
Привет! Недавно мы разработали для российского банка и запустили сервис, который помогает пользователям при получении финансовых услуг. Как и всегда в финтехе, сервис должен был отвечать требованиям безопасности, отказоустойчивости и надежности. А для его внедрения нужно было решить еще одну интересную задачу – разобраться в бизнес-процессах банка и улучшить их автоматизацию, используя движок Camunda BPM.
Изучая задачу, мы выяснили, что материалов об автоматизации бизнес-процессов в Camunda немного, особенно на русском языке. Поделимся своим опытом реализации проекта на Camunda, Java и Spring Boot.
Материал будет полезен в первую очередь тем, кто начинает новый процесс на Camunda, а также тем, кто находится в поиске свежего взгляда на реализацию процессов в условиях кластера с микросервисами. Планируем далее продолжить эту тему и рассказать о тестировании моделей процессов.

Что такое Camunda и что она дает бизнесу
Camunda BPM, говоря простыми словами, — это ВРМ-движок, который позволяет автоматизировать бизнес-процессы предприятия с помощью нотации BPMN. По сути, он переродился в большой отдельный фреймворк или, если угодно, самостоятельную платформу. Ее можно использовать для моделирования, автоматизации, интегрирования, оркестрации и отладки бизнес-процессов. С помощью платформы любой бизнес-процесс можно рассматривать с точки зрения некой программной сущности, к которой применимы не только бизнес-абстракции, но и ООП.
Что почитать и посмотреть по основам
Официальный форум Camunda.
YouTube — свой канал Camunda, есть Camunda Con, есть видео на русском языке по основам процессных приложений и межпроцессному взаимодействию, но информация разрозненная и придется анализировать, проецировать на свой проект. По крайней мере, нам пришлось.
Важно: Бизнес-процессы, протекающие в Camunda BPM, можно рассматривать с точки зрения ООП
Camunda BPM позволяет создать блок-схему на основе нотации BPMN, которая будет понятна подавляющему большинству. Открытый исходный код делает ее использование безопасным, а развитое сообщество делает знания доступными.
Camunda BPM написана на Java, а, если точнее, является Spring-приложением. Она не ограничивает разработчиков никакими условно "своими" инструментами. Вся логика исполнения задач в ней ведется путем запуска делегатного кода в соответствии со схемой, который уже пишется на чистой Java. Такой способ создания бизнес-схем в десятки раз быстрее, чем разработка подобных приложений в чистом коде.
Возвращаясь к утверждению о рассмотрении Camunda-процессов с точки зрения ООП, отметим, что реализация делегатного кода позволяет полностью инкапсулировать логику Java-кода от логики BPM-схемы. Например, в схеме может быть условная задача, ведущая логирование. Java-реализация ее делегата будет вызывать условный сервис-логгер на основе локальной переменной, заданной на BPM-схеме. Сама реализация логгера будет скрыта от схемы и не будет зависеть от нее. Это позволит разработчику в любой момент поменять как стратегию логирования, так и саму схему без последствий для всего процесса.
