
В статье показано как настроить мониторинг веб-приложения на Rust. Приложение выставляет наружу Prometheus метрики, которые визуализируются с помощью Grafana. Мониторинг осуществляется для проекта mongodb-redis demo, детально рассмотренного здесь. В итоге получена следующая архитектура:
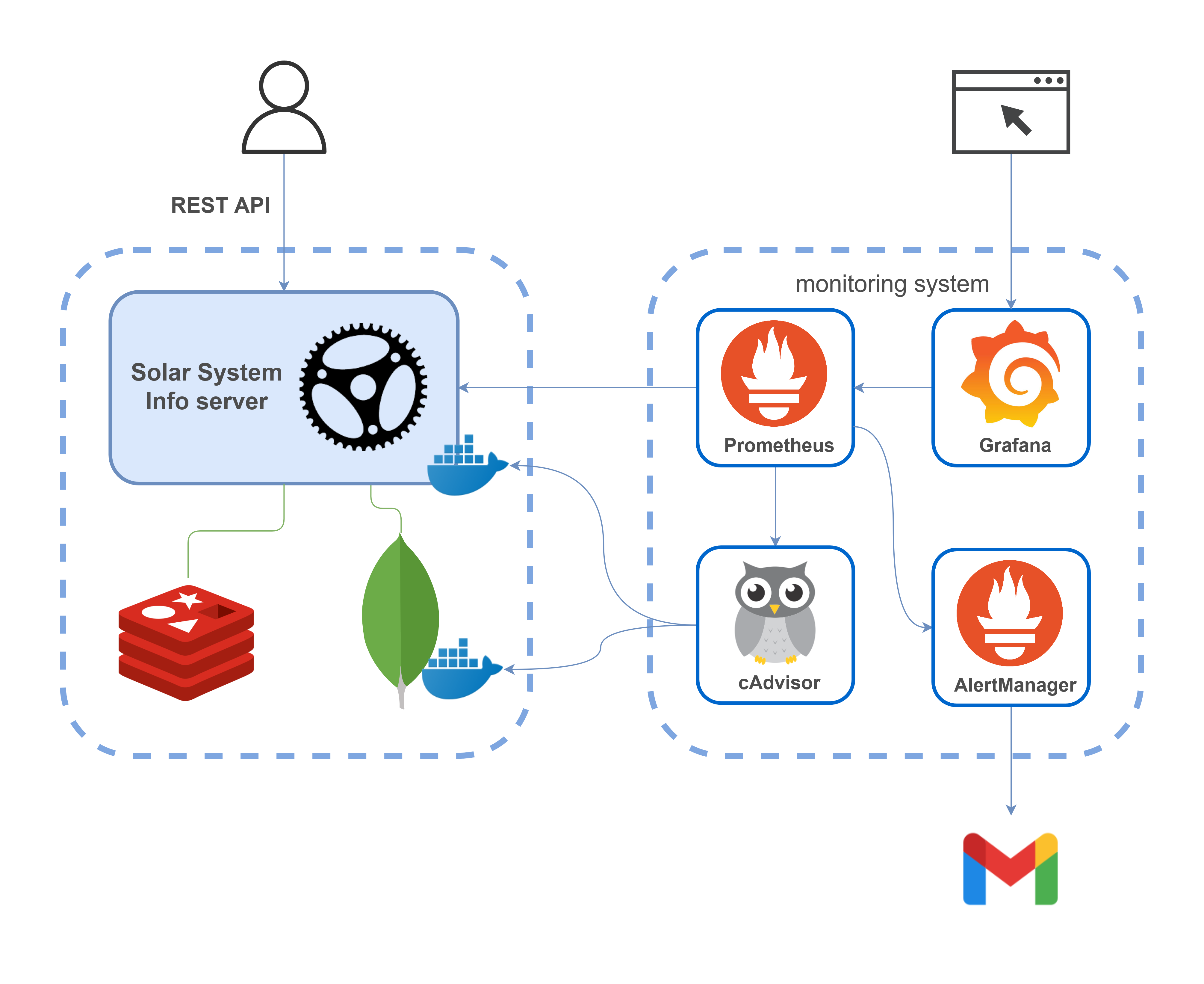
Система мониторинга включает:
- Prometheus — платформа для мониторинга, которая агрегирует метрики в режиме реального времени и сохраняет их в базу данных временных рядов (time series database).
