

В разработке цветет культ Карго. Многие полагаются на слова, которые сказал уважаемый автор десятки лет назад. Продолжают разрабатывать код, опираясь на подходы, которые либо не актуальны, либо сам автор поменял свою точку зрения. И сегодня мы поговорим о некоторых распространенных принципах программирования, которые не так однозначны как может показаться.
Меня зовут Кирилл Мокевнин и я — сооснователь школы программирования Хекслет. За последние пару лет я провел собеседования с более чем 400 человек, потенциальными наставниками по совершенно разным направлениям в разработке. В результате у меня собралась большая выборка наблюдений, которые мы разберем ниже.
Редакторы
Для развития экосистемы не очень круто, что каждая IDE сама реализует все фичи под каждый язык. Вендоры не хотят делиться этим с сообществом и разрабатывают механизмы для анализа и работы с кодом внутри себя. И если кто-то делает свой собственный редактор, то для поддержки языков ему приходится писать всё практически с нуля, особенно тяжелые фичи.
Не все знают, что недавно в мире редакторов произошла революция. Раньше было четкое разделение на IDE (которые дают рефакторинг, autocomplete, подсказки, документацию и запуск кода) и обычные редакторы, которые дают подсветку и небольшой набор базовых возможностей, типа перехода по файлам. Но какое-то время назад всё изменилось.
LSP (Language Server Protocol)
По-другому, это, как ни странно, реализовала Microsoft. Хотя миф, что Microsoft — ребята не очень, существует до сих пор. Но с точки зрения Open Source они — номер один в мире по количеству продуктов. Я уж не говорю о том, что им принадлежит GitHub.
Microsoft сделала LSP — спецификацию, про которую знает пока не так много людей. Понятно, зачем в Microsoft это сделали — они хотят, чтобы их среда и технологии распространялись, поэтому им выгодно делать это бесплатно. И тем не менее.
LSP — это стандарт, который определяет, как должен быть написан сервер, отвечающий за анализ и изменение кода. Такой сервер не связан с редактором, он пишется независимо. Единственное, что требуется от редакторов — встроить возможность общаться с таким сервером.

