
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревшими или "нежелаемыми".
Содержание статьи:
Вступление
ORM - это ужасный анти-паттерн, который нарушает все принципы объектно-ориентированного программирования, разбирая объекты на части и превращая их в тупые и пассивные пакеты данных. Нет никаких оправданий существованию ORM в любом приложении, будь то небольшое веб-приложение или система корпоративного размера с тысячами таблиц и манипуляциями CRUD с ними. Какова альтернатива? Объекты, говорящие на языке SQL (SQL-speaking objects).
Как работают ORM
Object-relational mapping (ORM) - это способ (он же шаблон проектирования) доступа к реляционной базе данных с помощью объектно-ориентированного языка (например, Java). Существует несколько реализаций ORM почти на каждом языке, например: Hibernate для Java, ActiveRecord для Ruby on Rails, Doctrine для PHP и SQLAlchemy для Python. В Java ORM даже стандартизирован как JPA.
Во-первых, рассмотрим на примере как работает ORM. Давайте использовать Java, PostgreSQL и Hibernate. Допустим, у нас есть единственная таблица в базе данных, называемая post:
+-----+------------+--------------------------+
| id | date | title |
+-----+------------+--------------------------+
| 9 | 10/24/2014 | How to cook a sandwich |
| 13 | 11/03/2014 | My favorite movies |
| 27 | 11/17/2014 | How much I love my job |
+-----+------------+--------------------------+Теперь мы хотим манипулировать этой таблицей CRUD-методами из нашего Java-приложения (CRUD расшифровывается как create, read, update и delete). Для начала мы должны создать класс Post (извините, что он такой длинный, но это лучшее, что я могу сделать):
@Entity
@Table(name = "post")
public class Post {
private int id;
private Date date;
private String title;
@Id
@GeneratedValue
public int getId() {
return this.id;
}
@Temporal(TemporalType.TIMESTAMP)
public Date getDate() {
return this.date;
}
public String getTitle() {
return this.title;
}
public void setDate(Date when) {
this.date = when;
}
public void setTitle(String txt) {
this.title = txt;
}
}Перед любой операцией с Hibernate мы должны создать SessionFactory:
SessionFactory factory = new AnnotationConfiguration()
.configure()
.addAnnotatedClass(Post.class)
.buildSessionFactory();Эта фабрика будет выдавать нам “сеансы” каждый раз, когда мы захотим работать с объектами Post. Каждая манипуляция с сеансом должна быть заключена в этот блок кода:
Session session = factory.openSession();
try {
Transaction txn = session.beginTransaction();
// your manipulations with the ORM, see below
txn.commit();
} catch (HibernateException ex) {
txn.rollback();
} finally {
session.close();
}Когда сеанс будет готов, вот так мы получаем список всех записей из этой таблицы:
List posts = session.createQuery("FROM Post").list();
for (Post post : (List<Post>) posts) {
System.out.println("Title: " + post.getTitle());
}Я думаю, вам ясно, что здесь происходит. Hibernate - это большой, мощный движок, который устанавливает соединение с базой данных, выполняет необходимые SELECT запросы и извлекает данные. Затем он создает экземпляры класса Post и заполняет их данными. Когда объект приходит к нам, он заполняется данными, и чтобы получить доступ к ним, необходимо использовать геттеры, как пример getTitle() выше.
Когда мы хотим выполнить обратную операцию и отправить объект в базу данных, мы делаем все то же самое, но в обратном порядке. Мы создаем экземпляр класса Post, заполняем его данными и просим Hibernate сохранить его:
Post post = new Post();
post.setDate(new Date());
post.setTitle("How to cook an omelette");
session.save(post);Так работает почти каждая ORM. Основной принцип всегда один и тот же — объекты ORM представляют собой немощные/анемичные (прямой перевод слова anemic) оболочки с данными. Мы разговариваем с ORM фреймворком, а фреймворк разговаривает с базой данных. Объекты только помогают нам отправлять запросы в ORM framework и понимать его ответ. Кроме геттеров и сеттеров, у объектов нет других методов. Они даже не знают, из какой базы данных они пришли.
Вот как работает object-relational mapping.
Что в этом плохого, спросите вы? Все!
Что не так с ORM?
Серьезно, что не так? Hibernate уже более 10 лет является одной из самых популярных библиотек Java. Почти каждое приложение в мире с интенсивным использованием SQL использует его. В каждом руководстве по Java будет упоминаться Hibernate (или, возможно, какой-либо другой ORM, такой как TopLink или OpenJPA) для приложения, подключенного к базе данных. Это стандарт де-факто, и все же я говорю, что это неправильно? Да.
Я утверждаю, что вся идея, лежащая в основе ORM, неверна. Его изобретение было, возможно, второй большой ошибкой в ООП после NULL reference.
ORM, вместо того чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм.
На самом деле, я не единственный, кто говорит что-то подобное, и определенно не первый. Многое на эту тему уже опубликовано очень уважаемыми авторами, в том числе OrmHate автора Martin Fowler (не против ORM, но в любом случае стоит упомянуть), Object-Relational Mapping is the Vietnam of Computer Science от Jeff Atwood, The Vietnam of Computer Science автора Ted Neward, ORM Is an Anti-Pattern от Laurie Voss и многие другие.
Однако мои аргументы отличаются от того, что они говорят. Несмотря на то, что их доводы практичны и обоснованны, например, “ORM работает медленно” или “обновление базы данных затруднено”, они упускают главное. Вы можете увидеть очень хороший, практический ответ на эти практические аргументы, от Bozhidar Bozhanov в его блоге ORM Haters Don't Get It.
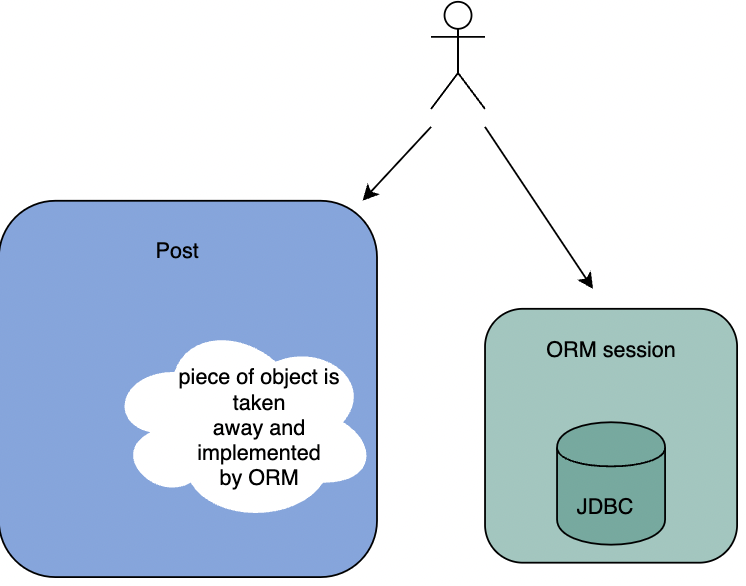
Суть в том, что ORM вместо того, чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм. Одна часть объекта хранит данные, в то время как другая, реализованная внутри механизма ORM (sessionFactory), знает, как обращаться с этими данными, и передает их в реляционную базу данных. Посмотрите на эту картинку; она иллюстрирует, что делает ORM.
Я, будучи читателем сообщений, должен иметь дело с двумя компонентами: 1) ORM и 2) возвращенный мне объект “ob-truncated”. Предполагается, что поведение, с которым я взаимодействую, должно предоставляться через единую точку входа, которая является объектом в ООП. В случае ORM я получаю такое поведение через две точки входа — механизм ORM и “предмет”, который мы даже не можем назвать объектом.
Из-за этого ужасного и оскорбительного нарушения объектно-ориентированной парадигмы у нас есть много практических проблем, уже упомянутых в уважаемых публикациях. Я могу добавить еще только несколько.
SQL Не Скрыт. Пользователи ORM должны говорить на SQL (или его диалекте, например, HQL). Смотрите пример выше; мы вызываем session.CreateQuery("FROM Post"), чтобы получить все сообщения. Несмотря на то, что это не SQL, он очень похож на него. Таким образом, реляционная модель не инкапсулируется внутри объектов. Вместо этого он доступен для всего приложения. Каждому, с каждым объектом, неизбежно приходится иметь дело с реляционной моделью, чтобы что-то получить или сохранить. Таким образом, ORM не скрывает и не переносит SQL, а загрязняет им все приложение.
Трудно протестировать. Когда какой-либо объект работает со списком записей, ему необходимо иметь дело с экземпляром SessionFactory. Как мы можем замокать эту зависимость? Мы должны создать имитацию этого? Насколько сложна эта задача? Посмотрите на приведенный выше код, и вы поймете, насколько подробным и громоздким будет этот модульный тест. Вместо этого мы можем написать интеграционные тесты и подключить все приложение к тестовой версии PostgreSQL. В этом случае нет необходимости имитировать SessionFactory, но такие тесты будут довольно медленными, и, что еще более важно, наши объекты, не имеющие ничего общего с базой данных, будут протестированы на экземпляре базы данных. Ужасный замысел.
Позвольте мне еще раз повторить. Практические проблемы ORM - это всего лишь последствия. Фундаментальный недостаток заключается в том, что ORM разрывает объекты на части, ужасно и оскорбительно нарушая саму идею того, что такое объект.
SQL-speaking объекты