- Grafana — платформа для анализа и визуализации метрик
- AlertManager — приложение, которое обрабатывает уведомления (alerts), отправляемые Prometheus сервером (например, когда в вашем приложении что-то идёт не так), и оповещает пользователя с помощью электронной почты, Slack, Telegram и т. д.
- cAdvisor — платформа для пользователей, использующих контейнеризацию, которая предоставляет данные по использованию ресурсов и параметрам производительности запущенных контейнеров. (На самом деле cAdvisor собирает данные со всех Docker контейнеров на схеме)
Для запуска всех этих инструментов вы можете воспользоваться следующим:
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: always
ports:
- '9090:9090'
volumes:
- ./monitoring/prometheus:/etc/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.external-url=http://localhost:9090'
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
ports:
- '3000:3000'
volumes:
- ./monitoring/grafana/data:/var/lib/grafana
- ./monitoring/grafana/provisioning:/etc/grafana/provisioning
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: admin
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
ports:
- '9093:9093'
volumes:
- ./monitoring/alertmanager:/etc/alertmanager
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--web.external-url=http://localhost:9093'
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
restart: always
ports:
- '8080:8080'
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:roОтдача Prometheus метрик Rust приложением
Отдача метрик имплементируется с помощью крейта prometheus.
Существует четыре типа Prometheus метрик: счётчик (counter), датчик/измеритель/шкала (gauge), гистограмма (histogram), сводка (summary). Использование первых трёх из них будет описано в статье (в настоящее время крейт не поддерживает сводки).
Создание метрик
Метрики могут быть созданы и зарегистрированы следующим образом:
lazy_static! {
pub static ref HTTP_REQUESTS_TOTAL: IntCounterVec = register_int_counter_vec!(
opts!("http_requests_total", "HTTP requests total"),
&["method", "path"]
)
.expect("Can't create a metric");
pub static ref HTTP_CONNECTED_SSE_CLIENTS: IntGauge =
register_int_gauge!(opts!("http_connected_sse_clients", "Connected SSE clients"))
.expect("Can't create a metric");
pub static ref HTTP_RESPONSE_TIME_SECONDS: HistogramVec = register_histogram_vec!(
"http_response_time_seconds",
"HTTP response times",
&["method", "path"],
HTTP_RESPONSE_TIME_CUSTOM_BUCKETS.to_vec()
)
.expect("Can't create a metric");
}В примере кода выше метрики добавляются в реестр по умолчанию. Также возможно зарегистрировать их в кастомном реестре (пример).
Счётчик
Если требуется посчитать все входящие HTTP запросы, то возможно использовать тип IntCounter. Но более полезно видеть не только общее число запросов, но также некоторые дополнительные измерения, такие как path и HTTP метод. Это можно сделать с помощью IntCounterVec; метрика HTTP_REQUESTS_TOTAL этого типа используется в кастомном Actix middleware таким образом:
Использование метрики HTTP_REQUESTS_TOTAL
let request_path = req.path();
let is_registered_resource = req.resource_map().has_resource(request_path);
// this check prevents possible DoS attacks that can be done by flooding the application
// using requests to different unregistered paths. That can cause high memory consumption
// of the application and Prometheus server and also overflow Prometheus's TSDB
if is_registered_resource {
let request_method = req.method().to_string();
metrics::HTTP_REQUESTS_TOTAL
.with_label_values(&[&request_method, request_path])
.inc();
}После того, как вы сделаете несколько запросов к API, появится что-то похожее на:
Выходные данные метрики HTTP_REQUESTS_TOTAL
# HELP http_requests_total HTTP requests total
# TYPE http_requests_total counter
http_requests_total{method="GET",path="/"} 1
http_requests_total{method="GET",path="/events"} 1
http_requests_total{method="GET",path="/metrics"} 22
http_requests_total{method="GET",path="/planets"} 20634Каждая выборка метрики содержит лейблы (атрибуты метрики) method и path, что позволяет Prometheus серверу различать выборки.
