
После прошлого поста про базовые концепции аллокаторов хотелось бы всё-таки посмотреть на что-то настоящее, из жизни, и заодно доказать, что ни Андрей Александреску, ни я не врём, и что-то из рассказанного и правда используется в продакшене. Потому посмотрим на несколько популярных аллокаторов и попытаемся что-нибудь в них понять.
dlmalloc
dlmalloc или Doug Lea allocator является одной из реализаций стандартного malloc. По мнению автора хороший general-purpose (не хочется менять на какой-то русский аналог, уж очень хорошо звучит) аллокатор должен прийти к компромиссу среди нескольких важных аспектов:
Максимальная совместимость с любыми другими методами управления памятью и их использованием.
Максимальная портируемость: c одной стороны аллокатор обязан как можно меньше зависеть от особенностей системы, но с другой стороны стараться использовать её положительные стороны ради оптимизации.
Минимальное ресурсопотребление: аллокатор обязан требовать у системы как можно меньше памяти и должен стараться минимизировать фрагментацию памяти. Этот пункт, кстати, ставится в приоритет среди всех остальных задач.
Минимальное время работы:
malloc,reallocиfreeв среднем должны работать как можно быстрее.Гибкость: должны быть предусмотрены возможности настройки различных параметров аллокатора (через
#defineили mallopt).Максимизация локальности памяти: выделение блоков памяти, которые часто используются вместе, рядом друг с другом.
Отслеживание ошибок. Да, невозможно сделать детекцию ошибок любого рода у general-purpose аллокатора, но трекать какие-то базовые вроде double free или use after free было бы хорошо.
Это должен быть действительно general-purpose аллокатор: абсолютно неважно, где вы собираетесь его использовать, он должен стабильно «хорошо» работать при любых размерах выделяемой памяти и нагрузке.
Есть два основных элемента в алгоритме dlmalloc, которые в той или иной форме имели место в течение всего его развития:
-
Теги на границах блоков памяти.
По обе стороны от выделенного блока хранился его размер, причём в размере перед блоком также есть его статус (занят/свободен). Это добавляло две полезные возможности: очень легко объединять соседние свободные блоки в один большой, а также просто обходить все подряд лежащие блоки в любом направлении (вперёд/назад). Позже, в силу того, что во время использования блока программой эти теги не нужны, их решили убрать и хранить только для свободных участков памяти (правда, тогда не очень понятно, откуда берётся размер при удалении). С одной стороны немного уменьшилось потребление памяти, с другой — чуть-чуть замедлилась работа аллокатора и пропала возможность проверки на corruption.
-
Группировка свободных блоков по размерам.
Есть фиксированное множество из 128 размеров блоков, по которым производится поиск наиболее подходящего (обычно это ближайший размер сверху) блока. Кстати при хранении свободных блоков в dlmalloc задействован freelist, хранящий указатель на соседние для данного размера блока участки внутри самих блоков, потому все дополнительные расходы для каждого отдельного размера – всего один указатель на первый блок этого размера.
В случае систем семейства UNIX чаще всего основным способом выделения памяти внутри является sbrk, однако при достижении некоторого порога (по умолчанию 1Мб) используется mmap. Эту границу можно изменить с помощью mallopt.
Ещё внутри применяется 2 эвристики:
Объединение свободных блоков в бо́льший блок происходит не сразу, а через какое-то время, ведь велика вероятность, что раз такой блок только что удалили, то скоро попросят что-то такого же или близкого размера обратно.
Иногда при нехватке блоков маленького размера большой свободный блок просто делится на блок нужного размера и оставшуюся часть. Потому такой блок стали делить сразу на много блоков поменьше, чтобы не тратить время не «откусывание» по чуть-чуть несколько раз в будущем, т.к., вероятно, пользователю понадобится ещё несколько блоков похожего размера.