Какова альтернатива? Позвольте мне показать вам это на примере. Давайте попробуем спроектировать класс Post. Нам придется разбить его на два класса: Post и Posts, единственное и множественное число. Я уже упоминал в одной из своих предыдущих статей, что хороший объект - это всегда абстракция реальной сущности. Вот как этот принцип работает на практике. У нас есть две сущности: таблица базы данных и строка таблицы. Вот почему мы создадим два класса. Posts будет представлять таблицу, а Post будет представлять строку.
Как я также упоминал в этой статье, каждый объект должен работать по контракту и реализовывать интерфейс. Давайте начнем наш дизайн с двух интерфейсов. Конечно, наши объекты будут неизменяемыми. Вот как будут выглядеть Posts:
interface Posts {
Iterable<Post> iterate();
Post add(Date date, String title);
} Вот как будет выглядеть один Post:
interface Post {
int id();
Date date();
String title();
}Вот так мы будем перечислять все записи в таблице базы данных:
Posts posts = // we'll discuss this right now
for (Post post : posts.iterate()) {
System.out.println("Title: " + post.title());
} Вот так создаётся новый Post:
Posts posts = // we'll discuss this right now
posts.add(new Date(), "How to cook an omelette"); Как вы видите, теперь у нас есть настоящие объекты. Они отвечают за все операции, и они прекрасно скрывают детали их реализации. Нет никаких транзакций, сеансов или фабрик. Мы даже не знаем, действительно ли эти объекты взаимодействуют с PostgreSQL или они хранят все данные в текстовых файлах. Все, что нам нужно от Posts - это возможность перечислить все записи для нас и создать новую. Детали реализации идеально скрыты внутри. Теперь давайте посмотрим, как мы можем реализовать эти два класса.
Я собираюсь использовать jcabi-jdbc в качестве оболочки JDBC, но вы можете использовать что-то другое, например jOOQ, или просто JDBC, если хотите. На самом деле это не имеет значения. Важно то, что ваши взаимодействия с базой данных скрыты внутри объектов. Давайте начнем с Posts и реализуем его в классе PgPosts (“pg” означает PostgreSQL):
final class PgPosts implements Posts {
private final Source dbase;
public PgPosts(DataSource data) {
this.dbase = data;
}
public Iterable<Post> iterate() {
return new JdbcSession(this.dbase)
.sql("SELECT id FROM post")
.select(
new ListOutcome<Post>(
new ListOutcome.Mapping<Post>() {
@Override
public Post map(final ResultSet rset) {
return new PgPost(
this.dbase,
rset.getInt(1)
);
}
}
)
);
}
public Post add(Date date, String title) {
return new PgPost(
this.dbase,
new JdbcSession(this.dbase)
.sql("INSERT INTO post (date, title) VALUES (?, ?)")
.set(new Utc(date))
.set(title)
.insert(new SingleOutcome<Integer>(Integer.class))
);
}
} Далее давайте реализуем интерфейс Post в классе PgPost:
final class PgPost implements Post {
private final Source dbase;
private final int number;
public PgPost(DataSource data, int id) {
this.dbase = data;
this.number = id;
}
public int id() {
return this.number;
}
public Date date() {
return new JdbcSession(this.dbase)
.sql("SELECT date FROM post WHERE id = ?")
.set(this.number)
.select(new SingleOutcome<Utc>(Utc.class));
}
public String title() {
return new JdbcSession(this.dbase)
.sql("SELECT title FROM post WHERE id = ?")
.set(this.number)
.select(new SingleOutcome<String>(String.class));
}
}Вот как будет выглядеть сценарий полного взаимодействия с базой данных с использованием только что созданных нами классов:
Posts posts = new PgPosts(dbase);
for (Post post : posts.iterate()){
System.out.println("Title: " + post.title());
}
Post post = posts.add(
new Date(), "How to cook an omelette"
);
System.out.println("Just added post #" + post.id());Вы можете увидеть полный практический пример здесь. Это веб—приложение с открытым исходным кодом, которое работает с PostgreSQL, используя точный подход, описанный выше, - объекты, говорящие на SQL.
Как насчет производительности?
Я слышу, как вы спрашиваете: “А как же производительность?” В этом сценарии, приведенном несколькими строками выше, мы совершаем множество избыточных обходов базы данных. Сначала мы извлекаем идентификаторы записей с помощью SELECT id, а затем, чтобы получить их заголовки, мы выполняем дополнительный вызов SELECT title для каждой записи. Это неэффективно или, проще говоря, слишком медленно.
Не беспокойтесь, это объектно-ориентированное программирование, а это значит, что оно гибкое! Давайте создадим декоратор PgPost, который будет принимать все данные в своем конструкторе и кэшировать их внутри навсегда:
final class ConstPost implements Post {
private final Post origin;
private final Date dte;
private final String ttl;
public ConstPost(Post post, Date date, String title) {
this.origin = post;
this.dte = date;
this.ttl = title;
}
public int id() {
return this.origin.id();
}
public Date date() {
return this.dte;
}
public String title() {
return this.ttl;
}
} Обратите внимание: этот декоратор ничего не знает о PostgreSQL или JDBC. Он просто декорирует объект типа Post и предварительно кэширует дату и заголовок. Как обычно, этот декоратор также неизменяем.
Теперь давайте создадим другую реализацию Posts, которая будет возвращать “постоянные” объекты:
final class ConstPgPosts implements Posts {
// ...
public Iterable<Post> iterate() {
return new JdbcSession(this.dbase)
.sql("SELECT * FROM post")
.select(
new ListOutcome<Post>(
new ListOutcome.Mapping<Post>() {
@Override
public Post map(final ResultSet rset) {
return new ConstPost(
new PgPost(
ConstPgPosts.this.dbase,
rset.getInt(1)
),
Utc.getTimestamp(rset, 2),
rset.getString(3)
);
}
}
)
);
}
} Теперь все записи, возвращаемые iterate() этого нового класса, предварительно снабжены датами и заголовками, полученными за одно обращение к базе данных.
Используя декораторы и несколько реализаций одного и того же интерфейса, вы можете создать любую функциональность, которую пожелаете. Что наиболее важно, так это то, что, хотя функциональность расширяется, сложность дизайна не возрастает, потому что классы не увеличиваются в размерах. Вместо этого мы вводим новые классы, которые остаются сплоченными и прочными, потому что они маленькие.
Что касается транзакций
Каждый объект должен иметь дело со своими собственными транзакциями и инкапсулировать их так же, как запросы SELECT или INSERT. Это приведет к вложенным транзакциям, что вполне нормально при условии, что сервер базы данных их поддерживает. Если такой поддержки нет, создайте объект транзакции для всего сеанса, который будет принимать “вызываемый” класс. Например:
final class Txn {
private final DataSource dbase;
public <T> T call(Callable<T> callable) {
JdbcSession session = new JdbcSession(this.dbase);
try {
session.sql("START TRANSACTION").exec();
T result = callable.call();
session.sql("COMMIT").exec();
return result;
} catch (Exception ex) {
session.sql("ROLLBACK").exec();
throw ex;
}
}
}Затем, когда вы хотите обернуть несколько манипуляций с объектами в одну транзакцию, сделайте это следующим образом:
new Txn(dbase).call(
new Callable<Integer>() {
@Override
public Integer call() {
Posts posts = new PgPosts(dbase);
Post post = posts.add(
new Date(), "How to cook an omelette"
);
post.comments().post("This is my first comment!");
return post.id();
}
}
);Этот код создаст новую запись и опубликует комментарий к ней. Если один из вызовов завершится неудачей, вся транзакция будет откачена.
Мне этот подход кажется объектно-ориентированным. Я называю это “объектами, говорящими на SQL”, потому что они знают, как разговаривать на SQL с сервером базы данных. Это их мастерство, идеально заключенное в их границах.
Комментарии (148)

Bromles
22.05.2022 02:18+6"We don't care which you choose, just don't choose an ORM" (c) Jake Wharton, Google & Alec Strong, Square, Inc.

sukhe
22.05.2022 10:36+19А можно я просто на SQL писать буду? Без всего этого лишнего обвеса.

udmiark
22.05.2022 13:45+2А как вы потом будете применять дополнительные изменения к запросу? Например у вас есть некоторый метод который подготавливает базовый запрос с условиями. Затем где то ещё потребовалось к этому запросу добавить ещё условий вынеся старые в отдельный OR и добавить группировку.
Или под каждую задачу запрос с нуля писать будете?

