
Длительная однообразная работа неизбежно вызывает приступы автоматизации. На этот раз предпримем попытку автоматизировать настройку устройств защиты электросетей напряжением 6 — 35 кВ.
Самозародившаяся задача требует расчёта коротких замыканий, а поскольку расчётов таких предвидится немало, выполнять их будем с помощью OpenCL, для должной утилизации имеющихся вычислительных мощностей.
Задача
Имеется участок электрической сети, приведённый на рисунке ниже. На схеме показана вся необходимя для решения информация.

На случай коротких замыканий, в сети имеются выключатели (обозначены □) и устройства релейной защиты. На каждый выключатель приходится по независимому устройству РЗ, никакого обмена информацией между ними не предусмотрено. Каждому устройству доступны для наблюдения: ток в месте установки, напряжение в месте установки и продолжительность короткого замыкания (с момента обнаружения). Каждому устройству доступно только одно действие — отключение своего выключателя. На основании наблюдений за локальными параметрами, устройства должны совместно: обнаружить замыкание, определить участок, на котором оно произошло, и ликвидировать, не отключая неповреждённые участки. При обоих, указанный на схеме, замыканиях (⚡) должен отключиться выключатель РК.
Для представленной схемы характерна защита с использованием единственного алгоритма — МТЗ (51 по ANSI С37.2). Имеет токовый орган обнаруживающий превышение током заданного порога и связанный с ним таймер, отключающий выключатель по достижении заданной выдержки. Порогов по току и таймеров может быть несколько.
Более сложные варианты тоже возможны, и должны учитываться.
Разрабатываемая программа должна самостоятельно:
- выбрать параметры, обеспечивающие корректную работу защитных алгоритмов во всех рабочих режимах заданной сети;
- при невозможности найти безупречное решение — найти решение с минимумом недостатков;
- сформировать карту уставок;
- сформировать документ с объяснениями выбранных значений;
- сформировать перечень недостатков в найденном решении с пояснениями как так вышло.
Надеяться, что результатом работы программы будет первый вариант, наивно. Принятие решений чем пожертвовать и оформление этих решений — существенная часть задачи.
Исходные данные задаются вручную. Теоретически, существуют базы данных оборудования и информация о конфигурации сети в электронном виде. Но, из известных мне, ни один такой источник не обладает необходимой полнотой и, тем более, работоспособным интерфейсом.
Результатом работы является документ предназначенный для человека. Автоматизация передачи параметров непосредственно устройствам возможна с технической точки зрения, но пока (или на совсем) не входит в задачу.
Расчёт электрических режимов
Решаемая проблема безусловно подразумевает необходимость выполнения расчётов режимов работы сети, как нормальных, так и аварийных. Эта задача определённо не относится к категории новых. Разработано множество алгоритмов и существует промышленное ПО (например www.pk-briz.ru).
Алгоритмы можно разделить на «аналитические» — составление системы уравнений сети и её решение. И итерационные — моделирующие поведение сети через поведение её элементов. Небольшая сеть может быть рассчитана любым способом, но я выбрал метод простых итераций по следующим причинам:
- очень простой алгоритм (всего 111 строк на OpenCL);
- нагляден, поскольку близок к физическому процессу;
- гарантированная сходимость (в отличие от некоторых);
- генерирует плавные переходы между режимами (не знаю зачем, но вдруг пригодится);
- работоспособен при наличии в сети нелинейных элементов.
Последний пункт становится с каждым годом актуальнее, поскольку в сети постепенно появляется оборудование с управляемыми параметрами (шунтирующие реакторы, инверторные электростанции и др).
Второй пункт упрощает отладку (с точки зрения электрика) и значительно уменьшает количество промежуточных преобразований данных. Алгоритм работает непосредственно на графе сети.
Недостаток у метода всего один:
- очень медленный способ расчёта электрических цепей.

Как видно на приведённой диаграмме, требуется около 20-и тысяч итераций для установления режима холостого хода после подачи напряжения.
Но есть у этого метода и компенсирующая особенность. Переход между близкими режимами выполняется значительно быстрее чем расчёт с нуля. Например, переход от короткого замыкания в узле ●Л1-4 к замыканию в узле ●Л1-3 требует только 4000 итераций. Эту особенность нужно будет учесть при определении порядка расчётов.
Кроме высокоуровневой проблемы вычисления режимов в сложнозамкнутой сети, есть и низкоуровневая проблема представления её элементов. Как известно, в базовый набор пассивных элементов входят: сопротивление, индуктивность и ёмкость. Поведение двух последних описывается дифференциальными уравнениями, что «несколько» усложняет вычисления.
К счастью, на этот случай существует метод комплексных величин, который приводит любой из трёх элементов или их комбинацию к одному — комплексному сопротивлению.
Все составляющие в нижней формуле являются комплексными числами, а потому требуют комплексной арифметики, но об этом ниже.
Такое существенное упрощение не проходит без потерь. Теряется возможности рассчитывать любые процессы, кроме синусоидальных с фиксированной частотой. Для большинства алгоритмов релейной защиты это подходит, но для некоторых потребуются дополнительные методы расчётов.
Алгоритм вычислений
Расчётная задача представлена в виде графа сети. Узлы являются точками соединения ветвей и имеют только по одному параметру — напряжению. Ветви представляют собой сопротивления между узлами и характеризуются протекающими в них токами.
Сначала моделируется поведение ветвей.

Затем моделируется поведение узлов.

Вопрос в какую сторону корректировать решается просто: если в узел втекают лишние токи, то здесь локальная «яма» и напряжение нужно поднять, если вытекают — опустить.