Конечно стоит помнить, что эффективность таких оптимизаций зависит от стоимости операций вроде разбиения или объединения на конкретной системе. Это в целом и есть проблема general-purpose аллокатора: он не знает никакой специфики программы. Но вообще это довольно хорошие решения для программ, которые, например, выделяют память с маленьким множеством размеров. Раньше были какие-то эвристики, следящие за использованием аллокатора и делающие вывод, стоит ли использовать ту или иную оптимизацию, но с ростом нагрузки эту часть выпилили, т.к. она стала сильно тормозить.
Это всё, конечно, хорошо, но у dlmalloc есть проблемы с выполнением в нескольких потоках, потому через какое-то был реализован ptmalloc и ptmalloc2, которые стараются бороться с различными гонками и проблемами синхронизации. Позже он получил своё развитие в лице nedmalloc, который побеждает ptmalloc2 по всем фронтам.
jemalloc
jemalloc — реализация malloc, заменившая собой phkmalloc и разработанная для оптимизации поведения при использовании в многопоточных программах на многопроцессорных системах.
Предостережение
После прочтения статьи формируется лишь очень смутное понимание того, как собственно организована память. Понятно, что есть чанки (по 2Мб), которые делятся на отрезки поменьше. Наличие чанков зависит от того, сколько памяти вы запросили. Но почему-то эти же чанки называются аренами (или тут имеется в виду именно отрезок/run?), количество которых зависит от количества процессоров. Может быть это разные арены? Тогда термин «арена» означает именно глобальную арену, из которой происходит выделение чанков. Как это происходит, к сожалению, не упоминается :(
В связи с этим, если вы знаете какой-то источник по устройству jemalloc, который поможет распутать этот клубок, поделитесь им пожалуйста в комментариях.
Основные моменты:
При выполнении в однопроцессорной системе используется лишь одна глобальная арена, с помощью которой и происходят все аллокации. При использовании в многопроцессорной системе используется 4*(кол-во процессоров) арен. При такой реализации нужно было решить, как же назначать арену потоку. Одним из предлагаемых решений было использование хеширования (например, от id потока), прямо как в хеш-таблицах при определении бакета, но было решено назначать по очереди циклически, чтобы добиться большей равномерности при использовании.
В прошлых версиях было замечено, что использование общей для арен кеш-линии, хранящей метаинформацию, серьёзно замедляет работу аллокатора. Решением может быть выравнивание арен при аллокации так, чтобы избежать false-sharing’а кеш-линий.
Всё управление памятью происходит с помощью чанков и отрезков (runs) вместо целых страниц. Чанки могут делиться на отрезки или наоборот: объединяться для хранения больших объектов. В начале каждого отрезка есть битмап с метаинформацией.
Все выделяемые размеры округляются к ближайшему сверху размеру из разрешённого множества. Вообще все размеры делятся на категории:
Small: tiny(4б, 8б); quantum-spaced(16б, 32б, 48б, …, 480б, 496б, 512б); sub-page(1Кб, 2Кб).
Large(4Кб, 8Кб, 12Кб, …, 1016Кб, 1020Кб, 1Мб).
Huge(2Мб, 3Мб, 4Мб, …).
Интересно, что вся метаинформация о huge аллокациях хранится с помощью красно-чёрного дерева.
Также jemalloc хорошо умеет в минимизацию фрагментации. Вот какой-то кейс (к сожалению, к оригинальной ссылке добраться не удалось) о том, как Firefox уменьшили фрагментацию на 22%.
tcmalloc
tcmalloc — «fast multi-threaded malloc implementation» от Google.
Реализация делится на три части: front-end, middle-end и back-end.

Front-end – per-thread и per-CPU кеши (в зависимости от режима) для быстрых операций выделения/удаления памяти. При новом запросе на аллокацию front-end ищет в своём кеше подходящий блок памяти. Если таковой отсутствует, то идёт в middle-end за новой порцией данных, чтобы заполнить свой кеш. Если же и тут ничего не находится (или запрошенный размер превышает некоторую величину, из-за чего не может быть закеширован ни на одном из уровней), запрос отправляется в back-end. Уже можно было заметить, что авторы аллокаторов любят иметь какое-то множество размеров блоков, с которыми аллокатор работает. tcmalloc не исключение: тут есть 60-80 различных классов. В зависимости от режима, хранятся либо заголовки с метаинформацией для каждого класса, а потом сами данные, либо freelist для каждого класса.
