
Привет, Хабр! Недавно, пришлось работать на проекте с внешним API. Работал, я, к слову, всегда либо с простым REST, либо с GET/POST only запросами, но в этом нужно было работать с API Timetta. Он использует OData и что же это такое?
Содержание
REST vs OData
В то время как REST - набор архитектурных правил создания хорошего API, OData - это уже веб-протокол, собравший в себя "лучшие архитектурные практики": defines a set of best practices for building and consuming RESTful APIs (как написано на официальном сайте). Сам протокол очень большой, поэтому я затрону наиболее практически-значимые аспекты.
Схема
Каждая система использующая OData должна описать свою схему данных. По ней можно понять все: какие сущности есть в системе, какие операции над ними можно производить. Схема может описывается в формате XML или JSON. Для получения схемы нужно сделать запрос по адресу:
<root>/$metadata
Где <root> - корень сервиса OData. Примеры дальше будут предполагать, что мы делаем запросы из этого <root>. Для Timetta этот адрес такой:
https://api.timetta.com/odata/$metadata
Примеры дальше будут с использованием XML схем.
Типы данных
Примитивные
Протокол определяет ряд встроенных типов данных. Все имеют префикс "Edm". Например:
Edm.Boolean
Edm.String
Edm.Int32
Edm.Int16
Edm.Stream
Edm.Date
Edm.Byte
Edm.Decimal
Edm.Binary
EntityType
EntityType похож на сущность из DDD: у него есть как состояние, так и свой ID (в схеме указывается отдельно). В схеме состоит из элементов
-
Property - поля со скалярными данными. Например, строка или число. Имеет атрибуты:
Name - название поля (обязателен)
Type - тип поля (обязателен)
Nullable - может ли быть null
-
NavigationProperty - поле, которое ссылается на другую сущность
Name - название (обязателен)
Type - тип (обязателен)
-
ReferentialConstraint - "как" мы ссылаемся
Property - название поля в ССЫЛАЮЩЕМСЯ типе
ReferencedProperty - название поля в типе, на который ССЫЛАЕМСЯ
-
Key - элемент, определяющий первичный ключ сущности. Значения могут быть только примитивными типами или перечислением и не может равняться null.
Name - название поля, которое является ключом
Alias - псеводним для ключа. Например, если ключ - поле вложенного типа.
Пример, для сущности TimeSheet, представляющей рабочий график проекта (табель) за некоторый период времени.
<EntityType Name="TimeSheet" OpenType="true">
<Key>
<PropertyRef Name="id"/>
</Key>
<Property Name="dueDate" Type="Edm.Date"/>
<Property Name="dateFrom" Type="Edm.Date" Nullable="false"/>
<Property Name="dateTo" Type="Edm.Date" Nullable="false"/>
<Property Name="approvalStatusId" Type="Edm.Guid"/>
<Property Name="submitted" Type="Edm.DateTimeOffset"/>
<Property Name="approved" Type="Edm.DateTimeOffset"/>
<Property Name="userId" Type="Edm.Guid"/>
<Property Name="departmentId" Type="Edm.Guid"/>
<Property Name="approvalInstanceId" Type="Edm.Guid"/>
<Property Name="templateId" Type="Edm.Guid" Nullable="false"/>
<Property Name="name" Type="Edm.String"/>
<Property Name="rowVersion" Type="Edm.Binary"/>
<Property Name="createdById" Type="Edm.Guid"/>
<Property Name="modifiedById" Type="Edm.Guid"/>
<Property Name="id" Type="Edm.Guid" Nullable="false"/>
<Property Name="created" Type="Edm.DateTimeOffset"/>
<Property Name="modified" Type="Edm.DateTimeOffset"/>
<Property Name="isActive" Type="Edm.Boolean" Nullable="false"/>
<NavigationProperty Name="approvalStatus" Type="WP.ApprovalStatus">
<ReferentialConstraint Property="approvalStatusId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="user" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="department" Type="WP.Department">
<ReferentialConstraint Property="departmentId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="approvalInstance" Type="WP.ApprovalInstance">
<ReferentialConstraint Property="approvalInstanceId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="timeSheetLines" Type="Collection(WP.TimeSheetLine)"/>
<NavigationProperty Name="timeAllocations" Type="Collection(WP.TimeAllocation)"/>
<NavigationProperty Name="approvalRecords" Type="Collection(WP.TimeSheetApprovalRecord)"/>
<NavigationProperty Name="lineApprovals" Type="Collection(WP.TimeSheetLineApproval)"/>
<NavigationProperty Name="template" Type="WP.TimeSheetTemplate"/>
<NavigationProperty Name="total" Type="WP.TimeSheetTotal"/>
<NavigationProperty Name="timeOffRequests" Type="Collection(WP.TimeOffRequest)"/>
<NavigationProperty Name="createdBy" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="modifiedBy" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
</EntityType>Объяснение:
Поле "id" - первичый ключ
-
Имеет несколько полей с примитивными типами. Например:
dueDate - до какой даты нужно закончить
dateFrom - когда начинать проект
dateTo - когда оканчивать проект
approvalInstanceId - Id документа (ресурса), который сигнализирует о том, что работа согласована (если не согласован, то значение - null, нет атрибута Nullable, что по умолчанию означает поддержку null)
Некоторые из которых могут принимать значение null:
dueDate - мы еще не знаем дедлайн
approvalInstanceId - работу еще могли не согласовать
-
Имеет навигационные свойства. Например:
approvalInstance - документ согласования
timeSheetLines - потраченные часы
createdBy - кем создан план работ
Где:
approvalInstance можно найти по занчению поля approvalInstanceId родителя и сопоставление по полю id искомой сущности
timeSheetLines - "слабая" сущность. Для нее не нужен Id, время жизни привязано к самому родителю
ComplexType
ComplexType похож на Value type из DDD - не имеет первичного ключа, сравнение по значению полей. Может состоять из тех же элементов, что и EntityType за исключением Key.