Суровая реальность
Camunda была призвана сделать так, чтобы разработчики и аналитики говорили на одном языке, но, зачастую, реальность вносит свои коррективы.

Микросервисы падают, пользователи вводят данные с ошибками, случиться может все, что угодно. Факт остается фактом: исключения существуют. В этот момент красивая аналитическая схема начинает обрастать всевозможными обработчиками ошибок, логгерами и альтернативными путями. Аналитик проектирует прекрасную, лаконичную и понятную схему. На ней малое количество делегатов, предусмотрены логические пути, по которым должен протекать процесс в разных ситуациях. Так выглядит условная схема в момент, когда она попадает в руки разработчика:
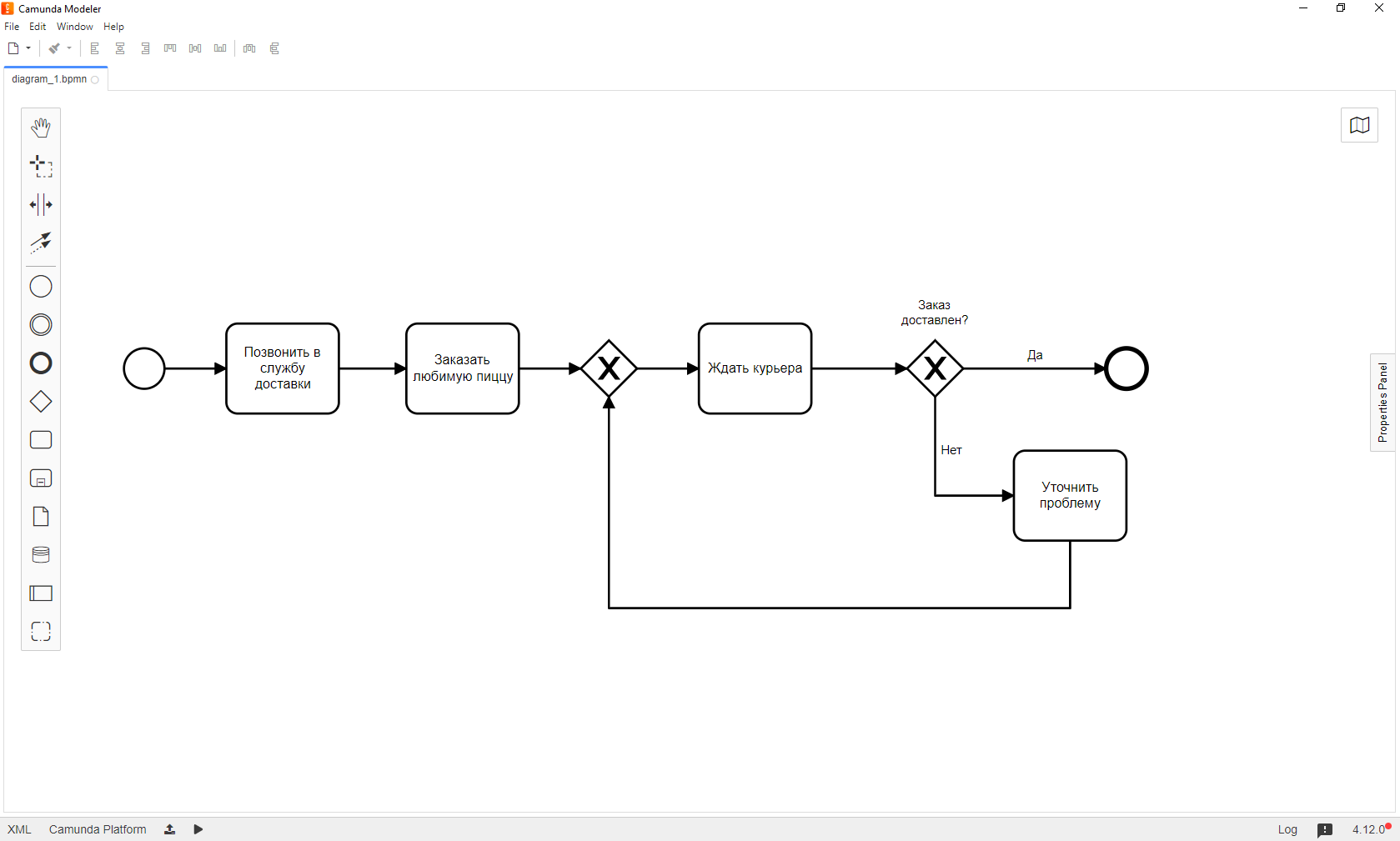
Но есть и минусы. Такая схема может содержать краткую формулировку задачи, например, “проверить клиента”, которая подразумевает несколько этапов, принятие решения по итогам каждого и обобщение полученных решений в единый результат, возможно, с последующей передачей этого результата во внешние системы.
Понятно, что в этот момент на схеме или в коде появляются обработчики ошибок, логгеры, служебно-технические элементы. Так одна “аналитическая” задача в Java-реализации становится объемной и сложной, или на схеме вырастает количество шагов, а каждый из них обрастает обработчиками и альтернативными путями. В итоге схема быстро становится запутанной, трудной для дальнейшей поддержки и модификации, а добавление нового функционала может повлечь за собою переработку огромного участка как схемы, так и делегатного кода. И по сути она содержит огромное количество однотипных элементов.
Вот так может выглядеть предыдущая схема в реальном деплое:
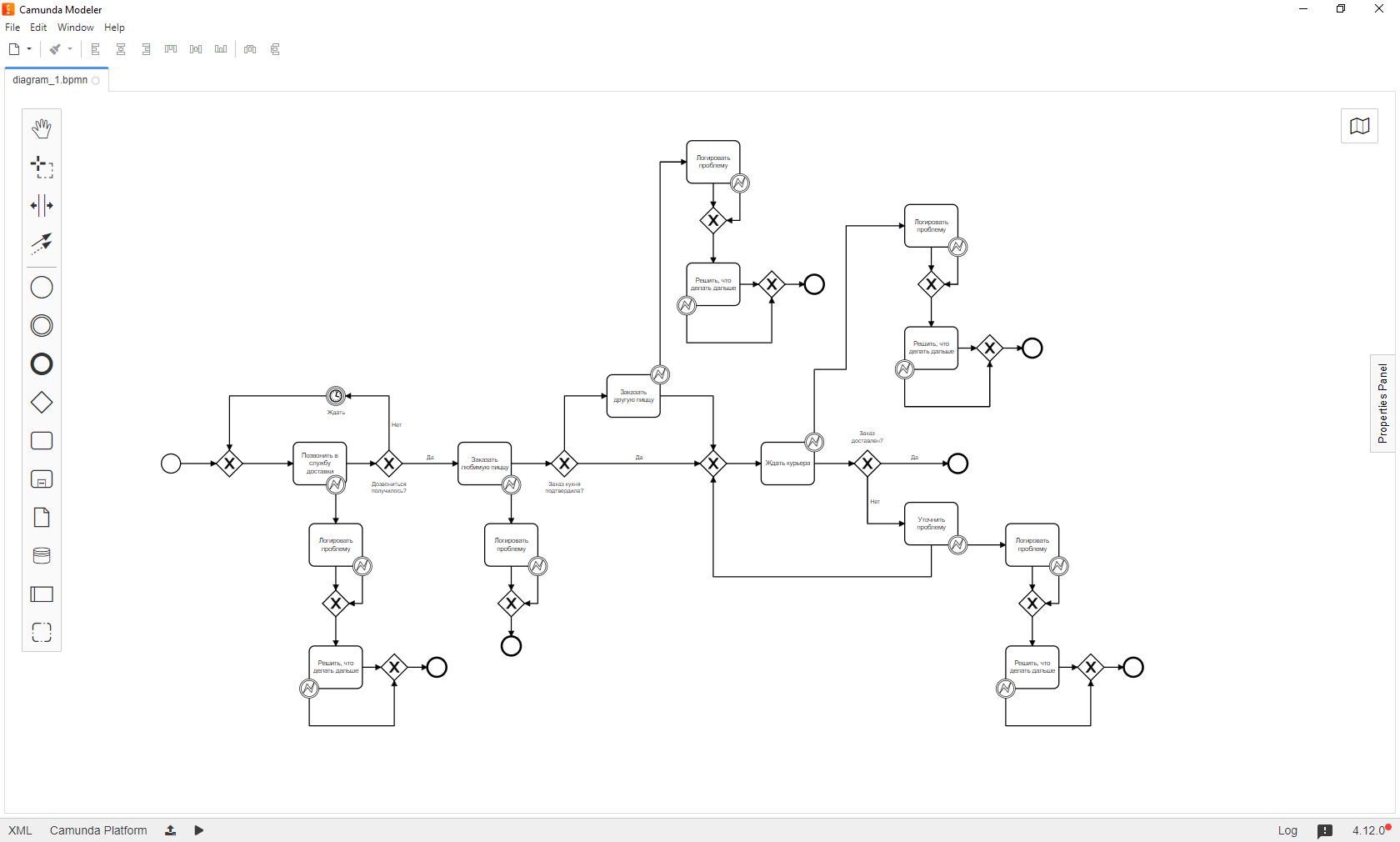
Очевидно, что схема разрослась, стала тяжелее. Но есть и плюсы: все задачи стали атомарны, появились ветви поведения в случае возникновения ошибок.
Осознание проблемы
Если попробовать отделить, инкапсулировать схему и бизнес-логику Java-кода, можно сделать следующее:
Отказаться от дублирования однотипных элементов, как на схеме.
Использовать универсальную и переиспользуемую реализацию делегатов в Java-коде.
Оптимизировать и ускорить течение процесса.
Упростить обработку технических ошибок и выстроить логику поведения процесса при их возникновении - практически без участия Java-кода. Это существенно упростит отладку и ручной разбор проваленных процессов, находящихся в инциденте.
Радикально уменьшить количество процессов, “падающих” в инциденты при возникновении технических исключений.
Заложить крепкую базу для дальнейшего развития.
