

Системы машинного обучения рождаются от союза кода и данных. Код сообщает, как машина должна учиться, а данные обучения включают в себя то, чему нужно учиться. Научные круги в основном занимаются способами улучшения алгоритмов обучения. Однако когда дело доходит до создания практических систем ИИ, набор данных, на котором выполняется обучение, по крайней мере столь же важен для точности, как и выбор алгоритма.
Существует множество инструментов для улучшения моделей машинного обучения, однако чрезвычайно мало способов улучшения набора данных. Наша компания много размышляет над тем, как можно систематически улучшать наборы данных для машинного обучения.
Совершенствование набора данных может значительно повысить точность ИИ
В своём недавнем докладе Эндрю Ын рассказал историю о проекте, над которым он работал в Landing AI, создавая систему компьютерного зрения для поиска дефектов в стали. Их первая попытка реализации системы имела точность 76%. Люди способны обнаруживать дефекты с точностью 90%, поэтому система была недостаточно хороша для запуска в продакшен. После этого работавшая над проектом команда разделилась на две части. Одна команда работала над проверкой различных типов моделей, гиперпараметров и изменений архитектуры. Вторая стремилась повысить качество набора данных. Спустя несколько недель итераций появились результаты. Несмотря на огромные усилия, занимавшаяся моделями команда никак не смогла повысить точность. С другой стороны, улучшавшая данные команда смогла получить рост точности на 16%. Улучшение набора данных для этой задачи позволило превысить результаты человека.
Устранив ошибки в наборе данных, команда смогла превратить не дотягивающий до человека алгоритм в превосходящий его.
И эта история не уникальна. У меня был подобный опыт в Humanloop. Мы работали с командой юристов из крупной бухгалтерской фирмы над обучением классификатора документов по юридическим договорам. Как и поиск дефектов в стали, эта задача требовала опыта в данной сфере. После завершения первого раунда разметки и обучения модель всё ещё не дотягивала до уровня показателей человека. У Humanloop есть инструмент для изучения примеров данных, в которых расходятся мнения модели ИИ и живых аннотаторов. Благодаря этому инструменту команде удалось найти примерно 30 случаев ошибочной классификации в наборе данных из 1000 документов. Устранения этих 30 ошибок было достаточно для того, чтобы система ИИ достигла уровня человека.
Как выглядят «баги в данных»?
Сейчас активно обсуждают «подготовку данных» и «очистку данных», но что отличает высококачественные данные от низкокачественных?
В большинстве систем машинного обучения сегодня применяется контролируемое обучение. Это значит, что данные обучения состоят их пар (input, output), и мы хотим, чтобы система могла получать входные данные и сопоставлять их с выходными. Например, входными данными может быть аудиоклип, а выходными — транскрипция речи. Или входными данными может быть фотография повреждённого автомобиля, а выходными — места всех царапин. Humanloop в основном занимается NLP, поэтому примером входных данных для нас может быть сообщение в службу поддержки клиентов, а выходными — шаблон ответа. Для создания таких наборов данных обучения обычно требуется, чтобы человек вручную размечал входные данные, по которым должен обучаться компьютер.
Если в разметке данных присутствует неопределённость, то для достижения высокой точности модели машинного обучения может понадобиться больше данных. Сбор и аннотирование данных могут оказаться неправильными по многим причинам:
-
Простые ошибки аннотирования. Простейший тип ошибки — это неправильное аннотирование. Аннотатор, уставший от большого количества разметки, случайно помещает пример данных не в тот класс. Хоть это и простая ошибка, она встречается на удивление часто, и может иметь огромное отрицательное влияние на производительность системы ИИ. Недавнее изучение наборов данных для бенчмарков в исследованиях компьютерного зрения выявило, что более 3% от всех данных было размечено ошибочно. Более 6% проверочного набора данных Imagenet размечено ошибочно. Как можно ожидать высокой производительности, если данные в бенчмарках неверны?
-
Несоответствия в руководствах по аннотированию. В аннотировании элементов данных часто присутствуют тонкости. Например, представьте, что вас попросили читать посты в социальных сетях и аннотировать, являются ли они обзорами продуктов. Задача кажется простой, но как только начинаешь аннотировать, быстро осознаёшь, что «продукт» — это довольно расплывчатое понятие. Нужно ли считать продуктами цифровые медиа, например, подкасты или фильмы? Один аннотатор скажет «да», другой «нет», поэтому точность вашей системы ИИ неизбежно снизится. А если вас попросили обозначить ограничивающими прямоугольниками пешеходов на фотографиях для беспилотных автомобилей, то какую часть фона можно включать в прямоугольник?