Пример, для объекта с 2 полями, который используется для отметок времени
<ComplexType Name="DateHours">
<Property Name="date" Type="Edm.Date" Nullable="false"/>
<Property Name="hours" Type="Edm.Decimal"/>
</ComplexType>Объяснение:
Тип DateHours является сложным (ComplexType)
-
Состоит из 2 полей:
date - дата (Type="Edm.Date"), за которую идет отсчет.
hours - время, представляемое дробным числом (Type="Edm.Decimal")
-
Где:
date - не может быть null, т.к. мы должны знать дату
hours - может быть null, т.к. время может быть просто не проставлено/указано
EnumType
EnumType - обычный тип перечисления. Особенность в том, как передается значение в параметры - сначала пишется полное имя Enum, затем в кавычках его значение. Для данного примера, чтобы передать PlanningMethod.Manual, нужно написать PlanningMethod'Manual'. Атрибуты:
Name - название перечисления (обязательно)
UnderlyingType - тип, которое определяет используемое значение (по умолчанию, Edm.Int32)
IsFlags - является ли перечисление флагом. Чтобы исползовать в UnderlyingType должно быть проставлено "true"
Для определения занчений - элемент Member:
Name - название элемента
Value - значение элемента
<EnumType Name="PlanningMethod">
<Member Name="Manual" Value="0"/>
<Member Name="FrontLoad" Value="1"/>
<Member Name="RemainingCapacity" Value="2"/>
<Member Name="Evenly" Value="3"/>
</EnumType>Объяснение:
Тип PlanningMethod является типом перечисления (EnumType)
-
Может принимать значения:
Manual, определяемое значением 0
FrontLoad, определяемое значением 1
RemainingCapacity, определяемое значением 2
Evenly, определяемое значением 3
P.S. В общем случае такой вид записи применяется ко всем типам и имеет вид: ПолныйТипСущности'Значение'. Например, для даты - date'2022-07-01'
Collection
Тип коллекции является отдельным. Определяется как Collection(ПолноеНазваниеТипа). Например, Collection(WP.TimeSheet).
<EntityType Name="TimeSheet" OpenType="true">
<Key>
<PropertyRef Name="id"/>
</Key>
<Property Name="dueDate" Type="Edm.Date"/>
<Property Name="dateFrom" Type="Edm.Date" Nullable="false"/>
<Property Name="dateTo" Type="Edm.Date" Nullable="false"/>
<Property Name="approvalStatusId" Type="Edm.Guid"/>
<Property Name="submitted" Type="Edm.DateTimeOffset"/>
<Property Name="approved" Type="Edm.DateTimeOffset"/>
<Property Name="userId" Type="Edm.Guid"/>
<Property Name="departmentId" Type="Edm.Guid"/>
<Property Name="approvalInstanceId" Type="Edm.Guid"/>
<Property Name="templateId" Type="Edm.Guid" Nullable="false"/>
<Property Name="name" Type="Edm.String"/>
<Property Name="rowVersion" Type="Edm.Binary"/>
<Property Name="createdById" Type="Edm.Guid"/>
<Property Name="modifiedById" Type="Edm.Guid"/>
<Property Name="id" Type="Edm.Guid" Nullable="false"/>
<Property Name="created" Type="Edm.DateTimeOffset"/>
<Property Name="modified" Type="Edm.DateTimeOffset"/>
<Property Name="isActive" Type="Edm.Boolean" Nullable="false"/>
<NavigationProperty Name="approvalStatus" Type="WP.ApprovalStatus">
<ReferentialConstraint Property="approvalStatusId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="user" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="department" Type="WP.Department">
<ReferentialConstraint Property="departmentId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="approvalInstance" Type="WP.ApprovalInstance">
<ReferentialConstraint Property="approvalInstanceId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="timeSheetLines" Type="Collection(WP.TimeSheetLine)"/>
<NavigationProperty Name="timeAllocations" Type="Collection(WP.TimeAllocation)"/>
<NavigationProperty Name="approvalRecords" Type="Collection(WP.TimeSheetApprovalRecord)"/>
<NavigationProperty Name="lineApprovals" Type="Collection(WP.TimeSheetLineApproval)"/>
<NavigationProperty Name="template" Type="WP.TimeSheetTemplate"/>
<NavigationProperty Name="total" Type="WP.TimeSheetTotal"/>
<NavigationProperty Name="timeOffRequests" Type="Collection(WP.TimeOffRequest)"/>
<NavigationProperty Name="createdBy" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
<NavigationProperty Name="modifiedBy" Type="WP.User">
<ReferentialConstraint Property="userId" ReferencedProperty="id"/>
</NavigationProperty>
</EntityType>Возвращаясь к типу TimeSheet. В нем присутствуют 5 коллекций*:
timeSheetLines
timeAllocations
lineApprovals
approvalRecors
timeOffRequests
*Тип коллекции может быть и у Property, не только NavigationProperty
EntitySet
У нас есть сущности, сложные типы, перечисления и т.д. Но где это хранить? Для этого нам нужна коллекция.EntitySet - это top-level коллекция доступная всем. Внутри нее хранятся какие-либо сущности. Соответственно, для нее обязательны имя и тип: Name="SampleName" EntityType="SampleType", соответственно. По умолчанию, все обычные поля (Property) коллекции включаются в вывод. Если у типа есть навигационные свойства, то их должны указать в EntitySet, иначе их существование не гарантируется.
<EntitySet Name="TimeSheets" EntityType="WP.TimeSheet">
<NavigationPropertyBinding Path="approvalStatus" Target="ApprovalStatuses"/>
<NavigationPropertyBinding Path="createdBy" Target="Users"/>
<NavigationPropertyBinding Path="department" Target="Departments"/>
<NavigationPropertyBinding Path="modifiedBy" Target="Users"/>
<NavigationPropertyBinding Path="template" Target="TimesheetTemplates"/>
<NavigationPropertyBinding Path="timeAllocations" Target="TimeAllocations"/>
<NavigationPropertyBinding Path="timeOffRequests" Target="TimeOffRequests"/>
<NavigationPropertyBinding Path="timeSheetLines" Target="TimeSheetLines"/>
<NavigationPropertyBinding Path="user" Target="Users"/>
</EntitySet>Здесь:
Name="TimeSheets" - название коллекции. Доступ к ней через это слово:
https://app.timetta.com/TimeSheetsEntityType="WP.TimeSheet" - тип сущностей используемый в коллекции (был выше). WP - пространство имен.
-
У коллекции есть несколько навигационных свойств. Свойства - те же, что и у самой сущности. Например:
user
template
modifiedBy
Но некоторые (total, lineApprovements) отсутствуют.