Чтобы в будущем работать с продуктом и поддерживать его было бы проще, нам нужно было декомпозировать схему на атомарные задачи, уменьшить суммарный объем элементов схемы, снизить количество служебных обработчиков, уменьшить объем Java-кода каждого делегата и переиспользовать универсальные делегаты, проводя мгновенный рефакторинг при возникновении необходимости. Всё это автоматически подразумевало под собой написание юнит-тестов на все делегаты и на основные пути процесса.
Декомпозиция и атомизация
Если внимательно посмотреть на процессное приложение и проанализировать его узлы, можно увидеть множество повторяющихся функций: запросы к внешним системам, логирование, обработка ошибок, отправка коллбэков и т.д. Другими словами, нужно критически оценить процессное приложение, выделить из него объекты, которые можно легко инкапсулировать...Но во что? В Java-код? Нет, это было бы нелогично, потому что в этом случае схема окажется крепко связана с ее Java-реализацией. В этом случае есть смысл посмотреть в сторону процессных пулов.
Процессный пул — это схема отдельного процесса, который будет иметь свой контекст. Примечательно, что в такие пулы удобно выносить атомарные кусочки функционала из основного процесса, а также все повторяющиеся моменты: отправка уведомлений, запросы к внешним системам и т.п.
Процессных пулов может быть много и будет логично их сгруппировать по тематике, семантически. Например, запросы к какому-то определенному микросервису, алертинг, отправка всевозможных нотификаций. Взаимодействие между такими пулами можно легко наладить с помощью Camunda messaging. При каждом вызове такого пула в Camunda engine передается некое сообщение, содержащее условный заголовок и номер процесса-родителя для возврата ответа, а также набор необходимых данных для работы именно этого маленького пула.

Здесь мы видим, как основной процесс (нижний) отправляет сообщение, на которое подписан стартер другого пула. При наступлении события второй пул начинает новый инстанс процесса, делает запрос и формирует ответ в основной процесс, после чего успешно завершается. Основной процесс в это время ждет наступления события ответа стороннего пула, в который он отправил запрос. Когда сообщение приходит, то процесс идет дальше. Если его нет в указанный временной интервал, процесс понимает, что внешнее вычисление недоступно или провалено и завершается.
Что это дает
Возможность переиспользования кода. Если по процессу нужно несколько раз вызывать один и тот же код в разных условиях, можно просто формировать определенные сообщения и вызывать соответствующие атомарные процессные пулы.
Инкапсуляцию программной реализации схемы от ее бизнес-представления. Не важно, как будет переделываться основная схема, по каким путям будет вестись процесс. Все взаимодействия уже вынесены в отдельные мелкие процессы, что полностью развязывает руки: достаточно лишь сформировать запрос и ждать ответ.