Middle-end отвечает за актуальность кешей во front-end. Он состоит из двух частей: transfer cache - хранит массив с указателями на блоки свободной памяти и умеет быстро вставлять/удалять из него данные, central freelist - freelist, откуда берётся память в случае, если transfer cache не смог ничего предоставить.
У back-end три основные задачи:
управление большими блоками памяти;
получение больших блоков из ОС, когда не получается ответить на запрос с помощью кешей двух прошлых уровней;
возврат неиспользуемой памяти в ОС.
Есть два режима работы:
-
Legacy pageheap – управление блоками памяти размерами tcmalloc pages (4Кб, 8Кб, 32Кб, 256Кб). Из себя представляет массив с 256-ю ячейками, в каждой из которых хранится freelist. В k-ом freelist'е хранятся блоки размерами в k страниц tcmalloc:

Legacy pageheap режим. 256-я ячейка предназначена для блоков, размер которых больше размера 255 страниц.
Hugepage Aware pageheap – управление памятью чанками бо́льших размеров (точнее размера hugepage, которая на x86 обычно 2Мб). Состоит из filler cache (что-то похожее на legacy pageheap режим), region cache (работа с несколькими подряд идущими hugepages и укладка данных в них для достижения непрерывности) и hugepage cache, управляющий памятью для блоков размерами больше размера hugepage (тут есть некоторое пересечение с обязанностями region cache, но последний включается в рантайме только в определённых ситуациях, если становится понятно, что это оптимальнее).
Вообще получился довольно гибкий аллокатор, имеющий не только разные режимы, оптимизации в зависимости от архитектуры, на которой он запускается, и поддержку последних стандартов C++, но и красивенькое читаемое описание. Приятно.
mimalloc
mimalloc – аллокатор от Microsoft, предназначенный для маленьких короткоживущих аллокаций. Адресное пространство разбивается на «mimalloc pages» размером либо 64Кб, либо 512Кб. Каждый из таких блоков может разбиваться на меньшие участки равных размеров.
Тут тоже хранится freelist для свободных блоков, причём есть один глобальный (для каждого «интересного» размера из множества подходящих размеров) и есть локальный freelist для каждой страницы. Это позволяет уменьшить фрагментацию и улучшить локальность данных. Более того, вместо одного локального freelist хранится два (больше freelist’ов богу freelist’ов!): один — для thread-local free операций, второй — для free операций, выполняемых в других потоках (т.е. выделили в одном потоке, удалять хотим в другом). Так авторы упрощают реализацию синхронизации между потоками, из-за чего получается использовать лишь «тривиальные» (лол) методы.
Внутри также можно найти битмап свободных блоков.
При аллокациях больше 512Кб всегда используется mmap/munmap. Такой порог, кажется, маловат. Вот ребята из Clickhouse пробовали mimalloc у себя и получили существенное замедление. Ещё реализованы разные моды для дебага аллокатора, что, ожидаемо, замедляет его, но позволяет найти некоторые проблемы.
В репозитории есть бенчмарки, по которым авторы утверждают, что mimalloc побеждает по перфомансу (память и время) другие известные аллокаторы (jemalloc, tcmalloc и др.).
Интересно, что он работает не только под windows, но и под UNIX-системами, а ещё есть предложение использовать mimalloc при удалении GIL из python.
tbb::scalable_allocator
Ещё один популярный аллокатор, на этот раз от компании Intel. Устройство схоже с tcmalloc за некоторыми поправками. Есть per-thread кеши, которые (уже в который раз) являются массивом freelist’ов для различных размеров. Также есть глобальный freelist. Большие блоки (в источнике 2007 года — от 8Кб, но заявлялось, что планируется повысить до 64Кб) выделяются/удаляются напрямую из ОС. Блоки меньших размеров не возвращаются ОС никогда. Аллокатор старается максимально переиспользовать память, и только в случае, если он не справился найти подходящий блок в собственных закромах, получает от ОС новый участок памяти, который не вернётся обратно до завершения работы приложения. Как и в jemalloc, размеры выделяемой памяти округляются вверх к ближайшему подходящему размеру, что повышает локальность данных.
