
Привет!
Мы в QIWI достаточно давно применяем микросервисную архитектуру, но ее понимание нами не всегда было одинаковым. И если наши первые микросервисы были всё же достаточно крупные, то сейчас мы делаем их гораздо меньшего размера с более узкой и ограниченной зоной ответственности. Часто такой сервис отвечает за одну небольшую фичу в нашем продукте или даже за часть фичи.
Независимые жизненные и релизные циклы микросервисов позволяют разрабатывать и выводить в production фичи нескольким командам не мешая друг другу. Также это даёт нам возможность независимо масштабировать сервисы и быстрее проверять гипотезы. В общем, плюсов много.

Сейчас будет «Но», правда?
В системе, которая состоит из множества небольших взаимодействующих частей, становится критически важным такое качество, как наблюдаемость.
Помимо высокоуровневых метрик, отражающих состояние системы в целом, нам также требуются дашборды и алерты для каждого микросервиса — нужно иметь возможность видеть его рабочие показатели и получать уведомления, если показатели выходят за пределы нормы.
Поскольку новые фичи мы делаем часто, то и новые микросервисы создаём часто. Создание дашбордов и настройка алертов превратились в рутину, которая отнимает ощутимую часть времени. Очень захотелось автоматизации. Что бы нам могло с этим помочь?
Всё есть кот
Подход «Все есть код» у нас в компании как философия существует достаточно давно. Описание инфраструктуры, описание pipeline CI/CD, описание необходимых сетевых доступов — всё это хранится в виде кода вместе с исходниками самого микросервиса.