Dgolubetd
22.05.2022 17:23+5Уж лучше с нуля, чем Орм.
Если запрсы совсем большие и сложные, то проще написать хранимку/функцию.

mayorovp
22.05.2022 18:07+1Чем лучше-то?

inkelyad
22.05.2022 18:27+9Проблема в ловле дефектов и разбора происходящего в эксплуатации. Явно написанный SQL можно просто взять из кода, и выполнить (попросить выполнить тех людей, что продукт эксплуатируют) на боевой (или близкой к ней) базе, чтобы посмотреть, что там оно такое из базы прочитало. А вот с тем, что ORM построил - надо включать отладку для вывода этих запросов, потом продираться через дебри этого отладочного вывода, собирая только то, что имеет отношение к делу итд итп. В результате время на получение ответа 'что такого произошло, что мы имеем не то поведение, которое хотели' резко увеличивается.
mayorovp
22.05.2022 18:38+1Или же можно взять нормальные инструменты для отладки и увидеть всё то же самое независимо от способа построения запроса.
inkelyad
22.05.2022 18:40+2Нельзя. Потому что эксплуатация - она где-то там, у заказчика. И с инструментами для отладки тебя туда не пустят.
mayorovp
22.05.2022 18:42А с сырыми запросами что, пускают?..
inkelyad
22.05.2022 18:46+9Ну как... Говоришь "хочу результат такого запроса", они на него смотрят, решают, что он ничего плохого не сделает, выполняют.
Потом в результате затирают все, что тебе не положено видеть, присылают результат тебе. Далее цикл повторяется.
Dgolubetd
22.05.2022 19:26+4ORM не дает полного контроля над запросами и делает написание и отлаживание нетривиальных запросов намного сложнее.
Вот есть у меня колонка в Postgis типа geometry. А мне нужно вызвать на ней функцию, которая работает с geography, но так чтобы индекс использовался. Я иду, создаю функциональный индекс, а потом в запросе делаю каст типа column::geography. Все, работает, збс.
А ORM (привет sqlalchemy) мне не дает этот каст сделать. Делает более сложный каст, с параметрами, который индекс не использует.
Это только пример одной ОРМ. А у них у всех свои приколы.

kirillk0
23.05.2022 08:33+1А какой процент от всех запросов в приложении нетривиальные? Можно использовать orm для простых запросов, избавив кодовую базу от рутинного ручного CRUDа, а в тех редких случаях, когда это действительно имеет смысл, писать голый sql.
Bromles
23.05.2022 13:56В Джаве для этого есть Spring Data JDBC. Те же автоматическая десериализация, готовый круд, декларативные транзакции и тд, но запросы пишутся руками. Не отбирает контроль, облегчает жизнь
Но большинству макак слишком сложно, проще 100+ аннотаций для JPA навесить на энтити и потом месяц пытаться понять, почему все это работает не так, как ожидалось
Traxternberg
23.05.2022 10:23А потом это все саппортить будет? А потом у нас испортозамещение и отказ от Oracle и все хранимки переписывать, к примеру на по PostgreSQL Dialect.
Bromles
23.05.2022 13:53+1Мне больше нравится подход SQLDelight с мультиплатформы Котлина и JOOQ из Джавы. Когда разработчик руками пишет SQL-запросы, а библиотека по ним и миграциям генерирует энтити и методы в репозиториях для вызова этих запросов. Получается "ORM наоборот", который и не отбирает контроль, и не генерирует всякую хрень (чем славится тот же Hibernate), и при этом облегчает работу
tungus28
22.05.2022 02:24+10У Егора Бугаенко часто свой взгляд на программиррвание как таковое. Он может быть противоречивым, неявным, но никогда не скучным) Всегда слушаю его с интересом, и жду следующей лекции под названием "ООП - зло, нас ждет тернистый путь обратно к процедурному программированию"))

BugM
22.05.2022 02:27+1Функциональное программирование пихают уже везде. И если не перебарщивать, то код заметно лучше становится.

0xd34df00d
22.05.2022 05:22+31Процедурное программирование — не то же самое, что функциональное.

vkni
22.05.2022 22:31Опять надо выступать в стиле "Карл Маркс и Фридрих Энгельс — это не муж и жена, а четыре разных человека". В смысле, ООП, процедурное, функциональное и декларативное — это совершенно разные языки, очень плохо выразимые друг через друга.

sshikov
22.05.2022 09:48+24>но никогда не скучным)
Ну, может вам и нескушно, я верю. Обычно целью желтой прессы (а тут именно она) является как раз развлечь. Но когда большинство концепций либо ничем не подтверждены, либо разваливаются при первой же попытке проверить практикой — это называется балабол, а не «свой взгляд на программирование». Взгляд все же предполагает некоторое исследование, доказательства и т.п. И если мне пишут «ORM зло», я как минимум ожидаю, что будут приведены явные и несомненные плюсы ORM — потому что иначе это автоматически пустопорожняя болтовня, а всех остальных (кто успешно применяет) автор считает идиотами. Я же предпочитаю подход, что если кто-то применяет технологию в приложении (а таких людей много), то априори им лучше знать про свои приложения, а идиот как раз вероятно автор утверждения.
Ну вот вам пример: «Нет никаких оправданий существованию ORM в любом приложении». Простите, но с каких пор Бугаенко разрешили утверждать за любое приложение? Мои приложения он в глаза никогда не видел, и не знает, приносит ли мне ORM пользу, или же вред. Поэтому данный взгляд идет лесом, а применять ли ORM, какую именно, и какую пользу я собираюсь получить — я уж решу сам.
>«ООП — зло, нас ждет тернистый путь обратно к процедурному программированию»))
Ну да, чисто ради поржать я бы тоже на такое посмотрел бы. Но этот жанр же называется «клоунада», не так ли?
pin2t
22.05.2022 10:02-17Но когда большинство концепций либо ничем не подтверждены, либо разваливаются при первой же попытке проверить практикой — это называется балабол, а не «свой взгляд на программирование».
Тут вы как раз в корне неправы. Егор практикующий программист, он пишет кода больше чем вся ваша команда, скорее всего. Посмотрите на его проекты на гитхабе, какой там код (не библиотеки типа cactoos, там как раз странновато, а прикладные проекты вроде zold и других). Там код на голову лучше чем в любом проекте на spring boot с ORM. Свой взгляд он как раз доказал практически много раз.
sshikov
22.05.2022 10:10+30>Егор практикующий программист, он пишет кода больше чем вся ваша команда, скорее всего.
Заметьте, это — такое же точно ни на чем не основанное утверждение, как и «ORM зло». Еще раз уточню — у меня претензия не к тому, что ORM бывает лишним звеном, у меня претензия к попытке обобщить это на все проекты, включая например мой (которого ни вы ни он в глаза не видели).
Что ORM бывает лишним — это как раз аксиома, любой инструмент нужно применять по делу. И в текущем проекте у меня ORM нет. Только я это не обобщаю вообще никуда.
Ложь в том, что ORM якобы зло всегда. Если вы пытаясь доказать это утверждение, и не способны (а точнее даже не пытаетесь) сформулировать ни одного плюса ORM — я почти на 100% уверен, что тут налицо подтасовка.
TimsTims
23.05.2022 01:19+2Соглашусь с вами. Сам не сторонник ORM, он зачастую вреден в больших проектах. Запросы тормозят, а узкое место - базы данных. Если при большой нагрузке серваков можно наклонировать и запараллелить, то с базами это делается намного сложнее.
Небольшие проекты с терпимыми нагрузками - прекрасно ложится ORM. Быстрое прототипирование, десятки/сотни CRUD-ов и вот рабочее приложение готово. Тяп-ляп готово.
Когда приложение большое, а данные приложения потом использует аналитический отдел, когда тебе нужно строить многоэтажные запросы, которые выдадут пользователю сложный набор данных, то никакой ORM не сравнится по производительности правильно написанному запросу, который потом идеально адаптирует планировщик запросов СУБД.
Могу ошибаться, но на своей практике, чаще всего, когда я встречаю ярых поклонников ORM, то часто так оказывается, что они просто не понимают СУБД, их плюсов, им нет особо дела до производительности (ведь это дело девопсов, пусть просто добавят серваков если тормозит), не хочется загрязнять код SQL-ем (тут можно понять), или им просто лень писать запросы (тоже понимаю, лень - двигатель прогресса, но везде нужен баланс).
sshikov
23.05.2022 19:37+1Ну да, в какой-то степени все это имеет место. Но заметьте, разница между вашим утверждением «зачастую вреден в больших проектах» и утверждением «ORM зло» — весьма существенная.
pin2t
23.05.2022 11:43-3мой (которого ни вы ни он в глаза не видели).
Вот именно что не видели. Дайте ссылку на гитхаб, и мы сравним, какой подход лучше. Иначе это просто балабольство, мол есть где-то какой-то мифический код, в котором очень удобно и красиво применяется ORM. Дайте ссылку
У Егора таких ссылок много, ссылок на его реализацию в реальных работающих проектах. Пока что все что я видел из ORM реализаций - код с ORM хуже по качеству на порядок, чем код без ORM. Менее поддерживаемый, расширяемый и тормозит.

