
Когда я общаюсь с клиентами, они рассказывают мне о том, что их приложения работают в двух центрах обработки данных, но при более детальном изучении оказывается, что их стек наблюдения доступен только в одном из них.
Это знание, как откровение, снизошло на многих в марте 2021 года. Один из крупнейших европейских провайдеров облачных услуг (OVHcloud) пережил масштабный пожар в одном из своих дата-центров, что вызвало серьезные перебои в работе даже таких крупных клиентов, как правительство Франции.
На следующий день после инцидента мой коллега, отвечающий за управление качеством, спросил меня, сможем ли мы выдержать подобную катастрофу. Это побудило меня задуматься о превращении нашего единого стека мониторинга в стек высокой доступности, работающего на базе нескольких центров обработки данных.
К счастью, используемые нами инструменты, такие, как Grafana Tempo (для трассировки) и Grafana Loki для логирования, способны реплицироваться посредством микросервисов. Но сможем ли мы запустить несколько экземпляров их в нескольких разных ЦОДах? И в состоянии ли мы «безопасно» потерять компонент или целую площадку (другими словами, сохранится ли у нас при этом возможность просматривать, что происходит в наших приложениях)?
На недавней встрече Grafana Labs EMEA я рассказал об облачном стеке мониторинга на основе нескольких центров обработки данных, который мы развернули, так что ответы на все вышеперечисленные вопросы были "да!".
Ниже привожу последовательность действий.
Добавляем Consul
Я начал менять свой стек мониторинга и внедрил Consul, как инструмент обнаружения сервисов, имеющий открытый исходный код, со встроенным хранилищем значений ключ-значение и инструментарием для формирования mesh-сети сервисов, созданный и поддерживаемый компанией HashiCorp.
Мы может объявить сервисы в Consul, задав Grafana как сервис Consul при помощи такого блока JSON:
{
"service":
{
"checks":[{"http":"http://localhost:3000","interval":"10s"}],
"id":"grafana",
"name":"grafana",
"port":3000,
"tags":["metrics"]
}
}Это позволит Consul проверять работоспособность сервиса, отправляя http-запрос на локальный хост и сообщая о работоспособности сервиса остальным нашим платформам. После настройки мы сможем запрашивать Consul, аналогично любому другому DNS-серверу, о местонахождении вашего сервиса.
dig @127.0.0.1 -p 8600 grafana.service.consul ANYВы даже можете встроить Consul в работающий в вашем ЦОДе DNS-сервер bind или unbound.
Подключаемся к кластерам Consul
Consul можно сделать поддерживающим несколько центров обработки данных путем федерации кластеров, но он всегда использует данные из кластера в локальном ЦОД для хранения значений ключ-значение, и для ответа на запросы по поводу сервисов. В нашем примере у нас есть два центра обработки данных - условно называемые DC1 и DC2 - которые соединены.
Будучи соединенными, кластеры Consul знают друг о друге, но DNS-запрос не будет автоматически направляться от одного кластера к другому. Для этого нам нужен подготовленный запрос, который можно создать, отправив следующий блок JSON на ваш сервер Consul с помощью curl:
curl http://127.0.0.1:8500/v1/query --request POST --data @- << EOF
{
"Name": "grafana",
"Service": {
"Service": "grafana"
"Failover": {
"Datacenters": ["dc2"]
}
}
}
EOFПриведенный выше подготовленный запрос с названием "grafana" настроит два кластера таким образом, что в случае сбоя в DC1 DNS-запрос будет перенаправлен в DC2. Для службы Grafana в DC2 мы настроим противоположный запрос. При любом развитии событий, если произойдет сбой в работе службы, произойдет автоматическое переключение на вторую сторону, и никто этого не заметит, за исключением короткого промежутка времени, в течение которого Consul нужно будет принимать решение, что ваш сервис не работает в ближайшем (локальном) ЦОДе.