Как показано в фрагменте выше, запросы к GET /metrics (эндпоинт, с которого Prometheus сервер собирает метрики приложения) также учитываются.
Датчик
Датчик отличается от счётчика тем, что его значение может уменьшаться. Пример датчика показывает сколько клиентов в настоящий момент подключены с помощью SSE. Используется следующим образом:
Использование метрики HTTP_CONNECTED_SSE_CLIENTS
crate::metrics::HTTP_CONNECTED_SSE_CLIENTS.inc();
crate::metrics::HTTP_CONNECTED_SSE_CLIENTS.set(broadcaster_mutex.clients.len() as i64)При переходе на http://localhost:9000 в браузере будет установлено SSE соединение, что инкрементирует значение метрики. После этого выходные данные станут такими:
Выходные данные метрики HTTP_CONNECTED_SSE_CLIENTS
# HELP http_connected_sse_clients Connected SSE clients
# TYPE http_connected_sse_clients gauge
http_connected_sse_clients 1Broadcaster
Для имплементации датчика числа SSE клиентов потребовался рефакторинг кода приложения и реализация broadcaster'а. Он сохраняет всех подключённых (с помощью функции sse) клиентов в вектор и периодически их пингует (с помощью функции remove_stale_clients), чтобы убедиться, что соединение по-прежнему активно, в противном случае удаляет отсоединённых клиентов из вектора. Broadcaster позволяет открывать всего лишь одно Redis Pub/Sub соединение; сообщения из него отправляются (broadcasted) всем клиентам.
Гистограмма
В этом гайде гистограмма используется для сбора данных о времени ответа. Как и в случае со счётчиком запросов, трекинг осуществляется в Actix middleware; это реализует следущий код:
...
histogram_timer = Some(
metrics::HTTP_RESPONSE_TIME_SECONDS
.with_label_values(&[&request_method, request_path])
.start_timer(),
);
...
if let Some(histogram_timer) = histogram_timer {
histogram_timer.observe_duration();
};Полагаю, этот способ не очень точный (вопрос в том, насколько измеренное время ответа меньше реального), но тем не менее данные наблюдений будут полезны в качестве примера гистограммы и для её дальнейшей визуализации в Grafana.
Гистограмма принимает результаты наблюдений и подсчитывает их количество в конфигурируемых bucket'ах (есть bucket'ы по умолчанию, но скорее всего вам потребуется определить кастомные bucket'ы, подходящие к вашему use case); чтобы их сконфигурировать, было бы неплохо знать примерное рспределение значений определённой метрики. В этом приложении время ответа невелико, поэтому используется следующая конфигурация:
Bucket'ы для метрики времени ответа
const HTTP_RESPONSE_TIME_CUSTOM_BUCKETS: &[f64; 14] = &[
0.0005, 0.0008, 0.00085, 0.0009, 0.00095, 0.001, 0.00105, 0.0011, 0.00115, 0.0012, 0.0015,
0.002, 0.003, 1.0,
];Выходные данные будут выглядеть примерно так (показана только часть данных):
Выходные данные метрики HTTP_RESPONSE_TIME_SECONDS
# HELP http_response_time_seconds HTTP response times
# TYPE http_response_time_seconds histogram
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0005"} 0
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0008"} 6
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.00085"} 1307
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0009"} 10848
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.00095"} 22334
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.001"} 31698
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.00105"} 38973
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0011"} 44619
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.00115"} 48707
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0012"} 51495
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.0015"} 57066
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.002"} 59542
http_response_time_seconds_bucket{method="GET",path="/planets",le="0.003"} 60532
http_response_time_seconds_bucket{method="GET",path="/planets",le="1"} 60901
http_response_time_seconds_bucket{method="GET",path="/planets",le="+Inf"} 60901
http_response_time_seconds_sum{method="GET",path="/planets"} 66.43133770000004
http_response_time_seconds_count{method="GET",path="/planets"} 60901Данные показывают число наблюдений, попавших в определённые bucket'ы. Также предоставляются данные по общему числу и сумме наблюдений.