agoncharov
23.05.2022 06:35+7Конечно он пишет много кода. Даже в этих элементарных примерах такая огромная простыня получается. Причём описанный подход совершенно не гибкий, на реальных примерах все будет гораздо хуже

CrocodileRed
22.05.2022 10:35-12Я вытираю попу грушами. Это моя попа, он мою попу не видел потому откуда ему знать что это плохо :-)))

gian_tiaga
22.05.2022 11:02+13Тогда и статью можно описать так: я нелюблю груши, нет ни одной причины для того, чтобы другие их ели.
CrocodileRed
22.05.2022 11:07-6Я вижу разницу между высказынием своего мнения и критикой чужого с использованием вот таких аргументов.

jdev
24.05.2022 02:51+1Бесстыжий плаг
Взгляд все же предполагает некоторое исследование, доказательства и т.п
я как минимум ожидаю, что будут приведены явные и несомненные плюсы ORM
Тогда вам, возможно, больше понравится мой пост против JPA, где я и признаю бесспорные плюсы JPA, и, на мой взгляд, аргументированно критикую её подход.Есть ещё черновик поста с критикой подхода к моделированию данных связным графом объектом.
В качестве альтернативы я предлагаю использовать Агрегаты и Spring Data JDBC.
К текущему моменту, я применил Spring Data R2/JDBC в 4 коммерческих проектах, есть определённы сложности (больше всего не хватает Specification), но в целом доволен и намерен и дальше использовать их в качестве технологии работы с БД по умолчанию.
sshikov
24.05.2022 21:34Ну, ваш пост не портит даже то, что вы декларируете ненависть к хибернейту в самом начале. Ненавидеть технологию вполне нормально, это даже совершенно не мешает ей пользоваться. Единственное, что я для себя еще отмечал:
>нанять разработчика, знающего JPA не проблема — берёте с любого рынка и с вероятностью 99% он имеет хоть какой-то опыт работы с JPA;
Пожалуй, когда я имею выбор, т.е. если меня хантят, а не я сам ищу работу, я склонен игнорировать предложения работы, где мне либо предлагают нелюбимые технологии, либо просто не оставляют выбора (очень типично например звать архитектором, при этом озвучивая весь стек до мелочей, включая JPA). Ну т.е. JPA — это такая надоевшая всем рутина, которая при упоминании в описании может где-то оттолкнуть кандидата.
Есть какие-то нюансы, с которыми я не согласился бы — но это тоже нормально.

ryanl
22.05.2022 10:09+13Бугаенко просто пиарит сам себя, пытаясь на эпатажных идеях привлечь внимание к своей персоне. Не воспринимаю его как инженера, только как бизнесмена/руководителя.
Линус Торвальдс, демонстрирующий фак в сторону Nvidia (известный мем) и Бугаенко, пытающийся сделать какой-то эпатажный вброс против идей, сформированных на базе многолетнего опыта инженерного комьюнити - небо и земля. Егор сам упоминал, что ему перестали приглашать на конфы в Голландии.
sshikov
22.05.2022 10:12+7>эпатажный вброс против идей, сформированных на базе многолетнего опыта инженерного комьюнити
Вот именно. «ORM зло» — и при этом даже нет попытки описать плюсы и минусы, которые есть у каждого подхода. Тогда как правильный, инженерный подход выглядит так: список плюсов, список минусов, условия, при которых плюсы перевешивают — выводы о рациональности применения. А в таком виде — не более чем пиар.

Nialpe
22.05.2022 14:23+9Невольно вспоминается диалог из "Пиратов Карибского моря" (не применительно к Егору или автору - о их способностях судить не берусь - не доводилось вместе работать):
Вы самый жалкий пират, о котором я слышал!
Но вы хотя бы слышали обо мне...

Palmar
22.05.2022 19:04-3Егора перестали приглашать в первую очередь из-за его абсолютно людоедских политических взглядов.

RH215
22.05.2022 05:01+13Главная проблема ORM в том, что альтернативы получаются ещё хуже.

SporeMaster
22.05.2022 11:22-11>Главная проблема ORM в том, что альтернативы получаются ещё хуже.
Потому что корень зла в РСУБД, а не способах доступа к ним. В адекватном мире у РСУБД рыночная доля уже давно должна быть 5-10%.
Монго с его родным API тоже альтернатива ORM, уже без костылей (хотя и со своими минусами, есно)

FanatPHP
22.05.2022 12:02+10"Минусами"?
Решето — это тоже альтернатива ведру, хотя и со своими минусами. Почему вы никогда не должны использовать MongoDBSporeMaster
22.05.2022 20:36-7Одна web-макака 8 лет назад запретила всем использовать монго (2.6 небось?), потому что её проект был под Neo4j (который тоже рулез), другая вебмакака в 2022 ссылается на неё как на истину в последней инстанции. Эхехе...
RH215
22.05.2022 15:54+3Нет, спасибо. Стадию NoSQL все уже прошли лет этак 10 назад.

mvv-rus
22.05.2022 17:04Кто когда, и по-разному для разных NoSQL.
Например, сетевая (и иерархическая, являющаяся ее подмножеством, но хорошо ложившаяся на архитектуру тогдашней дисковой подсистемы) модель СУБД — это наследие далекого прошлого, когда теоретические работы Кодда ещё не были воплощены в коммерческие программы.
Я-то, по молодости лет, успел поработать только с индексно-последовательными наборами данных (это не совсем СУБД), но были люди, которые работали и с полноценными до-реляционными СУБД.
Ну, а на ПК, уже в 90-х, можно было столкнуться с нереляционной (тоже сетевой) СУБД dbVista (переименованную впоследствии в Raima Database Manager).
Ну, и MS-овский движок ESE (это — конец 90-х, на его базе реализованы AD, Exchange и куча системных служб Windows Server) — он тоже, по имеющейся у меня информации, сетевой (но это неточно — сам я под него не программировал).sshikov
22.05.2022 19:06+5Ну, в каких-то областях (графовые, например, или timeseries) NoSQL конечно живее всех живых. Но с другой стороны, вот поработал я как-то с Onetick, на сравнительно малых объемах, и понял простую вещь — что реляционные СУБД при некоторой настройке спокойно переваривают нынче огромные объемы timeseries данных, и настройка эта достаточно тривиальна — потому что паттерны доступа к данным зачастую типовые, данные за сегодня нужны в одном виде, а данные за месяц назад уже практически являются холодными, и нужны очень редко. И простое партиционирование спокойно поднимает производительность реляционной СУБД до производительности специализированной, а инструменты для работы со всем этим остаются такими же — SQL.
Причем в контексте данной темы мисматч между моделью графовой или timeseries БД и кодом (ООП или что там у нас) все равно остается, просто принимает другую форму.
RH215
23.05.2022 01:58Стадию "NoSQL заменит РСУБД", которая частенько звучала в формате "все переезжаем на MongoDB". Закончилось всё тем, что проблемы РСУБД решили и окзалось, что просто существуют разные типы СУБД для разных задач и наборов данных. Причем, РСУБД - всё ещё самый гибкий и универсальный.

nin-jin
23.05.2022 08:07-3Самый гибкий и универсальный - мультипарадигменные субд. Обычно они строятся на базе документных.

kasthack_phoenix
22.05.2022 06:48+15Автор претендует на критику ORM, но недоволен почему-то именно Hibernate:
SQL Не Скрыт.
Hibernate-специфичная проблема. В каком-нибудь дотнете все ORM предоставляют к базе тот же интерфейс построения запросов, что даёт LINQ(ближайшим аналогом в Java будет Streams) к объектам.
Трудно протестировать.
Аналогично. EF предоставляет in-memory провайдера, задуманного специально для тестирования — БД мокается List'ами для каждой таблицы.
Java-экосистему я особо не знаю, но, скорее всего, там в 2022 похожие инструменты уже есть и автору стоило бы просто слегка расширить кругозор.

impwx
22.05.2022 09:30+4При том, что я люблю EF и много лет использую его в продакшене, конкретно эти претензии вполне справедливы.
Например, SQL иногда действительно просачивается в LINQ-запросы: DbFunctions, EF.Functions. У каждого провайдера БД этот набор функций может быть свой.
По той же причине тестирование на in-memory-провайдере покрывает далеко не все. Перечисленные выше функции не имеют реализации и "работают" только при трансляции в SQL, а при попытке действительно вызвать их на LINQ to Objects вы получите ошибку. И наоборот — относительно легко написать запрос, который выполнится на объектах в памяти, но не сможет быть транслирован в SQL.
kasthack_phoenix
22.05.2022 14:46+5SQL иногда действительно просачивается в LINQ-запросы
Просачивается, абстракции не идеальны и протекают, но значительную часть приложений можно написать без единого упоминания DbFunctions.
По той же причине тестирование на in-memory-провайдере покрывает далеко не все
Да, но, опять же, если шлёпать очередной CRUD, а не пытаться заставить ORM генерировать конкретный сложный запрос с оптимальным планом выполнения, он покрывает подавляющую часть случаев.
ORM, в первую очередь, это же средство ускорения и упрощения разработки, а не файн-тюнинга. Сервис с множеством примитивных операций и небольшим количеством сложных запросов заметно проще сделать и протестировать на ORM, вставив сырые запросы в критичных местах, чем закатывать солнце вручную везде.