Есть коллекция, значит есть и единственный элемент. Для получения нужно использовать ID сущности, который указан в схеме. Указывать в круглых скобках после названии коллекции. Например, для получения TimeSheet то его ID нужно сделать запрос:
/TimeSheets(00000000-0000-0000-0000-000000000000)
Запросы
На мой взгляд, что примечательного в OData - язык запросов. Можно делать запросы к ресурсам прямо в строке запроса. Для запросов есть свой специальный язык. По фукнционалу он очень похож на SQL.
Сам запрос передается в строке запросов (query string) URL. Например:
/TimeSheets?$select=id,dateFrom,dateTo&$filter=approval&$expand=createdBy($select=name)&$count=true
Метаданные
Вместе с каждым запросом возвращаются специальные поля с метаданными. Они могут быть полезны, например, для получения мета информации о запрашиваемой сущности. Дальше на них акцент делаться не будет.
Поэтому, многие запросы OData транслируются в SQL. У этого языка много ключевых слов, но рассмотрим основные. Для лучшего погружения представим ситуацию: нам нужно получить отчеты.
$select
$select позволяет нам выбрать только нужные поля.
Пример: нам нужно получить только отрезки времени отсчета таймшитов и имя того, кто его создал. Тогда следующий запрос:
/TimeSheets?$select=dateFrom,dateTo,id
{
"@odata.context": "https://api.timetta.com/odata/$metadata#TimeSheets(dateFrom,dateTo,id)",
"value": [
{
"dateFrom": "2021-10-04",
"dateTo": "2021-10-10",
"id": "00000000-0000-0000-0000-00000000"
},
{
"dateFrom": "2021-11-22",
"dateTo": "2021-11-28",
"id": "00000000-0000-0000-0000-00000000"
},
{
"dateFrom": "2022-06-27",
"dateTo": "2022-07-03",
"id": "00000000-0000-0000-0000-00000000"
}
}$filter
Прекрасно. Мы получили данные. Но что если какие-то табеля не были согласованы? Нужно убрать такие:
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null
{
"@odata.context": "https://api.timetta.com/odata/$metadata#TimeSheets(dateFrom,dateTo,id)",
"value": [
{
"dateFrom": "2021-10-04",
"dateTo": "2021-10-10",
"id": "00000000-0000-0000-0000-00000000"
},
{
"dateFrom": "2021-11-22",
"dateTo": "2021-11-28",
"id": "00000000-0000-0000-0000-00000000"
}
}Какой-то табель не был согласован! Хорошо, что мы обнаружили это.
Сам $filter принимает в себя логическое выражение. Доступные логические операции (bash-like):
eq (equal), ==:
name eq 'За ноябрь'ne (not equal), !=:
approvalInstanceId ne nullgt (greater than), >:
dueDate gt '2022-03-15'ge (greater or equal), >=:
dateFrom ge '2021-01-01'lt (less than), <:
age lt 18le (less or equal), <=:
ttl le 0
Эти выражения можно комбинировать с помощью скобок и:
and (логическое 'и'):
(name eq 'За ноябрь') and (dateFrom ge '2021-01-01')or (логическое 'или'): (
dateFrom ge '2021-01-01') or (approvalInstanceId ne null)not (отрицание):
not isActive
Также есть и булевы литералы: true, false
$expand
Прекрасно. Мы отфильтровали данные и выбрали только те поля, которые нужны. Но теперь в отчете нужно получить и имя человека создавшего табель. Можно сделать несколько запросов: сначала массив табелей, затем для каждого - запрос на информацию о пользователе. Но это лишнее. Можно ведь сделать просто - добавить $expand:
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name)
{
"@odata.context": "https://api.timetta.com/odata/$metadata#TimeSheets(dateFrom,dateTo,id)",
"value": [
{
"dateFrom": "2021-10-04",
"dateTo": "2021-10-10",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Владислав Иванов"
}
},
{
"dateFrom": "2021-11-22",
"dateTo": "2021-11-28",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Кирилл Ильин"
}
}
}Здесь продемонстрированы сразу 2 фичи:
Возможность вставить сущность из навигационного свойства (у типа TimeSheet есть навигационное свойство user типа WP.User)
-
Сделать подзапросы: здесь из всех возможных свойств нам нужно только имя. Для подзапросов есть ограничения - ключевые слова разделяются точкой с запятой, иначе парсинг строки запроса будет неверным. Например:
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name;$expand=schedules) - дает нам не только имя пользователя, но и список его рабочих графиков. Если бы вместо точки с запятой был амперсанд, то получилось бы 2 параметра: $expand=user($select=name и $expand=schedules)
$orderby
Вроде бы все прекрасно. Данные получаются, но мы хотим получать упорядоченные данные сразу. Нам поможет ключевое слово $orderby. Представим, что мы хотим сортировать табели сначала по дате начала по убыванию, а затем по дате конца по возрастанию (получим самые близкие к нам по дате, короткие по длительности):
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name)&$orderby=dateFrom desc, dateTo asc
{
"@odata.context": "https://api.timetta.com/odata/$metadata#TimeSheets(dateFrom,dateTo,id,user(name))
"value": [
{
"dateFrom": "2021-11-22",
"dateTo": "2021-11-28",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Кирилл Ильин"
}
},
{
"dateFrom": "2021-10-04",
"dateTo": "2021-10-10",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Владислав Иванов"
}
}
}По умолчанию используется сортировка по возрастанию - asc
$top, $skip
Вот проблема! У нас слишком много данных. Как бы нам ограничить их прием? Для этого можно указать какое количество мы хотим принять с помощью $top. Тогда нам вернется не больше заданного количества:
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name)&$orderby=dateFrom desc, dateTo asc$top=5
А что если нужно еще и пропускать некоторое количество (для пагинации, например)? Тогда используем $skip:
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name)&$orderby=dateFrom desc, dateTo asc&$top=5&$skip=10
$count
Мы можем получить наши данные - прекрасно. А если я хочу знать только количество удовлетворяющих критерию? Или для пагинации? Нужно посчитать общее количество элементов. Здесь нам поможет $count. Он принимает булево значение: true - вернуть общее количество, false - не возвращать (по умолчанию)
/TimeSheets?$select=dateFrom,dateTo,id&$filter=approvalInstanceId ne null&$expand=user($select=name)&$orderby=dateFrom desc, dateTo asc&$count=true
{
"@odata.context": "https://api.timetta.com/odata/$metadata#TimeSheets(dateFrom,dateTo,id,user(name))
"@odata.count": 2,
"value": [
{
"dateFrom": "2021-11-22",
"dateTo": "2021-11-28",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Кирилл Ильин"
}
},
{
"dateFrom": "2021-10-04",
"dateTo": "2021-10-10",
"id": "00000000-0000-0000-0000-00000000",
"user": {
"name": "Владислав Иванов"
}
}
}Функции, действия
Вот здесь начинается самое интересное - функции и действия (Functions, Actions). Теперь мы хотим получить табель за текущий период. Можно получить все табеля и отфильтровать их - сделать сложный запрос, а потом отфильтровать еще и результат. Это лишнее. Не проще ли использовать функцию:
/TimeSheets/Current
И все!
