понятно не всё. Для полного понимания нужна практика.
В этой статье не затрагивалась операционная система, блокировки, методы синхронизации, модели памяти, компиляторные оптимизации и многое другое. Если статья покажется читателям хорошей и самое главное понятной, я постараюсь в скором времени рассказать о других аспектах многопоточности в таком же ключе.
Поскольку это моя первая статья, я скорее всего допустил множество ошибок и неточностей, поэтому буду рад услышать комментарии. Спасибо за внимание!
Комментарии (26)

creker
19.11.2021 19:47+1В этой статье не затрагивалась модели памяти
Помоему раздел про барьеры как раз этого и коснулся. С учетом повсеместной когерентности как раз проблема будет не в кэшах, а в возможности смены порядка чтений и записей процессором. И барьеры в этом случае как раз и помогут. Собственно, а разве барьеры нам помогут, если у нас кэш автоматически не инвалидируется? Для этого вроде как отдельные инструкции нужны.

don-dron Автор
19.11.2021 21:24+1Постарался не вводить лишние сущности в виде моделей памяти (SC интуитивно понятна - поэтому не считается)) По поводу инвалидации кэша тема вообще отдельная и непростая, строго говоря LFENCE работает сложнее и не просто "обновляет" кэш. https://www.felixcloutier.com/x86/lfence

teleport_future
19.11.2021 22:58Интересно, а проще ни как сделать нельзя? Например в функциях, которые выполняются параллельно void* thread1(void* unused) {} и void* thread2(void* unused) {}, вызывать общую функцию для присвоения значения переменной? (в которую, ну если сильно надо, добавляем "локер"). Зачем кэш по каждому чиху дергать? Он нужен для других целей, а не для того, чтобы постоянно "сбрасывать" его в память.
don-dron Автор
19.11.2021 23:13+2Можно конечно, но тема блокировок - отдельная, здесь гвоздем программы были барьеры. Локи/блокировки дают очень классный (иногда колоссальный) оверхед на процессор. Особенно видно на конкурентных структурах данных. Условно, если написать стэк на DCAS (или стек на двух CAS), а потом сравнить его с стэком под локом, то на бенчмарках можно увидеть неприятную картину - количество операций в секунду может быть и в 3+ раза меньше на стэке под локом (будет зависеть от количества потоков).
Конечно, в реальных бизнесовых проектах редко встретишь конкаренси ( и это хорошо ), но если и встречается, то ограничивается synchronized в Java и спинлоками/мьютексами/фьютексами в C/C++.
Тема про барьеры описанная здесь - одна из подводок к моделям памяти. В частности хочется рассказать про JMM в более простом ключе, а не так как это описано в её спецификации (без 100 грамм не разберешься).

gwg605
20.11.2021 04:47+3На мой взгляд надо начинать не этого, это технические детали нижнего уровня. А с понимания, что такое вообще многопоточное программирование. Архитектура многопоточных приложений и тп. И при грамотном подходе к архитектуре приложения, выбору языка и библиотек возможно все вышеперечисленные "ужасы" не будут вообще нужны. А если вы наступили на эти "грабли" или у вас в приложении что-то не так или вы разрабатываете какую-то низкоуровневую библиотеку.
don-dron Автор
20.11.2021 15:57+1Согласен с этой точкой зрения, я буквально полгода назад придерживался её же. Но к сожалению, современные ограничения и в частности барьеры дают такое сильное влияние, что оно рушит всю картину. Появление acquire/release и вообще моделей памяти - высокоуровневых абстракций , модели happens before , связано со слабыми моделями памяти процессора. Для меня это тот случай, когда детали реализации оказывают решающее влияние. Иногда встречаю людей, которые живут в мире некоторых правил и не сталкиваются с такими ужасами, но стараются сыграть в многопоточность и совершают примитивные ошибки. Если не заходить дальше простых элементов, это не конечно нужно, но если вам нужен первоманс на той же джаве, без этого не обойтись.
gwg605
20.11.2021 16:39+2Какая основная задача в многопоточности - минимизировать синхронизацию. Синхронизация это то, что тянет обратно в монопоточность. Синхронизаия это работа с шаред данными из многих потоков и тп. И то что вы пишете в этой статье как раз относиться к нижнему уровню синхронизации. Но идеальное многопоточное приложение это приложение в котором нет вообще никакой синхронизации. Что в реальности - не реально. Поэтому если вы не являетесь гуру в разработке методов синхронизации в многопоточных приложениях, используйте стандартные, проверенные временем, подходы и объекты синхронизации, иначе вероятность сделать ошибку очень велика. Поэтому основная задача это убрать синхронизацию из приложения, не пытаться изобрести новый велосипед в синхронизации, и мыслить параллельно :)
don-dron Автор
20.11.2021 17:34Согласен, но, к сожалению, далеко не везде можно обойтись параллельным исполнением с синхронизацией только на join) В highload проектах, например GC, СУБД и других без этого никак не получится