Величина на которую напряжение корректируется может быть, в некоторых пределах, произвольной — недостаточная корректировка будет исправлена последующими итерациями. Важно не допустить перерегулирования. Если изменение будет слишком большим, то на следующей итерации небаланс увеличится и начнутся колебания относительно искомой величины, возможно, что расчёт пойдёт в разнос.
Оптимальная (обеспечивающая максимально быстрое схождение без перерегулирования) величина пропорциональна току небаланса и сопротивлению окружающих ветвей. Учёт сопротивления важен, поскольку чем меньше сопротивление, тем большее влияние окажет корректировка на окружающую сеть.
Искомое сопротивление получается запараллеливанием прилегающих ветвей.
Упростить ситуацию позволяет переход от сопротивления к проводимости:
Недостатком является появление операции комплексного деления при вычислении компенсации. В узлах без ветвей возникает математическая неопределённость 0/0. С практической точки зрения такие узлы не интересны, но при подготовке данных их необходимо обнаруживать и отбрасывать.
Поочерёдное выполнение описанных двух шагов повторяется циклически до тех пор, пока небаланс по току в каждом узле не станет пренебрежимо мал.
Инструментарий

Lazarus/Free Pascal — разновидность Delphi для адептов свободного ПО. Работает не только под Windows и Linux, но и на Raspberry Pi.
Лися — самодельный диалект Lisp. Про него я рассказывал. Решения на нём уже используются в промышленных условиях (хи-хи).
OpenCL — кросплатформенный (во всех смыслах) язык программирования для параллельных вычислений. Используется версия 1.1.
Карандаш — простой, твёрдостью «Т», позволяет рисовать на бумаге.
OpenCL обладает эффективным компилятором, позволяет использовать векторные инструкции, и, главное, позволяет компилировать исходный код под GPU.
Лися требуется для составления заданий на расчёт, подготовки исходных данных и, на дальнейших этапах, формирования выходных документов. Расчётное ядро встроено в интерпретатор, и теперь язык поддерживает не только замыкания функций вокруг переменных, но и замыкания в электропроводке.
Lazarus/Free Pascal для реализации Host процесса.
Отступление про предыдущий подход к задаче
У создаваемой программы был прототип, написанный на Ada. В стандартную библиотеку языка входят комплексные числа и шаблоны матриц, что при объединении даёт возможность рассчитывать режимы перемножением комплексных матриц в одно выражение как показано в статье о методе узловых потенциалов.
Как было сказано ранее, такой подход не позволяет включать в сеть нелинейные элементы. Значительно затрудняет разработку необходимость перестройки матриц при каждом изменении режима или параметров сети.
Внутреннее представление электросети
Схема замещения сети может быть сведена к нескольким разновидностям элементов:
- простые сопротивления (линии электропередач, нагрузки, реакторы, конденсаторные батареи);
- сопротивления с утечками (высоковольтные линии электропередач);
- источники напряжения с их внутренними сопротивлениями (генераторы или шины питающих подстанций);
- трансформаторы с их внутренними сопротивлениями (трансформаторы).
Как можно заметить, все элементы имеют в своём составе сопротивление. В реальной сети не встречаются идеальные элементы. И это существенно упрощает реализацию задуманного метода.
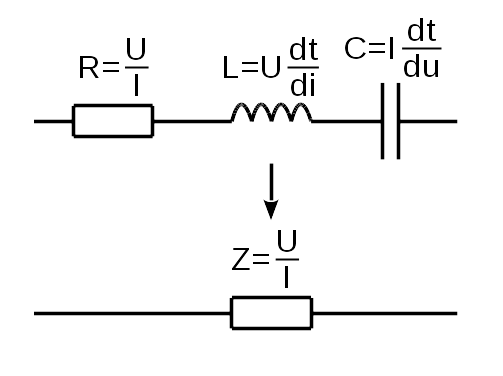
Дальнейшая унификация приводит к единственному универсальному элементу, описываемому четырьмя параметрами.

Все четыре параметра являются комплексными величинами, включая коэффициент трансформации.
Проводимость утечки Y условно показана в виде конденсатора поскольку, в основном, отражает наличие паразитной ёмкости на линиях электропередачи. В расчётной модели это комплексное число, позволяющее учитывать и активные потери.
Если требуемый элемент не имеет некоторых параметров, то для них задаётся нейтральное значение:
E = 0 — если элемент не является источником напряжения;
K = 1 — если элемент не является трансформатором;
Y = 0 — если элемент не имеет значительных утечек.
Следует отметить, что Z = 0 приводит к возникновению сингулярностей (деления на ноль) при расчёте. Что заставляет обратить внимание на ещё один элемент сети — выключатель.
Включенный выключатель имеет около нулевое сопротивление, что порождает проблему: бесконечно высокая проводимость приводит к бесконечно большим токам. Для решения этой проблемы есть два пути:
- топологический — анализ схемы и удаление из неё включенных выключателей, путём объединения узлов, прилегающих к выключателю;
- физический — если вспомнить, что идеальных элементов в реальной сети нет, то можно добавить в схему паразитное сопротивление выключателя.
Топологический подход позволяет снизить вычислительную нагрузку. Но поскольку на каждом выключателе установлена защита, измеряющая ток через него, требуется не только устранение ветви выключателя, но и поиск другой ветви с заведомо равным током, на которую можно пересадить защиту. Например, на рассматриваемой схеме сети можно устранить «В Ф1», а защиту подключить к ветви «Ф1». Но, к сожалению, не для всех конфигураций сети это так просто.
Физический подход вносит некоторую погрешность в расчёты, поскольку точное значение паразитного сопротивления неизвестно, но эта погрешность не велика ввиду малости сопротивления. Можно сделать предположение, что выключатели подключены к узлам сети ошиновкой длиной от нескольких метров до нескольких десятков метров, что даёт, как минимум, индуктивное сопротивление от 1 до 10 мОм.