OData определяет функции (Function) и действия (Action)
Function - это операция над ресурсами, которая обязательно возвращает значение и не имеет сторонних эффектов.
Action - это операция, которая может изменить значение
PS. похоже на CQRS
Как же ими пользоваться? Для начала: операции могут быть привязанными и нет - требуется ли сущность для выполнения операции. Описание операции состоит из
Функция из примера имеет следующее пределение:
<Function Name="Current" IsBound="true">
<Parameter Name="bindingParameter" Type="Collection(WP.TimeSheet)"/>
<ReturnType Type="WP.TimeSheet"/>
</Function>Что это все значит:
Name="Current" - название функции, которую будем вызывать
IsBound="true" - функция привязана к конкретному типу. Т.е. вызвать ее из произвольного места нельзя
"bindingParameter" - особый параметр означающий к какому типу функция применяется. Здесь применяется к типу
Collection(WP.TimeSheet)(чем и является/TimeSheets)Возвращает тип
TimeSheet
Если функция не принимает ничего, то скобок нет. Видели. А если функция принимает параметры? Тогда они указываются в элементе Parameter:
<Function Name="GetUserSchedule" IsBound="true">
<Parameter Name="bindingParameter" Type="Collection(WP.Schedule)"/>
<Parameter Name="userId" Type="Edm.Guid" Nullable="false"/>
<Parameter Name="from" Type="Edm.Date" Nullable="false"/>
<Parameter Name="to" Type="Edm.Date" Nullable="false"/>
<ReturnType Type="Collection(WP.DateHours)"/>
</Function>Эта функция принимает дополнительные параметры: userId, from, to (в данном случае они обязательные - Nullable="false"). Передача параметров - как вызов функции, в скобках, причем все параметры именованные и вставляются через запятую (как в Python). Пример:
/Schedules/GetUserSchedule(userId=00000000-0000-0000-0000-00000000,from=2022-01-01,to=2022-02-01) - получение расписания для пользователя за весь январь
Что по Action? Разница в том, что действие может модифицировать данные и может не возвращать данные. Например:
<Action Name="SetAsDefault" IsBound="true">
<Parameter Name="bindingParameter" Type="WP.Role"/>
</Action>Это действие устанавливает тип роли пользователя применяемой по умолчанию. Логично, что оно может модифицировать, а может и нет (если это тип уже был по умолчанию). Также он ничего не возвращает (разве что статусный код по которму и будет понятен результат). Как вызывать:
/Roles(00000000-0000-0000-0000-00000000)/SetAsDefault
Это привязанное действие и привязано оно к типу WP.Role, а значит к единственному элементу, а не к целой коллекции как было в предыдущем примере.
Пример действия, который что-то возвращает:
<Action Name="UpdatePermissionSets" IsBound="true">
<Parameter Name="bindingParameter" Type="WP.User"/>
<Parameter Name="permissionSets" Type="Collection(WP.UserPermissionSet)"/>
<ReturnType Type="Collection(WP.UserPermissionSet)"/>
</Action>Модификация ресурсов
Для операций модификаций ресурсов используются HTTP методы: POST, PATCH, PUT, DELETE
Создание
Создание сущности = добавление в коллекцию. Для этого нужно сделать POST запрос с адресом коллекции и передать необходимые для создания параметры. Например, для создания нового департамента нужно сделать такой POST запрос:
POST /Departments
{
"code": "69",
"resourcePoolId": null,
"name": "Какой-то департамент",
"leadDepartmentId": null
}И в ответ получим:
{
"@odata.context": "https://api.timetta.com/odata/$metadata#Departments/$entity",
"code": "69",
"resourceType": "Department",
"resourcePoolId": null,
"name": "Департамент",
"rowVersion": "AAAAAAACG60=",
"createdById": "00000000-0000-0000-0000-000000000000",
"modifiedById": "00000000-0000-0000-0000-000000000000",
"id": "11111111-1111-1111-1111-111111111111",
"created": "2022-07-22T20:24:00.9318599+03:00",
"modified": "2022-07-22T17:24:00.8776997Z",
"isActive": true,
"leadDepartmentId": null
}Обновление
Для обновления используются 2 HTTP метода: PUT, PATCH (последний предпочтительнее). Если бы мы хотели обновить название только что созданного департамента на "Лучший департамент", то сделали такой запрос:
PATCH /Departments(11111111-1111-1111-1111-111111111111)
{
"name": "Лучший департамент"
}И в ответ - 204 No Content
При повторном запросе:
{
"@odata.context": "https://api.timetta.com/odata/$metadata#Departments/$entity",
"code": "69",
"resourceType": "Department",
"resourcePoolId": null,
"name": "Лучший департамент",
"rowVersion": "AAAAAAACG7A=",
"createdById": "00000000-0000-0000-0000-000000000000",
"modifiedById": "00000000-0000-0000-0000-000000000000",
"id": "11111111-1111-1111-1111-111111111111",
"created": "2022-07-22T20:24:00.9318599+03:00",
"modified": "2022-07-24T05:21:09.764289Z",
"isActive": true,
"leadDepartmentId": null,
"editAllowed": true,
"deleteAllowed": true,
"rolesEditAllowed": true
}Название действительно изменилось. Также изменилось и поле "rowVersion" - для предотвращение параллельного обновления.
Но говорилось еще и о PUT. При использовании PUT нам нужно передавать ВСЮ сущность. Даже те поля, которые не обновляются (за исключением тех над которыми не имеем власти, например, rowVersion или modified). Тоже самое обновление, но с помощью PUT:
PUT /Departments(11111111-1111-1111-1111-111111111111)
{
"code": "69",
"resourceType": "Department",
"resourcePoolId": null,
"name": "Лучший департамент",
"id": "11111111-1111-1111-1111-111111111111",
"isActive": true,
"leadDepartmentId": null,
"editAllowed": true,
"deleteAllowed": true,
"rolesEditAllowed": true
}Удаление
И для удаления остался последний метод - DELETE. Удаление через ID сущности. Удалим же наш департамент:
DELETE /Departments(11111111-1111-1111-1111-111111111111)
В ответ получим - 204 No Content. И при обращении по этому же ID получаем Not Found.
