
Приветствую.
Год назад меня сильно увлекла тема отказоустойчивости приложений. Я начал изучать различные аспекты ее реализации в программах и больше всего меня заинтересовал процесс работы с диском. Ресурсов для изучения много, но они все разбросаны по сети и мне понадобилось время, чтобы сложить все кусочки пазла. Здесь я попытаюсь этот пазл собрать воедино, чтобы структуризировать полученные знания.
Для начала разберем путь операции записи, начиная с самого приложения.
Приложение
Все начинается в нашем коде. Обычно имеется интерфейс для работы с файлами. Это зависит от ЯП, но примеры:
fwrite- Cstd::fstream.write- C++FileStream.Write- C#FileOutputStream.Write- Javaopen().write- Pythonos.WriteFile- GO
Это все средства предоставляемые языками программирования, для работы с файлами: запись, чтение и т.д. Их преимуществом является независимость от платформы, на которой мы работаем. Но также и привносит свои недостатки. В данном случае, это буферизация.
Судя по документации, то из приведенных выше все ЯП используют либо поддерживают буферизацию:
C - setvbuf
C++ - filebuf
C# - BufferedFileStrategy
Java - Files.newBufferedReader
Python - io.BufferedIOBase
GO - bufio.Reader
Насчет C# - в реализации
FileStreamиспользуетсяFileStreamStrategyкласс, который обрабатывает запросы.
Например, при созданииFileStreamчерезFile.Open,BufferedFileStrategyобертывает целевойOSFileStreamStrategy.
Вообще, буферизация в пространстве пользователя штука неплохая, так как позволяет повысить производительность. Но если не знать этого, то часть данных может быть не записана. Тут может быть 2 случая:
Буферизованный файл создан вручную (GO, Java).
Буферизация происходит прозрачно для программиста (C, C++).
Если в первом случае мы точно знаем, что буферы надо сбросить после окончания записи, то второй вариант позволит выстрелить себе в ногу:
Приложение экстренно закроется (например, получили SIGKILL нельзя обработать) и буферы уровня приложения просто не сбросятся.
Файл после создания будет где-то в памяти и при закрытии буферы сброшены не будут, т.к. просто забудем сделать это.
Выходов здесь 2:
Сбрасывать буферы после каждого сеанса записи. Например, во время логирования мы сначала весь батч записываем через
writeи, только после сбрасываем буфер.Отключить буферизацию вообще и делать записи напрямую.
На мой взгляд, более привлекательный вариант - первый, так как он позволит немного повысить производительность.
Сравнение производительности
Для сравнения производительности я провел небольшой бенчмарк. Производил последовательную запись 64Мб данных в файл.
Тестирование производил на старом ноутбуке с HDD и новом с SSD M.2. Результаты следующие:
Ноутбук |
Не буферизированная запись, с |
Буферизированная запись, с |
|---|---|---|
Старый |
894.7 |
109.6 |
Новый |
8.932 |
1.198 |
Результат не удивителен: буферизированная запись быстрее чуть больше чем в 8 раз. Код бенчмарка расположен здесь.
ОС
Язык программирования дает хорошую абстракцию платформы - разработчику не нужно думать (как минимум, не так часто) на какой операционной системе работает приложение. Но в любом случае функции языка будут транслироваться/превращаться в системные вызовы ОС. Эти системные вызовы специфичны для каждой операционной системы, но в общем случае всегда есть для работы с файлами. Например, вот примерное отображение:
Операция |
*nix |
Windows |
|---|---|---|
Открытие/создание |
open |
CreateFile |
Чтение |
pread |
ReadFile |
Запись |
pwrite |
WriteFile |
Закрытие |
close |
CloseFile |
Под *nix имеют Unix-подобные ОС (Linux, FreeBSD, OSX). Названия у их системных вызовов одинаковые, хоть и поведение немного отличается.
На уровне ОС тоже присутствует буферизация - страничный кэш. И вот с помощью нее выстрелить в ногу еще проще.
При работе с файлом (чтение/запись) данные из него читаются страницами, даже когда запрошен только 1 байт (записать или прочитать). Когда страница была изменена, то она называется "грязной" и будет сброшена на диск. Причем в памяти одновременно может находиться множество страниц, они и создают страничный кэш - буфер уровня ОС. Так где это может нам повредить? Представим следующий процесс:
Нам пришел запрос на обновление данных о пользователе
Мы открываем файл с данными
Переписываем имеющийся диапазон имени переданным значением (представим, что для имени выделено в файле 255 символов)
Сообщаем пользователю, что имя успешно обновлено
Где может возникнуть проблема? После 4 шага. Представим, что после отправки ответа об успешно выполненной операции произошло отключение электричества. В результате имеем такую ситуацию:
Пользователь думает, что имя обновлено
Данные о пользователе хранятся старые
Почему старые? Потому что перезаписанное имя хранилось на грязной странице в памяти, а не на диске, и при отключении электричества мы ее сохранить не успели.
Страничный кэш полезен, когда над одним участком памяти производится множество операций чтения/записи. Но в случае, когда изменения должны быть "закоммичены" нам необходимо убедиться, что записанные данные действительно были сброшены на диск. Для этого можно применить несколько стратегий:
Системные вызовы для сброса буферов
При открытии файла говорить сразу, что буферизация не нужна
Системные вызовы для сброса страниц
Первый вариант использует специальные системные вызовы.
Linux
Для Linux можно использовать:
fdatasync(fd)- проверяет, что данные в памяти и на диске синхронизированы, т.е. выполняет сброс страниц и при необходимости обновляет размер файла;fsync(fd)- то же самое что иfdatasync, но дополнительно синхронизирует метаданные файла (время доступа, изменения и др.);sync_file_range(fd, range)- проверяет, что указанный диапазон данных файла сброшен на диск;sync()- эта функция тоже синхронизирует содержимое буферов и дисков, только делает это для всех файлов, а не указанного.
Как уже было сказано, fdatasync синхронизирует только содержимое, без метаданных как fsync, поэтому он выполняется быстрее.
В etcd делается явное различие между этими 2 вызовами:
// Fsync is a wrapper around file.Sync(). Special handling is needed on darwin platform.
func Fsync(f *os.File) error {
return f.Sync()
}
// Fdatasync is similar to fsync(), but does not flush modified metadata
// unless that metadata is needed in order to allow a subsequent data retrieval
// to be correctly handled.
func Fdatasync(f *os.File) error {
return syscall.Fdatasync(int(f.Fd()))
}
Больше про эти системные вызовы описано в статье Устойчивое хранение данных и файловые API Linux.
Windows
Для Windows это:
_commit(fd)- сбрасывает данные файла прямо на диск. Работает с файловым дескрипторомFlushFileBuffers(hFile)- вызывает запись всех буферных данных в файл. Работает с хэндлом ОСNtFlushBuffersFileEx(hFile, params)- сброс страниц на диск, но в отличие от предыдущего имеет большую гранулярность за счет дополнительных параметров. Работает с хэндлом ОС
P.S. NtFlushBuffersFileEx используется в Postgres как обертка для кроссплатформенного fdatasync, а для fsync - _commit
// https://github.com/postgres/postgres/blob/9acae56ce0b0812f3e940cf1f87e73e8d5784e78/src/include/port/win32_port.h#L85
/* Windows doesn't have fsync() as such, use _commit() */
#define fsync(fd) _commit(fd)
// https://github.com/postgres/postgres/blob/874d817baa160ca7e68bee6ccc9fc1848c56e750/src/port/win32fdatasync.c#L23
int
fdatasync(int fd)
{
// ...
status = pg_NtFlushBuffersFileEx(handle,
FLUSH_FLAGS_FILE_DATA_SYNC_ONLY,
NULL,
0,
&iosb);
// ...