Здесь стоит отметить, что проведённые опыты показали ярко выраженную зависимость скорости решения от сопротивления выключателей. Предпочтительно принимать максимальное значение исходя из компромисса между скоростью и вносимыми погрешностями. Это обстоятельство требует обратить, в будущем, внимание на топологический подход.
А пока будем использовать вариант с паразитными сопротивлениями.
В коде каждая ветвь представлена записью:
type
TArc = packed record
Yl: scomplex; //продольная проводимость (приведена к началу)
Yc: scomplex; //поперечная проводимость (приведена к началу)
K: scomplex; //коэффициент трансформации (в конце ветви)
E: scomplex; //ЭДС (приведена к началу)
I: scomplex; //сквозной ток
I_b: scomplex; //токи в начале и конце
I_e: scomplex; //с учётом поперечной проводимости
node1, node2: longint; //номера начального и конечного узлов
end;
OpenCL:
struct arc
{
float2 Yl;
float2 Yc;
float2 K;
float2 E;
float2 I;
float2 I_b;
float2 I_e;
int node1;
int node2;
};
Здесь, продольное сопротивление Z заменено продольной проводимостью Yl, как указано в разделе «Алгоритм вычислений». Поперечная проводимость (путь утечки) обозначена как Yc.
Кроме основных четырёх параметров предусмотрены поля I, I_e, I_b для результатов расчёта и индексы node1, node2 для указания на узлы подключения ветви.
Комплексные числа представлены записью scomplex = record re, im: single; end; со стороны хоста и вектором float2 = (float, float); стороны OpenCL.
Узлы сети представлены записями:
type
TNode = packed record
U: scomplex; //напряжение в узле
Y: scomplex; //сумма проводимостей прилегающих ветвей
I: scomplex; //небаланс токов в узле
end;
OpenCL:
struct node
{
float2 U;
float2 I;
float2 Y;
}; Узел сам по себе не имеет никаких параметров. Запись содержит поле U для результата вычислений и поля I и Y для хранения временных значений. Выделение места под временные переменные в основной структуре сети обусловлено невозможностью динамического выделения памяти при работе ядра написанного на OpenCL.
Double или Single
Как можно заметить в объявлениях типов, расчёт выполняется с использованием чисел одинарной точности. Free Pascal использует по умолчанию двойную точность, и библиотечный тип COMPLEX состоит из двух Double.
Посмотрим на параметры видеокарты, используемой при отладке.

Важное подчёркнуто красным. Подчёркнутое прозрачно намекает, что двойную точность использовать не стоит. Видеокарты не заточенные на вычисления предсказуемо не имеют 64-х битной арифметики. К счастью, при расчёте уставок требуется точность ±10% и про Double можно забыть со спокойной совестью.
Ещё одним очевидным плюсом Single является возможность уместить больше заданий в кэши (всех уровней) процессоров (всех типов).
Алгоритм реализованный на Pascal с использование Single показал снижение скорости (скорости, не времени!) в два раза по сравнению с идентичным кодом, работающим на Double. Ситуация Fail-Fail.
Реализация на Pascal
В первую очередь была создана версия вычислителя на Паскале.
procedure Solver1_clearNodes(var nodes: TNodes);
var n: integer;
begin
for n := 0 to high(nodes) do
with nodes[n] do
begin
I := 0;
Y := 0;
end;
end;
procedure Solver1_ArcCurrents(var nodes: TNodes; var arcs: TArcs);
var a: integer; u1, u2, u2_, du: complex;
begin
for a := 0 to high(arcs) do
with arcs[a] do
begin
u1 := nodes[node1].U;
u2 := nodes[node2].U;
u2_ := u2 * K - E;
dU := u1 - u2_;
I := dU * Yl;
I_b := I + u1*0.5*Yc;
I_e := K*(- I + u2*0.5*Yc);
nodes[node1].I := nodes[node1].I - I_b;
nodes[node1].Y := nodes[node1].Y + Yl + 0.5*Yc;
nodes[node2].I := nodes[node2].I - I_e;
nodes[node2].Y := nodes[node2].Y + K*K*(Yl + 0.5*Yc);
end;
end;
function Solver1_NodeVoltages(var nodes: TNodes): boolean;
var n: integer;
begin
result := true;
nodes[0].I := 0;
nodes[0].Y := 0;
for n := 1 to high(nodes) do
with nodes[n] do
begin
result := result and (abs(I.re)<1) and (abs(I.im)<1);
U := U + I/Y;
I := 0;
Y := 0;
end;
end;
procedure Solver1 (var nodes: TNodes; var arcs: TArcs;
iter: integer = 1000000);
var i: integer;
begin
Solver1_clearNodes(nodes);
for i := 0 to iter do
begin
Solver1_ArcCurrents(nodes, arcs);
if Solver1_NodeVoltages(nodes)
then
break;
end;
end;
Входные данные представляют из себя два плоских и однородных массива. Это хорошо, поскольку позволяет передать их в OpenCL двумя операциями копирования буфера, без дополнительных преобразований.
