
Сами по себе логи, трейсы, метрики - это очень узкие артефакты состояния нашего объекта наблюдения и обслуживания. Для понимания общей картины нужен взгляд сверху, сбор всех важных сигналов в одну систему и работа с большими данными в ней. Зонтичный подход близок по своим целям к RED и Golden Signals, но по своей сути является противоположным по принципу работы с данными. В Golden Signals мы отслеживаем Latency, Traffic, Errors отдельных сервисов и по ним можем быстро, но очень поверхностно определить их состояние. В случае зонтичного мониторинга или AIOps мы собираем данные о всех логах, событиях систем мониторинга метрик и трейсов, далее выстраиваем там топологию сервиса и определяем алгоритмически состояние здоровья, основываясь на сотнях и тысячах событий, метрик и трейсов. И два подхода, кстати, друг друга не исключают.

В этой статье я постараюсь сравнить четыре бесплатных инструмента, которые могли бы дать такую зонтичную картину: ELK, Graylog, Grafana Loki и Monq.
Сбор и анализ логов и событий является достаточно большой и необходимой частью любой более или менее полной системы ИТ мониторинга инфраструктуры и бизнес-процессов. Логи являются очень ценным материалом для observability ваших систем и сервисов, а события несут информацию о превышении пороговых значений в метриках или трейсах. События систем мониторинга, таких как Zabbix, Nagios, PRTG, SCOM и другие - это все по сути своей тоже логи. Поэтому мы в этой статье выбрали системы работы с логами.
Во многих ситуациях обработка логов помогает отследить сбои и проблемы в работе ИТ сервисов на раннем этапе их возникновения или помочь в поисках первопричин этих сбоев уже постфактум, причем зачастую анализ логов даёт единственную возможность выяснить эти первопричины. Поскольку логи - это, как правило, локальные файлы, куда пишут свои сообщения различные процессы и службы, запущенные на сервере или в контейнере (которых в большой ИТ системе может быть сотни и даже тысячи), решение задачи сбора и анализа логов представляется совсем не тривиальным. По мере роста объема данных отслеживать и управлять логами становится всё сложнее - по этой причине разработчики, инженеры и технические директора обращаются к различным инструментам для обработки логов.
В процессе обработки логов можно выделить, как минимум, четыре стадии:
собственно сам сбор логов с серверов и контейнеров с помощью агентов и их отправка по сетевым протоколам в централизованное хранилище либо напрямую, либо через агрегаторы с предварительной обработкой,
внутри агрегаторов лог-сообщения парсятся, обогащаются дополнительной информацией (отметкой времени, идентификатором источника, меткой местоположения и т.п.), приводятся к единому формату и отправляются в хранилище в виде готовых для индексирования полей и их значений,
непосредственно хранение логов и управление хранилищем,
анализ и визуализация данных, полученных из логов.
Как правило, на разных стадиях задействованы различные программы, так что общую схему процесса сбора и анализа логов можно проиллюстрировать следующей картинкой:
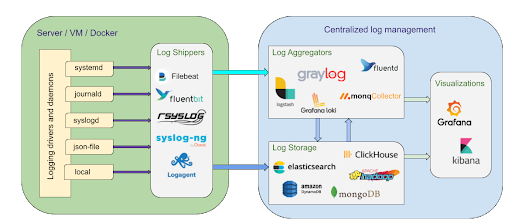
На рынке существует что-то около сотни программных решений с заявленными, в той или иной степени, возможностями по сбору и анализу логов. Выбор варьируется от полновесных, закрытых и платных, энтерпрайзовых решений вроде Splunk до лёгковесных, относительно открытых и бесплатных решений вроде Graylog Open.
В данной статье мы будем рассматривать только бесплатные решения и сравним декларируемый функционал нескольких уже популярных инструментов с новым решением от российских разработчиков:
ELK-стек (ElasticSearch + Logstash + Kibana),
Graylog Open,
Grafana Loki,
Monq.