}
macOS
Также стоит упомянуть macOS. Она хоть и является POSIX совместимой, т.е. предоставляет системный вызов fsync, но его одного недостаточно. Для нее требуется дополнительный вызов fcntl(F_FULLSYNC). Это также прописывается в документации:
For applications that require tighter guarantees about the integrity of their data, Mac OS X provides the F_FULLFSYNC fcntl.
При разработке на macOS об этом стоит помнить, иначе вероятность потерять данные высока. В etcd это поведение учитывается:
// Fsync on HFS/OSX flushes the data on to the physical drive but the drive
// may not write it to the persistent media for quite sometime and it may be
// written in out-of-order sequence. Using F_FULLFSYNC ensures that the
// physical drive's buffer will also get flushed to the media.
func Fsync(f *os.File) error {
_, err := unix.FcntlInt(f.Fd(), unix.F_FULLFSYNC, 0)
return err
}
// Fdatasync on darwin platform invokes fcntl(F_FULLFSYNC) for actual persistence
// on physical drive media.
func Fdatasync(f *os.File) error {
return Fsync(f)
}
Говорим ОС, что синхронизация не нужна
Для второго варианта, нам нужно открывать файл с необходимым параметром.
В Linux это можно сделать передав параметры O_SYNC | O_DIRECT функции open:
O_SYNC- любая запись сразу сбрасывается на диск (есть ещеO_DSYNC- синхронизация только данных, без метаданных)O_DIRECT- запись проводится в обход страничного кеша, т.е. отключает его
Использование флага O_SYNC/O_DSYNC можно сравнить с тем, что после каждого write будет вызываться fsync/fdatasync, соответственно.
С помощью fcntl после открытия файла можно изменить только O_DIRECT флаг, но не O_SYNC. Это прописано в описании fcntl:
... It is not possible to change the O_DSYNC and O_SYNC flags; see BUGS, below.
В Windows для этого есть свои аналоги: флаги FILE_FLAG_NO_BUFFERING и FILE_FLAG_WRITE_THOUGH для функции открытия файла CreateFile:
FILE_FLAG_NO_BUFFERING- отключает буферизацию ОС при записиFILE_FLAG_WRITE_THOUGH- все записи сбрасываются на диск, без внутреннего кэширования
В документации дано описание поведению при указании обоих флагов:
If FILE_FLAG_WRITE_THROUGH and FILE_FLAG_NO_BUFFERING are both specified, so that system caching is not in effect, then the data is immediately flushed to disk without going through the Windows system cache. The operating system also requests a write-through of the hard disk's local hardware cache to persistent media.
А в этой статье составили таблицу их совместного использования:
NO_BUFFERING |
|||
Нет |
Выставлен |
||
WRITE_THROUGH |
Нет |
Страничный кэш ОС используется. Отложенная запись на диск. Без аппаратного сброса |
Страничный кэш ОС _не_ используется. Немедленная запись на диск. Без аппаратного сброса |
Выставлен |
Страничный кэш ОС используется. Немедленная запись на диск. Аппаратный сброс |
Страничный кэш ОС _не_ используется. Немедленная запись на диск. Аппаратный сброс |
|
"Hardware flush", который использовался в статье, я перевел как "аппаратный сброс". По факту, это означает "записывать минуя внутренний кэш накопителя".
В Postgres имеется следующее отображение этих флагов:
Windows |
Unix |
|---|---|
FILE_FLAG_NO_BUFFERING |
O_DIRECT |
FILE_FLAG_WRITE_THROUGH |
O_DSYNC |
// https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/port/open.c#L65
HANDLE
pgwin32_open_handle(const char *fileName, int fileFlags, bool backup_semantics)
{
// ...
while ((h = CreateFile(fileName,
// ...
((fileFlags & O_DIRECT) ? FILE_FLAG_NO_BUFFERING : 0) |
((fileFlags & O_DSYNC) ? FILE_FLAG_WRITE_THROUGH : 0),
NULL)) == INVALID_HANDLE_VALUE)
// ...
}
Синхронизация директорий
Но это еще не все. Вспомним, что 1) файлы создаются, удаляются и перемещаются и 2) директории - тоже файлы. То есть при изменении содержимого директории, ее содержимое должно быть сброшено на диск так же как и файл. В POSIX выполняется это точно так же, как и с файлами - вызываем fsync(directory_fd) на дескриптор директории. Это поведение задокументировано:
Calling fsync() does not necessarily ensure that the entry in the directory containing the file has also reached disk.
For that an explicit fsync() on a file descriptor for the directory is also needed.
P.S. Я искал информацию о том, можно ли избежать ручного вызова fsync для директории через указание флага O_SYNC при открытии, но ничего не нашел. Если знаете, влияет ли этот флаг, то подскажите в комментариях.
Что же касается Windows, то там это сделать нельзя: хэндл для директории получить можно (с помощью того же CreateFile, например), но при вызове FlushFileBuffers возникает ошибка EACCESS - FlushFileBuffers работает только с файлами, либо томом (сброс данных всех файлов тома), но для последнего нужны повышенные привилегии.
Эта особенность должна учитываться. В Postgres проверяется:
/*
* fsync_fname_ext -- Try to fsync a file or directory
*
* If ignore_perm is true, ignore errors upon trying to open unreadable
* files. Logs other errors at a caller-specified level.
*
* Returns 0 if the operation succeeded, -1 otherwise.
*/
int
fsync_fname_ext(const char *fname, bool isdir, bool ignore_perm, int elevel)
{
returncode = pg_fsync(fd);
/*
* Some OSes don't allow us to fsync directories at all, so we can ignore
* those errors. Anything else needs to be logged.
*/
if (returncode != 0 && !(isdir && (errno == EBADF || errno == EINVAL)))
{
// ...
return -1;
}
return 0;
}
Ошибки fsync
fsync может вернуть ошибку и ее необходимо обработать. Это было показано в примере выше. Если она вернула ошибку, то единственное допустимое действие - завершение работы. Почему? Потому, что после этого мы не можем быть уверены в том, что файл остался в согласованном состоянии, даже если с точки зрения файловой системы он не поломан (об этом дальше),
Файловая система может быть повреждена
В файле может появиться дыра (неправильная запись)
Грязные страницы для записи могут быть помечены чистыми и больше сброшены не будут
Последнее может привести к тому, что состояния файла на диске и в памяти разные, но заметно этого не будет.
