

Цель статьи - описать создание инфраструктуры для парсинга на базе python, Django, Celery и Docker.
Введение
В студенческие годы я написал на заказ много парсеров магазинов и социальных сетей. Со временем парсеры усложнялись и из скриптов превращались в полноценные веб-приложения c базой данных и Rest API. В статье описан шаблон веб-приложения, который использую для создания парсеров.
Парсинг (в контексте статьи) -- это автоматизированный процесс извлечение данных из Интернета.
Из статьи мы узнаем
Как создавать Rest API на базе Django Rest Framework
Как создавать асинхронные задачи с помощью Celery
Как деплоить веб-пиложение с использованием Docker-compose
Архитектура приложения содержит 3 основые части:
Django для обработки HTTP запросов и хранения данных
Redis - транспорт (брокера сообщений)
Celery - для создания очередей задач (задач парсинга)

UseCase:
Пользователь делает HTTP POST запрос /task
Если запрос содержит правильные данные, то приложение запускает задачу парсинга
В базу данных сохраняются результаты задачи
1 Начнем с создания Django приложения
# Create Django application
python3.9 -m venv venv # create virtual environment
source venv/bin/activate # activate the environment
pip install Django==4.0.0 # install django library
mkdir project
cd project
django-admin startproject core_app . # create django app with initial settings Для аккуратности создадим отдельное приложение (директорию), код которого будет отвечать за логику приложения (парсинг)
# create a new app in /project
python manage.py startapp parser_appРезультат первой части
После выполнения команд у нас должен получиться такой проект:
project/
├── core_app
│ ├── asgi.py
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-39.pyc
│ │ └── settings.cpython-39.pyc
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
└── parser_app
├── admin.py
├── apps.py
├── __init__.py
├── migrations
│ └── __init__.py
├── models.py
├── tests.py
└── views.py2 Запустим приложение в Docker
2.1 Подготовка PostgreSQL базы данных
sudo apt-get update
sudo apt-get install python3-dev libpq-dev postgresql postgresql-contrib
sudo -u postgres psql
CREATE DATABASE parsing_db;
CREATE USER postgres WITH PASSWORD 'post222'; # postgres is username
GRANT ALL PRIVILEGES ON DATABASE parsing_db TO postgres;
\q 2.2 Подготовка docker-compose
Создаем .env файл с переменными окружения
# .env
DB_USER=postgres
DB_PASSWORD=post222
DB_NAME=parsing_db
DB_PORT=5444
DATABASE_URL=postgres://postgres:post222@db:5432/parsing_db"
DEBUG=1Модифицируем файл с настройками
# core_app/settings.py
import os
import environ
env = environ.Env()
ALLOWED_HOSTS = ['127.0.0.1', '0.0.0.0']
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
# packages
'rest_framework',
# my apps
'parser_app',
]
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': os.environ['DB_NAME'],
'USER': os.environ['DB_USER'],
'PASSWORD': os.environ['DB_PASSWORD'],
'HOST': 'db',
'PORT': 5432,
}
}
STATIC_URL = '/static/'
STATIC_ROOT = BASE_DIR / 'static'Описываем библиотеки, которые потребуются для запуска проект
# project/requirements.txt
Django==4.0
celery==5.2.6
djangorestframework==3.13.1
redis==3.4.1
django-environ==0.8.1
gunicorn==20.1.0
psycopg2==2.9.3
celery==5.2.6
redis==3.4.1
requests==2.23.0
lxml==4.8.0Описываем инструкции для сборки докер-образа в Dockerfile
# project/Dockerfile
FROM python:3.9-slim-bullseye
WORKDIR /project
# forbid .pyc file recording
# forbid bufferization
ENV PYTHONDONTWRITEBYTECODE=1 \
PYTHONBUFFERED=1
COPY . .