Data Parallel или Task Parallel
В документации на OpenCL описано два подхода к параллельным вычислениям. Для реализации этих подходов предложено две функции:
clEnqueueNDRangeKernel()
//и
clEnqueueTask()
Проанализируем алгоритм на предмет пригодности к Data Parallel.
u1 := nodes[node1].U;
u2 := nodes[node2].U;
u2_ := u2 * K - E;
dU := u1 - u2_;
I := dU * Yl;
I_b := I + u1*0.5*Yc;
I_e := K*(- I + u2*0.5*Yc);
// Обработка ветви сконцентрирована на единственном элементе
// -- идеальный случай.
nodes[node1].I := nodes[node1].I - I_b;
nodes[node1].Y := nodes[node1].Y + Yl + 0.5*Yc;
nodes[node2].I := nodes[node2].I - I_e;
nodes[node2].Y := nodes[node2].Y + K*K*(Yl + 0.5*Yc);
// При суммировании узловых токов начинается
// случайный доступ к памяти на запись
Можно добавить барьеров синхронизации, но это сводит на нет всю пользу параллельности. Проблему могла бы решить функция atomic_add() — атомарное сложение и запись, но в OpenCL 1.1 она работает только с целыми числами.
U := U + I/Y;
I := 0;
Y := 0;
// Корректировка напряжений в узлах
// Снова удобный для видеокарты код
result := result and (abs(I.re)<1) and (abs(I.im)<1);
// Совсем неудобная строчка
Информация о состоянии всех потоков должна быть свёрнута в единственный бит для проверки условия завершения итераций.
Не вышло.
Попробуем применить Task Parallel подход.
Реализация на OpenCL
Как ни удивительно, но в OpenCL не предусмотрены операции для работы с комплексными числами. Имеется возможность использовать векторные типы, поддерживающие поэлементные операции.
float2 a = (float2) (re, im); //инициализация
float2 z = a + b; // поэлементное сложение
//соответствует комплексному сложению
float2 z = a - b; // поэлементная разность
//соответствует комплексной разности
float2 z = a * 1; // поэлементное умножение на скаляр
//соответствует умножению комплекса на скаляр
float mod = length(a); //длина вектора
//соответствует модулю комплексного числа
На этом встроенный функционал заканчивается и оставшиеся операции потребуют ручной реализации.
// комплексное умножение
float2 cmul(float2 a, float2 b)
{
return (float2) ((a.x*b.x) - (a.y*b.y),
(a.x*b.y) + (a.y*b.x));
}
// комплексное деление
// монструозная функция
float2 cdiv(float2 a, float2 b)
{
if (fabs(b.x) > fabs(b.y))
{
float tmp = b.y / b.x;
float denom = b.x + b.y*tmp;
return (float2) ((a.x + a.y*tmp) / denom,
(a.y - a.x*tmp) / denom);
}
else
{
float tmp = b.x / b.y;
float denom = b.y + b.x*tmp;
return (float2) (( a.y + a.x*tmp) / denom,
(-a.x + a.y*tmp) / denom);
}
}
struct node
{
float2 U;
float2 I;
float2 Y;
};
struct arc
{
float2 Yl;
float2 Yc;
float2 K;
float2 E;
float2 I;
float2 I_b;
float2 I_e;
int node1;
int node2;
};
__kernel void tkz (int nodesNumber,
int arcsNumber,
__global struct node* pNode,
__global struct arc* pArc)
{
int global_id = get_global_id(0);
if (global_id > 0) return;
int i;
int a;
for (a=0; a<nodesNumber; a++)
{
pNode[a].I = 0;
pNode[a].Y = 0;
}
for (i=0; i<1000000; i++)
{
for (a=0; a<arcsNumber; a++)
{
int n1 = pArc[a].node1;
int n2 = pArc[a].node2;
//токи в ветвях
float2 K = pArc[a].K;
float2 u1 = pNode[n1].U;
float2 u2 = pNode[n2].U;
float2 u2_ = cmul(u2, K) - pArc[a].E;
float2 du = u1 - u2_;
float2 Yc = 0.5f*pArc[a].Yc;
float2 I = cmul(du, pArc[a].Yl);
float2 I_b = I + cmul(u1, Yc);
float2 I_e = cmul(K, cmul(u2, Yc) - I);
pArc[a].I = I;
pArc[a].I_b = I_b;
pArc[a].I_e = I_e;
//небалансы в узлах
pNode[n1].I -= I_b;
pNode[n1].Y += pArc[a].Yl + Yc;
pNode[n2].I -= I_e;
pNode[n2].Y += cmul(cmul(K,K), pArc[a].Yl + Yc);
}
pNode[baseNode].I = 0;
pNode[baseNode].Y = 0;
bool balanced = true;
for (a=1; a<nodesNumber; a++)
{
//условие завершения - отсутствие значительных небалансов в узлах
balanced = balanced && (length(pNode[a].I)<1.0f);
//корректировка узловых напряжений
pNode[a].U += cdiv(pNode[a].I, pNode[a].Y);
pNode[a].I = 0;
pNode[a].Y = 0;
}
if (balanced) break;
}
};
Хост-программа
Для упрощения работы была написана тонкая обёртка над OpenCL API, обрабатывающая коды ошибок и устраняющая необходимость передачи множества неиспользуемых параметров. Подробно описывать процесс инициализации и работу с OpenCL не буду. Отмечу лишь важные на мой взгляд детали.
Если буфер данных создан с флагом CL_MEM_USE_HOST_PTR и вычисления выполняются на CPU, то команды записи/чтения не требуются — ядро будет работать непосредственно с выделенной памятью.
Функции clEnqueueWriteBuffer() и clEnqueueReadBuffer() имеют параметр blocking_write, установка которого в CL_FALSE позволяет выполнять копирование буферов асинхронно с работой хост-программы.
Функции clEnqueueNDRangeKernel() и clEnqueueTask(), запускающие вычисления, такого параметра не имеет и работает всегда асинхронно.
Операции, добавленные в одну очередь, выполняются последовательно, если прямо не указано иное (ключ CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE при создании очереди).