Подытожим
OData - мощный веб-фреймворк, ядром которого является управление ресурсами.
Для функционирования использует возможности HTTP: HTTP методы, HTTP заголовки, строки запроса, URL.
Сервис, использующий OData, определяет свою схему. По ней можно понять какую функциональность данный сервис предоставляет:
-
Типы данных:
Перечисления, Enum
Сложные типы, ComplexType
Сущности, EntityType
-
Их атрибуты
Свойства (и свойства свойств (Nullability, MaxLength)
Навигационные свойства
Специфичные для данного типа атрибуты: ключ для сущности, значения для перечисления
Коллекции: их название, доступ, содержащийся в них тип данных
Предопределенные функции и действия (Function, Action)
Сам протокол определяет SQL подобный язык запросов (передается в строке запроса) и позволяет управлять получаемым контентом с помощью ключевых слов:
$select - в выводе только указанные поля. (~ SELECT)
$filter - вывести ресурсы, удовлетворяющие предикату (~ WHERE)
$expand - включить другие ресурсы, на который ссылается (~JOIN)
$orderby - сортировка по полю. (~ORDER BY)
$top - ограничить вывод максимальным количеством. (~TAKE)
$skip - пропустить какое-то количество. (~SKIP, OFFSET)
$count - дополнительно подсчитать общее число (или удовлетворяющих предикату) сущностей. (~COUNT)
Напоследок
OData очень большой фреймворк. Одна статья не может покрыть его полностью. Но целью этого поста стало простое ознакомление с наиболее используемой (по мнению автора) функциональностью. Многие темы не были покрыты, как например ключевое слово запроса $compute или лямбда операций any/all. Если вы хотите исследовать эту тему дальше, то вот некоторый список ссылок от куда можно стартовать:
https://www.odata.org - сайт по OData. Здесь можно найти спецификацию, туториалы для новичков и продвинутых, полезные инструменты и так далее.
https://docs.microsoft.com/en-us/odata - раздел об OData созданный Microsoft. Здесь много туториалов как по самому OData, так и по инструментам связанным с ним. Много уделяется фреймворку Microsoft.OData.
-
https://services.odata.org/ - сервис, для обучения/тестирования/просто попробовать OData. Как пользоваться для Read-Only Service:
Устанавливаю базовый URL
https://services.odata.org/V3/OData/OData.svc/Мне удобнее получать результат в виде JSON. Поэтому выставляю заголовок
Accept: application/jsonПолучаю схему OData:
https://services.odata.org/V3/OData/OData.svc/$metadataИзучаю полученную схему и делаю запросы.
-
Для получения списка всех продуктов по схеме нужно делаю такой запрос:
https://services.odata.org/V3/OData/OData.svc/ProductsRead-Only Northwind пользоваться по аналогии
Если нужно потренироваться и в модификации, то есть Read-Write. Для этого нужен ваш секретный ключ. Получить его можно, перейдя по ссылке Browse the Full Access (Read-Write) Service на указанном сайте. В браузере ваша строка заменится на строку с ключом. Либо, эту строка указывается в полученной схеме. Сам вид строки: https://services.odata.org/V3/(S(<секретный ключ>))/OData/OData.svc. А в запросах на создание (POST) нужно также указывать тип ресурса, который хотим создать в поле "odata.type" (там используется наследование, про которое не было рассказано). Например, для создания нового Product сделать вот такой запрос:
POST https://services.odata.org/V3/(S(j5lmqrfbgk1st4mmgrva1jtg))/OData/OData.svc/Products
{
"odata.type" :"ODataDemo.Product",
"Name": "Cottage cheese",
"ID": 11,
"Description": "Best cottage cheese",
"ReleaseDate": "2021-12-31T23:59:59",
"DiscontinuedDate": "2022-01-01T00:00:00",
"Rating": 5,
"Price": 123
}Полезные инструменты:
Расширение VS Code для работы с OData.
Веб-приложение для визуализации и исследования OData, по ее схеме. Использование: в верхней части в поисковике выберите вариант 'Metadata URL'. Вбейте в поисковик URL и нажмите 'Get Details'.

Триггером написания статьи было, то что автор не нашел "краш курсов" по OData и пришлось собирать знания по кусочкам. Если статья дала вам хороший старт, то значит проделанное было не зря.
Комментарии (47)

amarao
24.07.2022 13:35+1Опять XML. Не хочу. С мылом было не вкусно, с odata вкуснее не будет.

Ares_ekb
24.07.2022 15:13-1Возникла безумная идея... А что если использовать YAML? По крайней мере для всяких конфигов прошла эволюция XML -> JSON -> YAML. Почему бы и для API его не использовать?

mayorovp
24.07.2022 16:23+1Достоинство YAML перед JSON — в человекочитаемости. Нет никакого смысла использовать его в задачах, в которых как читателем, так и писателем является машина.
Ares_ekb
24.07.2022 17:03+2XML и JSON тоже человекочитаемые по сравнению, например, с protobuf. Вся разница в скобочках: угловые, фигурные, отсутствуют :)

nin-jin
24.07.2022 19:02XML -> JSON -> YAML -> Tree
amarao
24.07.2022 19:48Полистал. Во-первых на русском. Не взлетит. 97-98% населения планеты его не знают и учить не планируют.
Во-вторых экранирование ужасное. Как выглядит Tree внутри которого строка, содержащая в себе Tree, внутри которой находится, например, строка с yaml с многострочным литералом внутри которого докстринг с примером Tree?
nin-jin
24.07.2022 20:03Во-первых на русском.
Как выглядит Tree внутри которого строка, содержащая в себе Tree
hello some \ tree \ \hello \ another \ \ tree \ \ \hello: \ \ yaml: "" \ \ too: |- \ \ hello \ \ tree \ \ \ again \ \ \ \plain \ \ \textСмысла в этом мало, конечно.
amarao
24.07.2022 20:22Во. Сравните с это с yaml'ом.
nested_yaml: | another_nested: | and_random_gibberish: | j: :ff : - fsdfjd : sdlfdf - sdlkfsld "multiline в yaml - это то, за что можно простить on/false/yes.
nin-jin
24.07.2022 20:31Сравнил:
Сложно отследить, где закончился ямл и началась строка - нужно смотреть концы всех предыдущих строк. Подсветка синтаксиса есть не везде, особенно, если сам ямл находится в строке.