Nognomar
22.05.2022 10:10+10У меня, как у шарписта/дотнетчика тоже на моменте с "не скрытым sql" возникли вопросы к автору оригинального текста. Проблемы и недостатки конкретной реализации приписывать всему orm, ну такое

ApeCoder
23.05.2022 09:18Так в C# то же самое. Автор просто не понял что HQL объектный поверх объектов




DarthVictor
22.05.2022 09:38+1Интересный взгляд, а есть возможность в какой-нибудь экосистеме просто писать в коде типизированный SQL, желательно с учётом диалекта конкретной СУБД?
Вроде ближе всего java'вый JOOQ, у .NET есть EF, хотя там всё-таки довольно толстая прослойка, хоть и качественная.

rdo
22.05.2022 09:46+3JPA metamodel, но вам это не понравится.
Root<Student> root = criteriaQuery.from(Student.class); criteriaQuery.select(root).where(cb.equal(root.get(Student_.gradYear), 2015));Все типизировано, но невероятно многословно, поэтому им мало кто пользуется.

snuk182
22.05.2022 22:38+2Не сколько потому что многословно, сколько из-за фигово документированного API, которое создавал надмозг. JOINы там крайне нелогичны, а от вложенных запросов умирают котята.
0xd34df00d
22.05.2022 09:47+1Например, есть opaleye, но он заточен конкретно под постгрес.
vkni
22.05.2022 22:33Это DSL — то есть, мы не пытаемся на языке ООП выражать SQL запросы. :-)
0xd34df00d
22.05.2022 22:43Ну, это eDSL, так что запросы мы пишем на том же языке, на котором потом обрабатываем их результаты и пишем всю прочую логику.
vkni
22.05.2022 22:57Я имею ввиду, что мы не скованы ограничениями lambda-calculus'а. Мы используем наилучший инструмент под эту конкретную задачу — передачи информации от мозгов программиста к базе данных.
Да, то, что это всё ещё Хаскель имеет свои положительные стороны. Как, впрочем, и отрицательные. :-)
sshikov
22.05.2022 09:55+1Ну, многие пытаются, но редко получается совсем полноценно. Выж понимаете наверное, что если мы не пытаемся жить только в рамках некоего стандарта (а какого? SQL-92 уж больно старый, а SQL-2016 кто-то уже поддерживает? И много их таких?), то там или сям будут вылезать функции и процедуры в базе, без которых жить сложно, но про которые инструмент не знает.
И потом, вы вообще уверены, что они (функции) строго типизированы, и их получится обернуть в Java или c#, так чтобы типы параметров и результата можно было предсказать или вывести? Ну даже JOOQ возьмите, вы же догадываетесь, что при каждом вашем рефакторинге нужно по хорошему слазать в СУБД, и посмотреть, а не изменились ли типы данных в таблице? И тут сразу возникает вопрос — а в какой таблице, в нашей базе разработки, или в проме?
В общем, тут есть ряд идеологических проблем, которые с существующими СУБД вряд ли вообще преодолимы до конца.mayorovp
22.05.2022 10:40+1Если в СУБД в таблицах могут внезапно изменяться типы данных — проблема вовсе не в инструментах.
sshikov
22.05.2022 11:07+1А что вы предлагаете делать? Я такое в жизни видел десятки раз. Причина совершенно простая — есть интеграция между двумя системами, в одной нужно было что-то поменять, информация до второй просто не дошла — вполне типовая проблема коммуникации. И даже если не внезапно — ну если вас за месяц предупредили, все равно ведь код, котором типы данных СУБД зашиты статически, придется перекомпилировать.
Мы же не можем запретить ALTER TABLE в чужой системе, не так ли? Так что по крайней мере гипотетически SQL имеет вот такую вот типизацию, и нам с ней так или иначе нужно жить.mayorovp
22.05.2022 11:27+3Вы же понимаете, что если есть программа, которая обращается к чужой БД, и схему этой чужой БД поменяли — то перекомпиляция программы будет наименьшей из проблем? А основной проблемой будет то, что старая версия программы просто перестанет работать, и не важно ORM там использовалась или что-то другое.
По-хорошему, интеграцию между системами надо делать не одной программой "БД-БД", а двумя. Первая экспортирует данные, вторая импортирует, между ними — заранее согласованный формат данных. CSV там, XML или JSON с вполне определённой схемой.
sshikov
22.05.2022 11:57+1>перекомпиляция программы будет наименьшей из проблем?
Конечно. Еще раз, на всякий случай — я просто констатирую тот факт, что любая ORM как правило имеет дело в объектами, чьи типы данных зафиксированы при компиляции. Соответственно, для нее изменение типа данных в базе — повод перекомпилировать. Это просто такой факт. Изменение типов бывает, и влечет за собой перекомпиляцию, динамически обработать такой в программе скорее всего будет невозможно. Это недостаток ORM? По мне так нет — скорее это фича. Поэтому у меня, в текущем проекте, где требование динамической обработки изменения типов имеет место, ORM и нет.
>Первая экспортирует данные, вторая импортирует
Ну, наверное во многих случаях да, но вот у меня есть система, где суточный поток данных по одной таблице — порядка десятков терабайт. Никакие JSON тут рядом не валялись, единственное что можно, кроме собственно JDBC (ну или другой какой протокол похожего уровня) — это Golden Gate, причем даже его приходится хардкорно тюнить, потому что хрен вы на стандартных настройках такое перекачаете. То есть исключения тоже можно найти, не говоря уже о придумать.mayorovp
22.05.2022 13:05Что-то мне кажется, что при таких потоках данных уже и JDBC становится узким местом из-за привычки всё упаковывать и нагружать сборщик мусора.
А вот промежуточный формат данных узким место не будет, если вместо перечисленных мною ранее взять что-нибудь бинарное.
И да, я бы на вашем месте был сильнее всех прочих комментаторов заинтересован в типизации SQL, потому что остановка потока в пару десятков терабайт в день из-за несовпадения типов звучит очень страшно.
sshikov
22.05.2022 13:13>уже и JDBC становится узким местом
Ну в общем так и есть. Тупо вытащить такой объем целиком — я бы на это бы посмотрел с большим интересом.
>взять что-нибудь бинарное
Kafka Connect активно применяется. Насколько я понимаю, внутри кафки не JSON. И это в чем-то похоже на ваше предложение.
0xd34df00d
22.05.2022 21:16типы данных зафиксированы при компиляции. Соответственно, для нее изменение типа данных в базе — повод перекомпилировать.
Зачем, если можно просто вычислять всё в рантайме, а в компилтайме проверять корректность вычислений в зависимости от схемы?
Да-да, завтипы.
sshikov
22.05.2022 21:57>Зачем
Ну тут скорее не «зачем», а «так достаточно типично». Опять же, завтипы — а где они есть, из того что широко применяется?
>в компилтайме проверять корректность вычислений в зависимости от схемы?
Я бы с интересом посмотрел на то, как вы себе это представляете. Но, в тоже время: у нас на сегодня среда разработки и рантайм — это две физически разные сети. То есть, при компиляции мне недоступна реальная схема промышленной БД. И не будет никогда, если реалистично смотреть на вещи.
Я бы конечно хотел бы иметь копию в среде разработки — но при всем моем желании, у меня сотни интеграций (и +50 в год как-то называли темпы роста), поэтому схемы всех этих 150 или там 200 баз при компиляции мне не будут доступны никогда, а те, что доступны, очень сложно поддерживать в актуальном состоянии. Не хочу сказать, что у многих так, ситуации бывают разные, но в том числе очевидно и такие, когда при разработке и компиляции живой базы нет, потому что это «чужая» система.0xd34df00d
22.05.2022 22:12+1Опять же, завтипы — а где они есть, из того что широко применяется?
Мы обсуждаем принципиально возможные пути решения проблемы, или кто там в среднем что делает? Потому что если это второе, то люди в среднем не заморачиваются солидами, паттернами, полноценным тестированием, етц, и разговор можно завершать и идти дальше таскать таски в джире.
Олсо, у меня есть чувство, что для подавляющего большинства применений хватит более слабых систем типов вроде чего-нибудь хаскелевого, но доказывать это я не буду.
Я бы с интересом посмотрел на то, как вы себе это представляете.
Точно так же, как вы можете получить форматную строку для printf'а в рантайме, и сделать вызов printf'а в рантайме, но проверить соответствие аргументов строке в компилтайме.
sshikov
22.05.2022 23:01+1> принципиально возможные пути решения проблемы
Я таки не очень понимаю, о каких практических путях вообще речь? Ну вот что мне даст хаскель с его системой типов, для определенности, в ситуации, когда на входе у меня некая реляционная база, о которой на момент компиляции я не знаю ничего? Ну т.е. в рантайме мы можем выполнять запросы (но заранее не известно, какие), а при компиляции — просто ничего не знаем, кроме того, что она будет (но это неточно).0xd34df00d
22.05.2022 23:10+2А что вы вообще собрались делать с базой, о которой вы вообще ничего не знаете?
sshikov
23.05.2022 19:42Ну например реплицировать. Не, я понимаю что это на самом деле редкая задача, но бывает. И она довольно таки навороченная, если реплика должна вам что-то гарантировать.
На самом деле я просто крайний случай привожу, но по факту же вам никто не гарантирует, что таблица, которая существовала при компиляции, не пропадет (сама, или доступ к ней) в рантайме. Ну т.е. в нашем случае есть репликация из других систем, у нас нечто что называют DWH, или там озеро данных, кому как нравится. И никто нам из других систем в общем случае ничего не гарантирует — и для интеграционных проектов это вполне типовая ситуация.