Количество и вероятность падений основного процесса резко сводится к минимуму. До такого разделения процесс находился в неопределенности из 4 состояний:
ответ пришел,
ответ не пришел, потому что упал внешний микросервис,
ответ не пришел, потому что упал основной процесс в момент отправки запроса,
ответ не пришел потому что превышен тайм-аут.
С таким разделением процесс всегда находится в строго одном состоянии: ответ или пришел, или процесс ждал и завершился. Для бизнеса имеет значение, как именно завершился процесс: ошибкой или нет. Но это будет корректное завершение, не инцидент. Это важно, поскольку не висящий в инциденте процесс не "ест" ресурсы, а ошибки можно легко логировать, собирать статистику, настраивать алертинг и анализировать.
Уже не важно, что случается с мелкими процессами. Они могут делать, что угодно: падать, не падать... Важен только результат: ответ внешнего ресурса. Да и то не всегда, ведь основной процесс не должен гарантировать работоспособность внешних систем. Например, возможно, что в процессе не будет смысла ждать ответа от микросервиса нотификаций или ответа может совсем не быть. В нашем проекте все мелкие пулы строились максимально устойчивыми к работе в любых условиях: падения приводили к корректному завершению, но ответа не присылали, а основной процесс шел по ветке "я не получил ответ" и, исходя их этого, действовал дальше.
Резко уменьшается сложность основного процесса. Сложная логика может разноситься по отдельным небольшим пулам, которые проще дебажить. Например, проверка клиента может выглядеть примерно так:
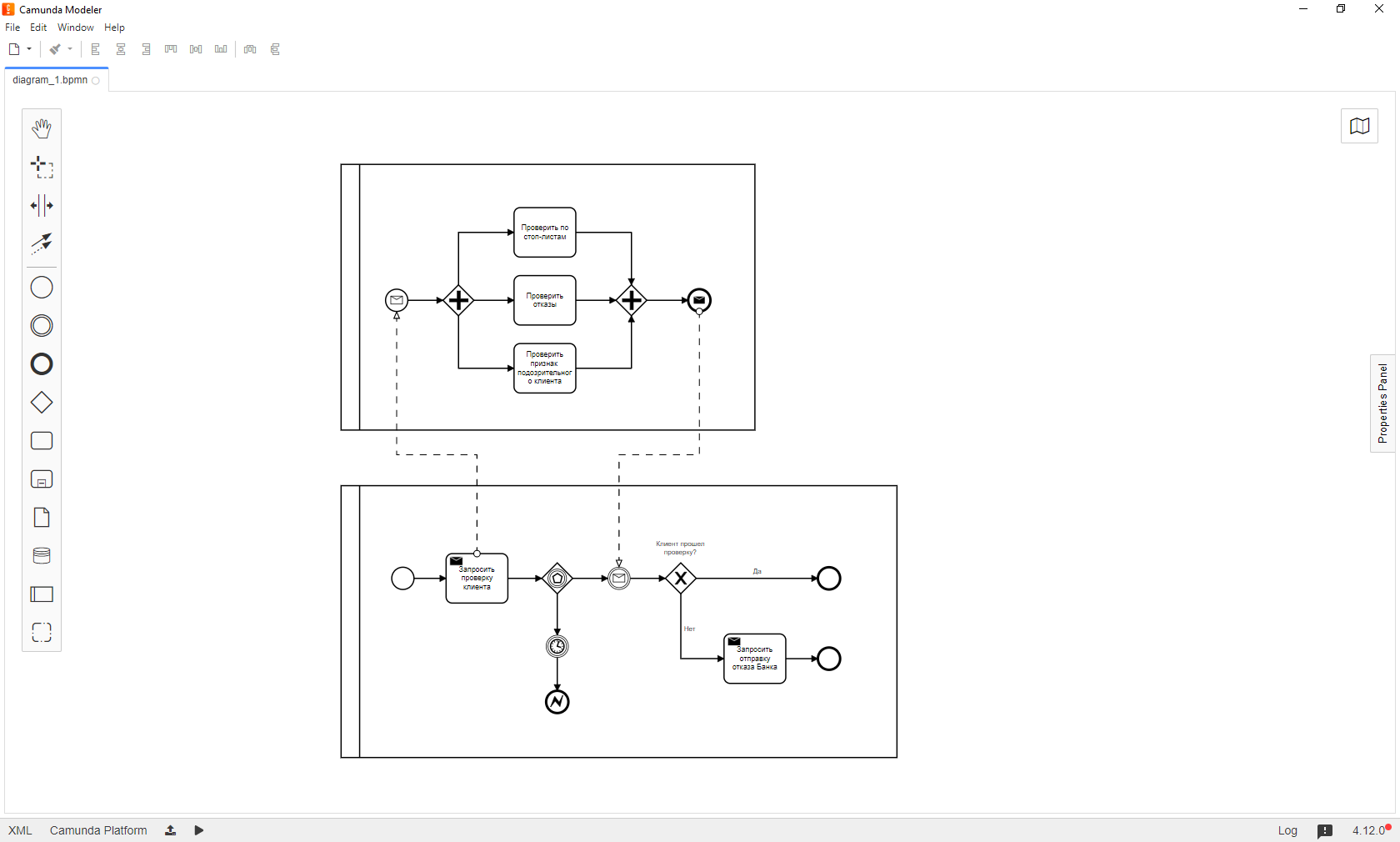
Здесь видно, что во внешнем пуле происходит одновременный вызов нескольких задач. Рассмотрим этот момент подробнее.