Для справедливости стоит сказать, что пометка страниц чистыми - это часть реализации Linux, так как он предполагает, что файловая система возьмет на себя обязательства корректно закончить операции. Вот тут есть примеры поведения различных ОС при ошибке fsync (что происходит со страницами):
Darwin/macOS - отбрасываются
OpenBSD - отбрасываются
NetBSD - отбрасываются
FreeBSD - остаются грязными
Linux (после 4.16) - помечаются чистыми
Windows - неизвестно
Можно привести пример, когда некорректное управление этими ошибками приводило к потерям данных - сохранение данных WAL в Postgres. Изначально, разработчики базы данных предполагали, что семантика fsync следующая:
Если
fsync()выполнился успешно, то все записи с момента последнего успешногоfsyncбыли сброшены на диск
Т.е. если мы сейчас вызвали fsync и он вернул ошибку, то мы можем повторить этот вызов в будущем в надежде, что данные в итоге попадут на диск. Но это ошибочное предположение. В реальности, если fsync вернул ошибку, то грязные страницы будут просто "забыты". Поэтому правильнее утверждать:
Если
fsync()выполнился успешно, то все записи с момента последнегоуспешногоfsyncбыли сброшены на диск
Это было замечено в 2018 году и вопрос поднялся в списке рассылки. Багу даже дали название fsyncgate 2018 и посвятили отдельную страницу на вики. Сам баг исправлен в версии 12 (и во многих предыдущих) в этом коммите следующим образом (изменение уровня критичности ошибки):
// https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/backend/storage/file/fd.c#L3936
int
data_sync_elevel(int elevel)
{
return data_sync_retry ? elevel : PANIC;
}
// Любая функция, например эта - https://github.com/postgres/postgres/blob/30e144287a72529c9cd9fd6b07fe96eb8a1e270e/src/backend/access/heap/rewriteheap.c#L1132
void sample_function()
{
// Любой вызов fsync в логике
if (pg_fsync(fd) != 0)
// ereport(ERROR,
ereport(data_sync_elevel(ERROR),
(errcode_for_file_access(),
errmsg("could not fsync file \"%s\": %m", path)));
}
Страничный кэш в БД
Работа с диском - важная часть любой базы данных. Поэтому многие реализуют свою систему работы со страничным кэшэм и не полагаются на механизмы ОС. Благодаря этому:
Более эффективный IO, т.к. запись на диск производится только после
COMMITИспользуются (потенциально) более оптимальные алгоритмы замещения страниц
Размер страницы и их количество в памяти может настраиваться
Безопасность работы с данными
Вот примеры некоторых СУБД:
СУБД |
Реализация |
Где почитать |
Алгоритм замещения страниц |
|---|---|---|---|
Postgres |
clock-sweep |
||
SQL Server |
Исходников не нашел |
LRU-2 (LRU-K) |
|
Oracle |
Исходников не нашел |
LRU, Temperature-based |
|
MySQL (InnoDB) |
LRU |
Как уже было сказано, собственный менеджер буферов позволяет оптимизировать работу СУБД, поэтому многие разработчики не останавливаются на единственном "умном" алгоритме замещения страниц. Примеры:
ORACLE и SQL Server имеет возможность использовать flash накопители в качестве временного хранения буферов, вместо сброса на основной диск (параметр
DB_FLASH_CACHE_FILEдля Oracle и расширение Buffer Pool для SQL Server)Postgres позволяет "разогревать" кэш страниц с помощью расширения
pg_prewarm
Я немного посмотрел исходники ядра и, возможно, нашел реализацию fsync тут
Файловая система
Когда речь идет про запись в файлы, обычно говорят "записать на диск". Отчасти это верно, но между ОС и диском есть важное связующее звено - файловая система. Она отвечает за то, как и куда будет производиться запись.
Файловых систем существует огромное количество, поэтому я выделю лишь часть:
ext4, ext3, ext2
btrfs
xfs
ntfs
Выбрал эти, так как часто упоминаются и многие исследования используют именно их
Каждая файловая система обладает своими характеристиками, параметрами и особенностями. Например, максимальная длина имени файла. Но сейчас нас интересуют те, что связаны с записью и сохранностью данных.
Поддержка целостности файловой системы
Для обеспечения целостности файловой системы могут использоваться различные механизмы:
Журналирование (ext3, ext4, ntfs, xfs) - файловая система ведет лог операций (WAL)
Copy-on-write (btrfs, zfs) - при пере/до записи содержимое не меняется, а вместо этого выделяется новый блок, куда новые данные и записываются
log structured - сама файловая система является большим логом операций
Но не все файловые системы поддерживают подобные механизмы безопасности. Например, ext2 - не журналируемая и любые операции идут сразу в файл.
Вроде бы вот таблетка от проблем - выбирай файловую систему с журналом (или другим механизмом) и радуйся жизни. Но нет.
Исследование Model-Based Failure Analysis of Journaling File Systems показало, что даже журналируемые файловые системы могут оставить систему в некорректном состоянии. Было изучено поведение 3 файловых систем (ext3, reiserfs и jfs) при возникновении ошибки записи блока. Результат их работы приведен в следующей таблице.
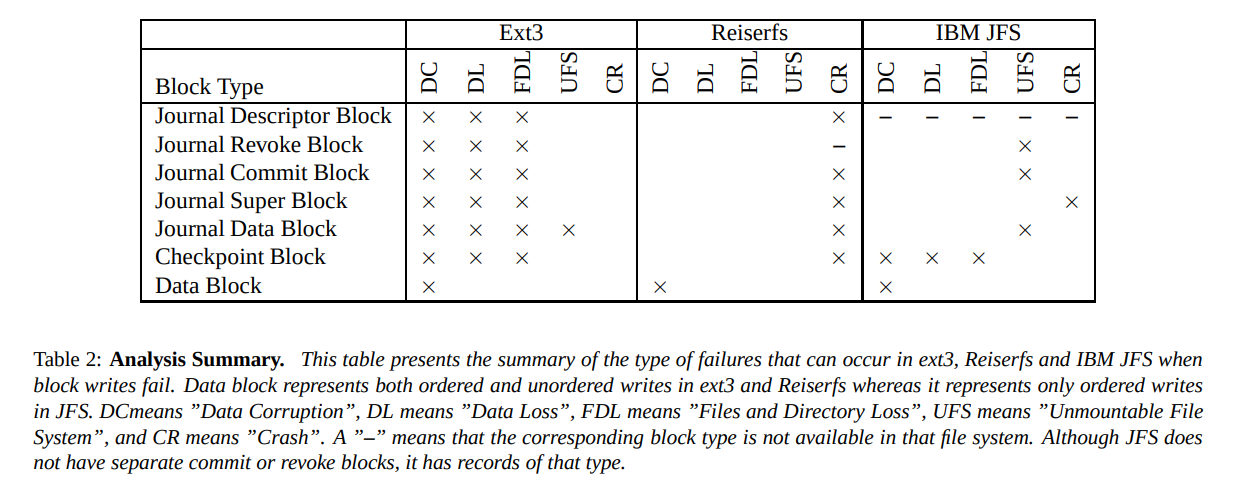
Можно заметить, что каждая из этих файловых систем может оставить содержимое файла (Data Block) в некорректном состоянии (DC, Data Corruption). Вывод: на журналирование полагаться не стоит.
Про NTFS тоже нашел исследование (страница 163) - даже с учетом избыточности метаданных файловая система может быть повреждена и не подлежать восстановлению.
А что с другими механизмами - copy-on-write и log structured?
В этом исследовании (результат на 26 странице) тестировалась btrfs на SSD и после нескольких отключений питания файловая система пришла в негодность и не смогла восстановиться, хотя журналируемый ext4 пережил 1406. Замечание: статья 2013 года, поведение сейчас может отличаться, но новых исследований не нашел.
Про log structured файловые системы исследований найти не смог.
Про запись в файл
Обобщая, файл состоит из 2 компонент - метаданные и блоки данных. При записи в файл надо понять что обновлять первым? Если метаданные, то после их обновления, в файле может появиться мусор:
Делаем запрос на дозапись в файл
Файловая система обновляет метаданные - увеличивает длину файла
Происходит отказ.
В результате мы имеем файл, который заполнен мусором, хотя ни файловая система, ни диск проблем не видят.