Применение аналогичного подхода к дашбордам и алертам выглядело бы для нас совершенно логично.
Плюсов много: хранение в системе контроля версий, прохождение через code review. А самое главное – если описание дашборда и алертов будет в виде некого исходного кода, то это позволит нам достичь наших целей по автоматизации, так как код мы умеем генерить!
Grafana JSON Model
Мы, как и многие, используем Grafana для визуализации наших дашбордов. Поэтому первая мысль была – использовать Grafana JSON Model для их описания. Grafana позволяет создавать и изменять дашборды, передавая данные в таком формате через её REST API.
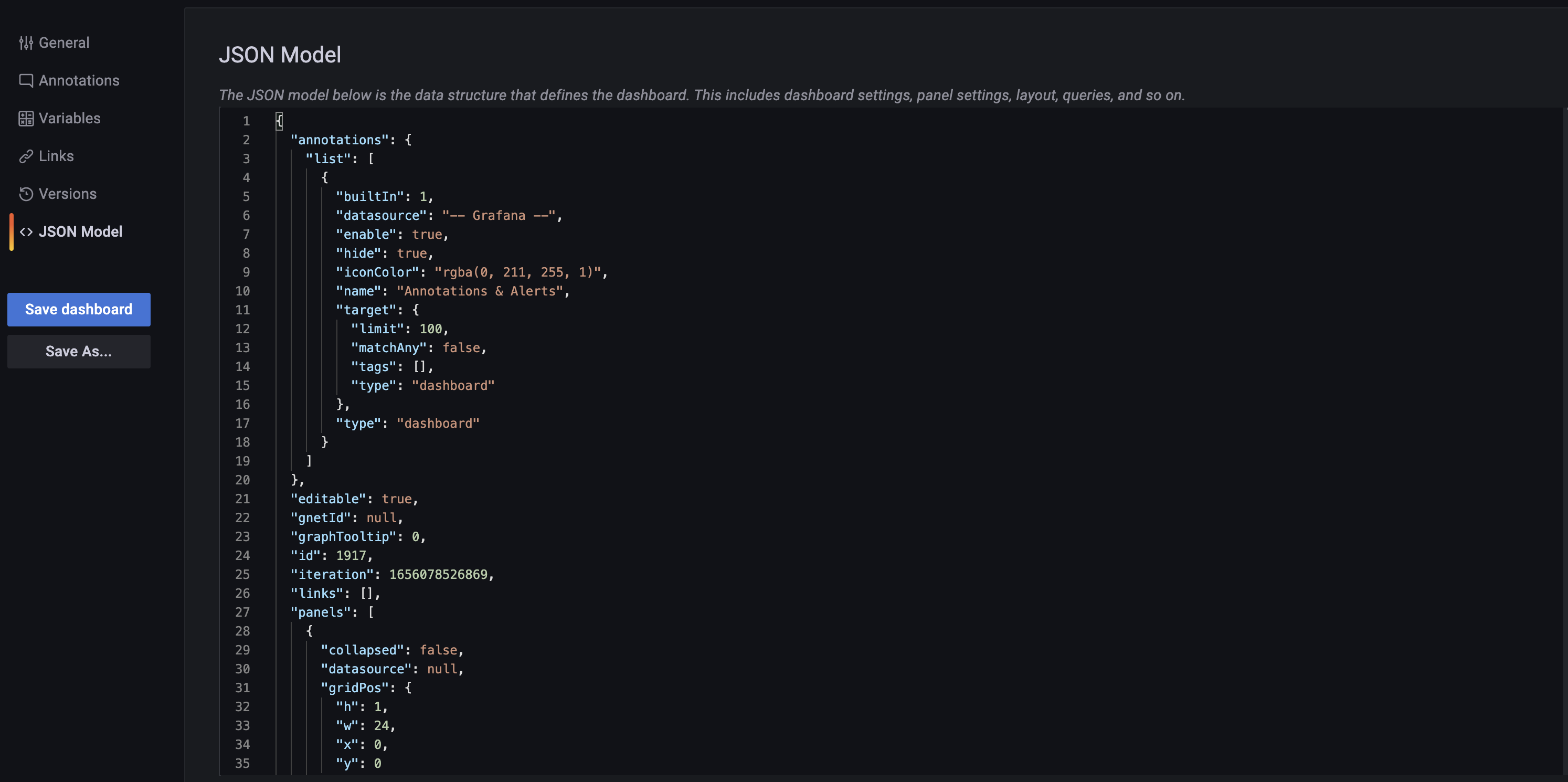
Но, к сожалению, такой формат очень тяжёл для восприятия человеком. Даже небольшой дашборд превращается в нём в огромный JSON, работать с которым человеку затруднительно.
Kotlin DSL
К счастью, оказалось, что мы не единственные на нашем пути, и для различных языков программирования уже существуют DSL, позволяющие описать дашборд ёмко, лаконично и понятно.
Поскольку у нас в компании развита JVM-экосистема, а Kotlin в Кошельке занимает сейчас доминирующее положение как язык разработки, наше внимание привлек open source проект от компании ЮMoney – Grafana Dashboard DSL, который позволяет описать дашборд на Kotlin.
Вот пример того, как может выглядеть описание дашборда на Kotlin DSL.
