
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
TXT
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
Hello, world!
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
01001000 — H
01100101 — e
01101100 — l
01101100 — l
01101111 — o
Но как операционная система расшифровывает эти данные? Всё просто. Операционной системе требуется загрузить таблицу, в которой описано соответствие бинарного кода конкретному символу. Таких таблиц много, самые известные сегодня — CP1251 (Windows), UTF-8 (Android, Mac) и так далее. Такие таблицы, часто называют кодировками. В данном файле используется кодировка UTF-8, то есть 8-битный Юникод.
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит»
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
çÁ%%?Ï?Ê%À (кодировка EBCDIC).
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
Еще интересный момент. Исторически, компьютеры «знали» только латиницу, которая используется в большинстве европейских языков. И тут произошла проблема: 8-бит — это всего лишь 256 возможных значений. Это немного, но этого было достаточно, чтобы закодировать все базовые символы + латинские буквы.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
…
Привет, мир!
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Кстати, помните все эти случаи, когда iPhone умирал от присланного сообщения со странными символами или картинки? Это как раз связано с тем, что система не могла правильно распознать присланные символы и правильно определить их длину.
Например, вот такое сообщение в своё время заставляло любой айфон уйти в цикличный ребут:
Power
لُلُصّبُلُلصّبُررً ॣ ॣh ॣ ॣ
冗
WAV
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
К примеру, возьмём файл в формате WAV.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Все эти данные позволяют быть уверенным, что аудио будет воспроизведено корректно.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие...
Но бывают и закрытые форматы файлов, а точнее проприетарные. Открытие и редактирование таких файлов сторонним софтом часто либо вообще запрещено, либо распространяется по лицензиям.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.
Формат основан на универсальном языке разметки XML. А сам файл ODF представляет из себя ZIP-архив с папками, XML-файлами и всякими вложениями в виде картинок, видео и прочим. Иными словами, если открыть такой файл через архиватор мы можем спокойно увидеть все внутренности. Вот так пример открытости!
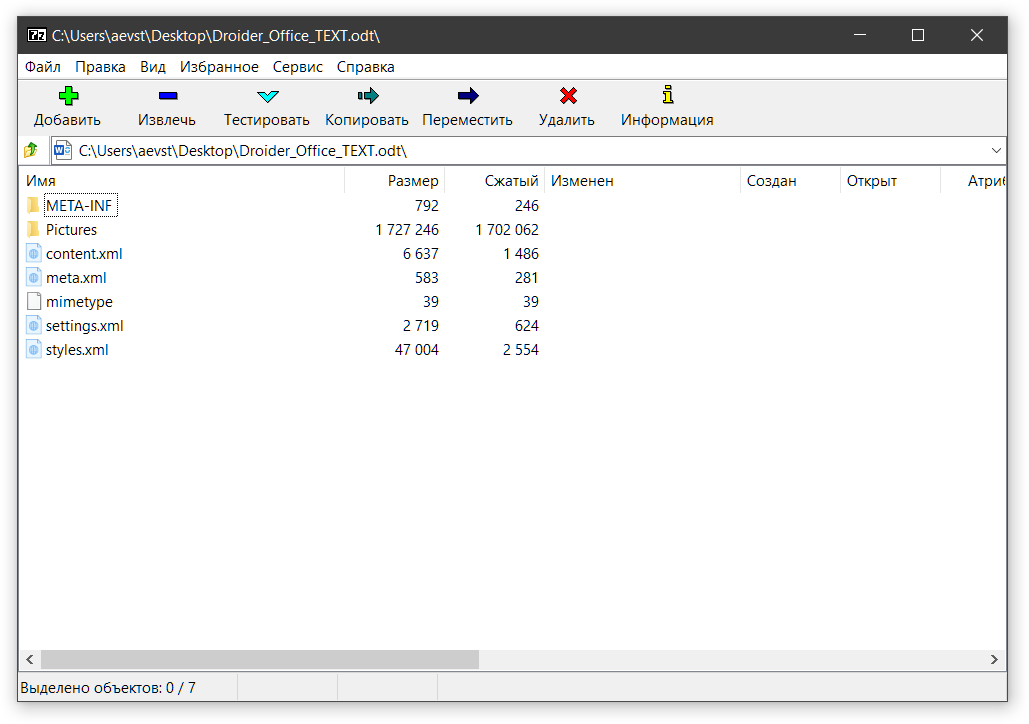
Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Комментарии (20)

nochkin
17.03.2022 17:12+1Если речь зашла про Notepad, то он как раз может хранить некие бинарные данные в формате TXT для определения Unicode.
Например, есть вариант "UTF-8 используя BOM". В начало файло добавляется информация в бинарном виде, которая помогает тому же Notepad определить формат.
Так же там есть вариант UTF-16. Там каждый символ будет уже не 8 бит.
Это всё делает формат TXT уже не таким простым как кажется.