Защититься от этого можно если выставлять специальные маркеры в файле, которые бы нам говорили, что файл инициализирован корректно и все хорошо. Например, можно использовать константу, чтобы проверять, что дальше действительно идут наши данные, а не мусор. Такой подход используют:
-
Postgres в начале заголовка страницы WAL выставляет magic number
/* * Each page of XLOG file has a header like this: */ #define XLOG_PAGE_MAGIC 0xD114 /* can be used as WAL version indicator */ typedef struct XLogPageHeaderData { uint16 xlp_magic; /* magic value for correctness checks */ // ... } XLogPageHeaderData; -
Kafka использует magic number в качестве номера версии
public class FileLogInputStream implements LogInputStream<FileLogInputStream.FileChannelRecordBatch> { @Override public FileChannelRecordBatch nextBatch() throws IOException { // ... byte magic = logHeaderBuffer.get(MAGIC_OFFSET); final FileChannelRecordBatch batch; if (magic < RecordBatch.MAGIC_VALUE_V2) batch = new LegacyFileChannelRecordBatch(offset, magic, fileRecords, position, size); else batch = new DefaultFileChannelRecordBatch(offset, magic, fileRecords, position, size); return batch; } } -
А может быть не числом, а строкой, как в SQLite, причем как осмысленной, так и случайной
// Заголовок журнала отката - несмысленная константа /* ** Journal files begin with the following magic string. The data ** was obtained from /dev/random. It is used only as a sanity check. */ static const unsigned char aJournalMagic[] = { 0xd9, 0xd5, 0x05, 0xf9, 0x20, 0xa1, 0x63, 0xd7, }; static int readJournalHdr( Pager *pPager, /* Pager object */ int isHot, i64 journalSize, /* Size of the open journal file in bytes */ u32 *pNRec, /* OUT: Value read from the nRec field */ u32 *pDbSize /* OUT: Value of original database size field */ ){ int rc; /* Return code */ unsigned char aMagic[8]; /* A buffer to hold the magic header */ i64 iHdrOff; /* Offset of journal header being read */ /* Read in the first 8 bytes of the journal header. If they do not match ** the magic string found at the start of each journal header, return ** SQLITE_DONE. If an IO error occurs, return an error code. Otherwise, ** proceed. */ if( isHot || iHdrOff!=pPager->journalHdr ){ rc = sqlite3OsRead(pPager->jfd, aMagic, sizeof(aMagic), iHdrOff); if( rc ){ return rc; } if( memcmp(aMagic, aJournalMagic, sizeof(aMagic))!=0 ){ return SQLITE_DONE; } } // ... } // Заголовок файла БД - человекочитаемая строка #ifndef SQLITE_FILE_HEADER /* 123456789 123456 */ # define SQLITE_FILE_HEADER "SQLite format 3" #endif /* ** The header string that appears at the beginning of every ** SQLite database. */ static const char zMagicHeader[] = SQLITE_FILE_HEADER; static int lockBtree(BtShared *pBt){ // ... if( nPage>0 ){ /* EVIDENCE-OF: R-43737-39999 Every valid SQLite database file begins ** with the following 16 bytes (in hex): 53 51 4c 69 74 65 20 66 6f 72 6d ** 61 74 20 33 00. */ if( memcmp(page1, zMagicHeader, 16)!=0 ){ goto page1_init_failed; } // ... page1_init_failed: pBt->pPage1 = 0; return rc; }
Дополнительно можно выделить заголовки начала файлов разных форматов, например, BOM, JPEG, PNG.
Но это константа, которая не зависит от данных. Чаще нужна для пометки границ данных. Что будет, если мы успешно запишем ее (константу), а потом в середине записи данных произойдет отказ? Часть данных будет записана, а другая нет. Причем нельзя сказать, какая именно часть была записана успешно - запись устройство может начать с последней страницы.
Для подобных ситуаций используют чек-суммы, которые рассчитывают по всем записываемым данным. Саму чек-сумму можно хранить как в начале, так и в конце. Я считаю, что лучше записывать чек-сумму в конце - локальность данных:
Страница для записи, скорее всего, уже будет в памяти, т.е. меньше вероятность промаха страницы (даже если записываем 4 байта, нужно загружать 4 Кб - страницу)
Меньше потенциальных позиционирований головки диска
Если константа по большей части является простым маркером ("дальше есть данные"), то чек-сумма может помочь в обнаружении нарушения целостности. Этот подход используют многие приложения.
Для примера:
-
Postgres использует CRC32C для проверки целостности записей WAL
typedef struct XLogRecord { // ... pg_crc32c xl_crc; /* CRC for this record */ } XLogRecord; -
etcd использует скользящую чек-сумму для записей WAL
type Record struct { Crc uint32 `protobuf:"varint,2,opt,name=crc" json:"crc"` } -
EventStore использует MD5 чек-сумму
public class ChunkFooter { // ... public readonly byte[] MD5Hash; // ... }
Модель согласованности
Прежде чем идти вперед, стоит поговорить о модели согласованности.
Есть такое понятие как модель памяти. В разных контекстах я находил разные определения, но скажем, что модель памяти - это правила, которые могут применяться для переупорядочивания store/load операций, т.е. их нарушение запрещается. Для примера у нас есть следующий участок кода:
void function() {
// 1
a = 123;
b = 244;
// 2
int c = a;
b = 555;
}
Вопросы такие:
В 1 случае, можно ли сначала записать
bи только потомa, т.е. изменить порядок store/store операцийВо 2 случае, можно ли сначала записать значение
bи только потом прочитать значение изa
На такие вопросы отвечает модель памяти. Для ЯП и железа есть документы с описанием их модели памяти:
Но оставим ЯП на потом. Сейчас важно понять, что для файловых систем тоже можно определить подобные правила переупорядочивания.
В исследовании Specifying and Checking File System Crash-Consistency Models подобное было названо Crash-Consistency Model - модель согласованности при сбоях. Дальше буду использовать это понятие. В исследовании All File Systems Are Not Created Equal выделили следующие "базовые" операции:
Перезапись чанка файла
Дозапись в файл
Переименование
Операции с директориями
В исследовании All File Systems Are Not Created Equal после проведения экспериментов с ext2, ext3, ext4, reiserfs, xfs и btrfs была составлена эта таблица:

Стоит сделать замечание, что это тесты, таблица показывает найденные воспроизводимые нарушения - если бага не найдено, это не значит, что его нет
Для простоты дальше я буду называть журналируемыми файловыми системами те, у которых есть какой-либо условный буфер, куда попадают операции прежде чем примениться - COW, log-structured, soft updates, журнал (всех под одну гребенку).
