

М.Видео-Эльдорадо поддерживает более сотни разных систем. Набор необходимых сервисов отличается для сотрудников разных должностей и даже разных функциональных обязанностей. Управлять таким парком, организовывать уровни доступа к разным продуктам – сложная задача.
Мы решили разработать специальное приложение, при помощи которого коллеги могли бы выполнять свои обязанности централизованно, из одного окна. Помимо удобства от пользователей была еще одна вводная - каждая продуктовая команда хотела иметь свой собственный, независимый от других, релизный цикл.
Так появилась идея: разработать единое приложение, позволяющее выкатить в продуктив свою систему, не согласуясь с другими командами и не ожидая тестирования с их системами. Пользователям такое приложение удобно, поскольку позволяет получить доступ только к тем системам, которые им реально необходимы.
Что такое SEW
SEW (Single Employee Workspace), написанное на Angular, работает как единое целое, но позволяет собирать «микро-фронтенды», каждому из которых соответствует свой микро-сервис. Выбор сервисов определяется при авторизации сотрудника и соответствует его функциональным обязанностям. Использовать SEW можно или через браузер, или на мобильном устройстве как приложение.
Приложение – объединяет в одном интерфейсе сразу несколько систем, которые необходимы сотруднику. И мы для работы над SEW выбрали монорепозиторий. Кому-то такое решение покажется неожиданным, но ниже объясним свои резоны.
Как мы выбирали репозиторий

Есть масса возможных вариантов репозиториев. Монорепозиторий, субмодульный репозиторий, мультирепозиторий и другие.
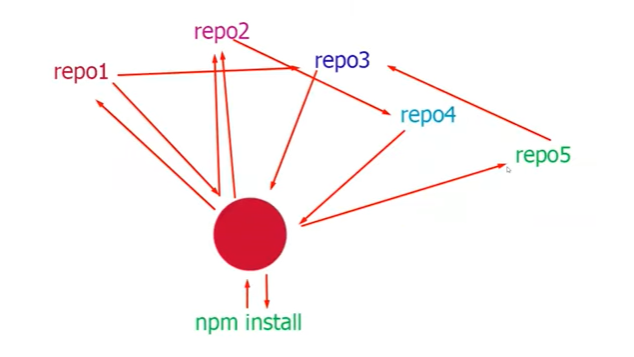
Субмодульные репозитории (см.выше) неудобны тем, что, когда необходимо подтянуть зависимости проекта, установить какие-то пакеты, необходимо обращаться не к одному репозиторию, а к множеству. Каждый из них общается с другими и проводит сравнение версий, прежде чем вернуть что-то назад. Такая схема обычно применяется там, где используются стейт-машины (state machine).
В работе с субмодульными репозиториями существует множество подводных камней. Например, зачастую не удается предоставить доступ к нему другим лицам, что обычно выливается в постоянные обращения к чату девопсов или управляющих репозиторием администраторов.
Свои недостатки имеет и монолитная модель репозитория. Внутри он разбит на изолированные блоки – более мелкие репозитории, в каждом из которых хранится код фронтенда, бэкенда, какие-то контейнеры, инструменты администрирования и пр. В том числе и отдельные репозитории с ограниченным доступом.
Такое решение часто вызывает проблемы на этапах установки, развертывания, так как приходится использовать тоннели и проксирование, для того чтобы перемещаться из одного репозитория в другой, получать соответствующие доступы и пр.
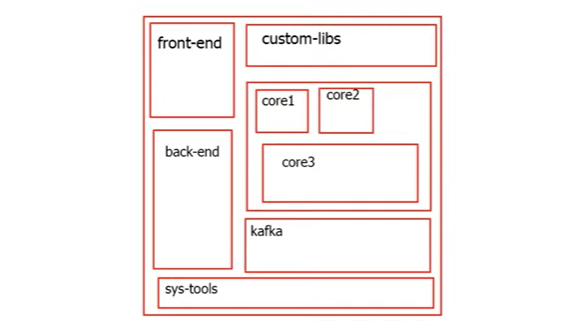
Монолитная модель репозитория, которую также многие используют, представляет собой огромный репозиторий с кучей мелких репозиториев внутри, где содержатся и фронтенд и бэкенд, управление версиями, кастомными библиотеками, контейнеры, админские тулзы, безопасность (core и управление доступами) и далее.
Что под капотом
Позади всей инфраструктуры у нас стоит платформа разработки веб-приложений Angular. Есть мнение, что это одно из лучших на данный момент решений для создания одностраничных приложений (кажется именно с этого места можно начинать холивар).