В основном сравнение будет проводиться по функциональности централизованной платформы, т.е. на уровне агрегаторов, систем хранения и инструментов визуализации, поскольку на стороне серверов и контейнеров все решения могут использовать одних и тех же стандартных коллекторов логов (log shippers), хотя сейчас практически все решения предлагают установку своих собственных агентов на мониторируемые узлы для большего удобства при развёртывании и конфигурировании системы.
Читатели знакомые с основными принципами работы сборщиков логов могут сразу перейти в конец статьи к сравнительной таблице функционала рассматриваемых решений.
1. ElasticSearch + Logstash + Kibana
ElasticSearch, Logstash и Kibana изначально разрабатывались как продукты с открытым исходным кодом и развивались отдельно друг от друга, но в 2015 году они объединились под брендом Elastic и стали позиционироваться как единый продукт - ELK-стек. Взаимодействие отдельных компонент в рамках ELK-стека можно описать следующей блок-схемой:
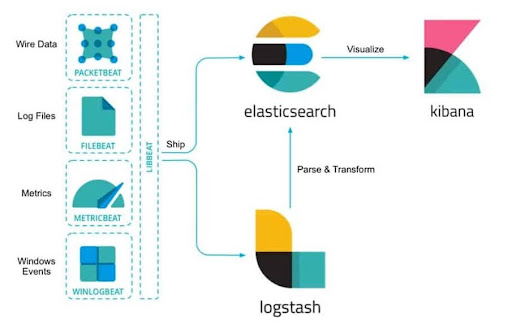
Logstash представляет собой конвейер обработки данных на стороне сервера, который одновременно принимает данные из множества источников (логи собираются через FileBeat), преобразует их, а затем отправляет обработанные данные в хранилище Elasticsearch. Основной функционал Logstash в качестве агрегатора логов включает в себя следующее:
Возможность принимать данные в разных форматах и разного размера из большого количества источников с помощью всевозможных входных плагинов – около 25-ти плагинов официально поддерживаемых самим Elastic (включая file, http, syslog, tcp, udp) плюс сотни неофициальных, размещенных как автономные пакеты на RubyGems,
-
Обработка входных данных с использованием отдельных плагинов – фильтров (около 30-ти официально поддерживаемых), которые парсят каждое лог-сообщение, находят именованные поля в соответствии с заданной структурой, преобразовывают их (при необходимости) и приводят все логи к общему формату. Наиболее часто применяются следующие фильтры:
grok – основной инструмент для парсинга лог-сообщений, который позволяет их структурировать путём определения регулярных выражений для поиска и извлечения в именованные поля отдельных частей строки. В grok доступно в общей сложности около 120 интегрированных шаблонов, среди который практически всегда найдётся что-то, что соответствует конкретным входным логам, но при необходимости всегда можно написать свой собственный. Пользователи могут ссылаться на значения именованных полей, выделенных grok, в файле конфигурации и использовать их для фильтрации событий и манипуляции данными.
date – этот плагин используется для парсинга дат из лог-сообщений и последующего использования этих дат в качестве меток времени (@timestamp), чтобы гарантировать, что обработанное событие будет содержать правильную метку, а не метку, основанную на том, когда событие поступило на вход конвейера обработки.
geoip – этот плагин ищет IP-адреса, извлекает из адресов информацию о географическом местоположении и добавляет её в виде отдельного поля в структурированные логи.
multiline – этот плагин позволяет сворачивать многострочные сообщения из одного источника в одно лог-сообщение.
Выходные плагины используются для отправки обработанных структурированных логов в различные системы хранения данных (чаще всего в Elasticsearch), в брокеры сообщений (kafka, redis) и т.п..
В Logstash есть возможность использования разных кодеков для декодирования и кодирования входных и выходных данных: в основном используются plain для работы с простыми текстовыми сообщениями и json для работы с событиями в формате json.
Конфигурация конвейера обработки задаётся в простом текстовом файле.