Элементы списка идут на том же уровне отступа, что и ключи, что усложняет ориентирование. Дефисы только путают.
Что происходит на 4 строке мало кто сможет ответить правильно.
amarao
24.07.2022 20:47Это всё такая мелочь на фоне проблемы "вставить блок в формат..."
Для того, чтобы вставить в Tree мне нужно будет менять каждую строку. Взрывая мозг себе и окружающим (если это повторная вставка вложенного текста).
Если вы думаете, что это редкий сценарий...
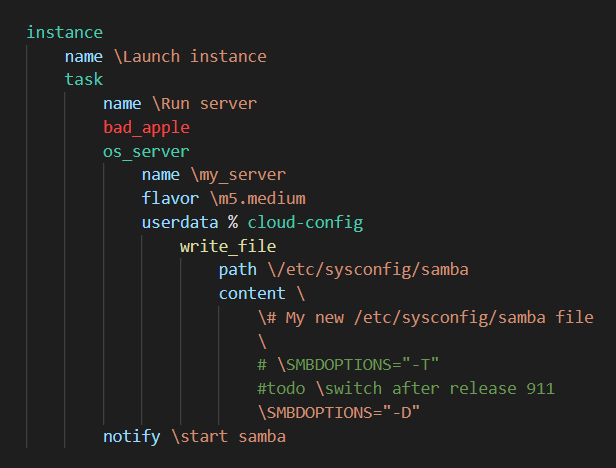
Представьте себе плейбуку ансибла (yaml), засылающего параметром в модуль os_server userdata (который тоже в yaml).
- name: Run server os_server: name: my_server flavor: m5.medium userdata: | #cloud-config write_files: - path: /etc/sysconfig/samba content: | # My new /etc/sysconfig/samba file SMBDOPTIONS="-D" notify: start sambaЭто я не придумываю, пример cloud-init - из официальной документации cloud-init'а.
Для меня это настолько киллерфича, что любой формат, который потребует реформатирования, автоматически дисквалифицируется.
nin-jin
24.07.2022 21:31чтобы вставить в Tree мне нужно будет менять каждую строку
Её в любом случае менять - надо добавить отступы. А если за вас это делает редактор, то и бэкслеши он добавить в состоянии.
Представьте себе плейбуку ансибла (yaml), засылающего параметром в модуль os_server userdata (который тоже в yaml)
Представил:
amarao
24.07.2022 21:52Сдвиг пробелами - наименее инвазивная форма, которая справляется с leading spaces и сохраняет общую структуру отступов.
Простите, мне реально надо вставлять '\' в середину строки? Это не опечатка? `todo \switch after release 911`?
А что делать, если у меня строка начинается с '\'? Удваивать?
--- - hosts: localhost tasks: - shell: /bin/echo -e " \\e[33;1m \\\\ - is a backslash "> /dev/ttynin-jin
24.07.2022 21:58мне реально надо вставлять '\' в середину строки? Это не опечатка? `todo \switch after release 911`?
Слева от бэкслеша структурные узлы, справа - сырые данные.
что делать, если у меня строка начинается с '\'? Удваивать?
Не важно с чего она начинается, в том-то и дело. Бэкслеш явно показывает начало сырых данных. Можете туда хоть бинарник засунуть.
Ares_ekb
25.07.2022 04:22Для меня в S-expressions такие конструкции выглядят понятнее. А ещё там есть quasiquote, unquote, unquote-splicing, позволяющие, например, в середину шаблона вставлять переменные. Для конфигов это выглядит интересной фичей. Может цикл наконец замкнется и люди вернутся к круглым скобочкам...
amarao
24.07.2022 19:44Я не видел много API с yaml внутри. Обычно yaml - это для человеков. За вычетом нескольких интересных типов, они близки (если быть точным, json - подмножество yaml), и API обычно на json'е неплохо себя чувствует. Обычно от json уходят в сторону протобафа, потому что так сильно быстрее.
Уходить от json в сторону xml - это делать всё одновременно нечитаемым, сложным для компьютеров (всякого рода xml bombs и т.д.), и оставаться медленным.

shark14
24.07.2022 16:56Так там же говорится, что схему можно не только в виде XML описывать, но и в виде JSON.
nin-jin
25.07.2022 00:52+3У XML есть киллер фича - к нему можно подцепить XSLT который при открытии ссылки из браузера нарисует разрабу красивый UI. Вот тут я делал пример. Странно, что я этого нигде не видел.

Xobotun
25.07.2022 09:29+3Для меня киллер-фича XML — что можно указать XSD-схему прямо в тексте документа, и что современные IDE умеют их парсить и включать автодополнение и подсвечивать некорректные токены.
Если у какого-то языка разметки данных нет столь же лёгкой в понимании воможности подключить схему, то он неудобен для меня.

OFrol
25.07.2022 11:22-1Для JSON аналогом является JSON Schema и атрибут
$schemaв корне документа. Это как-раз даёт возможность IDE налету валидировать документ и делать автодополнение
amarao
25.07.2022 09:38-2Да, для API это называется swagger. Зачем это на уровень браузера вытащить?
nin-jin
25.07.2022 11:02+1Если вы про сваггер инспектор, то это отдельный тул, через который нужно открывать ссылку. Это не так удобно, как просто переход по ней. К тому же он тупо раскрашенный json показывает, а это куча визуального шума, многострочный текст в одну строку, нет гиперссылок на связанные ресурсы, поиска и так далее.


MisterX
24.07.2022 13:38+2Вроде все неплохо, но стандарт вообще не популярный, и кмк не развивается. Даже на сайте https://www.odata.org/blog/ последняя запись 2018 года.
Ares_ekb
24.07.2022 15:16-1Раньше был норм. Но по моим ощущениям за пределами .NET он не особо распространился. Не очень понятна его ниша сейчас, когда какие-нибудь GraphQL или HATEOAS решают похожие задачи.
mayorovp
24.07.2022 16:25Э-э-э, сравнение с GraphQL тут понятно (решается одна и та же задача), но HATEOAS-то тут каким боком?
Ares_ekb
24.07.2022 17:31И то и другое это как минимум REST API 2-го уровня. Т.е. они даже ближе друг к другу, чем к GraphQL.
