
Росстат ежегодно публикует порядка 4 тысяч показателей государственной статистики. Они доступны всем без каких-либо ограничений по статусу, правам доступа и т.п. Но публикуя данные, Росстат прежде всего ориентируется на то, что пользователи будут работать с ними вручную (глазами и руками), хотя последние 20 лет, мягко говоря, это не совсем тренд.
Меня зовут Веденьков Максим, я работаю в ЦПУР (Центр перспективных управленческих решений), некоммерческой организации, которая проводит исследования на государственных данных с целью повышения информированности общества о происходящих в стране процессах. Также мы собираем, обогащаем и публикуем датасеты с государственными данными, как ранее опубликованными, так и теми, которые раньше не публиковались.
В этой статье хочу рассказать об одном из таких наборов данных. Большом, сложном, важном, но при этом доступном в крайне неудобном для исследователей формате — базе данных показателей муниципальных образований (БД ПМО).
Программисты часто хотят найти изящное решение, которое может быть сложным, трудозатратным, но универсальным. Однако с государственными данными такое не проходит. Красной нитью через всю статью пройдет не столько то, какие мы молодцы (хотя мы, конечно, молодцы), сколько то, что иногда нужно просто заморочиться, и даже пойти на некое соглашение с самим собой (когда ты вынужден делать не особо квалифицированную работу), чтобы достичь цели.
Но прежде чем начать говорить о БД ПМО, стоит рассказать, зачем вообще нужно дополнительно обрабатывать открытые данные.
Дело в том, что исследователи — не программисты, у них другой стек навыков и инструментов. Исследователи хотят получать исходные данные в удобном виде, чтобы не нужно было совершать никаких дополнительных действий и можно было сразу приступить к анализу и исследованиям.
Вот пример исследования от моих коллег — «От избрания к назначению. Оценка эффекта смены модели управления муниципалитетами в России». Контекст был такой: по всей России отменяют или уже отменили выборы мэров, но никто не мог сказать, к чему это приводит на практике. Это не могли оценить, потому что для такой оценки нужны данные о том, что было до и что было после отмены, в разрезе по муниципалитетам. И за долгий период, чтобы можно было проследить историю.
Вот какие показатели, в частности, использовались при оценке:
Численность населения
Средняя зарплата
Расходы и доходы местных бюджетов
Возрастная структура населения
Пример таблицы с данными о доходах местного бюджета:

Вывод исследования: Отмена выборов повлияла негативно, муниципалитеты стали беднее. В тексте исследования аргументация. А выводы и аргументация — это основа для принятия решений.
В примере выше данные фактически находятся в форме т.н. панельных данных (Panel data). Что это значит?
Измерения охватывают достаточный период времени
Различные объекты можно сравнивать между собой
Все нужные переменные собраны в одну таблицу
При этом данные, которые выкладывают госорганы, далеки от такого формата, и БД ПМО в этом смысле — анти-чемпион.
Что такое БД ПМО
БД ПМО — это база данных показателей муниципальных образований, которую ведёт Росстат. Муниципальные образования — это элементы административного деления страны. А вот примеры показателей, которые в них отслеживаются:
Общая площадь расселенного аварийного жилищного фонда
Расходы местного бюджета, фактически исполненные
Число лечебно-профилактических организаций
Посевные площади сельскохозяйственных культур
Оценка численности населения на 1 января текущего года
БД ПМО — одно из крупнейших хранилищ информации о социально-экономическом состоянии страны. Такая информация полезна социологам, экономистам, политологам, журналистам и другим исследователям. А их исследования, в свою очередь, полезны для общества и государства. Кстати, показатели, использованные для оценки эффекта смены модели управления муниципалитетами, тоже можно найти в БД ПМО.
В чём заключалась задача
Собрать 85 региональных баз данных в одну. Потому что никакой «базы» БД ПМО как единого объекта данных не существует. В каждом регионе своя БД, почти не связанная с другими. Структурно они должны быть идентичны, но на практике это не так, ведь их заполняют вручную сотни людей.
А теперь представьте нашу задачу на абстрактном уровне. У вас есть базы данных из 85 регионов, все они об одном и том же, но имеют микроразличия. И вам нужно объединить все базы так, чтобы устранить эти микроразличия, и сделать это корректно. Отталкиваемся от этой точки и идем далее.
Как устроена БД ПМО
Мы решили не парсить данные, а обратиться к первоисточнику. Росстат пошёл нам навстречу и передал дампы баз данных, значения из которых сейчас позволяет выгрузить конструктор на сайте Росстата, но отдельными таблицами.
То есть на входе мы получили дампы баз данных по всем субъектам в формате .bak (MS SQL Server) и один Word-файл с документацией. В развернутом состоянии они занимали ~200ГБ и содержали порядка 200 млн строк наблюдений. В среднем 780 таблиц в каждой БД.
Всего мы получили 82 базы — меньше, чем субъектов (85), потому что четыре автономных округа (Ненецкий, Ханты-Мансийский, Чукотский, Ямало-Ненецкий) включены в БД своих «родительских» субъектов, два из которых находятся в Тюменской области. Т.е. данные по Ямало-Ненецкому и Ханты-Мансийскому АО хранятся в базе по Тюменской области.
Вот так выглядит одна база:
В каждой базе лежат таблицы двух типов: таблицы с данными и справочники. Одна таблица данных — это один показатель. Вот, например, данные по показателю «Число проживающих в аварийных жилых домах» (код 8008022):