AnthonyMikh
23.05.2022 03:03+1Поэтому у меня, в текущем проекте, где требование динамической обработки изменения типов имеет место, ORM и нет.
У меня вопрос: что это за проект такой, где схема базы меняется достаточно часто, чтобы типы мешали с этой БД работать?
sshikov
23.05.2022 19:45-1На самом деле в какой-то степени — любой интеграционный. То есть схема не наша, мы ее не контролируем. Этого достаточно, чтобы априори известным типам нельзя было полностью доверять. Только тем, что мы реально видим в базе.
mvv-rus
22.05.2022 17:14Вы же понимаете, что если есть программа, которая обращается к чужой БД, и схему этой чужой БД поменяли — то перекомпиляция программы будет наименьшей из проблем? А основной проблемой будет то, что старая версия программы просто перестанет работать, и не важно ORM там использовалась или что-то другое.
Изначально СУБД как идея задумывалась как средство избежать перекомпиляции (и, тем более — переписывания) программ при изменении конкретных форматов хранения данных. Но изменения схемы БД для этого должны быть, конечно, ограничены чем-то типа Open/Close принципа из SOLID. При бесконтрольных и неограниченных изменениях схемы перекомпиляции (а то и переписывания) избежать, конечно, не удастся.
Остается только убедить разработчиков не менять схему слишком уж радикально.mayorovp
22.05.2022 18:10+2Смотрите, если схема СУБД изменена таким образом, что программа осталась рабочей — то и перекомпилировать её не нужно. Если стала нерабочей — то одной перекомпиляцией не отделаться, надо программу исправлять.
Это не зависит от того, используется ли ORM или другие способы типизации запросов в программе. То есть необходимость перекомпиляции вообще не является недостатком ORM.
mvv-rus
22.05.2022 18:53-2Перекомпиляция — это больше про прежние времена, когда данные хранились в файлах, и никакой программно-доступной схемы для этих файлов не было.

makkarpov
22.05.2022 13:12+2Выж понимаете наверное, что если мы не пытаемся жить только в рамках некоего стандарта (а какого? SQL-92 уж больно старый, а SQL-2016 кто-то уже поддерживает? И много их таких?), то там или сям будут вылезать функции и процедуры в базе, без которых жить сложно, но про которые инструмент не знает.
В рамках того, что предоставляет СУБД XXX версии не ниже YY.ZZ. Пытаться абстрагироваться от конкретной СУБД - прямой путь к тому, что ничего сложнее JOIN-а использовать не получится.
И потом, вы вообще уверены, что они (функции) строго типизированы, и их получится обернуть в Java или c#, так чтобы типы параметров и результата можно было предсказать или вывести?
У JOOQ есть кодогенератор, который берет схему БД и генерирует классы, её описывающие. Таким образом ваш код всегда синхронизирован со схемой БД, и если она поменялась - код просто не скомпилируется, пока не исправите.
Ну даже JOOQ возьмите, вы же догадываетесь, что при каждом вашем рефакторинге нужно по хорошему слазать в СУБД, и посмотреть, а не изменились ли типы данных в таблице? И тут сразу возникает вопрос — а в какой таблице, в нашей базе разработки, или в проме?
Для этого кодогенератор запускается относительно текущих миграций, существующих в проекте. И (1) либо при запуске мигратор выдаст ошибку (если состояние отличается от ожидаемого), (2) либо схема будет точно соответствовать, поскольку миграции идентичны, (3) либо кому-то надо отрубить
рукидоступы, чтобы в прод в обход миграций не лез.sshikov
22.05.2022 13:22+1Так я не говорил, что эти проблемы не решаются. Я просто констатирую, что если мы живем в такой ситуации — то нам ORM не особо годится. Но это не недостаток ORM, это называется ограничение. Ну т.е. например, у меня просто в задании написано, что миграции в БД источника данных мы должны обрабатывать на лету, а на кодогенерацию у нашей команды просто нет ресурсов, потому что у нас сотни интеграций, при этом людей всего меньше десяти. Поэтому мы делаем код на голом JDBC, который динамически строит запросы под текущую схему таблицы, при каждом запуске, а применить ORM в проекте такого типа никто даже и не предлагал. Если же у вас база — это своя база, на которую вы выпускаете релизы синхронно с софтом клиента, то вы вполне можете на такое пойти, и вероятно будет удобно.
>либо кому-то надо отрубить руки, чтобы в прод в обход миграций не лез.
Ну да, это такой организационный способ решить техническую задачу.makkarpov
22.05.2022 13:26Если же у вас база — это своя база, на которую вы выпускаете релизы синхронно с софтом клиента, то вы вполне можете на такое пойти, и вероятно будет удобно.
Ну так 99.9% применений Hibernate именно такие - когда есть какой-то сервис, которому надо где-то хранить свои данные.
И почему-то там вместо "возьмем тринадцатый постгрес" (как у Гитлаба, например) начинается "а вдруг там будет SQLite 0.0.1 beta, нам срочно нужна абстракция над абстракцией! о нет, мы забыли вариант с текстовыми файлами!" непонятно для чего. Потому что если этим всем не заниматься - то Hibernate не особо-то и нужен.
sshikov
22.05.2022 14:23+3>когда есть какой-то сервис, которому надо где-то хранить свои данные.
Ну, насчет 99% не уверен, у меня в практике значительная часть проектов были интеграции с другими системами, где я как-то обрабатывал и хранил данные чужие. Но наверное это не имеет значения, потому что главное то, что таких проектов конечно много.
>Потому что если этим всем не заниматься
Не, ну из применения ORM можно разный профит получать. Я бы сказал, что в моей практике никогда смена СУБД не была таким фактором выбора. Но это длинная история, и мне скажем неохота такой текст писать. Не стоит овчинка выделки, сто раз уже про все это написаны вполне приличные тексты.

alan008
22.05.2022 10:05+2github.com/linq2db/linq2db
Но я не использовал, так что не могу сказать, насколько всё это удобно и работоспособно.
Evengard
23.05.2022 03:59Я использую в рабочих проектах совместно с EF Core. Есть особенности и баги, но в общем и целом - в восторге.
mvv-rus
22.05.2022 16:51Собственно, поддержка SQL когда-то в древние времена с этого — встроенного (embedded) SQL — и начиналась: с раширения языков общего назначения для включения операторов SQL в текст программы.
Но сейчас это, похоже, уже не стильно, не модно и не молодежно.
В Википедии однако есть вот такой список продуктов, поддерживающих встроенный SQL.



aceofspades88
22.05.2022 09:57Он вроде свой тру ооп язык пилил, интересно выстрелило? кто-то пользуется?