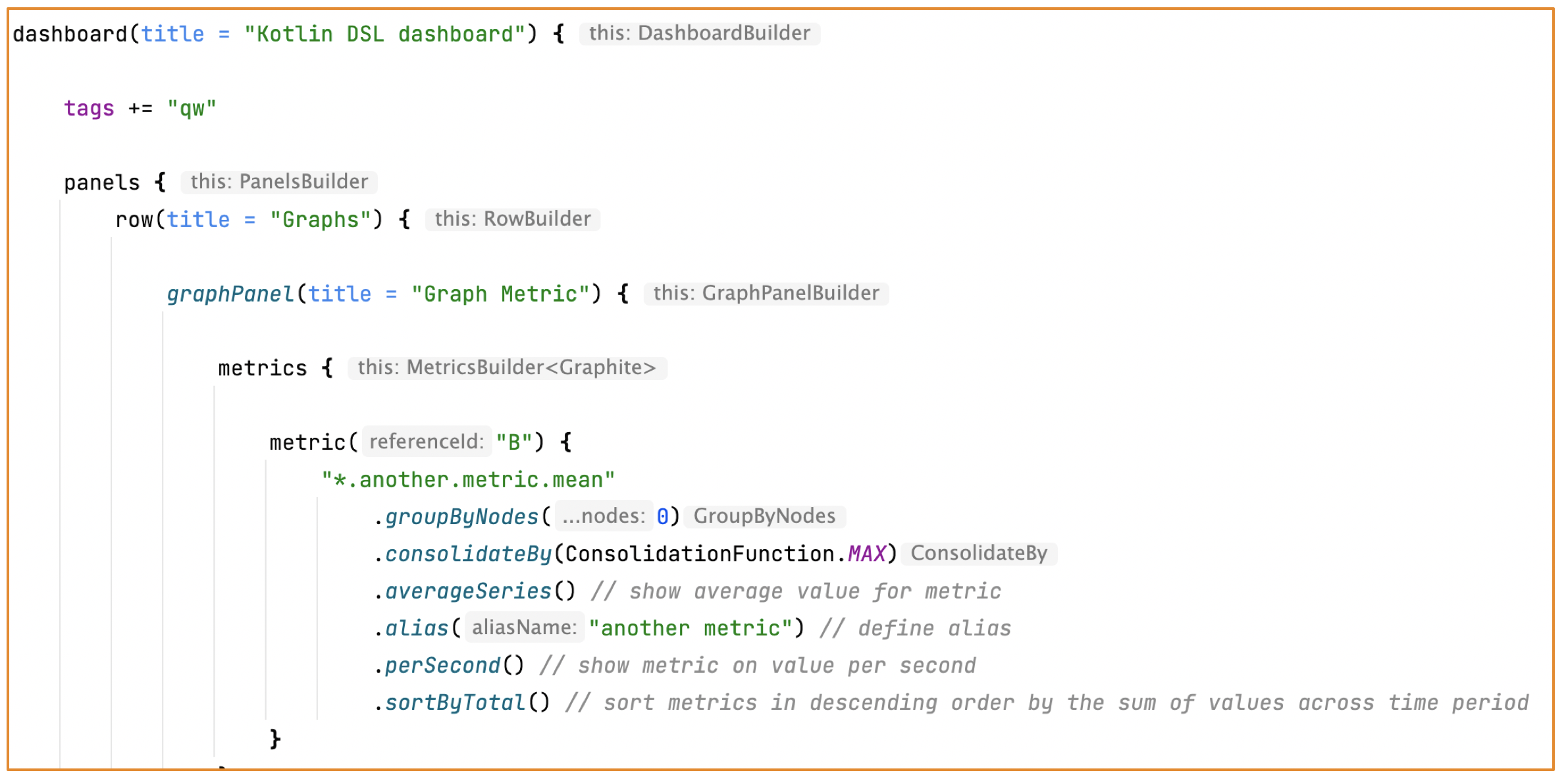
Но мы захотели пойти ещё дальше – сделать описание дашбордов ещё более простым и коротким. И в этом нам помогли наши договорённости.
У нас в Кошельке уже достаточно давно существуют договорённости по метрикам: их именам, формату, набору обязательных метрик. И микросервисы этим договоренностям следуют.
Это дало нам возможность использовать подход convention over configuration – вместо детальной конфигурации каждой панели дашборда с указанием полного имени метрики, всех применяемых функций, единиц измерения и прочего мы можем конструировать наш дашборд на более высоком уровне абстракции из типовых для нас панелей.
Для всех наших типовых панелей и основных метрик мы сделали расширение для Kotlin DSL.
К примеру, если у микросервиса есть REST API, то мы обязательно захотим на его дашборде видеть частоту запросов, время их обработки и HTTP-статусы ответов. Поскольку все микросервисы пишут эти метрики схожим образом, нам не требуется полная многословная конфигурация каждой панели. Вместо этого мы можем просто перечислить в коде этот набор типовых панелей, указав имя интересующего микросервиса и только те свойства, которые хотим изменить.

А где автоматизация?
Мы заметили, что микросервисы, схожие по техническому устройству, имеют у нас и похожие дашборды. Набор панелей и алертов во многом определяется тем, какой тип API предоставляет микросервис и с какими системами интегрируется.