Системные метрики
process фича позволяет экспортировать метрики процесса, такие как использование процессора или памяти. Для этого нужно указать фичу в Cargo.toml. После этого вы получите что-то вроде:
Выходные данные метрик процесса
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 134.49
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1048576
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 37
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 15601664
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1636309802.38
# HELP process_threads Number of OS threads in the process.
# TYPE process_threads gauge
process_threads 6
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 439435264Обратите внимание, что крейт prometheus поддерживает экспорт метрик процесса в приложениях, запущенных на Linux (например, в таком Docker контейнере).
Эндпоинт для отдачи метрик
Actix сконфигурирован так, чтобы обрабатывать запрос к GET /metrics с помощью следующего хэндлера:
pub async fn metrics() -> Result<HttpResponse, CustomError> {
let encoder = TextEncoder::new();
let mut buffer = vec![];
encoder
.encode(&prometheus::gather(), &mut buffer)
.expect("Failed to encode metrics");
let response = String::from_utf8(buffer.clone()).expect("Failed to convert bytes to string");
buffer.clear();
Ok(HttpResponse::Ok()
.insert_header(header::ContentType(mime::TEXT_PLAIN))
.body(response))
}Теперь, после успешного конфигуриования приложения, вы можете получить все ранее описанные метрики выполнив запрос GET http://localhost:9000/metrics. Этот эндпоинт используется Prometheus сервером для получения метрик приложения.
Метрики отдаются в простом текстовом формате.
Настройка Prometheus для сбора метрик
Prometheus собирает метрики используя следующий конфиг:
Конфиг Prometheus для сбора метрик
scrape_configs:
- job_name: mongodb_redis_web_app
scrape_interval: 5s
static_configs:
- targets: ['host.docker.internal:9000']
- job_name: cadvisor
scrape_interval: 5s
static_configs:
- targets: ['cadvisor:8080']В конфиге определены две job'ы. Первая собирает ранее описанные метрики приложения, вторая — метрики использования ресурсов и производительности запущенных контейнеров (это будет подробно рассмотрено в разделе, описывающем использование cAdvisor). scrape_interval указывает как часто забирать данные с target. Параметр metrics_path не указан, поэтому Prometheus ожидает, что метрики будут доступны на target'ах по пути /metrics.
Expression browser и графический интерфейс
Для использования встроенного Prometheus expression browser перейдите на http://localhost:9090/graph и попробуйте запросить любую из ранее описанных метрик, например, http_requests_total. Используйте вкладку "Graph" для визуализации данных.
PromQL позволяет делать более сложные запросы; рассмотрим пару примеров.
-
вернуть все временные ряды для метрики
http_requests_totalи заданной job'ы:http_requests_total{job="mongodb_redis_web_app"}Лейблы
jobиinstanceавтоматически добавляются к собираемым Prometheus сервером временным рядам.
-
вернуть с помощью функции rate число запросов в секунду на основании измерений в последние 5 минут:
rate(http_requests_total[5m])
Вы можете найти больше примеров здесь.