MFilonen2
22.05.2022 10:02+1Хм, а если закрыть ORM-объекты как раз теми абстракциями, которые предложены в статье – как будет с производительностью?
kirillk0
22.05.2022 10:15+20То, что предлагает автор, это же по сути active record паттерн как в django?
Только вместо того, чтобы наследовать базовый orm-класс, в котором уже реализована вся crud логика, он фактически предлагает её каждый раз писать вручную. Спасибо большое, всю жизнь мечтал вместо программирования бизнес-логики писать простыни повторяющегося бессмысленного кода
zaqqq13
22.05.2022 12:00+2Да, судя по всему, он это и имеет в виду, не учитывая что orm с active record уже давно существуют, причем работают удобней того, что он предлагает, плюс такой подход нарушает первую буковку в SOLID если уже мы начинаем вести разговор о "правильности"


panzerfaust
22.05.2022 10:45+8Кроме геттеров и сеттеров, у объектов нет других методов. Они даже не знают, из какой базы данных они пришли.
Какой эталонный софизм. Если вам в течении жизненного цикла объекта реально нужно знать, из какой базы он пришел, то у вас явно не с ORM проблемы.
Ну а второй софизм - предположение, что ООП это догма и следовательно весь код должен плясать от нее. Нет, тысячи приложений работают с БД в обычном процедурном стиле через jooq или mybatis и горя не знают.
sshikov
22.05.2022 11:09+1>Если вам в течении жизненного цикла объекта реально нужно знать, из какой базы он пришел
Ну, ради объективности, такой кейс вполне можно вообразить. Репликация какая-нибудь. Правда к этой теме он вряд ли имеет отношение.


maxzh83
22.05.2022 11:20+4Посты и лекции Бугаенко это как авторское кино, когда фильм интересен в первую очередь самому автору и зрителю ничего не должен. Тут примерно также, с точки зрения программирования сферического коня в вакууме это может быть забавно и даже интересно. Но с точки зрения практического применения для решения реальных задача выглядит как какая-то дичь. Кстати, примерно так реагирует неподготовленный зритель в полупустом зале, когда случайно попадает на сеанс авторского кино.

SerP1983
22.05.2022 13:23Martin FAwler поправьте плиз. В оригинальной статье правильно через O
Nialpe
22.05.2022 15:13Если речь о этом https://martinfowler.com/aboutMe.html человеке, то в английском написании он через O, в русском написании и произношении через А.


karambaso
22.05.2022 13:45+3Буду обвинять потому что могу. Примерно так автор общается с аудиторией. Доказательства примитивны. Даже назвать-то эти обоснования доказательствами язык не поворачивается. Зато апломб зашкаливает. Вот пример:
Из-за этого ужасного и оскорбительного нарушения объектно-ориентированной парадигмы у нас есть много практических проблем, уже упомянутых в уважаемых публикациях.
То есть автор "ужасно оскорбился", но назвать проблемы не может, а отсылает к "уважаемым публикациям". Такой стиль подачи понятен для какого-нибудь пропагандистского канала, но зачем вот так безумно обращаться с программированием?
Хотя далее добавляется, что автору не нравится SQL, а потому он должен быть скрыт, но в ORM этого не сделали. Только как автор собрался писать программы без SQL? И чуть ниже видим ответ - SQL всё-таки предлагается использовать, но только перенеся его в другое место. Но кто-то же должен написать SQL в этом другом месте, ведь так? И почему автор в этом другом месте не видит нарушения всех столь важных принципов, за которые он так громко негодует по ходу статьи?
Второй недостаток, который всё же привёл автор - сложность тестирования. Но тестирование чего конкретно? Вот что говорит автор:
Когда какой-либо объект работает со списком записей, ему необходимо иметь дело с экземпляром
SessionFactory. Как мы можем замокать эту зависимость?Оказывается ему хочется "замокать"
SessionFactory.Но зачем? Что бы тестировать Hibernate? Ну тогда уж и всю JVM стоит подробно и со всей дотошностью обложить тестами. А вдруг там ошибка? И мы, ради программы Hello world, напишем эдак сотню мегабайт тестов. А что, ведь действительно можем ошибку найти!В целом очень жаль, что подобные статьи вообще появляются на данном ресурсе. Самоуверенное бесстыдство, наряду с отсутствием здравого смысла, не просто не являются чем-то полезным, но пропагандируют оболванивающие молодёжь "знания", что гораздо хуже самолюбования автора с его зашкаливающим апломбом.
nin-jin
23.05.2022 08:53Вы не поняли, sql тут спрятан в модели, а не расползается по прикладному коду. Ну и под замокать тут понимается замена объекта моком, а не обкладывание его самого моками.
karambaso
23.05.2022 10:00Вы не поняли, sql тут спрятан в модели, а не расползается по прикладному коду
Кто пишет модель? Если тот же самый программист, то это как раз расползание его внимания по разным частям программы в то время, когда он должен воспринимать бизнес-логику как что-то целостное. И даже если другой, то всё равно имеем существенно разные зоны ответственности, отгороженные одна от другой исключительно благодаря религиозным принципам.
под замокать тут понимается замена объекта моком, а не обкладывание его самого моками.
Пишем интерфейс вроде getRecords и имеем полное счастье. Но автор же задаёт вопрос - как? Он не знает, что такое интерфейсы? Или?
Вообще, тестировать каждый чих - это неправильно. Тестировать возвращаемый SQL набор записей на полноту и другие проблемы - это очень трудоёмко, вполне сопоставимо с тестированием JVM. Так писать программы может себе позволить лишь тот, у кого есть в наличии бесконечное время. Но в реальности ни у кого такой опции нет. Отсюда очевидный (и не самый лучший для автора) вывод.
nin-jin
23.05.2022 11:38Не важно, кто её пишет. Пишется она один раз, а используется в сотни местах. Это называется абстракция. Ну а в крупных проектах да, пишется она отдельными людьми.
Чем проще абстракция, тем проще её мокать. И абстракция "дай пользователей по таким-то условиям" куда проще, чем "вот тебе SQL запрос, распарси его, правильно обработай и сформируй соответствующий респонс" и надёжней, чем "в ответ на такую строку запроса выдай такие-то объекты".
ApeCoder
23.05.2022 12:14Совершенно верно. Поэтому можно поверх что SQL, что HQL построить репозиорий с какими-нибудь ограниченными запросами. Но дело в том, что SQL тогда останется не протестированным, а его бы тоже хотелось.
В случае [хорошего] ORM у нас есть слой, который представляет таблички и запросы в системе типов, в случае прямого SQL у нас такого нет.

transcengopher
24.05.2022 23:01SQL можно тестировать интеграционными тестами. Вот прямо, создать заранее известные тесту наборы записей, проверить, потом по желанию всё это удалить через rollback, чтобы остальным тестам не мешать.
Главный недостаток — время подтверждения от тестов. Но тут уж решать нужно, что важнее — протестированный запрос или прошедшие за 0,1с тесты.
karambaso
23.05.2022 17:05+1Не важно, кто её пишет
Это очень важно с точки зрения развития системы.
Это называется абстракция
Автор не про "абстракции вообще" говорил, он говорил, что ему не нравится абстракция ORM. Но предложил он в итоге простейшую прослойку, в которой сам использует какую-то ORM. То есть вместо сокращения числа абстракций автор плодит сущнсоти без какой-либо необходимости.
Чем проще абстракция, тем проще её мокать
Ну я же предлагал интерфейс. Это самый очевидный способ, его и автор должен знать на отлично. Но автор предложил всё усложнить, введя какие-то итераторы и прочие конструкции, в которых даже разбираться не хочется из-за очевидности бессмысленного нагромождения смыслов.
Автор не решает проблемы, он лишь призывает всех делать так, как ему нравится. И не делать так, как ему не нравится. Аргументы я разбирал выше.
makar_crypt
22.05.2022 15:08мне кажется проблема в невыразительном , замусореном коде и неправильном выбранном инструменте.
Советую автору попробовать для строготипизированных языков например драйверы Mongodb : чистые модели , автосессии , удобные типизированные запросы и плюсом поддержка Expressions например как LINQ в C#

siarheiblr
22.05.2022 15:47Мне кажется, или в прилагаемых примерах он Spring Data JPA в итоге изобрёл?

plumqqz
22.05.2022 16:09С ОРМ можно жить, другое дело что он дубовый, как хороший гроб.
Предлагаемый подход, впрочем, еще хуже.
Живите, чего уж.
Dgolubetd
22.05.2022 17:32Посыл, что ОРМ зло - верный. А вот решение - не сильно лучше.
Зачем вам ООП для запросов в БД? Чтобы решать несуществующие проблемы декораторами?

elzahaggard13
22.05.2022 19:10На мой взгляд - слишком фанатичное отношение к принципам ООП. Как говорил дядюшка Боб, где лучше применять ООП подходы, где то процедурные. В случае orm, как раз удобнее использовать процедурный подход, как в работе с rast api. Нужно использовать то, что понятно и удобно, а не то, что кажется вам правоверным