Первые шесть атрибутов есть всегда, из них мы узнаем год, период записи и коды муниципального образования. Поле zn8008022 — это поле для значения показателя, записанное по маске zn[код показателя]. Но эта структура непостоянна, показатель может иметь от одного до трёх дополнительных атрибутов, которые мы называем группами категорий. Вот пример:

В этой таблице не семь, а восемь атрибутов. Один дополнительный — это поле «stdohod», в которое записываются значения из группы категорий «Статьи доходов местного бюджета». А значение этого кода хранится в отдельной таблице-справочнике данной группы категорий. Вот он:
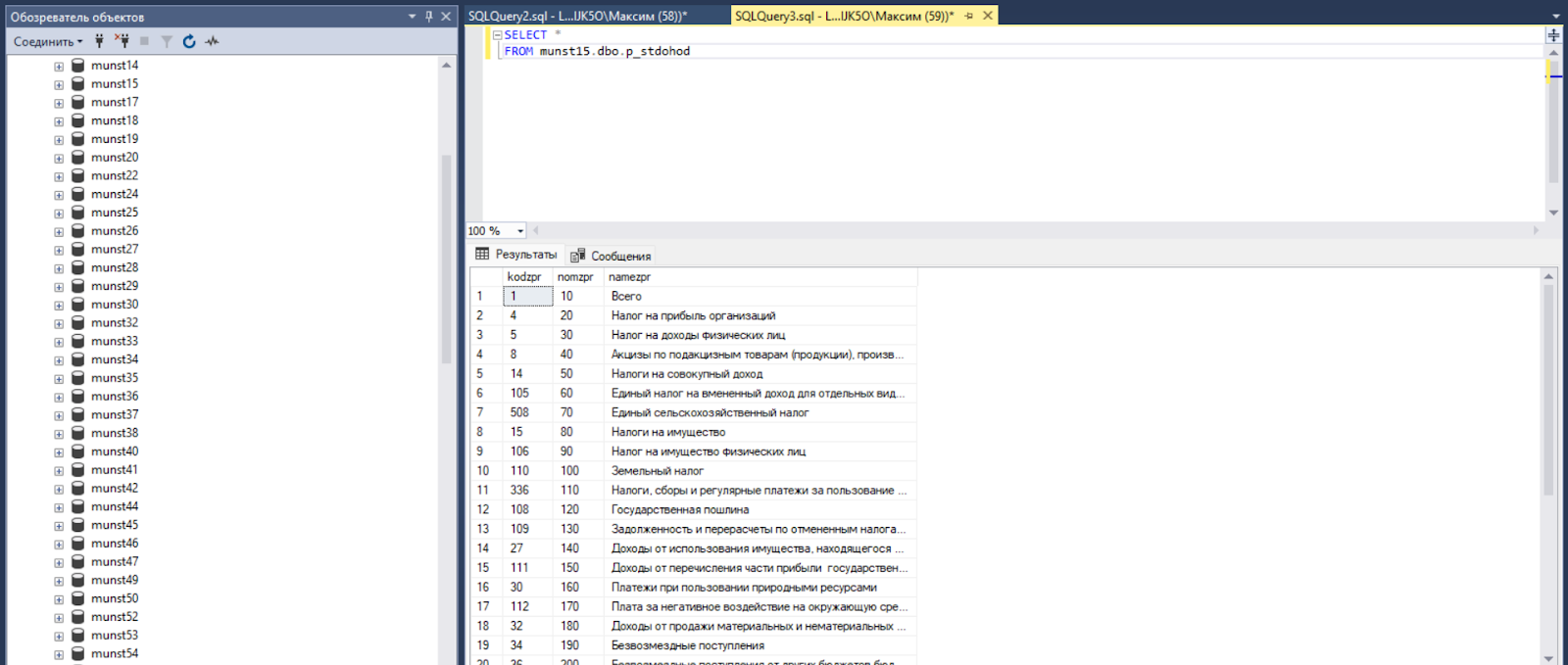
Если объединить таблицу данных со справочниками её атрибутов, то мы получаем полноценную panel data, т.е. заменяем коды категорий на сами эти категории.
В каждом регионе «своя версия» справочника. Т.е. один условный показатель — это 82 таблицы плюс 82 справочника для каждого атрибута в ней.