Если раньше поддержку языков писали под каждый редактор, то сейчас на GitHub есть открытые имплементации LSP и они работают абсолютно со всеми редакторами. На самом деле это серьезная вещь и она полностью изменила ландшафт. Например, теперь очень просто создать собственный редактор с сумасшедшими возможностями.
Более того, для современных языков (Rust, Swift, TypeScript) уже не делают специализированных IDE и даже плагинов к существующим. На том же GitHub разработчики этих языков сразу декларируют, что будут делать реализацию LSP, чтобы вы сами могли подключить поддержку языка в ваш любимый редактор.
Это уже поддерживают Apple, Microsoft и Mozilla — и рано или поздно мы получим все возможности IDE в любом редакторе. Для примера — мой редактор Vim.
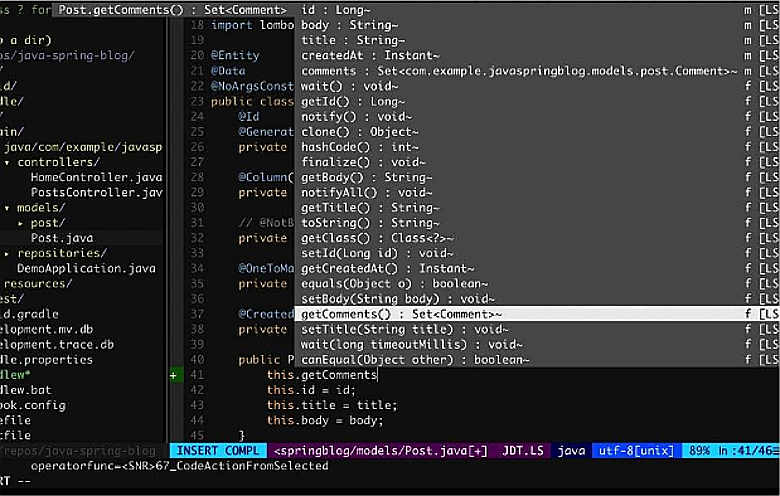
Видно, что здесь есть умный autocomplete: он знает не только про класс и стандартную Java, но и Lombok. Сверху есть аннотации, Vim всё подсказывает и подсвечивает. Кроме того, есть еще рефакторинг, организация импортов, проваливание, дизассемблирование и много других вещей. Может быть, это не так симпатично, как в IDE, но очень эффективно. А достигается всё это благодаря LSP.
Благодаря этому сейчас начинается узкоспециализированный бум: на GitHub можно увидеть множество новых редакторов, потому что они из коробки получают поддержку всех популярных языков.
Разработка
В разработке существуют не то чтобы мифы, но многие думают, что можно делать только так, а не по-другому.
Ритуалы
Я специально назвал это ритуалами — люди часто что-то выполняют, не задумываясь, потому что другого просто не видели. Например, синхронные митинги, когда надо всем в одно и то же время созвониться и рассказать, кто и что сделал. Подобные митинги часто превращаются в обычную отчетность.
То же самое происходит со спринтами и деплоями. Например, я знаю людей, у которых спринт идет две недели, и деплой почему-то тоже раз в две недели. При этом в скраме нет требования привязывать деплой к концу спринта. В идеале, нужно деплоиться каждый день, независимо ни от чего, потому что с точки зрения бизнеса Time To Market — это самая главная вещь. Когда вы выкатываете сразу множество фич, сложно оценить, что на что повлияло и к чему все это приведет. При этом всем очень важно считать — все хотят понять, что происходит и оценивают, оценивают и оценивают...
Все подобные ритуалы приводят к проблемам, которых без них бы не было. Укладываться в спринтах в срок не то чтобы невозможно, а чаще всего не нужно. Это выдуманная проблема, которая не только приводит разработчиков к стрессу, но даже разборки после спринта провоцирует. «Почему мы не успеваем, давайте на 3,14 умножать! У нас есть коэффициенты? А, их же нельзя, персональной ответственности нет — мы, как команда, зафейлили…»
Но всё возможно совсем по-другому:
Деплой в любой момент, хоть 5 раз в день;
Задачи по мере поступления;
Асинхронные дейли;
Отсутствие оценок.
Всё это применяется и у нас в Хекслете. При этом сейчас мы стали использовать множество ботов для тех же дейли.
Код ревью и фича-ветки
Все сталкиваются с долгими фича-ветками и блокирующими код ревью. Все не упускают случая пожаловаться, что фича-ветку ребейзят и мержат в мастер пять дней и всей командой, а на код ревью надо пятерых уговаривать, и у них все равно нет времени.
Хотя на самом деле возможно по-другому:
Неблокирующее ревью;
Короткие ветки;
Прямо в мастер (хотя сейчас уже надо говорить main).
Делать неблокирующее ревью через маленькие изменения позволяет подход Trunk-based Development. Многие программисты не всегда осознают, что изменения могут быть небольшими — они уверены, что их фича не бьется. Но если проверить, то почти всегда это возможно: ведь глобальные изменения, которые затрагивают всё, и их нельзя поэтапно накатывать, бывают достаточно редко.
Благодаря маленьким изменениям практически всё можно делать сразу в main. При таком подходе даже если вы что-то напишете не так, то быстро и легко сможете это поправить.
Есть еще дополнительный бонус от такого подхода. Когда программист что-то долго пишет и где-то в начале уходит не туда, он может идти не туда целую неделю и даже больше. В результате накопленный негативный эффект будет слишком большой. Но если бы он вливал в main очень маленькими кусочками, то вы бы намного раньше увидели, что он пошел не в ту сторону, и поправили это.
Понятно, что это работает не везде, и что это связано с культурой компании. Но у нас это работает — и мы требуем ветки только от новичков.
Качество