Из этого наблюдения родилась автоматическая генерация дашбордов.
Работает всё при помощи нашего Maven-плагина. Автогенерация дашборда запускается таской generate.
Плагин анализирует зависимости микросервиса и его исходный код, собирает набор метаданных и строит профиль микросервиса. На основе этой информации формируется дашборд на Kotlin DSL – добавляются ряды, панели и алерты, которые мы хотим видеть в типовом дашборде такого микросервиса.
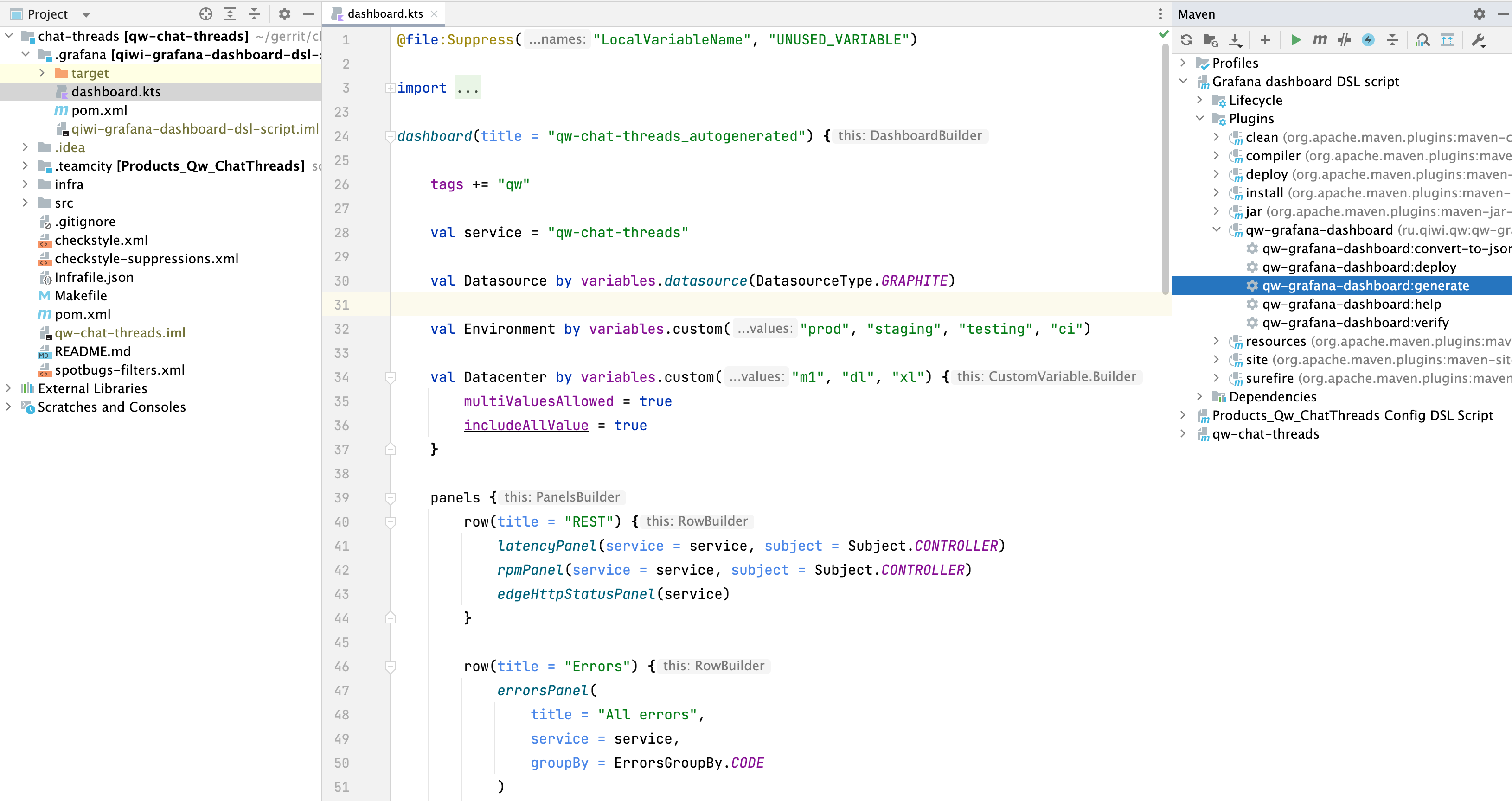
После автогенерации при необходимости можно доработать дашборд руками – например, добавить какие-нибудь дополнительные кастомные панели.