Вообще, аллокатор позиционируется как решение, оптимизированное под процессоры Intel. Каких-то конкретных указаний на это не обнаружилось, но, подозреваю, это выражается в значениях границ для различных операций.
LowFat
LowFat – единственный в данном списке debug-аллокатор, спроектированный для отслеживания различных out-of-bounds ошибок. Несмотря на то, что архитектурно он стоит поодаль от расмотренных ранее, встречаются и знакомые идеи. Например, всё адресное пространство программы делится на большие (на самом деле очень большие) регионы памяти, в каждом из которых хранятся объекты конкретного размера (1-16 байт, 17-32 и т.д.). Первый регион отвечает за различную метаинформацию, остальные — за само хранение. Каждый объект выравнивается до максимального размера в регионе (т.е. 13 байт до 16, например), что позволяет по указателю выяснить всю нужную информацию об объекте. Содержит в себе очень много различных проверок, которые можно отключать за ненадобностью. Конечно, из-за такого контроля над поведением программы он даёт некоторую просадку по эффективности (до 1.5 раз), но при включении оптимизаций (с небольшими жертвами функциональности) оверхед можно снизить до 10%.
Настораживает то, что авторы оставили просто огромное количество предостережений, но, почитав, можно понять, что ничего критического они в себе не несут и просто просят с осторожностью следить за своими действиями при использовании.
Allocator
Ну вот так он называется ¯_(ツ)_/¯. Это не что-то очень известное, но какое-то количество звезд и форков на гитхабе он имеет и скорее полезен в обучающих целях, потому что это очень-очень легко читаемая реализация freelist (в отличие от чего-то более промышленного).
Предытоги
Всегда интересно посмотреть на бенчмарки различных решений, ведь обычно это даёт некоторую информацию.
Во-первых, почти всегда jemalloc показывает результаты лучше (или по крайней мере не хуже) других аллокаторов: например, раз, два или три.
Во-вторых, интересно, что Google утверждает, что эффективность tcmalloc растёт при росте «поточности» приложений, однако мы видим результаты в пользу других аллокаторов:
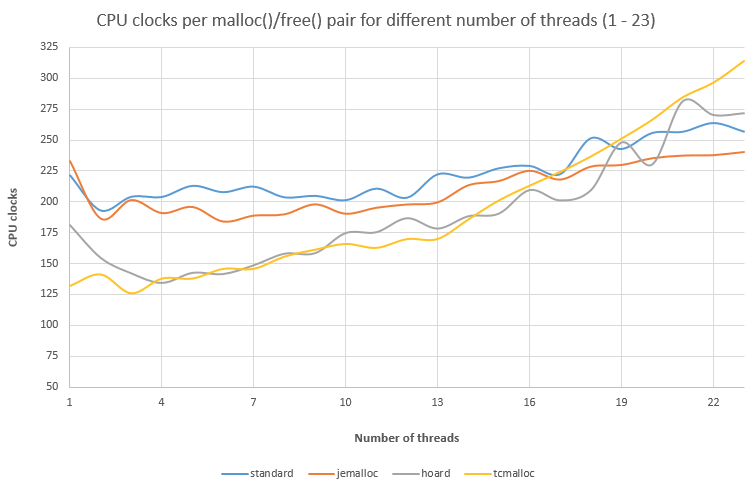
Найти другие замеры для подтверждения/опровержения не удалось, но этого хватает, чтобы задуматься.
В-третьих, по заверения Microsoft mimalloc разносит всё и вся почти по всем проводимым (а их немало) бенчмаркам. Можно даже найти похожие, пусть и не такие впечатляющие результаты. Может даже не врут.