Атомарность
При операциях с файловой системой часто необходимо обновлять сразу несколько мест и во время их обновлений может оказаться в некорректном состоянии. Например, при дозаписи в файл требуется обновить длину в его inode, создать и инициализировать новый блок данных. Атомарность, в данном случае, означает атомарность всех этих операций. Из таблицы можно сделать следующие выводы:
Никакая файловая система не может атомарно дозаписать несколько блоков (разве что один)
Перезапись 1 сектора практически везде атомарна
Нежурналируемые файловые системы почти всегда не предоставляют атомарность операций
Операции с директориями почти всегда атомарны, за исключением файловых систем вообще без журнала (еще и ext2, но чувствую, что он не так часто используется)
Что может случиться, если произойдет отказ во время операции, которая не является атомарной? Самое простое - нарушится целостность и придется запускать fsck (который не всегда может все восстановить). В случае, если во время неатомарной операции произойдет сбой:
В файле окажется мусор, если производилась дозапись - выделили новый блок данных, но ничего не записали, либо частично
Перезапишется только часть данных - операция перезаписи не завершилась до конца
В исследовании Specifying and Checking File System Crash-Consistency Models было изучено поведение нескольких файловых систем в случае отказа. Была построена следующая таблица:
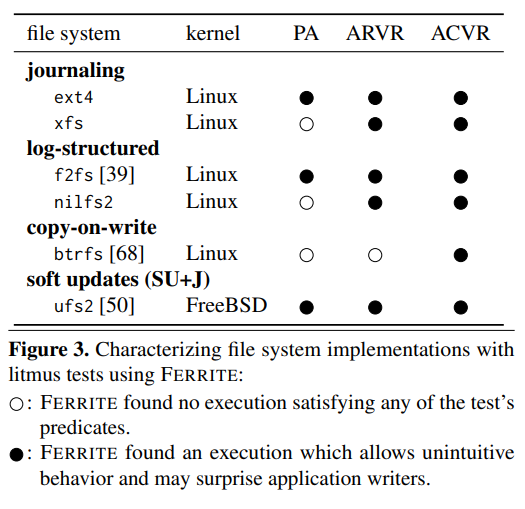
Закрашенные точки показывают, что какое-то поведение могло привести к нарушению целостности. В частности в случае отказа:
PA(Prefix Append) - безопасное добавление не гарантируется всем файловыми системами - может появиться мусорARVR(Atomic Replace Via Rename) - атомарное обновление содержимого существующего файла через его переименование не всеми гарантируется - при замене старого файла на новый, в файле может оказаться только часть данныхACVR(Atomic Create Via Rename) - атомарное создание нового файла через переименование никем не гарантируется - при переименовании временного файла, новый может не содержать всех данных и быть нулевой длины
Также стоит обратить внимание на ARVR и ACVR - это паттерны, которые используются многими приложениями при работе с файлами. Например, в etcd новые сегменты лога создаются с помощью ACVR.
Важное допущение в исследовании касательно ARVR/ACVR
В исследовании изучили поведение файловых систем для ACVR/ARVR и показали, что эти операции могут быть не атомарны.
Далее, конечно, было объяснение, что так делать нельзя и надо бы вызывать fsync.
Чтобы понять насколько это критичное допущение, посмотрим на сам тест (его описание):
# Atomic Replace Via Rename (ARVR)
initial:
g <- creat("file", 0600)
write(g, old)
main:
f <- creat("file.tmp", 0600)
write(f, new)
rename("file.tmp", "file")
exists?:
content("file") 6= old ^ content("file") 6= new
# Atomic create via rename (ACVR)
main:
f <- creat("file.tmp", 0600)
write(f, data)
rename("file.tmp", "file")
exists?:
content("file") 6= ∅ ^ content("file") 6= data
Если присмотреться, то между write и rename не вызывается fsync. Что происходит?
Создается файл
Вызывается
writeдля записи данныхФайл переименовывается (для ARVR)
Файловая система решает сначала переименовать файл (переупорядочивание операций)
Происходит отказ
В результате, после запуска приложения:
ARVR - содержимое файла пустое, т.к. был переименован пустой на тот момент файл
ACVR - содержимое файла пустое, т.к. в файл не успели записаться данные
Если данные для приложения критичны, то оно не будет так себя вести и вызовет fsync перед rename (об этом будет позже).
Но на всякий случай, разработчики файловых систем делают оптимизации, которые обнаруживают подобные паттерны вызовов и сбрасывают данные на диск перед переименованием:
ext4 - опция монтирования
auto_da_allocобнаруживает эти паттерны вызовов.btrfs - опция монтирования
flushoncommitсбрасывает все грязные страницы при вызовеrename(описание взял отсюда, но вики заархивирован, поэтому, возможно, это уже не так)xfs - судя по рассылке за 2015 год предложение было рассмотрено, но отклонено (
The sync-after-rename behavior was suggested and rejected for xfs)
P.S. ссылки на примеры взял отсюда
Но является ли сам rename атомарным? Мы, конечно, можем записать данные во временный файл и убедиться, что содержимое на диске, но какой в этом смысл, если все сломается во время вызова rename? В документации написано следующее:
If newpath already exists, it will be atomically replaced, so that there is no point at which another process attempting to access newpath will find it missing.
То есть, в документации прописано, что эта операция атомарна. Но "атомарная" с точки зрения работающих процессов, но не отказоустойчивости.
Далее, мы видим:
However, there will probably be a window in which both oldpath and newpath refer to the file being renamed.
Из этого можно сделать вывод, что в случае отказа возможна ситуация, когда оба пути указывают на один и тот же файл. И еще:
If newpath exists but the operation fails for some reason, rename() guarantees to leave an instance of newpath in place.
Это уже говорит о том что в случае ошибок содержимое файла по newpath (для ACVR/ARVE - целевого) останется неизменным. Про отказы явно ничего не говорится. В документации GNU C нашел следующее описание поведения:
If there is a system crash during the operation, it is possible for both names to still exist; but newname will always be intact if it exists at all.
Вот тут уже явно про отказ - целевой файл останется неизменным (не будет поврежден) в случае отказа.
Я делаю следующий вывод: rename - атомарен, но только если перед ним вызывается fsync, чтобы гарантировать, что данные действительно на диске и переименовываемый файл не пустой.
Переупорядочивание
Касательно переупорядочивания можно сделать следующий вывод: если файловая система журналируемая, то порядок операций в большинстве случаев сохраняется. Этого нет в ext2, ext3-writeback, ext4-writeback, reiserfs-nolog, reiserfs-writeback поэтому операции могут спокойно быть переупорядочены.
Также важным является факт переупорядочивания операций над директориями и других. Это означает, что если мы сначала записываем файл, а потом хотим его переименовать, то может случиться так, что мы сначала переименуем файл, (т.е. потенциально старое содержимое потеряем) и только потом начнем запись. К моему удивлению, на такое переупорядочивание способны не все, даже некоторые нежурналируемые могут сохранять порядок (xfs не ожидал здесь увидеть).
Барьер записи
В модели памяти, есть такое понятие как барьер записи - механизм, который запрещает переупорядочивание последовательностей store/load операций. Для модели файловой системы он тоже есть - это fsync(). Можно сказать, что этот барьер имеет следующую семантику:
Все вызовы записи до
fsync()сброшены на диск
Но мы не можем сказать, в какой именно последовательности они были выполнены, просто выполнены. До этого момента, состояние файла неопределенное. Вообще, fsync() - не барьер записи, просто его можно так использовать. Подобная тема уже поднималась - было предложение добавить новый системный вызов fbarrier(), который им бы и являлся, но Линус идею отверг, посчитав, что это добавит лишнюю сложность.
Примеры проблем
В том же исследовании All File Systems Are Not Created Equal были анализированы несколько приложений на наличие уязвимостей, касательно моделей согласованности в случае отказа. В таблице ниже представлено описание алгоритмов (порядка вызовов функций) при работе с диском:

А результаты анализа приведены в следующей таблице:

Какие из нее можно сделать выводы:
Приложения, в которых работа с данными критична (СУБД например), часто используют
fsyncв качестве барьераЧем хуже предоставляемые файловой системой гарантии - тем больше багов можно обнаружить (и нарушений целостности)
Каждое приложение имеет свои представления о гарантиях файловых систем и при их нарушении может пострадать целостность. Например, здесь приведены предположения SQLite и сами авторы исследования обнаружили, что ZooKeeper требует атомарности записи в файл лога.
Другие файловые системы
Исследования выше были ориентированы на файловые системы *nix мира, но существуют и другие, о которых пойдет речь.
NTFS
NTFS - "стандартная" файловая система для Windows. Я не нашел исследований, касательно ее отказоустойчивости, но, опираясь на описание, можно сделать следующие выводы:
Журналируются только метаданные - в файлах может появиться мусор
Имеет свой транзакционный API, но разработчикам рекомендуется искать ему альтернативы
APFS
APFS (Apple File System) - файловая система для Apple, которая должна заменить HFS+.