В .NET можно описать схему данных и получить готовое OData API. И, например, в Spring можно описать схему данных, репозитории данных и получить готовое HATEOAS API через Spring Data. Ну, т.е. общая решаемая задача - получить API на основе схемы данных с минимальными усилиями.
В самом HATEOAS как в подходе этого нет, но Spring'овая реализация предоставляет разные стандартные ссылки типа получения следующей страницы для коллекции объектов и т.п. Т.е. в обоих случаях решаемая задача - это стандартизация API. Не нужно изобретать свои запросы для пагинации, сортировки.
Другая общая задача - предоставление метаданных. По крайней мере в Spring реализации есть profile-ссылки. HAL Forms из той же области, хотя я ими никогда не пользовался.
Ещё в статье упоминается следующее:
OData определяет функции (Function) и действия (Action)
Function - это операция над ресурсами, которая обязательно возвращает значение и не имеет сторонних эффектов.
Action - это операция, которая может изменить значение
Я не помню, чтобы я пользовался этим в OData, но в HATEOAS это основная фишка. Т.е. общая задача, решаемая этими протоколами - это предоставлении информации о том, какие действия доступны для ресурса, в какое новое состояние его можно перевести.
На мой взгляд у этих протоколов много пересечений. Там где в .NET используется OData, в Java скорее всего будет использоваться HATEOAS.
mayorovp
24.07.2022 17:56Вы как-то сильно путаете HATEOAS и детали спринговой реализации. HATEOAS — это, в терминах той статьи на которую вы привели ссылку, основной принцип REST 3 уровня, и больше этот термин не означает ничего.
HATEOAS не предусматривает ни коллекций сущностей, ни стандартной формы запросов к ним, ни даже машиночитаемой схемы!
Ares_ekb
24.07.2022 19:18Я согласен, HATEOAS - это абстрактный подход в абстрактном вакууме, в котором практически ничего нет. Но есть в разных форматах, построенных на нём. В Siren даже сущности и коллекции упоминаются. В HAL-FORMS много метаданных. Хотя всё это и на много проще, чем OData.
Это конечно слишком абстрактная аналогия. Но всё-таки даже если соотносить чистый HATEOAS и OData, всё равно в основе одна идея, что сервер передаёт клиенту какие-то метаданные. В случае OData - это схема данных, действия и функции. В случае HATEOS - это ссылки (по смыслу аналог действий и функций из OData). А затем пользователь принимает решение куда перейти дальше (к какой сущности или по какой ссылке) и переходит. Даже схема данных в OData с одной стороны конечно машиночитаемая, но всё равно решение о том какие данные запрашивать принимает пользователь.
На мой взгляд всё-таки идея одна. Клиент меньше привязан к серверу, более универсальный. У пользователя есть возможность, грубо говоря, "напрямую" получать информацию от сервера о том, что он может делать.
А отличия в том, что, да, в спецификации OData описано дофига всего. А HATEOAS - это практически просто идея, даже формат ссылок не определен, при этом более конкретные вещи определены уже в отдельных спецификациях (HAL, HAL-FORMS, Siren, ...).
Честно говоря, с некоторой натяжкой я бы даже назвал OData одной из реализаций HATEOAS :)
mayorovp
24.07.2022 19:33Я согласен, HATEOAS — это абстрактный подход в абстрактном вакууме, в котором практически ничего нет. Но есть в разных форматах, построенных на нём. В Siren даже сущности и коллекции упоминаются. В HAL-FORMS много метаданных. Хотя всё это и на много проще, чем OData
Ну так и сравнивайте с OData эти самые Siren и HAL-FORMS (вон, у них даже названия есть!), зачем приплетать сюда HATEOAS?
Честно говоря, с некоторой натяжкой я бы даже назвал OData одной из реализаций HATEOAS :)
Со слишком большой натяжкой. Для HATEOAS недостаточно положить метаданные где-то рядом, все допустимые ресурсы должны быть доступны по ссылкам начиная с некоторого корня (или корней). Фактически, HATEOAS несовместим с любым языком запросов.

Alexsey
24.07.2022 17:00Да даже в .NET нынче с ним связываться - боль и страдание. Мы года полтора назад по глупости пытались новый проект на нем запустить, поплевались и переписали на web api с нужными самописными обертками все. Odata нынче больше мертв чем жив и "автор не нашел "краш курсов" по OData и пришлось собирать знания по кусочкам" как раз очень хорошая демонстрация этого.

TimsTims
24.07.2022 14:01-1За статью спасибо, хорошо знать, чего надо остерегаться. Вот серьезно, зачем столько сложностей. Тут и схема на xml, а ответы в json. Запросы Get-ом, которые могут закешироваться. SQL прямо в запросе. Столько всего намешано, что получился какой-то монстр.
mayorovp
24.07.2022 14:04+1Э-э-э, а где тут sql прямо в запросе? Или теперь любой язык запросов — это sql?
TimsTims
24.07.2022 14:39Можно делать запросы к ресурсам прямо в строке запроса. Для запросов есть свой специальный язык. По фукнционалу он очень похож на SQL.
Не чистый SQL само собой, но теперь тебе помимо SQL нужно ещё знать как Odata его интерпретирует в SQL (у odata ведь ещё пока нет своего встроенного движка субд?), и делает ли он это оптимально, или как обычный ORM - через жопу.
Начинали с неплохой api которая задумывалась "хорошей заменой других restfull", закончили встроенным ORM.
mayorovp
24.07.2022 14:49Учитывая, что вложенные запросы в условии $filter (оно же where), как и какая-нибудь группировка, не поддерживаются — накосячить в трансляции запросов затруднительно.
TimsTims
24.07.2022 23:03+1запросы в условии $filter (оно же where)
Есть хоть одна причина, почему WHERE нужно было называть словом $filter?$filter=approvalInstanceId ne null
И почему NOT NULL здесь решили писать ne null? Как-будто кто-то сделал транслитерацию перевода учебника по SQL.