В некоторых командах количество тестировщиков зашкаливает: их больше, чем программистов. Есть компании у которых по 5 стейджингов, и иногда это действительно бывает оправдано. Но на самом деле в современном мире может быть по-другому:
Нет тестировщиков
Нет стейджинга
От стейджинга отказываются из-за того, что существуют флаги включения фич, канареечные релизы и другие подходы, которые позволяют минимизировать ошибки и сделать так, чтобы они проявлялись на небольшом количестве людей, либо только внутри продукта. Года 2-3 назад было много статей на тему, как большие компании типа Airbnb и Spotify отказались от стейджингов и почему.
В Booking работают несколько тысяч разработчиков и у них вообще нет отдела тестирования. Да, они используют жесткие маркетинговые приемы, можно их за это не любить. Но с точки зрения инженерной культуры они довольно продвинутые ребята. Например, они очень хорошо считают деньги и, если у них появляются баги, то они сразу же понимаю, сколько теряют.
Однажды они решили, что могут потерять $100 тыс. в месяц. Назвали это RND — как бы деньги на исследования. И если в конце месяца они не были потеряны из-за ошибок программистов, CEO писал письмо типа: «Ребята, мы были слишком консервативны в этом месяце и замедлили движение вперед. Давайте в следующем месяце сделаем все поинтересней, потому что иначе мы остановимся в развитии». Но когда они переходили через эту цифру, их просили немного успокоиться и замедлиться, не так сильно экспериментировать.
Если мы делаем баги, то в нормальной разработке это означает, что мы на что-то не обращаем внимания, зато двигаемся и развиваемся очень быстро. Если у нас багов нет, то почти всегда это связано с консервативным подходом к разработке — то есть она очень длительная.
В Booking поменяли негатив на позитив. Подход интересный, и, с моей точки зрения, за ним скрывается очень важная вещь: самое главное — это мониторинг. Ведь вы никогда в жизни не добьетесь того, чтобы у вас совсем не было ошибок. Но если у вас отличный мониторинг, разделение и все эти подходы, о которых я говорю, то не принципиально, как и что вы делаете. Вы всегда можете откатиться, поправить всё, и продолжить двигаться с высокой скоростью.
Пирамида тестирования
Это моя любимая тема. Все знают про пирамиду тестирования Фаулера: если спросить про тесты, большинство сразу говорит, что пишут юнит-тесты.
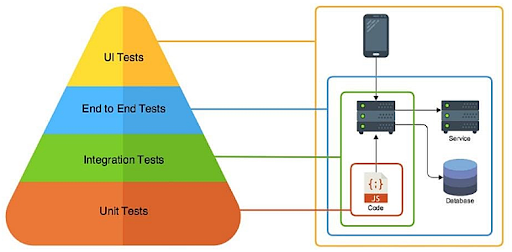
Это очень фанатическая история, относящаяся к тому, что надо писать. Особенно часто я это встречаю, когда собеседую Java-разработчиков. В книгах, в документации Spring, в статьях, везде — только и разговоров, что о unit-тестах.
Я сам в тестировании много чего повидал и много как тестировал. Но вы же знаете, что мир меняется? Например, в 2008 году Kent Beck сказал: «I get paid for code that works, not for tests, so my philosophy is to test as little as possible to reach a given level of confidence...». В 2019 году он же написал про принципы тестирования, но многие люди, которые высказываются за юнит-тесты, до сих пор на него ссылаются. Хотя он уже давно переосмыслил tdd, и даже написал в Фейсбуке, что попробовал Haskell и изменил своё отношение к тестам.
Бережливое тестирование
К счастью, подходы все-таки меняются, это хорошо видно во фронтенде. Например, появилось новое веяние — бережливое тестирование.
Основная цель тестов — сделать так, чтобы наше приложение работало, а не заниматься тестами. В этом я абсолютно солидарен с Кентом Беком 2019 года, который предложил писать как можно меньше тестов, но так, чтобы мы покрывали как можно больше функциональности.
Понятно, что E2E тесты всё это могут, но они сложные и дорогие в написании. Это не ежедневные тесты, которые надо писать разработчикам. Их чаще пишут тестировщики — и это правильно.
Но если посмотреть на фронтенд, теперь всё крутится вокруг интеграционных тестов. Благодаря Kent C. Dodds и Guillermo Rauch появилась концепция «Testing Trophy», в которой этот факт подчеркивается. Тот же React Testing Library придерживается жесткой позиции, что хватит уже лазить внутрь, всё должно работать независимо от того, React у вас или нет.
Понятно, что иногда нужны юнит-тесты, а иногда — какие-то другие тесты. Но идеальный тест — если функционально ваш код не поменялся, то и тест не сломается. Если тесты ломаются — значит вы увлекаетесь мокингом или слишком глубоко лезете в кишки. Я много раз видел, как люди сначала всё покрывали юнит-тестами, а когда начинался рефакторинг — выкидывали их, потому что эти тесты ничем не могли им помочь.
С бэкендом похожая история. Тестируем интеграцию, а детали реализации сейчас мало кого волнуют. Главное чтобы у вас системы друг с другом работали.