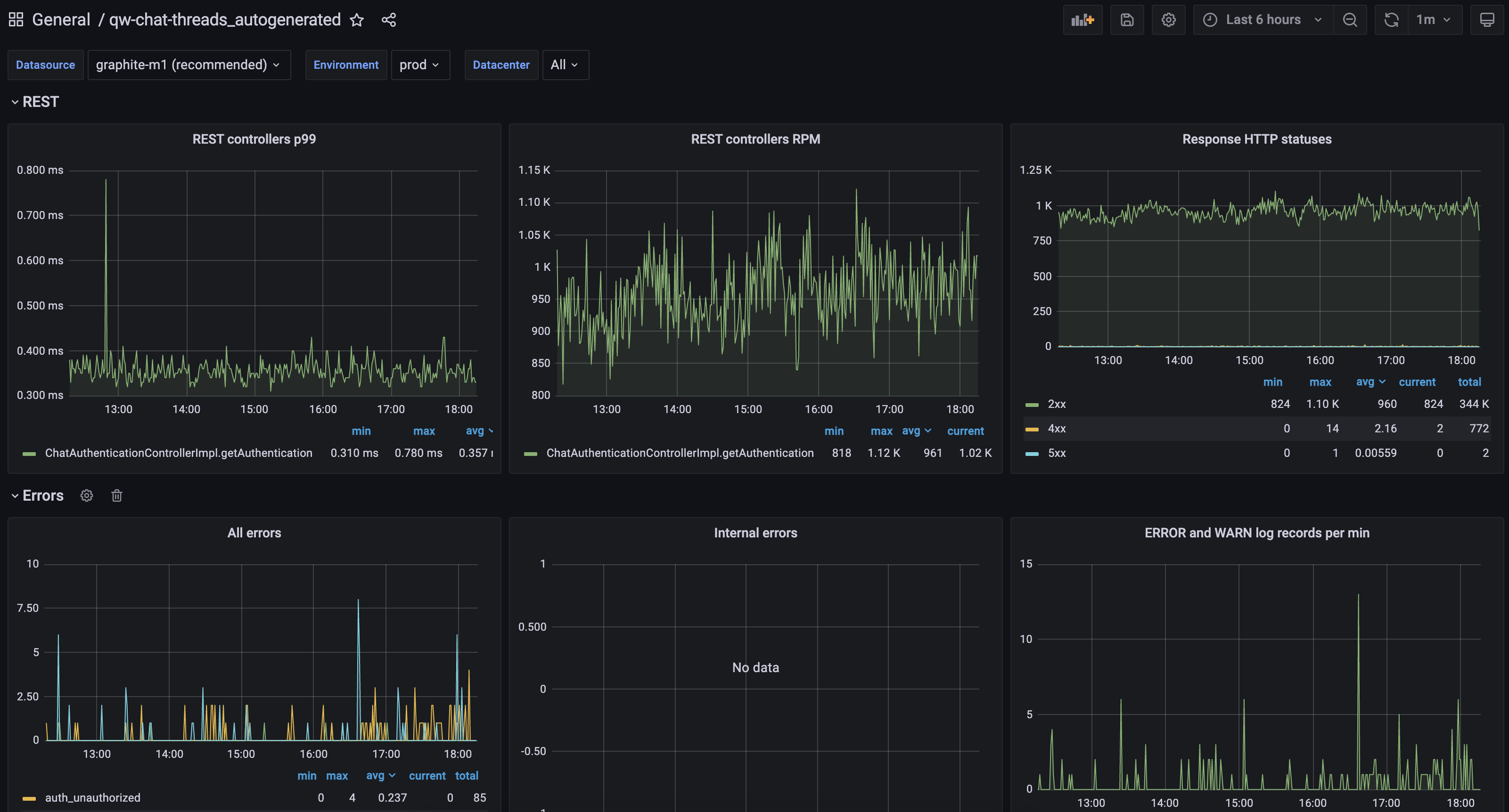
Вот наш свежесгенерированный дашборд.