Подключаем отдельные экземпляры Grafana
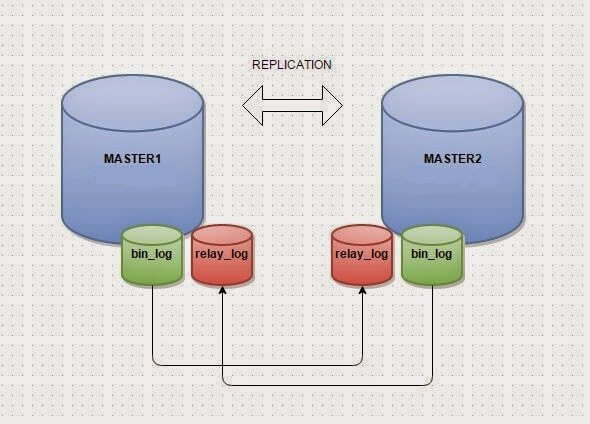
Теперь мне нужно было каким-то образом заставить два экземпляра Grafana взаимодействовать друг с другом. Grafana имеет три бэкенда баз данных: SQLite, PostgreSQL и MySQL. SQLite — это база данных, использующая в роли хранилища локальный файл на диске, что, очевидно, не способствует масштабированию. PostgreSQL не имеет репликации мастер-мастер в виде решения с открытым исходным кодом, поэтому всегда будет существовать «первичный» ЦОД и «вторичный» ЦОД, и некоторая задержка в записи данных между ними. Поэтому, я выбрал базу данных MySQL, которая имеет возможность репликации мастер-мастер. Grafana всегда будет записывать данные в локальный MySQL, а затем они будут копироваться в другой (удаленный) экземпляр, и наоборот.
Далее необходимо изменить источники данных в Grafana. Вместо того, чтобы задавать их в виде IP-адресов рядом расположенного Loki или Prometheus, вы легко можете использовать DNS-запись, которая была создана с помощью подготовленного запроса, в качестве адреса каждого источника данных (например, использовать loki.query.consul:3100 вместо 192.168.43.40:3100).
Подключаем Prometheus
Как добиться высокой доступности в Prometheus? Делать ли нам федерацию? Будем ли мы «читать дважды»? Будем ли мы «писать дважды»?
Для решения этого я предлагаю следующее: Prometheus, что удобно, имеет встроенную опцию работы с обнаружением сервисов в Consul. Так что, вместо того, чтобы иметь длинный список объектов для сканирования, я изменил конфигурацию DC1 так, чтобы он использовал ближайший (локальный) кластер Consul для обнаружения всех сервисов, объявленных в DC1, которые имеют тег "metrics", и уже эти сервисы будут сканироваться. В итоге всё, что находится в Consul с нужным тегом, автоматически собирается в Prometheus, и на основе этого можно создавать свои информационные панели. Для DC2 мы копируем конфигурацию и заменяем DC1 на DC2:
- job_name: DC1
scrape_interval: 10s
consul_sd_configs:
- server: localhost:8500
datacenter: dc1
tags:
- metrics
- job_name: DC2
...Подключаем Grafana Loki
Для Grafana Loki решение было простым: мы можем настроить локальный Promtail для отправки логов сразу на две точки назначения (обратите внимание: я использую здесь IP-адреса вместо запросов, поскольку хочу быть уверенным, что именно делаю запись дважды):
clients:
- url: https://192.168.43.40:3100/loki/api/v1/push
- url: https://192.168.43.41:3100/loki/api/v1/pushПодключаем Grafana Tempo
Grafana Tempo оказался самым сложным инструментом для настройки. Производя её, мы задавались одними и теми же вопросами, касающимися всего стека: отправлять ли данные дважды? Записывать ли данные дважды? Читать ли данные дважды?
Затем встал вопрос: нужно ли вводить прокси?
И здесь на помощь пришла конфигурация Grafana Agent:
tempo:
configs:
- name: default
receivers:
zipkin:
remote_write:
- endpoint: 192.168.43.41:55680
- endpoint: 192.168.43.40:55680В Grafana Agent v0.14 представили remote_write для Tempo, что сделало его отличным прокси - и именно тем, что нам было нужно.
В нашем случае, вместо того, чтобы напрямую отправлять данные в Tempo, все мои агенты трассировки используют в качестве конечной точки Grafana Agent, и затем пишут в оба моих экземпляра Tempo. Это требует небольшого изменения в конфигурации: Grafana Agent теперь имеет приемник, в данном случае Zipkin, и я пишу в две разные конечные точки. Одна из них находится в моем локальном центре обработки данных, другая - во втором (резервном) ЦОД-е.
Теперь мы будем использовать приемник для данных OpenTelemetry, который прослушивает разные конечные точки и разные порты, поэтому убедитесь, что ваши брандмауэры настроены соответствующим образом (на них ушли два часа моей жизни, которые уже никогда не вернуть!)
distributor:
receivers:
zipkin:
distributor:
receivers:
otlp:
protocols:
grpc:Подключаем Alertmanager
В случае с Alertmanager HA все намного проще! Вы запускаете его с дополнительнм флагом, который, по сути, гласит: «Я — кластер, и мои пиры живут на следующих портах». Затем они начинают общаться и дедублировать алерты. В Prometheus вам нужно будет добавить дополнительную цель в файл prometheus.yaml.