В заключение темы разработки я задам короткий вопрос: «Замедляют ли тесты разработку?». Я даже провел небольшой опрос в Твиттере — половина опрошенных ответили, что нет, а в комментариях объяснили, что тесты наоборот, разработку ускоряют.
Все зависит от того, про какие тесты мы говорим. Чаще всего это упирается в умение писать тесты, а, как ни странно, их умеют писать далеко не все. Например, все ли понимают хотя бы разницу между моками и стабами, если моками называют то, что ими не является, или их пишут там, где не надо? Посмотрите на моем канале видео, я там рассказывал про эту тему.
ООП
Это отдельная большая тема, поэтому сегодня остановимся только на некоторых интересных особенностях.
Полиморфизм
Когда я разговариваю с людьми об этом, то очень многие удивляются, что существует несколько видов полиморфизма (а их вообще много). Во-вторых, когда начинаешь копать, то выясняется, что все хорошо знают определение, но довольно слабо понимают, где это можно и нужно использовать, почему это надо и какие проблемы решает.
Я провел еще один опрос в Твиттере:

Только половина ответила правильно. Это грустно, потому что полиморфизм в ООП наиболее сильно влияет на структуру кода (Бенджамин Пирс в ТАПЛ выделяет полиморфизм подтипов как основную фишку современного мейнстримового ООП).
Если взять навскидку несколько паттернов — Null Object, Strategy, Adapter, Decorator, Composite, Proxy, State — все это просто разновидности применения полиморфизма. Но если вы знаете полиморфизм и понимаете его, вам эти паттерны и знать не надо. Вы и так будете понимать, в какой момент и как их можно применить.
Принципы SOLID
Еще одна прекрасная вещь в ООП — SOLID. Тут вообще надо знать историю, откуда SOLID взялся и почему эти принципы так получились.
Самый забавный принцип здесь — Liskov. Как часто в жизни вы про него вспоминаете? Как он вообще на архитектуру вашего кода влияет? Этот принцип абсолютно правильный, но он нужен для редких кейсов, я бы даже сказал — для специфических языков. Но армия программистов следует за Робертом Мартином, который не только сейчас на Clojure пишет, но и давным-давно отдал предпочтение динамической типизации, пересмотрев свое отношение к возможностям языков. Почитайте его блог. Он писал на Ruby, перешел на Clojure, и вообще на днях написал, что это будет его последний язык.
Про Лисков. В своей статье про SOLID он сказал: «People (including me) have made the mistake that this is about inheritance. It is not. It is about sub-typing». В принципе в Liskov нет ни слова про классы или наследование, там всё связано с типами, которые обычно выражаются интерфейсами.
Если вы действительно хотите узнать про архитектуру, то послушайте Андрея Аксенова, который сделал Sphinx. «Снесите это немедленно», — один из лучших докладов про архитектуру. Кроме всего прочего, он говорит, что принцип Liskov понадобился ему только один раз — на собеседовании.