Настройка Grafana для визуализации метрик
В этом проекте Grafana сконфигурирована с помощью следующих параметров:
-
источники данных (откуда Grafana будет запрашивать данные)
Конфиг источников данных для Grafana
apiVersion: 1 datasources: - name: Prometheus type: prometheus access: proxy url: prometheus:9090 isDefault: true
-
провайдер дашбордов (откуда Grafana загрузит дашборды)
Конфиг дашбордов для Grafana
apiVersion: 1 providers: - name: 'default' folder: 'default' type: file allowUiUpdates: true updateIntervalSeconds: 30 options: path: /etc/grafana/provisioning/dashboards foldersFromFilesStructure: true
После запуска проекта с помощью файла Docker Compose вы можете перейти на http://localhost:3000/, войти с помощью admin/admin и найти дашборд webapp_metrics. Некоторое время спустя он будет выглядеть примерно так:

Дашборд показывает состояние приложения под простым нагрузочным тестом. (Если вы запустите какой-нибудь нагрузочный тест, то для большей наглядности графиков (особенно гистограммы) вам нужно будет отключить ограничение MAX_REQUESTS_PER_MINUTE, например, путём резкого увеличения этого числа.)
Для визуализации данных в дашборде используются PromQL запросы, включающие ранее показанные метрики, например:
-
rate(http_response_time_seconds_sum[5m]) / rate(http_response_time_seconds_count[5m])Показать среднее время ответа за последние 5 минут
-
sum(increase(http_response_time_seconds_bucket{path="/planets"}[30s])) by (le)Используется для визуализации распределения времени ответа в форме тепловой карты. Тепловая карта похожа на гистограмму, но во времени; каждый интервал времени представляет собой отдельную гистограмму:
-
rate(process_cpu_seconds_total{job="mongodb_redis_web_app"}[1m]),sum(rate(container_cpu_usage_seconds_total{name='mongodb-redis'}[1m])) by (name)Показывает использование процессора за последние 5 минут. Запрашиваемые данные приходят из двух источников и показывают использование ресурса процессом и контейнером соответственно. Два графика почти одинаковы. (
sumиспользуется посколькуcontainer_cpu_usage_seconds_totalпредоставляет информацию по использованию каждого ядра.)
Примечание: График "Memory usage" показывает память, используемую:
- процессом (
process_resident_memory_bytes{job="mongodb_redis_web_app"} / 1024 / 1024) - контейнером (