Из статей выделил следующее:
Вместо журналирования используется Copy On Write, причем новая технология
novel copy-on-write metadata scheme(информацию про нее не нашел)Имеет технологию
Atomic Safe-Saveдля гарантии атомарногоrenameИспользует чек-суммы только для метаданных, но не данных пользователей
Последний пункт я выделил специально, так как я неправильно понял статью, на которую опирался. В ней прописано apfs doesn’t checksum data because “[apfs] engineers contend that Apple devices basically don’t return bogus data”, но если перейти на ссылаемую статью, то там прописано APFS checksums its own metadata but not user data. Недопонимание произошло из-за того, что в изначальной статье идет сравнение с ZFS (в которой реализованы чек-суммы данных пользователя), а в той, что изучал я - про нее ни слова.
К слову, чек-суммы для пользовательских данных мало кто выполняет без явного указания. Например, ext4 по умолчанию устанавливается в data=ordered режиме, в котором чек-сумма не рассчитывается, в отличие от data=journal. XFS согласно документации поддерживает чек-суммы только для метаданных. А некоторые файловые системы их не поддерживают, например NTFS.
Ошибки fsync
В предыдущей главе было сказано, что от ошибок fsync не восстановиться и описано как различные ОС обрабатывают подобные ситуации. Но было сказано только про пометку страниц в памяти.
Данные я взял из исследования Can Applications Recover from fsync Failures? Оно говорит само за себя - в нем было проведено исследование поведения различных приложений, файловых систем и ОС в случае ошибки fsync. Для начала посмотрим на таблицу с результатами тестирования файловых систем в случае ошибки fsync.

ext4 data - означает journal режим
Из этой таблицы можно сделать следующие выводы:
Ошибки
fsyncвозникают только в случае проблем с записью блоков данных или журнала, т.к. сначала журналируются метаданные. Но при этом, если ошибка в метаданных будет найдена, то xfs и btrfs станут недоступны для записи (либо закроется (XFS), либо смонтируется в read-only режиме соответственно), а ext4 просто залогирует это и продолжит работу.При ошибке записи в блоки данных (добавление новых, перезапись существующих), могут сохраниться обновленные метаданные (длина), т.е. размер файла изменится, но содержимое останется старым/возникнет дыра или мусор
Если произойдет ошибка во время записи и файловая система восстановится, то состояния файла на диске и в ОС могут различаться. В примере это btrfs - при ошибке записи, метаданные не меняются, но в памяти сохраняется старый дескриптор файла, который указывает на позицию в файле за его пределами (при записи)
Все файловые системы помечают страницы чистыми в случае ошибок, но это связано с тем, что тесты производились на Linux - в других системах поведение может отличаться (примеры были выше)
-
Ошибка
fsyncне обязательно возвращает соответствующий код когда запись провалилась сейчас - ext4 в data режиме может вернуть ошибку только при следующем вызове, то есть возможна такая ситуация:Записываем данные
fsyncвозвращает успешный статус кодОчищаем буфер с данными для записи
Записываем новую порцию данных
fsyncвозвращает ошибку. В этом случае, мы уже не можем просто повторить операцию, так как старые данные не сохранили, а повтор текущей операции может сохранить данные, которые полагаются на те, что пропали
Не все файловые системы при ошибке перемонтируются в read-only режиме, т.е. даже при ошибке
fsyncмы не гарантируем того, что можем приложение на этом узле запустить для обслуживания запросов только на чтение (чтобы полностью не упасть)ext4 в journal режиме сохраняет целостность только для самой файловой системы, но с точки зрения приложения/пользователя, данные могут быть в некорректном состоянии (это можно сказать и про все остальные фс)
Вывод: работая с файловой системой, можно ожидать любого поведения - любой комбинации из рассмотренных выше.
В этом исследовании изучали и поведение приложений в случае ошибки fsync. Результаты приведены в этой таблице:

OV (old value) - возвращение старого значения, а не нового
FF (false failure) - пользователю говорим, что операция провалилась, но новое значение сохранено
KC/VC (key/value corruption) - данные были повреждены (тесты на key-value хранилище проводились)
KNF (key not found) - пользователю говорим, что операция выполнилась, но новое значение не сохранилось на диске (пропало)
Можно сделать следующие выводы:
Если ошибка
fsyncне проявляется сразу (например, ext4 journal режим), то ошибок в работе возникает гораздо большеCOW файловые системы (например, btrfs) лучше справляются с ошибками
fsync, чем обычные журналируемыеВ случае обнаружения ошибки многие приложения просто останавливаются и откатываются до последнего корректного состояния (
-,|в ячейках таблицы)Приложения больше нацеливаются на конкретные ОС, а не файловые системы, поэтому так много различий в поведении
Интересное замечание авторов - Redis не обращает внимание на код ошибки fsync и всегда возвращает успешный результат.
Скорее всего, это потому что Redis в первую очередь In-Memory БД и сохранение данных просто небольшая фича.
Хранилище
Вот последний этап - постоянное хранилище данных. Сейчас мы говорим про:
Жесткие диски, HDD
Твердотельные накопители, SSD
Не только HDD/SSD
Кроме HDD и SSD стоило бы указать еще:
Ленточные накопители
CD/DVD/Blu-ray диски
PCM, FRAM, MRAM
Дальше про них разговор вестись не будет, но не хорошо вот так их опустить.
Ленточные носители - хороший вариант для резервного копирования. Если верить этой статье, то они:
Самые надежные - 15-30 лет
Вмещают много - 18 Тб
Мало стоят - 1300 р/Тб (за пример взял этот картридж))
CD/DVD/Blu-ray диски продолжают использоваться. Судя по анализу рынка в США их оборот только увеличивается. Скорее они подходят для распространения контента (игры, фильмы, музыка), чем для интенсивных IO операций, поэтому тоже пропустим.
Также за бортом я оставил такие технологии как PCM (Phase-change Memory), FRAM (Ferroelectic RAM) и MRAM (Magnetoresistive RAM). Данных по ним я не нашел.
Механизмы хранения, которые они используют, различаются, но сейчас это не главное. Главное то, что мы можем выделить параметры, которыми их можно охарактеризовать:
Износ
ECC
Контроллер доступа
Износ
Каждое оборудование изнашивается. Если железо (процессор, видеокарта) испортится, то мы это быстро заметим и заменим. В общем, ничего страшного не случится.
Но если умрет накопитель, то мы можем потерять данные. Blackbaze выпустили отчет за 2023 год по статистике отказов своих жестких дисков. Из него можно сделать следующие выводы:
Среднее время жизни HDD зависит от многих факторов, например, производителя или размера диска, но среднее по больнице - примерно 65 месяцев (5.5 лет)
В сравнении с 2022 годом AFR (Annualized Failure Rate, вероятность отказа в году) дисков в среднем увеличился
Но предыдущие результаты получены на момент написания статьи. Есть статья за 2021 год How Long Do Disk Drives Last?, в которой провели анализ продолжительности жизни дисков. Из нее можно сделать следующие выводы:
Средняя продолжительность жизни диска - 6 лет и 9 месяцев. Это значение получено с помощью экстраполирования, так как данные были только за 6 лет (за 6 лет выживало 65% дисков)
График AFR жестких дисков имеет форму ванной, то есть AFR достигает максимумов в начале и конце своего времени жизни (это называется bathtub curve, не смог красиво перевести)
Что касается SSD, то у них тоже есть отчет, но за 2022 год. Согласно ему, AFR для SSD - 0.92% (ниже чем у HDD). Но стоит учитывать, что в эксплуатацию SSD взяли только в 2018 году, поэтому статистику надо еще собрать.
