
Архитектура
Можете ли вы, читая эту публикацию, дать четкий ответ на вопрос, что такое архитектура? Что такое архитектура в контексте программирования и проектирования? Какую роль она играет? Достаточно много неясностей есть в этом термине. И вроде бы все понятно, но как-то абстрактно, и без точности. Мартин считает, и я с ним солидарен, что приложение имеет две составляющих:
- Поведение (behavior) — функции и задачи, которые программа (компонент, сервис) выполняет.
- Архитектура — этот термин в большей мере о изменении приложения.
Но даже, если приложение очень хорошо выполняет задачу, которую она должна выполнять, это совсем не значит, что оно имеет хорошую архитектуру. Архитектура — это не о поведении приложения. Архитектура — это о легкости изменяемости, архитектура — это о легкости развертывания, архитектура — это о независимости разработки. Архитектура — это о скорости, с которой понимание приходит к новому человеку в команде
И вот как строить эту архитектуру, как избавится от головной боли при маленьком изменении требований от PM’а, или от стейкхолдера: об этом и поведает книга
Об авторах
Перед тем, как что-либо говорить об этой книге, я хочу сказать немного о себе.
На данный момент я Strong Junior Developer, специализирующийся на разработке сервисов посредством ASP .NET CORE’а.
Я уже год работаю на одной “галерке”, и вроде бы по чуть-чуть справляюсь
Книгу я эту уже прочел 2 раза, и к чтению рекомендую всем:
- разработчикам embeded систем;
- фронт-эндщикам;
- бэк-эндщикам;
- и даже девопсам.
Вообщем всем, кто хоть как то связан с разработкой ПЗ, имеется в виду непосредственной разработкой разных там Сейлов и ПМ’ов сюда не учитываем (хотя тоже было бы полезно знать, почему дев бывает тратит в 2 раза больше времени на задачу), советую прочесть эту книгу.
И сейчас я попробую аргументировать, почему я так считаю
Немного об авторе этой книги ( потому что для меня авторитет пишущего играет большую роль). Я думаю вы меня поймете, хоть это не всегда правильно, но если вам что-то говорит авторитетный человек в сфере — вы проявляете намного больше доверия к сказанному им. Например, я думаю вы больше поверите в диагноз, который вам ставит врач, нежели от какой-то человек из толпы (погугливший симптомы)
Роберт Мартин — он же Анкл Боб (дядюшка Боб) — работает в сфере программирования, причем разных систем (от вебсервисов до ембедит систем), с 1970 года. является техническим консультантом и архитектором, писал в разные технические журналы, сам по себе очень опытный программист, и человек который играл одну из ключевых ролей при создание всем известных SOLID принципов (можно сказать создатель). Так же, хочется добавить, что мне эту книгу посоветовал мой тимлид с 15+ опытом работы
О книге
Зависимости
Перед прочтением книги, я достаточно много статеек на том же Хабре читал, где фигурировало такое слово, как “зависимость”. Что это такое, кто от кого зависим, что конкретно значит “зависеть”, и как какой то класс может зависеть от кого-то?
И вот по мере прочтения книги я усвоил два момента:
Зависимость — это термин, значащий, что какой-то класс (компонент, сервис) знает о каком-то другом классе (компоненте, сервисе), и это знание на уровне кода определяется (сейчас джависты, шарписты, сишники меня поймут) определенным импортом неймспейса. Иными словами: есть у вас класс А с неймспейсом Default.Classes и класс B Another.Classes. Так вот, если в сорс коде класса А будет фигурировать using Another.Classes; — то это значит, что класс А зависит от класса B.
Чтобы понять по схеме, где зависимый класс, а где нет — смотрите на направление стрелки: в 1) стрелка будет указывать от класса А в направлении класса B. Это значит, что класс B более независимый, чем класс А. И изменения в классе А, никакого “ущерба” классу B не нанесут

SOLID
Одной из основной причины, которая была для меня к прочтению этой книги — это объяснение SОLID принципов из первоисточника, потому что дядя Роб разрабатывал эти принципы и можно сказать, благодаря ему мы слышим это название — SOLID.
Для тех, кто не в курсе — эти принципы говорят и советуют дизайнить свои приложения в соответствии с 5 правилами:
S — SRP (Single responsibility principle)
O — OCP (Open-closed principle)
L — LSP (Liskov substitution principle)
I — ISP (Interface segregation principle)
D — DIP (Dependency Inversion principle)
Все эти принципы могут быть применены на уровне классов и объектов, на уровне модулей и компонентов и на уровне лееров (сервисов).
Если вы считаете что Single responsibility principle — это про то, что класс, или же модуль должен делать только что-то одно — то вам обязательно нужно прочитать хоть бы главу про Солид. Ибо то определение, что дано выше — это следствие, но никак не определение самого принципа
О Dependency Inversion
Особое внимание хочу обратить на объяснение Dependency Inversion Principle (тот, что D из SOLID’a). По ходу прочтения книги, я понимал, это не просто принцип, это ещё механизм и инструмент, с помощью которого, вы можете менять направление ваших зависимостей, и делать, к примеру, бизнес логику (DOMAIN) независимой от деталей реализации Data access layer’а (DAL’a)
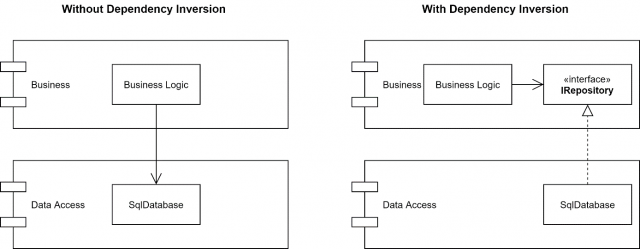
Хоть сам принцип на ряду с остальными в СОЛИД значит немного не то, что механизм, сам механизм используется на протяжении всей книги, и это один из основных методов инвертировать и менять направление ваших зависимостей, который кстати используется при DDD
О принятии архитектурных решений
Очень часто в книге будет упоминается принцип о принятии важных архитектурных решений: о том, какую БД использовать, какой фреймворк использовать, какую библиотеку подключать, что использовать как поисковой движок и т.д
Так вот, автор считает: вы должны КАК МОЖНО МЕНЬШЕ принимать такого рода решения. Ибо requirements могут изменяться, ограничения по perfomance’у тоже, сама поведенческая составляющая имеет тенденцию меняться. В процессе разработки какие-то решение может показаться менее эффективным нежели другое, менее удобным нежели другое. И сила твоей архитектуры будет определять, насколько быстро и безболезненно ты сможешь заменить одну технологию на другую (об этом кстати твердит OCP).
Например, внезапно, вы решите использовать вместо Postgresql MongoDb, или вообще файлики, или использовать mock’нутые данные, операции с которыми будут производится в памяти. И при некоторых условиях — это может заставить переписать почти всю логику.
Чтобы таких ситуаций не возникало, мы можем использовать некоторые механизмы, которые будут максимально далеко отодвигать время принятия решения. Один из этих механизмов — абстракция.
Отсылки на DDD
DDD — Domain Driven Design — подход к разработке сервисов с сложной бизнес логикой, критической к изменениям, который направленный на максимальной понимание руководящих должностей проекта (PMs, Sale managers etc), с рядовыми гребцами. То есть, что бы между все членами проекта был ubiquitous language, и каждый мог понять другого, и чтобы все мыслили в одном domain’е с одними и теме же бизнес правилами.
Если вы — приверженец DDD, или хотите быть таковым, или вы что-то в этом не понимаете, но хотите понимать — книга обязательна к прочтению, особенно вторая часть книги.
Здесь автор объясняет о существование Dependency Rule, и почему, следуя ему — вы будете строить правильную архитектуру приложения. Почему зависимости должны следовать в направлении к High Policy компонентам, почему домен (High Policy компонент) должен быть независим от инфраструктуры и как это упростит вам деплоймент и девелопинг
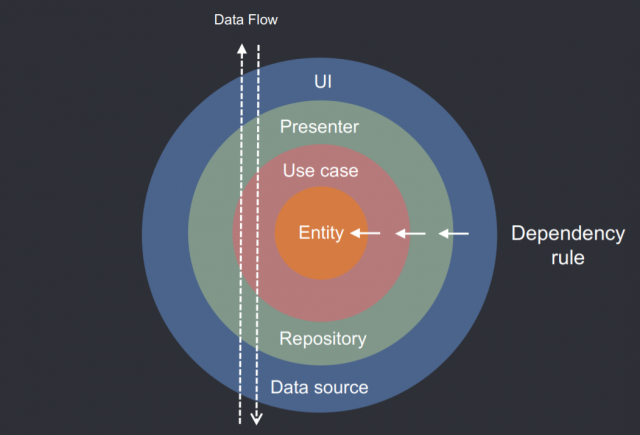
Абстрагирование
Дядя Роб, также рассказывает о том, как детали реализации могут навредить вашей системе, и не дать эволюционировать без боли в дальнейшем.
Помните!
БД — это деталь реализации
Клиенты (Web, Mobile, etc) — детали реализации
Фреймворки — это деталь реализации
От этого всего нужно максимально абстрагироваться и не зависеть, используя выше описанный Dependency Inversion с интерфейсами и абстракциями, Dependency Rule и прочие механизмы
Методы построения модулей
Этот раздел мне понравился особо сильно, как разработчику сервисов на ASP .NET CORE’е. Ибо здесь рассказываются о методологиях построения единой архитектуры сервиса из готовых компонентов.
Роберт описал 4 возможных схемы разделения слоев.
Он дал понять почему так часто используемый механизм 3-х слоевой архитектуры: UI (controllers), Services (Domain), DAL (Database) — достаточно плох по сравнению с другими. Я видел не очень много проектов, но в каждом, например микро-сервисе, на бэк-энде, используется именно трех-слоевая архитектура.
Так же, достаточно часто, используется архитектура один-компонент-один-сервис. В целом они обе неплохие, но она имеет достаточно много минусов, в сравнении к примеру, как строится архитектура при использовании DDD, особенно при критических к изменению, и сложных сервисов.