Параллелизация процессных вычислений
Camunda позволяет запускать ветви процессных вычислений параллельно. Для этого существует специальный шлюз Parallel Gateway, с помощью которого поток можно разделить на параллельные или объединить несколько параллельных вычислений в один поток. Понятно, что для ускорения течения процесса было бы неплохо вынести некоторые вещи в параллельные потоки. Если логика независимая, то ее можно выполнять параллельно, например, сделать одновременно несколько запросов к внешним системам и ждать ответов сразу от всех:
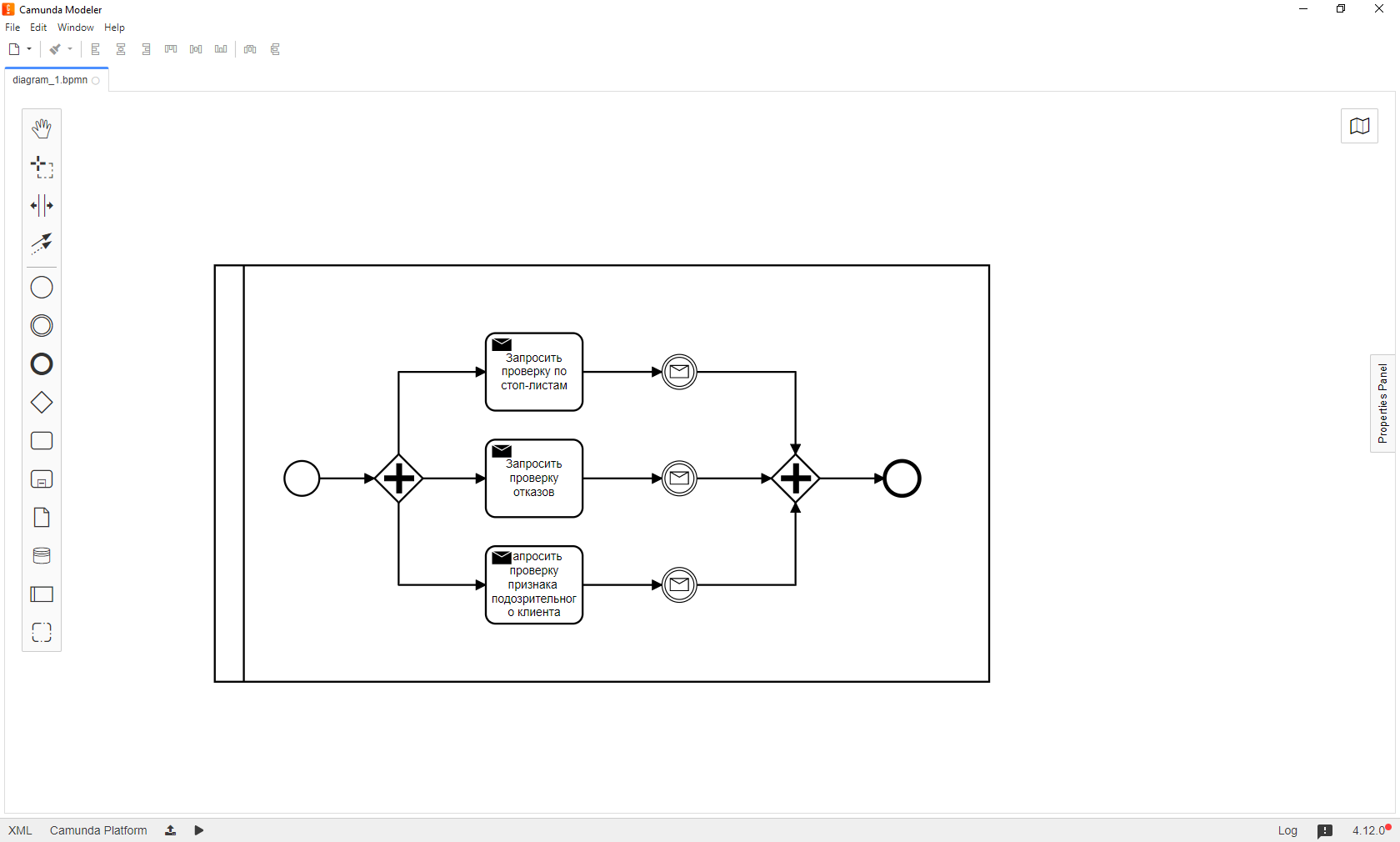
Каждый раз на таком шлюзе будут возникать накладные расходы, связанные с созданием новых потоков для разделения задач и слияния результатов. Можно получить разные locking exceptions и, конечно, всегда так делать не обязательно и, зачастую, неоправданно, особенно без тестов, но плюсы очевидны.
При последовательном исполнении суммарное время выполнения равняется сумме времен исполнения каждой операции, а при параллельном — времени исполнения самой долгой операции в условиях немгновенного ответа внешних источников, ретраев и падений имеет далеко не последнее значение. Есть еще один несомненный плюс в виде "бесплатных ретраев", т.е. пока исполняется самый долгий запрос, остальные гипотетически имеют возможность несколько раз упасть и попробовать повторить свои действия, не влияя на общее время исполнения задач.
Сломалось? Бывает
Исключения неизбежны. Уже несколько раз звучала фраза "попытка повтора". Разберем, что это такое.