Оба этих примера кажутся живому аннотатору логичными, но если между аннотаторами возникнут разногласия, то неизбежно пострадает качество модели. Командам нужно находить способы быстрого поиска источников проблем между аннотаторами и моделью, а затем устранять их. -
Несбалансированные данные или отсутствующие классы. Способ сбора данных сильно влияет на состав наборов данных, что в свою очередь может повлиять на точность моделей на конкретных классах или подмножествах данных. В большинстве наборов данных из реального мира количество примеров в каждой категории, которые мы хотим классифицировать (баланс классов) может сильно варьироваться. Это может приводить к снижению точности, а также к усугублению проблем баланса и перекосам.
Например, система распознавания лиц ИИ Google была печально известна тем, что плохо распознавала лица цветных людей, что в большой степени было результатом использования набора данных с недостаточно разнообразными примерами (среди множества прочих проблем).
Инструменты наподобие активного обучения помогают находить редкие классы в крупных наборах данных, чтобы упростить создание богатых и сбалансированных наборов.
Ещё важнее качество данных для небольших наборов данных
У большинства компаний и исследовательских групп нет доступа к масштабным наборам данных, которые имеются у Google, Facebook и других технологических гигантов. Когда набор данных настолько велик, можно закрыть глаза на небольшой шум в данных. Однако большинство команд работает в областях, где существуют только сотни или тысячи размеченных примеров. В этой сфере с малым объёмом данных качество этих данных становится ещё более важным.
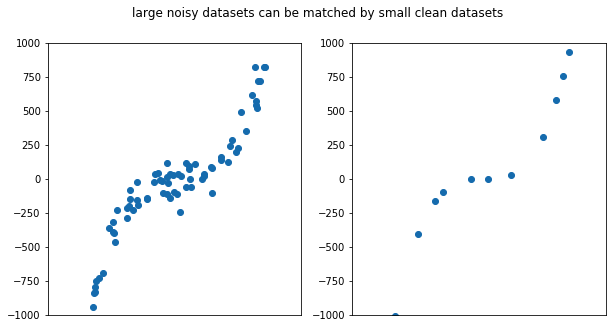
Чтобы получить некоторое понимание того, почему качество данных настолько важно, рассмотрим описанную выше очень простую одномерную задачу контролируемого обучения. В этом случае мы пытаемся подстроить кривую под некие измеренные точки данных. Слева мы видим большой шумный набор данных, а справа — небольшой чистый набор. Вполне очевидно, что небольшое число точек данных с очень низким шумом демонстрирует ту же кривую, что и большой, но шумный набор данных. Из этого можно сделать вывод о том, что шум в небольших наборах данных особенно вреден. Хотя большинство задач машинного обучения имеют высокую размерность, они работают на тех же принципах, что и приближение кривой, и подвержены аналогичным проблемам.
Разумный подбор инструментов может сильно влиять на повышение качества данных
Существует множество инструментов для улучшения моделей машинного обучения, но как можно систематически совершенствовать наборы данных для машинного обучения?
Инструменты очистки данных
В некоторых командах начинают применять следующий рабочий процесс: итерации между обучением моделей и исправлением «багов данных». Появляются инструменты, упрощающие этот процесс, например, шум меток в контексте и аквариумное обучение, или отладчик данных Humanloop.
Эти инструменты работают следующим образом: они используют обучаемую модель, чтобы находить «баги данных». Это можно реализовать изучением областей, в которых возникают сильные противоречия между моделью и человеком, или классов, где есть сильные противоречия между разными аннотаторами. Различные способы визуализации помогают находить кластеры ошибок и устранять их одновременно.
Частичная разметка
Ещё один подход к улучшению наборов данных заключается в том, чтобы учитывать наличие шума, но использовать эвристические правила для увеличения масштабов аннотирования.
Как мы видим из показанного выше примера, можно получить хорошие результаты или на очень маленьких, но чистых наборах данных, или на очень больших, но шумных наборах. Идея частичной разметки заключается в автоматической генерации очень большого количества шумных меток. Эти метки генерируются благодаря тому, что специалисты в соответствующей области создают эвристические правила.
Например, может существовать такое правило для классификатора электронных писем: «пометить письмо как резюме по работе, если в нём содержится слово „cv“. Это правило будет не очень надёжным, но его можно автоматически применить к тысячам или миллионам примеров.
Если таких правил много, то их метки можно скомбинировать и очистить от шума, чтобы создать высококачественные данные.
Активное обучение
Инструменты очистки данных всё равно используют труд человека по ручному поиску ошибок в наборах данных и не помогают справляться с описанными выше проблемами дисбаланса классов. Активное обучение — это методика, обучающая модель в процессе того, как команда аннотирует данные и использует эту модель для поиска самых ценных данных. Активное обучение может автоматически улучшать баланс наборов данных и помогать командам создавать модели с высокой производительностью при значительно меньшем количестве данных.
Использование принципа „главное — это данные“ повышает степень взаимодействия команд
Как мы писали недавно, одним из серьёзных преимуществ использования принципа „главное — это данные“ в машинном обучении является то, что он обеспечивает гораздо более тесное взаимодействие различных команд. Улучшение наборов данных усиливает взаимодействие между аннотирующими данные специалистами в области и дата-саентистами, которые думают о том, как обучать модели.
А какие способы контроля качества разметки используете вы?
Комментарии (11)