Итоги
Когда я только начинал погружаться в тему аллокаторов, было сложно найти хоть как-то организованные материалы о том, какие они вообще бывают, как устроены и для чего, собственно говоря, они устроены именно так. Надеюсь, этот небольшой ликбез поможет интересующимся сложить некоторое представление о том, что вообще происходит в сфере управления памятью в C++.
И в качестве повторения кратко отметим самые частые практики в упомянутых аллокаторах:
Использование freelist (глобальный на весь аллокатор).
Выделение памяти аренами/страницами/регионами, которые позже разбиваются на отрезки поменьше.
Ещё freelist’ы (по одному на арену/регион/страницу/ещё какое-то удобное для вас слово).
Использование множества «разрешённых» размеров или их классификация по размерам. Округление размеров в запросах к ближайшему сверху.
Да, опять freelist’ы (для каждого размера).
Кеширование для каждого потока/процесса (в качестве кеша, например, freelist).
Использование некоторой границы, размеры выше которой сразу ходят в ОС.
P.S.
Ещё немного ссылочек:
Hoard allocator — A Fast, Scalable, and Memory-efficient Malloc for Linux, Windows, and Mac.
kmalloc – выделение памяти для объектов, меньших размера страницы в ядре Linux.
CAMA – предсказуемый cache-aware аллокатор.
ottomalloc – основанный на mmap аллокатор, спроектированный для получения случайно распределённой памяти.
snmalloc — очередной high-performance аллокатор.
LRMalloc — lock-free реализация malloc.
Lockless — ещё один аллокатор, оптимизирующий поведение в многопоточных приложениях.
SLAB — концепция, используемая для уменьшения фрагментации в аллокаторах.
Комментарии (7)

dmitry_rozhkov
12.01.2022 14:48+2Во-вторых, интересно, что Google утверждает, что эффективность tcmalloc растёт при росте «поточности» приложений, однако мы видим результаты в пользу других аллокаторов
Этот график из 2018 года. Гугловский tcmalloc был анонсирован только два года назад, когда в него были добавлены restartable sequences. На графике речь идёт скорее всего о tcmalloc из gperftools. Лучше померить производительность самостоятельно.

Kelbon
Это вообще не то что в С++ подразумевается под аллокаторами. Это скорее какие то системные внутренние хрени, тем более с управлением через #define...
Аллокаторы в С++ это абстракция(а тут как раз конкретные реализации на уровне системы рассмотрены), абстракция эта применяется в основном в стандартных контейнерах С++, где аллокатор становится частью типа на компиляции и полностью скрыт от пользователя, как и любое ручное управление памятью в С++
template<typename T, typename Allocator = std::allocator<T> >
class vector;
Вот что такое аллокатор в С++, а не этот ужОс из статьи
Dasfex Автор
Хотелось бы отметить два момента: расмотренные аллокаторы всё же называются аллокаторами, более того, это довольно стандартные для мира C++ вещи (хотя местами может даже и для C). Да, это прослойка между стандартной библиотекой и системой, но нельзя же утверждать, что аналогичные методы не применимы в проектировании ваших аллокаторов, но уже более высокоуровнево?)
Задачей стояло пройтись по известным аллокаторам и разобрать их концептуально. С технической точки зрения они разобраны уже во множестве источников, потому повторяться не хотелось бы. Если у вас есть какие-то ссылки на источники про аллокаторы в вашем понимании, можете поделиться. Разберёмся и с ними.
cross_join
Аллокаторы рекомендуются к использованию во всех template-объявлениях, если они представляют собой библиотеку. Никто ведь не знает заранее, когда, кем и с какой целью твой библиотечный код будет использован. По умолчанию просто ставим std::allocator с чувством заботы о ближних.
Kelbon
сомнительное предложение, я тут библиотеку по работе с вариадик шаблонами сделал, куда аллокатор лепить?) Ну или скажем локфри очередь, попробуй туда прилепи аллокатор...
cross_join
Встречный вопрос: "Как использовать вашу библиотеку с custom allocators?"
Обычно аллокатор вставляют в заголовок. Возможно, ваши классы совсем не работают с памятью, ничего не создают и не удалают, тогда, действительно, можно обойтись без него.