

Дисклаймер: Я написал такую статью, какую сам хотел бы прочитать полгода-год назад, когда мы стартовали миграцию в облако. Мне бы она здорово помогла сэкономить силы, время и нервы – надеюсь, теперь поможет кому-то ещё. Здесь нет исчерпывающей экспертизы, только немного моего опыта для конкретных условий и наработанные мною решения и инструменты.
Критика и дополнения приветствуются.
Краткие вводные
К концу 2021 года наша серверная инфраструктура состояла из почти сотни виртуалок на паре десятков физических серверов, арендованных в одном из московских ЦОДов и была настоящей болью для эксплуатации. По причинам, столь банальным, что их не стоит обсуждать, мы погрязли в проблемах:
Сервера-снежинки в наихудшей их форме (хуже, чем вы представили)
Разносортица гипервизоров, платформ, конфигураций, версий ОС и ПО
Полное отсутствие решений по отказоустойчивости чего бы то ни было
Мучительные масштабирование, обслуживание и контроль
После нескольких чувствительных аппаратных сбоев было принято решение о масштабной модернизации. Перво-наперво нужно было выбрать стратегическое направление: строим мы свою инфраструктуру on-prem с СХД, VmWare и MLAG-ом, или, по-модному подвернув штаны, катим камень в гору IaaS.
Почему облако
Мы, конечно, слышали о том, что on-prem всегда дешевле, но настоящие инженеры не руководствуются слухами, предрассудками и шестым чувством. Поэтому, собрав в таблицу суммарное наше потребление vCPU, vRAM, дискового пространства и IOPs, пожелания по аренде лицензий и объёму системы резервного копирования, мы отправились получать цифры. Работа с дюжиной поставщиков, интеграторов и облачных провайдеров не была ни простой, ни быстрой, но всё же, спустя месяц-другой мы получили пухлую сводную таблицу: количество и модели серверов, СХД, коммутаторов, лицензии, СРК и прочее с заветной строчкой ИТОГО в самом низу.
Вопреки бытующему мнению, на наши не самые маленькие объёмы ресурсов в сумме 3 лет аренда IaaS у нескольких облачных провайдеров оказалась немного дешевле, чем построение on-prem инфраструктуры. В разрезе 5 лет - немного дороже, но при том, что с облаком уменьшаются накладные трудозатраты на обслуживание, а масштабироваться легче, чем сходить за кофе, выбор в пользу IaaS был несложным.
Теперь необходимо было выбрать между облачными провайдерами из шорт-листа. Мы составили список из нескольких десятков параметров для оценки: от SLA и синтетических тестов IOPs в разных размерах дисков до удобства работы с техподдержкой. Тесты, тесты, тесты, потом митинги с архитекторами и менеджерами облачных провайдеров и снова тесты - субъективно самая долгая и утомительная часть проекта на тот момент.
По совокупности критериев мы остановили выбор на VKCS (тогда ещё Mail.ru Cloud Solutions).
Почему Infrastructure As Code
Облако само по себе решало проблемы #2-4, но lift-and-shift миграция не решила бы проблему #1 с хаосом серверов-снежинок. Мы хорошо представляли, что только одновременная переработка сервисов в концепции Infrastructure As Code даст прозрачность, повторяемость, стандартизацию и прочие преимущества. Даже для тех сервисов, полную конфигурацию которых сложно (привет, платформа 1С, как там твой 2007й год?) или невозможно автоматизировать, мы решили применять IaC для создания всех облачных объектов и базовой конфигурации ОС.
Но понимать, что паровоз сильнее лошади – это одно, а управлять паровозом и, тем более, его создать – совсем другое. Десятки просмотренных видео с конференций могут дать понимание того, какие проблемы решает IaC и какие есть инструменты на рынке, а документация к инструментам – как ими пользоваться, но это не равно экспертизе.
По мере подготовки проекта миграции перед нами встали следующие вопросы, большую часть которых мы решали, не имея ещё опыта, полного видения желаемого результата и в условиях жесткого дедлайна:
А теперь ответы, которые мы для себя нашли, грабли, по которым мы прошли и инструменты, которые мы для себя создали.
Тулинг
В качестве SCM мы выбрали Ansible – потому что минимальные знания по Ansible в команде уже были, а Chef или Puppet пришлось бы учить вообще всем. Кроме того, Ansible лидирует на рынке, что должно коррелировать с размером сообщества и скоростью доработки.
В качестве системы управления инфраструктурой выбрали Terraform – потому что Cloudformation слабо применим к Openstack-облаку, а Pulumi требует хорошего знания общего языка программирования. Возможно, стоило рассмотреть Terragrunt, потому что управление окружениями с ванильным Terraform потребовало отдельной проработки и сложных шаблонов и пайплайнов.
Для CI/CD-платформы решили использовать имеющийся self-hosted инстанс Gitlab, так как именно его мы в компании используем для всех прочих проектов и, когда придёт время и инфраструктурный код сольётся с продуктовым, не нужны будут дополнительные усилия по миграции.
В качестве IDE выбрали Visual Studio Code – множество дополнений для IaC (Ansible, Terraform, Gitlab), приятный интерфейс, встроенный GUI для гита, чтобы упростить вход для начинающих и отличная интеграция с WSL.
Как поделить ресурсы на проекты
В терминологии VKCS «проектом» называется сущность, аналогичная VPC в AWS – набор облачных ресурсов под единым управлением группы пользователей, отделённый от других подобных наборов. Например, виртуальные машины в проекте могут быть напрямую объединены в одну сеть или подсеть, а между проектами связь возможна только через VPN. Список пользователей, рулсетов файрволла, образов и т.п. также различны в разных проектах. Коротко говоря – это независимое отдельное виртуальное частное облако.
Нужно ли вообще делить ваши ресурсы на проекты?
Плюсы деления:
Различные скоупы управления – можно наделить администратора или разработчика полными правами для экспериментов и не бояться, что он случайно уничтожит продакшн
Можно разворачивать полные копии объектов в тестовых окружениях, не опасаясь что-то сломать на проде
Минусы деления:
Нужно обеспечивать сетевую связность между проектами своими силами
В Terraform-коде нельзя ссылаться напрямую на объекты из другого проекта, например, на адрес инстанса для правила группы файрволла, только через remote state
Дополнительный административный оверхед на управление квотами и доступами
Для себя мы решили вопрос, выделив 3 отдельных типа проектов:
Типы проектов

Playground – песочница для быстрых экспериментов, разработки и отладки инфраструктурного кода. Когда знания команды по Ansible и Terraform изначально недалеки от нуля, а предстоит переработать в IaC несколько десятков сервисов в ограниченный срок, очень важно дать людям возможность быстро и удобно начать учиться и разрабатывать. Любой желающий имеет права на создание и удаление любых объектов в песочнице, как вручную, так и посредством исполняемого локально или через CI/CD-пайплан кода Terraform.
Production – боевой проект с серверами и сервисами, обслуживающими живых пользователей – внешних и внутренних.
DevQA – проект со статически и динамически создаваемыми окружениями для тестировщиков и разработчиков.
В каждом проекте, конечно, есть core-объекты: сети, подсети, гейтвеи, базовые группы файрволла, роутеры для vpn-связности и т.п., доступ к которым должен быть ограничен.
Что, во имя всех CCIE, делать с сетью
Мы понимали, что сеть – основа основ, а ошибки при проектировании могут выйти дорого. Конечно, cloud-native подход предлагает меньше думать о сегментировании, vlan-ах, маршрутизации и прочих старомодных глупостях, а больше сосредоточиться на продукте, максимально используя преимущества облачные PaaS. Но это всё здорово только если вся компания работает на собственный софтверный продукт и продаёт только его. В наших условиях, кроме продуктовых серверов, нам нужно обеспечивать эксплуатацию множества внутренних сервисов сторонних вендоров, без которых компания не сможет продавать свои услуги.
Подсети
Сегментация – одна из составляющих безопасности в старых-добрых энтерпрайз сетях. Вы делите сеть на заключенные в vlan подсети и на границах ставите файрволл, чтобы ограничить подключения между подсетями только жизненно необходимыми. Таким образом сервер, доступный извне, при потенциальной компрометации, не сможет стать для злоумышленника площадкой для доступа ко всей остальной внутренней сети.
В случае с облачной сетью во vlan нет такой необходимости, потому что вы можете виртуально поставить управляемый отдельно файрволл перед каждым сетевым интерфейсом каждой виртуальной машины – в терминологии VKCS это называется Security Group. «Группа безопасности» — это набор правил, определяющий, в каком направлении, по какому протоколу и на какие порты могут быть установлены соединения с помощью этого интерфейса. Этот файрволл не управляется из ОС виртуальной машины, в этом он полностью аналогичен аппаратному файрволлу.
Подробнее об использовании SG будет сказано ниже, но разделение на подсети в целях ИБ потеряло смысл, поэтому мы приняли решение использовать одну сеть в каждом проекте, в каждой из которых по одной подсети – это существенно упрощает эксплуатацию и создание новых инстансов, и не несёт ограничений.
Группы безопасности
Группа безопасности default, назначаемая при ручном создании ВМ по-умолчанию, позволяет всем инстансам беспрепятственно обмениваться трафиком с другими ВМ в группе – некий аналог плоской сети. Это удобно для быстрого старта, когда скорость разработки важнее безопасности, но, конечно, нас такой вариант не устраивал.
С помощью SG вы можете относительно легко реализовать микросегментацию – когда каждая отдельная ВМ или группа ВМ (например, в составе кластера) имеет доступ только к тем адресам, портам и протоколам, к которым должна иметь доступ. Это затрудняет lateral movement для злоумышленника или малвари в случае компрометации одного из серверов и, следовательно, положительно влияет на безопасность.
Для себя мы разработали и приняли следующую схему (принципиальный вариант, только облачная часть; не все механизмы безопасности показаны):
Схема работы с Security Groups
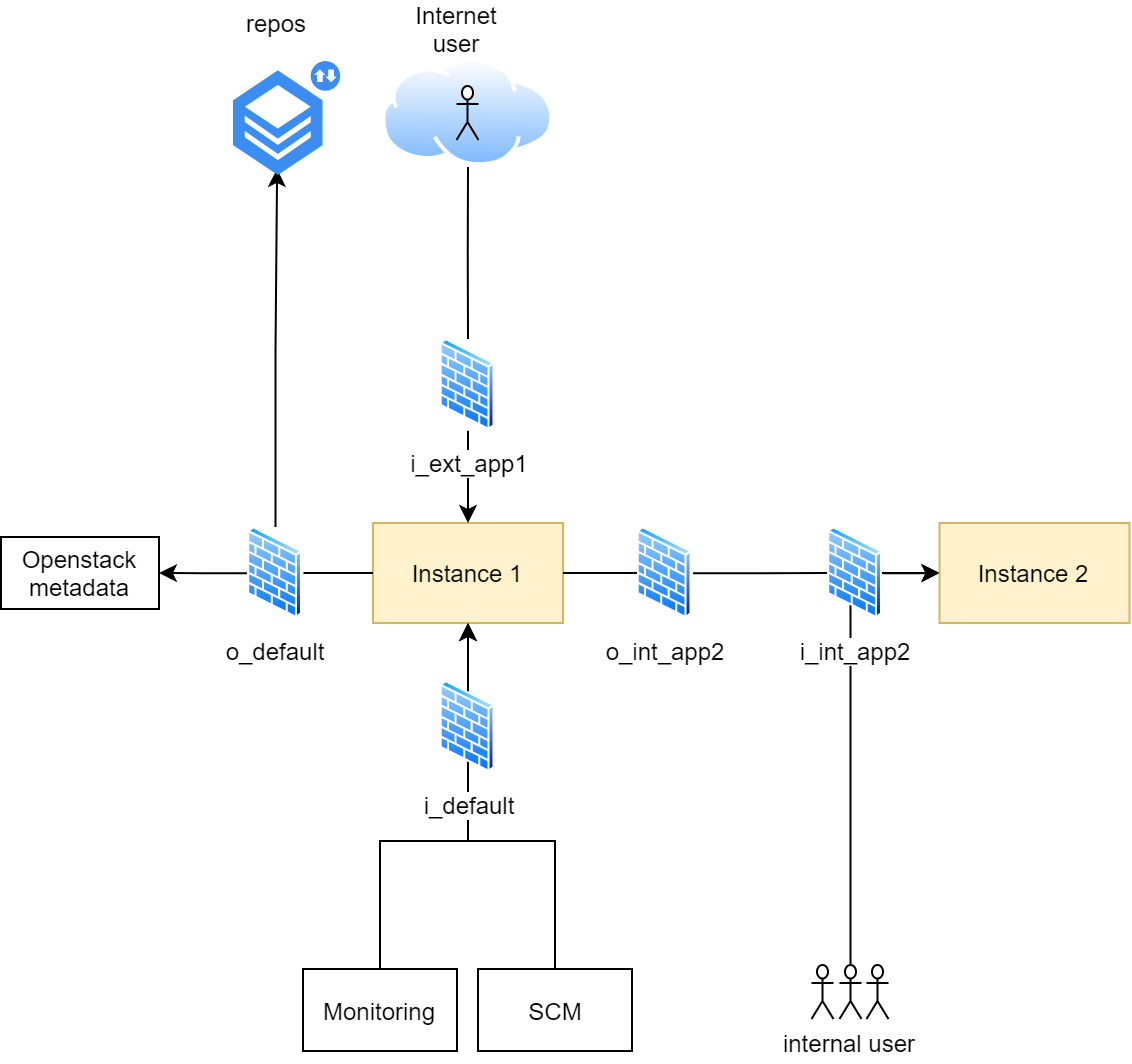
i_default/o_default На виртуальную машину почти всегда назначаются группы по-умолчанию, которые разрешают только самое необходимое – входящие подключения с нод управления, мониторинга и пр., и исходящие во внутреннюю сеть, адреса метаданных Openstack и на репозитории пакетных менеджеров
i_int_appname_servicename Для всех сетевых доступов внутри сети создаются отдельные группы с перечисленными адресами или подсетями, которые должны иметь доступ к конкретному сервису
o_int_appname_servicename Если список облачных хостов неопределён, например, это кластер, или просто слишком велик для ручного управления, то к группам на входящее подключение создаётся комплиметарная группа на исходящее подключение. В этом случае правило входящего подключения привязывается не к конкретному адресу источника, а к имени группы. То есть группа o_svc_appname_servicename здесь служит как некий тег
i_ext_appname_servicename Для доступов извне к сервисам в нашем облачном проекте создаются отдельные группы
В целом, схема получилась простая для понимания и использования, и позволяет строить сервисы с достаточной сетевой изоляцией между ВМ. Минус - заметный оверхед на обработку списков адресов.
Site-to-site VPN
К сожалению, VPNaaS от VKCS пока не умеет ни в ECMP, ни в route-based ipsec, ни в протоколы динамической маршрутизации. А у нас достаточно жёсткие требования по устойчивости и качеству связности с сервисами в ЦОДе/облаке – например, для систем колл-центра. Раньше мы обеспечивали выполнение этих условий, используя Fortigate SDWAN на двух ipsec-туннелях через разных провайдеров с каждой площадки, но в случае с VPNaaS такая схема не могла работать.
Пришлось искать другое решение для виртуального роутера. Хорошее со всех сторон решение Fortigate-VM, к сожалению, на тот момент не прошло по бюджету, поэтому мы использовали VyOS 1.3. Среди плюсов VyOS можно отметить бесплатность (если не покупать поддержку и использовать rolling release), готовый модуль для Ansible и удовлетворительную работу OSPF и route-based ipsec. Собрать образ для KVM можно самостоятельно с помощью любезно предоставленных вендором инструментов, установив в него, например, гостевые утилиты и включив поддержку cloud-init.
В-целом этап с настройкой и тестированием VyOS съел слишком много времени. Мой совет: если у вас нет особых требований к резервированию канала в облако, то лучше используйте VPNaaS, а если есть – купите Fortigate или другое виртуализированное решение с поддержкой.
DNS
Мы используем Active Directory для управления пользовательскими ПК и частью серверов под внутренние сервисы, поэтому DNS-записи должны регистрироваться в зонах, которые обслуживаются контроллерами домена. Мы не нашли решения, которое позволило бы интегрировать платформенные DNS-сервера с нашими, поэтому записи мы создаём через Terraform-провайдер, аутентифицируясь на DNS-серверах через GSS-TSIG. Для каждой ВМ описывать отдельно запись в коде, конечно, неудобно, поэтому мы добавили эту функциональность в модуль Terraform, о котором ниже.
Какую структуру репозиториев выбрать
Казалось бы, пустяковое решение, которое, однако повлияло в дальнейшем и на CI/CD и работу со стейтами, а неверный подход привёл нас в итоге к заметному техническому долгу, который здорово тормозил некоторые наши операции.
Стартовать мы решили в варианте, когда под каждый облачный проект VPC у нас отдельный репозиторий Terraform-кода. А под каждый сервис, конфигурируемый через Ansible, ещё свой отдельный репозиторий.
Как это выглядит

Плюсы такого подхода:
Проще настроить CI/CD один раз вручную и вроде как забыть
Можно ссылаться на атрибуты из одного модуля в другом
Минусы:
Чем больше сервисов заезжает в репозиторий, тем медленнее становятся операции. State-файл растёт, и для каждого объекта Terraform должен опросить API платформы на предмет изменений. Terraform plan может идти несколько минут.
Проблема с одним объектом парализует работу со всеми другими. Например, если при ресайзе поломалось какое-то PaaS-файловое хранилище, другие изменения с несвязанными сервисами вы тоже не сможете применить, потому что Terraform каждый раз будет спотыкаться на одном месте. Всем придётся ждать, когда придёт техподдержка и починит злосчастное хранилище.
Невозможно раскатывать один и тот же код в разных окружениях автоматизированно – только ручной копипаст
Если для отдельного сервиса потребуется отдельный CI/CD-пайплайн, вы не сможете его сделать, пока код хранится в репозитории
Хранимый отдельно код Ansible банально сложнее искать
В итоге сейчас мы пришли к концепции «один сервис – один IaC-репозиторий», с подключаемой из общего репозитория конфигурацией CI/CD и очень жалеем, что не начали так делать с самого начала. Неверные решения - генеральный спонсор нашего технического долга.
Схема нового типа репозиториев
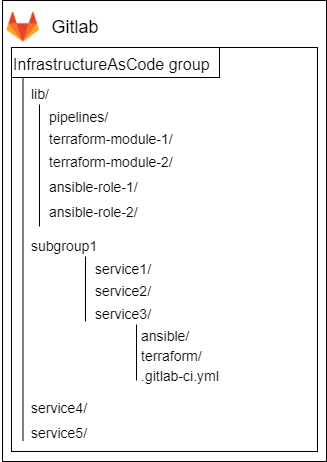
Подробнее о структуре в разделе про CI/CD
Как готовить Terraform
State-файл
.tfstate – основа основ Terraform, это файл, в котором Terraform сохраняет всю полученную от API информацию о каждом описанном в коде объекте и их зависимости друг от друга. Например, при создании облачного диска вы описываете в коде его название, тип и размер, но с точки зрения платформы облачного провайдера у него есть множество других свойств, генерируемых автоматически – уникальный ID, метаданные и пр., которые нужны будут Terraform, чтобы при следующем обращении к API однозначно определить, какой объект в коде соответствует объекту в облаке и какие параметры изменились.
Хранить стейт нужно надёжно, безопасно и, желательно, иметь возможность вернуться к предыдущей версии, если что-то пошло не так. Кроме того, если вы работаете с кодом не в одиночку с одного ПК, а, например, используете CI/CD для командной разработки, state должен быть доступен для всех ваших коллег, а во время выполнения кем-то кода на state должен ставиться признак блокировки.
Terraform поддерживает множество бэкендов – хранилищ для стейта. Часто для бэкенда выбирают S3, но, к сожалению, на момент старта нашей миграции в облако VKCS ещё не очень хорошо умел в ACL, поэтому мы воспользовались Gitlab-managed Terraform state – встроенным в Gitlab бэкендом типа http с шифрованием at rest, версионированием и блокировками. Этот бэкенд отлично оптимизирован под работу с Gitlab CI/CD.
Стандартизация и модули
Очень скоро после начала совместного написания кода стало понятно, что, во-первых, Terraform-провайдер Openstack - весьма "многословный" с результатом в виде портянок трудночитаемого кода, в котором легче лёгкого ошибиться с именами и значениями десятков объектов. Во-вторых, каждый из коллег писал код так, как казалось правильным именно ему, произвольно именуя и разбивая по файлам десятки объектов. Сопровождать такой код сложно, мы ежедневно ошибались в значениях параметров и именах переменных.
Настоящим спасением стало написание своих модулей.
Это позволило перейти от подобной портянки
resource "openstack_networking_secgroup_v2" "i_example" {
name = "i_example"
description = "Group to access some service"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_1" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 80
port_range_max = 80
remote_ip_prefix = "10.10.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_2" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 80
port_range_max = 80
remote_ip_prefix = "10.20.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_3" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 80
port_range_max = 80
remote_ip_prefix = "10.30.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_4" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 80
port_range_max = 80
remote_ip_prefix = "10.40.10.1/32"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_5" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 443
port_range_max = 443
remote_ip_prefix = "10.10.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_6" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 443
port_range_max = 443
remote_ip_prefix = "10.20.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_7" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 443
port_range_max = 443
remote_ip_prefix = "10.30.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_8" {
direction = "ingress"
ethertype = "IPv4"
protocol = "tcp"
port_range_min = 443
port_range_max = 443
remote_ip_prefix = "10.40.10.1/32"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
resource "openstack_networking_secgroup_rule_v2" "i_example_9" {
direction = "ingress"
ethertype = "IPv4"
protocol = "udp"
port_range_min = 9000
port_range_max = 11000
remote_ip_prefix = "192.168.0.0/24"
security_group_id = "${openstack_networking_secgroup_v2.i_example.id}"
}
data "openstack_compute_flavor_v2" "standard-2-4-50" {
name = "Standard-2-4-50"
}
data "openstack_images_image_v2" "win2019en" {
name = "Windows-Server-2019Std-en.202105"
}
locals {
winrm_cert = {
winrm-sf-prod-main = {
admin_cert0 = substr (filebase64("~/.winrm/winrm.der"),0,255)
admin_cert1 = substr (filebase64("~/.winrm/winrm.der"),255,255)
admin_cert2 = substr (filebase64("~/.winrm/winrm.der"),510,255)
admin_cert3 = substr (filebase64("~/.winrm/winrm.der"),765,255)
}
}
}
resource "openstack_compute_keypair_v2" "ansible-key" {
name = "ansible-key"
public_key = file("~/.ssh/id_rsa.pub")
}
resource "openstack_blockstorage_volume_v2" "win-example-c" {
name = "win-example-c"
size = 60
volume_type = "ceph-ssd"
availability_zone = "MS1"
image_id = data.openstack_images_image_v2.win2019en.id
}
resource "openstack_blockstorage_volume_v2" "win-example-bases" {
name = "win-example-bases"
size = 120
volume_type = "ceph-ssd"
availability_zone = "MS1"
}
resource "openstack_compute_instance_v2" "win-example" {
availability_zone = "MS1"
name = "win-example"
flavor_id = data.openstack_compute_flavor_v2.standard-2-4-50.id
security_groups = ["i_default", "o_default", openstack_networking_secgroup_v2.i_example.name]
key_pair = "ansible-key"
network {
name = "network-1"
fixed_ip_v4 = "10.0.0.10"
}
block_device {
uuid = "${openstack_blockstorage_volume_v2.win-example-c.id}"
source_type = "volume"
boot_index = 0
destination_type = "volume"
delete_on_termination = false
}
metadata = merge(
local.winrm_cert.winrm-sf-prod-main,
{
os = "windows"
os_ver = "2019"
app = "example"
}
)
}
resource "openstack_compute_volume_attach_v2" "bases" {
instance_id = "${openstack_compute_instance_v2.win-example.id}"
volume_id = "${openstack_blockstorage_volume_v2.win-example-bases.id}"
}
resource "dns_a_record_set" "dns" {
zone = "example.com."
name = openstack_compute_instance_v2.win-example.name
addresses = [
openstack_compute_instance_v2.win-example.network[0].fixed_ip_v4
]
ttl = 300
}К такому лаконичному и удобному коду
module "i_example" {
source = "git::https://github.com/realscorp/tf-openstack-vkcs-secgroup.git?ref=v1.0.0"
name = "i_example"
description = "Group to access some service"
rules = [{
direction = "ingress"
protocol = "tcp"
ports = ["80", "443"]
remote_ips = {
"Office 1" = "10.10.0.0/24"
"Office 2" = "10.20.0.0/24"
"Office 3" = "10.30.0.0/24"
"Server" = "10.40.10.1"
}
},
{
direction = "ingress"
protocol = "udp"
ports = ["9000-11000"]
remote_ips = {
"Remote access VPN" = "192.168.0.0/24"
}
}]
}
module "win-example" {
source = "git::https://github.com/realscorp/tf-openstack-vkcs-vm.git?ref=v1.0.0"
name = "win-example"
flavor = "standard-2-4-50"
image = "Windows-Server-2019Std-en.202105"
ssh_key_name = "ansible-key"
winrm_cert_path = "~/.winrm/winrm.der"
metadata = {
os = "windows"
os_ver = "2019"
app = "EXAMPLE"
}
ports = [
{
network = "network-1"
subnet = "subnet-1"
ip_address = ""
dns_record = true
dns_zone = "example.com."
security_groups = ["i_default", "o_default"]
security_groups_ids = [module.i_example.id]
}
]
volumes = {
root = {
type = "ceph-ssd"
size = 60
}
bases = {
type = "ceph-ssd"
size = 120
}
}
}При этом создаваемые внутри модулей объекты именуются автоматически и по стандарту, и при необходимости ручного вмешательства всегда можно по имени определить, к какому сервису они относятся.
Модули можно взять на Гитхабе: инстансы и группы безопасности.
Как готовить Ansible
Динамический инвентори
Одна из основ Ansible – это инвентори: список хостов, конфигурацией которых требуется управлять, а также информация о том, как они сгруппированы и, иногда, список переменных для них. Конечно, если мы хотим максимально автоматизировать свои операции с облачными ВМ и всегда владеть актуальной информацией, статический инвентори нам не подходит.
Среди коллекций, устанавливаемых вместе с Ansible, уже есть плагин динамического инвентори Openstack, и остаётся только решить, как его правильно использовать. Что нам было нужно от инвентори:
Получать список хостов из облака каждый раз при запуске плейбука
Получать список групп также из облака
Задавать группы хостов при создании ВМ через код Терраформ
Стандартизировать работу с группами
Очевидный способ задавать группы – использование тегов, но на данный момент VKCS ещё не поддерживает назначение тегов на инстансы через Terraform (точнее, нельзя их задать в момент создания). Исходя из этого ограничения и наших пожеланий мы приняли решения использовать атрибут Metadata для хранения key/value-тегов и написали такую конфигурацию для динамического инвентори:
inventory/openstack.yml
# Настройки динамического инвентори Openstack
# Сами значения переменных для аутентификации задаются в переменных окружения с префиксом OS_
############
# Включаем плагин
plugin: "openstack.cloud.openstack"
# Отключаем встроенный алгоритим разбития на группы
legacy_groups: false
# По умолчанию доступ к хостам по внутренним ip
private: true
# Создаём кастомные группы по различным атрибутам с нужным префиксом
keyed_groups:
- prefix: mtag
key: openstack.metadata
parent_group: all
separator: "_"
# Генерируем некоторые переменные для каждого хоста
compose:
# Если на машине установлен метатег ssh_external = yes, настраиваем подключение ansible по внешнему адресу
ansible_host: openstack.public_v4 if 'yes' == openstack.metadata.ssh_external else openstack.private_v4
ansible_ssh_host: openstack.public_v4 if 'yes' == openstack.metadata.ssh_external else openstack.private_v4
# Полезно для отладки
fail_on_errors: true
Теперь на создаваемые инстансы добавляем в metadata записи по стандарту:
os = linux
os_ver = ubuntu20
app = nginx
service = site1И эти записи автоматически разворачиваются в группы mtag_os_linux, mtag_os_ver_ubuntu20, mtag_app_nginx и mtag_service_site1. Для групп, описывающих тип ОС и дистрибутив, через переменные в group_vars можно описать особенности подключения, а для групп приложения и сервиса – создавать таски в плейбуках.
WinRM
Большой загадкой для нас была работа Ansible с Windows, ведь если для Linux есть ssh с привычной, простой и безопасной аутентификацией по ключу, то как поступить с Windows?
Протокол WinRM, который на данный момент в Ansible является предпочтительным для удалённого конфигуририрования Windows (ssh поддерживается, но для продакшна не рекомендован), позволяет использовать несколько схем аутентификации:
Basic – прост в использовании, но не безопасен к перехвату злоумышленником. При использовании с Ansible ещё и необходимо устанавливать на все ВМ с Windows одинаковый логин-пароль при создании
NTLM – устаревший, недостаточно криптографически стойкий протокол, плюс та же проблема с общим паролем, что и у Basic. При всех недостатках это один самых популярных способов
CredSSP – аутентификация по логину и паролю для локальной или доменной учётной записи. Секреты шифруются и протокол считается более безопасным, чем NTLM, однако остальные недостатки остаются, и добавляется необходимость предварительной настройки хоста
Kerberos – при правильной настройке и использовании безопасный способ, но требует ввода всех виртуальных машин в домен, что в наших условиях не подходит
Certificate – аутентификация по паре открытая/закрытая часть сертификата. Очень безопасный способ, но и самый сложный в использовании: требуется включить WinRM, сгенерировать сертификат, установить его в систему и настроить аутентификацию с нужным отпечатком и, внимание, с указанием пароля пользователя, для которого настраивается аутентификация
Поначалу мы откровенно приуныли - выбор был, как казалось, между слишком компромиссными и слишком сложными методами. Несколько дней прошли в экспериментах и написании собственных Powershell-скриптов по настройке Certificate-based аутентификации. К счастью и большому нашему облегчению, после длительного изучения откровенно плохой документации, выяснилось, что самую грязную работу за нас уже заботливо выполнили авторы Cloudbase-init – Windows-аналога cloud-init из мира Linux.
Во всех образах Windows, любезно предоставляемых VKCS, уже предустановлен Cloudbase-init, и, если вы в создаваемый инстанс добавите открытую часть сертификата через userdata или, порезав его на куски, в metadata, то при первой загрузке инстанса cloudbase самостоятельно установит сертификат и настроит WinRM. Пароль при этом будет сгенерирован автоматически и будет уникальным для каждого инстанса. Останется только добавить настройки подключения по сертификату в group_vars и можно приступать к написанию плейбуков. Мы можем использовать все преимущества аутентификации по сертификату с минимумом усилий и избежав практически всех недостатков этого способа!
Однако нужно помнить об одной особенности: если вы измените пароль пользователя, к которому привязан сертификат, то аутентификация по сертификату после перезагрузки перестанет работать. Нужно будет либо перепривязывать сертификат через Powershell, либо пересоздавать инстанс.
Полезный совет
Версионируйте! Всё и всегда! Фиксируйте версии пакетов, которые вы устанавливаете в плейбуках. Фиксируйте версии сторонних ролей, которые вы используете. Создавайте теги с версиями для каждой роли, которую вы написали внутри компании (например, с семантической схемой) и указывайте версию в requirements.yml
Без привязки к версиям вы не сможете полагаться на ваш код, а развитие компонентов будет сущим мучением.
То же самое относится и к Terraform – обязательно создавайте теги с версией для ваших модулей и вызывайте конкретную версию.
CI? CD, я сам открою
Все мы, конечно, понимаем, что CI/CD – это не только про пайплайны и автоматизацию (можно почитать, например, у Фаулера), но в контексте статьи я хочу рассказать именно про них.
По мере погружения в работу над Terraform-кодом в команде мы очень, очень быстро перешли от знания того, что без CI/CD жить плохо, к пониманию. Запускать код с локальной машины техлида вручную, по сообщению в мессенджере делая пулл из общей репы – не только небезопасно, но и исключительно неэффективно.
К счастью, Gitlab имеет хорошие встроенные инструменты для быстрого построения Terraform-пайплайна: вы можете хранить state-файл во встроенном http-бэкенде (с шифрованием и версионированием) и выполнять код в специально подготовленном контейнере. Документация содержит базовый пример для быстрого старта, и именно на этом стартовом пайплайне мы длительное время работали.
Но, конечно, базовый пайплайн не мог покрыть наши потребности:
Максимально простой и быстрый старт в разработке
Работа из одного пайплайна со всем инфраструктурным кодом, Terraform, Ansible, в будущем Packer и пр.
Вспомогательные инструменты вроде списка флейворов/образов в проекте
Полное самообслуживание – от создания проекта до настройки CI/CD-пайплана, доступное без изучения Gitlab
Перенос в боевое окружение именно того кода, что проверен локально
Разворачивание через CI/CD одного параметризированного кода в разные окружения
Модульность для самостоятельного выбора инструментов, версий и окружений
Инструменты для простой отладки как локально, так и в боевом окружении
Возможность использовать в пайплайне привычные опции Ansible --tags и --limit
Хотя бы базовая безопасность для хранения секретов
Пришлось хорошенько попотеть над документацией Gitlab и инструментов, за вайтбордом над схемами и провести множество экспериментов, но в результате получилось найти решение для всех поставленных задач.
Страшная схема пайплайна

Страшная схема воркфлоу

Нестрашное описание словами:
IaC-разработчик создаёт репозиторий в Gitlab из шаблона через Import by URL (ограничение бесплатной версии)
Склонировав репозиторий на свою машину, он запускает скрипт для настройки окружения на работу с проектом-песочницей
Раскомментировав примеры из шаблона, уже можно создать и конфигурировать первые инстансы
Шаблон написан так, чтобы инстансы создавались с локальными парами ssh-ключей и winrm-сертификатов. Если winrm-сертификат ещё не создан, поможет второй скрипт.
Чтобы зайти на созданный инстанс Linux, нужно просто набрать ssh user@host, и, так как он был создан с локальной парой ключей, логин пройдёт успешно.
Чтобы зайти на Windows-инстанс по RDP, можно использовать четвёртый скрипт для получения и дешифровки уникального пароля от платформы Openstack. Для этого нужно, чтобы при создании инстанса был указан ssh-ключ, точно также, как и для Linux.
Примеры Ansible в шаблоне также преднастроены на работу с локальными ключами ssh и WinRM – дополнительные действия не требуются, после создания инстанса можно немедленно запускать его конфигурацию.
Те параметры кода, которые должны отличаться между песочницей и боевым проектом, например, флейворы, выносятся в переменные и указываются либо локально, либо в файлах в каталогах environment
После того, как код готов к деплою в боевое окружение или проверке через CI/CD, разработчик отмечает в .gitlab-ci.yml, какие инструменты и окружения ему нужны и делает push в main или merge request. Пайплайн сам создаст только нужные джобы только в нужных окружениях и заботливо подставит боевые ключи и настроит контейнер на исполнение кода. Изменять код как-то отдельно не нужно.
Для траблшутинга (на отладку это не тянет) исполняемого через пайплайн кода предусмотрен вывод в лог переменных окружения и содержимого файлов с переменными в удобном виде.
Если разработчик хочет использовать Ansible Vault для хранения части переменных, ему поможет ещё один скрипт – нужно только перенести сгенерированный пароль в CI/CD-переменные Gitlab, и не забыть удалить файл с паролем с локального диска, когда работа закончена.
Если разработчику нужно посмотреть список флейворов или образов в проекте, он может использовать вспомогательные джобы пайплайна – просто нажимаешь кнопочку в Gitlab, выполняется запрос через Openstack CLI и выводит информацию.
.gitignore предотвращает случайную загрузку в репозиторий на Gitlab ключей и локальных стейтов.
Посмотреть код пайплайнов, вспомогательных файлов, шаблона и скриптов можно на Гитхабе.
О каких стандартах договориться «на земле»
Конечно, нейминг!
Я немного «повёрнут» на стандартах нейминга – эдакий посттравматический синдром после внутреннего аутсорсинга в большом холдинге, когда можно было часами искать в AD нужную группу или политику среди сотен хаотично и бестолково названных, чтобы выполнить пустяковую задачу. Правильный нейминг позволяет легко ориентироваться среди тысяч объектов, и, зная схему, в голове сгенерировать имя и угадать почти всегда.
Для нейминга инстансов можно использовать несложную схему вроде такой:

Примеры:
v-sql-qa – Microsoft SQL Server для продакшн-приложения в QA-окружении
v-iis-app1-1 – Веб-сервер для бизнес-приложения 1, первый из нескольких
v-gitlab – Сервер Гитлаб
Для нейминга SG отлично показала себя такая схема

Примеры Security Groups:
i_default – группа по-умолчанию для входящих подключений (мониторинг, управление и т.п.)
i_int_web_office – доступ к http/https с офисных площадок
i_ext_smtp – входящие подключения к smtp извне
o_int_saml – исходящие подключения к сервису saml
Все остальные рекомендации по неймингу есть в документации к Terraform, либо просто очевидны (например, префиксы ans-role- к репам с ролями Ansible), но хотелось бы сделать акцент на именовании переменных в коде Ansible. Из-за того, что значения переменных можно задать в 22 местах и они будут переопределены в соответствии с таблицей приоритетов, недопустимо случайно назвать одинаково переменную роли и переменную плея. Для себя мы определили, что все переменные роли должны иметь префикс из 3-4 букв от сокращённого имени роли, например, wcmn_domain_join – переменная из common-роли для Windows, определяющая, нужно ли заводить инстанс в домен.
Как работать с IaC в команде
Инфраструктурный код – это тоже код. Его можно и нужно версионировать, тестировать и применять другие полезные практики из мира разработки. Одна из таких практик – код-ревью, которую мы широко применили на старте проекта миграции. Всё, что должно было выкатываться в бой из ветки main, не могло попасть туда напрямую, требовалось делать мердж-реквест (MR) на техлида. Это была исключительно полезная практика для команды, потому что стало возможно:
На живых и важных задачах обучать коллег
Контролировать качество кода и вместе переделывать
Выявлять узкие места в процессах и инструментах и тут же их дорабатывать
Понимать, кто и с какой проблемой застрял и помогать её решить
Но для этого техлида (меня в данном случае) практика была опустошающая. После пары месяцев одновременной разработки ролей и модулей, пайплайнов, написания кода для миграции своей части сервисов, обучения коллег, ревью реквестов и постоянных переключений контекста в условиях жёсткого дедлайна я с размаху врезался в границы возможностей нервной системы и не хотел бы повторять этот опыт.
К счастью, к этому времени костяк команды уже неплохо научился писать инфраструктуру, я дописал все модули и инструменты и настало время попытаться перейти к кросс-ревью внутри команды.
На данный момент мы приняли следующие правила игры:
Разработка нового сервиса ведётся локально через песочницу, пока не будет готово
При выкатке в бой делается МР на кого-то из коллег, тот просматривает код, задаёт вопросы, вносятся правки
После того как сервис уже работает на бою, несрочные правки и фиксы вносятся через МР на коллегу
Срочные фиксы и правки пушатся напрямую в main
У такого подхода есть минусы, например, после первой выкатки в бой могут требоваться доработки, если что-то забыли или проявилась разница в окружениях песочницы и боевого проекта. Каждый раз ждать МР может быть неудобно – ведь задачи обычно все срочные, и такие правки идут без ревью. Но мы понимаем, что для совершенно новой концепции работы это нормально, и процессы будут развиваться.
Заключение
Даже практически завершив миграцию мы, конечно, ещё не достигли всех намеченных целей. Да, на уровне виртуализации всё отказоустойчиво, производительность всегда предсказуема, масштабироваться теперь можно за минуты, а не за недели, а новый сервис развернуть за полчаса. Да, 100% виртуальных машин как минимум базово описаны в коде; у нас есть тесты, версионирование, автор любой правки и найти ошибку или массово изменить конфигурацию стало проще на порядки.
Но есть и технический долг из-за неверно принятых решений, есть и незакрытая ещё потребность в immutable infrastructure, есть и планы по переработке продакшн-сервисов в Cloud Native. Но даже пройденные этапы потребовали значительных затрат времени и сил.
Поэтому надеюсь, что кому-то, кто только задумался о миграции в облако или рефакторингу в IaC, наш опыт и наработки помогут принять правильные решения и провести свои проекты быстрее, эффективнее и без нервного истощения :)
Комментарии (30)

gecube
20.03.2022 13:51+3Скол ко человеко-часов потратили? Судя по описанию - я так понял, что стартанули в конце 2021, а уже март 2022, то есть, в общем-то, не так много времени прошло? И о каких масштабах инфры идёт речь? Сотни, тысячи виртуалок? Переезд уже закончился или все ещё в процессе?
Ещё такой вопрос - почему ансибл? Как я понял, Вы доконфигурируете сервера после создания их терраформом? Почему не пошли от обратного - создание своих шаблонов под каждый тип приложений и уже развёртывание готовых к эксплуатации ВМ?
В остальном статья очень подробная и полезная. Большая спасибо. Есть что почерпнуть для своей работы.

realscorp Автор
20.03.2022 15:05+3Скол ко человеко-часов потратили? Судя по описанию - я так понял, что стартанули в конце 2021, а уже март 2022, то есть, в общем-то, не так много времени прошло? И о каких масштабах инфры идёт речь? Сотни, тысячи виртуалок?
Проект стартовал в декабре 2020, примерно до февраля шла работа по выбору между on-prem и IaaS, затем до августа - выбор конкретного облачного провайдера, это всё в одного техлида параллельно с другими проектами, плюс ~неделя со стороны пары QA и разработчика для тестирования копии продов. С сентября началась подготовка миграции и сама миграция. Подготовка - проработка концепций, сетевая часть, написание модулей и common-ролей, пайплайны и т.п. - примерно 3 месяца работы одного техлида суммарно. Сама миграция - порядка 5-6 месяцев командой из 3-4 человек (параллельно с другими задачами). Масштаб - чуть менее сотни виртуалок.
Переезд уже закончился или все ещё в процессе?
Почти закончился, осталось примерно 7%.
Ещё такой вопрос - почему ансибл? Как я понял, Вы доконфигурируете сервера после создания их терраформом? Почему не пошли от обратного - создание своих шаблонов под каждый тип приложений и уже развёртывание готовых к эксплуатации ВМ?
Я согласен, что это стратегически более правильный подход и это будет следующим этапом развития нашей инфры. Но, во-первых, для этого нужно освоить Packer, обучить команду и вписать его в общий воркфлоу и пайплайны, а у нас был жёсткий дедлайн. Во-вторых, многие наши виртуалки в любом случае, после создания даже из шаблона, нужно доводить до ума - хотя бы вводить в домен Windows-инстансы. А в-третьих, Ansible очень удобен для сложного конфигурирования и даже в Packer мы бы именно его использовали, как провижионер, и текущие плейбуки и роли очень пригодятся.
В остальном статья очень подробная и полезная. Большая спасибо. Есть что почерпнуть для своей работы.
Спасибо на добром слове! Рад, что статья понравилась.

amarao
20.03.2022 17:16+8По совокупности критериев мы остановили выбор на VKCS
Фатальная ошибка. Почему? Потому что "single provider". У них проблема - у вас проблема, и быстро её не решить.
Как надо было? Слышали поговорку "cattle, not pets"? Её обычно говорят про виртуалки, но! На самом деле она в первую очередь относится к поставщикам.
Стандартизированные API, минимальный объём отличий, менять провайдеров как перчатки. Упал VKCS? Нагрузка плавно переползла на другого поставщика. Кто-то выкатил условия на 10% дешевле? 30% нагрузки уползло к нему. Без даунтаймов.
Т.е. выбор поставщиков должен начинаться не с заверений в изумрудном SLA, бриллиантовых инженеров саппорта и лазурных персональных менеджеров, а с простейшего тест-драйва API. Можно фигакнуть ансиблом/терраформом сетап или нет?
Если нет, то это ни чем не лучше, чем on-prem, кроме того, что теперь ещё меньше ручек для контроля происходящего.
UPD, если ещё не убедило. Сколько поставщиков электричества должно быть у Tier IV дата-центра? Один, с самым лучшим SLA на рынке? Или всё-таки больше?
realscorp Автор
20.03.2022 22:14Потому что "single provider". У них проблема - у вас проблема, и быстро её не ререшить.
В наших условиях, разделив тот же объем закупки ресурсов на разных провайдеров, мы бы получили существенно худшие условия контракта от каждого. Бизнес ежедневно платил бы больше ради весьма невысокой вероятности того, что все зоны доступности VKCS упадут.
Можно фигакнуть ансиблом/терраформом сетап или нет?
Конечно, почти все публичные облака имеют api и с ними можно работать яерез Терраформ. Но у всех своя специфика - сеть, работа с образами, ключами, свой Терраформ-провайдер со своими конструкциями. Можно писать под два облака, но у нас слишком маленькая для этого команда. Риски и неудобства работы только с одним облаком, конечно, есть, я согласен, но на данном этапе нашего развития и размера они не перевешивают выгоды того же решения.
Если нет, то это ни чем не лучше, чем on-prem, кроме того, что теперь ещё меньше ручек для контроля происходящего.
Меньше ручек - плохо тем, что меньше возможности их крутить. Но меньше ручек - это ещё и хорошо тем, что меньше необходимости их крутить. Решение зависит от условий задачи.
amarao
20.03.2022 22:21+4Короче, вы взяли свой on-prem, и сделали из него aas. Чужой aas. Тот же вендор-лок, но который могут рубануть просто в результате конфликта собственников или ещё какой-то внешней фигни.
Вы бы не получили существенно худшие условия в aas'ах порезав объём в 2-3 раза. А реализовав универсальный слой в IaC вы бы смогли в любой момент выворачивать руки сейлзам любого провайдера угрозой съехать.
После того, как вы на оный VKCS переехали с потрошками и завязались на их особенности реализации, теперь они вам могут выкручивать что угодно.
(На практике это означает, что они просто не будут снижать цены или будут индексировать их по курсу, и у вас не будет аргументов возразить).
realscorp Автор
21.03.2022 05:54Вы говорите разумные вещи и я в-целом с вами согласен. Если есть финансовая возможность делать мультиклауд - лучше делать. У нас такой возможности не было. Мы пока слишком маленькие.
amarao
21.03.2022 12:08+1А когда вы станете больше, у вас слишком много будет инвестировано в одного поставщика.
Становиться vendor agnostic надо пока это дёшево.
gecube
20.03.2022 22:41+2Но меньше ручек - это ещё и хорошо тем, что меньше необходимости их крутить
это не так. Это скорее необходимость обходить ограничения, связанные с невозможностью их крутить. Коллеги, которые заехали в яндекс, репортили, что там не хватает коннекшенов на один узел. Ну, вот так и сделано. Ответ ТП - заказывайте больше узлов (а, следовательно, и платите нам побольше денег)
Бизнес ежедневно платил бы больше ради весьма невысокой вероятности того, что все зоны доступности VKCS упадут.
т.е. VKCS (амазон, гугл и пр.) никогда целиком не валялся? Валялись и еще как. Но я соглашусь с тем, что реализация кросс-провайдера достаточно дорогая. Если Вы осознанно приняли эти риски - молодцы.
realscorp Автор
21.03.2022 06:08Это скорее необходимость обходить ограничения, связанные с невозможностью их крутить
Я про то, что теперь мы не можем менять коэффициент переподписки, выбирать модель процессора, рейд-контроллера, конфигурацию массива, создавать вланы, выбирать сетевое железо и пр., Но, с другой стороны, мы теперь и не обязаны этого делать, и это на практике пока что перевешивает недостатки.

scarab
21.03.2022 08:51+1Подождите, ну два десятка физических серверов и сотня виртуалок - это работа для одного админа. Ну двух-трёх, если ещё надо сопровождать продукты какие-то внутри этих виртуалок и обеспечивать подмены на время отпусков.
Зачем городить вот эту историю с терраформами и прочим всем? Это нужно для случаев в тысячи хостов. А Вашу инфраструктуру один нормальный админ за полгода причешет, замониторит, настроит бэкапы и потом бОльшую часть времени будет сидеть, пить кофе и читать хабр, как и положено админу.
realscorp Автор
21.03.2022 09:23Подождите, ну два десятка физических серверов и сотня виртуалок - это работа для одного админа. Ну двух-трёх, если ещё надо сопровождать продукты какие-то внутри этих виртуалок и обеспечивать подмены на время отпусков.
Один админ совершенно точно не справляется с сотней виртуалок при потребности в относительно частых изменениях. И уж тем более, если это on-prem на солянке из оборудования без полноценных vSphere, кластеров, СХД и пр.
Зачем городить вот эту историю с терраформами и прочим всем? Это нужно для случаев в тысячи хостов. А Вашу инфраструктуру один нормальный админ за полгода причешет, замониторит, настроит бэкапы и потом бОльшую часть времени будет сидеть, пить кофе и читать хабр, как и положено админу.
Нет, это так не работает :) Один, а ещё хуже, несколько админов, которые вручную всё конфигурируют - это путь в хаос и безумие. Невозможно постоянно обеспечивать высокое качество и стандартизацию конфигураций при работе вручную, даже если ты работаешь один. А в команде - тем более.
Даже в наших масштабах мы постоянно, ежедневно, непрерывно спотыкались на необходимость понять, чем и как думал человек, который до тебя настраивал эту ВМ и какого чёрта он напихал скрипты подключения одной NFS-шары в 5 (пять, Карл) разных мест Windows-инстанса. Я не могу здесь приводить другие реальные примеры, касающиеся, например, прода, но это действительно была ежедневная огромная боль.
И я знаю, как бы это стало выглядить, когда мы бы выросли в несколько раз. Я работал раньше во внутреннем it-аутсорсе большого холдинга и знаю, как выглядят несколько сотен серверов-снежинок. Это выглядит, как ад - всё постоянно горит, а десяток админов только тушат пожары и никак не могут потушить. Такого будущего не желаю ни одной компании, и тем более, той, в которой я работаю :)

Sergey-S-Kovalev
21.03.2022 10:34+1Я работал раньше во внутреннем it-аутсорсе большого холдинга и знаю, как выглядят несколько сотен серверов-снежинок. Это выглядит, как ад - всё постоянно горит, а десяток админов только тушат пожары и никак не могут потушить.
Пять+ сотен серверов-снежинок. И не десяток, а шесть админов, которые подменяли техсуппортов, если последних не хватало по причине отпуска или болезни.
Невозможно потушить пожар, если ты работаешь в кратере действующего вулкана. ^_^
realscorp Автор
21.03.2022 10:46Невозможно потушить пожар, если ты работаешь в кратере действующего вулкана
Могу только ещё раз поздравить тебя с тем, что своё кольцо Саурона ты в этот кратер наконец выкинул :)
scarab
21.03.2022 12:58Ну, Вы решили свою проблему и поделились интересным опытом, за что Вам большое спасибо.
если это on-prem на солянке из оборудования без полноценных vSphere, кластеров, СХД и пр
Вот в том-то и дело, что описанное Вами состояние инфраструктуры выглядит как манифест чьей-то некомпетентности. Видимо, руководство когда-то решило сэкономить на руководителе IT. Про 5 скриптов NFS-шары - очень хорошо ложится в этот же пазл.
Именно потому что нормальный админ даже этот бардак бы причесал и привёл к общему знаменателю. При этом совсем необязательно тратить мегабаксы на VMware и стораджи от EMC, в бюджетных условиях вполне нормально можно собирать кластеры на бесплатном Proxmox и СХД на самосборных серверах имени Supermicro.
Я работал раньше во внутреннем it-аутсорсе большого холдинга и знаю, как выглядят несколько сотен серверов-снежинок
Подозреваю, что именно в этом дело. Аутсорс, даже внутренний - он всё равно работает по тушению пожаров, тогда как для админа в штате этот процесс, по-хорошему, занимает не больше 5% рабочего времени; ещё где-то около 20% - текущие задачи (создать виртуалку, дать доступ и т. п.), а всё остальное рабочее время админа должно уходить как раз на превентивные меры - мониторинги, автоматизации, документирование, написание скриптов. Тогда количество пожаров очень быстро сойдёт на нет.
За 25 лет админства, руководства админами, IT-аудитов и прочего я тоже много разного насмотрелся. И да, филиал ада легко можно устроить не то, что с парой десятков, а и с тремя-четырьмя серверами. Но если процессы выстроены грамотно - то один человек легко может управляться с весьма большими инфраструктурами без всяких пожаров.
realscorp Автор
21.03.2022 13:46Ну, я думаю, мы с вами всё равно каждый при своём мнении останемся :) Исходя из моего опыта и того, что я знаю о чужом опыте - это так не работает и не может работать. Но, видимо, в каких-то условиях возможно.
scarab
21.03.2022 17:37Да я не спорю. Ваше мнение и опыт весьма интересны, хотя бы уже тем, что они отвечают нынешнему состоянию рынка и такие вещи надо уметь. Большое спасибо за пост.
видимо, в каких-то условиях возможно
Из моего опыта (просто в копилку):
Небольшой хостинг с доп. услугами: пара десятков физических серверов в двух датацентрах, около 400 виртуалок, из них около 30 обеспечивающих собственную инфраструктуру (всякая там IP-телефония, роутеры), около 300 VPN-линков, OSPF и BGP в комплекте и прочее - спокойно обслуживается одним человеком (но без поддержки юзеров).
Инфраструктура среднего банка - 70 физических нод, около 200 виртуалок (далеко не всё было виртуализовано), 100+ филиалов со всякими VPN и телефонией, AD+Exchange на 2000 юзеров - обслуживалось командой в 8 админов (но это уже с делением на сетевиков, виндузятников, юниксоидов, Oracle DBA, MSSQL DBA). Более того, эта инфраструктура бесшовно смигрировала как раз из состояния "целый сугроб снежинок".
Ну то есть оно не требует сверхчеловеков каких-то.
amarao
21.03.2022 12:10+2Основная причина, в которой iac нужен, вовсе не экономия сил админов на саппорте, а повышение качества. Чем больше инфры проходит через ci/cd, тем предсказуемее продакшен и тем быстрее и смелее можно что-то менять.
У iac тоже должен быть стейджинг, а его не может быть без автоматизации провиза.
scarab
21.03.2022 13:05А для какого класса/размера инфраструктур это начинает иметь значение?
Ну, условно, есть инфраструктура средних размеров банка. Сервера виндовой инфраструктуры (AD, Exchange); боевые и тестовые сервера БД, всякие там сервера приложений, телефонии, чёрт знает чего ещё. Скажем, полтыщи разноплановых виртуалок.
Новые - разворачиваются нечасто, только при внедрениях и развитиях новых продуктов и там чаще всего потребные мощности заранее известны. И даже если под некий продукт разворачивается десяток виртуалок в тестовый контур - то потом развернуть аналогичные в боевой вопрос максимум пары часов.
Вот серьёзно, какой класс сервиса может потребовать стэйджинг инфраструктуры, если её планировать заранее и с умом?
gecube
21.03.2022 13:50Вот серьёзно, какой класс сервиса может потребовать стэйджинг инфраструктуры, если её планировать заранее и с умом?
любой. На почтовики тоже накатываете обновления не глядя? Один раз я чуть актив дайректори не положил неудачным обновлением.
Возможно, если б у ребят был стейджинг, то не было отказов вроде https://blog.cloudflare.com/october-2021-facebook-outage/ https://blog.cloudflare.com/how-verizon-and-a-bgp-optimizer-knocked-large-parts-of-the-internet-offline-today/
Shit happens, но наличие песочницы позволяет снизить требования к персоналу и снизить вероятность ошибки. С другой стороны, да, можно на каждый чих писать план отката и нанимать суперпрофи, которые умеют чуть ли не в ручном режиме производить закат солнца. Но в реальности - это всегда баланс. Да, и денег никто вам не вернет в случае сбоя...
scarab
21.03.2022 15:04Вендозная инфраструктура стейджингу поддаётся с большим трудом. Я тоже знаю случаи, когда обновлениями клали AD DNS, клали Exchange. В лично моём портфеле достижений такого нет, но у знакомых бывало.
При этом даже иметь рядом копию AD и Exchange особо не помогает, потому что если что-то где-то и спотыкается - то на какой-то неявной и нереплицируемой вещи типа особо хитрой комбинации настроек отдельного ящика.
В общем, откатить всю AD назад при неудачном апдейте раз в несколько лет обычно дешевле, чем постоянные расходы на поддержание синхронизации.да, можно на каждый чих писать план отката и нанимать суперпрофи, которые умеют чуть ли не в ручном режиме производить закат солнца
Это сейчас считается суперпрофи? Я понял, пойду обратно в заморозку ещё лет на двести :)
Тогда да, проще тратить в три раза больше времени на стейджинги и прочее.
amarao
21.03.2022 14:31+2Я обычно делаю стейджинг на второй итерации. Первая - exploratory, пощупать как оно там "вообще". Дальше идёт стейджинг (ephimerial, когда он создаётся/удаляется на каждый прогон), когда на стейджинге работает, то продакшнен становится "как стейджинг, только не ephimerial".
Потом там начинается сегрегация "этот стейджинг люди трогают и его не надо ребилдить, а этот поднимается на каждый коммит в гит, а этот используют workflow для релиза приложений" и т.д.
Я совершенно не понимаю как это можно всё сделать с виндами (кто может развернуть ephimerial active directory, exchange и проверить, что почта ходит, а секретерша не может забанить гендира?), но в мире серверного софта такой подход оказывается
а) примерно в три раза медленее от mvp до продакшена (по сравнению с "настроили руками")б) оказывается единственным, который позволяет уверенно коммитить изменения и применять их роботом по merge request'у.
в) кратно экономит время во время новых изменений.
Ах, да, польза от всех этих стейджингов оказывается в несколько раз выше, если после накатывания конфигурации её тестировать.
gecube
21.03.2022 15:13а) примерно в три раза медленее от mvp до продакшена (по сравнению с "настроили руками")
ну, это приемлемо. Главное, что если делать руками - то потом опять делаешь руками, но старое сжигаешь ))) потому что разобраться в старом попросту, ну, нет никакой возможности. Аудит провести? Анрил. А если хочется, чтобы был порядок - приходится так или иначе приходить к IaC, а там все эти чудесные процессы со стейджингами, проверками и всем прочим.

osipov_dv
21.03.2022 08:58+1всегда удивляюсь, когда сравниают on prem с облаком без учёта переподписки...
А уж диагностировать, в опеделенные моменты прошлого, производительность paas вообще нереально. Вот и думай, почему висел тот или иной важный сервис.
realscorp Автор
21.03.2022 09:28Ну, мы сравнивали с учётом переподписки. Это было отдельной строкой в рабочей таблице и предполагаемые к закупке on-prem кластера считали именно с переподпиской, сравнивая с чистыми vCPU в облаке. Плюс VKCS обещает 100% времени HT-ядра. Не знаю, насколько это правда, но по тестам производительности всё было достаточно стабильно и нас в итоге устроило.
osipov_dv
21.03.2022 10:12+1чистые vcpu в облаке, так не бывает? то что работает сейчас именно так, не гарантирует что не изменится завтра или через месяц. А средств объективного контроля - 0, разве что стилы в top. И это не касается частного случая с VKCS, это общая облачная практика. Плюс DRM может менять ситуацию.
realscorp Автор
21.03.2022 10:45Согласен, средств объективного контроля нет. Можно замерять производительность и выкатывать претензии, если она не совпадает с SLA, но это сложно, и в продакшне - тем более.
amarao
21.03.2022 12:12Если вам обещают HT в multi-tenant cloud, то вы полностью в небезопасности. SMT (HT) не возможно защитить от side channel spectre, так что если у ваших данных хоть какая-то ценность, то вы вполне можете получить копию ваших данных у посторонних людей.
onyxmaster
Лучшая по полезности статья, прочитанная мною за последнее время. Спасибо, Сергей!