Центральным элементом ELK-стека является Elasticsearch - поисковая система для высокопроизводительного полнотекстового поиска, разработанная на основе открытой библиотеки Apache Lucene. Она сочетает в себе функции базы данных, а также поискового и аналитического движков со следующими основными свойствами:
Elasticsearch является нереляционным документоориентированным хранилищем данных (NoSQL) в формате JSON без строгой структурированности,
вся работа с базой данных строится на json запросах с помощью REST API, которые позволяют добавлять, просматривать, модифицировать и удалять данные, выдавать документы по индексу, считать различные статистики,
отсутствие схемы (schema-free) позволяет загружать в хранилище любые текстовые документы и индексировать их автоматически,
процедура индексации заключается в обработке текста документа анализатором (токенизацию, лемматизацию и фильтрацию токенов) и добавлением выходного набора токенов в поисковый индекс,
Elasticsearch обеспечивает быстрый и гибкий полнотекстовой поиск по всем полям во всех документах хранилища данных (слова из запроса ищутся по индексу),
поддерживает несколько различных способов нечеткого поиска,
поддерживается работа с текстами восточных языков CJK (китайского, японского, корейского),
Elasticsearch обладает возможностями высокого горизонтального масштабирования и репликации для работы с высоконагруженными проектами с большими объёмами данных, а также относительно легким управлением и хорошей отказоустойчивостью.
Kibana, как составная часть ELK-стека, представляет собой инструмент, отвечающий за представление результатов поисковых запросов в Elasticsearch в удобном для восприятия виде. По сути, Kibana - это веб-интерфейс для поиска, просмотра и взаимодействия с документами, находящимися в хранилище данных, позволяющий:
отправлять поисковые запросы в Elasticsearch (используя специальный синтаксис KQL, Kibana Query Language) и проводить всевозможную фильтрацию полученных результатов,
проводить анализ данных и визуализировать результаты в виде различных диаграмм, гистограмм, таблиц, графиков, карт и т.п.,
создавать, изменять, сохранять и загружать пользовательские дашборды, объединяющие несколько визуализаций на одном экране, причём можно загружать и сторонние дашборды,
администрировать хранилище данных Elasticsearch, управлять индексами и конвейерами обработки,
управлять правами и уровнями доступа пользователей к разным элементам системы.
Следует отметить, что в последних версиях (начиная с 7.14) Elastic фактически перешли на сбор логов с помощью собственных программ-агентов (Elastic Agents), устанавливаемых на серверах и в контейнерах, вместо использования входных плагинов к Logstash. Elastic Agent - это единый унифицированный способ добавить мониторинг логов, метрик и других типов данных на каждый узел, что упрощает и ускоряет развертывание мониторинга в большой системе. В веб-интерфейсе Kibana появилась дополнительная панель Fleet, которую можно использовать для добавления агентов и управления ими, а также из неё можно устанавливать уже готовые интеграции для популярных сервисов и платформ. Интеграции обеспечивают довольно простой и быстрый способ подключения стандартных источников данных, плюс они поставляются с настроенными элементами, такими как дашборды, визуализации и конвейеры для извлечения структурированных полей из лог-сообщений.

ELK-стек, в силу своего уже почти 20-летнего периода развития, де-факто является некоторым эталоном системы для сбора и обработки логов и используется многими большими компаниями. В частности, Netflix использует систему, состоящую из 150 кластеров Elasticsearch по 200 инстансов в каждом, а в России в Тинькофф на основе Elasticsearch строят сервис по обработке 1 млн логов в секунду.
2. Graylog Open
Одной из конкурирующих с ELK-стеком системой по сбору и обработке логов является Graylog Open, который в качестве хранилища логов и поискового движка использует всё ту же Elasticsearch. Непосредственно сам Graylog выполняет функции агрегатора логов и инструмента визуализации в виде клиентского одностраничного браузерного приложения:

В плане агрегирования логов функционал Graylog очень схож с функционалом Logstash:
возможность принимать данные в разных форматах из различных источников с помощью всевозможных входных плагинов, причем некоторое их количество уже встроено внутрь самого Graylog (около 10-ти, включая http, syslog, tcp, udp),
обработка входных данных с помощью так называемых экстракторов, в которых правила извлечения значений нужных именованных полей из строк сообщений можно задавать с помощью регулярных выражений и шаблонов grok,
отправка обработанных структурированных логов в систему хранения данных Elasticsearch или, с помощью специальных выходных плагинов, в другие системы,
возможность работы как с простыми текстовыми сообщениями, так и с событиями в формате json.