Почему так важен not null? Потому-что в SQL NULL это не пустая строка. И это не 0. Это отдельное значение. Для SQL where NOT NULL… Как его обрабатывает OData в этом случае? Я не знаю, ведь авторы таким образом могли сделать всё что угодно. Я видел такие ORM, которые сначала делают SELECT *, а все условия парсят уже на своей стороне. А очень популярная в PHP ORM Eloquent — если делать нежадный JOIN таблиц, то он сначала выберет все ИД из одной таблицы, а затем вставит их в WHERE IN второй. Никакого вам INNER JOIN.Можно сделать несколько запросов: сначала массив табелей, затем для каждого — запрос на информацию о пользователе. Но это лишнее. Можно ведь сделать просто — добавить $expand:
Почему $expand а не join? Опять-же, у меня было 100500 случаев, когда нужно в условии JOIN прописать сразу два условия (Join), как здесь их прописать? Не уверен, что такое возможно, если только не дописывать в $filter (но возможно не пройдет валидацию).
Короче сделали свой SQL, который делает тоже самое что и SQL, но писать надо на другом языке. Ну и тема с доступом к данным не раскрыта — буквально сразу такая API потребует ограничения со всех сторон, и проще будет писать свои запросы на сервере, чем позволять это делать пользователю.mayorovp
24.07.2022 23:25+2Есть хоть одна причина, почему WHERE нужно было называть словом $filter?
А есть хоть одна причина, почему оператор фильтрации нужно было называть словом WHERE? :-)
И почему NOT NULL здесь решили писать ne null? Как-будто кто-то сделал транслитерацию перевода учебника по SQL.
Потому что not equals null.
Как его обрабатывает OData в этом случае? Я не знаю, ведь авторы таким образом могли сделать всё что угодно. Я видел такие ORM, которые сначала делают SELECT *, а все условия парсят уже на своей стороне. А очень популярная в PHP ORM Eloquent — если делать нежадный JOIN таблиц, то он сначала выберет все ИД из одной таблицы, а затем вставит их в WHERE IN второй. Никакого вам INNER JOIN.
А это для клиента не важно, это проблема того кто пишет бэк.
Кстати, WHERE IN вместо INNER JOIN — совершенно корректный способ соединения коллекций если они лежат на разных серверах СУБД.
И да, сделать
SELECT *и парсить на стороне бэкенда — это, конечно, зашквар для ORM, но всё ещё валидный случай для OData. Заметьте: несмотря на повышенное потребление ресурсов, траффик до клиента всё ещё экономится. Просто представьте что было бы, если бы ещё и клиенту результатыSELECT *выдавались...Ну и тема с доступом к данным не раскрыта — буквально сразу такая API потребует ограничения со всех сторон
Не потребует, потому что доступ тут настраивается настолько элементарно что я не понимаю зачем вообще об этом говорить: просто на этапе формирования запроса к БД добавляем в блок WHERE условие что присутствует доступ к записи.
mayorovp
25.07.2022 00:22+1Ах да, что-то не сразу заметил:
Почему $expand а не join?
Потому что в OData вы не джойните произвольные коллекции, а раскрываете вложенные записи.
Опять-же, у меня было 100500 случаев, когда нужно в условии JOIN прописать сразу два условия (Join), как здесь их прописать?
Никак. Обращайтесь к бекендеру, пусть даст вам отдельное API для такого хитрого запроса.

denisromanenko
24.07.2022 20:32+1Проблема ОДаты - в том что она протокол, а не решение.
Типа большие дяди с Майкрософт во главе порешали и сказали "Слушайте, а как было бы здорово, если бы все бизнес-программы могли обмениваться данными примерно одинаково, ну чтобы ты знал что можешь ожидать? Во здорово-то будет".
Реализация же этого всё равно ложится на разработчика. Сейчас есть решения по типу Hasura и Postgraphile, которые простраивают прямо из БД доступ ко всем сущностям, и даже по более простому стандарту OpenAPI. Полный REST автоматически и бесплатно.
Так что ОДата, к сожалению, немного сейчас не нужна уже.
P.S. Но за то, что 1С её поддерживает, за это разработчикам ОДаты низкий поклон - работать с данными в 1С так гораздо удобнее.
P.P.S. Одата может отдавать и JSON, просто дописываешь к строке запроса &$format=json

alexhott
25.07.2022 09:52Работали с одатой без XML.
Все прекрасно дружит с Core WEB Api и работает на JSON.
Но вещь специфическая, да можно быстро на БД повешать апи для работы со всеми сущностями. Но тут подключаются архитекторы с разными принципами и вот волшебная одата в них уже не совсем вписывается.
Делили все на сервисы: Сервис работы со сделками ,сервис работы с контрагентами ...
Сервис работы со сделкой, например имеет методы работы с сущностями "Государственный контракт", "Муниципальный контракт" атрибуты и логика различается, а в базе это один и тотже набор таблиц. В итоге ОДАТА какбы с сырыми данными работает.
Ну и вы забыли что можно через такой апи запулить запрос типа "Select * from database" от которого сервер БД прикурит. И надо сразу ограничения прописывать (механизм кстати есть в odata) типа нельзя все поля селектитить, всегда ограничение на размер выборки, и т.п.mayorovp
25.07.2022 09:59Сервис работы со сделкой, например имеет методы работы с сущностями "Государственный контракт", "Муниципальный контракт" атрибуты и логика различается, а в базе это один и тотже набор таблиц. В итоге ОДАТА какбы с сырыми данными работает.
Это кто-то где-то недоработал. Нет никаких проблем сделать две разные коллекции "Государственный контракт" и "Муниципальный контракт", отображая их на одну и ту же таблицу с разными фильтрами.
nin-jin
25.07.2022 11:07А ОДата тут при чём? Те же проблемы у вас были бы и с любым другим автоматическим адаптером к субд.
rPman
Про обработку ошибок и поведение в неоднозначных ситуациях?
Типа при удалении что происходит с теми кто ссылается на удаляемый объект? delete cascade?
AshBlade Автор
Я посчитал, что для вводной статьи это много. Но если кого интересует, то напишу тут:
При удалении сервис должен сам проверить и обновить ссылаемые/ссылающиеся сущности: удалить их, поставить null или значение по умолчанию. Выбор действия зависит от ограничения в обозначенного в схеме. Это не относится к НЕ внешним ключам.
Например, если сущность, на которую мы ссылаемся ключом fk_id = '11111', удалится, то сервис обязан обновить наш ссылающийся ключ (в зависимости от типа отношений: проставить null, или удалить нас самих). Но если это поле зависит от другой сущности по бизнес логике не прописанной в схеме, то сервис не обязан делать обновления.
Грубо говоря, поведение при удалении описывается схемой.
https://docs.oasis-open.org/odata/odata/v4.01/odata-v4.01-part1-protocol.html#sec_DeleteanEntity