
Привет! Меня зовут Антон Поляков, и я разрабатываю аналитическое хранилище данных и ELT-процессы в ManyChat.
Несколько лет назад мы выбрали Snowflake как сервис для нашей дата-платформы. С ростом объемов данных до сотен миллионов строк (спойлер: а затем и до десятков миллиардов), мы задались вопросом: «Как тратить меньше времени на расчет запросов для ежедневной отчетности?». Идеальным вариантом было использование материализованных представлений, позволяющих обращаться к предварительно вычисленным результатам расчета витрин гораздо быстрее, чем к исходным данным.
Мы могли отдать управление нашим пайплайном таким популярным сегодня инструментам для трансформации данных, как, например, dbt, Matillion или Dataform. Однако, в начале 2020 года ни у одного из них не было возможности тонкой кастомизации под нужды Snowflake и ManyChat. К тому же, нам не хотелось платить за еще один сторонний инструмент. Так, мы приняли решение изобрести собственный велосипед для работы с материализацией данных. Именно об этом я сегодня и расскажу.
Проблема больших представлений
В ManyChat мы используем анкор модель. В детальном слое находится уже более 150 Тб данных и 1500+ таблиц. Каждый день в нашем Snowflake-хранилище 30 человек выполняют сотни аналитических запросов, причем это не только аналитики, но и разработчики, HR, бухгалтерия.

При работе с шестой нормальной формой, применяемой в анкор-модели, неизбежно приходится использовать большое количество join’ов, поэтому со временем аналитические запросы становятся все сложнее.
Очень часто, чтобы построить отчет, требуется соединить более 10 таблиц, и, несмотря на микро-партиции, фильтры и правильную кластеризацию, запрос работает медленно. Казалось бы, можно вдвое увеличить производительность кластера, но и цена за его использование тоже вырастет в два раза, а это совсем не то, чего хотелось бы молодому стартапу.
Чтобы упростить работу аналитиков, слишком длинные запросы декомпозируются на мелкие view, которые можно использовать повторно в разных отчетах. Это помогает организовать код и стандартизировать разработку, так как для производных представлений появляется один источник данных.
Каждый аналитический запрос ко view запускает кластер и начинает потреблять кредиты Snowflake, а также занимает место в очереди запросов. Кроме того, результат работы view, основанных на непрерывно обновляемых данных, не постоянен на протяжении дня, и хранилищу постоянно приходится их пересчитывать. Несмотря на то, что часть данных уже есть в горячем кэше, этот процесс может занимать много времени.

Если данные из производных объектов (Derivative Data) пропадут или окажутся не консистентными, у нас всегда есть возможность пересчитать их заново из источников (Primary Data), без потерь. Каждый раз, когда кто-то пишет запрос к конечному объекту с результатом агрегации, система фактически запускает весь процесс получения и преобразования данных.
Но что делать, когда с ростом объемов данных, каждая view начинает вместо пары секунд работать десятки минут?
Полные материализации
В сегодняшнем мире сложно представить себе, что кто-то ждет результаты отчета за последний месяц по 10, 20 или даже 30 минут. Именно поэтому чаще всего результат работы всего пайплайна материализуют. Материализация – это сохранение набора данных в виде таблицы.
Мы решили начать с добавления команды create or replace table ко всем существующим представлениям и их ежедневного обновления по расписанию.
В подавляющем большинстве аналитических отчетов нет необходимости в обновлении данных в реальном времени, достаточно near real time, допустим, с задержкой в сутки. Поэтому для них мы решили брать все данные из хранилища на конец предыдущего дня.


Полная материализация полностью перезаписывает уже существующие данные без историчности. Данный метод подходит для небольших таблиц с малым количеством операций join/order/group by/window functions. В кластере М подобный запрос должен выполняться не более 5-10 минут.

Для получения данных из набора B, системе необходимо будет задействовать данные только из материализованного объекта A. Все остальные датасеты, материализованные или нет, могут быть выброшены из расчета запроса.
Подобный подход позволил обновлять результат работы представлений раз в сутки, используя достаточно дешевый кластер размера M. Также появилась возможность использовать эти данные в других view и отчетах без их повторной обработки.
До: Расчеты аналитических представлений производились на S кластере и съедали приличное количество кредитов ежедневно. Вдобавок, в некоторые моменты кластер был перегружен и многие запросы уходили в очередь (оранжевый цвет), даже при наличии второго виртуального кластера.