Поскольку Graylog использует Elasticsearch, то в плане поисковых запросов и работы с хранилищем данных и индексом он аналогичен ELK-стеку, а в плане возможностей по обработке и визуализации данных из лог-сообщений веб-интерфейс Graylog предоставляет функционал, практически аналогичный функционалу Kibana, как всё это было описано в предыдущем параграфе.
Несмотря на значительную схожесть в принципах работы и пользовательских функциях между ELK-стеком и Graylog, последний имеет ряд особенностей:
дополнительно использует базу данных mongoDB для хранения конфигураций и настроек,
c помощью механизма Search Workflow в Graylog можно создавать и объединять несколько поисковых запросов в одно действие и просматривать полученные результаты на экране, похожем на дашборд, причём эти комбинированные запросы можно сохранять.
Но самое важное отличие и достоинство Graylog Open перед ELK-стеком - наличие встроенной системы оповещений (алертов) при возникновении каких-либо специфических ситуации или событий в процессе сбора логов (в ELK система оповещений есть, но она - платная, хотя есть и бесплатные сторонние плагины с подобным функционалом). Алерты Graylog - это периодически самозапускающиеся поисковые запросы, которые могут рассылать уведомления, если в результате запроса выполняются определенные условия. Graylog позволяет задавать разнообразные условия оповещения на основе собираемых данных, по умолчанию доступны следующие (для других необходимо устанавливать плагины):
условие фильтра срабатывает, когда в заданном потоке приходит хотя бы одно сообщение, в котором конкретное поле содержит заданное значение,
условие агрегации срабатывает, когда результат агрегирования (как правило, счётчик значений каких-либо полей) превышает определённое пороговое значение.
Оповещения можно отправлять либо на электронную почту, либо по http любому настроенному получателю.
Graylog, также как и последние версии Elastic, предоставляет возможность установки на каждую подконтрольную систему своих агентов (Graylog Collector Sidecars), которые занимаются сбором необходимой информации и отсылкой ее на сервер. C помощью отдельной панели Graylog Sidecars в веб-интерфейсе можно осуществлять централизованное управление и поддерживать согласованную конфигурацию различных агентов по сбору логов на всех узлах. Для этого используется система тегов, которые создаются через веб-консоль и содержат конфигурации для сбора определенного типа логов (например, логи Apache, логи DNS и т.п.), а агенты Sidecar на конкретных машинах могут “само-конфигурироваться” по указанному тегу и начать посылать данные.
3. Grafana Loki
Grafana Loki сравнительно недавнее добавление к списку программных решений для сбора и анализа логов - проект был запущен в 2018 году. В принципе, Grafana Loki работает по той же схеме, что и ELK-стек и Graylog, но со своей спецификой:

Во-первый, сам Loki не более чем индексатор направляемых в него структурированных логов, причём индексация проводится не по всему тексту лог-сообщений, а только по метаданным логов (тегам или меткам), сами же логи сжимаются рядом в отдельные файлы и хранятся либо локально, либо в облачных хранилищах вроде Amazon S3 или GCS. Поэтому в Loki невозможен полнотекстовый поиск по индексу, в нём данные ищутся сначала по индексированным полям, а затем текст выбранных логов сканируется регулярными выражениями. Такой подход позволяет избежать проблем с требованиями к оперативной памяти (полнотекстовый индекс логов зачастую сопоставим по размеру с самими логами, а для быстрого поиска его весь надо загружать в память), но значительно увеличивает время поиска в случае большого объёма логов. Для ускорения поиска Loki может разделять запрос на несколько частей и выполнять их параллельно, так что скорость обработки зависит от выделенных ресурсов. Такой механизм, маленький индекс с параллельным полным перебором, позволяет лучше балансировать стоимость системы Grafana Loki в соответствии с требованиями по скорости обработки и объёму данных.