В общем, вот и подошел к концу этот обзор на книгу. Сама книга мне очень понравилась, не жалею о прочитанном, спасибо автору. Вам, дорогие читатели, спасибо за внимание, не судите строго — эта публикация, основанная на впечатлении от книги и моем личном энтузиазме
UPDATE 1.0
В ходе дискуссий, можно понять, что ВНЕЗАПНАЯ, и ЛЕГКАЯ смена хранилища — будет не легка, так, или иначе. В некоторых случаях, даже очень болезненная, и все же, абстракция и инкапсуляция доступа к хранилища, сомнительно, что сделает положение хуже, а скорее немного лучше, как минимум за счет независимости изменяемого компонента от остальных.
Комментарии (168)

Almet
19.08.2019 15:14+1Лучше почитайте Принципы, паттерны и методики гибкой разработки на языке C, от того же Мартина, то же самое, но букв намного больше. Смысл пересказывать то, что можно прочитать за пару-тройку дней

andreyka26 Автор
19.08.2019 15:47Согласен, смысл только в том, если хочешь решить надо ли читать или нет, и в том, что если у тебя нету этих 3 дней — то основные мысли, кроме раскрытия темы SOLID'a — я передал тут.
Что касается этой книги — в планах почитать уже давно, нужно только время, спасибо за рекомендацию

aragaer
19.08.2019 16:40Заинтересовался, пошел искать. Но оказалось, что там язык не С, а С#.

SamDark
19.08.2019 18:22Если вы считаете что Single responsibility principle — это про то, что класс, или же модуль должен делать только что-то одно — то вам обязательно нужно прочитать хоть бы главу про Солид. Ибо то определение, что дано выше — это следствие, но никак не определение самого принципа
Не "делать что-то одно", а делать что-то логически связное так, чтобы потребитель использовал это целиком, но не по частям.
Например, внезапно, вы решите использовать вместо Postgresql MongoDb, или вообще файлики, или использовать mock’нутые данные, операции с которыми будут производится в памяти. И при некоторых условиях — это может заставить переписать почти всю логику.
Уверены что будет меняться — делаете интерфейс. Затупливаете и не можете выбрать — делаете интерфейс, но сначала убедитесь что в этот интерфейс лягут возможные реализации. С другой стороны, иногда хорошо именно завязаться на тот же PostgreSQL потому что иначе мы ограничим себя очень небольшим набором возможностей СУБД, который допустимо использовать. Но тут уже нужно быть уверенным.
Дядя Роб, также рассказывает о том, как детали реализации могут навредить вашей системе, и не дать эволюционировать без боли в дальнейшем.
И, насколько помню, забывает упомянуть что абстракции более-менее сложных штуковин обязательно протекают. И это делает половину того, что в книге, отличной пищей для ума, но быстро разваливающейся на практике если применять не сильно думая.
andreyka26 Автор
19.08.2019 19:06И, насколько помню, забывает упомянуть что абстракции более-менее сложных штуковин обязательно протекают. И это делает половину того, что в книге, отличной пищей для ума, но быстро разваливающейся на практике если применять не сильно думая.
Солидарен.
Если заниматься программированием не сильно думая — вообще все плохо может получится.

Kanut
19.08.2019 19:57Дядюшка Боб очень часто задаёт очень правильные вопросы но очень редко даёт ответы, которые можно применять не задумываясь в любой ситуации.
То есть на мой взгляд прочитать его книжки очень даже стоит, но вот воспринимать их как истину в последней инстанции пожалуй не надо.andreyka26 Автор
19.08.2019 20:04Пожалуй соглашусь, вообще, я думаю нельзя воспринимать все за единственно-возможное решение, это же своего рода творчество


ggo
21.08.2019 10:16Роберт Мартин в своей книге пишет про набор принципов и подходов.
Это не значит что взяв любой из пунктов, и бездумно применив его, можно сразу сделать хорошо.
Там выше в комментах была активная дискуссия, насколько легко/тяжело менять одну БД на другую.
Тогда как Мартин акцентирует внимание не на легкости смены одной БД на другую. А на том, что важные решения нужно принимать при наличии фактических данных, т.е. как можно позже. По сути, речь идет о том, что выпускай релиз как можно раньше, потом смотри какая у тебя нагрузка, что болит, и только потом думай, как с этим правильно работать.
И в целом пропагандирует не легкость замены одной БД на другую, а наличие четких тонких границ между компонентами. Да, в качестве примера приводится в том числе возможность замены БД, но это только пример правильных границ. Да и сами правильные границы не являются самоцелью. Цель — управляемость изменений.
lair
Угу, абстракция, ага. А теперь давайте посмотрим на этот конкретный пример: вот вы хотите сделать такую систему, в которой не важно, что вы используете — СУБД, или внезапно ДОБД, или внезапно, ключ-значение (я бы хотел, конечно, посмотреть, на проект, в котором это происходит внезапно). И за какой же абстракцией вы спрячете все эти различия, чтобы замена произошла незаметно и безболезненно?
Это все к тому, что красивые фразы "это все детали реализации" обычно так и остаются красивыми фразами, потому что суровая реальность намного сложнее, чем простые примеры.
andreyka26 Автор
Полностью согласен с вами, не всегда можно просто сменить способ хранение данных. Имеется в виду скорее переход с однотипных баз данных, например c Postgresql на MSSQL и т.д.
Даже в случае key-value, я думаю, это нужно инкапсулировать доступ к данным так или иначе.
lair
Ну то есть первый же попавшийся мне на глаза пример, который вы показываете, как пример "хорошей архитектуры", невозможен.
Так какие же полезные (и при этом не-тривиальные) советы дает в этом вопросе книга?
andreyka26 Автор
Я думаю, здесь многое зависит от самого проекта, естественно переход к новому способу хранения данных — это всегда боль, вопрос будет в том насколько это будет больно. Как минимум совет инкапсулировать доступ к данным через какую-нибудь абстракцию — рабочий, и малость снизит боль перехода. + к этом будет простота в тестировании. А общего и безболезненного солюшна нету, я думаю. Поэтому и в конце автор говорит, и в книге есть его личные примере с его опыта, что такого рода архитектурные решения нужно принимать как можно позже — что бы свести к минимуму вероятность изменения способа хранения данных
lair
Так чему же тогда учит эта книга? "Думать"?
Это проходит по категории "тривиальный". Чтобы он стал не-тривиальным, нужно иметь критерии, отличающие "хорошую" абстракцию от "плохой".
А код-то как писать, если не принимать такие архитектурные решения рано?
andreyka26 Автор
Был бы рад, если бы вы скинули литературы, которая учит отличать хорошую от плохой.
Ну в моем понимании, ваше приложение должно иметь какую-то свою логику (бизнес логику), и начать нужно именно с ней, а не имплементить доступ к данным сходу — вот о чем говорит автор.
Кроме того, книга эта я бы не сказал что для опытных ребят, это скорее для новичков вроде меня, где разложенные и разжеванные основы
lair
Len Bass, Paul Clements, Rick Kazman. Software Architecture in Practice, если я ничего не путаю за давностью лет.
И как предлагается начать с бизнес-логики, если она работает с данными из БД и других внешних источников, своим входом имеет UI, и выходом — тоже UI?
andreyka26 Автор
За авторов спасиб)
сейчас скажу в контексте только бэк-енда. Есть такая книжечка про microservices & DDD от майкрософтов, возьму пример их же проект EShopOnContainers, сервис Ordering. В домене есть некоторые Aggregate и Entities. Можно начать с них, обдумать что как и с чем должно взаимодействовать, описать логику, а в самом поведении использовать абстракцию Repository без implementation. Как-то так. Если прям нужно тестить — ну можно in memory implementation в IoC подставить. Можно так же заняться Application Layer.
lair
Стоп. Вот же оно ваше "архитектурное решение", использовать паттерн repository, да еще и с конкретным интерфейсом наверняка. А вы говорите "отложить на потом". Да, а потом вы возьмете СУБД, и поймете, что ее нельзя запихнуть в тот интерфейс, который вы на первом этапе нарисовали для репозитория, и что тогда?
А что такое в этом контексте application layer, и почему его написание не приводит к принятию архитектурных решений?
andreyka26 Автор
Я думаю, что есть организация данных — которая сама по себе навязывает способ хранения данных. Сам я, к примеру с NoSql не работал, но мне кажется, что в том конкретном случае логично понятно, что все связи в сервисе было бы проще организовать с помощью SQL-based структуре хранения данных. И если например бизнес логика навязывает один способ хранения данных как подходящий и иной — как не подходящий, может стоит использовать подходящий, а не менять бизнес логику из-за того, что работа с данными в них не вписывается?
Что в таком случае бы вы сделали? Вы предлагаете от способа хранения данных плясать и писать бизнес логику?
Это уже DDD штука, если в двух словах — Layer, который в себе имеет Use Case'ы, делегирует все запросы с UI на Домен, и обратно и т.д.
lair
Так, и? Что с решениями-то делать?
"Логично понятно что" — это вы приняли (крупное!) архитектурное решение ("мы будем использовать реляционную модель") и даже не заметили этого.
Подождите, вы же в статье пишете "БД — это детали реализации".
Я предлагаю как-то привести в соответствие заявления, которые вы делаете в статье, и реальную практику, которая в ваших же примерах этим заявлениям не соответствует.
А у вас Use Case никак не зависят от того, каким образом используется домен? Проще говоря, use case для человека перед пользовательским интерфейсом, и для внешней системы, работающей через API, не отличаются?
andreyka26 Автор
Так, а кто говорил, что эта книга подходит под все, и волшебная таблетка от всего. Так не бывает — есть частные случаи. К сожалению, я не имею того опыта, что бы спорить о практике. В тех же примерах личного жизненного опыта автора он описывал как абстракция над доступом к данным помогла избежать некоторых проблем, точнее помогла не делать лишней работы, можете лично с ними ознакомится.
В примере конкретно Майкрософтов, DDD навязывает некоторые решения, как, к примеру, о интерфейсе репозитория — потому что, это — паттерн, который и был создан для абстрагирования от доступа к данным. И он имеет свой определенный интерфейс.
Рассмотрим к примеру апдейт того же самого ордера. В репозитории. Для этого есть соответственный метод на GetOrder(), и если его не будет, то и апдейта не будет, и если способ хранения данными не позволяет достать этот ордер — то значит он не подходит. То же самое с методом репозитория на сохранение всех изменений, который призван для того, что бы в случае изменений не одной ентити, а нескольких в пределах одного агрегата — сделать это одной транзакцией (либо все, либо ничего). Это, как я понимаю. реквайрмент бизнеса, и если же такой метод не может быть представлен каким-то способом хранения данных, значит он не подходит для этой бизнес логики. Именно поэтому ДДД и говорит о том, что полного соответствия ентити в БД с ентетей из домена может и не быть.
lair
А для чего она подходит и от чего она помогает?
Я про это и говорю: вы, на самом деле, принимаете множество архитектурных решений на самом старте (начав, кстати, с решения исползовать DDD). Так что же, собственно, вы предлагаете отложить на потом?
А почему в репозитории-то? Почему вы другие паттерны не рассматриваете?
Неа, это то, как вы это какое-то требование бизнеса интерпретировали. Совершенно не факт, что бизнесу нужна именно такая транзакционность, как вы описываете.
Подождите, сначала вы говорите, что способ хранилища данных должен полностью соответствовать требованиям бизнеса, а потом вы говорите, что именно поэтому "полного соответствия быть не может". Где-то что-то перепутано.
andreyka26 Автор
Не много не так выразился: может допускаться, что будут различия между моделью БД и моделью Домена. Это делается, на примере того же EShopOnContainers, как раз для абстрагирования от деталей хранилища. У ордера(может и не у него, но не суть, в какой-то ентите) должен быть адрес. И этот адрес мы можем сразу организовать как член класса этого самого ордера, хотя прямой связи может и не быть в SQL(так оно и есть, ибо там это Value object), или же мы сможем с легкостью сделать по классике, через ещё одну таблицу в SQL и реляционную связь, либо же использовать NoSQL и поместить адрес прям в ордер. Можно вообще организовать бинарные файлы, Но фишка вся будет в том, что интерфейс репозитория как возвращал ордер с адресом — так и возвращает — вот такой маленький (идеализированный) пример, понятно, что есть случаи, когда так легко сделать не получится, опять же говорю, я этого и не отрицал — книга — не панацея от всего.
П.С. про легкость перехода с SQL на NOSQL или key-value, напишу апдейт, тут с вами согласен — легким этот переход не сделать, но все же, думаю, что если это будет инкапсулировано и абстрагировано по максимуму — это сделает переезд менее болезненным. У меня нету большого опыта, что бы знать какие ситуации бывают, и насколько это сложно, ибо сам такого опыта не имел. Конкретные техники, и как лучше абстрагироваться в том или ином случае — это уже не об этом книга, на то архитекторы и получают свои тысячи зеленью и едят сыры xD
lair
Может допускаться, да. И что? Как это помогает принимать решения?
Угу, и во всех этих вариантах у вас будут разные гарантии целостности. Дада, те самые, про которые вы только что говорили как про бизнес-требования на транзакции. Вас это не волнует, нет?
Вы это уже говорили, и я спросил: а для чего же она полезна?
Если все будет инкапсулировано и абстрагировано по-максимуму, вы можете так задолбаться в процессе разработки первой версии, что до переезда никогда и не дожить.
А о чем она тогда? Вы вроде пишете "И вот как строить эту архитектуру". Нет?
andreyka26 Автор
Ну так это и будет задача имплементации того репозитория, что бы при SaveChanges(), все осталось целостным, ну как мне кажется. Как я понял, фишка в том, что бы бизнес лейер об этом не думал в процессе выполнения какой-то логики
это поможет какое-то время НЕ принимать решения.
Ну как по мне набор базовых принципов, которых следует придерживаться что бы построить хотя-бы не неправильную архитектуру. Она не может покрыть всех случаев. И есть случаи, когда, мне лично, эти знания помогали в принятии одного из двух решений, не раз я видел подтверждение их в разного рода проектах. Тот же самый EShopOnContainers.
Только общие принципы, и пару примеров из опыта самого автора. Почему вы хотите увидеть какую-то конкретику? Если вас интересует какую лучше абстракцию над данными выбрать — так нужно именно это искать статьи, книги, спикинги умных людей. Книга, как по мне, скорее введение в правильное строение, что бы вообще понимать, что будет хорошо, а что плохо.
Так же, мне уже самому интересно, как тогда вообще строить доступ к бд, как строить абстракции над данными, или вообще не строить их? Приведите пару примеров, может личные рекомендации?
Может вы лично сталкивались с проблемами переезда с одного способа хранения на другой — поделитесь тогда опытом
lair
Вы себе стоимость такой имплементации для нетранзакционной распределенной системы представляете?
Ну так можно просто не принимать никаких решений. Что мешает?
Что такое "неправильная" архитектура, и как отличить ее от правильной? Гарантирует ли следование вашим "базовым принципам", что "неправильная" архитектура не получится?
Как вы можете проверить, что принятые вами решения — правильные?
Потому что без конкретики это все бесполезно (и неоднократно описано).
Так что же будет хорошо-то? И что — плохо?
Да как обычно: собирать требования, формулировать их, выбирать решения.
andreyka26 Автор
Есть варианты, описаны в ещё одной книжке Designing Data-Intensive Applications.
Я лично — никак. Только общаясь с ребятами поопытнее и поумнее. Для этого и существуют тим-лиды в тиме и архитекторы — что бы подходить и советоваться, что лучше и как лучше сделать.
Ну, например, если мы уже говорили за книжку мелкомягких и их апликейшн — тогда поясню, что я думаю, было бы плохо. Точно было бы плохо написать Raw SQL запросы прям в контролер екшене, оттуда же отправить event на message-broker и залогировать все, к примеру. И это бы противоречило принципам, описанным в книге.
lair
Да понятно, что есть, вопрос, во сколько они обойдутся.
Ну то есть вам лично эта книжка помогла принять решения, но вы не знаете, правильные ли они?
Я понятия не имею, что там за апликейшн.
Почему?
Собственно, у меня в свежем проекте есть AWS Lambda, которая шлет прямой запрос в AWS CloudSearch, отправляет событие в другую лямбду, и все это логирует. Как раз как вы описали. Это плохая архитектура? Почему?
Я задал другой вопрос, если вы помните: "Гарантирует ли следование вашим «базовым принципам», что «неправильная» архитектура не получится?"
Впрочем, вопрос, какая же архитектура неправильная, почему, и как ее отличить от правильной, меня волнует больше.
andreyka26 Автор
нет не гарантирует — все индивидуально, я думаю. Мне кажется никакая книга ничего гарантировать не может, просто по причине того, что ее можно не правильно понять, как минимум.
Я говорю не за лямбду, я с этим никогда не работал. Я имел в виду сложный сервис(стандартный asp net) который имеет достаточно много логики, которая в последствии может меняться. Как минимум это будет виолейтить SRP, если написать и логирование, и запросы в бд, и ивенты на меседж брокер в екшене контроллера. Если же говорить о простой логике, я думаю можно это сделать и там. Повторяю ещё раз нету решения, которое бы подходило для всего, нужно думать что, как и где применять.
я его неоднократно упоминал выше — семплик от майкрософтов, как бороться со сложностью апликейшна, как пишутся микросервисные архитектуры, как их деплоить.
Все зависит от сложности проблемы. Но все же, я думаю, перепроверять никогда не помешает в более опытных коллег.
lair
Тогда какой в них смысл?
Гм. А как тогда понять, куда можно применять принципы из книжки, а куда нельзя?
И что? Почему это плохо?
Тааак… и что является аргументами для этого "думать"? Какие критерии? Как отличить правильное решение от неправильного?
Вот я и говорю: понятия не имею.
Вы только что написали, что не говорите за лямбду, а теперь пишете про микросервисные архитектуры. Гм...
Ну так я говорю про конкретно те решения, которые вы приняли. Это были сложные проблемы или простые?
Kanut
Ну тут вы тоже не совсем правы. Ремень безопасности тоже например не гарантирует что вы переживёте аварию. Но это не значит что в нём нет смысла. И на мой взгляд «следование базовым принципам» конечно не гарантирует что мы не получим «неправильную архитектуру», но уменьшает вероятность такого исхода.
П.С. Особенно если человек их применяющий не является экспертом, то следуя им он гораздо меньшей вероятностью получит «плохую архитектуру» чем без них.
П.П.С. Стоит ли «не экспертам» заниматься архитектурой это вопрос отдельный :)
lair
Не прав в том, что задаю вопрос?
Один пункт забыли: разумное следование. Ну да, с этим спорить сложно. Только до этого понимания еще надо дойти, к сожалению.
А вот это как раз совершенно не обязательно: следуя этим принципам тоже можно очень легко получить плохую архитектуру. Проблема, как обычно, в балансе.
Kanut
В том что уж совсем зашугали бедного strong junior developer'a :)
Конечно можно. Но точно так же её можно получить если иметь эксперта с многолетним опытом работы и т.д. и т.п. Вопрос в том какой шанс что получится плохая или хорошая архитектура в том или ином случае :)
И да, голову включать всегда надо и без этого всё равно не обойдёшься. И такие «базовые принципы» всего лишь немного «сокращают путь» и позволятют избежать пары-тройки лишних шишек(из бесчиcленного количества возможных :) ).
lair
Это полезно. В том смысле, что задавать себе вопросы — очень полезно.
И вот это очень интересный вопрос, да. И мой пойнт, not too subtle at that, состоит в том, что в статье описан случай, который с большей вероятностью приведет к плохой архитектуре, чем к хорошей.
Kanut
Однозначно. И если честно я бы тоже сказал что молодой человек книжку прочитал, базовые принципы запомнил, но зачем они на самом деле нужны пока ещё не совсем понял. Но это как с огнём: надо один раз обжечься чтобы понять почему с огнём надо вести себя аккуратно.
И чтобы понять зачем нужны подобные принципы, SOLID, clean code, и куча других вещей надо на мой взгляд сначала на своём собственном опыте ощутить к чему приводит их отсутствие или неправильное использование.
Ну если кто-то в принципе решит строить свою архитектуру по статье джуниора на хабре, в которой он описывaет своё понимание книжки по архитектуре(да ещё и на мой взгляд достаточно абстрактно написаной), то это 100% ни к чему хорошему не приведёт. Но сама книжка, опять же на мой взгляд, всё-таки не так уж и плоха :)
lair
Я честно скажу, я не помню, читал я ее, или нет. Мне нравится Мартиновский Clean Coder, но в первую очередь за не-технические советы. В остальном я разделяю высказанное тут неподалеку мнение: Мартин хорошо задает вопросы, но плохо дает на них ответы.
Kanut
Ну она немного более «техническая» чем «clean coder», но всё ещё достаточно абстрактна и полна хороших вопросов. И я там тоже не всегда был согласен с конкрентыми «ответами». Но если уже читал другие книжки Мартина, то она вполне себе.
То есть если бы меня попросили её коротко охарактеризовать, то для эксперта она наверна уже бессмыслена и интересна только как беллетристика. Для «одинокого» джуниора немного опасна. А вот каким-нибудь миддлам и начинающим сениорам её вполне себе стоит прочитать.
andreyka26 Автор
конечно не стоит, поэтому «не экспертам» такое не доверяют, но что бы стать экспертом, нужно учится, советоваться, спрашивать обсуждать и практиковать, не знаю иных способов.
andreyka26 Автор
Ну могу кинуть референс на СОЛИД и какие проблемы первая рекомендация может помочь решить, но думаю вы и сами найдете.
Как я бы то делал? Советовался, писал бы на форумы, думал сам бы — вот как.
github.com/dotnet-architecture/eShopOnContainers
И такие бывали, и такие
lair
Ну то есть следование SOLID позволяет написать архитектуру, которая хороша, потому что она соответствует SOLID. Так?
Если вас послушать, получается, что книжка про "чистую архитектуру" не дала вам ни одного (нециклического) критерия того, что же такое хорошая архитектура.
Я и говорю: понятия не имею.
Давайте возьмем простые. Как вы можете проверить, что принятые вами решения — правильные?
andreyka26 Автор
Потому что архитектура — это не стандарт, я думаю прям абсолютной объективности здесь нельзя ожидать
Окей, банальный свой проект, REST, решение: инапсулировать доступ к бд, и не писать в екшене контроллера RAW SQL, следуя, как минимум SRP & DIP. Спросил коллег: «стоит ли нагромождать екшн контроллера запросами к бд скюельными», получил ответ — «не стоит». Понял, что вероятность того, что не стоит, достаточно велика по сравнению с тем, что бы писать все в екшне.
lair
А я не прошу объективности, я прошу нециклических критериев того, что такое "хорошая архитектура".
Ну то есть ваш критерий правильности архитектуры — "коллеги согласились"?
andreyka26 Автор
Как по мне архитектура, которая дает простоту в понимании, в особенности для нового человека, и архитектура которая позволяет более быстро и безболезненно менять логику и поведение.
Пока да, это мнение других,, более умных и опытных людей, иначе пока не придумал как это сделать быстро. Единственный вариант — свою хорошесть архитектура проявит когда станет вопрос о изменении логики, поведения и т.д.
lair
По обоим этим критериям, как ни странно, архитектура с DI и разделением на слои — плохая. Потому что чтобы понять, что делается, нужно просмотреть больше кода, и чтобы изменить одну операцию, нужно изменить больше кода.
Получается, что книжка для вас в этом оказалась бесполезна.
(кстати, два абзаца в вашем комментарии противоречат друг другу)
andreyka26 Автор
Изменить, может и больше, но чтобы осознать не повредит это ещё чему-то, не поломает ли это логику чего-то ещё — проще все-таки лейерная архитектура, в силу того, что там стараются выделить независимые компоненты, при изменении которых (в идеальных условиях) ничего сломаться не должно, по крайней мере вероятность меньше.
И в случае все логики в контроллере(вы спросили чем это плохо), нужно смотреть 100500 строк кода, что бы понять что нужно изменить, вспомнить что вообще здесь происходит. А в лейерной архитектуре — ты строго знаешь какой лейер за что отвечает — сразу идешь туда и изменяешь это там.
Почему же? Ведь перед тем как спросить, ты думаешь сам, читаешь, возвращаешься, опять таки, к принципам книги, и подбираешь какой-то вариант. Книга дает тебе набор принципов и «инструментов» с которых можно выбрать, не читая книги можно было о чем то не знать, либо знать о чем то не очень правильно и т.д.
lair
Нет. Потому что если весь код, отвечающий за выполнение сценария, находится в одном месте, то его изменение может повлиять только на этот сценарий и ни на что больше.
Ну так код, который содержит все, что нужно для сценария, и есть такой независимый компонент.
Откуда?
Потому что она не дала вам критерия, как правильно.
andreyka26 Автор
Я думаю зависит от сложности проекта. Если проект простенький, множества всяких либ и компонентов с сложной логикой там нет — тогда, почему нет?.. Но так или иначе, если например контролер в себе имеет логику написания чистого СКЛ к БД, это виолейшн SRP так точно. Не думаю что это хорошо.
Про сложность и независимость: Когда один екшн контролера занимает строк 400, то я думаю, для этого и придумали лейерную архитектуру(тот же самый DDD), что бы изолировать независимые между собою компоненты, что упрощает понимание, потому что конкретный компонент отправки меседжа на какой-то брокер легче понять, нежели искать куски этой логики где-то в 400 строках контроллера, может это только мне упрощает чтение и понимание логики. Если бы я увидел в каком-то сервисе, например, артиклах(представим что там ещё и серч енджайн юзается какой-нить), то если я бы увидел в контролере логику валидейшна инпута, запрос(и билдинг запроса) на серч енджайн, запрос(и билдинг запроса) на бд, логика склеивания это в оутпут, и отправку к примеру куда то ещё на другой сервис — то мне бы было сложно и неудобно с такой структурой. Противопоставлю этому пример: если бы я увидел 3 интерфейса — для серч енджайна, для бд, для отправки на внешний сервис, мне было бы легче и быстрее понять этот код, и что делает этот экшн в контроллере.
lair
… то есть мы приходим к тому, что "хорошая архитектура" зависит от проекта? А как понять, какая архитектура хороша для конкретного проекта?
Вы это уже говорили. Но почему это "не хорошо"?
Правда?
andreyka26 Автор
lair
Она всегда позволяет.
andreyka26 Автор
Цитата автора с книги(architecture chapter): «Software was invented to be 'soft' It was intended to be a way to easily change the behavior of machines. If we'd wanted the behavior of machines to be hard to change, we would have called it hardware
To fulfill its purpose, the software must be soft — that is, it must be easy to change»
lair
Ну то есть критерий "как правильно" — это легкость изменения? Все мои аргументы остаются валидными, значит.
andreyka26 Автор
Напомните, какие аргументы? Я понмню только кучу вопросов.
lair
Что для легкости изменения не нужна, скажем, архитектура со слоями (и много других "правил" тоже мешают).
andreyka26 Автор
Ну тогда зачем ребята делали абстракцию, например, на TCP\IP стеке?? Там тоже все на леерах, и она вроде-бы не течет, по крайней мере за столь бедный опыт, не было проблем с этим. Ребята дали абстракцию для работы с сетью (сокет), Никто не пишет логики поиска роута, логики транслирования битов в электрические или радио сигналы. ПОЧЕМУ? Почему сделали абстракцию над тем самым ассемблером, почему вы не пишите все на нем? Раз уж вы считаете, что абстракции текут — откажитесь совсем от них, они не несут, как вы сказали ничего полезного. По вашим словам, и простоты они не добавляют, и легкости изменения не дают.
lair
За этим, я думаю, надо в устанавливающие документы идти. Но что-то мне кажется, что не для легкости изменений, нет.
Потому что так оказалось удобнее.
Неа, я этого не говорил.
Вот вам, кстати, еще один повод подумать (раз уж вы прошлый пример проигнорировали). Есть типичное такое asp.net WebAPI, смена пароля (хэшами не заморачиваемся), один
POSTс телом. В ответ от него прилетает "Password should be at least 6 letters long", надо это сообщение поменять на "Password should be at least 6 characters long". Только сообщение, больше ничего, всю логику надо оставить как есть.Вот реализация WebAPI номер 1:
Вот номер 2:
В каком из вариантов вы поменяете сообщение быстрее? Если этот вопрос кажется вам издевательским, то вот вам более интересный: где вообще искать это сообщение во втором случае?
andreyka26 Автор
Есть для этого разного рода валидаторы, от дефолтных аспнетовских — где можно атрибутами навешать почти все констрейнты — до флюент валидаторов.
Но конкретно в этом примере — оставить это в контролере это нормально, потому что далеко не факт, что юзерСервис должен валидацией заниматься.
Не только за этим, но за этим в ТОМ ЧИСЛЕ. Потому что, с такисм пожзодом легко свичнуться например с UDP -> TCP, и при этом логика IP & LINK лееров будет не затронута, их не надо апдейтить, редеплоить и т.п. ВОТ одна из причин почему, я думаю. Плюс к тому, для борьбы со сложностью, потому что каждый леер представляет довольно сложно реализующуюся логику с разного рода алгоритмами и т.д.
lair
Вот в этом и был мой вопрос: передо мной есть такой код, где мне искать это сообщение?
Гм. А я-то думал, проверка бизнес-ограничений в бизнес-слое быть обязана… И как же на самом деле надо делать?
И это первый раз, когда вы вообще упоминаете борьбу со сложностью как критерий качества.
andreyka26 Автор
Так или иначе, я его упомянул.
lair
Вы не правы. Длина пароля — это бизнес-правило.
(я, собственно, не понимаю, что за "валидация инпута", которая не вызвана бизнес-правилами)
andreyka26 Автор
Ну тогда, этот инпут должен конвертироваться в доменную модель, которая, в свою очередь должна валидить. никак не можно считать сходной моделью конроллера — бизнес моделью — опять таки виолейшн SRP.
Даже в случае с юзер сервисом, должен быть валидатор, я думаю, как отдельный сервис, и в нем уже искать валидацию. либо же не усложнять себе жизнь и прописать все в контроллере. Если это позволяет сложность.
Насколько мне известно, валидация инпута, и бизнесс-констрейнты — это разные вещи.
lair
Где-то, наверное, конвертируется. В приведенном примере (
userService.ChangePassword(model.OldPassword, model.NewPassword)) модель, связанная с представлением, не покидает presentation layer.Я не понимаю, что вы хотели сказать.
Попробуйте просто перечислить, сколько уже мест, где искать валидацию, вы назвали, и сколько еще потенциально есть. Знаете, просто в списочек.
Что значит "позволяет сложность"? Весь пример — перед вами; сложность позволяет или нет?
Это разные вещи, потому что одно — следствие другого. Это никак не отменяет того, что валидация инпута, не вызванная бизнес-правилами — редкая и специфическая вещь (и обычно ее все равно можно проследить до бизнес-требования).
andreyka26 Автор
Входная модель контролера — не имеет ничего общего с Доменом
Если вы — новый человек в проекте — то нужно, наверное, спросить в ответственного человека — какая архитектура, и какой компонент ответственный за валидацию — и искать её там. Нету точного определения, где должна быть валидация, как и вообще нету конкретных стандартов правильной архитектуры, ну или киньте мне какой-то аналог RFC, где бы четко было прописано «как надо». Нужно прежде всего думать. А книга это набор принципов и инструментов, которые можно использовать — можно не использовать, никто же не запрещал. Только вот в нужном месте использование их — уменьшит вероятность нагавнить своим «велосипедом»
lair
Не обязана иметь. Ну да, в примере так и есть. И что?
Ну то есть что читай книжки, что не читай, что следуй паттернам, что не следуй — все равно надо идти и спрашивать. В чем тогда смысл?
А теперь давайте это сравним с вашим же утверждением из поста:
andreyka26 Автор
И где тут противоречие? Следуя принципам, разумным, естевственно, вероятность налажать будет меньше, я думаю.
lair
И где же? Вот представьте себе, что я вам сказал, что в этом примере все по DDD. Дальше что?
Пока что вам не удалось никак эту мысль подтвердить.
andreyka26 Автор
так как имеем дело с инпутом, скорее всего должно быть в апликейшн лейере. так же, если это уже относится к Домену, валидация и некоторые констрейны могут быть и в домене, в какой-то ентите к примеру. Так или иначе, если вся валидация там или там, то она на весь сервис там будет. И не нужно будет искать каждый раз в разном месте.
как и вам — вашу. Как по мне, накидать все в екшн контроллера и сказать «что в этом плохого» — так себе идея. по крайней мере не видел такого ни в одном коммерческом проекте, и ни одного совета ни от одного дева, кроме вас, делать так.
lair
Так как же узнать, в каком из двух (на самом деле — больше) "там" валидация, ни у кого не спрашивая? Вы только что говорили, что если сказано, что "по DDD", сразу понятно, где.
Нужно, нужно. Даже у вас нужно как минимум два места обойти. А теперь я вам добавлю веселья: если этот же сценарий вызывается из браузера, проверка должна делаться на клиентской стороне (отзывчивость, вот это всё).
Мне кажется, вы пока даже не понимаете мою мысль, о каком уж подтверждении тут говорить.
andreyka26 Автор
Не нужно, если ты уже раз видел где валидация на проекте.
Окей перефразирую — ты будешь знать где валидации точно не может быть. И я ещё раз повторяю, в вашем примере не вижу ничего плохого, что бы держать валидацию в контрллере. теперь представьте, там моделька на 15 пропертей, и в каждой делать иф, потом ещё логику в контроллер запихнуть — это уже посложнее будет выглядеть, и разобраться в этом посложнее будет. Ну лично мне проще перейди в какую-то папочку «validation», и разобраться там с 20 строками, нежели бегать по всему екшене на 400 строк.
Ну пока, конкретные мысли которые вы пытались донести, кроме 100500 вопросов лично мне:
— абстракции текут, в прочем, разработчики ОС, например, разработчики TCP\IP доказали, что не всегда они текут.
— что на мое «напихать всю логику в контроллере» — вы ответили, «а что в этом плохого». И виолейшн обычного SOLID принципа — это в порядке вещей, и тоже нормально. С чем я тоже, не согласен. В большинстве случаев, это может привести к проблемам.
lair
Мы говорим о человеке, который первый раз пришел на проект, и еще не видел. Если уже видел, то понятно, что вопросов нет.
И где же?
Это автоматически означает, что валидация не в одном месте.
Нет, не доказали. Чего далеко ходить, вы про проблемы с
HttpClientв .net не слышали?Это тоже был вопрос, если что.
То, что вы не согласны, понятно. Почему не согласны — тоже понятно, в книжке написано, что это плохо. Это всё?
Любой код может привести к проблемам. Вопрос в том, какой код приведет к проблемам с меньшей вероятностью, и тут ваши тезисы меня пока никак не убеждают.
lair
Кстати, забавно. Джоэл Спольски, который озвучил "закон текущих абстракций" ("All non-trivial abstractions, to some degree, are leaky"), показывает его на примере… TCP/IP.
andreyka26 Автор
lair
Это никак не отменяет закона текущих абстракций. И конкретно абстрация TCP/IP — течет.
andreyka26 Автор
Окей, дайте точное определени «текущей» абстракции.
И что же вы скажете в этом случае про ОС. У них очень даже неплохо получилось абстрагироваться от железа. Насколько все проще становиться, когда тебя не заботит как все устроенно там, под коробкой, ты просто используешь интерфейс. Это экономит время, ресурсы.
lair
Это написано в статье, на которую я дал ссылку, и по которой вы "пробежались".
Проще говоря, текущая абстракция — это когда то, что за абстракцией все равно влияет на вас, как на пользователя.
То же самое. Вы можете не заботиться, как оно там устроено, а потом вам надо гарантировать D из ACID, и все, добро пожаловать в маленький ад.
Да что там D-из-ACID, банальное различие между SSD и HDD может привести к тому, что один и тот же код выполняется быстро или медленно (и, наоборот, если мы хотим, чтобы код выполнялся быстро, нам надо прилагать дополнительные усилия). Абстракция? Да. Протекла? Да.
andreyka26 Автор
Окей, но плюсы то все ровно есть, и сложность, и изменение, не нравиться SSD — юзни HDD, а вызывающий код трогать не надо.
Ну окей, но от лейера IP & LINK абстрагороваться то получилось. И работает, ещё ни разу не слышал что бы один из них делал что-то некорректно. И их может юзать как TCP так и UDP, и их не заботит как он устроен.
lair
Плюсы — есть.
… вот только он взял и просел по скорости на порядок, а так да, трогать ничего не надо.
Ключевое — как-то.
andreyka26 Автор
Вы в этом участвовали? что точно знаете, что как-то? Так или иначе — получилось. Поэтому НЕ ВСЕ — текут. Я думаю можно сделать максимально не-текущие абстракции, вопрос в релевантности и денежных запасах.
lair
Проще, чем в каком случае?
Я этим пользуюсь. И при отладке сетей дома прыгать между уровнями приходится.
Цитата выше, спорьте с автором. Я не видел ни одной абстракции, которая бы не текла рано или поздно.
andreyka26 Автор
между какими уровнями?
Пример IP лейер стэка — где здесь утечка? Может это и так, я не спорю, просто я пока её не вижу, и хотелось бы видеть
lair
А откуда вы взяли эту альтернативу? Я ее не озвучивал.
Как минимум — application и transport. И я хорошо знаю, что нельзя просто взять и заменить tcp на udp — можно и связность потерять.
В статье, которую вы проглядели.
andreyka26 Автор
там только за TCP. С этим, пожалуй пока соглашусь.
ну да, апликейшн лейер будет зависеть от транспортного, потому что две разные имплементации транспортного в корне разные. Но вы глядите глубже, вам же не приходилось залезать в LINK & IP лейер?
lair
Я спросил, что плохого.
Подождите, но как же, как же абстракция?
Лично мне не приходилось, я вообще сетями не занимаюсь.
andreyka26 Автор
Если спросили — значит не знаете, или как?
lair
Я тоже не говорил, что все — плохие. Я говорил, что все — текут. Это не отменяет того, что даже текущие абстракции могут быть полезны, просто надо каждый (каждый!) раз помнить, что та абстрация, на которую ты сейчас встал, может потечь и потопить тебя.
Значит, не знаю, почему вы утвержаете, что это плохо.
andreyka26 Автор
Опять таки, пока что, не вижу утечки у IP & LINK лейера, и ОС. Даже в примере с SSD & HDD, разве ОС гарантирует скорость. Она гарантирует, что если система рабочая, она запишет и считает данные
lair
Объяснить — объяснили. Но не убедили.
… и даже этого она не гарантирует.
А главное, какая мне разница, что она гарантирует? Мне важно, что я не могу просто сделать вид "это абстракция, что за ней — мне не важно", я должен помнить детали конкретных реализаций. Что хуже, иногда абстрация построена так, что я не могу выяснить, какая там реализация (что, в общем-то, еще хуже).
andreyka26 Автор
Так а кто сказал, вообще не знать о деталях реализации? Вы скорее всего будете знать, как в общем что-то устроено, описывая очередную имплементацию. Только вот работать с этим проще, при росте проекта, и проще заменить на что-то другое при этом.
Ну почему же? Так, как и с TCP, есть условия, при которых есть гарантии. Так или иначе, имплементация не дает тоже никаких гарантий. Единственное, что дает гарантии в этом мире — это то, что мы все умрем. Если вы хотите гарантий — вам не к абстракциям.
lair
Говорят, что information hiding — одна из задач абстракции. Нет?
По опыту.
Угу. Вот возьмем .net (полный, на винде):
В какой момент гарантированно произойдет физическая запись этих байтиков на носитель, и какие условия нужны для выполнения этой гарантии?
andreyka26 Автор
Я точно сказать не могу, я же это не писал. Я думаю, что при том, если все системы пк будут в норме. Конечно есть возможность бага, но она исключительно мала, и легче фиксится, благодаря абстракциям,
lair
Вот это и ответ на (ваш же) вопрос "кто сказал, вообще не знать о деталях реализации?". Вы сказали. Потому что вы говорите, что важно стремиться к тому, чтобы не знать о деталях реализации. Следовательно, когда я получу абстракцию, написанную по этим правилам, у меня будет минимум (в пределе — ноль) информации о реализации. А это то, что меня не всегда устраивает.
Подождите, один из смыслов абстракции ровно в том, чтобы вы могли ей пользоваться, хотя не вы ее писали. Или нет?
Это ответ на вопрос "какие условия", но не на вопрос "когда".
И да, этот набор условий непроверяем. Я, как пользователь этой абстракции, как тот, кто пишет этот код, не имею никакой возможности проверить, что эти условия выполнены, и, как следствие, что мои данные успешно записаны.
andreyka26 Автор
lair
Отменяет, в том-то и дело. Потому что вы поменяете то, что раньше люди узнали сквозь вашу абстракцию.
Простота и легкость изменения есть только тогда, когда у вас есть непроницаемый барьер (который и создает абстракция), который говорит, кому, что и как вы должны, и ничего больше. Все за пределами этого "должны" вы вольны менять. Если ваша абстракция протекла, и люди узнали больше, чем это "должны", вы уже не можете это так просто поменять.
Аналогично и со стороны пользователя: вся видимая простота абстракции сохраняется ровно до того момента, пока мне не нужна конкретная специфика поведения, этой абстракцией не описанного, и дальше абстракция начинает мне активно мешать.
andreyka26 Автор
Ну пока она не нужна — это работает. Если становиться нужна, ну значит такая сложилась ситуация, подставить другую имплементацию под интерфейс — все равно легче, нежели лазить и барахтаться в имплементации.
По поводу этого — можно пожалуйста пример, когда у вас такая ситуация возникала.
lair
Зато не надо тратить ресурсы на абстракцию, это уже хорошо.
А дальше вопрос отношения числа случаев.
Вот только я не могу "подставить другую имплементацию под интерфейс", потому что я потребитель, мне все имплементации передают.
Как-то раз надо было нам запустить процесс парсинга asp.net-страницы внутри IIS. Подняли IIS-овский пайплайн, сделали фейковый запрос, запихнули — падает. Внутри в одном месте они не учли, что запросы бывают фейковые. Ну что, мы написали рядом костыль, котороый это место подменяет, чтобы работало правильно. А потом они в минорной версии поняли, что у них была ошибка, и починили ее — а наш костыль немедленно упал.
andreyka26 Автор
не могу понять почему. Простой пример, в DI в аспнете, когда сервис регистрируешщь, меняешь одну иплементацию на другую, при этом все сервисы, которые юзали ту имплементацию. не нуждаются в рефакторинге, фиксинге и т.д. Даже при билде, они билдится не будут.
Баг в абстракции — не проблема абстракции, а проблема разработчиков — это не делает её — плохой. Я просто не до конца понял. что за фейковые страницы, что там и как надо было парсить.
lair
Нет, не может. Это одни и те же изменения.
Вам это неизвестно.
Вы за пять секунд проектируете интерфейс? Восхищаюсь вами. Я над одним названием метода дольше думаю.
Потому что IoC и DI. Я, как потребитель сервиса, не определяю, какую реализацию сервиса мне передают, я должен работать с той, которую передали.
Вы забываете про маленький нюанс: не все "сервисы регистрируете" вы. Что вам передали — с тем и работайте, инфраструктура вам не подконтрольна.
Баг не в абстракции, а в реализации. Я не понимаю, зачем просить пример, если любой пример можно отвергнуть с теми же аргументами.
andreyka26 Автор
Но и без абстракции, вы будете потребителем, и будете работать с теми методами, которые вам представляют.
та же проблема с имплементациями, они в этом ничем не лучше, а вот для людей, которые «передают», это упрощает жизнь.
То есть, если вы некорректно напишите mergesort — то проблема в алгоритме, а не в вас?
Да, изменения те же, только чтобы поменять имя переменной в имплементации к примеру — вам не нужно будет ребилдить, и каким-то образом афектить «потребителя» абстракции — а при имплементации — придется.
lair
Неа. Если имплементация используется "по месту", она не является долгосрочным контрактом, поэтому нет необходимости ее проектировать как публичную.
Вот только я, например, смогу выбирать, какая реализация мне нужна.
Неа.
То проблема в имплементации.
Я смотрю, вы любите некорректные аналогии.
Если имплементация сырая, то потребитель абстракции все равно будет поаффекчен.
andreyka26 Автор
ну если вы разработчик — можете, только вот если вы разработчик абстракции с имплементацией — то что мешает поменять имплементацию так же, как и в случае чистой имплементации?
Да, ибо абстракция — упрощает, изолирует логики между собой, это упрощает задачу в изменении. Для чего же по вашему придумали паттерны, к примеру? Потому что были проблемы, вот с такими «грубыми» имплементациями. Все паттерны строятся через абстракцию.
Ну вот, но вы же не скажете, что сам алгоритм плох при этом? Или скажете? Именно это вы и сказали, говоря про то, как вы парсили через IIS. То, что майкрософты не углядели баг — не делает саму абстракцию плохой.
А чем плоха та аналогия?
Каким образом? Сразу пример. Имею либу(что бы сразу отпали вопросы, либа — потому, что логика будет использоваться повторно), и аспнет. В аспнете интерфейс, имплементация в либе. Есть один метод в интерфейсе, описанный. Билджу все — все окей. теперь, к примеру, нужно кусочек логики переписать в либе. Переписываю — билджу, аспнет не билдится. Почему? потому, что зависимости нету на либу. Либа зависит от абстракции. Все по Депенденси рулу. В случае вырой имплементации, аспнет бы тоже ребилдился.
lair
Если это делать после разработки — то да, немного. Но тогда все время разработки я буду зависеть от имплементации.
Я не понимаю, что вы спрашиваете.
Это вы так говорите. А в реальности это далеко не всегда так, и это всегда приносит с собой дополнительные проблемы.
Вы просили пример ситуации, когда понадобилось залезть в детали реализации, и потом за это поплатиться? Вы их получили.
Тем, что архитектура — это не дом.
Таким, что он уже заложился на другое поведение.
Вы так этим восхищаетесь, как будто это что-то важное. Так вот — нет, не важное. А на билд-сервере все равно будет собираться все целиком.
andreyka26 Автор
Почему вы говорите об имплементации абстракции, как что-то от третьей стороны, а от просто имплементации, как о чем то своем? В случае абстракции, вы сами же сможете заменить реализацию, так же, как вы собирались менять имплементацию.
ну мне это не принесло дополнительных проблем, а только облегчало жизнь, на протяжении 1,5 года ентерпрайз разработки. Согласен — может я когда-то наткнусь на эти проблемы, о которых вы знаете, в силу большего опыта. Но пока что, даже если это дает какие-то дополнительные сложности — профит перебивает все равно.
Вы привели пример БИТОЙ реализации. Приведите не битой, которая работает как-надо, а где проблему составила именно абстракция.
в случае разноса нагрузки — это очень поможет, потому что такие леера легче потом разбить на независимо деплоябельные компоненты.
Аналогия — это, вроде как, объяснение одних явление через другие, через схожесть по качествам и характеристикам явлений. То, что вы сказали сводить любую аналогию на 0.
unel
Кажется должно быть очевидным, что сообщение меняется либо там, где оно выводится (а не там, где кидается эксепшн), либо вообще в системе локализации.
У меня другой вопрос к этому примеру: как пользователь попал именно в этот файл? Раскручивая цепочку вызовов? Не проще ли было осуществить поиск по самому сообщению (по неизменяемой его части)?
lair
А где это место?
Это точка входа.
Конечно, проще. Но это автоматически делает бессмысленным заявление "архитектура дает нам ответ, где искать такой код".
unel
Как он нашёл эту точку входа? Почему он искал именно её?
Вы мне скажите =) Если просто кинуть эксепшн и не обработать его, врят ли это сформирует корректный http-ответ клиенту (наверное, тут замешана какая-то абстракция? ;-))
Не совсем так) Если бы у нас была «архитектура», то мы бы знали, что все строки хранятся там-то и там-то (в системе локализации, в константах с описанием ошибок / сообщений / etc), а не просто лежат раскатанные по всему коду.
lair
Зная конвеер обработки запроса в asp.net WebAPI
Потому что в задаче было сказано, какой запрос выдает ошибку.
Это зависит от конвеера, некоторые конвееры вполне себе это делают.
Ну так я и задал вопрос, где они хранятся, если архитектура соответствует тому, что описано в статье. Ответа пока не получил.
unel
Ответ я уже дал (в константах / системе локализации).
Или Вы рассчитываете на какой-то ещё?
Так почему не искать саму ошибку? Или получается, что мы вновь и вновь будем возвращаться во все места, где происходит валидация пароля пользователя (например, при регистрации нового) и исправлять эту ошибку ещё раз и ещё?
Ну т.е. мы всё равно должны знать этот конкретный нюанс, чтобы пользоваться данным кодом? Тогда чем он лучше другого варианта, если он тоже подразумевает под собой некую неявность?
niklisto
Это конечно все так. Но не потому, что абстракция плохая и не работает. Чаще всего просто не хотят / не умеют четко разделять слои, считают что это слишком долго, дорого и т.д.
Тот же переход с реляционки на KV например. Если сразу правильно спроектировать слой доступа к данным, то там будет, например, для сущности Customer интерфейс с необходимыми для работы приложения методами.
Поменять реализацию этого интерфейса — поменяется хранилище. На что угодно. В том числе и на KV.
Да, там будет много проблем с поиском не по ключу, с объединением данных и т.д. и т.п. Это может действительно оказаться очень долго и дорого. Но! Это реализация только слоя хранения. Те самые «детали реализации». Все остальное уже разработано, протестировано. И трогать не надо ни бизнес логику, ни UI, ни что-то другое.
После такого перехода конечно же поменяются характеристики работы приложения, такие как скорость работы, максимальная нагрузка и т.д. и т.п. Все зависит от новой реализации.
Совершенно другой вопрос — откуда необходимость столь радикальной смены хранилища? Слишком суровый архитектурный косяк, imho.
lair
Конечно. Это потому, что абстракции текут.
Как отличить правильно спроектированный слой доступа к данным от неправильно спроектированного?
Угу. Возьмем один метод,
getById(id), и посмотрим на его свойства.getById(1) == getById(1)? А вот так:getById(1).name = 'def'; print(getById(1).name)? А вот так:getCustomerRepository().getById(1) == getCustomerRepository().getById(1)? А то же самое между потоками? А между процессами (передача сериализованных данных)?Теперь добавим еще один метод:
save(entity).Что сохранится?
А теперь смотрите, в чем ловушка: совершенно не важно, какие ответы вы дадите. Важно другое — все эти ответы (и десятки других!) явно описаны где-то? На каждый из них есть тест? Или вы просто привыкли, что оно работает так?
Подождите. Вы же только что говорили, что все уже разработано и протестировано, а теперь говорите, что характеристики поменяются. Если поменялись характеристики — надо перетестировать, а если они стали неудовлетворительными — переписывать. И нет, переписывать только DAL окажется недостаточно. А это значит, ваша абстракция снова протекла.
Я этот же вопрос задаю автору статьи, потому что это его утверждение, что все это можно поменять.
Занятно, не находите? Утверждается, что архитектура, которая позволяет поменять хранилище, хорошая, но необходимость поменять хранилище — архитектурный косяк.
andreyka26 Автор
хочешь мира — готовься к войне
ну клиент, к примеру, может захотеть фичи какой-то, и из-за этого может быть придется менять хранилище, из-за того, что оно в каком-то роде не подходит
lair
Стоимость этой подготовки посчитать не забыли?
А может не захотеть, а вы уже вложили ресурсы в подготовку к этой ситуации.
Ну и да, это не отменяет исходного вопроса: если вам пришлось поменять хранилище — это архитектурный косяк, или нет?
andreyka26 Автор
я думаю, тут однозначно сказать нельзя. Если изначально было выбрано хранилище, при том что был выбор лучше подходящего, нежели выбранное, то тогда — да. Если же к такому прибегают в следствии изменения реквайрментов от клиента, наверное — нет. Опять же вы хотите получить конкретный ответ на абстрактный вопрос. Я думаю, зависит от проекта, людей и ситуации.
lair
Я не понимаю, что вы хотите сказать.
Ну да, потому что из таких вопросов и состоит выбор архитектуры. Странно, да?
andreyka26 Автор
Если захочет внести эти изменения потом — они выйдут дороже, нежели подготовка к этим изменениям на раннем этапе проекта.(Ошибки проектирование — самые дорогие)
lair
Ну вот вам конкретный пример: я пишу веб-сервис (в том смысле, что он общается с внешним миром посредством JSON по HTTP), который должен обеспечивать полнотекстовый поиск по базе статей и отслеживать качество этого поиска на основании пользовательского отклика. Как мне оценить качество его архитектуры?
Ну да. Но потом, возможно, и деньги на это будут, в отличие от старта проекта.
Вот только это не ошибка проектирования.
andreyka26 Автор
Я думаю, что на протяжении развития проекта, будут возникать новые требования на новые фичи, если текущая архитектура будет затруднять по ресурсам и времени их имплементацию. Во время обдумывания имплементации новых фич, вы осознаете, к примеру, что если бы я когда-то сделал по -другому, не было бы такой проблемы сейчас. И вот чем больше таких проблем — тем хуже архитектура, я думаю. А сразу оценку сделать, сложно я думаю. На то и придумали такие рекомендации как SOLID и Dependency Rule, что бы четко видеть, где может быть плохо сразу. По этому если ребята берут DDD, то держат домен независимым, по тому же Dependency rule. Хотя в в тот момент это может быть и не нужно, но для возможных будущих проблем это делается.
lair
Вот только это будущее, а мне сейчас писать надо. Как мне сейчас писать?
Я еще раз напомню вашу фразу из статьи:
Так как же мне "строить эту архитектуру"?
andreyka26 Автор
Есть готовые решения, которые минимизируют возможность налажать, готовые принципы — которым можно следовать. В книге эти принципы и описаны.
lair
Окей, возвращаемся на шаг раньше. Какие готовые решения и принципы надо применить при построении моего сервиса, и почему?
andreyka26 Автор
Ну как минимум SOLID, Reuse\release equivalenxe, common closure, common reuse principles, и ещё ряд рекомендаций, почему — там автор и говорит.
lair
"Там автор и говорит" без цитаты не отвечает на мой вопрос.
Например, расскажите мне, как именно я должен применить REP к своей задаче. Или, еще веселее, CCP — что именно является компонентом в моей задаче?
andreyka26 Автор
окей, по CCP: если нужно полнотекстовый поиск — это отдельный кусок логики, который можно выделить как отдельный компонент: Потому что что запихнуть туда ещё и логику валидации — это виолейшн этого принципа — ибо валидация может менятся независимо от серч енджайна. Вот, один простенький пример
lair
Гм. У меня весь код, отвечающий за полнотекстовый поиск — это формирование HTTP-запроса к ElasticSearch. Вы мне предлагаете его выделять в отдельный компонент?
andreyka26 Автор
lair
Почему для этого необходим отдельный компонент? Вы вообще помните определение компонента из книги, на которую вы ссылаетесь?
lair
Ладно, давайте я попроще вопрос задам, чтобы на примере было. У меня есть две архитектуры-кандидата, между которыми я выбираю:
Какую архитектуру из двух мне выбрать и почему?
andreyka26 Автор
Я не знаю, как работает aws lamda. Поэтому я не знаю. Я бы выбрал первый, если это единственные реквайрменты.
Было бы два микросервиса, один на артиклы, другой на фидбек. Если нужно будет что-то дополнительное реализовать, мне будет проще это добавить. К примеру скажу что может поменятся. Артиклы могут расти, и хранить все в еластике станет лишним. Например, в моем проекте, все с серч енджайна тянется только айдиха, потом уже от модельки, мы подтягиваем необходимые данный с постгресса. Это к слову тоже отдельные логики, ибо постгрес может с легкостью сменится на MYSQL, к примеру. И что бы в одном методе не менять какой то синтаксис SQL, и редеплоить все — я поменяю это только в компоненте, отвечающего за доступ к бд.
lair
Почему два? Вы понимаете недостатки двух микросервисов?
andreyka26 Автор
Почему два? потому что принципиально разные ответственности и причины для изменения у них.
lair
Забыли латентность, а это для пользователя важнее всего.
Не "когда", а "если". Если вы доживете до момента, когда проект начнет расти, а не погрязнете в разработке согласованного деплоя, системы коммуникации, протокола обмена с клиентом и прочих мелочей, которые вас тормозят.
Вы понимаете, да, что у поискового микросервиса все равно больше одной причины для изменения (равно как, впрочем, и у микросервиса фидбека)?
(забавно при этом, что выше вы предлагали другую декомпозицию, но уже про нее забыли)
andreyka26 Автор
А как это повлияет на латентность?
Я думаю это уже совсем другой вопрос. Естественно, для этого архитекторы собираются с ПМами и т.д., что бы оценить риски, и стоит ли делать вот так и все сразу, или что-то пока что оставить на потом.
имелась в виду эта, может я не правильно выразился
lair
Вообще-то, она увеличится, потому что вместо обращения к одному компоненту будет обращение к двум, а пересечение границы компонента — это дорого.
… и если они оценят иначе, то ваша архитектура перестанет быть правильной, и станет правильной какая-то другая?
Мне, конечно, нравится, как вы элегантно проигнорировали нарушение CCP в вашей декомпозиции (а при этом продолжаете говорить, что нарушение SRP в классе — это плохо).
andreyka26 Автор
нет, она станет не релевантная в данном случае.
вполне может быть — я не архитектор, и когда привел пример, я не советовался вообще ни с кем, а с потолка взял то, что первое в голову пришло. Где же там нарушение?
lair
Неа, первый фидбек пишется в момент прохождения запроса в полнотекстовый поиск (чтобы сам факт запроса фиксировать).
Вот видите. Вы все сделали по вашим правилам, а архитектура все равно "не релевантная".
Там, где каждый ваш компонент имеет больше одной причины для изменения.
andreyka26 Автор
Но такого разговора не было, никто ничего не решил — поэтому ещё не не релевантная. Просто когда обсуждали проект, в котором я — приняли, например, решение писать на микросервисах — и сейчас я понимаю, что если бы не приняли — были бы сложности.
И какая там причина изменения кроме причины изменения связанная с серч енджайном?
lair
Нет, это фидбек о работе поиска, в контексте конкретных результатов. Так что, будете архитектуру менять?
… но до такого разговора нельзя принять решение о выборе архитектуры.
У сервиса полнотекстового поиска:
У сервиса фидбека:
(я, заметим, еще не факт, что все вспомнил)
andreyka26 Автор
Теперь изменения в посыле фидбека никак не влияет на гет статей.
lair
А какая разница, в скольких оно методах, мы про компоненты говорим.
Никуда она не пропадает, она все так же в том же компоненте. В другом классе, но в том же компоненте.
Я вас еще раз спрошу: вы вообще помните определение компонента из книги, на которую вы ссылаетесь?
andreyka26 Автор
Ну в данном случае, я бы реализовал посыл по нетворку какого-то меседжа в отдельной библиотеке, а это — компонент, потому что ее можно отдельно задеплоить.
Тут я за компонент забыл, но вспомнил. Даже на уровне классов и методов принципы остаются рабочими. Пропадает только фича независимого деплоинга.
lair
Теперь у вас появился контракт между этим компонентом и вашим. Компонентов стало больше, контрактов стало больше, но проблема никуда не исчезла.
Но вообще, конечно, нельзя. Деплоить надо релиз целиком, потому что REP.
На уровне классов и компонентов этот принцип называется SRP, и там ровно те же проблемы, просто с другими словами.
andreyka26 Автор
но через инвертирование зависимостей все стает независимым, независимо деплоябельным, и независимо девелопабильным. Так или иначе эти же контракты остаются, будучи в одном компоненте.
Почему?? если н е устраивает фидбек, или его нужно слать ещё в одно место, к примеру, что мешает написать эту логику, и задеплоить только этот микросервис??? Именно поэтому он и был разделён, по этому же принципу, что бы так можно было сделать. В случае вашем же, редеплоить пришлось бы и артиклы, просто потому, что архитектура хуже бы была, а почему? потому что этот принцип (REP) не соблюден.
для того придумали Dependency Inversion.
lair
Нет, не станет.
Чтобы у вас появилась независимая разработка, вам надо разнести это по разным проектам, положить каждый в независимый версионник и настроить там сборку (желательно вместе с CI, чего уж). И это не забыв про то, что вам надо как-то прокинуть общеиспользуемый интерфейс между этими двумя проектами.
Чтобы у вас появилось независимое развертывание, вам нужно для каждого проекта сделать свое версионирование (не путать с хранилищем версий) и конвеер развертывания, и не забыть добавить проверки, чтобы у вас не оказалось в одном окружении несовместимых версий. А, и да, если вас волнует высокая доступность, то каждая точка развертывания должна иметь механизм развертывания без прекращения обслуживания, и удачи вам в выполнении этого с взаимнозависимыми "независимыми" компонентами.
А теперь вопрос — зачем мне это? Зачем мне "независимая разработка" для функциональности размером в десять строк кода? Зачем мне независимое развертывание для куска кода, который служит тонкой прослойкой между остальным кодом и ElasticSearch? Что я такого получу, что объяснит моему заказчику, почему я потратил на это в два с половиной раза больше ресурсов?
И знаете, что самое грустное? Что CCP все равно нарушен.
Потому что нормальная единица развертывания для asp.net-сервиса — это сервис целиком, а не отдельные сборки внутри него. Если вы хотите подменять сборки по отдельности, вам придется сколхозить собственный набор механизмов доставки и обновления.
Напомню, что мы говорим про поисковый "микросервис", который вы недавно предложили разбить на несколько компонентов. До фидбека мы еще не дошли (хотя в нем будет все то же самое).
Для чего именно "того"?
andreyka26 Автор
Касательно зависимости фидбека и артаклов. Окей, вы предлагаете иметь все в одной сборке. Теперь предположим, у вас появился сервис юзеров, там тоже нужно делать фидбек(слать меседж в какой-то екстернал сервис). Эта логика уже есть в артиклах, вы предлагаете это копипастить, или же юзеры теперь будут зависим компонентом от артиклов?
для того, чтобы убрать явные зависимости, и сделать компонент независимым от деталей реализации.(в статье есть картинка) — это работает на масштабах объекта, компонента, и сервисов в целом.
Можно это сделать через РЕСТ, объявить фидбек, как интернальный микросервис, и все делать через него, и мы сможем независимо деплоить его.
lair
А разве можно считать хорошим нерентабельный подход?
Вы опять переводите тему. Нет, не касательно "зависимости фидбека и артаклов". Меня интересует только выделенный вами микросервис поиска, который — в вашей декомпозиции! — нарушает CCP. Про фидбек поговорим потом.
Нет, не предлагаю.
Вы мне хотите сказать, что код, использующий интерфейс, не имеет явной зависимости от этого интерфейса?
Я еще раз повторю, мне не сложно: мы. говорим. не. про. фидбек. Мы говорим про один микросервис поиска по статьям.
andreyka26 Автор
Окей уберем фидбек, есть сервис, который отвечает только за артиклы(полнотекстовый поиск), где здесь виолейшн? Пришел запрос на вебсервис, пошел на абстракцию серч енджайна — вернул данные, где тут виолейшн ССP?
Да. Таким образом и строится архитектура по ДДД, абстракция репозитория в домене, и домен неимеет явных зависимостей на инфраструктуру.
в этом же ответе выше.
lair
Если я не могу его купить, он для меня хуже. Аналогично, если бизнес не можете себе позволить архитектуру, значит, эта архитектура хуже для этого бизнеса, чем другая.
Там, где у этого сервиса как минимум четыре причины для изменения, совершенно разных по времени.
Гм.
Вы мне хотите сказать, что у класса
Someнет явной зависимости от интерфейсаIDependency?Вот только и домен, и инфраструктура имеют явную зависимость от этой абстракции. А это именно то, о чем я вас спрашивал.
andreyka26 Автор
а вы в том же неймспейсе оставьте интерфейс — и не будет зависимости.
Инфраструктура — имеет, домен нет. Домен независим от остальных лееров при этом.
lair
Почему же, вполне объективный. Наличие ресурсов — это объективный фактор.
Никуда она не денется. Не важно, где интерфейс, если интерфейса нет — код не скомпилируется.
Оба имеют.
Ну да, от других слоев он теоретически независим. И что?
Я так понимаю, вы на нарушение CCP забили? Оказался неважный принцип?
andreyka26 Автор
Хотя, если так все сложить, как вы сказали — действительно зависимость будет. Но причин для изменения абстракции меньше — нежели имплементации. Абстракция стабильнее, именно поэтому зависимость на ней, а не на деталях реализации. Об этом, к слову, автор книги тоже говорит.
Вернемся обратно к аналогии с домом и квартирой, от количества ресурсов, сам дом и квартира лучше не станут, или хуже. Они уже такие, какие есть.
«независимость суждений, мнений, представлений и т.п. от субъекта, его взглядов, интересов, вкусов, предпочтений и т.д. (противоположность — субъективность). О. означает способность не предвзято и без предрассудков вникать в содержание дела, представлять объект так, как он существует сам по себе» с словаря — ключевое слово . Дом, САМ ПО СЕБЕ, а не в контексте сколько у вас есть бюджета.
как по мне, там нету виолейшна, сервис один, в себе имеет логику, которая связанна с полнотекстовым поиском.
Независимость слоев — это тоже архитектура. Она дают простоту, изолирует один слой от другого, делает независимость одного слоя от другого, и логически связывает логику в одном. слое.
lair
Не на этапе разработки. Но спасибо, кэп, да.
Архитектура не существует сама по себе.
Я то же самое могу сказать про ситуацию, когда вообще все сделано в одном сервисе: "сервис один, в себе имеет логику, которая связана с полнотекстовым поиском". Будет ли это означать, что сделать все в одном сервисе не нарушает CCP?
Независимость слоев делает независимость слоев. Угу. Зачем мне это?
Ваше утверждение "дает простоту" ничем не подтверждено. Вы это говорите, но на примере конкретной задачи все предлагаемые вами принципы только усложняют решение.
Неа. Независимость слоев никак не влияет на логическую связность логики в одном слое.
andreyka26 Автор
почему же?
Нет, потому, что в вашем случае логика будет на посыл фидбека. А в моем, только артиклы.
ну вы когда пишете слой — пишете связанную логично там логику.
lair
А на этапе продакшна уже и трогать не надо. Пусть работает.
Потому что она призвана выполнять задачу. Без задачи это просто чьи-то размышления о благом.
Во-первых, нет, не только артиклы — еще отправка фидбека по запросам.
А во-вторых, CCP формулируется не в терминах логики, а в терминах причин для изменения: "Gather into components those classes that change for the same reasons and at the same times. Separate into different components those classes that change at different times and for different reasons."
Или это так, несущественные мелочи?
andreyka26 Автор
выполнять задачу — это о поведении апликейшна, а архитектура — это о другом, о чем, спросите? — я это выше говорил.
я говорю оо артиклах без фидбека. Если фидбек включать, я уже говорил, что это был бы отдельный рест скорее всего.
Все правильно, сервис артиклов — отправляет запрос на серч енджайн — выдает респонс. Если отправлять фидбек — то через абстракцию, — это не ответственность артиклов, потому что они бы не имели имплементации фидбеков.
lair
… и в этот момент снова не понятно, то ли надо имплементацию менять, а то ли интерфейс трогать.
Неа. Архитектура должна выполнять задачу, которую перед ней поставили. Поддерживать расширяемость — задача. Поддерживать тестируемость — задача. Позволять работать в облаке — задача. Ну и так далее...
Вы не понимаете. Он отправляет фидбек о том, какие запросы были сделаны. Он должен это делать.
"Все правильно" — это сколько у него причин для изменения?
andreyka26 Автор
ааа, я вас неправильно понял. С этим полностью солидарен. Кстати говоря, тестировать то проще с абстракциями и интерфейсами. Расширять — тоже проще с абстракциями.
Ну в моем случае будет отдельный сервис(по сути класс с интерфейсом), который будет иметь метод — отправить фидбек. Можно сделать отдельную либу, которая будет отправлять что-то наружу. И заюзать ее. Сервис будет делать тоже — возвращать артиклы, только ещё к тому, на каком-то интерфейсе вызывать _externalInteractor.SendMessage(string message). он не будет имплементить это, он просто вызовет метод. Если нужно будет, потом леер, который отвечает за отправку меседжа можно изменять, дополнять — что угодно. Только это будет проще, нежели искать эту имплементацию в методе, где с статьями работают.
причина — изменение логики, либо чего-то связанного с серч енджайном. Сервис по себе не зависит от посыла фидбек, ибо он это не имплементит.
niklisto
Вот в этом как раз и проблема всегда. Вы размываете границы между слоями. Вы получили данные из DAL, дальше что вы с ними делаете — не его ответственность. Разные потоки, процессы, да хоть дата центры.
На этот вопрос ответит реализация абстракции TransactionManager
На весь функционал, который востребован — да, все описано и покрыто тестами. Иначе подмена реализации чревата проблемами. Да и непонятно как работала первая реализация.
Вы тут забыли прихватить в цитату окончание фразыЭти вещи обязательно поменяются, т.к. напрямую зависят от характеристик хранилища данных. Но перетестирования всего остального не потребуется. Верстка UI от этого не поломается. Бизнес логика какой была, такой и осталась. Или вы хотите поменять часть приложения так, чтобы ничего не поменялось? Так архитектура не об этом.
Не особо. Есть архитектура приложения, которая позволяет заменить часть приложения, если вдруг это необходимо, без необходимости переписывать вообще всё. И есть архитектурное решение — «мы тут посоветовались и я решил» — используем вот это хранилище. С моей точки зрения эти вещи не связаны. Но если второе вдруг оказалось неверным, то пусть лучше первое будет, чем не будет.
lair
То есть на момент проектирования — никак? В таком случае задача "сразу правильно спроектировать слой доступа к данным" невыполнима.
Я не размываю ответственность, я задаю конкретные вопросы. Потому что это все важно.
… которой у вас раньше не было, следовательно, ваш изначальный пример уже неполон (и, как следствие, неверен).
Ну то есть сделано очень много работы, применимость которой в будущем под большим вопросом.
Потребуется перетестирование системы в целом — а это включает "все остальное".
А о чем тогда "архитектура"?
До тех пор, пока разработка "первого" не оказалась настолько дорогой, что до второго вы не дошли.
unel
А если она просто пройдёт менее заметно и менее больно — это уже может быть плюсом абстракции?
Суровая реальность допускает некий объём прочности, прежде, чем абстракция протечёт.
Да, все абстракции текут, но это вовсе не повод ими не пользоваться вообще.
lair
Если пройдет — то да.
Я, в общем-то, и не утверждал обратного. Просто надо помнить стоимость абстракции.
unel
Безусловно! Впрочем, надо так же учитывать и стоимость «прямолинейного кода» (без абстракции), ведь сопровождение кода не бесплатно. И до тех пор пока абстракция не потекла, она предназначена как раз таки облегчать его сопровождение
lair
Конечно, надо. А дальше надо сравнивать несколько величин, а не просто говорить "давайте добавим абстракцию, и все станет лучше".
Предназначена, да. Выполняет ли она это предназначение просто тем фактом, что она — абстракция? Нет.
unel
Ну тут уже разница в интерпретациях самого термина. Выделение существенных элементов и сокрытие менее значимых (в данном месте) в целом выполняет это предназначение.
andreyka26 Автор
Где вы раньше были? Я пробовал то же самое донести в дискуссии, но как-то не получилось подобрать точные слова, как вы это сделали.