Коробочная версия Camunda имеет возможность повторить проваленную транзакцию. Под транзакцией имеется в виду внутренний камундовский механизм исполнения делегатного кода. Началом транзакции является, например, пометка async before или async after на задаче в моделлере. Когда движок встречает эту пометку, он коммитит свою информацию в БД и начинает новый асинхронный поток. Это важно. Если чуть детальнее, то под транзакцией будет пониматься участок исполнения между вызовами метода .complete() у TaskService с последующей записью информации в БД. Эти транзакции, как и другие, атомарны.

Когда возникает техническое исключение, т.е. любая не-бизнес ошибка, например, поделили на ноль и забыли проверку на null, транзакция делает rollback и пробует стартовать снова. И так по дефолту 3 раза подряд без пауз. Попытка повтора стартует при возникновении обычного исключения, которое в мире BPMN называется техническим, а не BpmnError. Возникший BpmnError обрывает процесс без попытки повторов. Представьте, насколько, благодаря этому, повышается отказоустойчивость процесса.
Логично это использовать на максимум, поэтому, на каждом делегате, запрашивающем внешнюю систему, мы выставили эти метки, указали количество повторов и паузу между ними, а в делегатном коде написали отдельную логику, когда нужно обрывать процесс, а когда нет. Это дало нам полный контроль над механизмом обработки исключений и попыток повторов. В итоге процесс сначала пытался несколько раз повторить проваленную задачу, и только после серии неудач уходил в ошибку.
Пожалуй, самой большой проблемой является обработка технических исключений и BPMN-ошибок, а также проектирование логики их обработки для беспрерывного течения процесса. Часть ошибок, связанных с обработкой ответов от внешних источников, мы уже рассмотрели, когда обсуждали деление на процессные пулы. Напомню, что сам вызов инкапсулировался в отдельный мини-процесс, а основной или получал ответ и двигался дальше, или уходил по тайм-ауту в ветку "я ответа не получил".
Теперь давайте посмотрим на тот самый маленький процесс:

Видите рамку? Это подпроцесс. Он содержит конкретные задачи и улавливает ошибки, выброшенные внутренними задачами. Кроме того, на таких рамках job executor оказывается способным создать job для таймера, который задает время исполнения всего того, что находится внутри подпроцесса.
Как это работает? Поток исполнения доходит до подпроцесса, создает параллельную обработку таймера и ждет либо завершения того, что внутри, либо, если время, засеченное таймером выйдет раньше, уйдет по ветке таймера. Если в процессе будет выброшено исключение, которое рамка подпроцесса улавливает, процесс прекратит свое исполнение по текущей ветке и пойдет по ветке ошибки.
Также видно, что есть возможность создавать отправку ответов для критичных запросов. Отметим, что улавливание ошибок работает только в случае BpmnError с определенным кодом, поэтому, технически необходимо ловить любой Exception, и перебрасывать BpmnError с нужным кодом, который слушается ErrorBoundaryEvent.
Обработка ошибок в основном процессе происходит похожим образом. Из нескольких тасков выделяются логические единицы, которые можно поместить в рамку подпроцесса, повесить слушатель, настроенный на определенный код ошибки. Но тут есть два нюанса. Первый - создавать множество однотипных ветвей с обработкой множества ошибок, различающихся лишь кодом неудобно. Если изменится стратегия обработки ошибок или, например, логирования, придется переделывать очень много делегатов на схеме, чего не хотелось бы. Поэтому можно посмотреть в сторону event-based подпроцессов.

По своей сути — это отдельный подпроцесс пула процесса, который стартует только при наступлении какого-либо события, на которое он подписан. Например, если такой подпроцесс подписать на событие BpmnError с кодом, например, MyCustomBusinessError, то при наступлении этого события сработает обработка, и по ее завершению процесс корректно завершится. Да, он завершился не успехом, но корректно. В этих подпроцессах также можно повесить разную логику обработки одного и того же события в зависимости от внешних условий, например, опционально уведомлять об уводе заявки в ошибку при прохождении процессом какой-то условной точки.
Второй нюанс намного сложнее. В реальной жизни, скорее всего, жизненный цикл каждого процесса будет делиться на два бизнес-этапа: до формирования лида и после него. Если ошибка произошла до того, как данные оформлены в лид, то, скорее всего, процесс можно просто завершить, оповещая о возникших сложностях. После того, как лид сформирован, так делать уже нельзя.
Также не рекомендуем завершать процессы, если в течение процесса возникают какие-то юридические обязательства, например, подписывается договор. Как же обрабатывать подобные ошибки? Часть технических ошибок, например, связанных с недоступностью внешних сервисов, отсекается автоматическими повторами в рамках заранее оговоренного тайм-аута. Но как быть, если процесс упал, ретраи прошли, но условный внешний микросервис по-прежнему лежит? Мы приходим к понятию ручного разбора или, как мы называем их внутри команды, компенсации.