container_memory_usage_bytes{name="mongodb-redis"} / 1024 / 1024)
По неизвестной мне причине график показывает, что процесс потребляет намного больше памяти, чем весь контейнер. Я создал issue по данному вопросу. Напишите, если что-то не так в этом сравнении или знаете, как это объясняется.
Мониторинг метрик контейнера приложения с помощью cAdvisor
В дополнение к системным метрикам процесса (было показано ранее) также могут быть экспортированы системные метрики Docker контейнера приложения. Это можно сделать с помощью cAdvisor.
Веб-интерфейс cAdvisor доступен по http://localhost:8080/. Все запущенные Docker контейнеры показаны на http://localhost:8080/docker/:
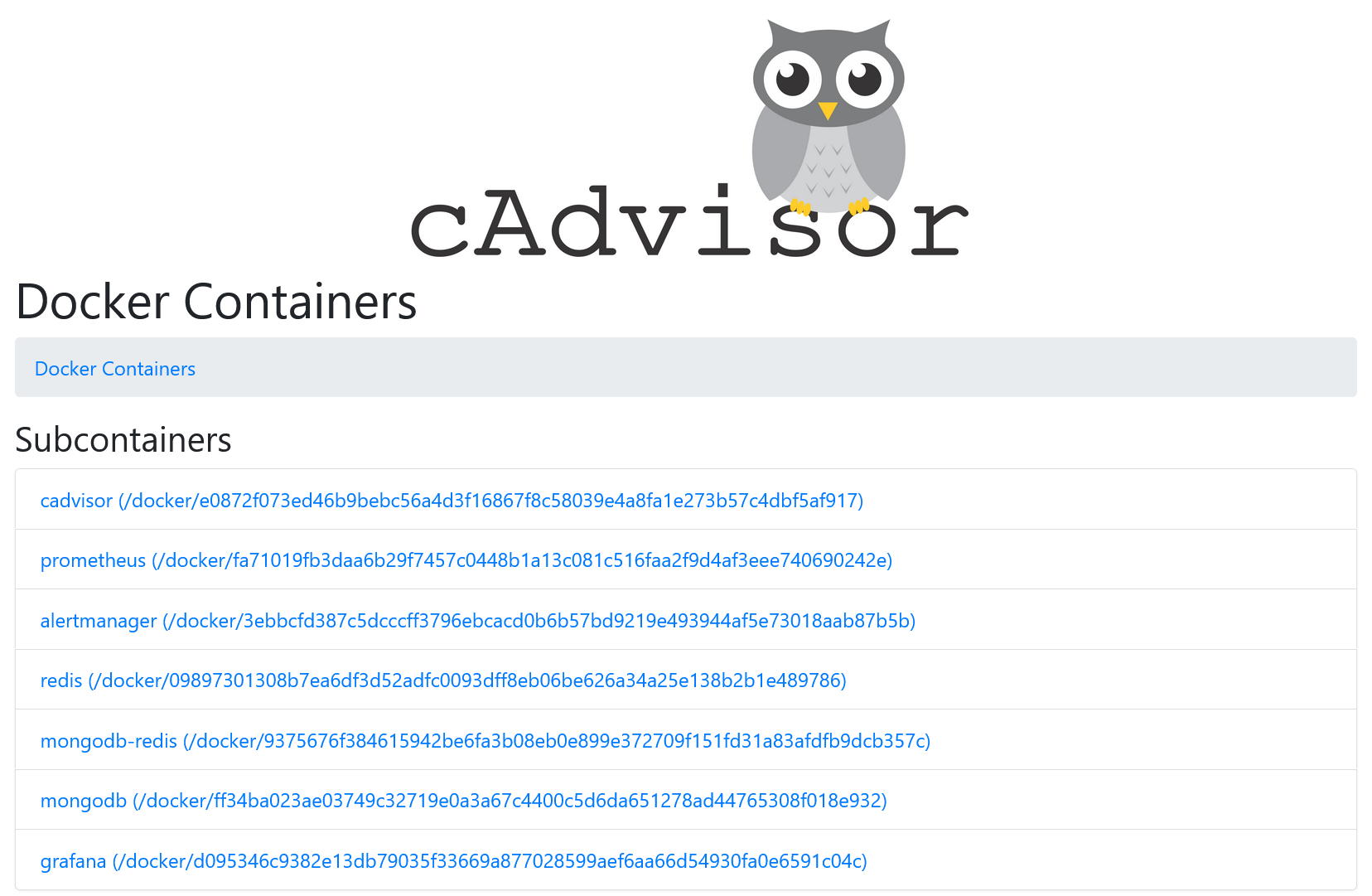
Вы можете получить информацию по использованию ресурсов любым контейнером:

Метрики собираются Prometheus сервером с http://localhost:8080/metrics.
Метрики, экспортируемые cAdvisor'ом, перечислены здесь.
Системные метрики серверов могут быть экспортированы с помощью Node exporter или Windows exporter.
Настройка уведомлений с помощью правил и AlertManager
В этом проекте следующая часть конфига Prometheus отвечает за уведомления:
Конфиг Prometheus для уведомлений
rule_files:
- 'rules.yml'
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']В разделе alerting определён инстанс AlertManager, с которым взаимодействет Prometheus сервер.
Правила оповещений позволяют определить условия на основе PromQL выражений:
Пример правила оповещения в rules.yml
groups:
- name: default
rules:
- alert: SseClients
expr: http_connected_sse_clients > 0
for: 1m
labels:
severity: high
annotations:
summary: Too many SSE clients- alert – название оповещения
- expr – определение правила в виде Prometheus выражения
- for – как долго правило должно быть нарушено перед отправкой оповещения. В нашем случае если число SSE клиентов будет больше 0 в течение 1 минуты, то будет отправлено оповещение
- labels – дополнительная информация, которая может быть добавлена к оповещению, например, уровень серьёзности проблемы
- annotations – дополнительные сведения, которые могут быть добавлены к оповещению
Указанное правило, что число SSE клиентов больше 0, — это не то, что вы обычно настраиваете в приложении. Оно используется в качестве примера только потому, что позволяет легко его нарушить с помощью всего лишь одного запроса.