Теперь о влиянии физического мира на накопители:
В HDD больше движущихся деталей, поэтому он сильно подвержен физическим воздействиям. За примерами ходить не надо - Shouting in the Datacenter. На этом видео было показано как сильно возрастает задержка ответа HDD, когда на него кричат. А в этом исследовании провели анализ влияния шумов на работу HDD. Грубо говоря, HDD заставили работать при постоянных шумах (устроили ему ADoS, Acoustic Denial of Service). В результате возросло количество ошибок позиционирования, а в не которых случаях и отказ всего диска.
Хоть в SSD и нет подобных движущихся деталей, но зато есть электричество и вот к нему, а точнее к его внезапному отключению он уязвим. В этом исследовании провели тестирование поведения SSD на внезапное отключение электричества во время работы. И, внезапно, отключение электричества приводит к нарушению целостности данных, их потере, либо вообще может превратить SSD в кирпич.
ECC
HDD и SSD имеют встроенную поддержку ECC - Error Correction Code, Коды Исправления Ошибок:
HDD имеет поддержку разметки секторов согласно Advanced Format, который позволяет хранить ECC для всего сектора. Для этого нужна дополнительная поддержка со стороны ОС - сегодня она есть практически везде, но в старых системах может отсутствовать. Стоит учитывать еще и то, что файловые системы знают про Advanced Format и могут под него подстраиваться, но это за рамками статьи.
SSD тоже имеет подобную поддержку, но только для NAND технологии (в "быту" - обычные SSD, USB флешки, SD карты), но в NOR не так часто (в микроконтроллерах). Причем, эта поддержка - на уровне накопителя, а не ОС
Но даже если ECC и есть, то он не всегда может справиться с ошибками. В этом исследовании сравнивали жизненные циклы HDD и SSD путем тестирования их на собственных наборах данных. Следующие графики показывают сколько было обнаружено неисправимых ошибок (UE, Uncorrectable Error) до момента отказа диска - ошибок, которые не могли исправить ECC

Выводы можно сделать следующие:
Количество неисправленных ошибок у SSD зависит от времени жизни диска, тогда как у HDD - от времени позиционирования головки диска (Head Flying Hours)
Количество ошибок HDD резко возрастает за 2 дня перед отказом
Количество неисправленных ошибок на SSD больше, чем на HDD
Вывод: чаще всего (на современном оборудовании и версиях ОС) накопители имеют коды коррекции ошибок, но полностью полагаться на них не стоит.
P.S. пункт 1 - еще одна причина учитывать локальность данных
Контроллер доступа
Последний элемент, который стоит рассмотреть - это контроллер накопителя. Этот компонент знает как работать с физическим хранилищем и обрабатывать приходящие от ОС запросы. Важной деталью здесь является дисковый кэш накопителя - туда попадают все операции изменения данных.
Вспомним про fsync - он должен обеспечивать сброс всех данных на диск, т.е. возвращаться только когда данные точно на диске. Если посмотреть man для fsync сейчас, то можно увидеть:
The fsync() implementations in older kernels and lesser used filesystems do not know how to flush disk caches. In these cases disk caches need to be disabled using hdparm(8) or sdparm(8) to guarantee safe operation.
В старых версиях ядра (судя по указанной ранее версии 2.2) fsync не знал как правильно сбрасывать кэш диска, как и не знали некоторые редко используемые файловые системы. Если верить статье Ensuring data reaches disk, то начиная с версии ядра 2.6.35 ext3, ext4, xfs и btrfs могут быть смонтированы с флагом barrier, чтобы включить барьеры (сброс дискового кэша). По крайней мере, в man странице для mount эти файловые системы имеют флаг barrier.
Я немного поискал в исходниках Linux файловые системы, которые не умеют выполнять fsync, но пришел к выводу, что кастомный fsync не реализован только в readonly файловых системах (например, efs и isofs не регистрируют fsync). Также если файловая система не имеет своей логики сброса данных (например, не журналируемая), то всегда может использовать обобщенную реализацию fsync - с помощью комбинаций других системных вызовов:
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/block/bdev.c#L203
/*
* Write out and wait upon all the dirty data associated with a block
* device via its mapping. Does not take the superblock lock.
*/
int sync_blockdev(struct block_device *bdev)
{
if (!bdev)
return 0;
return filemap_write_and_wait(bdev->bd_inode->i_mapping);
}
EXPORT_SYMBOL(sync_blockdev);
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/mm/filemap.c#L779
/**
* file_write_and_wait_range - write out & wait on a file range
* @file: file pointing to address_space with pages
* @lstart: offset in bytes where the range starts
* @lend: offset in bytes where the range ends (inclusive)
*
* Write out and wait upon file offsets lstart->lend, inclusive.
*
* Note that @lend is inclusive (describes the last byte to be written) so
* that this function can be used to write to the very end-of-file (end = -1).
*
* After writing out and waiting on the data, we check and advance the
* f_wb_err cursor to the latest value, and return any errors detected there.
*
* Return: %0 on success, negative error code otherwise.
*/
int file_write_and_wait_range(struct file *file, loff_t lstart, loff_t lend)
{
int err = 0, err2;
struct address_space *mapping = file->f_mapping;
if (lend < lstart)
return 0;
if (mapping_needs_writeback(mapping)) {
err = __filemap_fdatawrite_range(mapping, lstart, lend,
WB_SYNC_ALL);
/* See comment of filemap_write_and_wait() */
if (err != -EIO)
__filemap_fdatawait_range(mapping, lstart, lend);
}
err2 = file_check_and_advance_wb_err(file);
if (!err)
err = err2;
return err;
}
EXPORT_SYMBOL(file_write_and_wait_range);
// https://github.com/torvalds/linux/blob/a4145ce1e7bc247fd6f2846e8699473448717b37/fs/hfs/inode.c#L661
static int hfs_file_fsync(struct file *filp, loff_t start, loff_t end,
int datasync)
{
// ...
file_write_and_wait_range(filp, start, end);
// ...
sync_blockdev(sb->s_bdev);
// ...
return ret;
}
Гарантии записи
В конце хочется поговорить о том, какие гарантии записи дают разные устройства. Под этим я сейчас подразумеваю 2 вещи:
Атомарность записи
PowerSafe OverWrite (PSOW)
Атомарность записи
Чтение и запись на диск производится не по 1 байту за раз, а блоками.
Для HDD единица чтения и записи - сектор, но у SSD они разные: страница и блок для чтения и записи соответственно. Но сейчас больше интересна атомарность записи, поэтому внимание обращать будем на единицу записи. Согласно этому ответу на StackOverflow - запись скорее всего (likely) атомарна, но при условии, что:
Контроллер диска имеет запасную батарею
Вендор SCSI диска дает гарантии атомарности записи
Для NVMe вызывается функция для атомарной записи
Звучит вполне логично, поэтому приму это за ответ.
PowerSafe OverWrite (PSOW)
PowerSafe OverWrite - это термин, который используют разработчики SQLite для описания поведения некоторых файловых систем и дисков в случае внезапного отключения электричества. Заключается оно в следующем:
When an application writes a range of bytes in a file, no bytes outside of that range will change, even if the write occurs just before a crash or power failure.
Перевод:
В случае отказа или отключения питания во время записи диапазона байтов в файл, никакие данные за пределами этого диапазона не будут изменены.
В практическом смысле, это свойство означает наличие батареи в накопителе на случай отключения электричества для безопасной записи последних данных. Если этого нет, то запись может остановиться на половине сектора и он окажется наполовину измененным. Если при записи мы учитываем размер сектора и считаем, что запись в него атомарна, то отсутствие PSOW станет для нас проблемой.