RUN apt-get update && apt-get install --no-install-recommends -y \
gcc libc-dev libpq-dev python-dev libxml2-dev libxslt1-dev python3-lxml && apt-get install -y cron &&\
pip install --no-cache-dir -r requirements.txtКонфигурируем nginx
# project/nginx-conf.d/nginx-conf.conf
upstream app {
server django:8000;
}
server {
listen 80;
server_name 127.0.0.1;
location / {
proxy_pass http://django:8000;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_redirect off;
}
location /static/ {
alias /var/www/html/static/;
}
}
Создаем docker-compose.yml на одном уровне с папкой project/
# docker-compose.yml
version: '3.9'
services:
django:
build: ./project # path to Dockerfile
command: sh -c "
python manage.py makemigrations
&& python manage.py migrate
&& gunicorn --bind 0.0.0.0:8000 core_app.wsgi"
volumes:
- ./project:/project
- ./project/static:/project/static
expose:
- 8000
env_file:
- .env
db:
image: postgres:13-alpine
volumes:
- pg_data:/var/lib/postgresql/data/
expose:
- 5432
env_file:
- .env
environment:
- POSTGRES_USER=${DB_USER}
- POSTGRES_PASSWORD=${DB_PASSWORD}
- POSTGRES_DB=${DB_NAME}
nginx:
image: nginx:1.19.8-alpine
depends_on:
- django
ports:
- "80:80"
volumes:
- ./project/static:/var/www/html/static
- ./project/nginx-conf.d/:/etc/nginx/conf.d
volumes:
pg_data:
static:
Запускаем приложение
docker-compose up --build -dДалее зайдем в докер-контейнер и создадим суперпользователя
docker ps # intended to find django container name --> code_django_1
>> 6f5db39cfa3b code_django "sh -c ' python mana…" 47 seconds ago Up 46 seconds 8000/tcp code_django_1
docker exec -ti code_django_1 bash # go into the container
python manage.py createsuperuser # create admin user in django
python manage.py collectstatic # intended to load css and js files
exitРезультат второй части
Заходим на 127.0.0.1 Должен быть такой результат:
3 Подключаем Celery
Добавляем в docker-compose.yml файл новые сервисы
celery:
build: ./project
command: celery -A parser_app worker --loglevel=info
volumes:
- ./project:/usr/src/app
env_file:
- .env
environment:
# environment variables declared in the environment section override env_file
- DEBUG=1
- DJANGO_ALLOWED_HOSTS=localhost 127.0.0.1 [::1]
- CELERY_BROKER=redis://redis:6379/0
- CELERY_BACKEND=redis://redis:6379/0
depends_on:
- django
- redis
redis:
image: redis:5-alpine
volumes:
pg_data:
static:Добавляем настройки для celery
# settings.py
CELERY_BROKER_URL = os.environ.get("CELERY_BROKER", "redis://redis:6379/0")
CELERY_RESULT_BACKEND = os.environ.get("CELERY_BROKER", "redis://redis:6379/0")
CELERY_IMPORTS = ("parser_app.celery",)Создаем объект для работы с celery
# parser_app/celery.py
"""
Celery config file
https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html
"""
from __future__ import absolute_import
import os
from celery import Celery
from core_app.settings import INSTALLED_APPS
# this code copied from manage.py
# set the default Django settings module for the 'celery' app.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'core_app.settings')
# you change the name here
app = Celery("parser_app")
# read config from Django settings, the CELERY namespace would make celery
# config keys has `CELERY` prefix
app.config_from_object('django.conf:settings', namespace='CELERY')