Revertis
20.11.2021 15:18int a = 0 // операция 1, выполнится самая перваяint b = 0 // операция 2, выполнится после операции 1a = a + b // операция 3, выполнится после операций 1 и 2b = a + a // операция 4, выполнится после всех операцийВ упор не вижу откуда тут может взяться единица.

martin_wanderer
21.11.2021 13:24Такое впечатление, что этот код не относится к вопросу про возможные результаты выполнения двух потоков. Видимо, к вопросу относится только следующая картинка.


paluke
20.11.2021 15:40+1Поэтому представляю рабочий вариант(решение через добавление обоих барьеров), который корректно будет исполнятся в любом случае (вариант на процессоре x86).
Этот пример у меня успешно завершается. А вот если заменить на mfence пару sfence + lfence, то не завершается. Ryzen 7 5800X, linux.don-dron Автор
20.11.2021 15:47Как раз и не должен завершаться) это значит , что мы исключили вариант (0,0), вообще странная ситуация, по спецификации mfence это комбинация lfence и sfence
paluke
20.11.2021 19:03Я понимаю, что не должен. И да, мне тоже показалось странным. Но вот так. Несколько раз перепроверил. Получается, mfence != lsence+sfence
don-dron Автор
20.11.2021 19:19Попробую поискать информацию об этом, что то новое для меня, к сожалению на Intel не воспроизводится( надо найти AMD
paluke
20.11.2021 19:21+1Нашел обсуждение stackoverflow.com/questions/27627969/why-is-or-isnt-sfence-lfence-equivalent-to-mfence
don-dron Автор
20.11.2021 20:24Отличное объяснение спасибо, не знал таких тонкостей, надо как-то в будущем будет упомянуть этот аспект
paluke
20.11.2021 20:20Почитал я разные обсуждения по этому поводу. У меня сложилась некоторое представление, может и не совсем верное… Но попробую рассказать. Современные процессоры суперскалярные, с несколькими исполнительными блоками. И в результате порядок выполнения инструкций процессором может меняться, если перестановка не влияет на результат, видимый в этом потоке. То есть просто в нашем примере a=y может выполниться раньше, чем x=1.
sfence запрещает перестановку операций записи в память до и после себя, lfence — операций загрузки из памяти. Но они не могуг запретить выполнить чтение до записи. А mfence запрещает перестановку любых обращений к памяти.don-dron Автор
21.11.2021 00:08Да это правда, процессор реордерит операции, я это не хотел рассказывать раньше времени, но уже выше обновил

alexeivanov
20.11.2021 15:58Спасибо за статью.
Подскажите, когда вы делаете в последнем примере// load barrier - для честности эксперимента __asm__ __volatile__ ("lfence" ::: "memory");это ведь делается для подъёма в кеш значений переменных a и b?
Но чем гарантируется предварительный сброс значений этих переменных в память?
sfence после их присвоения не вызывается.
Это обеспечивается особенностями memory model в C (не знаю этот язык), или я упустил саму цель lfence перед валидацией значений a и b?don-dron Автор
20.11.2021 16:02Хорошее замечание) по факту, да, в нашей модели должен быть еще store барьер после завершения инструкций каждого потока, я постараюсь рассмотреть этот пример еще раз в следующей статье и подробнее рассмотреть load barrier, мне уже кажется , что я принял слишком не точное его определение, которое может запутать, если действительно хочется разобраться советую почитать https://www.felixcloutier.com/x86/lfence и https://en.wikipedia.org/wiki/MESI_protocol (раздел про Memory barriers)
don-dron Автор
20.11.2021 17:42По просьбам трудящихся, обновил раздел про барьеры. Решил, что всё таки стоит немного углубится в кэши и очереди инвалидации, поскольку термин "обновление" кэша очень неоднозначный и вводит в заблуждение.
render1980
21.11.2021 21:16Спасибо, хорошо написано.
Небольшая ремарка. Вот на этой картинке https://habrastorage.org/r/w1560/getpro/habr/upload_files/5f4/81e/21c/5f481e21c932d0fcfab39e56977455c8.png варианты 3 и 4 полностью идентичны. Наверное, для варианта 4 имелось в виду: y=1 x=1 b=x a=y.
{kind=link}
gleb_l
Когда-то мы защищались только от прерываний и ПДП (CLI и блокировка шины). Потом начали защищаться от псевдопараллельных потоков в одном ядре (XCHG). С тех пор, как ядра получили локальные кеши, а порядок инструкций перестал быть определен - появились заборы. В результате определить мысленно минимально-достаточный способ блокировки стало очень сложно :)