На самом деле есть гораздо более важные принципы. Например, Single level of abstraction и вообще барьер абстракции — это одна из ключевых частей разработки. А с Command-Query Separation мы вообще сталкиваемся каждый день. Law of Demeter — попроще, но он встречается гораздо чаще, чем принцип Liskov.
Микросервисы
Я прекрасно понимаю джавистов, когда на собеседовании они начинают со слова «микросервис». Но мне не очень понятно, когда об этом говорят ребята из других языков, особенно когда в их команде разработки три человека.
Например, человек мне рассказывал, что они переходят на микросервисы, потому что у них тормозит ORM в Django. И что у Django плохая ORM, потому что там нельзя писать рекурсивные запросы. Я решил докопаться до сути и начал его расспрашивать.
Выяснилось, что у ребят древовидный каталог, они пишут рекурсивные запросы прямо на SQL, и они тормозят. Как это матчится на микросервисы, не очень понятно, но суть оказалась в другом. Человек просто не знал, как хранить деревья в базе, потому что когда они делали каталог, то не посмотрели, какие есть способы хранения, кроме adjust set. Когда я рассказал ему про материализованный путь, он ушел исправлять проект. Такое у нас было собеседование.
Другая история связана с Python. Парень сказал, что он реализовал микросервисы именно потому, что у него было много зависимостей в одном проекте, и они долго устанавливались. Я попытался поговорить с ним, что это не совсем связанные вещи, но он был твердо уверен, что всё сделал правильно.
О чем я хочу сказать. Микросервисы, безусловно, решают проблемы, и есть проекты, в которых они нужны. Но существует миф, что если где бы то ни было внедрить микросервисы, то станет лучше. Часто говорят: у нас код так себе, поддерживать невозможно, а вот если мы его сейчас разделим на микросервисы, то он сразу станет классным.
Но вообще-то микросервисы сложнее, потому что логика никуда не денется — система останется такой же сложной, но при этом станет еще и распределенной.

С микросервисами вы сразу упираетесь в:
Асинхронность/Обработка ошибок;
Трафик/Кэши;
Распределенные транзакции/Согласованность;
Логи/Отладка;
Версионирование;
Люди/Шаринг/Рефакторинг.
То есть микросервисы не спасают от плохого кода — при разделении он станет еще хуже, потому что в том месте, в котором он все равно собирается, вместо синхронных вызовов будут асинхронные вызовы, и т.д. Я уж не говорю про логирование и всякие другие штуки. Плохой код в тысячу раз проще сделать хорошим в рамках системы, где вы работаете. А микросервисы нужны для другого и решают другие проблемы.
Расскажу историю. В одной компании пишут на Java, и у них всё в микросервисах. При этом их архитектор не любит Spring, и они реализовали пять разных алгоритмов в одном зашифрованном файле. И чтобы достать из этого файла алгоритм, у них реализовано семь микросервисов: один берет данные, другой складывает в базу, плюс под каждый алгоритм написан свой собственный микросервис (еще пять штук).
Все микросервисы одновременно берут этот файл, потому что они одновременно срабатывают. Внутри каждого есть проверка на свой файл. Сам алгоритм на 200 строк, и еще обвязка на пару тысяч, чтобы все это запускалось. Это явный перебор, но так работают многие компании, особенно в аутсорсе. Хотя, на самом деле, это решается классическим паттерном — обычной стратегией, которая делается с помощью простого свитча.
Если вы хотите по-настоящему знать всё про микросервисы, рекомендую доклад Валентина Гогичашвили «События, шины и интеграция данных в непростом мире микросервисов». Он рассказывает, как в Заландо пришли к этому решению и с чем столкнулись по дороге.