Во-вторых, всю основную работу (парсинг, нахождение именованных полей в тексте лог-сообщений, их преобразование и приведение к общему формату) Loki делегирует агентам-сборщикам. В качестве “родного” для Loki агента выступает Promtail, хотя возможно использование Fluentd, Logstash и некоторых других. В настоящий момент Promtail может читать лог-сообщения только из локальных файлов и из службы systemd, но при этом он заимствует у Prometheus механизм обнаружения сервисов, что позволяет ему автоматически интегрироваться с Kubernetes и собирать логи с узлов, сервисов или подов, сразу развешивая метки на основе метаданных из Kubernetes. Механизм обработки лог-сообщений и приведения их к структурированному виду у Promtail похож на механизм экстракторов у Graylog (хотя везде есть свои нюансы), однако у Promtail нет графического интерфейса и всю конфигурацию конвейеров обработки нужно задавать отдельно в текстовом файле, что не всегда удобно.
Инструментом визуализации данных из логов в системе Grafana Loki выступает, естественно, Grafana. Поисковые запросы в Loki можно отправлять в специальном интерфейсе Grafana Explore, для запросов используется язык LogQL, очень похожий на использующийся в Prometheus PromQL. Как и Kibana, Grafana предоставляет широкий спектр возможностей по визуализации данных:
результаты поисковых запросов можно отображать в виде различных графиков, гистограмм, таблиц, тепловых карт и т.п.,
можно объединять несколько визуализаций на одном дашборде, которые можно сохранять, загружать и изменять, а также экспортировать и импортировать с Grafana.com.
Grafana имеет весьма развитую встроенную систему оповещений (алертов), которые, аналогично Graylog, представляют собой периодически самозапускающиеся поисковые запросы, генерирующие уведомления при выполнении определенных условий. При этом возможности по конфигурированию и настройке алертов, предоставляемые в графическом интерфейсе Grafana, очень широкие, а уведомления могут рассылаться по многим каналам: email, slack, telegram, discord и т.п..
4. Monq
Платформа Monq интересна тем, что позиционирует себя именно как Freemium решение для полноценного зонтичного мониторинга, сбора и анализа логов и AIOps. При этом в бесплатной версии нет ограничений ни на количество пользователей, ни на объем данных. Есть ограничение только на количество конфигурационных единиц для расчета метрик здоровья сервиса, чем можно и не пользоваться на начальном этапе. Само решение Monq появилось на рынке совсем недавно, пару лет назад, и использует современный стек технологий и докеры. Хотя Monq ещё совсем молодой продукт, по функциональным возможностям он вполне может конкурировать с устоявшимися решениями вроде ELK-стека, поскольку обладает всеми необходимыми элементами для организации системы по сбору и обработке данных.

Как агрегатор лог-сообщений Monq может выполнять следующие функции:
прием данных в формате json из различных источников по http, причем множество шаблонов подключения встроено внутрь самого monq (Zabbix, Prometheus, Nagios, Ntopng, SCOM и др.),
-
обработка входных данных с использованием low-code движка и скриптов на языке Lua или С# с возможностями:
извлечения значений именованных полей из текста сообщений с помощью регулярных выражений,
трансформации и изменения значений полей,
добавления новых полей и их значений (обогащение данных новыми метками).
отправка обработанных структурированных логов на хранение в базу данных ClickHouse,
управление правами доступа пользователей к конфигурациям и настройкам потоков данных.
В качестве хранилища данных, а также поискового и аналитического движков monq использует СУБД ClickHouse, которая наделяет его следующим основным функционалом:
отправка поисковых запросов (с синтаксисом похожим на Lucene) и всевозможная фильтрация полученных результатов,
столбцовый тип базы данных ClickHouse обеспечивает очень быструю обработку поисковых и аналитических запросов (отсутствие индексации),
модель для базы данных формируется автоматически исходя из модели json конкретного потока, нужные поля добавляются при необходимости.