Кроме того, мы используем решение NX от Nrwl, с помощью которого и поддерживаем наш репозиторий. NX предоставляет большой набор средств для настройки, конфигурирования и пр. Инструменты для smoke test мы создаем сами, используя для этого Cypress.
На бэкенде мы используем паттерн Backend For Frontend (BFF), в основе которого лежит Node.js и фреймворк Nest. Он достаточно прост в изучении для тех, кто пишет на Angular.
Также мы применяем технологию PWA (Progressive Web App). Она помогает работать на тех объектах, – например, складах – где периодически может пропадать доступ к сети, в то время как сотруднику необходимо использовать приложение. В этом случае оно кэшируется с помощью service worker, и это позволяет, допустим, продолжить сканирование штрих-кодов даже при отсутствии соединения с дата-центром.
Наконец, среди наших инструментов нашлось место для Redis, которую сложно назвать фронтенд-решением. Однако для наших задач оказалось очень удобно держать в ней промежуточные данные – чеки, наряды, заказы и все прочее, требующее временного хранения.
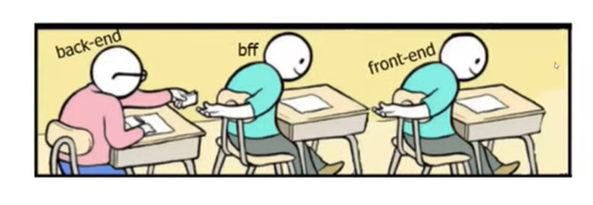
Зачем нам фронтенд с BFF
Обычно схема взаимодействия фронтенд-бэкенд выглядит примерно так, как изображено на иллюстрации ниже.

В основе паттерна Backend For Frontend лежит идея создания некоего тоннеля между Java-сервером и Angular-приложением. Именно наличием такого тоннеля BFF отличается от классической схемы взаимодействия фронтенд-бэкенд. Это дает ряд преимуществ, среди которых безопасность обмена данными и сокрытие от клиента адреса production-сервера.
При возврате данных с сервера на уровне BFF мы можем сделать маппинг, убрать все лишнее и преобразовать данные так, чтобы их удобно было передать во фронтенд.

С помощью BFF от клиента можно скрыть и другую информацию. Допустим, ему нужно отдать номер телефона. Но объект на сервере помимо этого номера содержит и другие данные профиля – ФИО, адрес, возраст, ID и пр.

После маппинга на BFF клиент получает ровно то, что требовалось, и ничего лишнего. Помогает это и при загрузке больших объемов данных, например, ордеров с сотнями свойств. Когда клиент запрашивает выборку сотни таких ордеров, лишние данные не проходят дальше BFF и задержка ответа значительно сокращается.
Еще одним плюсом является наличие у нас макета ошибок. Вне зависимости от того, какие ошибки отправляет сервер бэкенда, мы собираем их и отдаем фронтенду в нужном формате. Это позволяет построить на фронтенде свою модель ошибок, легко менять в них текст и пр.
Наконец, паттерн BFF помогает нам решать задачи логирования – использовать «перехватчики» Java Interceptor и визуализировать данные в Grafana и Jaeger. Это делает поиск ошибок в реальном времени по-настоящему удобным.
Процесс деплоя
Так как мы используем монорепозиторий, хранится в нас все в одном месте – и тестирование, и Node.js с Nest, и приложения на Angular. Деплой на стенд или в прод происходит откуда-то из этой «кучи». Почему мы не используем разные репозитории под каждую задачу, как все нормальные люди? На то есть причины.


Давайте рассмотрим процесс попадания отдельных Angular-приложений на деплой. Каждое приложение характеризуется своей версией и состоянием.
Для деплоя нам достаточно выбрать имя приложения и веткуGit, из которой оно будет собираться. В момент деплоя мы используем специальный эндпоинт, который, в зависимости от того, куда отправляется приложение, собирает необходимые ему конфигурационные ссылки, идентификаторы и пр.
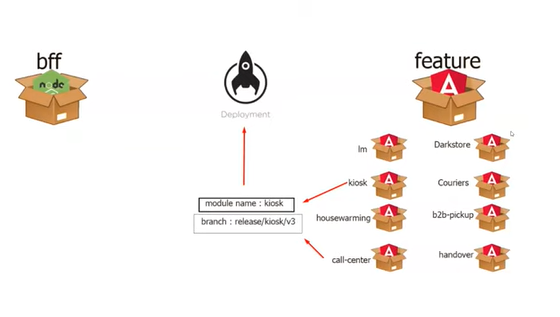
Все это позволяет нам просто задать номер версии модуля и задеплоить его отдельно от остальных, которые останутся нетронутыми. В большинстве же случаев использования монолитных или мульти-репозиториев приложение придется собирать полностью и зачастую проводить общие автотесты, даже если обновлению подвергся отдельный модуль.