Это прекраснейший доклад. В нем помимо практики есть и философия — от просмотра оторваться нельзя, как от хорошей книжки.
Заключение
Есть фундаментальные правила проектирования кода:
Менеджмент состояния. Как только у нас появляется shared state, то возникает определенный класс проблем, и это нужно понимать. Это связано с concurrency и распределенными системами.
Изоляция побочных эффектов. Если вы писали или будете писать на функциональных языках, вы это хорошо поймете, потому что они к этому приучают.
Семантическое именование имеет невероятно важное значение, потому что именовать все равно никто не умеет.
Что делать?
Читайте книги! Есть огромное количество книг, в которых давно написана вся правда. А читая про ОС, вы поймете, как работает все остальное — в операционках много готовых архитектурных решений.
Если вы не писали на языках с совершенно другой парадигмой, то потратьте время на них. У меня есть набор языков, которые я всегда рекомендую, чтобы захватить как можно большее количество разных парадигм и подходов:
Haskell
Clojure, и вообще любой Lisp в принципе.
Kotlin из языков уровня C#, Java и подобных.
С
Ruby, Python, JS — не сильно принципиально какой, любой из них.
Elixir или Erlang.
И последнее: работайте среди тех, кто сильнее вас.
Видео моего выступления на эту тему на конференции TechLead Conf 2021:
В 2022 году конференция TechLead пройдет на одной площадке с конференцией DevOps Conf 2022 — 9 и 10 июня в Москве, в Крокус-Экспо. Подать заявку на выступление для техлидов вы можете здесь, а для devops-коммьюнити — здесь.
Если у вас есть идеи и мысли по выступлению, но есть и много вопросов, то можно встретиться в прямом эфире с Программным комитетом и расспросить их обо всем. На сайтах обеих конференций смотрите информацию о встречах.
Комментарии (21)


OlegZH
04.12.2021 15:51+1когда начинаешь копать, то выясняется, что все хорошо знают определение, но довольно слабо понимают, где это можно и нужно использовать, почему это надо и какие проблемы решает.
Мне было бы крайне интересно узнать, что такое параметрический полиморфизм и полиморфизм ad-hoc.
С чисто обывательской точки зрения, полиморфизм — это возможность писать определённый обобщённый код таким образом, чтобы его конкретное исполнение зависело от объекта, который поступает в обработку. Или, точнее, от его класса или типа. (Это и есть полиморфизм подтипов?)
В книгах и статьях нередко приводят, как мне кажется, довольно искусственные примеры применения полиморфизма. Наверное, самый важный вопрос — это вопрос о том, в каких ситуациях полиморфизм действительно нужен. Например, можно было бы написать библиотеку, аналогичную по своим функциям STL, но без применения шаблонов (как это и делалось в стародавние времена). Совершенно очевидно, что, в такой ситуации, полиморфизм будет важнейшим способом реализации всевозможных контейнеров.
И ещё. Я подозреваю, что у полиморфизма есть неприятная оборотная сторона. Если, вдруг, кому-то понадобится соорудить новый подтип, то, может оказаться, что этот подтип плохо вписывается в общую схему.

k12th
04.12.2021 16:23Если, вдруг, кому-то понадобится соорудить новый подтип, то, может оказаться, что этот подтип плохо вписывается в общую схему.
Дык принцип подстановки Лисков как раз про то чтоб подтипы вписывались, нет разве?

indestructable
04.12.2021 19:53+2Параметрический полиморфизм - это дженерики (параметры типов)
Ad-hoc полиморфизм - перегрузка функций и операторов (выбор варианта во время компиляции).
Ну и по идее должен быть какой-то полиморфизм для прототипных языков, в которых нет подтипов, но есть полиморфизм