В плане визуализации данных Monq в текущей версии имеет следующий функционал:
отображение общего числа обработанных событий в виде гистограммы временного ряда,
представление значений различных полей в виде гистограммы частотности (для числовых полей ещё рассчитываются минимум, максимум и среднее значение),
поддержка разметки Markdown в отображении текста лог-сообщений (можно написать свой обработчик, который будет навешивать разметку Markdown к необходимым полям),
визуальный конструктор фильтра с возможностью включения и исключения конкретных значений полей в фильтр по клику на них.
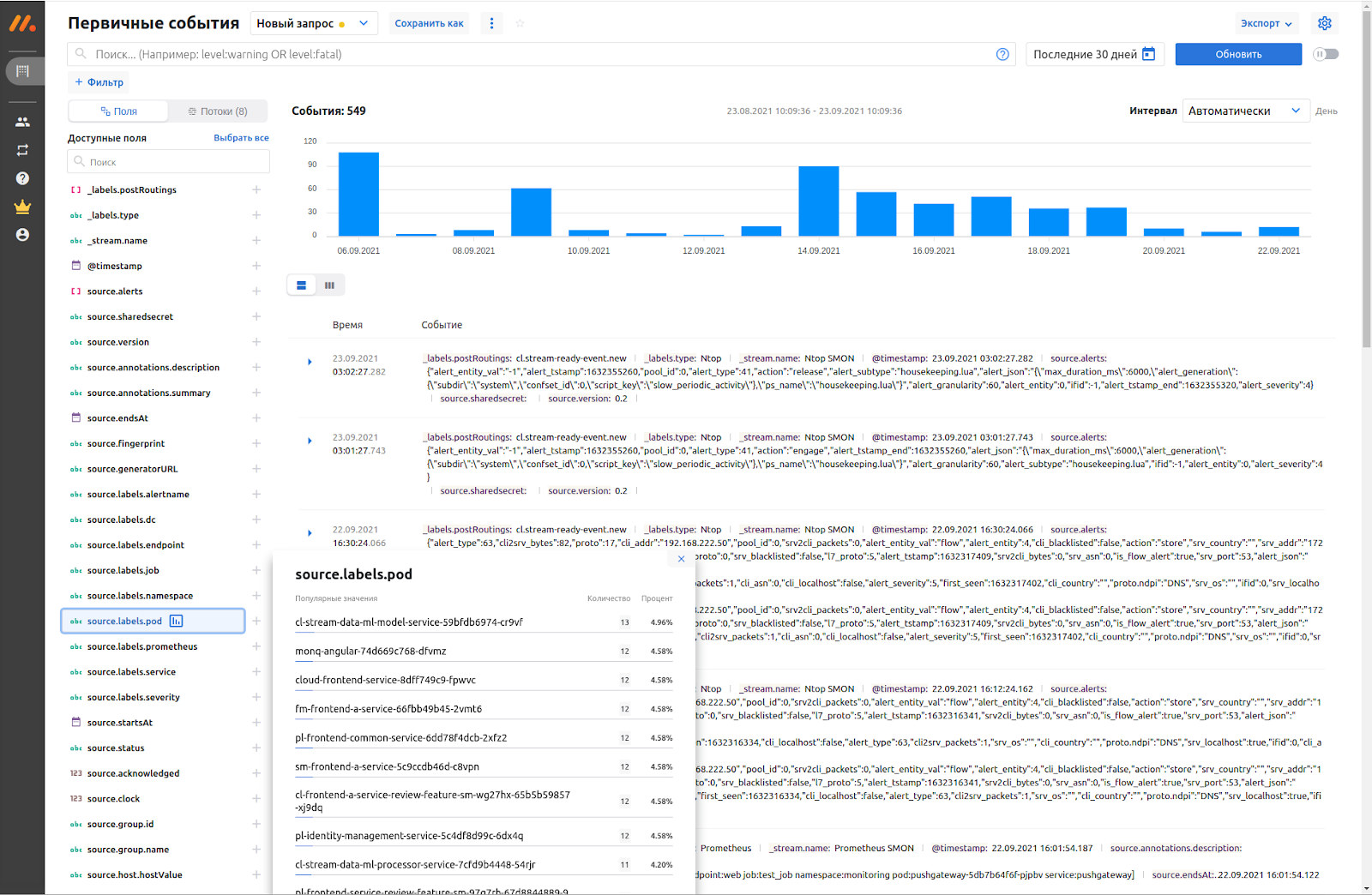
Помимо стандартного представления сырых данных логов и событий, есть также и более специфические визуальные компоненты:
таймлайн для событий и планирования работ (это удобно когда надо поделиться с коллегами графиком важных мероприятий, регламентных работ или маркетинговых активностей, а также на таймлайне можно расследовать первопричину инцидента и коррелировать по времени события),
тепловая карта состояния выбранного набора сервисов и объектов мониторинга,
граф топологии с состояниями отдельных объектов и передача статусов здоровья с формированием здоровья этих объектов,
другие экраны для более узких задач, например, для расчета SLA и анализа бизнес-влияния.