Людям, погрузившимся в пучину вариантов репозиториев, рано или поздно приходит гениальная идея вернуться к идее монорепозитория. Довольно часто можно встретить следующую концепцию (см.ниже).

На предыдущей схеме монорепозитория был представлен вариант при котором можно было задать версию (например доставка курьером) и задеплоить отдельно. Именно он будет, как приложение на проде обновлен. Все другие останутся нетронутыми. В примере мультирепо (монолит) придется собирать приложение целиком.
Допустим вся приведенная выше куча создала релизную ветку с каким-нибудь названием и проходит регресс в течение нескольких дней (или будут автотесты, но все равно время потрачено). И тут на проде случается баг. Допустим, касается какой-нибудь важной библиотеки. Версию меняют, фичу доливают в релизную ветку, но тк это затрагивает UI (англ. user interface), желательно бы сделать это все заново. И снова регресс, автотесты, смотрим за ошибками, теряя кучу времени.
Побочные эффекты
Прекрасная картина эффективной разработки таит в себе несколько недостатков. И один из них связан с размерами node_modules. Впрочем, взглянуть на это можно и иначе.

Допустим, у нас есть 40 приложений. Устанавливать модули придется на каждое из них. И контейнер, где это все было бы задеплоено, будет вынужден не один раз получить нужные версии и установить все, что нужно, а повторить эту процедуру все 40 раз. Причем весить такой контейнер будет даже больше, чем в нашем случае.

Более серьезной проблемой является первый запуск проекта из монорепозитория. Но она актуальна лишь при серьезных ограничениях по объему оперативной памяти сервера. Это происходит из-за того, что в нашем случае получается тяжелым, и индексирование занимает много времени. То же самое случается и при смене веток различных версий. Мы для себя решили, что сможем с этим жить, так как преимуществ нашего подхода гораздо больше.

О минусах
Наш подход к строительству бэкенда влечет за собой некоторые неудобства, о которых можно честно рассказать. Например, оказалось достаточно сложно управлять системой контроля версий и искать нужные коммиты в конкретные модули или задачи. Помочь в этом может жесткий стандарт для названий коммитов, которым бы пользовались абсолютно все разработчики.
Кроме того, при нашей архитектуре все модули пользуются едиными версиями пакетов. Это может стать проблемой, если одному из 40 приложений понадобится версия, отличная от установленной.
К недостаткам можно отнести и очень большой размер конфигурационного файла angular.json. Но с этим мы рассчитываем справиться в ближайшем будущем – попробуем разбить его на отдельные элементы для каждого из модулей.
О плюсах
Количество преимуществ, которые дает нам наше решение, значительно перевешивает количество недостатков. Одним из основных плюсов является то, что тестирование в нашем случае касается только одного конкретного модуля и тестировщику не нужно проверять никаких зависимостей, которые могли бы повлиять на работу соседних модулей.
То же касается и разработки. Когда работа ведется специалистом над одним модулем, она не затрагивает соседние, над которыми трудятся другие люди. И это раз в десять снижает потенциальную возможность конфликтов из-за несогласованных действий.
Добавим сюда максимально удобный деплой, который в отрасли встретишь не часто. Возьмем, например, откат. Реализовался какой-то невероятный сценарий и что-то поломалось после запуска новой версии, которую теперь надо срочно откатить.
Достаточно зайти в интерфейс, найти имя модуля и выбрать предыдущую версию. Пять секунд – и предыдущая версия на проде. Трогать при этом все приложение нет никакой необходимости.

P.S. С радостью ответим на любые ваши вопросы в комментарии к этой статье. И да, если вы вдруг в поиске работы, у нас для вас хорошие новости по ссылке.
K1aidy
Не зная структуры и зависимостей фронта сложно судить, но по прочтению статьи показалось, что реализация микрофронтов через балансер исключила бы у вас еще несколько минусов