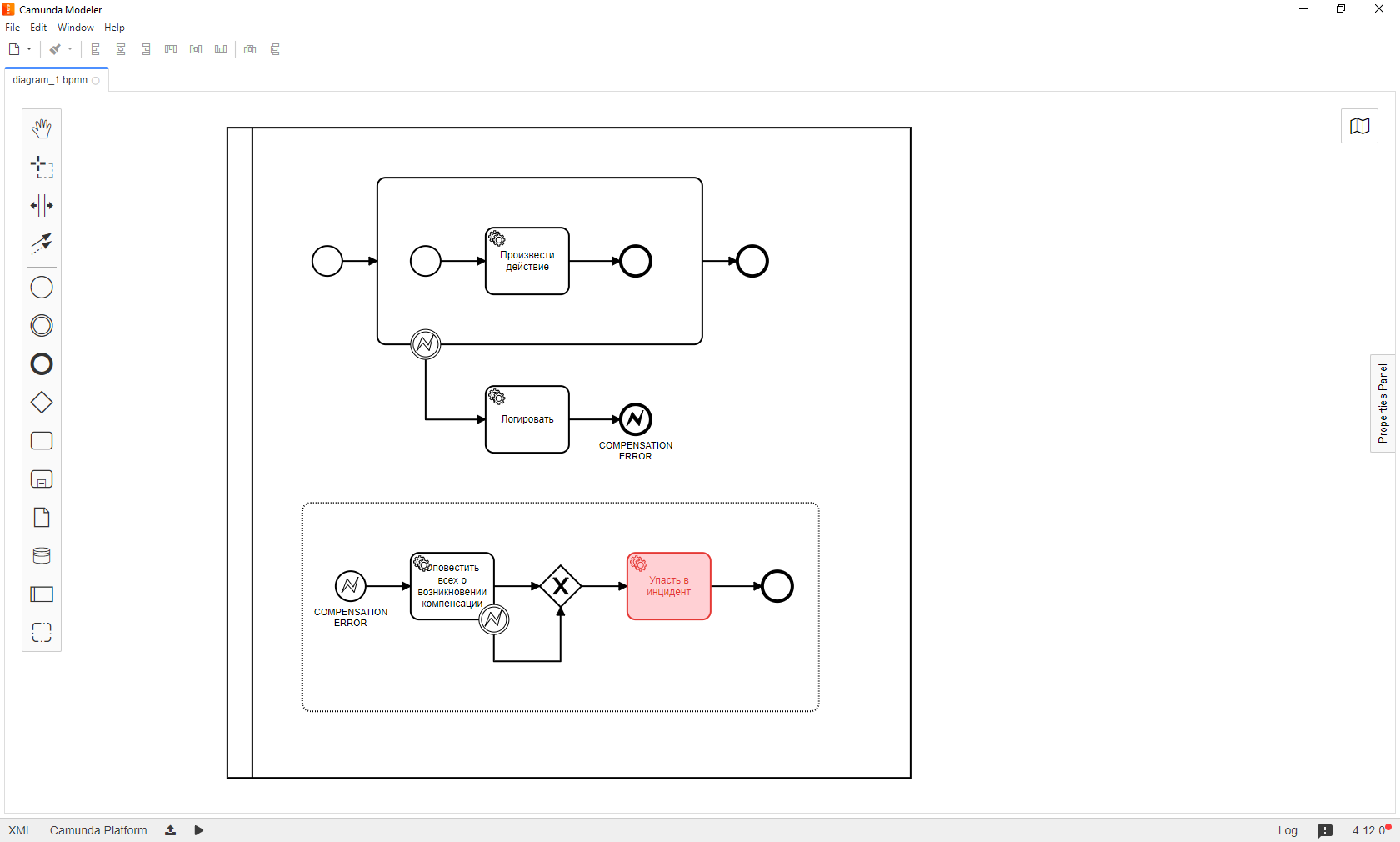
Как это работает? Любые ошибки отлавливаются, делегатам при необходимости дается возможность отретраиться и, если все равно удача не улыбается, процесс уходит в ошибку, но с нужным кодом, например, COMPENSATION_ERROR. Этот код отлавливает уже другой event-based подпроцесс, он все обрабатывает, логирует, оповещает и при этом не имеет возможности свалиться в неположенном месте, только там, где нужно, он отдельным делегатом кидает техническое неотлавливаемое исключение и падает в инцидент.
Зачем так делать? Для мониторинга можно использовать EXCAMAD — это внешняя админка для Camunda, аналог Cockpit, обладающая крутой функциональностью. Она подсвечивает красным процессы в инциденте. Эти процессы можно модифицировать или перезапустить с нужного места. Например, положить в контекст нужное значение переменной и перезапустить процесс с точки, которая будет сразу после проблемной. Это удобно, легко и позволяет малыми силами проводить ручной разбор проблем.
А что там с кодом?
Понятно, что каждая задача на схеме, скорее всего, — это какой-то класс Java, реализующий интерфейс JavaDelegate. Также очевидно, что каждый шаг, каждая ступень процесса должна быть качественно залогирована, настроена обработка ошибок. Поэтому логично воспользоваться абстрактными классами и настроить иерархию делегатов. Например, родительский делегат может выглядеть примерно так:
@Slf4j
public abstract class AbstractDelegate implements JavaDelegate {
@Override
public void execute(DelegateExecution delegateExecution) {
try {
log.trace("Delegate {} was called for process {}",
getClass().getSimpleName(),
delegateExecution.getProcessInstanceId());
run(delegateExecution);
} catch (Exception exception) {
log.error("Error occurred", exception);
executeHandling(delegateExecution, exception);
}
}
public void executeHandling(DelegateExecution delegateExecution, Exception exception) {
throw new BpmnError("PROCESS_ERROR", exception);
}
public abstract void run(DelegateExecution delegateExecution);
}Как это работает? Делегат реализует интерфейс JavaDelegate, определяет метод execute(), в котором в try-catch блоке проводит базовое логирование и вызывает абстрактный метод run(). Любое исключение будет отловлено, залогировано и передано в метод executeHandling(), где по умолчанию проводится оборачивание выброшенного исключения в BpmnError с нужным кодом ошибки, отлавливаемым на схеме. Это дает невероятное удобство: в каждом конкретном делегате не будет нужды дублировать основные методы.