Ilya81
17.03.2022 17:14Насколько я слышал, первоначально применялось 7 бит, 8-й был для контроля чётности. Поскольку тогда с электронными лампами да дискретными транзисторами каждый лишний бит стоил немало, использовали 7, поскольку 6 всяко мало, а 6,5 сделать сложно. Ну а когда ошибки копирования между регистрами и ячейками оперативной памяти стали редкими, 8-й бит тоже под данные приспособили, благо уже с интегральными микросхемами так экономить память надобность исчезла.

hoegni
17.03.2022 19:27+3У Вас написано:
"К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый."
На самом деле, это - некоторая неточность. В действительности, ASCII со всеми латинскими буквами определяет только первые 128 символов, а втоорые использовались для разных алфавитов, включая и кириллицу, поэтому обычный текст с кириллицей занимал столько же места, сколько и с латиницей. Другое дело, что стандартов кодировки кириллицы было несколько: KOI-8, популярный под юниксом, кодировка ДОС (DOS-866), кодовая страница 1251 в Windows. Ну и кроме того, иметь в одном тексте и кириллицу и латиницу было можно, а вот, к примеру, грузинский алфавит к ним засунуть было уже некуда.
И вот чтобы разместить сколько угодно языков в одном тексте, а заодно избавиться от этого зоопарка кодировок, и придумали Юникод.
С зоопарком, правда, получилось... как всегда. Вместо зоопарка кодовых страниц теперь зоопарк юникодов, но лингвистам жить стало легче - можно иметь сколько угодно алфавитов в одном файле.

vorphalack
18.03.2022 02:27дополненьице небольшое: на коммерческих юниксах еще резвилась ISO8859-5, а вдобавок еще и MacCyrillic на соответствующих железяках была. интересно у каких еще языков был такой бардак?

vin2809
18.03.2022 07:47Спасибо за труд. Но это только вступление или все...?
На эту тему можно написать книгу и не одну, потому что в наше время расширение файла практически НИЧЕГО не говорит о содержимом. Например, ".img".

greenkey
18.03.2022 09:01+1Кодировка UTF-8 имеет гораздо более сложную структуру, и она не "двухбайтовая", как могло бы показаться. Просто для подавляющего числа используемых символов его код будет состоять из одного или двух байтов. Но сама кодировка предполагает и большее количество байт на символ/знак.
greenkey
18.03.2022 09:20+3Вообще, принято условно разделять все файлы на две важные группы: plain text и binary. Первый - условно текстовый формат, на однобайтовой (старой) или многобайтовой (UTF-8 новой) кодировке, может иметь структуры высшего порядка внутри, но базирующиеся на тексте. Любой текст программы, xml, ini и куча других форматов - это plain text. Это важно, потому что позволяет применять общие системы контроля версий к ним и некоторые другие вещи.
Binary - имеет какую-то собственную структуру, как правило, состоящую из некоторого "заголовка" и "тела" с данными. Заголовок, зачастую, имеет часто признак типа файла - сигнатуру, которая также может быть использована при попытке определить его тип. Вот jpg, wav, mp3, exe - это именно binary.

motocross
18.03.2022 14:04"Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV."
Akina
Вот именно о том, что это утверждение может быть ложным, приходится регулярно напоминать...
Расширение даёт подсказку операционной системе и программам о том, какой тип данных файл, вероятно, содержит. Но при этом расширение не накладывает на содержимое файла никаких обязательств.
Ну и ещё можно отметить, что расширения бывают многоуровневыми (хотя более 3 уровней я лично не видел). tar.gz или fb2.zip, например. При этом расширение после последней точки подсказывает возможный конечный формат файла, предыдущее расширение - что мы, вероятно, получим, расшифровав последний формат, и т.д.
iig
Расширение (как отдельное поле) было актуально во времена MS DOS. В 21 веке это просто несколько символов в конце имени.
Akina
Тем не менее оно ещё очень интенсивно используется. Достаточно того, что интерфейсы ОС умеют его скрывать, а также передавать файл связанной с расширением программе на обработку. А так - да, Вы правы. Я даже специально использую термины "имя файла" и "полное имя файла" для случаев, когда расширение вырезано и когда оно присутствует, соответственно.
rPman
Сокрытие расширения — это худшее UI решение из всех существующих, как и к примеру сокрытие реального расположения или реального имени приложения (android), сколько на этом копий было сломано, после чего стало за правилом — везде выключать эти настройки.
greenkey
...отделенное последней точкой в имени, это важно, потому что точек может быть много.
unsignedchar
Archive.yyyy.mm.dd.tar.gz :)
13werwolf13
Неистово плюсую. Из-за вот таких объяснений бухгалтера потом и открывают отчёт.doc который внезапно оказывается скриптом.sh, благо современные ОС зачастую ругаются если файл является не тем что написано у него в имени.
ещё доставило это:
Автор, это например какие? я на вскидку вспомнил такое поведение только в windows, linux (по крайней мере те DE и файловые менеджеры которые я знаю), freebsd (с теми же DE и фм) и macos ничего не скрывают по умолчанию..
rPman
точно помню еще почтовый клиент какой то скрывал
greenkey
честности ради, автор и написал - "подсказку", что и означает "вероятно".
vmir88
Но в приведённом вами фрагменте ничего не сказано про обязательства. В чём ложность данного утверждения тогда?
Сами придумали тезис, даже не озвучили его, и сразу же бросились с ним спорить.
Akina
В цитате совершенно безальтернативно утверждается, что тип данных и структурирование соответствуют расширению. Именно это и есть обязательство. Я лично не готов воспринимать эту фразу как "Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано (но может и соврать)".
Считаете иначе? Ваше право.
vmir88
А, понял, вы безальтернативным утверждением считаете не «никогда не врёт», а отсутствие слов о том, что может соврать.
>Считаете иначе? Ваше право.
Почему вы не сказали, что это моё право, но не обязанность, вы что, безальтернативно утверждаете, что это моя обязанность?:)