forthuser
04.12.2021 16:25+1Не все знают, что недавно в мире редакторов произошла революция. Раньше было четкое разделение на IDE (которые дают рефакторинг, autocomplete, подсказки, документацию и запуск кода) и обычные редакторы, которые дают подсветку и небольшой набор базовых возможностей, типа перехода по файлам. Но какое-то время назад всё изменилось.
А, что изменилось в мире IDE и сторонних редакторов?
Разве они стали больше, например, поддерживать языки мало присутствующие в ротации?
feycot
04.12.2021 18:45+1Как раз ниже рассказывается про LSP.
Грубо говоря - хочешь автокоплит, рефакторинг, разные крутые штуки - покупай или качай IDE.
Хочешь скорости, простоты, комп не тянет IDE? Бери редактор (vim, notepad++, sublime и тд)
И как еще было - под каждый стек\язык своя IDE. Щас можно просто взять редактор и всунуть в него то, что самому хочется.
indestructable
05.12.2021 12:18Изменилось то, что разработчик языка может создать language server, и поддержать сразу много ide


michael_v89
04.12.2021 19:17+4Делать неблокирующее ревью через маленькие изменения позволяет подход Trunk-based Development.
Делать неблокирующее ревью позволяет отдельная ветка для разработки фичи, которая для этой фичи является мастером, пока фича не будет полностью сделана и протестирована. Долгая фича делится на подзадачи, каждая подзадача проходит ревью и мержится в ветку фичи. Мастер периодически мержится в ветку фичи для поддержания актуальности кода.
Koval97
04.12.2021 21:55+4Как технику тяжело читать при таком количестве грубых англицизмов. Неужели так трудно соблюдать строгость терминологии и при переводе применять полный нативный термин, как это принято во всей академической литературе.
Недумаю, чтобы вместо "давления" использовали прежуре от pressure, вместо температура темпреча от temperature, вместо колесо вилл от whell.
Такой же незаметной и довольно пагубной практикой является безумное стремление многих российских компаний к разработке в один присест, одновременно сосуществующая с другой крайностью в виде бесконечной разработки в виде вечного бета-теста, что мы наблюдаем во всех текстах посвещенных менеджменту в IT, и одновременно написанным людьми, которые реальный менеджмент ни разу не видели, ни нюхали.
Некоторые программисты этого не замечают, потому что сами не придают этому значения. А многие и не скажут прямо, посчитав темой табуированной. Но стоит им хоть раз увидеть картину здоровую, как например в студиях разработки видеоигр в начале нулевых, то каждый скажет - "Вот, вот оно! Мы так хотим".

smirnov_dm
04.12.2021 22:28+2Да ладно, какие нулевые? Давайте уже сразу вернёмся к двоичному коду) И к методологии "ну будем, короче, делать так". Относительно претензий в адрес не нюхавших менеджмента: если их аргументация ценна и работает, то совершенно не имеет значение нюхали они менеджмент или пили. У вас argumentum ad hominem получается с этой претензией.

pankraty
04.12.2021 22:50+23Как технику тяжело читать при таком количестве грубых англицизмов. Неужели так трудно соблюдать строгость терминологии и при переводе применять полный нативный термин, как это принято во всей академической литературе.
Какая ирония
pankraty
04.12.2021 22:58+5При таком подходе даже если вы что-то напишете не так, то быстро и легко сможете это поправить. Есть еще дополнительный бонус от такого подхода. Когда программист что-то долго пишет и где-то в начале уходит не туда, он может идти не туда целую неделю и даже больше. В результате накопленный негативный эффект будет слишком большой. Но если бы он вливал в main очень маленькими кусочками, то вы бы намного раньше увидели, что он пошел не в ту сторону, и поправили это.
Вот тут не могу согласиться. Одно дело, когда разработчик неделю писал в своей ветке что-то не то - да, он потратил время, но ущерб проекту на этом заканчивается. И совсем другое дело, когда он за эту неделю сделал 50 мелких коммитов в trunk (параллельно с десятком-другим разработчиков, делающих свои коммиты) , и их надо творчески отреверсить, ничего не пропустив и не сломав никакого кода, который потенциально с ним связан. Риски, что что-то "отъедет", весьма велики.