@Component
public class FooTask extends AbstractDelegate {
@Override
public void run(DelegateExecution delegateExecution) {
System.out.println("Hello, delegate!");
}
}Как видно из фрагмента, делегату будет нужно лишь переопределить один метод run() и, при необходимости, метод обработки ошибок.
Наверное, месседжей придется много писать?
Да. Но все они должны быть небольшими, легко отлаживаемыми и простыми. На деле все должно свестись к написанию одного сервисного компонента, который должен уметь отправлять запросы и ответы на основе переданного в него DTO-объекта сообщения.
Сам процесс отправки сообщений представляет собой корреляцию сообщения к конкретному процессу по processInstanceId или processBusinessKey.
runtimeService.createMessageCorrelation("ORDER_ADDED")
.processInstanceId((String) delegateExecution.getVariable("parent"))
.setVariable("approved", true)
.correlate();Понятно, что в параметры корреляции можно и нужно вставлять поля DTO-объекта, который будет сформирован непосредственно в конкретном делегате.
Всегда хочется чего-то еще
В этом решении мы учитывали опыт, который накопили при автоматизации бизнес-процессов для наших клиентов из разных отраслей. Примеры есть тут, сейчас не будем уходить от темы.
Считаем, что это решение, как и любое другое, можно дополнительно улучшать. Например, отказаться от контекста Camunda в пользу документо-ориентированной базы данных MongoDB. Это даст мгновенный слепок всего процесса на любом этапе, позволит избежать записи в БД самой Camunda клиентских данных, а также решит множество проблем с сериализацией непримитивных типов и позволит стартовать новый процесс с уже имеющимся набором данных.
Надеемся, статья была вам полезна. В следующий раз мы расскажем об особенностях тестирования моделей процессов Camunda и обсудим best practice.
Комментарии (4)

vasyakolobok77
29.03.2022 00:24После некоторого опыта работы с bpm движками подобный маркетинг вызывает лишь улыбку. Оно все хорошо на примерах уровня - пара тасков и шлюзов, но в реальной жизни это боль и мучения.
Почему-то всегда в подобных статьях упускают такие моменты:
– Как версионировать БП, как мигрировать со старой версии на новую?
– А если при этом состав процессов или модели данных несовместимы?
– Где хранить актуальное состояние модели: только в инстансе процесса или во внешнем хранилище? Если во внешнем хранилище как решать проблему конкурентного доступа?
– Как вообще рефакторить это все это добро?
– И самое главное: а какой вообще bpm дает профит? По своей сути bpmn - это описание конечного автомата, так почему не использовать, например, акторную модель?
SSul Автор
29.03.2022 10:24Добрый день. Всё зависит от задачи, условий и уровня владения тем или иным инструментом. В общем случае сеньор-разработчику зачастую проще написать все чистым кодом, тогда как бизнесу бывает удобнее Camunda – чтобы наглядно видеть блок-схему процесса и легко подключать к проекту разработчиков любого уровня, не требуя от них погружения в чужой код.
Что касается вопросов, мы сделали несколько предположений, исходя из опыта нашего проекта – и в других проектах, безусловно, могут быть свои особенности.
1. Как версионировать БП, как мигрировать со старой версии на новую?
Можно указать в пулах version tag, кроме того, при деплое активные процессы закончат свой жизненный цикл по старой версии схемы.
2. А если при этом состав процессов или модели данных несовместимы?
Основы SOLID говорят, что проект должен быть открыт для расширения, но закрыт от изменений. Модель данных нужно менять в рамках разумного.
3. Где хранить актуальное состояние модели: только в инстансе процесса или во внешнем хранилище? Если во внешнем хранилище как решать проблему конкурентного доступа?
Можно хранить в контексте или во внешней БД (что даже лучше). Проблему конкурентного доступа нужно решать по мере ее возникновения, иначе сориентироваться трудно, если вообще возможно. Острее будет стоять вопрос версионирования и миграций БД. Также стоит присмотреться к документоориентированным БД.
4. Как вообще рефакторить это все это добро?
Рефакторить как раз-таки просто: схема оказывается отвязана от кода и можно с большой степенью свободы менять реализацию как схемы, так и кода.
5. И самое главное: а какой вообще bpm дает профит? По своей сути bpmn - это описание конечного автомата, так почему не использовать, например, акторную модель?
Дело в скорости разработки: в чистом коде реализация займет гораздо больше времени, а поддерживать может быть нелегко из-за запутанной паутины вызовов и управления доступом. Хотя, где-то действительно можно и проще работать без bpm – каждый решает сам.
Doctorrr
Спасибо за полезную статью, не помешало бы больше кода %)
SSul Автор
Рады, что материал полезен! Показать детали, увы, не можем – зато через неделю расскажем подробности о тестировании проекта. Кода будет больше)