[Unit]
ExecStart=/usr/local/bin/alertmanager \
--config.file=/etc/alertmanager/alertmanager.yaml \
--storage.path=/var/lib/alertmanager \
--cluster.advertise-address=192.168.43.40:9094 \
--cluster.peer=192.168.43.41:9094
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.43.40:9093
- 192.168.43.41:9093Заключение
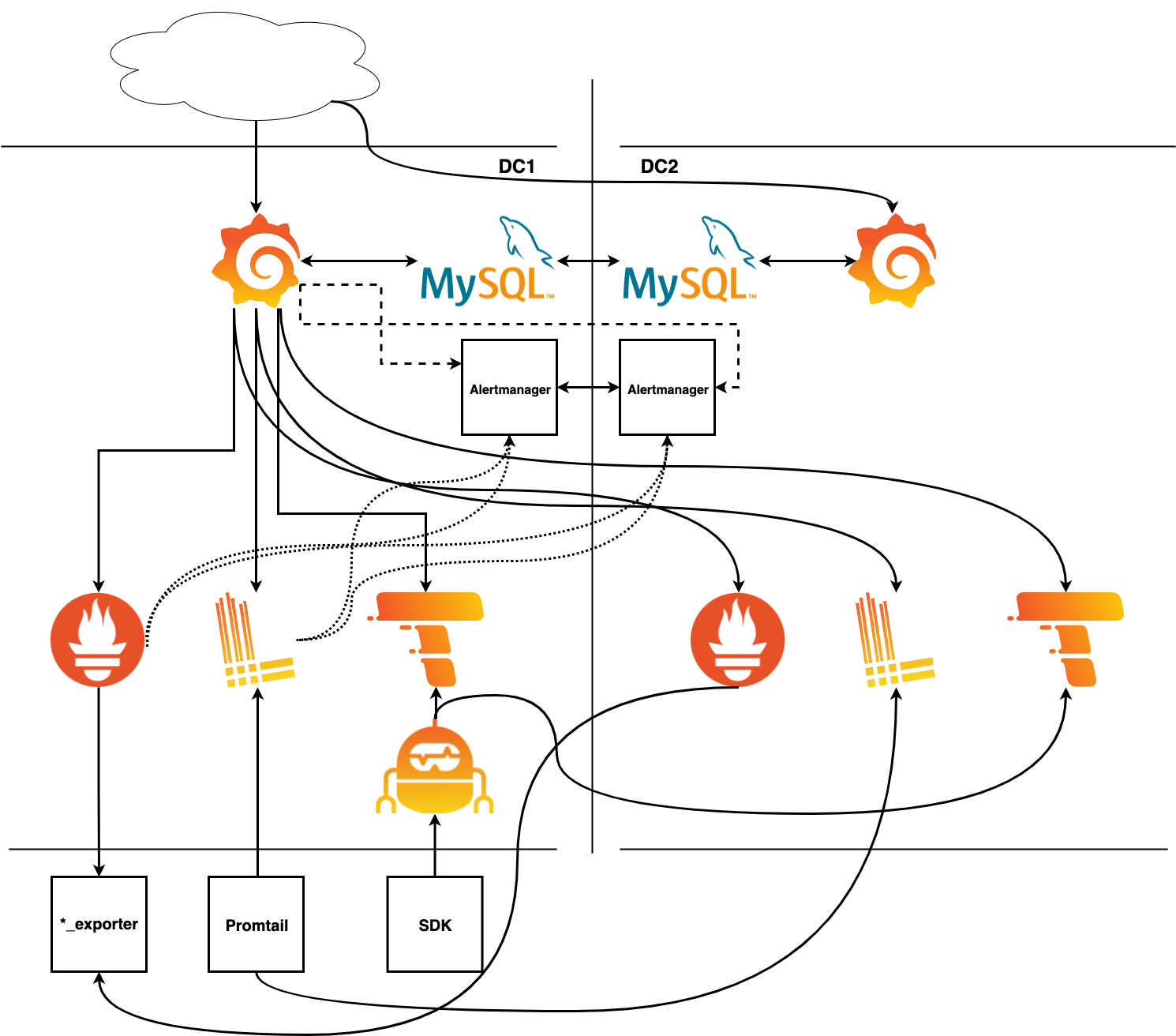
В моей полностью дублированной схеме мониторинга мне потребовалось копировать все строки кода, потому что это превратилось бы в один большой бардак. Вместо этого я добавил все необходимые дополнительные строки и все ключевые компоненты, чтобы один и тот же стек работал в двух разных центрах обработки данных. В итоге, теперь я могу уничтожить любой элемент или весь центр обработки данных, зная, что у меня все еще будет полностью функционирующий стек мониторинга.