

Для создания революционно нового ИИ следующего поколения необходимы мощные суперкомпьютеры, способные выполнять квинтиллионы операций в секунду. Meta представляет новый суперкомпьютер с искусственным интеллектом. По словам материнской компании Facebook, когда AI Research SuperCluster (RSC) будет полностью построен, он станет самым быстрым суперкомпьютером с ИИ в мире. Это стало результатом почти двухлетней работы нескольких сотен человек. В проекте приняли участие исследователи из Nvidia Inc., Penguin Computing Inc. и Pure Storage Inc.
Meta заявила, что её исследовательская группа в настоящее время использует суперкомпьютер для обучения моделей ИИ обработке естественного языка и компьютерному зрению. Цель состоит в том, чтобы расширить возможности однодневных обучающих моделей с более чем триллионом параметров на наборах данных размером до эксабайта, что эквивалентно высококачественному видео длительность примерно в 36 000 лет.
«То, что мы создаем для Метавселенной, требует огромных вычислительных мощностей… и RSC позволит создавать новые модели ИИ, которые могут учиться на триллионах примеров, понимать сотни языков и многое другое», — заявил Марк Цукерберг.
По данным Meta, в новом суперкомпьютере с искусственным интеллектом установлено 6080 графических процессоров Nvidia, что ставит его на пятое место среди самых быстрых суперкомпьютеров в мире. К середине лета 2022 года, когда AI Research SuperCluster будет полностью построен, в нём будет размещено 16 000 графических процессоров. Компания пока что отказывается комментировать расположение объекта и его стоимость.

На пути к Метавселенной
Мета начала делать долгосрочные инвестиции в ИИ с 2013 года, когда создали Исследовательскую лабораторию искусственного интеллекта Facebook. В последние годы они добились значительных успехов в области искусственного интеллекта благодаря лидерству в ряде областей, включая самоконтролируемое обучение, где алгоритмы могут учиться на огромном количестве неразмеченных примеров, и трансформеры, которые позволяют моделям ИИ более эффективно «рассуждать», сосредотачиваясь на определённых областях вводимой информации.
Чтобы в полной мере реализовать преимущества самоконтролируемого обучения и моделей на основе трансформеров различных областей, будь то зрение, речь, язык или выявление вредоносного контента, требует обучения всё более сложных и адаптируемых моделей. Компьютерному зрению, например, необходимо обрабатывать большие и длинные видео с более высокой частотой дискретизации данных. Распознавание речи должно хорошо работать даже в сложных условиях с большим количеством фонового шума и «понимать» больше языков, диалектов и акцентов. Робототехника и мультимодальный ИИ помогут людям выполнять полезные задачи в реальном мире.
Например, одним из ИИ для которых разработан RSC является аудиовизуальный скрытый блок BERT (Audio-Visual Hidden Unit BERT, AV-HuBERT), современная самоконтролируемая платформа для распознавания речи, которая учится как с помощью «слуха», так и с помощью «зрения». Это первая система, которая совместно моделирует речь и движения губ из неразмеченных данных — необработанного видео, которое ещё не было расшифровано. AV-HuBERT на 75 % точнее, чем лучшие аудиовизуальные системы распознавания речи (которые используют как звук, так и изображение говорящего, чтобы понять, что говорит человек). Поскольку для большинства языков мира трудно получить большие объёмы размеченных данных, подход AV-HuBERT с самоконтролем поможет создать устойчивые к шуму системы автоматического распознавания речи для большего количества языков и приложений.

Первое поколение высокопроизводительной инфраструктуры, разработанное в 2017 году, включает 22 000 графических процессоров NVIDIA V100 с тензорными ядрами в одном кластере, выполняющем 35 000 учебных заданий в день. До сих пор такая инфраструктура устанавливала планку для исследователей Meta с точки зрения её производительности, надежности и производительности.
В начале 2020 года было решено, что лучший способ ускорить прогресс — это спроектировать новую вычислительную инфраструктуру с чистого листа, чтобы использовать преимущества новой технологии GPU и сетевой структуры.
В то время как сообщество высокопроизводительных вычислений десятилетиями боролось с масштабированием, необходимо было убедиться, что у Meta есть все необходимые средства контроля безопасности и конфиденциальности для защиты любых данных обучения, которые используются. В отличие от предыдущей исследовательской инфраструктуры ИИ, которая использовала только открытый исходный код и другие общедоступные наборы данных, RSC помогает обеспечить эффективное воплощение исследований в жизнь, позволяя включать реальные примеры из производственных систем Meta в обучение моделей. Это первый раз, когда производительность, надежность, безопасность и конфиденциальность решаются в таком масштабе.

Обычные суперкомпьютеры оптимизированы для высокоточной деятельности, в то время как суперкомпьютеры с искусственным интеллектом работают с гораздо более низкими уровнями точности. ИИ обычно требует, чтобы компьютеры одновременно выполняли большое количество низкоточных вычислений. Графические процессоры хорошо подходят для этой задачи, поскольку они имеют тысячи вычислительных ядер, которые могут работать одновременно.
Высокопроизводительная вычислительная инфраструктура, жизненно необходима, чтобы разобраться в тех объёмах данных, которые есть у Facebook. Это сокровищница данных, которую получают от пользователей, и этот набор данных слишком огромен для большинства систем искусственного интеллекта, которые обычно используют исследователи.
В конечном итоге суперкомпьютер поможет создавать модели ИИ, которые могут совместно анализировать текст, изображения и видео и разрабатывать инструменты дополненной реальности. Эта технология также поможет Meta более легко выявлять вредоносный контент и будет направлена на то, чтобы помочь исследователям разработать модели искусственного интеллекта, которые работают подобно человеческому мозгу. RSC поможет создать совершенно новые системы искусственного интеллекта, которые смогут, например, обеспечивать голосовой перевод в реальном времени для больших групп людей, каждый из которых говорит на своем языке, чтобы они могли беспрепятственно сотрудничать в исследовательском проекте или вместе играть в игру с дополненной реальностью. В конечном итоге работа, проделанная с RSC, проложит путь к созданию технологий для следующей крупной вычислительной платформы — Метавселенной.
Под капотом
Проектирование и создание чего-то вроде RSC зависит от производительности в максимально возможном масштабе самых передовых технологий доступных сегодня. Вся эта инфраструктура должна быть чрезвычайно надежной, поскольку, некоторые эксперименты могут длиться неделями и требовать тысяч графических процессоров. Наконец, весь опыт использования RSC должен быть удобным для исследователей, чтобы команды могли легко исследовать широкий спектр моделей ИИ.

Большая часть достижения этого была достигнута благодаря работе с рядом давних партнеров Meta, каждый из которых также помог разработать первое поколение инфраструктуры искусственного интеллекта в 2017 году. Penguin Computing работала с операционной группой по интеграции оборудования для развертывания RSC и помогла настроить основные части плоскости управления. Pure Storage предоставила надёжное и масштабируемое решение для хранения данных. NVIDIA предоставила свои вычислительные технологии искусственного интеллекта с передовыми системами, графическими процессорами и коммутационной сетью InfiniBand, а также компоненты программного стека, такие как NCCL.
Суперкомпьютеры с искусственным интеллектом строятся путём объединения нескольких графических процессоров в вычислительные узлы, которые затем соединяются с помощью высокопроизводительной сетевой структуры для обеспечения быстрой связи между этими графическими процессорами. Сегодня RSC включает в общей сложности 760 систем NVIDIA DGX A100 в качестве вычислительных узлов, что в общей сложности составляет 6080 графических процессоров, причём каждый графический процессор A100 более мощный, чем V100, использовавшийся в предыдущей системе. Каждый DGX обменивается данными через двухуровневую матрицу Clos NVIDIA Quantum 1600 Гбит/с InfiniBand. Уровень хранения RSC включает 175 петабайт Pure Storage FlashArray, 46 петабайт кэш-памяти в системах Penguin Computing Altus и 10 петабайт Pure Storage FlashBlade.
Ранние тесты RSC по сравнению с устаревшей производственной и исследовательской инфраструктурой Meta показали, что он запускает рабочие процессы компьютерного зрения до 20 раз быстрее, запускает библиотеку коллективных коммуникаций NVIDIA (NCCL) более чем в девять раз быстрее и обучает крупномасштабные модели распознавания речи в три раза быстрее. Это означает, что модель с десятками миллиардов параметров может завершить обучение за три недели по сравнению с девятью неделями ранней версии.

Помимо самой базовой системы, также требовалось мощное решение для хранения данных, которое могло бы обслуживать терабайты пропускной способности системы хранения эксабайтного масштаба. Чтобы удовлетворить растущие потребности в пропускной способности и емкости для обучения ИИ, с нуля разработали службу хранения AI Research Store (AIRStore). Для оптимизации моделей ИИ в AIRStore используется новый этап подготовки данных, который предварительно обрабатывает набор данных, который будет использоваться для обучения. После того как подготовка выполнена один раз, подготовленный набор данных можно использовать для нескольких тренировочных прогонов, пока не истечёт срок его действия. AIRStore также оптимизирует передачу данных, чтобы свести к минимуму межрегиональный трафик в магистрали между центрами обработки данных Meta.
Чтобы создавать новые модели ИИ, которые приносят пользу людям — будь то обнаружение вредоносного контента или создание новых возможностей дополненной реальности — необходимо обучать модели, используя реальные данные из существующих производственных систем. RSC был разработан с нуля с учётом конфиденциальности и безопасности, поэтому исследователи Meta могут безопасно обучать модели, используя зашифрованные пользовательские данные, которые не расшифровываются до непосредственного момента обучения. Например, RSC изолирован от Интернета, без прямых входящих и исходящих соединений, а трафик может проходить только из производственных центров обработки данных Meta.
Чтобы соответствовать требованиям конфиденциальности и безопасности, весь путь данных от систем хранения до графических процессоров полностью зашифрован и имеет необходимые инструменты и процессы для проверки соблюдения этих требований в любое время. Прежде чем данные будут импортированы в RSC, они должны пройти процесс проверки конфиденциальности, чтобы подтвердить, что они были правильно анонимизированы или были приняты альтернативные меры безопасности для защиты данных. Затем данные шифруются, прежде чем их можно будет использовать для обучения моделей ИИ. Данные и ключи дешифрования регулярно удаляются, чтобы гарантировать, что старые данные недоступны. А поскольку данные расшифровываются только в одной конечной точке, в памяти, они защищены даже в маловероятном случае физического взлома объекта.

Второй этап
RSC, по утверждению Meta, должен составить конкуренцию суперкомпьютеру Perlmutter из Национальной лаборатории Лоуренса в Беркли. Пока что, RSC пятый самый мощный суперкомпьютер, который сейчас работает. Это может измениться, поскольку компания продолжает строить систему. В конечном итоге они планируют сделать его в три раза мощнее, что теоретически позволит ему претендовать на третье место. Но тут есть оговорка. Такие системы, как Summit из Ливерморской национальной лаборатории Лоуренса, занимающая второе место, используются в исследовательских целях, где точность имеет первостепенное значение. Если смоделировать молекулы в какой-либо области атмосферы Земли с беспрецедентным уровнем детализации, то нужно довести каждый расчёт до большого количества после десятичной запятой. А это означает, что эти вычисления требуют больших вычислительных затрат.
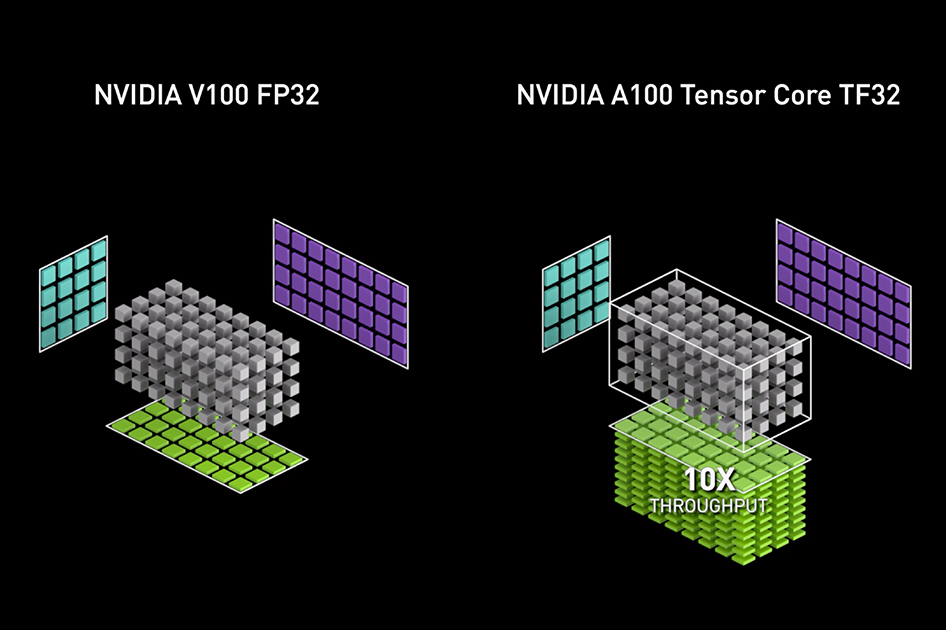
В Мета объясняют, что приложениям ИИ не требуется подобная степень точности, поскольку результаты не зависят от этой тысячной доли процента — операции вывода в конечном итоге дают результаты по типу, «90 % уверенность, что это кошка», и если бы это число было 89 % или 91 % не имело бы большого значения. Трудность заключается скорее в достижении этих 90 % уверенности для миллиона объектов или фраз, а не для сотни. Это всего лишь упрощение, но в результате RSC, работающий в математическом режиме TensorFloat-32, может получить больше FLOP/s (операций с плавающей запятой в секунду) на ядро, чем другие, более ориентированные на точность системы. В данном случае это до 1 895 000 терафлоп/с, или 1,9 экзафлоп/с, что в 4 раза больше, чем у Fugaku. Но всё это не меняет того факта, что RSC будет одним из самых быстрых компьютеров в мире, возможно, самым быстрым из тех, которые будут использоваться частной компанией для собственных целей.
RSC запущен и работает сегодня, но его разработка продолжается. Как только завершится второй этап создания RSC, это будет самый быстрый суперкомпьютер с искусственным интеллектом в мире, выполняющий почти 5 экзафлопс вычислений. К 2022 году Meta будет работать над увеличением количества графических процессоров с 6080 до 16 000, что повысит эффективность обучения ИИ более чем в 2,5 раза. Коммутационная сеть InfiniBand будет расширяться для поддержки 16 000 портов в двухуровневой топологии без превышения лимита подписки. Система хранения будет иметь целевую пропускную способность 16 ТБ/с и эксабайтную емкость для удовлетворения растущего спроса.
Ожидается, что такое ступенчатое изменение вычислительных возможностей позволит не только создавать более точные модели ИИ для существующих сервисов, но и обеспечит совершенно новый пользовательский опыт, особенно в метавселенной. Долгосрочные инвестиции в самоконтролируемое обучение и создание инфраструктуры искусственного интеллекта следующего поколения с помощью RSC помогут Meta создавать основополагающие технологии, которые будут питать метавселенную и продвигать более широкое сообщество искусственного интеллекта.
На данный момент суперкомпьютер Meta используется лишь в исследовательских целях, и вряд ли на его основе появятся продукты в ближайшие годы. Его цель состоит в том, чтобы собирать массивы данных для создания моделей ИИ, которые могут думать как человеческий мозг, с несколькими входными данными, такими как голосовое и визуальное распознавание, и могут обеспечивать контекстуальное понимание ситуаций.


Комментарии (27)

ABy
30.01.2022 14:35+2в новом суперкомпьютере с искусственным интеллектом установлено 6080 графических процессоров Nvidia
Уже, наверное, половину стоимости отмайнили :)

aegoroff
30.01.2022 19:27+2Его цель состоит в том, чтобы собирать массивы данных для создания моделей ИИ, которые могут думать как человеческий мозг, с несколькими входными данными, такими как голосовое и визуальное распознавание, и могут обеспечивать контекстуальное понимание ситуаций.
Видимо хотять сделать таргетирование рекламы еще лучше - ты только подумал а тебе уже на, порцию рекламы

Xuxicheta
30.01.2022 20:21+2Первое что приходит на ум при упоминании фейсбука и суперкомпьютеров. Дескать следить за пользователем и шпионить будут еще более лучше.
"обучения моделей ИИ обработке естественного языка и компьютерному зрению" - т.е. читать как - "на этот раз вацап начнет прислушиваться к намекам и иносказаниям, а по фоткам котиков определять психологический портрет".
aegoroff
30.01.2022 20:55т.е. читать как - "на этот раз вацап начнет прислушиваться к намекам и иносказаниям, а по фоткам котиков определять психологический портрет".
И это тоже :) но портрет то нужен не просто так ...

Rutel_Nsk
30.01.2022 21:27А чем суперкомпьютер отличается от сети из мощных рабочих станций, ну разве что сетевой интерфейс чуть более быстрый?

tbl
31.01.2022 12:43у inifiniband в отличие от ethernet:
у устройств отдельные каналы до свитча, а не общий "эфир"
cpu не участвует в передаче данных между nic и gpu
другие протоколы передачи данных (не tcp и udp)
infiniband обеспечивает отсутствие потери пакетов (т.к. транспортный уровень по модели OSI реализован на уровне железа)
низкая латентность
возможно не точно, но слышал, что на свитчах конфигурация сети прибивается гвоздями, есть что-то типа autodiscovery, но обычно его не используют, т.к. при утилизации емкости каналов близкой к максимальной начинаются неприятные спецэффекты, что приводит к неполной утилизации конечных устройств
Ну а про про суперкомпьютер от meta: пока в top500 не засветился, говорить о нем еще рано, может, пока полгода-год до рабочего состояния дотюнивать будут, кто-то успеет их обойти. В общем, это не та сфера, где надо говорить "Гоп!", пока не перепрыгнешь.
Rutel_Nsk
31.01.2022 15:46Особенности InfiniBand понимаю.
Мой вопрос вызван тем, что ранние суперкомпьютеры отличались от обычных машин применением «продвинутых» архитектурных решений.
В настоящее время все старые наработки реализованы в обычных процессорах настольных ПК, а новых не появилось. Последние фундаментальные работы относятся к семидесятым годам, потом только их внедрение в серийные изделия.
Вот и получается, что современный суперкомпьютер не сильно отличается от «сети персоналок» как аппаратно, так и программно.
ToSHiC
31.01.2022 17:11Ну если быть более точным, то эти современные суперкомьютеры для ИИ - это кластеры из GPU. На уровне вычислительного сервера всё построено таким образом, чтобы как можно быстрее передавать куски данных из памяти видеокарты в память видеокарты другого сервера, используется DMA копирование из памяти видеокарты сразу в infiniband сетевушку. Некоторые операции reduce можно сделать прямо на свитчах, но там много ограничений - технология называется SHARP.
Rutel_Nsk
31.01.2022 18:30Если интересно, то вот мой проект более быстрой сети:
habr.com/ru/post/577810
habr.com/ru/post/512652
Сейчас занят создание Verilog проектом простого коммутатора, после завершения напишу статью с описанием проекта (комментарии верилог текста).
Потом займусь таким же проектом для суперкомпьютера (показ принципов функционирования суперкомпьютера следующего поколения).
В современных реалиях, данные разработки можно применить в проекте распределенной памяти — своеобразный коммутатор совмещенный с большим объемом динамической памяти. К таким коммутаторам можно подключать компьютеры или такие же коммутаторы (что бы создать иерархию DSM).
Одно печалит, мелкие компании не хотят заниматься подобными проектами (рискованно), а до крупных невозможно «достучаться». Задержка доступа определяется физическими размерами кабельной инфраструктуры.

Sychuan
01.02.2022 22:00Ну а про про суперкомпьютер от meta: пока в top500 не засветился
Ну то что он засаетится в top500 это очевидно, если фейсбук захочет тратить время и ресурсы на этот процесс (участие в топе все-таки по желанию). Будет ли он там на первых позициях или нет это другой вопрос
tbl
02.02.2022 11:38Прогон LINPACK (использующийся в top500) - это хороший способ проверить, что с суперкомпьютером все хорошо. Если он показывает плохие результаты, то наверняка где-то проблемы. Поставщики оборудования (та же nvidia) среди прочих тестов крайне рекомендуют его прогонять и фиксить проблемы, пока не получатся ожидаемые цифры производительности.
z0ic
30.01.2022 22:37-5И опять мужики у них обнимаются, неужели для пропаганды "вот этого вот всего" нужно строить суперкомпьютер.

ZDn5nRF8BPse4b
30.01.2022 23:03+9Сходите на улицу, подышите воздухом. Возможно, найдёте очень много 'пропаганды «вот этого вот всего»' вокруг. Или поймёте, что это не пропаганда.

SovGVD
31.01.2022 04:43А я вижу двух строителей и/или инженеров.

dealershowers
31.01.2022 12:30Синие каски на стройке крановщики в основном носят, видать мету с колен крановщики поднимают =)


Yser
31.01.2022 00:05+3Все это очень интересно, но читать весь этот поток техномаркетинга слишком тяжело. Пример:
В отличие от предыдущей исследовательской инфраструктуры ИИ, которая использовала только открытый исходный код и другие общедоступные наборы данных, RSC помогает обеспечить эффективное воплощение исследований в жизнь, позволяя включать реальные примеры из производственных систем Meta в обучение моделей. Это первый раз, когда производительность, надежность, безопасность и конфиденциальность решаются в таком масштабе.
При беглом чтении сразу воникает ощущение чтотебе заливают гно в ушичто-то не так, но только перечитав пару раз, становится ясно что они используют данные своих пользователей для обучения моделей. Интересно дали ли юзеры согласие на это все.SovGVD
31.01.2022 04:45Более чем уверен что где то в термс энд кондишн это прописано, но кто же их читает =) Вспоминается серия Сауз Парка про Эппл.


erydit
31.01.2022 11:54+3Да что такое эта ваша "метавселенная"?! Придумали абстракцию на основе набора хайповых терминов "виртуальная реальность! и с блокчейном! вот ИИ еще там будет! все за NFT!" и пихают в каждое заявление для прессы.

SerjAir
31.01.2022 13:12Meta (Facebook) пытаются отыграть негативный фон, который на них пал в октябре 2021 года, когда бывшая сотрудница Facebook Фрэнсис Хауген предоставила СМИ материалы внутренних расследований и документы компании о вреде, который наносят ее алгоритмы приложений и сервисов.

SerjAir
Facebook переименовался в Meta на фоне скандалов и весьма отвратной репутации, не сделав ровным счётом ничего, чтобы исправить свои ошибки, а теперь активно пиарит то, что вносит в вклад в развитие технологий ИИ.
Они не могут обеспечить нормальную поддержку и функционирование своих текущих продуктов, и я уверен, что такая же будет у них мета вселенная.
fishHook
А что вы имеете в виду под ошибками? Погуглил — акции стабильно растут, капитализация увеливается, индексы там всякие — всё вроде в порядке, бизнес чувствует себя как никогда хорошо. Какие ошибки то?
SerjAir
Акции стабильно растут. Особенно за последние 6 месяцев выросли, аж на -15% почти.
Про ошибки, неудобства, уязвимости, излишнюю завуалированность, тормознутость, просто попробуйте поработать с Facebook Business Manager, я думаю вы меня сразу поймёте.
Или например Instagram, вы скорее всего пока не сталкивались пока с заказными блокировками, а ведь там до сих пор есть возможность заблокировать любой профиль без галочки верификации всего лишь за $50.
А последующая разблокировка аккаунта это целый квест, так как службы поддержки у Instagram нет, ни почты, ни телефона, ничего, есть только полурабочие формы разработанные лет 15-20 назад.
Это всего лишь первое, что приходит на ум. Это личный пользовательский опыт.
Новостной фон в отношении Meta (Facebook), крайне негативный.
Meta Platforms упала на 36 позиций в списке лучших работодателей
Акции Meta падают на фоне расследования The Wall Street Journal
Meta вслед за Google получила оборотный штраф почти на ₽2 млрд
Акционеры Meta требуют перемен в системе управления компанией
«Facebook изменится, если уйдет Цукерберг». Активист требует отставки СЕО
Snap, Facebook и Twitter теряют почти $10 млрд из-за новой политики Apple
Власти США начали подробно изучать внутреннее исследование Facebook
Facebook теряет популярность среди молодежи
Сервисы Facebook используются для разжигания религиозной розни в Индии
Бывшая сотрудница Facebook раскрыла СМИ данные о вреде алгоритмов соцсети
Sychuan
Большинство из этих вещей это либо естественные процессы (фейсбук теряет популярность у молодежи) либо искусственная истерика СМИ, которая одинаково может относится к чему угодно, хоть у твитеру, хоть к тиктоку, хоть телеграмму. Модная истерия "фейсбук корпорация зла" , ничем не отличается от "проклятый Билл Гейтс" десятилетие назад и каких-либо вменяемых оснований под ней нет.