В monq также есть система оповещений, работающая на тех же принципах, что и в Graylog или Splunk, есть механизм синтетических триггеров для генерации событий и механизм “Правил и действий” для запуска нужных действий по срабатыванию сложных правил. Также в декабре 2021 года появился новый модуль автоматизации, построенного на собственном low-code движке.
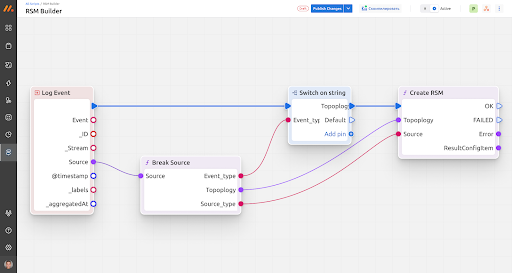
Наряду с остальными программными решениями по сборке логов Monq также предоставляет возможность установки своих агентов (monqAgent) на удаленных устройствах, которые занимаются сбором локальных логов и отсылают их на сервер в централизованную систему. Управление агентами и мониторинг их состояний можно проводить с отдельной панели веб-интерфейса “Агентов”, похожей по функционалу на панель управления агентами у Graylog.
5. Сравнительная таблица функциональности
Все проанализированные возможности рассматриваемых программных решений для сбора и анализа логов можно представить в виде следующей сравнительной таблицы (с определённой долей субъективности):
|
ELK (Нидерланды- США) |
Graylog (США) |
Grafana Loki (США) |
Monq (Россия) |
|
Входные форматы данных |
++ |
++ |
+ |
++ |
Встроенные интеграции |
+++ |
++ |
+ |
+ |
GUI потоков данных |
++ |
++ |
+ |
++ |
Парсинг именованных полей из строк |
+++ |
++ |
а |
+ |
Обработка входных данных и обогащение |
++ |
++ |
а |
++ |
Шаблоны обработчиков |
++ |
++ |
а |
+ |
Визуализация данных |
+++ |
++ |
+++ |
+++ |
Поддержка Markdown |
+ |
- |
- |
+ |
Корреляция и дедупликация |
п |
п |
- |
++ |
Интеграция с платформами совместной работы и ITSM |
п |
п |
- |
+++ |
Алерты |
п |
+ |
+ |
++ |
Эскалации |
- |
- |
- |
++ |
Свои агенты |
+ |
+ |
+ |
+ |
Управление агентами |
++ |
++ |
- |
++ |
Возможности расширения |
+++ |
++ |
+ |
+ |
Документация |
++ |
++ |
++ |
++ |
Процесс установки |
+ |
++ |
+ |
++ |
где “+” “++” “+++” означает наличие данного функционала по возрастающей степени возможностей, “а” означает, что данный функционал обеспечивают агенты-коллекторы, “п” означает, что данный функционал доступен только в платных версиях, “-” означает, что данный функционал пока отсутствует.