Запуск вычислений осуществляется следующей последовательностью команд:
procedure TSolver.Run();
var nodesNumber, arcsNumber: cl_int;
begin
nodesNumber := Length(nodes);
arcsNumber := Length(arcs);
setArg(kernel, 0, SizeOf(nodesNumber), @nodesNumber);
setArg(kernel, 1, SizeOf( arcsNumber), @arcsNumber);
setArg(kernel, 3, SizeOf(nodes_buffer), @nodes_buffer);
setArg(kernel, 4, SizeOf( arcs_buffer), @arcs_buffer);
enqueueWriteBuffer(queue, nodes_buffer, SizeOf(TOCLNode)*nodesNumber, @nodes[0]);
enqueueWriteBuffer(queue, arcs_buffer, SizeOf(TOCLArc )* arcsNumber, @arcs[0]);
enqueueTask(queue, kernel);
enqueueReadBuffer(queue, nodes_buffer, SizeOf(TOCLNode)*nodesNumber, @nodes[0]);
enqueueReadBuffer(queue, arcs_buffer, SizeOf(TOCLArc )* arcsNumber, @arcs[0]);
end;
Для синхронизации хост-программы с очередью используется функция clFinish(). При её вызове программа блокируется до завершения выполнения задач в очереди.
procedure TSolver.WaitResult();
begin
finish(queue);
end;
Приведённый код ядра и хост-программы успешно работает при указании в качестве вычислительного устройства центрального процессора и видеокарты.
В однозадачном режиме явно лидирует процессор — 30 мс, против 1455 мс на видеокарте. Разница в 50 раз. Хм?
Data Parallel или Task Parallel (продолжение)
После успешного запуска единичной задачи можно приступить к параллельным вычислениям. На данном этапе ещё не выработана стратегия формирования задач, а потому просто запустим множество копий одной и той же задачи.
for i := 0 to n - 1 do solvers[i] := TSolver.Create(nodes, arcs);
for i := 0 to n - 1 do solver[i].Run();
for i := 0 to n - 1 do solver[i].WaitResult();
Приведённый код выполняется за время приблизительно равное 1455*n мс независимо от значения n. Странное совпадение наводит на мысли о последовательном выполнении.
Раз не работает, то придётся почитать документацию.
"Some devices of compute capability 2.x can execute multiple kernels concurrently. "
Судя по слову «some» в начале, рассчитывать на работу множества задач не стоит, тем более, что у меня «compute capability» ≈ 2.1.
Ещё почитаем документацию.
"It is difficult to get more than 4 kernels to run concurrently"
Похоже вариант с параллельным запуском стоит отложить в долгий ящик.
При запуске на Phenom II X6 (шесть ядер), задания тоже выполняются последовательно. Подозревать CPU в отсутствии многозадачности странно. По видимому, мне уже пора обновить свой Debian до чуть менее старого, и провести тесты на оборудовании поновее.
В любом случае kernel у меня всего один. Попытаемся представить множество задач как одну с множеством наборов данных. Для этого копируем блоки исходных данных последовательно в один буфер узлов и один буфер ветвей. Каждый экземпляр ядра (work-item) на основании полученного номера (global_id) выделяет из общих буферов свои участки и далее его работа не отличается от предыдущего варианта.
Окончательный вариант ядра, как и сказано ранее, в 111 строк вместе с комментариями.
//комплексное умножение
float2 cmul(float2 a, float2 b)
{
return (float2) ((a.x*b.x) - (a.y*b.y),
(a.x*b.y) + (a.y*b.x));
}
//комплексное деление
float2 cdiv(float2 a, float2 b)
{
if (fabs(b.x) > fabs(b.y))
{
float tmp = b.y / b.x;
float denom = b.x + b.y*tmp;
return (float2) ((a.x + a.y*tmp) / denom,
(a.y - a.x*tmp) / denom);
}
else
{
float tmp = b.x / b.y;
float denom = b.y + b.x*tmp;
return (float2) (( a.y + a.x*tmp) / denom,
(-a.x + a.y*tmp) / denom);
}
}
struct node
{
float2 U;
float2 I;
float2 Y;
};
struct arc
{
float2 Yl;
float2 Yc;
float2 K;
float2 E;
float2 I;
float2 I_b;
float2 I_e;
int node1;
int node2;
};
__kernel void tkz (int nodesNumber, int arcsNumber, int tasksNumber,
__global struct node* pNode, __global struct arc* pArc)
{
int global_id = get_global_id(0);
if (global_id >= tasksNumber) return;
int i;
int a;
int baseNode = nodesNumber * global_id;
int baseArc = arcsNumber * global_id;
for (a=baseNode; a<(baseNode+nodesNumber); a++)
{
pNode[a].I = 0;
pNode[a].Y = 0;
}
for (i=0; i<1000000; i++)
{
for (a=baseArc; a<(baseArc+arcsNumber); a++)
{
int n1 = pArc[a].node1 + baseNode;
int n2 = pArc[a].node2 + baseNode;
//токи в ветвях
float2 K = pArc[a].K;
float2 u1 = pNode[n1].U;
float2 u2 = pNode[n2].U;
float2 u2_ = cmul(u2, K) - pArc[a].E;
float2 du = u1 - u2_;
float2 Yc = 0.5f*pArc[a].Yc;
float2 I = cmul(du, pArc[a].Yl);
float2 I_b = I + cmul(u1, Yc);
float2 I_e = cmul(K, cmul(u2, Yc) - I);
pArc[a].I = I;
pArc[a].I_b = I_b;
pArc[a].I_e = I_e;
//небалансы в узлах
pNode[n1].I -= I_b;
pNode[n1].Y += pArc[a].Yl + Yc;
pNode[n2].I -= I_e;
pNode[n2].Y += cmul(cmul(K, K), pArc[a].Yl + Yc);
}
pNode[baseNode].I = 0;
pNode[baseNode].Y = 0;
bool balanced = true;
for (a=baseNode+1; a<(baseNode+nodesNumber); a++)
{
//условие завершения - отсутствие значительных небалансов в узлах
balanced = balanced && (length(pNode[a].I)<1.0f);
//корректировка узловых напряжений
pNode[a].U += cdiv(pNode[a].I, pNode[a].Y);
pNode[a].I = 0;
pNode[a].Y = 0;
}
if (balanced) break;
}
}
Управление вычислениями
Для управления созданным в Лисю было добавлено несколько функций.
