

Привет, Хабр! На связи — Григорий Грязнов, руководитель подразделения «Аналитические сервисы» Единой информационной системы жилищного строительства (ЕИСЖС) ДОМ.РФ
По горячим следам недавно запущенного пилота машинного обучения (ML) в ДОМ.РФ решил поделиться с вами этапами его разработки и внедрения. Цель проекта – научиться анализировать темпы строительства многоквартирных домов и выявлять вероятные срывы сроков ввода их в эксплуатацию. В статье я постараюсь описать технологии, процесс построения алгоритмов и автоматизации сформированного решения простым языком, чтобы человек без специальных навыков в ML смог во всем разобраться.
Проблема и постановка задачи
В начале исследования всегда следует максимально конкретно определить, чего мы хотим достичь. У нас была следующие вводные.
Сейчас в России строится более 9 тыс. многоквартирных домов, информация о которых загружаются в ЕИСЖС и обновляются ежемесячно. Из всего этого массива данных нам нужно было отследить те, которые бы говорили о трудностях у застройщика, грозящих задержкой ввода объекта в эксплуатацию. «Недострой» всегда негативно сказывается на развитии регионов, не говоря уже о положении семей, которые просто не получают свои квартиры, и чем раньше заметить проблему, тем лучше.
Сложность заключалась в том, что вручную мониторить все поступающие в ЕИСЖС сведения было крайне затруднительно. Даже приоритизация объектов в модуле мониторинга позволяла бы существенно сократить эту работу, не говоря уже об автоматизации процесса. Поэтому нам нужен был такой инструмент, который позволил бы следить за строительством объектов и предупреждать срывы на горизонте года и более.
Спецификация моделей
В машинном обучении существует два подхода построения моделей: «Обучение с учителем» и «Обучение без учителя». Мы выбрали первый метод, чтобы классифицировать каждый объект по степени проблемности. Нам потребовалось собрать размеченные данные, на которых модель будет учиться, выявляя зависимости, которые влияют на определенный класс. По заданной шкале 0 означал не проблемный объект, а 1 – проблемный.
Отдельным аспектом исследования стали фотографии хода строительства объектов, загружаемые в ЕИСЖС. Для анализа изображений в открытом доступе размещены архитектуры нейронных сетей, которые уже предобучены на открытых датасетах картинок (например, COCO и ImageNet). Основная цель — отобразить изменения на фотографиях и определить новые объекты, например этажи, окна, стены и т.д. Мы взяли модели, которые готовы к выявлению и фиксации изменений на наших данных (Image Detection).
Извлечение и формирование признаков
При выборе определенных признаков для датасета, на котором будет обучаться модель, важно определить специфику области применения. В нашем случае мы рассматриваем строительство домов, которое имеет ряд нюансов. Выбор признаков происходит с учетом гипотезы о наличии зависимости с тем или иным классом объектов.
В базе данных ЕИСЖС ДОМ.РФ сосредоточена вся информация о строящихся объектах из проектных деклараций по всем регионам. При выборе признаков проверялась гипотеза о влиянии на класс объекта. Также мы использовали технику Information Value, что позволило понять, насколько тот или иной признак информативен. Суть Information Value заключается в определении веса каждого признака, на основании которого рассчитывается значение показателя. Далее оценивается прогнозная сила каждого параметра исходя из следующей таблицы.
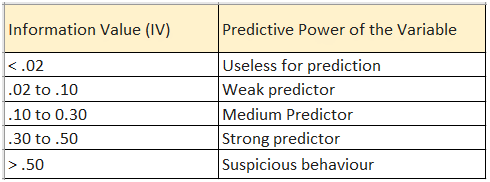
Отобранные признаки и рассчитанные показатели раскрывают тенденцию повышенного спроса на покупку квартир в многоэтажках, вероятную прибыль к окончанию строительства и историю застройщика по реализованным объектам. Далее была проведена проверка на адекватность каждого показателя в целях исключения разного рода выбросов и некорректных значений, чтобы модель выявила верные зависимости между атрибутами и классами.
Предобработка фотографий хода строительства заключалась в преобразовании изображений в виде матрицы 224x224x3 для подачи на вход модели. Для обработки данных использовалась библиотека работы с нейронными сетями TensorFlow. Архитектура сети была выбрана ResNet50, как лучшее решение для определения схожести изображений.
Метрики качества
Выбор метрики, по которой смотрится качество обучения модели, зависит от того, какая задача перед нами стоит: классификация, регрессия или кластеризация. У нас происходит классификация, однако мы также должны учитывать особенности собранных данных, следовательно, выбирать метрику нужно с учетом дисбаланса классов. Для определения качества обучения модели мы опирались на следующие метрики: ROC-AUC, F1-score и Cohen’s Kappa coefficient. Все они основываются на confusion matrix (матрица ошибок – прим. автора), которая сопоставляет спрогнозированные значения с фактическими и дает возможность рассчитать требуемые параметры.

ROC-AUC представляет собой площадь под графиком ROC (Receiver operating characteristic), которая может иметь значения в диапазоне от 0,5 (бесполезная модель) до 1 (идеальная модель). График имеет следующий вид:
F1-score представляет собой среднее гармоническое между precision (точность) и recall (полнота), которые рассчитываются исходя из значений матрицы ошибок. Формула расчета данной метрики выглядит следующим образом:
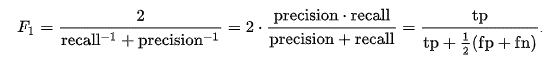
Cohen’s Kappa coefficient оценивает согласие между результатами классификации и фактическими результатами. Данный показатель является довольно сложным в интерпретации, однако учитывает влияние дисбаланса между классами. Формула его расчета имеет следующий вид:
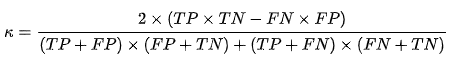
В нашем случае мы получили f1-score равным 0,739. Значение Cohen’s Kappa coefficient 0,663. Полученные значения позволяют говорить об адекватности модели и ее согласованности с ручной обработкой информации.
Oversampling and undersampling
Перед обучением модели при наличии довольно большего дисбаланса классов применяют техники oversampling и undersampling. Oversampling заключается в увеличении выборки, чтобы уменьшить дисбаланс за счет увеличения меньшего класса. Благодаря этому модель может лучше выстроить зависимости между классами и признаками. Undersampling подразумевает сокращение выборки, уменьшение большего класса. Это снижает влияние на модель, выстраиваются более верные зависимости.
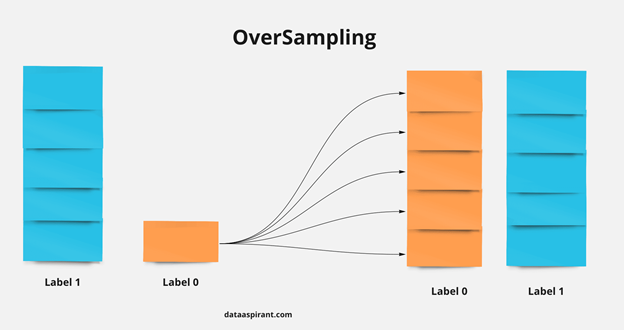
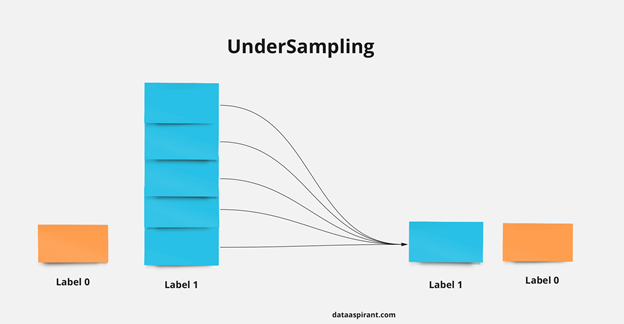
Выбор конкретной техники зависит от решаемой задачи и полностью основывается на значении ключевых метрик. Тот метод, который позволяет получить лучшее значение, и выбирается в качестве целевого.
Мы пришли к тому, что наилучший результат получился при сокращении большего класса, уменьшения количества непроблемных объектов (undersampling) в обучающей выборке.
Выбор и настройка моделей
После подготовки данных и определения метрики качества переходим к выбору моделей машинного обучения для решения поставленных задач. Всего их два. Первый тип, линейный, легок в интерпретации и позволяет довольно быстро получить результат прогнозирования, однако такие модели способны выявлять только простые зависимости, что снижает их результативность. Вторые – нелинейные модели – выявляют более сложные зависимости, но требуют больше вычислительных мощностей. При их запуске возрастает количество ресурсов для проведения эффективных расчетов, а значит, увеличивается и время их работы. Следует отметить, что в обоих типах моделей при выборе гиперпараметров можно столкнуться с проблемой overthinking – переобучения. Важно смотреть на динамику значений метрик и в случае их ухудшения можно констатировать переобучение нашей модели. Так мы поймем, что стоит остановиться на тех гиперпараметрах, перед которыми произошло ухудшение метрик.
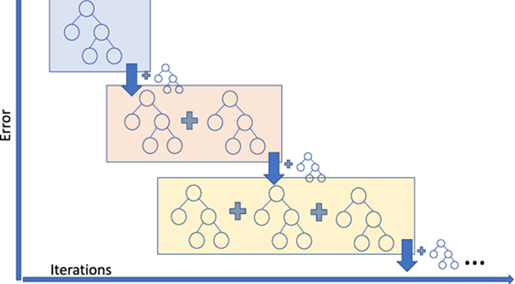
В ходе решения нашей задачи по выявлению наиболее вероятных проблемных объектов лучший результат продемонстрировала модель CatBoost, основанная на технологии Gradient boosting. Этот метод обучения модели представляет собой последовательность простых алгоритмов, таких как decision tree (дерево решений – прим. автора), где каждый последующий учитывает результат предшествующих. Как результат, повышается качество обучения и прогнозирования.
В части анализа фотографий хода строительства мы рассмотрели довольно большое количество различных архитектур нейронных сетей: LeNet, AlexNet, VGG, Inception, ResNet и других. Лучшие результаты показала ResNet50, которая уже предобучена на открытых датасетах изображений. Простыми словами, нейронная сеть находит наиболее схожие фотографии по объектам строительства, сравнивая их между собой, и фиксирует выявленные изменения. Сама архитектура модели выглядит следующим образом:
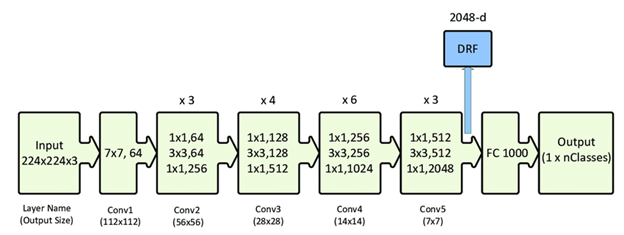
На вход подаются предобработанные изображения в виде матриц размера 224x224x3. Эти данные проходят через 50 свёрточных слоев сети. После получения результата свертки рассчитывается схожесть между всеми полученными изображениями.
Тестирование моделей
После отбора конечных моделей была проведена их проверка на тестовых выборках. Результат получился схожий с результатами при проверке на валидационной выборке. Далее мы приступили к сбору актуальных данных по строящимся домам, чтобы спрогнозировать, какие объекты наиболее вероятно могут стать проблемными в ближайшие полтора года. Полученные результаты мы проанализировали по изображениям соответствующих объектов с помощью нейронных сетей. Спрогнозированные объекты имели довольно малые изменения на различных периодах времени. Как следствие, это указывает на вероятное возникновение проблем с этими домами.
Уже сейчас весь процесс автоматизирован, ежемесячно после изменения проектной декларации формируется новый прогноз на полтора года, проводится анализ изменений по ним. Также проводится историзация результатов для дальнейшей калибровки моделей, чтобы улучшить целевые метрик.
Для бизнеса результат выдается в виде регулярных отчетов с объектами строительства, по которым необходим дополнительный контроль и автоматическая фильтрация таких объектов в модуле мониторинга.