Как дашборд попадает в Grafana?
Таска deploy в нашем maven-плагине преобразует Kotlin DSL в формат Graphana JSON model и загружает его в Graphana через её REST API.
Запустим таску deploy – она отработает и мы увидим ссылку, по которой сможем перейти к созданному дашборду.
Чем это нам помогло
Во-первых, мы стали быстрее настраивать дашборды и алерты.
Во-вторых, мы теперь не забываем настроить алерты для новых микросервисов, потому что они генерятся автоматически.
В-третьих, мы переиспользуем типовые панели и типовую конфигурацию, поэтому нам не приходится каждый раз накликивать в Grafana или кодировать в виде DSL подробное описание каждой панели, если она является типовой. Наши дашборды стали иметь стандартный, узнаваемый, типовой вид, понятный всем разработчикам.
Какие я сделал лично для себя выводы из этой истории?
Прежде всего, очень важно договариваться в команде и в компании о самых разных вещах – от стиля кодирования до требований к метрикам. Помимо того, что это повышает общее владение кодом, это ещё и открывает возможности для автоматизации. Стандартизированные вещи автоматизировать просто, а если каждый делает всё по-своему, то уже не получится.
В микросервисной архитектуре очень важно переиспользовать код. Помимо стандартной мотивации не изобретать очередной велосипед, здесь ещё очень важно переиспользование поведения. Когда у вас много компонентов и все они в похожих ситуациях ведут себя одинаково, это упрощает и понимание системы, и её поддержку, и открывает возможности для автоматизации, которая иначе бы была невозможна.
Ещё важная штука: автоматизация даже небольших задач принесёт ощутимый результат по экономии времени и усилий, если эти задачи возникают часто, из спринта в спринт.
Quber
Привет! Спасибо за статью! Рассматривали ли вы вариант делать микросервисы на одной базе аля своём фреймворке , который под капотом умеет слать все общие между микросервисами метрики? Если да, то почему такой вариант не подошёл? Тогда в графане достаточно было просто сделать один раз общий дашборд на котором сделать переключатель по микросервисам. У нас так сделано и не надо ничего изобретать ???? все микросервисы конечно при таком подходе должны использовать общие методы логирования, воркеров, консьюмеров, контроллеры веб сервера и тд
AntonYuriev Автор
Привет! Спасибо за вопрос!
Да, у нас все микросервисы на одной платформе. Многие технические метрики пишутся именно платформой, и это во много позволило достичь стандартизации.
Но вариант с единым дашбордом с переключателем для всех микросервисов нам не подошёл, потому что набор панелей у нас отличается в зависимости от технического устройства микросервиса и типов API, которые он предоставляет. Например, у сервиса с публичным REST API и у сервиса, который внутри контура взаимодействует только через kafka, дашборды будут отличаться. Нам хочется видеть на дашборде только те панели, которые релевантны конкретному сервису.
Ещё на дашборд иногда добавляется ряд с "бизнесовыми" метриками (например, количество успешно заказанных карт). Мы стремимся к тому, чтобы у микросервиса была строго определённая роль с точки зрения бизнес логики. И если существует метрика, по которой видно, насколько хорошо он с этой ролью справляется, то мы добавляем для неё панель и алерты. Чтобы не перемешалось с техническими метриками, выносим "бизнесовые" в отдельный ряд.
В сумме это позволяет иметь дашборды которые могут ёмко передать всю ключевую информацию о состоянии сервиса. Но не даёт возможности сделать один единый дашборд с переключателем.