; Вывод перечня имеющихся устройств
(print nil (opencl:platforms))
; Считать будем на видеокарте
(opencl:processor "GeForce")
; Предупреждение!
; Далее следует код написанный на русском языке кириллицей
; Узел не имеет никаких параметров кроме имени
(ТКЗ:УЗЕЛ "Г")
(ТКЗ:УЗЕЛ "ВН")
(ТКЗ:УЗЕЛ "НН Т1")
(ТКЗ:УЗЕЛ "1С")
; ...
; Генератор, указано сопротивление и ЭДС
(ТКЗ:ВЕТВЬ "Г1" "земля" "Г" :Z 0+i1 :E (/ 37k sqrt3))
; ЛЭП - только сопротивление
(ТКЗ:ВЕТВЬ "ВЛ 35" "Г" "ВН" :Z 7.5+i10)
; Трансформатор - сопротивление и коэффициент трансформации
(ТКЗ:ВЕТВЬ "Т1" "ВН" "НН Т1" :Z 0+i12,5 :K 3.333∠330˚)
; Выключатель, задано минимальное сопротивление
(ТКЗ:ВЕТВЬ "В Т1" "НН Т1" "1С" :Z 0.001+i0.01)
; Короткое замыкание. На данный момент специального
; механизма задания КЗ нет, поэтому просто ветвь
; между узлом и землёй имеющая минимальное сопротивление.
(ТКЗ:ветвь "КЗ1" "Л1-4" "земля" :Z 0.001)
; ...
; Запуск вычислений
(ТКЗ:вычислить)
; Не закрывать программу без реакции пользователя
REPL
; Здесь недоработка - русского синонима этой команды нет
; ЧВПЦ?
Бенчмарк
На, приведённой в начале, схеме имеется 13 коммутационных аппаратов + два режима работы источника питания (максимальный и минимальный). Имеется 26 узлов и 10 участков ЛЭП, на каждом из которых могут быть множество (например 10) замыканий в промежуточных точках. Это даёт:
| 213+1 | 16 384 | режимов |
| 26 | 26 | замыканий в узлах |
| 10*10 | 100 | замыканий в промежуточных точках |
| 16 384 * (26 + 100) | 2 064 384 | расчёта сети нужно выполнить |
Посмотрим что у меня имеется на этом компьютере. Команда, приведённая в предыдущем разделе возвращает
> (opencl:platforms)
=
(("NVIDIA CUDA"
"GeForce GT 430")
("AMD Accelerated Parallel Processing"
"AMD Phenom(tm) II X6 1075T Processor"))
Очень «мощная» конфигурация.
Посмотрим на зависимость времени выполнения от количества задач.
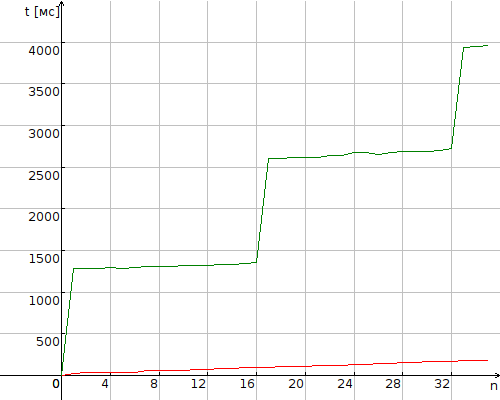
Процессор (красный), многократно быстрее видеокарты (зелёный).
На графике видны характерные ступеньки с интервалом в 16 задач. При просмотре спецификаций обращает на себя внимание совпадение этой цифры с количеством текстурных блоков.

Дальнейшее чтение документации показало, что архитектура Fermi не допускает более 8-и рабочих групп на один «мультипроцессор». В моём случае рабочая группа состоит из одной задачи (потока), что в сочетании с конигурацией 2 SM * work-group и даёт 16 потоков. Текстурные блоки ни при чём.
Фиктивное объединение задач в рабочие группы по 32, путём задания параметра local_size функции clEnqueueNDRangeKernel() позволило удвоить производительность, но до «паспортных» 96-и потоков остаётся далеко. Требуется более тщательная оптимизация.

Процессор, в свою очередь, имеет предсказуемые ступеньки на числах кратных количеству ядер.
При росте количества задач процессор сходится на цифре 4 мс/задачу, видеокарта — 84 мс/задачу.
| Одна задача | Множество задач | Ожидаемое время решения | |
|---|---|---|---|
| Pascal c Double Phenom II X6 1075t |
120 мс | 24 мс/задачу | 14 ч |
| Pascal c Single Phenom II X6 1075t |
240 мс | 48 мс/задачу | 28 ч |
| Pascal c Single Ryzen 5 3600 |
151 мс | 30 мс/задачу | 17 ч |
| OpenCL Phenom II X6 1075t |
30 мс | 4 мс/задачу | 2,4 ч |
| OpenCL GeForce GT 430 |
1455 мс | 41 мс/задачу | 24 ч |
| OpenCL GeForce GTX 1650 |
275 мс | 2,2 мс/задачу | 1,3 ч |
Процессор, вероятно, не сможет долго работать под полной нагрузкой и упрётся в TDP или охлаждение.