Если правило нарушено, Prometheus сервер отправит оповещение на инстанс AlertManager, который предоставляет множество фич, таких как дедупликация оповещений, группировка, отключение и роутинг уведомлений конечного пользователя. Здесь мы рассмотрим только роутинг: уведомление будлет перенаправлено на email.
AlertManager сконфигурирован так:
route:
receiver: gmail
receivers:
- name: gmail
email_configs:
- to: recipient@gmail.com
from: email_id@gmail.com
smarthost: smtp.gmail.com:587
auth_username: email_id@gmail.com
auth_identity: email_id@gmail.com
auth_password: passwordВ этом проекте AlertManager сконфигурирован с помощью Gmail аккаунта. Чтобы сгенерировать app password, вы можете использовать этот гайд.
Чтобы правило оповещения SseClients сработало, вам нужно перейти на http://localhost:9000 в браузере. Это увеличит значение метрики http_connected_sse_clients на 1. Вы можете видеть изменения статуса оповещения SseClients на http://localhost:9090/alerts. После срабатывания оповещение перейдёт в статус Pending. По прошествии интервала for, определённого в rules.yml (в нашем случае это 1 минута), оповещение перейдёт в статус Firing.
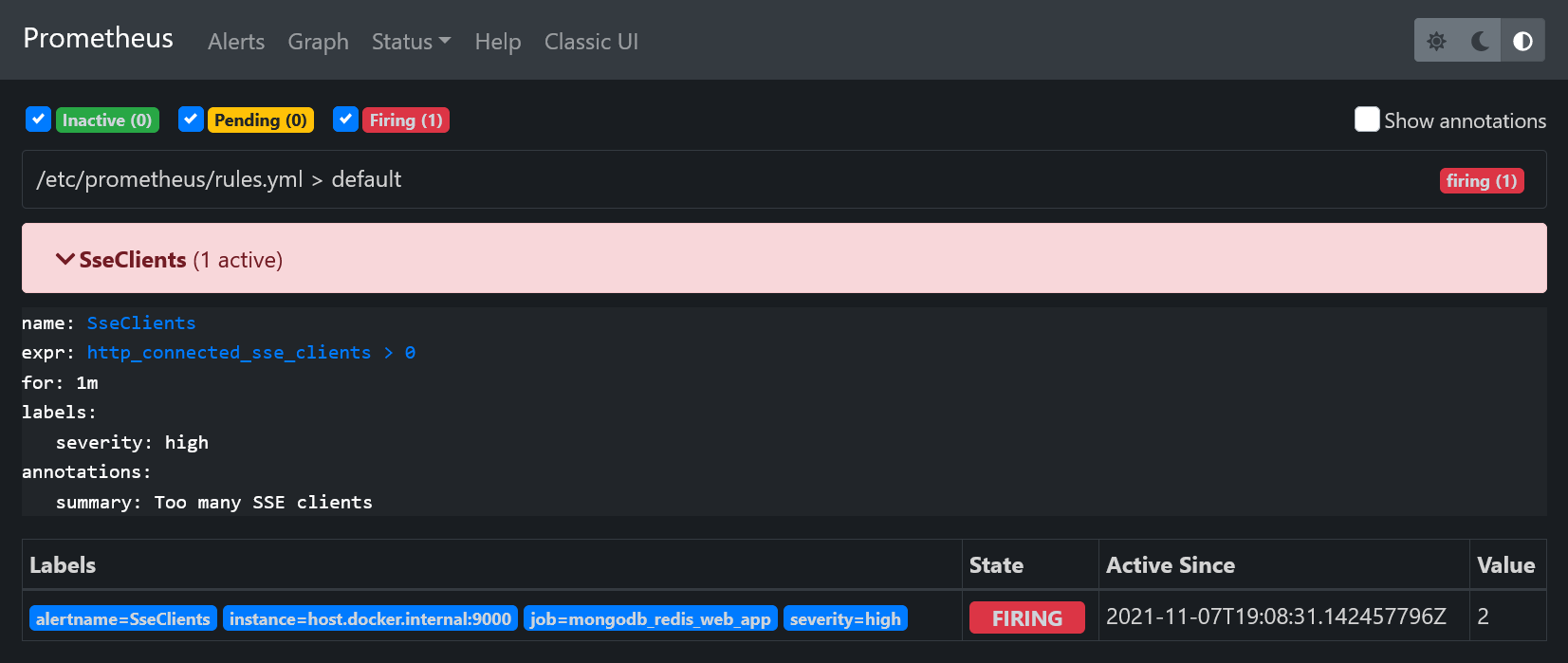
Это приведёт к тому, что Prometheus сервер отправит оповещение в AlertManager, который определит что с ним делать. В нашем случае будет отправлен email:

Мониторинг third-party систем с помощью Prometheus exporters
Для third-party тулов, таких как MongoDB, Redis и многих других, есть возможность настроить мониторинг с помощью Prometheus exporters.
Запуск
docker compose up --build
Заключение
В этой статье было показано как настроить отдачу метрик веб-приложения на Rust, их сбор Prometheus'ом и визуализацию данных с помощью Grafana. Также было показано как начать работу с cAdvisor для сбора метрик контейнеров и с нотификациями с помощью AlertManager. Не стесняйтесь написать мне, если нашли какие-либо ошибки в статье или исходном коде. Спасибо за внимание!
Полезные ссылки
Комментарии (10)


mouze1976
13.01.2022 08:44Спасибо за статью, подскажите почему не использовали zabbix?
not_bad Автор