gatoazul
04.12.2021 23:12+6Барбара Лисков - это вообще-то она. Самая известная ее работа - язык CLU, который стал пионером абстрактных типов данных и одним из первых, куда ввели исключения. Но помнят ее почему-то только за какой-то дурацкий принцип.
pankraty
05.12.2021 00:35+6Да и я бы не сказал, что принцип дурацкий; при написании кода мы практически всегда стараемся в той или иной мере ему следовать, пуусть и неосознанно. Например (в C#), переопределяя метод ToString, обычно никто не будет выбрасывать исключений, а спроси почему это плохая идея - ответят, что вызывающий код может не знать, что объект такого типа требует особого обращения, и вызвать ToString, и неожиданно упасть. Или, к примеру, реализуя метод Equals, технически мы можем делать всё что угодно, хоть картинки котиков показывать, но обычно мы туда помещаем логику сравнения объектов, потому что это именно то, что ожидает потребитель интерфейса.
Так это же и есть проявления принципа Лисков, к которым мы привыкли и воспринимаем как данность. Ну так и многие "принципы", "паттерны", "законы" лишь формализуют то, что давно известно и применяется. Так вот живешь и не знаешь, что всю жизнь говорил прозой.
gatoazul
05.12.2021 01:24+3Принцип нормальный, но как по мне, ее вклад в информатику намного больше этого принципа. Этот самый CLU разработчики последующих языков прилично раздербанили, используя его идеи. Я еще про итераторы забыл.

Ivanzabu
06.12.2021 16:53+1Очень люблю эти фразы про то, что любую задачу можно разделить и лить супер маленькими мр-ами. Только все почему то сразу забывают - что смотрящий мр теперь не видит ни картины того, что делает разработчик, ни вообще что происходит т.к. видит маааленький кусок логики оторванный от задачи, и ему потребуется стянуть себе ветку (что конечно никто делать не будет), чтобы посмотреть все зависимости влитые до этого. Что на декомпозицию задачи уйдёт дополнительный день разработки, а самое главное, что когда все в итоге не заработает в конце - то исправляющие мры/рефакторинг скорее всего затронут насквозь кучу предыдущих изменений и мр-ов станет больше, а значит еще дольше смотреть.
Серьёзно, работал на проекте одного банка где было ограничение на мр по количеству строк - так я убедился что просто разделив код можно протащить в кодовую базу вообще что угодно, главное делить фичу так, чтобы каждый компонент выглядел максимально нейтрально сам по себе. 1 коммит на 5 интерфесов, второй на 5 xml с разметкой, и вот уже смотрящий не увидит что класс управляющий разметкой творит какое-то говно, потому что и разметку уже не видно, и вроде интерфейс уже из кодовой базы.

Onkami
07.12.2021 14:36Trunk-based разработка это такой же карго-культ. Который в принципе разбивается об SLA на уровне 2-4 девяток. Пример с букингом плохой: 100000 для них пыль, а вот для компаний поменьше это повод для разбора полетов на уровне СЕО и прочих боссов. И автор не сообщает, что же делать, если фича-флагов становится много и как управлять этим зоопарком.
Короче, уменьшать бюрократию надо так, чтобы она не возникала в других местах. И своп карго-культов, генерализация удачных практик одной компании на всё и вся - не выход. Кому то транк будет помогать, если потеря транзакций из за багов не катастрофична, но легко представить сценарии, где он будет опасен (например торговые системы, которые не должны терять деньги, и прочий критичный софт - те же транспортные системы).
Что делать? Прежде всего - думать в лббой непонятной ситуации.
OlegZH
Очень хорошо в качестве концентрированного обзора для расширения изначально узкого кругозора, но каждая отдельная тема требует отдельной статьи. Иначе остаются за кадром основания и мотивировки для появления каждой проблемы, да и неясными оказываются последствия. В отдельных статьях можно было бы привести по нескольку конкретных примеров, чтобы хорошо почувствовать, что происходит, если использовать определённые принципы и подходы, и что происходит, если не использовать.
S__vet
да, большие статьи на каждый блок — это отдельная история