amarao
24.01.2022 15:03А никто не пробовал использовать модель для поиска ошибок в данных? Например, если у нас есть N образцов, то мы можем тренировать на N-1 образце и смотреть, насколько N'ы образец соответствует N-1 модели. Если не соответствует, привлекать оператора для сурового "да" или переразметки.
В целом, если из миллиона образцов 200 будет отмечено как "странные", то над ними уже можно подумать и обсудить человекам...

S_A
24.01.2022 15:27У моделей есть не просто да/нет, а некоторое "подобие" вероятности (можно калибровать).
Так вот сэмплы, где модель на грани сомнения, не мешает подвергать пристальному взгляду. Но это имеет смысл для не переобученных (overfitted) моделей.
Еще, на Хабре была статья про разные распределения трэйна и теста. Есть также "просто" поиск аномалий, который разными способами проверяет на соответствие распределению (local outlier factor например).
И предложенный метод тоже применялся и для imagenet вроде, уже не вспомню статью. Докинуло скора после переразметки.
Но есть проблематичное с этим подходом в том, что если в природе существует ненулевая вероятность ошибки, то есть шанс не отличить собаку от кошки, то ошибка модели будет не нулевой, и можно пропустить все же плохие сэмплы (и кроссвалидация не отработает). Особенно на малых датасетах. А миллионные учить долго, особенно с leave one out (проверять на N+1 отложенном сэмпле). Если есть еще и дисбаланс в датасете, то еще сложнее будет ловить отличия моделью.
В итоге, все классификаторы не дотягивают до идеального, да и тот работает с ошибкой (на не детерминированных данных).

kucev Автор
24.01.2022 17:09Да, хорошая идея, она много где используется. Больше всего мне реализация у https://hasty.ai/quality-control понравилась. Но мы у себя в компании на базе CVAT такую штуку реализовали и нам скрипт скидывает ссылки на таски разметчиков, у которых ответ с обученной неронкой не сошелся.


Groramar
24.01.2022 23:55Устранения этих 30 ошибок было достаточно для того, чтобы система ИИ достигла уровня человека.
Можно узнать как именно устраняли и вообще как устраняются подобные ошибки? Занова перучивать?
Goupil
Garbage in - garbage out, к ML это тоже применимо. А вот что делать если данные противоречивые по своей природе, что часто бывает в биомедицинских данных?
S_A
Искать разделяющую фичу... может синтетически как-то, если даже медицине она неизвестна. На правах гипотезы.
Goupil
Спасибо. Простой пример, чтобы понимать в чем сложность - то, что мед сообществом понимается как одна нохологическая единица (болезнь) может быть соверщенно разными болезями по этиологии и патогенезу, но с общим деталями. Просто на уровне научного понимания или медицинского консенсуса их считают за одну. При включении их в обучающую выборку под одним лейблом получается каша. Интересно есть ли можно ли надежно понять, что модель плохо учится не из-за криворукой разметки данных, а потому что изначально данные гетерогенные по лейблам?
S_A
а) кластеризовывать со своей метрикой и смотреть статистику кластеров, в том числе по признакам. кластеры (и расстояния до центроид) можно подавать в классификаторы,
б) интерпретировать модели локально (то есть смотреть что дало вклад в конкретный предикт, shap values например), и смотреть как группируются интерпретации в датасете. объявлять группы чем-то различным.
это все достаточно искусственно. то что вы описали текстом - то что различает эти самые единицы - и есть хорошие разделяющие фичи. так что может сначала научиться выделять их наличие/различие... а там дальше стэкинг.
но я с мед. данными не работал, так что все это навскидку.
S_A
знал бы прикуп, жил бы в Сочи)) считайте, если достаточно толстая двух-трехслойная нейросеть без переобучения даёт какую-то метрику, если нет каких-то проблем с предобработками и дефектами в коде... больше не выжмете из данных.
Думаю вам знаком датасет breast cancer. что там можно выжать больше, чем выжали?.. а да наверное ничего.
ну и мой коммент ниже, про неустранимую ошибку, так же в силе...
YNK
Нозологическую единицу полагают единственным диагнозом только в той терминологической формулировке, в которой его можно перевести в международный статистический код (МКБ). Статистика помогает врачам не путаться в ситуациях когда из-за многокомпонентной сложности диагноза приходится лечить в одном эпизоде по основному заболеванию, а в другом обследовать по сопутствующему синдрому.