AlexunKo
22.05.2022 19:18Ну не то чтобы прям ORM плохой паттерн. А плохо масштабируемый. Он полачалу экономит строки кода, а потом может сильно напрягать. Но все зависит от случая, я бы не сверхобобщал. А что этот инструмент не идеален - это уж извините. В мире еще очень много разочарований :)

misato
22.05.2022 21:03+3Это ещё далеко не факт, что объект должен инкапсулировать в себе взаимодействие с базой данных.
Объект - это объект, ему бы своей внутренней логикой заниматься, а база данных - это так, сохранялка, по возможности изолированная, чтобы её несложно было переделать на другую, если что.
Hett
22.05.2022 23:45+4Я правильно понял, автор заявляет, что ORM зло, потому что там что-то не так с ответственностью (якобы) и объект "отвязан". Потом изобретает ActiveRecord, что в свою очередь тоже ORM. И объект там все так же "отвязан". Но зато велосипед свой! Подскажите, это какие-то наркотики или что? Как такое сожно на серьезных щщах делать? И кто за это плюсы ставит? +15 на данный момент у статьи, это как?
ApeCoder
23.05.2022 09:05Меня тоже удивляет, что Егор пользуется популярностью. По-моему, типичный Кулибин, что в программировании, что в управлении

euroUK
23.05.2022 12:57Самое главное (я конечно не суперспец по джаве) что предложенный код выглядит просто плохим.
Мне лично кажестя, что это товарищ просто не видил комерческих проектов с сотнями таблиц. Я бы его отправил бы на пару лет писать вот все эти обертки руками без кодгена, чтобы он понял зачем вообще придумали ОРМ и почему в 95% случаев производительность запросов в ОРМ практически не важна.
А потом он сможет вылезти из мира очень плохих библиотек в джава в мир дотнета и офигеть, что мало того, что EF пишется лучше и работает хорошо, но что там можно оказывается и самим запросы писать! А еще есть миграции!
Hett
23.05.2022 13:34Это он еще про репозитории не знает :)
ApeCoder
23.05.2022 13:47Не факт, что он не знает, может быть, для него его идея важнее, чем все репозитории мира вместе взятые. Если послушать его доклад, то сначала идет мотивировочная часть (типа, ООП, чтобы было проще разобраться) потом идет основная часть (например, пишите вместо статических функций, объектные ориентированные обертки, которые эквивалентны лениво вычисляемым статическим функциям семантически, но без выигрышей от ленивости) которая противоречит "проще разобраться". А когда ему указывают на противеоречие, он вместо аргументов использует эмоции или вообще ответ сводится к "я так вижу"

Bakuard
23.05.2022 10:25+1Предложенный в статье подход - хороший пример нарушения принципа единой ответственности. При этом затронутая в нем проблема (rish domain model vs simple domain model) вообще не раскрыта, и вместо этого мы видим обычную вкусовщину.

themen2
23.05.2022 16:30Сам по себе язык SQL крут. И всем стоит его изучить. Он не такой и сложный в целом. Это реально язык манипуляции с данными. Пока вы там будете перебирать коллекции в цикле и что-то с чем-то матчить руками, sql сделает это за вас одним запросом;)
Да, есть нюансы, такие как - сложные запросы надо уметь профилировать, чтобы не нарваться на зависание запроса, блокировки итд. Приходит с опытом.
Вообще можнл писать и на чистом sql п приложении, но существенный недостаток - это нет проверки правильности sql при компиляции. То есть, можно ошибиться в выбираемом поле и получить ошибку в рантайме. Особенно это актуально, если надо рефпктрить часть с data слоем с sql.
siarheiblr
23.05.2022 18:42+1Выносить куски логики приложения в хранимые процедуры? Не, спасибо.
themen2
23.05.2022 20:03Так я ни слова не сказал про хранимые процедуры, за меня не надо додумывать.
Можно в приложении писать raw sql и ручками мапить в объекты, я про это говорил.
siarheiblr
23.05.2022 20:39-2Можно и на ассемблере все писать, только зачем? ORM экономит тонны времени, если им правильно пользоваться. Ну а маппинг руками это то ещё удовольствие частенько
themen2
23.05.2022 22:05-1Так а причем тут ассемблер? Вы наверное Джун, воспитанный на курсах и паттернах;)
Sql изначально придумался как язык , оперирующий множествами структурированных данных.
Если в приложении надо выбрать, отфильтровать, соединить, объединить какой-то массив данных, то вполне можно написать компактный sql запрос. А потом смапмить ответ в структуру.
Я об этом и писал
BugM
Не сработает. Даже на простейших примерах, которые успешно ORM успешно разруливает, ваша концепция ломается.
where id in (что-то из другой таблички)select ... inner join другая табличкаИ тому подобное. И это совсем простейшие штуки которые должны понятно работать из коробки. Таких штук много, и они все нужны.
Mauzzz0 Автор
Тоже об этом задумался когда переводил. Но это Егор Бугаенко) Его мнение почти никогда не совпадает с мнением комьюнити)
Suvitruf
Я, если честно, удивлён, что кто-то по собственной инициативе вбросы Бугаенко переводит.
alxt
Егор отлично видит проблемы. Но его решения не годятся. Но проблема-то есть.
То, что SQL противоречит ООП - факт.
AlexunKo
Это искажение из разряда "желаемое за действительное". А если их не противопоставлять и не исходить из подразумеваемого долженствования (что SQL должен соотноситься/подчиняться ООП) то ни отрицать ни доказывать ничего не нужно будет. Теплое останется теплым, а мягкое будет только помогать теплому не остывать так быстро. Как плед. Во! Плед - не противоречит ООП!
FanatPHP
По мне, так постановку проблемы путем сравнения ORM с войной во Вьетнаме так до сих пор никто и не переплюнул, именно по четкости и структурированности.
vabka
Кстати, почему когда обсуждают ORM - все напрочь игнорируют всякие микро-ORM.
В мире .NET его офигенный Linq2DB - он, кмк, отлично решает все проблемы:
Разработчик хочет удобный DSL, чтобы делать запросы к базе. Желательно, без просачивания SQL в код.
Разработчик не хочет портить красивый мир его объектного дизайна, подстраивать модель под фреймворк.
Разработчик не хочет терять в производительности только из-за того что его ORM не может что-то, что можно сделать прямым запросом к базе.
Остаётся только добавить слой, который это всё из реляционной модели переложит в объектную (если она так уж сильно нужна. О чём можно поспорить отдельно).
Этот самый слой можно будет легко и безопасно мокать, в отличие от DbContext/SessionFactory/etc.
А тестировать соединение с БД без БД просто нереально, что многие пытаются делать при помощи всяких in-memory sqlite, EF Core InMemory, или H2, заменяя настоящий продовый Postgres или что там ещё, а потом ловят какие-нибудь ошибки от того, что какая-то фича работает в проде, но не работает в тесте, или наоборот.
Alcpp
До него проблему заметили некто Мартин Фаулер и Jeff Atwood.
alxt
Согласен. Её многие видят, но пока никто не решил.
inkelyad
Проблема, описанная в статье, вообще к БД никакого отношения не имеет. Это просто проблема альтернативы по размещению кода внутри классов. Мы можем делать либо
либо
В статье утверждается, что первый подход лучше второго. Оно, может быть, и верно... Но только с точки зрения того, кто пользуется и пишет логику отчета и логику заказа. А с точки зрения пишущего код работы с базой данных или работы с принтером - удобнее второй.
ApeCoder
«В вашей работе много нового и верного. К сожалению, то, что в ней верно, – то неново, а то, что ново, – то неверно»
FanatPHP
ошибся ответомtzlom
Сработает, у меня есть проектик, там или очень простенькие инсерты/апдейты, или ветвистые селекты но только для чтения. В итоге создаём ворох объектов для селектов, пишем этот разухабистый код и все работает. Для некоторых совсем веселых селектов с кучей параметров и опциональными пересечениями привлекается QueryBuilder.
Из минусов - не уверен что это генерализованный подход, если задача построить в памяти огромное лениво загружаемое дерево объектов, навалить изменений тут и там и потом сохранить - все придётся делать ручками.
Но для приведенных выше ограничений - эта штука простая, работает очень быстро т.к. пишем запрос сами а значит и оптимизируем его тоже сами, и весьма гибкая.
siarheiblr
Вам никто не мешает самому писать SQL в хибернейте
Revertis
Так нафига тогда хибернейт?
siarheiblr
Разруливать случаи, когда кастомные запросы не нужны, работать с кэшем и транзакциями ну и конвертировать все туда-сюда.
anastasy_bogdanovskaya
угу
semmaxim
Предполагается, что, например, делается некий интерфейс PostsWithUsers, у которого и будут методы типа GetUsersWitchAnswerPost(postId). И под капотом там уже будет sql с where / join. Либо, если действительно сложная выборка, то делаются интерфейсы для построителя запросов типа IQueryable. Которые внутри сервиса "разматываются" и по ним строится sql. Так что всё это делается, вопрос только в том, стоит ли такое дикое усложнение ради "строгости" ООП.