
Вступление
У меня бывают ситуации на проектах, когда нужна база данных какой-то статической информации. Но увы, пошарив в интернетах, какого то публичного хранилища найти не удалось, но тем не менее, я вижу кучу ресурсов, которые это используют.
В моем случае мне понадобилась база данных пород кошек, но среди этих примеров может быть что угодно, от базы данных имен, названия городов, областей и т.д. Эта статья о базовых подходах и практиках парсинга данных с веб ресурсов.
Хочу подметить, что хоть в моих жилах течет дотнет, в этом примере я буду использовать Node JS, потому что так быстрее, и удобнее в плане парсинга. Чем именно удобней - я расскажу позже в статье.
Можем ли мы спарсить?
Да, к сожалению (или счастью) веб - он не однообразен, и каждый ресурс может быть уникален по своему, но в нашем деле, ключевым моментом будет то, есть ли на этом ресурсе Server-Side Rendering (SSR), или там Client-Side Rendering и важная для нас информация подтягивается позже с помощью JS.
К примеру, нативные апки на React или тот же Angular by default есть CSR. И что бы прикрутить там SSR нужно порой очень сильно попотеть. Тем не менее, большинство сайтов с топ серч результатов любой поисковой системы будут поддерживать именно SSR, потому что таков мир SEO оптимизаций.
В моем примере, страница, которую будем парсить - это простая вики страница:
Мы можем видеть, что эта страница использует SSR, ибо в первом запросе, мы видим, что информация о породах уже есть в ответе от сервера.
Как будем парсить?
Перед тем, как начать парсить, давайте сначала определимся, что именно будем парсить. В моем примере - мне нужны были названия и фото пород. Названия я потом переводил на английский и русский, а фотки сохранял в директории с приложением. К слову, потом это все перегонялось в Postgres похожим скриптом.
Первое, что нужно сделать - это заинспектить нужные элементы страницы через тулзы браузера (в моем случае хром).


Кликаем на выбранный элемент и смотрим HTML в сайдбаре тулзов.

Как вы видите, мы имеем дело со стандартной таблицей, и для парсинга названия породы все, что нам нужно сделать - это спарсить необходимые нам <td> для каждого <tr>.

Фото также находится на одном из <td> тегов. Убеждаемся, что сорс фото валидный, и у нас есть доступ туда без никакой авторизации и прочих вещей.
Начнём парсить!
Создадим папку с проектом и в руте создадим main.js.
Потом с рута проекта открываем терминал и пишем:
npm init

Можете пропустить все, что спрашивается там, это неважно в нашем случае.
Для нашего апликейшена нам будут нужны axios для HTTP запросов, node-html-parser, чтобы парсить html, fs.promises для асинхронных колов файловой системы, google-translate-api, для перевода с украинского.
В терминале пишем следующую команду:
npm install axios node-html-parser @vitalets/google-translate-api --save
Дальше пишем такой код в нашем мейн файле:
Как вы видите, мы определили наши константы, библиотеки, которые собираемся использовать и асинхронный мейн, чтобы писать чистый и асинхронный код.
Теперь, чтобы спарсить контент с этой страницы, мы должны ее как-то получить. Мы просто сделаем GET запрос к ней и получим наш HTML.
Дальше, что мы можем сделать с нашим HTML? Есть несколько вариантов парсинга: XPath и нативные JS querySelector & getElementsBy. Я использовал querySelector ибо это упрощает написание парсера, потому что это легче тестировать (чуть ниже я покажу каким образом), лично мне больше понятен его синтаксис нежели синтаксис XPath.
Что же, давайте попробуем написать селектор для нашего имени. И вот тут и проявляется вся прелесть выбора querySelector, потому что мы просто идем в тулзы для девов в браузере, и там все это тестируем.
Тут я выпарсил все <tr>.

Как только “подобрали” правильный селектор, просто копипастим это в апку в какую-то константу.
Как мы видим, мы должны исключить первый и последний элемент.


Давайте теперь напишем ещё вспомогательный метод, который будет проверять, существует ли папка или файл по заданному пути, ну и добавим нашу константу.
Следом за этим - напишем логику, которая будет парсить все наши строки:
В коде выше — мы создали директорию для фото, взяли HTML через риквест на CAT_URL, и потом спарсили все <tr> теги. Теперь в Promise.all мы можем отдельно парсить каждую строку.
Теперь давайте поиграем с селекторами еще, чтобы взять имя породы:

Как вы видите, внутри <tr> тега мы должны следовать за <td> тегом и взять текст тега <a>.