13.01.2022 09:02Интересен был именно такой набор инструментов, возможно потому, что в работе не сталкивался с Zabbix

gecube
13.01.2022 13:52+1кратко - заббикс прошлый век, плохо масштабируется.
В принципе, никто не мешает приделать prometheus-совместимый экспортер как источник для заббикса, но не думаю, что описание решения может быть интересно
mouze1976
14.01.2022 06:17Спасибо за ответы! Единственное не согласен про плохое масштабирование. Возможно предложенный подход более оптимален для данной задачи, не готов оценить.

denaspireone
14.01.2022 13:37+1 за плохое масштабирование и убогость api
К тому же, если вы начнёте собирать метрики с деплоев в k8s - забикс просто начнёт упираться в полку по ресурсам в сравнении с теми же специлизированными решениями для time series(prometheus, victoriametrics) и конечно же? оверхед по необходимым ресурсам: к примеру для обработки запросов за очень большие промежутки времени.
Лучше посмотрите в сторону https://gitlab.com/mikler/glaber/-/wikis/home
gecube
Спасибо. Очень познавательно. Интересно было именно посмотреть на интеграцию мониторинга с Rust.
Касательно развертывания через докер компоуз - спорно, интереснее было бы на каком-нибудь minikube показать. Даром, что многие уже отъехали в кубер. cadvisor туда же - он попросту в таком сетапе становится не нужен. Если считаете, что миникуб ту мач - есть k3s, microk8s. В конце-концов на docker desktop кубернетес тоже включается одной галочкой (!)
это логично, потому что эти метрики считают разные типы памяти... Т.е. это не является багом, а скорее фичей. Хоть и весьма неочевидной и очень раздражающей. Но это больше вопросы в целом к линуксу и его аккаунтингу памяти...
not_bad Автор
Спасибо.
При деплое в k8s что-то другое используется для мониторинга контейнеров?
Да, к сожалению пока не нашёл такой вариант метрик памяти контейнера и приложения, который измеряет один и тот же тип памяти и при этом корректно отображается на графике
gecube
kubelet экспоузит метрики аналогичные cadvisor
потом это точно так же собирается https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack