
Стоит оговорить, что не все современные пользователи перешли на «онлайновую» жизнь. Ввиду технических и музыкальных особенностей немалая часть продвинутых пользователей до сих пор пользуются программами для прослушивания музыкальных файлов, а некоторые и вовсе предпочитают «аналог», презирая цифровой звук. Большинство пользователей проигрывателя Winamp в разгар его популярности не вникали в тонкости функционала программы. В основном игрались со скинами и визуализацией. Некоторые из опытных пользователей экспериментировали с настройкой плагинов вывода звука для достижения лучшего звучания. А были те пользователи, которые использовали функцию медиабиблиотеки Winamp. Лично я использовал только часть данной функции, а именно – историю воспроизведения.
Функция истории воспроизведения Winamp довольно удобная. В отдельном окне программы отображается таблица со списком ранее открытых медиафайлов. В записях содержится информация о названии прослушанной композиции, её длительности, количества прослушиваний и дате-времени последнего прослушивания. Также есть поле текстового ввода для быстрого поиска, и есть возможность сортировки по любому параметру.

Рис. 1. Окно Winamp с историей воспроизведения.
Со временем, накопив историю до нескольких сотен записей, у меня возник интерес с точки зрения информатики получить непосредственный доступ к данной таблице для дальнейших желаемых действий по её хранению и обработке. Будучи школьником, я не умел творить подобные чудеса. Максимум, что я сумел сделать – отыскать то место, где хранится данная информация. Как выяснилось, за хранение истории воспроизведения отвечают два файла – «recent.idx» и «recent.dat», находящиеся по адресу «C:\Program Files\Winamp\Plugins\ml». В отдельных случаях, в зависимости от версии программы и ОС, эти файлы могут лежать в каталоге пользователя. Если открыть файлы с помощью «Блокнота», то в первом случае отобразится мусор, а во втором – среди мусора ещё можно различить читаемый текст, представляющий собой названия прослушанных композиций. Но это не то, что я тогда ожидал. Я надеялся, что история воспроизведения хранится в открытом текстовом виде, как я её вижу в проигрывателе. Тем не менее, я не терял надежду, что когда-нибудь в будущем я найду софт для редактирования этих файлов, и я заботился о том, чтобы не терять их.
По прошествии многих лет я так и не нашёл нужный мне софт (что и неудивительно), а интерес к данной задаче возрос ещё сильнее. Учитывая «эволюцию» в области моей компьютерной техники, у меня накопилось несколько архивов историй воспроизведения с большим числом записей. Последнее время мне стало интересно вспоминать, какие песни я слушал раньше. В связи с тем, что я переслушал огромное количество разнообразной музыки, многие хорошие песни могли быть утрачены в моей памяти. Кроме того, большинство файлов истории воспроизведения перестали проигрываться непосредственно из истории, так как изменились каталоги на моих накопителях.
В данной статье будет показано, как устроены файлы истории воспроизведения, а также будет приведён текст простой программы на Си для извлечения информации из этих файлов в текстовый файл для дальнейшей обработки в Excel. Также я расскажу, какие подходы я использовал для изучения и разгадки структуры этих файлов.
Изучив структуру файлов истории, можно было написать собственный редактор с оконным интерфейсом и всеми необходимыми мне функциями, но задачу я ставлю иную. Главное для меня, как и всегда в таких случаях – минимум программирования. Чем короче и проще программа, тем лучше. В качестве интерфейса для обработки подобной информации я привык пользоваться Экселем. Более того, я решил производить окончательную обработку там же, с помощью формул. Стоит отметить, что можно было и вовсе не прибегать к программированию на Си, а полностью сделать всё в Excel, написав скрипт VBA. Но я предпочёл тот набор инструментов, с которым я привык работать на протяжении большого времени.
Изучение структуры файлов истории воспроизведения Winamp я начал с их открытия и предварительного анализа в HEX-редакторе. Для примера я взял историю воспроизведения за последние 4 года, в которой содержится 2562 записи. Сначала открыл файл «recent.idx», несмотря на то, что он вспомогательный. Это я выяснил ещё ранее. Тем более, по разнице в их размерах и по расширениям «dat» и «idx» это можно понять интуитивно. Первые 8 байт файла «recent.idx» – заголовок с текстом «NDEINDEX». Видимо, там содержится список индексов. Я уже сталкивался с похожими вещами, о чём я писал в ранних своих статьях. После заголовка, а точнее, со смещения 16 начинается интересная последовательность 32-битных чисел, байты которых записаны справа налево (little endian). Опытным глазом заметно, что эти числа поделены на две группы разного рода информации. Числа с нечётными номерами в последовательности неравномерно возрастают, а с чётными – на первый взгляд случайны. Ещё я заметил, что по смещению 8 записано 32-битное число – количество записей в истории. Но оно почему-то на 2 больше (а именно, 0x0A04 (2564)), чем реально отображающееся значение в истории (2562, как видно на рис. 1). Всё вышесказанное изображено на рис. 2. После заголовка (основное выделение) голубой заливкой выделены 4 байта значения количества записей в истории. Потом – число 255 (0xFF) – пока непонятно для чего, оно закрашено серым цветом. Далее идут те самые последовательности чисел с чередованием. В красную рамку выделены числа из первой группы, а в зелёную – из второй. Первые четыре числа (два красных и два зелёных) закрашены в серый цвет. Забегая вперёд, напишу сразу, почему. Каждая пара чисел (одно красное и одно зелёное) соответствует одной записи в истории, но, начиная со смещения 32, как это выяснилось позже. А первые две пары чисел (начиная со смещения 16) оказались фиктивными (то есть стартовыми), не имеющие отношение к записям истории. Их я и закрасил серой заливкой. Но они всё равно соответствуют записям, пусть даже и условным. Вот поэтому значение количества записей в истории после заголовка на 2 единицы больше. Там учтены как раз эти самые две фиктивные записи.

Рис. 2. Вид файла «recent.idx» в HEX-редакторе.
Мне сразу захотелось посмотреть данные последовательности чисел в виде графиков. Не прибегая к использованию Matlab и прочих серьёзных инструментов, я открыл исследуемый файл «recent.idx» в звуковом редакторе «Adobe Audition», как RAW PCM-данные 32 бит стерео. Данный редактор не имеет никакого отношения к музыке, хранящейся в истории воспроизведения. Он используется для графической визуализации чисел из файла. Этим приёмом я пользуюсь не так уж и редко.
Рис. 3. Параметры чтения файла редактором Adobe Audition.
Частоту дискретизации можно указать любую, ибо она влияет только на скорость воспроизведения. Разумеется, воспроизводить эти незвуковые данные я не собираюсь. Сразу поясню, в чём смысл такого действия. Как я написал выше, файл содержит 32-битные числа (беззнаковые, скорее всего). Точнее, две последовательности, числа которых чередуются по очереди. По такому же принципу, как известно, записываются значения семплов стерео аудиоданных PCM. Поэтому, если подсунуть аудиоредактору мой файл (хоть он даже не звуковой), то аудиоредактор на волновом виде отобразит мои последовательности чисел в виде двух графиков, как отображается звуковой файл стерео.
После открытия файла я увидел вот такую картину.

Рис. 4. Графический вид файла индексов «recent.idx» в Adobe Audition.
Я сразу обратил внимание на «перелом» информации ровно посередине. Но так как до середины файла в HEX-редакторе я пока ещё не дошёл, я более детально рассмотрел графики только первой половины. С первой последовательностью (в «левом канале») всё понятно. Как и было сказано, она монотонно возрастает, на глаз практически равномерно. А вот график второй последовательности (в «правом канале») скрывается из-за малых значений чисел по сравнению со значениями из предыдущей последовательности. Пришлось увеличить масштаб.

Рис. 5. Вид с увеличенным масштабом по вертикали.
На экране представился график интересной формы, который я не сразу понял. Масштаб чисел из данной последовательности сравним с количеством записей в истории. Ещё сразу стало понятно, судя по графику, что данная вторая последовательность (с маленькими числами) на первой половине файла по своему роду сравнима с первой последовательностью на второй половине файла. Их формы графиков похожи, они будто бы «вверх ногами» друг относительно друга. Кроме того, первая последовательность (с большими числами) на первой половине файла по своему роду сравнима со второй последовательностью на второй половине файла. Вот только в первом случае, как я уже сказал, числа возрастают, а во втором случае те же числа будто перемешаны, а форма их графика немного напоминает форму графика, расположенного над ним.
Получив из графиков предварительные сведения, я отследил в HEX-редакторе содержимое файла «recent.idx» на его середине.

Рис. 6. Содержимое файла «recent.idx» на его середине.
Делая предварительные выводы о равенстве количества пар чисел до и после середины, и пролистав файл до конца, я отсеял лишнее число, равное нулю (выделено на рисунке). Именно из-за него каналы во второй половине файла при визуализации графиков поменялись местами. У данного числа нет пары. Затем следуют пары чисел по аналогии с предыдущей последовательностью. Но их порядок уже другой, и никакой закономерности не наблюдается. Выделены они уже другими цветами: розовым и тёмно-зелёным. Количество таких пар равняется количеству пар из первой половины. Как я посчитал, это количество равно значению числа, стоящего после заголовка (число реальных записей истории + 2).
Итак, пока что мне представилась такая картина в отношении файла «recent.idx». Ввиду того, что этот файл не играет ключевой роли в моей задаче, но играет роль вспомогательную, я не буду строго излагать его структуру какой-либо таблицей, напишу простыми словами. Файл начинается с заголовка «NDEINDEX», затем до самого конца файла идут 32-битные числа. Первое число – количество записей в истории, второе число – 255, затем – пары чисел. Число пар совпадает с количеством записей в истории, указанным первым числом после заголовка. По факту же оно на 2 единицы больше реального количества записей в истории. После числовых пар записано число 0, затем – снова пары чисел, но уже другие. Их количество аналогичное. Итого размер файла в байтах можно вычислить так: 8+4*(1+1+2*(n+2)+1+2*(n+2)) = 8+4*(3+4*(n+2)) = 20+16*(n+2) = 52+16*n, где n – число реальных записей в истории воспроизведения.
Чтобы понять, какую информацию несёт каждая из получившихся четырёх семейств последовательностей чисел, мне пришлось импортировать все числа файла «recent.idx» в Excel. Для этого я составил короткую вспомогательную программу. Затем, уже в Excel, я разбил исходный массив чисел (столбец C) с помощью специальных формул на 4 массива по вышесказанным правилам (столбцы D-G). Столбец A представляет собой порядковые номера исходной и получившихся последовательностей, начиная с нуля. Столбец B – шестнадцатеричные аналоги исходной последовательности. Также представлены цветные графики полученных последовательностей в представлении «два по два».

Рис. 7. Анализ чисел файла «recent.idx» в Excel.
Они в точности похожи на графики, которые были сформированы нестандартным способом с помощью Adobe Audition. Графики имеют такие же цвета, какими я выделял в HEX-редакторе соответствующие им числа последовательностей. Таким образом, к примеру, зелёный график соответствует числовой последовательности из чётных чисел первой половины файла. За ним расположен тёмно-зелёный график, соответствующий последовательности из чётных чисел второй половины файла. Аналогично ниже – вторая пара графиков (красный и розовый) для последовательностей с большими числами. Как я предположил, различие внутри каждой пары таких однородных последовательностей заключается в определённой перестановке чисел. Причём перестановки чисел для каждого столбца разные. Речь идёт про пары последовательностей столбцов [D;F] и [E;G]. А в самом начале описания речь шла про пары чисел, которые приходятся на столбцы [D;E] (первая половина файла) и [F;G] (вторая половина файла).
С помощью функции сортировки в Excel мне удалось выяснить, что обозначают зелёные и тёмно-зелёные числа. Создав копию значений на отдельном листе, я отсортировал столбец E по возрастанию, подтягивая за собой соседний столбец D и столбец порядковых номеров A. После этого я сразу заметил следующее. Порядок чисел столбца D стал таким же, как и в F, а порядок чисел столбца A стал таким же, как и в G. Проще говоря, зелёные числа показывают, по каким позициям в розовом столбце расположены соответствующие числа из красного столбца. И наоборот, как я выяснил и проверил позже, тёмно-зелёные числа показывают, по каким позициям в красном столбце расположены соответствующие числа из розового столбца. Например, числу №15 (A=15) в ячейке D17 = 3010 соответствует число из соседней ячейки E17 = 7. Это значит, что под номером 7 в столбце F находится число 3010 (ячейка F9). Ему соответствует число из соседней ячейки G9 = 15. Это означает, что число 3010 в столбце D находится под номером 15. На данном этапе, не зная сущности чисел из красного и розового столбцов, я пока не понял сущность и правило перестановки. Поэтому я отложил изучение структуры файла «recent.idx» и перешёл к файлу «recent.dat».

Рис. 8. Вид файла «recent.dat» в HEX-редакторе.
У данного файла также есть заголовок, содержимое которого не зависит от количества записей в истории. На рисунке он выделен в синюю рамку. Он начинается со слова «NDETABLE». Также там можно заметить знакомые английские слова – названия полей таблицы истории воспроизведения. В другие детали заголовка я особо не вникал, в этом нет необходимости. Я разгадал значения некоторых байтов, но писать об этом особого смысла я не вижу. После заголовка следуют блоки информации о записях истории, где по очереди перечисляются значения каждого поля. В глаза сразу бросаются тексты названий и пути файлов из истории, они представлены в кодировке ucs-2le. Размер каждого блока разный в зависимости от длины этих текстовых полей. Сначала я попытался найти границы между блоков, улавливая некую периодичность ключевых байтов. Потом я вернулся к файлу «recent.idx», а точнее, к числам из красного столбца. Как я заметил, эти числа оказались адресами в файле «recent.dat» начал записей истории, то есть ссылками. А о сущности перестановки я узнал в самый последний момент всего этого проекта, о чём напишу в конце этой статьи. На рисунке 8 позиции начал каждого блока отмечены квадратной красной скобочкой. Первые две отметки попали в заголовочный блок, выделенный в синюю рамку. Это те самые две фиктивные ссылки, которые не ссылаются на реальные записи истории. А вот, начиная с третьей ссылки, всё сходится, и все предположения подтверждаются. На рисунок попал полностью первый блок (блок первой записи истории) и часть второго блока.
Рассмотрим структуру блока более подробно. В нём содержится непосредственная (значения полей) и вспомогательная информация. Те байты, которые относятся к непосредственной информации, я разгадал гораздо быстрее, но у меня был интерес полностью изучить структуру блока. И это несмотря на то, что я уже на данном этапе мог приступить к написанию программы извлечения данных в текстовый файл. При этом можно было даже обойтись без файла «recent.idx». Но с этим файлом программа упрощается. Ещё проще и понятнее текст программы становится, если пользоваться вспомогательной информацией внутри блоков. На этапе изучения я замечал некие несостыковки, но потом всё-таки понял фишку, и всё стало на свои места. Приведу сразу описание структуры блока. Как уже я писал, блок состоит из описания полей таблицы истории, идущие вплотную друг за другом. Всего имеется 5 полей. Ниже приведена таблица общей структуры полей с указанием размера в байтах каждого подполя (сложно определиться с терминологией).

Рис. 9. Общая структура поля блока записи истории.
Таким образом, ряд из 5 полей представляет собой так называемый двунаправленный связный список из 5 элементов. В собственных полях элементов содержатся адреса, то есть указатели на предыдущий и следующий элемент. Учитывая, что размер содержимого поля может быть разный (var) в зависимости от типа поля, приведу описание каждого из 5 полей по отдельности.
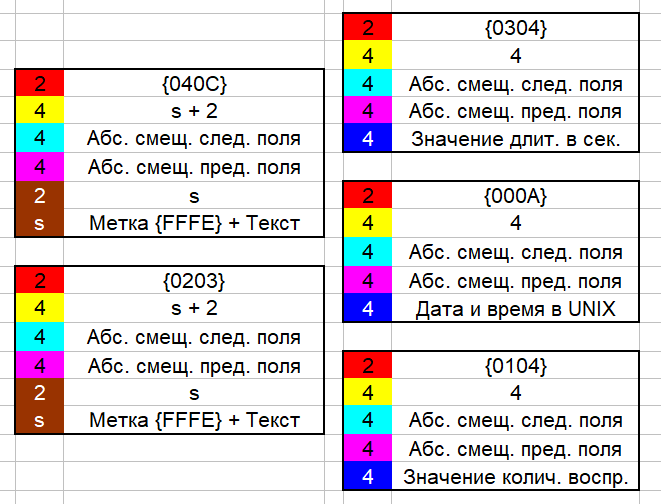
Рис. 10. Структуры каждого поля блока записи истории.
Здесь нужно дать небольшой комментарий по структуре каждого поля. Размеры трёх полей (длительность, дата-время и количество воспроизведения) статичны, заранее предопределены и равны 18 байтам. А вот размеры текстовых полей (пути и названия) зависят от длины соответствующих текстовых данных. И так, сначала идут два байта кода поля, затем – 32-битное число – условный размер содержимого поля. Только сейчас понял, что это в чистом виде размер содержимого поля в байтах. Для текстовых полей это значение на 2 больше длины текста (s), а для остальных полей – 4. Затем идут два 32-битных числа – абсолютные смещения (то есть, от начала файла) следующего и предыдущего полей. Затем – содержимое поля. Для текстовых полей содержимое представляет собой текст, который предваряется 16-битным числом – размером текста (s). Вот почему для текстовых полей размер содержимого поля указывается на 2 больше размера текста. Потому что в содержимое поля входит не только текст, но и размер текста. Вот такая вложенная структура, почему-то разработчики решили так усложнить. Более того, текст представлен в кодировке ucs-2le. В него входит метка из двух байтов «FFFE», являющаяся меткой указания на данную кодировку. С остальными полями всё проще. Содержимое этих полей имеет фиксированный размер в 4 байта. Значение длительности композиции – в секундах – целое 32-битное число. Аналогично – количество воспроизведения. А вот дата и время последнего воспроизведения представлена в формате UNIX. С этим форматом я уже сталкивался в одной из ранних своих статей. Поля полей раскрашены в различные цвета для того, чтобы уловить соответствия с дальнейшими иллюстрациями. Есть ещё один интересный момент. Когда я анализировал файл истории от ранней версии Winamp, я столкнулся с некими различиями в представлении двух текстовых полей (название медиа и имя файла) по сравнению с описываемым случаем. Во-первых, код поля имени файла (с адресом) не {04 0C}, а {04 03} (0x0304). Во-вторых, текстовое содержимое обеих полей представлено не в ucs-2le, а в обычной ASCII. То есть, по одному байту на символ. Действительно, как я помню, старые версии Winamp не умели правильно записывать в историю прослушанные песни с названиями, например, на греческом языке. Вместо нужных символов в названии песни в истории отображались знаки вопроса.
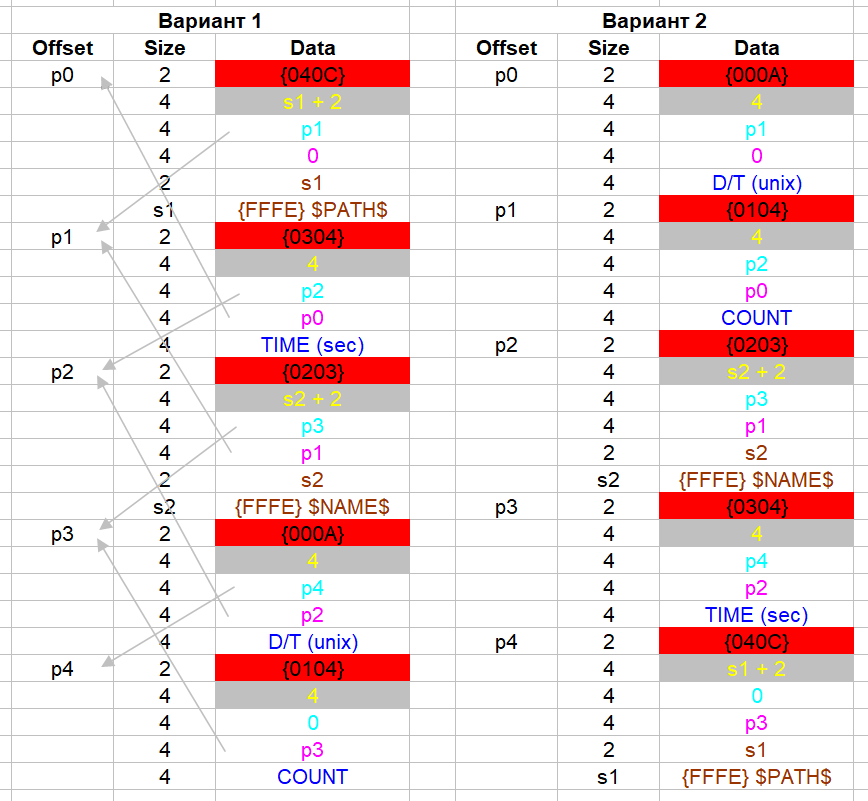
Рис. 11. Схемы чередования полей в двух вариантах.
Указательные стрелочки связного списка я нарисовал только для первого варианта. А в целом, как я думаю, данная схема в лишних комментариях не нуждается. Указатель на предыдущее поле в первом поле равен нулю, как и указатель на следующее поле последнего поля. Первый блок записи истории, что виден на рисунке 8, подпадает под второй вариант чередования. Рассмотрим этот блок в HEX-редакторе более подробно.
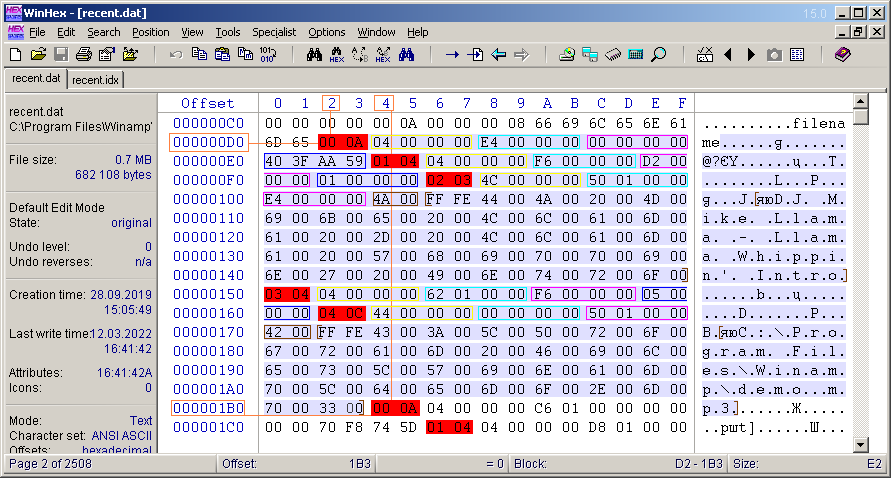
Рис. 12. Вид блока записи истории в HEX-редакторе.
Сам блок выделен заливкой основного выделения редактора. Байты этого блока дополнительно выделены различными цветами в соответствии со схемами и описаниями выше. Ярче всего (красной заливкой) выделены байты кодов полей. Два последних выделения относятся уже к блоку следующей записи истории. Кстати, оранжевым цветом я показал адреса начал первого и второго блока, что содержатся в файле «recent.idx». В Excel-интерпретации этого файла (рис. 7) это числа в ячейках B6 и B8 (0xD2 и 0x1B04), то есть первые два числа из красного столбца (не считая первых двух фиктивных чисел). После байтов, выделенных красной заливкой, следуют 4 байта, выделенных в жёлтую рамку. Это размер содержимого полей. И так далее, рассуждения вполне понятны. Единственный момент – я не стал выделять тексты в рамку, а отметил лишь начало и конец текстов квадратными скобочками. Также видно, что первые два байта текста – метка «FFFE».
Пришло время приступить к написанию программы. Напомню, что я делаю уклон на её простоту, при этом подразумеваю, что окончательную обработку полученного результата я буду делать в Excel. Как и раньше, программу писал на языке Си в «Dev-Cpp» с применением некоторых функций WinAPI. Формат выходного файла – текстовый. Обычно, при формировании такого файла я пользуюсь привычной функцией fprintf(), в нашем случае текст в файле будет иметь кодировку ucs-2le. Поэтому я решил формировать выходной файл с помощью функции WriteFile(), как много раз уже делал ранее при формировании нетекстовых файлов. Выходной файл должен содержать таблицу, поля которой отделены символами табуляции, а строки – символами переводов. При обычном копировании и вставке такого текстового содержимого в Excel вставка и заполнение таблицы происходит корректно без дополнительных манипуляций. Всего столбцов должно быть 6 в следующем порядке: имя файла (с адресом), название медиа, дата и время, количество воспроизведения, длительность, индекс. Все поля, кроме последнего, соответствуют непосредственной информации из истории. А последнее поле с названием «Индекс» – это столбец с теми самыми непонятными числами, взятыми из файла «recent.idx», которые выше представлялись зелёным цветом, и которые ставятся в соответствие адресам записей блоков (красным числам). Это я сделал для того, чтобы по возможности исследовать и понять их назначение. Полное имя файла и название будут представлены в выходном файле в точности, как они записаны в исходном файле истории, но без метки «FFFE». Данная метка будет поставлена один раз в самом начале выходного файла. Дата и время будут записаны в виде оригинальных 4-х байтов UNIX формата даты-времени, но в их текстовом представлении, то есть, как 8-значное HEX число. Это я сделал для того, чтобы не усложнять программу, тем более я ни разу не сталкивался с функциями преобразования даты-времени. А вот в Excel эти функции мной давно хорошо изучены, и они отлично работают. Также будет предварительно задействована функция Excel «ШЕСТН.В.ДЕС()» для конвертации из HEX в DEC формат целого числа. Я сознательно вывожу в выходной файл значение UNIX даты-времени именно в виде 8-значного HEX числа, так как вывод больших 32-битных чисел в обычном десятичном виде функцией printf() работает некорректно. Да и смысла в данном случае в этом нет. А вот оставшиеся три поля, значения которых являются 32-битными числами, будут выводиться в выходной файл в десятичном виде, так как они не огромные и выводятся корректно. Это количество воспроизведения, длительность в секундах и индекс. К примеру, первая строка выходного файла будет выглядеть так: «C:\Program Files\Winamp\demo.mp3\tDJ Mike Llama — Llama Whippin' Intro\t59AA3F40\t1\t5\t2». Вместо «\t» будут символы табуляции, то есть небольшой отступ.
Полный код с подробными комментариями (по возможности) представлен ниже под спойлером. Написание и отладка заняла буквально пару часов. Столкнулся только с одной неожиданной проблемой. Я обычно привык, что при выполнении функции ReadFile() файловый курсор продвигается автоматически на количество прочитанных байтов. Так оно и происходит, когда я читаю 1, 2 или 4 байта. А вот при выполнении этой же функции на чтении текстового содержимого в буфер (чтение нескольких десятков байт) файловый курсор почему-то не продвигался. Поэтому, как будет видно далее, при переходе от поля к полю я пользовался той самой вспомогательной информацией, а именно, указателем на следующее поле, выставляя по нему файловый курсор. Также, равенство указателя нулю – это признак завершения чтения текущего блока и перехода на новый блок. Это на случай, если заранее неизвестно, сколько содержится полей в каждой записи истории. Я пока столкнулся с пятью полями, но мало ли что может быть? Остальные интересные моменты описаны в комментариях кода.
#include <stdio.h>
#include <windows.h>
#include <string.h>
DWORD wr;
DWORD ww;
HANDLE openInputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_READ, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
void filepos(HANDLE f, unsigned long int p){
SetFilePointer (f, p, NULL, FILE_BEGIN);
}
unsigned long int read32(HANDLE f){
unsigned long int b0;
ReadFile(f, &b0, 4, &wr, NULL);
return b0;
}
unsigned short int read16(HANDLE f){
unsigned short int b0;
ReadFile(f, &b0, 2, &wr, NULL);
return b0;
}
unsigned char read8(HANDLE f){
unsigned char b0;
ReadFile(f, &b0, 1, &wr, NULL);
return b0;
}
void write8(HANDLE f, unsigned char b0){
WriteFile(f, &b0, 1, &ww, NULL);
}
//Для записи символа ASCII в кодировке UCS-2LE;
void write08(HANDLE f, char b0){
char b1=0;
WriteFile(f, &b0, 1, &ww, NULL);
WriteFile(f, &b1, 1, &ww, NULL);
}
int main(){
HANDLE idx; //Входной файл с адресами;
HANDLE dat; //Входной файл с данными истории;
HANDLE out; //Выходной текстовый файл в кодировке UCS-2LE;
unsigned long int N; //Количество записей в истории;
unsigned long int k; //Счётчик для цикла;
unsigned long int p; //Адрес, считанный из idx;
unsigned long int index; //Число, которое сопоставляется адресу в idx;
unsigned short int hdr; //Код поля в блоке записи истории;
char folder[1024]; //Строка UCS-2LE с именем файла медиа, включая путь;
char name[1024]; //Строка UCS-2LE с названием медиа;
char str[32]; //Строка ASCII со значениями остальных полей;
unsigned long int sz; //Размер содержимого поля;
unsigned long int ppr; //Смещение предыдущего поля;
unsigned long int pnx; //Смещение следующего поля;
unsigned long int dt; //Значение поля "Дата и время";
unsigned long int cnt; //Значение поля "Количество воспроизведения";
unsigned long int len; //Значение поля "Длительность";
unsigned short int i; //Счётчик для цикла;
unsigned short int ssz1; //Длина текста с именем файла медиа;
unsigned short int ssz2; //Длина текста с названием медиа;
idx=openInputFile("recent.idx"); //Открытие файла с адресами;
dat=openInputFile("recent.dat"); //Открытие файла с данными;
out=openOutputFile("out.txt"); //Открытие выходного файла;
filepos(idx,8); //Пропуск заголовка (хотя, можно было и проконтролировать);
N=read32(idx)-2; //Чтение количества записей истории (без двух фиктивных);
printf("N = %i (%08X)\n",N,N); //Вывод на экран для контроля;
system("PAUSE"); //Ожидание подтверждения пользователя;
filepos(idx,32); //Позиционирование на начало списка адресов;
write8(out,0xFF); //Запись в выходной файл метки кодировки UCS-2LE;
write8(out,0xFE); //Запись в выходной файл метки кодировки UCS-2LE;
for(k=0;k<N;k++){ //Цикл по числу записей в истории;
p=read32(idx); //Чтение адреса (первого числа);
index=read32(idx); //Чтение второго числа (для дальнейшего понимания его сути);
printf("%08X\t%08X\t",p,index); //Вывод этих чисел на экран для красоты;
filepos(dat,p); //Позиционирование в файле данных по считанному адресу;
do{ //Обработка блока, как связного списка;
hdr=read16(dat);
printf("0x%04X ",hdr); //Вывод кода поля на экран для красоты;
switch(hdr){ //Анализ поля по коду;
case 0x0A00: //Дата и время посл. воспр.;
sz=read32(dat); //Считывание размера содержимого блока (хотя он и не нужен);
pnx=read32(dat); //Считывание указателя на след. поле;
ppr=read32(dat); //Считывание указателя на пред. поле (хотя он и не нужен);
dt=read32(dat); //Считывание значения даты и времени;
break;
case 0x0401: //Количество воспр.;
sz=read32(dat);
pnx=read32(dat);
ppr=read32(dat);
cnt=read32(dat);
break;
case 0x0C04: //Адрес (путь);
sz=read32(dat);
pnx=read32(dat);
ppr=read32(dat);
ssz1=read16(dat)-2; //Считывание размера строки, но без метки UCS-2LE;
read16(dat); //Пропуск метки (чтение вникуда);
ReadFile(dat, folder, ssz1, &wr, NULL); //Чтение строки в буфер;
break;
case 0x0403: //Длительность (сек.);
sz=read32(dat);
pnx=read32(dat);
ppr=read32(dat);
len=read32(dat);
break;
case 0x0302: //Название;
sz=read32(dat);
pnx=read32(dat);
ppr=read32(dat);
ssz2=read16(dat)-2;
read16(dat);
ReadFile(dat, name, ssz2, &wr, NULL);
break;
default: //Если поле с неизвестным кодом;
printf("Unknow header!\n",hdr); //Предупредить об этом;
system("PAUSE"); //Приостановить программу;
break;
}
if(pnx){ //Если поле не последнее;
filepos(dat,pnx); //Позиционирование на следующее поле;
}
}while(pnx); //Пока указатель на следующее поле не равен нулю (пока существует следующее поле);
printf("\n"); //Новая строка на экране;
WriteFile(out, folder, ssz1, &ww, NULL); //Перезапись текстового буфера в выходной файл;
write08(out,'\t'); //Поля выходного файла отделены символами табуляции (кодировка UCS-2LE);
WriteFile(out, name, ssz2, &ww, NULL);
write08(out,'\t'); //Табуляция желательна для лёгкого импорта файла в Excel;
sprintf(str,"%08X\t%i\t%i\t%i\n",dt,cnt,len,index); //Формирование строки с остальными полями;
i=0; //Необходимо преобразовать сформированную строку в UCS-2LE;
while(str[i]){ //Пока не конец строки;
write08(out,str[i]); //Перезапись в выходной файл строки с преобразованием символов в UCS-2LE;
i+=1;
}
}
CloseHandle(idx); //Закрытие файла с адресами;
CloseHandle(dat); //Закрытие файла с данными;
CloseHandle(out); //Закрытие выходного файла;
system("PAUSE");
return 0;
}
Программа выполняется мгновенно, что вполне радует. Выходной файл открывается в Блокноте. Затем нужно выделить весь текст, скопировать его в буфер обмена и вставить в новый документ Excel. После изменения и подбора ширины каждого столбца получается вот такой вид.

Рис. 13. Выходной текстовый файл программы, вставленный в Excel.
Это будут исходные данные Excel, они расположены на первом листе документа. На втором листе будет формироваться красивая таблица, как результат обработки исходных данных с первого листа. Порядок расположения столбцов я сделаю примерно такой же, как и в таблице истории в самом плеере Winamp. Кроме этого, добавлю столбец с порядковым номером строки и добавлю строку с заголовками столбцов. Столбец «Индекс» поставлю на предпоследнее место.
Ячейки столбца «№» с порядковым номером строки получаются без формулы с помощью автозаполнения. Ячейки столбца «Дата и время» имеют одноимённый формат (ДД.ММ.ГГГГ чч: мм: сс) и рассчитываются по формуле (на примере первой ячейки) B2=ШЕСТН.В.ДЕС(Исх!C1)/86400+25569+3/24. Сначала происходит конвертация HEX числа Исх!C1 (где «Исх» – название первого листа) UNIX формата даты-времени в десятичный формат. Затем «целое число секунд», свойственное UNIX формату, преобразуется в «дробное число дней», свойственное Excel, делением на 86000 (число секунд в сутках). После этого значение смещается на 25569. Это число дней между началами отсчёта Excel и UNIX форматов даты-времени. В конце ещё прибавляется число 3/24 – смещение на 3 часа (на 3/24 дня) вперёд, так как время в истории воспроизведения указывается по GMT, а 3 часа – смещение для моего часового пояса. Следующий столбец «Название» остаётся без изменения. Ячейки столбца «Длительность» имеют формат времени (чч: мм: сс) и рассчитываются по формуле (на примере первой ячейки) D2=ЕСЛИ(Исх!E1>=0; Исх!E1/86400;0). Во-первых, также происходит деление значения длительности в секундах на 86400, так как в Excel время представляется дробным числом от 0 до 1 (целая часть этого числа отвечает за дату или количество дней) относительно суток. Условие «Если» необходимо для отображения только неотрицательных длительностей (иначе будет отображаться 0). Дело в том, что при воспроизведении потока аудио по ссылке (Интернет радио) Winamp записывает в свою историю данный объект, как медиа с длительностью -1 (0xFFFFFFFF), ибо поток по своей сущности не имеет длительности. Последние три столбца (количество, индекс и путь) – без изменения.
Чтобы в дальнейшем работать с полученными данными в чистом виде, необходимо всё содержимое второго листа скопировать на третий лист в режиме значений (без формул), что я и сделал. Можно производить сортировки по любому столбцу, в зависимости от нужной цели.
В результате получился примерно вот такой вид (рис. 14). Ширину столбцов и высоту окна Excel я уменьшил, сделав примерно так же, как при отображении истории воспроизведения в Winamp в оригинале. Я специально полностью выделил столбец с количествами воспроизведения. В строке состояния Excel отображается сумма выделенных чисел. В данном случае это общее количество воспроизведений, и оно равно 4457. Точь-в-точь такое же значение отображается в нижнем правом углу окна Winamp (рис. 1). Это своего рода дополнительный контроль на корректность работы моей программы.

Рис. 14. Результат обработки данных в Excel.
В заключение, вместо ненужных итогов и выводов, я напишу о назначении столбца «Индекс». Как я выяснил, числа в этом столбце прямо пропорциональны значениям даты-времени. Сортировка по дате-времени и сортировка по данному столбцу не меняет картины в целом. Следовательно, в файле «recent.idx» числа, выделенные зелёным цветом, служат индексами для быстрой сортировки записей истории в Winamp по дате-времени прослушивания.
Комментарии (7)

zorn_v
26.03.2022 21:57-2> На что только люди не пойдут лишь бы за пять минут быстренько не
посмотреть в IDA или Ghidra как создаются, как читаются и какой формат
требуемых файлов.
А зачем, учитывая что не за "пять минут" ? )Иногда проще разобрать формат файла, чем разбирать как с ним программа работает
IDA/Гидра же не панацея, а если вы просто знаете эти названия, то расскажите как вы бы сделали )
PS. Винамп вроде на делфи был, а там жуть ) DeDe а не ида )


unsignedchar
27.03.2022 07:53+1Впечатляет ;) Можно было упростить себе жизнь. Создать список из 1 пункта, сравнить со списком из 2 пунктов..

chnav
27.03.2022 11:15+1Спасибо за информацию, я даже не был в курсе, что он хранит историю.
Всегда была мысль заиметь какой-нибудь плагин WinAmp, который позволял бы одной кнопочкой давать рейтинг от "буду часто переслушивать не один раз" до "никогда в жизни не хучу больше это слышать", чтобы потом очистить диск от ненужного хлама. Описанный в статье метод уже близко, но если я прослушал файл на прокрутке с целью определиться с рейтингом он всё-таки попадёт в историю. Хотя и тут есть варианты, например отсеивать по количеству прослушиваний. В общем очень интересно.
Наверняка эта фича есть в современных онлайн-сервисах (рейтинги, стили и пр.), но как всякий олдфаг я предпочитаю иметь всё на физическом носителе чтобы не зависеть от облаков. Эта привычка осталасья от многолетней работы в море, если что-то не привезёшь с собой на диске - интернет 128 kbps на весь пароход.
PS: другие аудиоплееры не интересуют принципиально, в WinAmp уже найдена и установлена куча плагинов, н-р перецифровка под нативные частоты дискретизации аудиокарты, нормальное воспроизведение MIDI с выбором устройства вывода и т.д. Для кого-то это анахронизм, а для меня нежелание влезать в эту тематику в очередной стопицотый раз. Если работает годами - зачем менять. PS:помните как в молодые времена любую проблему решали переустановкой системы чтобы попробовать очередную чудо-сборку ))) С последующей переустановкой и настройкой всего софта ))

R3EQ Автор
27.03.2022 22:49Я с вами полностью согласен. Я сам уже за 20 лет привык к Винампу, так как с него и начал. Есть более продвинутые плееры во всех отношениях, например, foobar2000, но к нему надо привыкать. Кстати, чтобы открыть медиабиблиотеку Винамп, нужно нажать комбинацию Alt+L. Слева в иерархическом меню должна быть вкладка "История". Если её нет, значит данный компонент на этапе установки не был активирован. Рейтинг песен, если я не ошибаюсь, можно выставлять в AIMP, по аналогии с облачными плеерами в соцсетях. Но я не знаю, как там это работает. Насчёт "знакомства" с песней на прокрутке и попадания в историю - есть возможность этого избежать. Можно настроить в параметрах задержку по времени или по процентам прослушивания перед попаданиям в историю. Я настроил так, чтобы песня попадала в историю спустя 10 сек. после открытия. А вообще, действительно, возможности обработки широки. Можно в Эксель не только любоваться и анализировать, но и сортировать музыкальные файлы по разным признакам, написав несложные сценарии.
pfemidi
Adobe Audition, Excel… На что только люди не пойдут лишь бы за пять минут быстренько не посмотреть в IDA или Ghidra как создаются, как читаются и какой формат требуемых файлов.