Посмотрим, что мы можем использовать для парсинга фото:


Как же мы можем быть уверены, что можем это спарсить с нашей хтмл?
Мы можем скачать эту HTML любым удобным способом (cURL, Postman) и проверить, есть ли там фотка.
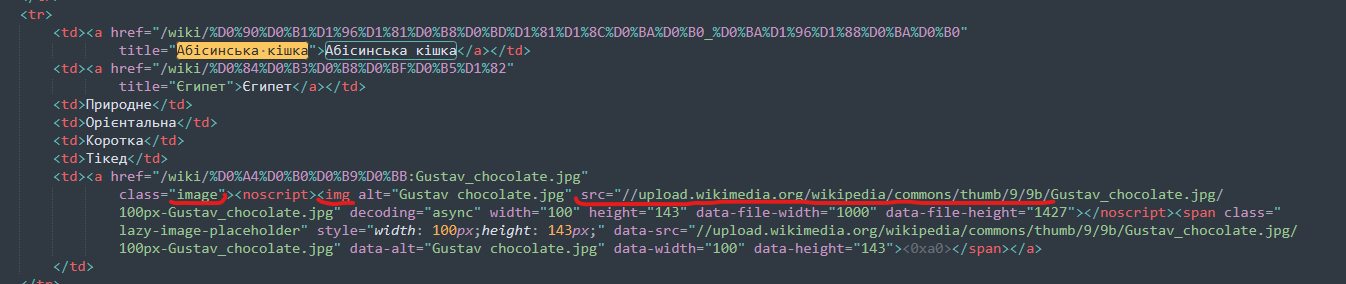
И конечно же, там нету элемента с классом ‘.image-lazy-loaded’. Но как решение, мы можем взять элемент с классом ‘.image’ потом взять тег <noscript> и из его дочернего элемента взять сорс фото.
Добавим нужные селекторы в код:
В коде, мы проверяем, есть ли уже у нас фото с названием породы (возможно апка будет запускаться множество раз, чтобы лишний раз не делать риквест на вики), и если нету мы скачиваем фото в локальную директорию.
Так же проверяем, есть ли фотка у породы вообще, потому что ее может не быть

Теперь создадим метод, который будет скачивать. Так же нам понадобиться юзерагент википедии, потому что после нескольких скачиваний, у меня начали падать ошибки, и они пофиксились добавлением этого хедера.
Последнее, что нужно сделать, после того, как мы скачали фото - это перевести название породы, сохранить это название в файлике.
Я также отделил создание новой строки в отдельный метод, потому что это платформ специфик штука.
Попробуем же это все запустить с командой:
node main.js
Весь код солюшна:
Результаты

Перевод не такой классный, как мог бы быть, но это уже не проблема парсинга, а проблема процессинга.
Я еще сделал видео, демонстрирующее написанное в статьи, если хочется увидеть процесс вживую — вот ссылка.
Комментарии (30)

Yser
18.01.2022 02:04+14Мда, хабр уже не то что не торт, но даже не пироженка.
За усилия конечно плюсик, но у википедии же есть офийиальный API насколько я помню, да и снепшоты они публиковали же или это не они?
Так или иначе давайте по пунктам:
" любой веб ресурс" - очевидно не любой. Я не читал весь этот поток мыслей смешанный со скриншотами, но финальный листинг кода не содержит ничего что относило бы его к категории "универсальный".
У википедии есть та же страница на русском и английском, та же таблица. Возможно данные не совпадают, но зачем дергать перевод для всех данных...
Ну и да, показывать парсинг на википедии это как показывать как хорошо ты знаешь карате - на детях в песочнице.

andreyka26 Автор
18.01.2022 02:23+1да, вы правы, не любой

QeqReh
18.01.2022 07:02+7Так исправьте заголовок. Как парсить википедию.
Если вы реально попробуете парсить какой нибудь сайт объявлений, то для вас будет очень много интересных открытий.

Medeyko
18.01.2022 02:46+8Да, про карате в песочнице - красиво :) Ну, да, я понимаю, что человек пытался продемонстрировать общие походы на проекте, который специально сделан так, чтобы максимально удобно распространять знания, чтобы информацию из него можно было брать без такого вот превознемогания. Но всё равно не удержусь:
Да, для Википедии распространяются snapshot'ы, есть публичный API, через который эту задачу решить проще. https://uk.wikipedia.org/api
Что касается перевода, то в той таблице все названия пород - это ссылки на соответствующие статьи. Причём большинство статей - существуют, так что из Викиданных (это тоже проект Викимедиа, в симбиоз с которым работает Википедия) можно просто брать переводы на другие языки, причём практически без риска неточностей, в отличие от Google translate.
Да и вообще, всю нужную для этой статьи информацию можно получить в готовом виде через несложный SPARQL-запрос к Вики-данные. https://query.wikidata.org/
Туториал: https://wikidata.org/wiki/Wikidata:SPARQL_tutorial
Чтобы не быть голословным, по ссылке набросал запрос. Кликаете по ссылке, нажимаете "выполнить запрос" (или ctrl+enter) - и вуаля!
Убеждаемся, что сорс фото валидный, и у нас есть доступ туда без никакой авторизации и прочих вещей.
В Википедии не может быть картинок с "какими авторизации и прочими вещами": картинки там либо с неё самой, либо с Викисклада (ещё одного проекта Викимедиа, в симбиозе с которым работает Википедия, и который тоже открытый).

Merzavets
18.01.2022 07:38Вот за такие ответы я и люблю Хабр! Если сама статья, возможно, и представляет какую-то ценность (хотя человек, пообещавший нам некоторые "общие подходы", применимые для "любого веб-ресурса", с третьей строки своего повествования свалился в абсолютные частности), то именно ваше сообщение на конкретном примере с котиками открыло мне новые общие принципы работы с Википедией.
Уполз изучать SPARQL. Спасибо!

Radisto
18.01.2022 09:37Хабр - это когда комментарии к статье зачастую несут больше информации чем сама статья. Спасибо
HistoryART
18.01.2022 02:10Всё бесполезно и говнисто на фоне nightmare/puppeteer но спишем на то, что вы .net, полезно было про заголовки. Парсил много на фрилансе включая с динамическим прокси и обходом капчи. То что реализовано здесь в гору каких-то крайностей, можно реализовать в 20 строк на nightmare.
andreyka26 Автор
18.01.2022 02:14Ну здесь тулзы для автоматизации не сильно нужно, какой-то оверинжиниринг уже, ибо ССР есть, все, что нужно в респонсе - тоже есть, запускал я это один раз что бы перекатить в постгрес. Мне нужны были породы котов. То, что написано в сорс коде статьи - тоже можна намного компактнее уложить без проблем.
Yser
18.01.2022 04:26+3А еще можно из пушки по воробьям стрелять. Зачем puppeteer там где сервер отдает (хрен с тем API уже) - готовый HTML
curl http:/puppeteer-puppeteer.end-of-your-softdev.career сделает то же самое в надцать раз дешевле, если уж мы говорим про этот конкретный пример.
На днях ради интереса спрашиваю джуниор девелопера, фронтендера:
- Алекс, мне надо стянуть данные вот из этой таблицы на странице. Что бы ты сделал?
- Ну, я бы нафигачил маленький скрипт на папатир (Алекс делает какой-то там проект на нем и для него все ново) и ...
И тут я показываю ему 3 строчки в консоли браузера которые созвращают мне готовый табличный текст для копирования. А была бы однородная таблица, вообще бы скопировал и вставил в гугл таблицы, чтобы получить данные в колонках.

napa3um
18.01.2022 09:25Иногда как раз "дешевле" завести скрипт puppeter / playwright в полторы строчки, быстро реализовав навигацию по материалам нужного сайта "визуальным" способом (в духе "тыкнуть эту кнопку, прочитать этот фрагмент, повторить"), а не мучаясь с реверсинжинирингом всех нужных запросов, кук и заголовков, что задумал разработчик сайта (и не боясь SPA/PWA). Да ещё если и заготовка от парсера другого сайта уже есть :). Парсеры - продукт зачастую одноразовый и наколеночный, нужный здесь и сейчас, а не какой-то долгоиграющий автономный сервис (такие сервисы обычно долго не живут, ибо завязаны на стороннюю скрытую архитектуру). Мы же экономим время и ресурсы программиста, а не машины :).
Yser
18.01.2022 10:13Ключевое слово - иногда. Парсеры, а точнее скраперы, продукты разный и если вы не играли с ними в долгую, это не значит что так не бывает.
Ну и в целом, если мне надо забить гвоздь - я беру молоток, а не 17 микроскопов и биолога, но это все лирика.
napa3um
18.01.2022 10:52+1Играл, и для меня в итоге оказалось проще именно на вебките :). Да, вы будете из религиозных побуждений и чувства прекрасного пол часа реверсить заголовки какого-нибудь неожиданно сопротивляющегося парсингу сайта, а я за пять минут вероломно напрягу свой процессор вебкитом и займусь чем-нибудь полезным :).
Но я не настаиваю на абсолюте своего мнения, конечно, оба варианта имеют право на жизнь, ведь всё дело в задачах и предпочтениях программиста и способах масштабирования своего опыта, а не в каких-то там "так правильнее :).
watti
18.01.2022 03:24+3не могу не отметить кликбейтный заголовок (тоже периодически занимаюсь парсингом). ожидал увидеть какой-то оригинальный подход, а оказывается это просто основы


Andrey_Epifantsev
18.01.2022 05:13+3Открыл эту страницу. Выделил таблицу с породами. Скопипастил её в Excel. Вставилась без проблем. Дальше с этой таблицей можно делать что угодно.
Или я что-то не понял и ваш парсинг извлекает больше информации?
MrsIrina
18.01.2022 21:42От новичков благодарствую. Очень полезно. Всем кто писал возмущенные коменты типа API взять проще, nightmare/puppeteer, три строчки в консоли и прочее - тоже благодарность)))
Умничайте дальше, а я читать буду ????
dimuska139
Статья о том, как делать http-запросы и обрабатывать полученный html - серьёзно? Ну могли б хотя бы распарсить сайт, закрытый аутентификацией, или лимитировать количество запросов к ресурсу, использовать прокси, разгадывать каптчи, а так слишком примитивно как-то, прямо совсем.
chtulhu
Человек явно постарался, на фоне некоторых "статей", которые непонятно что делают на хабре - это научная диссертация. Если такие заметки https://habr.com/ru/post/645893/ набирают на хабре такие результаты, то почему эта хорошо оформленная и возможно кому-то полезная (каким нибудь новичкам пришедшим из гугла), не может быть опубликована на хабре?
dimuska139
Ну, в Кодексе авторов Хабра написано "Я пользуюсь поиском, чтобы уточнить, нет ли уже на сайте похожего материала. Если так вышло, я дополню его в комментариях.". То есть вот эта статья через поиск не нашлась?
chtulhu
Если сравнивать с тем примером, что вы привели, то эта статья лучше оформлена, несет больше смысловой нагрузки и показывает больше лайфхаков. Не говорю уже про другой стек технологий.
andreyka26 Автор
да, серьезно, это кейс из опыта, если бы википедия была закрыта аутентификацией - то парсил бы в обход этого) Скиньте мне то, что Вам было бы интересно спарсить. Возможно я это сделаю и напишу статью по этому поводу.
SamMolokanov
Попробуйте парсить поисковики в несколько потоков, там все будет очень интересно - капчи, JS, прокси...
Например, определять Top30 сайтов по запросу "купить пластиковые окна" в Google по Киеву или Москве.
avvor
Статья называется "...любой сайт", но любой сайт так просто спарсить не получится, вот Вам сайт который защищён от парсинга, аутентификацией не закрыт, попробуйте спарсить - https://kad.arbitr.ru
init0
Нет смысла парсить этот сайт, на порядок быстрее и проще спарсить ресурсы откуда этот сайт напарсил свои результаты - sudrf.ru, сайт минюста и т.п.
dimuska139
Avito, например, или парсить выдачу Яндекса/Гугла, как уже выше предлагали
rostislav-zp
https://e.land.gov.ua/auth_select
tempick
спарсите всех фолловеров у человека в твиттере. Любого человека, у которого хотя бы 100к фолловеров) Допустим, у него twitter.com/yurydud
KislyFan
Честно говоря душу бы продал сейчас за толковый мануал по аутентификации на ресурсах с авторизацией через microsoftonline.com )