Про документацию
Вместе с базой мы получили внутреннюю документацию. В документации было ноль картинок, ER-диаграмм или каких-то других графических схем, зато было 26 страниц отборного казённого текста. Например, можете ли вы сразу понять, что содержат вот эти типы справочников: «Справочники вхождений значений признаков» и «Справочники разрезности значений признаков». Из названия смутно понятно, что есть некие признаки и разрезы. А если посмотреть в документацию, скажем, второго справочника, то там мы найдем такое: «Имя таблицы формируется путём присоединения приставки "p_" и окончания "_raz" к содержимому поля namesprav справочника признаков». Т.е. нет объяснения, что это, есть строго техническая информация.
И здесь первый вывод. Если вы сталкиваетесь с казённым языком в документации, то переписывайте её под себя, вводите новую терминологию, стандартизируйте названия, упрощайте формулировки, классифицируйте объекты данных, визуализируйте. Работайте с тем, что понятно вам, а не тем, кто написал это для вас.
Мы не стали делать этого сразу (это же долго), и это было огромной ошибкой. Любой контакт (совещание, статус, мозговой штурм) вне нашей маленькой команды наталкивался на стену непонимания от коллег, пока мы не ввели новую терминологию.
Каждая вложенная минута на переписывание документации окупится десятикратно, когда вам раз за разом не придётся отвечать на вопросы «Что это? В чем разница? Как они связаны друг с другом?». Она будет окупаться каждый раз, когда ваш мозг не будет тратить пару секунд, чтобы вспомнить, чем принципиально отличается «Справочник значений признаков» от «Справочника числовых значений признаков» и в каком из них лежит то, что вам нужно.
Сложность в том, что нет точки опоры, ни в чём
Допустим, вы получили такую задачу, какое первое нативное решение? Справочники приводим к эталону, данные очищаем от аномалий. Всё логично. Но этот путь не работает с БД ПМО.
Вспомним, что данные в БД ПМО — это статистические показатели. Вот, кажется, показатель, простая штука, например, «Число муниципальных спортивных сооружений». Но он может иметь от 4 до 7 групп категорий (атрибутов в таблице). Применяться в 10 или 85 регионах. Его могут заполнять раз в квартал, в год или в 10 лет. На 30 декабря текущего года или на 30 января года следующего за отчётным. Он может иметь одну из 27 единиц измерения. Натуральные показатели могут измеряться в шт и кг, денежные — в суммах от тысяч рублей до миллиардов. И конечно, все эти цифры разные: разные по годам, разные по регионам, разные для муниципальных образований в одном регионе. А ещё меняются границы регионов, меняется ОКТМО мун. образований, меняются названия.
Код ОКТМО — это восьмизначный код вида 14701000, который кодирует мун. образование. В данном примере 14 — это Белгородская область, 701 — город Белгород, 000 — ничего не значат. Если бы Белгород имел внутри себя другие муниципальные образования, то вместо 000 были цифры. Сам термин «ОКТМО» расшифровывается как «Общероссийский классификатор территорий муниципальных образований».
Базы разные между собой, потому что разные регионы. Взять какой-то из них за эталон невозможно. В Краснодарском крае выращивают в 60 тыс раз больше пшеницы, чем в Якутии. И Якутия из-за этого не становится аномалией. Другими словами, у вас нет диапазона валидных значений для показателей. А ещё показатель для одного региона может не применяться в другом. А ещё есть человеческий фактор: у каждого показателя есть ответственный по заполнению, и когда его нет на месте или его Windows 98 попросил обновления, нет и данных.
Показатели вводились не единовременно, а с годами. И истории этих изменений нет. Какие-то старые выводились, какие-то заменялись. Такие классификаторы как ОКВЭД и ОКОГУ (Классификатор видов экономической деятельности и органов государственной власти и управления) являются федеральными, а не росстатовскими. Следовательно, когда они изменялись, Росстат был вынужден проводить перекодировки параллельно во всех 82 базах. И конечно, это не обходилось без человеческих ошибок, которые, например проявляются в том, что используются одновременно два разных кода.
Другой пример. Показатели и категории также не являются статичными. С некой регулярностью они обновляются. Например, потому что вышел закон с обновлением кодов для федерального классификатора (ОКОГУ). И это делают тоже по-разному. В каком-то регионе просто меняют название категории под определённым годом, где-то вводят новый, дописывая что-то типа «с 2014 года» в новом и «до 2014 года» в старом. В результате мы получаем дубль (два разных наименования категории на один код).
Также, непросто формализовать и в цифрах посчитать такие метрики качества данных как полнота, непрерывность и целостность, чтобы опираться на них в дальнейшей работе. Вот, например, в таком-то регионе в таком-то сельском поселении данные были заполнены не по каждому селу, а по всему сельсовету. Формально они как бы есть, но уже агрегированные.
Эта особенность с агрегацией данных в БД ПМО является следствием её концепции, т.к. одно наблюдение — это значение показателя для одного ОКТМО. Проблема в том, что код ОКТМО — это сама по себе структурная единица, поэтому данные, заполненные для него, не являются атомарными (неделимыми). Поэтому, например, если вы посчитаете сумму по всем мун. образованиям Омской области, вы получите 43 млн человек населения:

Так происходит из-за того, что мунобразования, как матрёшка, вложены один в другой. А вложены они, потому что база не находится в третьей нормальной форме, т.к. поле ОКТМО содержит структурную информацию. А ОКТМО содержит структурную информацию, потому что оно является федеральным справочником и именно в привязке к ОКТМО сам Росстат получает данные. Вот такая матрёшка.
На практике эти проблемы проявляются в том, что у вас нет и не может быть единых паттернов поиска аномалий, не говоря уже об их устранении. А любая найденная аномалия с равной вероятностью может оказаться артефактом, или даже быть нормой для данного региона. И нет чётких критериев (кроме натуральных показателей, если, например, протяжённость трубопровода стала на 1 млн км длиннее за год) как определения аномалий, так и отличия аномалий от артефактов. План «находим аномалии, понимаем природу, находим универсальное решение» не работает на таком масштабе и вариативности, это слишком трудозатратно. Такое может занять месяцы работы команды людей.
В итоге мы пришли к следующему выводу: собираем базу, нормализуем справочники, но поиск и устранение аномалий оставляем исследователям. Это разумно по двум причинам:
Во-первых, исследователи работают с гораздо меньшим количеством показателей по какой-то конкретной теме и погружены в неё гораздо больше, чем мы.
Во-вторых, мы слишком рискуем, если будем чистить данные, убрать по-настоящему ценные артефакты, потому что они попали под паттерн аномалии.
Нормализация справочников
Со справочниками, в отличие от данных, было проще. Вот у вас есть 82 базы данных, и значит — 82 справочника. Например, kultur, «Сельскохозяйственные культуры». Напомню, справочник связан с данными вот так:

Эта таблица показателя «Посевные площади сельскохозяйственных культур» в Алтайском крае, в дополнительный атрибут (kultur) которого записан код 1010500. В справочнике этого атрибута код 1010500 кодирует категорию «Пшеница, яровая». Если в каждой базе под кодом 1010500 записана одна сущность, значит, проблем нет.
Это идеальный вариант. Но в реальности мы имеем несколько вариантов написания одной и той же сущности. Вот простейший пример, одна сущность, но разное написание:

В этом и есть проблема справочников. Они не нормализованы между базами, а эталона, к которому можно было бы их привести, тоже нет. Как их нормализовать и привести к эталону? Здесь работает нативное решение: создаём эталон из всех справочников по принципу «какая категория чаще применяется с кодом, та и есть эталон».
Здесь были свои сложности:
Во-первых, каким способом считать метрику «разности» между категориями и какой трешхолд для этой метрики выбрать. Например, некая условная «категория 1» и «категория 2» отличаются только словами «с 2014 года», но дают разность в 86 (по Левенштейну). А «другая категория 1» и «другая категория 2» дают трешхолд в 80, но явно принципиально отличаются между собой.
Во-вторых, если у вас пропорция 81/1, где в 81-й базе названия категорий совпадают, а в одной принципиально отличаются, то, где эталон, понятно. А если у вас пропорция 42/28? Уже не так очевидно.
В-третьих, вот нашли мы такие проблемы (к слову, их было больше 2000), что с ними делать?
Первую задачу мы решили с помощью старого доброго Левенштейна. Вторую — с помощью здравого смысла. А третью — с помощью Росстата.
Кроме Левенштейна мы ещё пробовали посимвольную TF-IDF матрицу на разных алгоритмах. Технически, нужно было сравнить одно наименование категории с каждым другим из всех справочников и получить трешхолд. На практике трешхолд Левенштейна был наиболее понятным и точным из всех, поэтому оставлен был именно он. А валидацию результата мы проводили собственными глазами.
Природа пропорций вроде 42/28 оказалась во всех случаях одной и той же: сосуществование в справочниках как старых, так и новых кодов. В каких-то субъектах старые коды оставляли, в каких-то удаляли.
А как нам помог Росстат? Он взял на себя задачу по решению «сложных случаев». Мы собрали для них полный отчёт, в каких субъектах, в каких показателях и категориях есть проблемы, и отправили им. А они — региональным отделениям на детальную проверку.
План действий готов
Вот я сейчас описал вам всё это, и, кажется, понятно, в чём проблема. Как будто наш путь выглядел вот так:
На самом деле каждый из этих выводов, как и общий итог, не были очевидными с самого начала. 80% времени в работе с БД ПМО ушло на устранение неопределённостей и поиск путей решения, а не на само исполнение решения (коды, алгоритмы). Наш реальный путь выглядел примерно вот так:

Множество раз мы шли в каком-то направлении, понимали, что это движение не решает нашу задачу и откатывались назад. Мы искренне пытались найти некий универсальный путь, но его не было. В итоге мы пришли к компромиссу.
Вот как сейчас выглядит наш компромиссный пайплайн:
Налаживаем коммуникацию. Переписываем документацию под себя. Упрощаем и сокращаем.
Выбрасываем лишнее. Классифицируем таблицы по принципу «если есть ценность — оставляем, нет — удаляем». Например, справочник «Видов доступа пользователей» или пустая таблица «TestTable» ценности для нас не представляли.
Конкретизируем конечную цель. Цель — панельные данные с заданным уровнем качества за ограниченный период времени.
Конкретизируем критерии качества. Ставим на первое место полноту и достоверность.
Вводим критерий трудозатрат. Мы понимаем, что можем больше, но это нерационально. Делаем то, что рационально.
Выделяем проблемные области. Конкретные показатели или категории, которые вызывают сомнения в достоверности.
Находим пути решения проблем. О них ниже.
Решаем задачу.
Что конкретно мы понимаем под проблемной областью данных? Проблемная область — это X строк какого-то показателя, в котором мы сомневаемся, или X строк нескольких показателей, где применяется категория, в которой мы сомневаемся. Например, если в Алтайском крае под кодом 100 записана не категория «ячмень», как должно быть, а «отдано голосов за прежнего мэра», то проблемная область, это: показатель «Выборы мэра и ячменя», регион Алтайский край, все строки с кодом категории 100.
Выбрасываем лишнее — что именно? Служебные таблицы (список пользователей базы). Таблицы, информация из которых напрямую не связана с данными, например, вложенная группировка внутри группы категорий (есть и такое). Таблицы с некорректным названием, например, название показателя «fd_8001002_1» вместо «fd_8001002» (это копии таблицы данных на какой-то момент времени). Таблицы типа «TestTable». Старые версии справочников и т.д. Можно сказать, что мы вводим формальные критерии оценки ценности данных, критерии, оценка которых стоит «дешево» по времени.
Часть таблиц данных, возможно, и представляла интерес, но восстановление информации из них были признано нерациональным. Как по причине малого объема данных (< 1% от всех строк), так и потому, что часть неопределённостей ни мы, ни Росстат не смогли бы устранить.
Какие пути решения мы использовали? «Я принимаю реальность, а не сопротивляюсь ей». Или, другими словами, работали руки и глаза. Печень тоже.
По каждому показателю был собран детальный отчёт о полноте, периоде наблюдения и т.п. Исследователи из нашей команды и сотрудники Росстата проверяли показатели. Напомню, особенность показателей БД ПМО – в вариативности и достаточно длительном периоде наблюдения. Показатели «в моменте» почти бесполезны, они имеют ценность только при сравнении между регионами или внутри региона на длинном временном ряду (тренды). Поэтому те показатели из базы, что имели очень короткий срок наблюдения, прерывистость, малую полноту по регионам, исключались из массива данных. Из 608 показателей в итоговых данных осталось 355.
Из более чем 2 тыс проблемных случаев в справочниках все, кроме 187, нормализованы путем расчёта «похожести» по Левенштейну. Эти 187 «сложных» случаев отправлены в Росстат для проверки «на местах».
На момент написания этой статьи мы находимся в режиме ожидания этих изменений. В панельных данных, которые мы отдаем исследователям, данные с категориями «под сомнением» заменены на Nan.
В итоге получаем 79Гб панельных данных и новую БД
База — для нас, панельки — для исследователей, выводы — для всех. Панельки выглядят вот так:

Показатели сгруппированы по рубрикам (в примере выше рубрика «Спорт» ). Коды категорий заменены их значениями. В каждую таблицу добавлены единицы измерения и точная локация. Получилось удобно, не нужно что-то объединять. С этим могут работать даже те, кто хочет «просто в excel посмотреть» распределение (а такие есть и немало). Цифры: 25 рубрик, 355 показателей, 211 млн строк, 79Гб общий размер всех csv.
До выгрузки в панельный формат данные хранятся в нашей базе в PostgreSQL. Относительно оригинальной она почищена и пересобрана. Мы упростили структуру до трёх типов сущностей:
Рубрики — это таблицы данных, содержащие несколько показателей, объединённых одной темой (например, спорт, население, здравоохранение и т.д.).
Справочники групп категорий, которые содержат два поля — id категории и название категории. Через id категории мы можем смержить справочник с конкретным атрибутом в таблице.
Мета-справочники — это справочники, связанные со всеми рубриками. В них входит: справочник показателей, их единиц измерения, кодировка рубрик, ОКТМО.
ER-диаграмма рубрики «Спорт»:

Каждый атрибут в рубрике связан со своим справочником (кроме поля со значением показателя и года). Это почти 3NF (код ОКТМО все ещё содержит структурную информацию), это легко в восприятии, это легко при выгрузке в панельные данные.
А что насчет выводов после этой работы?
Выводы есть. Вот процессы нашего пайплайна:
Коммуникация в команде. Про это весь Scrum.
Выбрасываем лишнее. Это история про MVP и минимальную достаточность.
Конкретные цели и критерии. Это вообще про здравый смысл.
Выделяем проблемные области, ищем решение, решаем. Это про MVP, здравый смысл и итеративный подход.
Ничего нового. Несмотря на нестандартность задачи, все так любимые в IT методологии работают и здесь. Скажем, я знаю их, я применяю их, этого достаточно? Не совсем, давай добавим смысл «я адаптирую их».
Как я писал выше, 80% времени в работе с БД ПМО ушло на устранение неопределённостей и поиск путей решения. Наверное, каждый из нас способен принять лучшее решение, если он обладает двумя вещами: знаниями и полнотой информации. А если полноты информации нет? И устранение неопределённостей не приближает тебя к цели? Наверное, стоит устранять неопределённость более системно?
В такой момент я вспоминаю цикл НОРД, состоящий из четырёх повторяющихся процессов: наблюдение, ориентация, решение, действие. Эту ментальную стратегию разработал стратег и полковник ВВС США Джон Бойд. Раз он полковник, значит, он придумал её не для покупки молока, а, скажем, чего-то типа победы в войне.
В этой стратегии есть два способа достижения целей: быстрее проходить петлю НОРД или повышать качество принимаемых решений за счёт удлинения процессов наблюдения и ориентации. И сейчас я бы сказал, что первый способ более выигрышный.
Мы очень долго «разбирались» в БД ПМО. Мы понимали больше, но это не приближало нас к законченному продукту. Прогресс пошёл тогда, когда мы стали отрезать лишнее, отрезать непонятное и делать какой-то ограниченный продукт на известных и понятных данных — там, где нам хватало знаний и понимания вопроса, чтобы создать понятную применимую ценность.
Да это же Agile, скажете вы? Да, точно. Адаптированный к задаче. Где адаптация заключается в том, что каждый трек начинается с устранения неопределённости в какой-то локальной области задачи (когда нет ТЗ, когда план на трек невозможно написать, не устранив эту неопределённость), постановки цели, и, наконец, решения.
Комментарии (10)

dmitryvolochaev
16.02.2022 00:12+3In normal world you set up a database.
In Soviet Russia the database upsets you.



StrangeBelk
17.02.2022 10:58+1Пхахаххаа ))) Счастливчики, в РФ есть БД у Статистики. В Казахстане, чтоб собрать даже самый мало-мальский простенький показатель (то же население, с разбивкой по месяцам и по административным единицам), необходимо выкачать штук ЦЦать файлов, причем какието будут XLS, какие-то DOC, третьи вообще какого-то другого формата. И потом все это сводить в одну какую-то портянку.
Какие нормальные БД и сервисы? вы о чем? ))))
vmakid Автор
17.02.2022 14:31+1В этом смысле Росстат и правда молодец. Но в других наших проектах, например, в попытках проанализировать regulation.gov.ru, все те же проблемы с docx, расшифровкой pdf и тп.
vmakid Автор
17.02.2022 14:35Может вам поможет. Вот коллеги делали рекурсивный алгоритм, который делает из отчётоподобных документов таблички в pandas и тексты https://github.com/CAG-ru/report_parser

Barsik68
17.02.2022 11:02А где можно скачать или как воспользоваться очищенной БД ?
Или вы все это делали исключительно для своих нужд?

Ivan22
Welcome to the real world