После: Создание полных материализаций было перенесено на кластер размера М. Аналитические запросы к собранным данным остались на одиночном S-кластере.
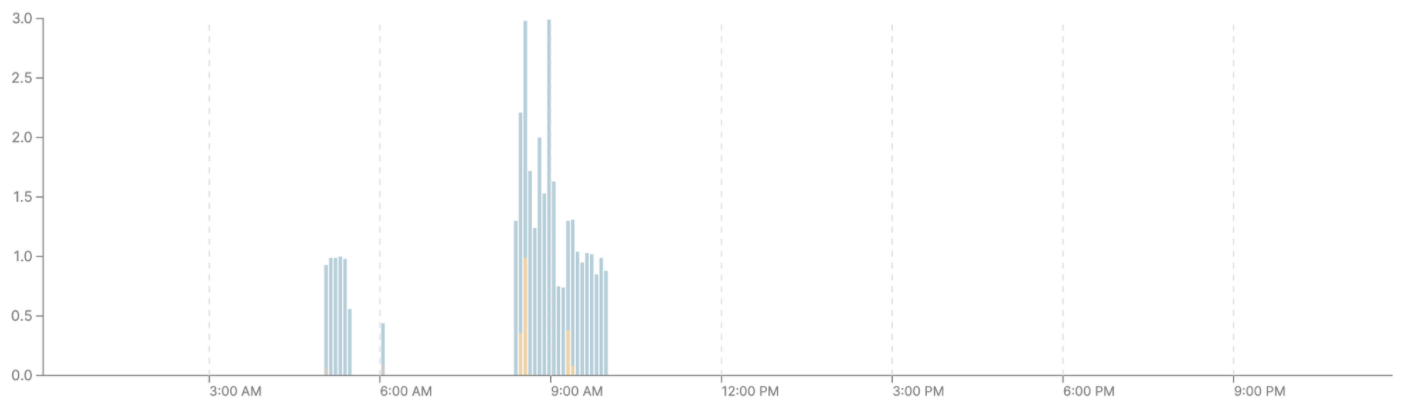
Кластер размера М дороже в использовании, но за счет того, что обновления идут одной пачкой, друг за другом, кластер не простаивает и работает только в заданный промежуток времени. Это значит, что деньги на запуск и прогрев кластера, а также на таймаут перед его выключением больше не тратятся впустую.
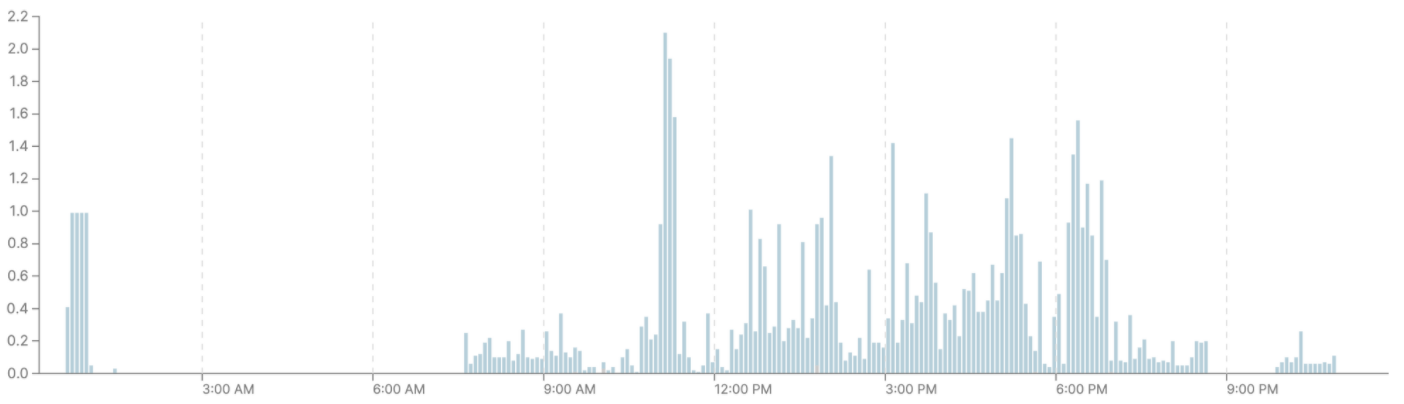
Запросы на S-кластере стали потреблять меньше ресурсов, исчезли очереди и время выполнения запросов сократилось.
Суммарное потребление кредитов двух кластеров S и M сократилось примерно на 20% по сравнению с исходным потреблением двойного S-кластера: второй кластер поднимался при полной загрузке первого и выключался при отсутствии нагрузки более 5 минут. Время ожидания результата аналитических отчетов уменьшилось с десятков минут до 0-5 минут.
Инкрементальные материализации
Полная материализация работала отлично на небольших объемах данных. При join’ах таблиц в сотни миллионов строк все происходило быстро, и каждый запрос отрабатывал не более 5 минут. Но мы растем очень быстро, и через несколько месяцев объем данных увеличился в десятки раз.
Join’ы таблиц с десятками миллиардов строк начали выявлять проблемы нехватки ресурсов кластера размера М. Мы все еще могли обрабатывать подобные объемы, но время создания таблиц росло. На материализацию одного такого отчета порой уходило более 30 минут, а при 30-40 материализациях в день время сборки всей отчетности доходило до 5-7 часов.
Конечно, мы бы могли решить проблему увеличением размера кластера до L или XL (и далее до XXXXL). Но изначально нами был выбран путь экономии и размеренного потребления ресурсов. Это привело нас к логичному развитию нашей системы материализаций – к материализации с инкрементом.
Инкрементальная материализация работает по другому принципу, нежели полная: обновляется не вся целевая таблица, а лишь интересующая нас часть. Это может быть новый расчетный день или партиция. В целевую таблицу добавляются только те данные, которые изменились или добавились с последней материализации. Этот способ позволяет работать с меньшим набором данных, а значит, сокращает время выполнения запросов для материализаций и затраты.
Полная материализация
Старая целевая таблица удаляется и вместо нее создается новая с актуальными данными.

Инкрементальная материализация
Старая таблица материализации не удаляется, но добавляются записи, которых в ней еще не было.

Данный тип материализаций подразумевает инкрементальное обновление целевой таблицы путем добавления (insert / delete + insert) новых данных к уже существующим по заданному ключу partition.
Партиция может быть выбрана абсолютно любая. В большинстве случаев это колонка с датой совершения события / обновления модели. Подобный подход позволил уменьшить объем данных для получения инкремента в представлении.
Время работы инкрементальной материализации удалось уменьшить на 70-80% по сравнению с полной перезаписью существующей таблицы. Несмотря на рост объема данных, подход с обновлением данных за последние несколько дней помог заморозить траты на инфраструктуру на одном уровне.
Как мы управляем нашими материализациями?
Каждое утро материализации обновляются через наш ELT-фреймворк в порядке, учитывающем зависимости. После присвоения каждому представлению грейда, который зависит от уровня связанности с другими объектами в хранилище, рекурсивно рассчитывается весь путь (data lineage) для каждой view и её содержимого от источника до результата в материализации. С учетом количества зависимостей и их веса, выстраивается DAG (Directed acyclic graph) для поочередной материализации каждого представления. Иногда это происходит в асинхронном режиме. Например, в случае отсутствия прямой зависимости между двумя представлениями, они могут быть запущены параллельно.

Заключение
Благодаря материализациям представлений, мы смогли уменьшить время сборки ежедневной отчетности в несколько раз. Наш новый пайплайн позволил сократить время работы кластеров и уменьшить затраты на инфраструктуру Snowflake на несколько десятков процентов. Прошел уже год после внедрения системы материализаций, и все это время потребление кредитов остается стабильным, а понимание того, как устроен оптимизатор Snowflake, позволило писать быстрые запросы и использовать множество хаков через python-код нашего фреймворка.
Про нюансы работы наших ELT-процессов или аспекты работы со Snowflake спрашивайте меня в комментариях – обязательно отвечу.
ajvol
Интересно. Я сам со snowflake не работал. Можете подсказать 1-2 небанальных особенностей оптимизатора, которые приходилось учитывать?