Для всех рассмотренных программных решений в последних версиях следует отметить сильный тренд на делегирование функционала первичной обработки логов своим локальным агентам, что может привести к некоторому упрощению функционала агрегаторов логов, как это уже видно на примере Grafana Loki, что также подчеркивает тренд на упрощение. Также стоит отметить тренд постепенного урезания бесплатного функционала и появления все больше и больше платного. Это относится к ELK и Graylog. Из таблицы видно, что ELK-стек является самым полнофункциональным решением по сбору и обработке данных, но алертинг только в платных версия существенно портит картину. Graylog также является средством больше для анализа логов. Grafana Loki является самым простым и легковесным решением и он подходит для решения узких задач, когда не нужна полноценная наблюдаемость (observability) систем и сервисов. Monq по функционалу существенно превосходит представленные решения, но продукт весьма свежий и отзывов по его использованию в Интернете пока не много.
Надеюсь статья вам была полезна, выбор решения для себя или для организации всегда непростой шаг, так что рад буду продолжить дискуссию в комментариях.
Комментарии (5)

creker
11.12.2021 20:03Недавно как раз задеплоил локи и пока все нравится, но и не было пока случаев, когда надо прямо сильно копаться в логах. ELK помню помогал в этом плане, когда тупо отсеивали по одному сообщению мусор и докапывались до истины. При этом все это делалось за считанные миллисекунды.
Но зато в плане простоты и легковесности нет равных. Читая документацию по архитектуре, выглядит это все жутко наворочено, но если ограничиться монолитными вариантом деплоя и начать с конфига из примеров, то вся система простая как пробка. Сейчас переваривает логи с 4 хостов и загрузка CPU до процента не доходит даже. Память тоже несколько сотен мегов.
Единственное надо быть очень осторожным с лейблами. Каждая комбинация лейблов это отдельный "memory stream" в памяти локи и отдельные файлы на диске для каждого чанка. Очень быстро может оказаться, что в памяти миллион стримов, а не диске все десятки и сотни. И если руками заданные лейблы ты естественно контролируешь сам, то динамические могут легко выйти из под контроля. Например, если логи прилетают извне по syslog протоколу.
amarao
У kibana самый античеловеческий интерфейс, который я когда-либо видел. Лучший метод унизить админа - заставить его чинить сервер по мотивам логов в elk'е.
creker
Почему? Для админа вполне естественно читать сырые логи на этих серверах. Кибана практически в сыром виде эти логи и выводит, добавляя лишь к этому свой синтаксис запросов. Выглядит не так модно, как графана например, но, по сути, все оно одно и тоже. Грейлог и тем более монк выше чистая копипаста с кибаны. А другого я ничего и не видел. Платными решениями не приходилось пользоваться.
eigrad
В ES очень много подводных камней не очевидных даже опытному админу, если он не спец по ES. Это может выстрелить в любой момент - просто не увидишь нужную критичную запись из за особенностей поискового запроса / настроек анализатора.
Выводит то может и похоже, хотя тут тоже спорный момент - настроили или нет корректное разбиение на записи обрабатываемого логфайла при заливке большой вопрос, и чаще ответ будет нет, чем да. Graylog тут чуть лучше смотрится, так как у него хотя бы есть нормальный log-ориентированный протокол.
На любых хоть сколько-нибудь значимых объемах эластик это очень дорого. Стоит ли платить за его мощь как распределенного поискового движка - зависит от случая. Среднестатистический админ профита получит с гулькин нос, а боли - достаточно.
Вообще, кажется что лучше и удобнее чем grep по файлам пока не придумали ничего, но даже таким инструментом не каждый админ умеет нормально пользоваться.
Локи имеет право на жизнь.
creker
Ну да. Я писал с позиции, что сбор логов настроен нормально и в систему попадает все как надо. Тут конечно можно накосячить сильно. Проще просто не увлекаться с попытками парсить логи, а тупо лить как есть и опираться на индексы эластика, чтобы в них найти нужное.
Про ненужность эластика для такой простой задачи как логи я тоже постепенно прихожу и неоднократно видел блог посты других с подобным мнением. Даже простейшая конфигурация требует дохера ресурсов и взамен дает инструмент, возможности которого используются на жалкие доли процента. А разбираться с его индексами, шардами и настраивать ротейт адекватный это то еще удовольствие.
Локи хорош тем, что с этой позиции его похоже и сделали. Для логов достаточно грепа, а локи это централизованный и параллельный греп, по сути.