# load tasks.py in django apps
app.autodiscover_tasks(lambda: INSTALLED_APPS)
Импортируем celery приложени, чтобы оно запускалось вместе с django
# parser_app/__init__.py
from __future__ import absolute_import, unicode_literals
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ('celery_app',)4 Переходим к логике парсинга
Мы будем парсить сайт https://books.toscrape.com/ так как сайт предназначен для парсинга и не изменится. В HTTP POST запросе пользователь будет передавать название категории (напрмер, mystery_3)
Программа будет сохранять названия книг из этой категории
Начнем с создания модели данных
from django.db import models
class BaseTask(models.Model):
""" Celery task info"""
name = models.CharField(max_length=100)
is_success = models.BooleanField(default=False)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
def __str__(self):
return self.name
class BaseParsingResult(models.Model):
""" Parsing result details"""
task_id = models.ForeignKey(
BaseTask,
blank=True,
null=True,
on_delete=models.PROTECT
)
data = models.TextField(blank=True)
task_type = models.CharField(blank=True, max_length=64)
Изменения в urls.py файлах. У нвс будет всего один запрос task/ -- постановка задачи на пасинг и мониторнг результатов
# core_app/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('parser_app.urls'))
]# parser_app/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('task', views.task, name='task'),
]
В файле views.py описываем обработчик запроса task/
GET -- возвращает статус задачи, POST -- ставит задачу на парсинг
from django.shortcuts import render
from rest_framework.decorators import api_view
from rest_framework.response import Response
from celery.result import AsyncResult
from parser_app.tasks import create_task
@api_view(['GET', 'POST'])
def task(request):
if request.method == 'POST':
if "type" in request.data:
category_name = request.data["type"]
task = create_task.delay(category_name) # create celery task
return Response({"message": "Create task", "task_id": task.id, "data": request.data})
else:
return Response({"message": "Error, not found 'type' in POST request"})
if request.method == 'GET': # get task status
if "task_id" in request.data:
task_id = request.data["task_id"]
task_result = AsyncResult(task_id)
result = {
"task_id": task_id,
"task_status": task_result.status,
"task_result": task_result.result
}
return Response(result)
else:
return Response({"message": "Error, not found 'task_id' in GET request"})
Создаем файл tasks.py с описание логики работы задачи парсинга
import requests
import time
from lxml import etree
from datetime import datetime
from parser_app.models import BaseTask, BaseParsingResult
from core_app.celery import app
from django.core.cache import cache
def parse_data(celery_task_id: str, category_name: str):
new_task = BaseTask.objects.create(
name=celery_task_id,
)
new_task.save()
try:
response = requests.get(
f"https://books.toscrape.com/catalogue/category/books/{category_name}/"
)
if response.status_code == 200:
tree = etree.HTML(response.content)
results = tree.xpath("//article/h3/a")
for cur in results:
cur_parsing_res = BaseParsingResult.objects.create(
task_id=new_task,
data=cur.text,
task_type=category_name
)
cur_parsing_res.save()
except Exception as e:
print("Error: ", e)
else:
new_task.is_success = True
new_task.save()