Видеокарта при запуске вычислений перестаёт выполнять основную функцию и изображение на экране застывает, с этой точки зрения запуск на рабочем компьютере достаточно неудобен.
Итого
Токи КЗ получены.
AMD Phenom(tm) II X6 1075T Processor
Память: 2440 Б
U I Y
0 ∠ 0° 0 ∠ 0° 0.000 земля
21208 ∠ 0° 0 ∠ 0° 0.000 Г
18369 ∠ -2° 0 ∠ 0° 0.000 ВН
5308 ∠ -5° 0 ∠ 0° 0.000 НН Т1
5308 ∠ -5° 0 ∠ 0° 0.000 НН Т2
5306 ∠ -5° 0 ∠ 0° 0.000 1С
5304 ∠ -5° 0 ∠ 0° 0.000 2С
5306 ∠ -5° 0 ∠ 0° 0.000 ВН ТСН1
212 ∠ -5° 0 ∠ 0° 0.000 НН ТСН1
5306 ∠ -5° 0 ∠ 0° 0.000 Ф1-0
5306 ∠ -5° 0 ∠ 0° 0.000 Ф1-1
5306 ∠ -5° 0 ∠ 0° 0.000 Ф3-0
5306 ∠ -5° 0 ∠ 0° 0.000 1С РП
5306 ∠ -5° 0 ∠ 0° 0.000 Н3-0
5304 ∠ -5° 0 ∠ 0° 0.000 Ф4-0
5304 ∠ -5° 0 ∠ 0° 0.000 2С РП
5304 ∠ -5° 0 ∠ 0° 0.000 Н4-0
5299 ∠ -5° 0 ∠ 0° 0.000 Ф2-0
4427 ∠ -7° 0 ∠ 0° 0.000 Ф2-1
3430 ∠ -8° 0 ∠ 0° 0.000 Ф2-2
3425 ∠ -8° 0 ∠ 0° 0.000 Л1-0
1171 ∠ -9° 0 ∠ 0° 0.000 Л1-1
1171 ∠ -9° 0 ∠ 0° 0.000 Л1-2
48 ∠ -32° 0 ∠ 0° 0.000 Л1-3
1 ∠ -42° 0 ∠ 0° 0.000 Л1-4
5304 ∠ -5° 0 ∠ 0° 0.000 ВН ТСН2
212 ∠ -5° 0 ∠ 0° 0.000 НН ТСН2
Z Y [мкСм] K E I
1.0 ∠ 90° 0 ∠ 0° 1.0 ∠ 0° 21362 ∠ 0° 233 ∠ -41° Г1
12.5 ∠ 53° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 233 ∠ -41° ВЛ 35
12.5 ∠ 90° 0 ∠ 0° 3.3 ∠ 0° 0 ∠ 0° 88 ∠ -41° Т1
7.7 ∠ 90° 0 ∠ 0° 3.3 ∠ 0° 0 ∠ 0° 145 ∠ -41° Т2
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 295 ∠ -41° В Т1
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 483 ∠ -41° В Т2
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 297 ∠ -42° СВ
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 96° В ТСН1
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 96° В Ф1
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 1 ∠ 108° В Ф3
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 1 ∠ 119° В Ф4
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° В Ф2
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 126° В ТСН2
24.0 ∠ 90° 0 ∠ 0° 25.0 ∠ 0° 0 ∠ 0° 0 ∠ 128° ТСН1
37.5 ∠ 90° 0 ∠ 0° 25.0 ∠ 0° 0 ∠ 0° 0 ∠ 91° ТСН2
9.6 ∠ 39° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 179° Ф1
0.5 ∠ 11° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 113° Ф3
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 141° В Н3
0.5 ∠ 11° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 113° Ф4
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 59° В Н4
1.1 ∠ 45° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° Ф2/1
1.3 ∠ 39° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° Ф2/2
0.0 ∠ 84° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° РК
2.9 ∠ 34° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° Л1/1
0.1 ∠ 9° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 0 ∠ 176° Л1/2
1.4 ∠ 34° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° Л1/3
0.1 ∠ 9° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° Л1/4
0.0 ∠ 0° 0 ∠ 0° 1.0 ∠ 0° 0 ∠ 0° 781 ∠ -42° КЗ1
Выполнено за 30 мс
>
Есть странности в поведении видеокарты, которые требуют вникнуть несколько глубже.
Полученная производительность достаточна для решения поставленной задачи, даже при использовании довольно старого оборудования.
Можно приступать к следующему шагу.
Следующий шаг — разбивка сети на зоны защиты.
Комментарии (17)


mechanicmind
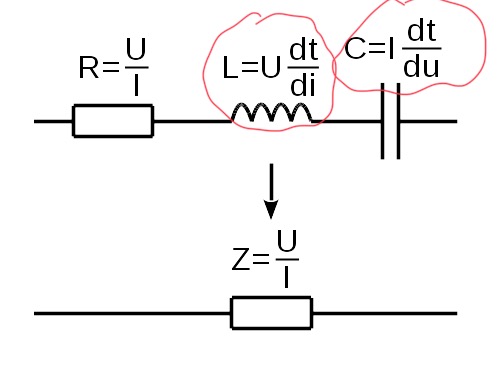
21.11.2021 11:45Как это понимать?
andrey_ssh Автор
21.11.2021 11:55Как иллюстрацию сравнительной сложности вычислений.
С физической точки зрения:
если подать фиксированное напряжение, то можно увидеть, что индуктивность пропорциональна "медленности" нарастания тока;
если подать фиксированный ток, то можно увидеть, что ёмкость пропорциональна "медленности" нарастания напряжения.
где "медленность" - величина обратная скорости.
С практической - просто вывернул уравнения ёмкости и индуктивности в нестандартный вид, чтобы на картинке лучше смотрелись.
mechanicmind
21.11.2021 13:17Да, но вы же понимаете, что с физической точки зрения запись абсолютно некорректна. Даже если бы вы хотели просто «перевернуть» производную.
andrey_ssh Автор
21.11.2021 14:35Нет, не понимаю.
Допустим, у нас есть индуктивность неизвестного номинала и источник известного напряжения. Мы подключаем одно к другому и всё вместе к осциллографу. Получаем зависимость тока от времени.
Как, на Ваш взгляд, можно определить номинал индуктивности?

kovserg
21.11.2021 15:44Вам просто хотят сказать что ток зависит от времени, а не время от тока. И записть dt/dI вызывает небольшой диссонанс, и хотят там видеть 1/(dI(t)/dt). Хотя если трактовать как предел приращения времени к приращению тока, то ничего криминального в этом нет.
mechanicmind
22.11.2021 20:38Как коэффициент пропорциональности между током и магнитным потоком, каковым он всегда и был в этом контексте.


FGV
21.11.2021 16:31а зачем монструозная функция деления комплексных чисел? не проще ли через домножение на комплексно сопряженное b в пару строк все записать:
float div = b.x*b.x+b.y*b.y;
return (float2)((a.x*b.x+a.y*b.y)/div,(-a.x*b.y+a.y*b.x)/div);andrey_ssh Автор
21.11.2021 17:24Разница не очень большая. Приведённый алгоритм имеет пояснение:
"The following algorithm is used to properly handle denominator overflow"
Скорее всего Вы правы. Деление в алгоритме только одно и можно заранее выяснить будет переполнение или нет.
Упрощённая версия не имеет условного перехода и должна лучше ложиться на SIMT инструкции, которыми страдает видеокарта.
Позднее я попробую это проверить.
iwnw
21.11.2021 18:53Я что-то не понимаю цель всей этой деятельности.
Вы хотите посчитать токи КЗ? ОК, есть множество проверенных на практике программ: EnergyCS ТКЗ, АРМ СРЗА, RastrWin, более сложные и «навороченные» комплексы вроде PSCAD или DigSilent Power System. Берете и применяете. Такая схема, как у вас — вообще не вопрос. Возможно, даже демо-версия справится.
Или нужно что-то бесплатное и свое?andrey_ssh Автор
22.11.2021 06:25Цель - посчитать уставки в полностью автоматическом режиме:
показал схему --> забрал карту уставок.
Берете и применяете.
Не. В реальности это выглядит как то так:
платите, платите за совместимое оборудование и ПО, берёте, решаете проблемы с DRM, заводите и поддерживаете реестр лицензий, пытаетесь применить, доплачиваете за опции и применяете.
Это проверка концепции и самообразовательный проект. Ну, и немного опенсурса пора принести в эту область, засиженную коммерческими лицензиями.
iwnw
22.11.2021 08:53А, ну то есть все-таки хочется изобрести свой велосипед.
Что ж, пробуйте. Задача решаема :)

propell-ant
22.11.2021 13:37У вас расчет запустится на линуксе, так ведь?
Я посмотрел ценник на облачные вычисления, 0.0168 доллара за машино-час на 2 виртуальных ядра (шесть ваших физических ядер работают как 12 виртуальных), частота 2.5GHz.
Весь расчет в течение 14 часов на 6 ядрах стоит 0.0168х14х6х(3/2.5)=3,38 доллара, это чуть менее 240р.
В облаке можно поднять любое количество машин, просто старт-стоп тоже придется оплачивать и запускать расчет на одну минуту может оказаться неоптимально по деньгам.
Я не знаю, насколько для вас приемлемо заплатить 300р. за выполнение расчета за 10 минут вместо 14 часов, но как вариант - рассмотрите.
Если что, пишите в личку, помогу советом.andrey_ssh Автор
22.11.2021 18:10GeForce GTX 1650 осиливает задачу, за 1,3 часа. Так что, пока смысла переходить в облака нет.
Но для общего развития хотелось бы спросить:
Сталкивались ли с облачными видеокартами?
Есть провайдеры, которые позволяют установить в виртуалку любой компилятор (Free Pascal например) и запускать собранное им?. Когда я интересовался в последний раз этой темой предлагался фиксированный набор ПО.
Описанная программа в основном под линукс и собирается.
propell-ant
23.11.2021 13:41Это специфическое направление, я не работал с GPU в облаке. Знаю что сейчас все ведущие провайдеры предлагают инстансы с GPU: AWS, GCP, Azure, Яндекс.
Я не сталкивался с ограничениями на установку опенсорс-софта на инстансы. Набиваете шаблон и стартуете когда вам нужно и сколько вам нужно.
Лет десять назад приходилось видеть подход "вот разрешенные загрузочные образы, если вам чего-то не хватает - звоните", но сейчас этого нет.
судя по поисковой выдаче, Free Pascal доступен даже как serverless на AWS. Вряд ли он будет подключен к GPU, но это может сгодиться.
kovserg
Можно глупый вопрос?
А нельзя все узлы скопировать из __global в __local и там делать кучу итераций, или не влазит?
andrey_ssh Автор
Я наивно надеялся, что видеокарта будет использовать локальную память как кэш, и после первого прохода скопирует данные в неё.
Если скопировать данные в __local вручную, то это действительно ускоряет работу одиночной задачи в два раза. Но для множества задач это требует написания кода распределяющего память между задачами, и учитывающего размеры памятей используемых устройств. Неоправданное усложнение и кросплатформенность теряется.