@app.task(name='create_task', bind=True)
def create_task(self, category_name):
parse_data(self.request.id, category_name)
return TrueДобавляем в админку данные
from django.contrib import admin
from .models import BaseTask, BaseParsingResult
@admin.register(BaseTask)
class BaseTaskAdmin(admin.ModelAdmin):
list_display = ['id', 'name', 'is_success', 'created_at']
readonly_fields = ['created_at']
list_filter = ['is_success']
@admin.register(BaseParsingResult)
class BaseResultAdmin(admin.ModelAdmin):
list_display = ['id', 'task_id', 'data', 'task_type']Перезапускаем приложение.
5 Использование приложения
5.1 Запрос парсинга POST
# POST http://127.0.0.1:80/task
{
"type": "philosophy_7"
}
RESPONSE:
{
"message": "Create task",
"task_id": "062ac81f-dafe-4e2c-95e9-c042936e85f3",
"data": {
"type": "philosophy_7"
}
}5.2 Посмотрим результат задачи
# GET http://127.0.0.1:80/task
{
"task_id": "062ac81f-dafe-4e2c-95e9-c042936e85f3"
}
RESPONSE:
{
"task_id": "062ac81f-dafe-4e2c-95e9-c042936e85f3",
"task_status": "SUCCESS",
"task_result": true
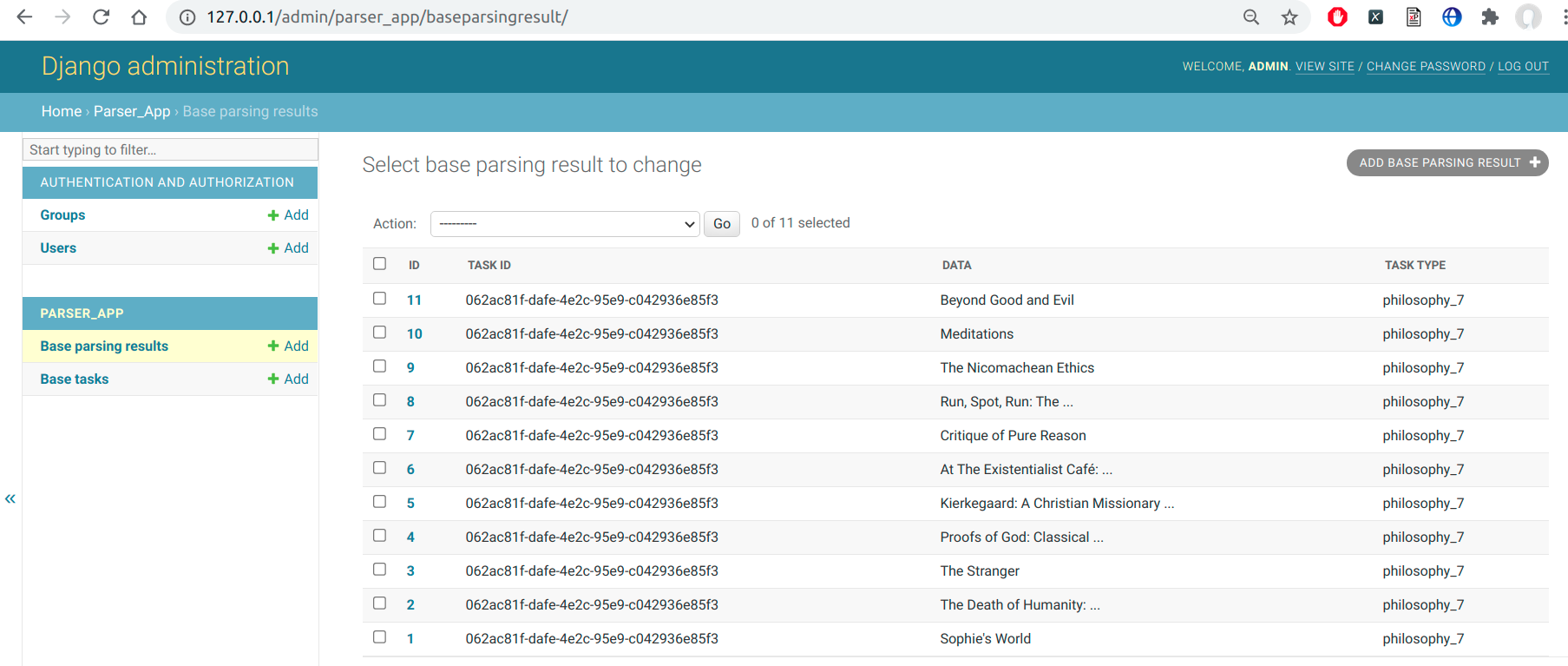
}5.3 Результаты работы в админке
Приложение готово!
Буду признателен за фидбек :-)
Комментарии (10)


TyVik
26.04.2022 13:57+2Поддержу комментарий выше про Scrapy. Это очень удобный фреймворк, в котором уже о многом позаботились за вас. Формат данных, ретраи, прокси... Стоит того, чтобы раз его изучить и пользоваться.
У меня была практика с подобной архитектурой как в статье, но под нагрузкой она легла. Каждые новые 16 воркеров Celery обходились в несколько сотен долларов из-за HIPAA compliance хостинга. В итоге всё переписал на aiohttp и сократил затраты примерно на порядок.

foxairman
26.04.2022 14:03+1Круто, спасибо! А есть способ заставить Django делать парсинг одной странички каждые 5 минут? Тут видимо какой-то таймер должен быть, который через API заставляет работать Django, но я не пойму как такое реализовать

mascai Автор
26.04.2022 16:37Celery позволяет запускать задачи с помощью планировщиков, таких как crontab в Linux.
Пример:
from celery.schedules import crontab CELERY_BEAT_SCHEDULE = { 'monday-task': { 'task': 'myproject.apps.tasks.task_name', 'schedule': crontab(day_of_week=1, hour=1) }, }


Buchachalo
27.04.2022 15:07А вы Django используете только ради админки или есть еще плюсы?
mascai Автор
27.04.2022 15:32Плюсы использования Django:
1) Готовые библиотеки для создания Rest API2) Возможность описывать модель данных через Django ORM
3) Готовая админка
Tinkz
Здравствуйте, не совсем понятно кто адресат данной статьи. Если для перехода от парсинга "для детей" к парсингу "для взрослых" - то совсем "галопом по европам". Не уверен что можно воспроизвести рабочий вариант следуя шагам описанным выше. Детализации не хватает на мой взгляд. Но в целом - спасибо, это действительно шаг вперёд в данной сфере.
mascai Автор
1) Адресаты - программисты, которые хотят научиться разрабатывать сложные парсеры (не просто скрипт, а полноценное веб-приложение с рест-апи, базой данных и асинхронными задачами)
2) "совсем галопом по европам" - согласен, что в статье раскрыты не все фишки, но главная цель статьи - это пошаговое руководство по созданию инфраструктуры для парсинга
3) Рабойчий вариант 100 % можно воспроизвести, так как шаг за шагом записывал свои действия))
Спасибо за фидбек)