Атомарность и PSOW - не пересекаются
Атомарность и PowerSafe OverWrite - это разные характеристики и одно не является частным случаем другого.
Для примера рассмотрим такую ситуацию - мы хотим перезаписать участок файла и в момент перезаписи отключилось электричество. В зависимости от различных комбинаций, последствия будут разными.
Представим, что у нас есть 3 сектора, заполненных 0, и хотим перезаписать определенный диапазон единицами, причем этот диапазон затрагивается. Изобразим следующим образом.
А Б В
Секторы: |000000000|000000000|000000000|
Запись: |------------------|
Тогда в зависимости от свойств последствия могут быть следующими:
-
Atomic + PSOW
Каждый сектор содержит либо старые данные, либо полностью обновленные данные (биты были перезаписаны).
Возможные ситуации:
А: |000011111|000000000|000000000| |------------------| Б: |000000000|111111111|000000000| |------------------| В: |000000000|000000000|111100000| |------------------| -
!Atomic + PSOW
Представим, что при записи в сектор А произошел сбой. Тогда в диапазоне от начала записи и до конца возможно любое состояния, т.е. будут смешаны старые и новые данные, но биты за пределами этого сектора затронуты не будут.
Тогда возможны такие ситуации:
А: |000011010|000000000|000000000| |------------------| Б: |000000000|110011010|000000000| |------------------| В: |000000000|000000000|001000000| |------------------|Главное заметим, что данные за пределами этого диапазона не были изменены.
-
Atomic + !PSOW
Дела становятся интереснее, когда запись в сектор атомарна, но PSOW гарантировать не можем. Пример подобного поведения привели разработчики SQLite: при перезаписи участка файла ОС считывает весь сектор, изменяет в нем нужные байты, записывает на диск (Read Modify Write) и в момент записи происходит отключение электричества. Данные были записаны только частично, ECC не был обновлен и при запуске диск обнаруживает, что сектор некорректный и зануляет его. Хоть запись и атомарна, но данные за пределами диапазона были изменены. В нашем примере это можно представить следующим образом (единицы означают чистые страницы):
А: |111111111|000000000|000000000| |------------------| Б: |000000000|111111111|000000000| |------------------| В: |000000000|000000000|111111111| |------------------| -
!Atomic + !PSOW
Это последний и самый страшный пример. В этом случае, мы никаких гарантий не даем и абсолютно любое изменение единственного байта может привести к инвалидации всего сектора. Картина в данном случае похожа на 3 случай.
В репозитории hashicorp/raft-wal имеется README, в котором описаны предположения приложений относительно гарантий хранилища.
На этом можно было бы и закончить, но мы пропустили один довольно важный слой - среда выполнения.
Рантайм
В самом начале мы перешли от приложения сразу к операционной системе. Но между ними может лежать еще один слой - рантайм:
Среда выполнения - Node.js, .NET, JVM
Интерпретаторы - Python, Ruby
Если при работе в C/C++ можно сразу вызвать (системный вызов) fsync, то для других надо учитывать различные аспекты рантайма. Сейчас поговорим про fsync, так как он необходим для подтверждения сохранности данных.
В java имеется метод force(true) для этого. В документации написано:
Forces any updates to this channel's file to be written to the storage device that contains it.
То есть напрямую fsync не вызывается, мы полагаемся на интерфейс, который среда предлагает. То же самое можем увидеть в .NET - у класса FileStream есть перегруженный метод Flush(bool flushToDisk). Если ему передать значение true, то все данные будут записаны на диск:
Use this overload when you want to ensure that all buffered data in intermediate file buffers is written to disk. When you call the Flush method, the operating system I/O buffer is also flushed.
Но стоит заметить, что ничего про fsync не сказано. Да, это платформозависимая деталь реализации, но если мы хотим точно убедиться в сохранности лучше проверить. Что я и решил сделать - посмотреть как себя ведет вызов этого метода. Сначала поискал в исходниках и нашел следующую цепочку вызовов:
Цепочка вызовов
public class FileStream
{
private readonly FileStreamStrategy _strategy;
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/FileStream.cs#L389
public virtual void Flush(bool flushToDisk)
{
if (_strategy.IsClosed)
{
ThrowHelper.ThrowObjectDisposedException_FileClosed();
}
_strategy.Flush(flushToDisk);
}
}
internal abstract class OSFileStreamStrategy : FileStreamStrategy
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/Strategies/OSFileStreamStrategy.cs#L137
internal sealed override void Flush(bool flushToDisk)
{
if (flushToDisk && CanWrite)
{
FileStreamHelpers.FlushToDisk(_fileHandle);
}
}
}
internal static partial class FileStreamHelpers
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/System.Private.CoreLib/src/System/IO/Strategies/FileStreamHelpers.Unix.cs#L40
internal static void FlushToDisk(SafeFileHandle handle)
{
if (Interop.Sys.FSync(handle) < 0)
{
Interop.ErrorInfo errorInfo = Interop.Sys.GetLastErrorInfo();
switch (errorInfo.Error)
{
case Interop.Error.EROFS:
case Interop.Error.EINVAL:
case Interop.Error.ENOTSUP:
// Ignore failures for special files that don't support synchronization.
// In such cases there's nothing to flush.
break;
default:
throw Interop.GetExceptionForIoErrno(errorInfo, handle.Path);
}
}
}
}
internal static partial class Interop
{
internal static partial class Sys
{
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/libraries/Common/src/Interop/Unix/System.Native/Interop.FSync.cs#L11
[LibraryImport(Libraries.SystemNative, EntryPoint = "SystemNative_FSync", SetLastError = true)]
internal static partial int FSync(SafeFileHandle fd);
}
}
// https://github.com/dotnet/runtime/blob/da781b3aab1bc30793812bced4a6b64d2df31a9f/src/native/libs/System.Native/pal_io.c#L736
int32_t SystemNative_FSync(intptr_t fd)
{
int fileDescriptor = ToFileDescriptor(fd);
int32_t result;
while ((result =
#if defined(TARGET_OSX) && HAVE_F_FULLFSYNC
fcntl(fileDescriptor, F_FULLFSYNC)
#else
fsync(fileDescriptor)
#endif
< 0) && errno == EINTR);
return result;
}
То есть, при указании true, должен произойти вызов fsync. Дальше я захотел проверить это в реальности. Для этого написал следующий код и отследил его выполнение с помощью strace.
using var file = new FileStream("sample.txt", FileMode.OpenOrCreate);
file.Write("hello, world"u8);
file.Flush(true);
Вот часть вывода strace с открытия и до закрытия файла.
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
fsync(19) = 0
flock(19, LOCK_UN) = 0
close(19) = 0
По шагам:
openat- Открыт файл с дескриптором 19lseek- Указатель смещен в самое началаpwrite64- Записаны наши данныеfsync(19)- Вызовfsync- сброс данных на дискclose(19)- Файл закрыт
Вот и хорошо - fsync вызывается. Но для запуска я использовал версию .NET 8.0.1. Мне стало интересно как различается цепочка вызовов на других версиях. Я поставил .NET 7 (7.0.11), скомпилировал с теми же параметрами и запустил strace:
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
flock(19, LOCK_UN) = 0
close(19) = 0
В последних строках нет fsync! Более того, если вызвать Flush(true) еще раз, то он появится:
openat(AT_FDCWD, "/path/sample.txt", O_RDWR|O_CREAT|O_CLOEXEC, 0666) = 19
lseek(19, 0, SEEK_CUR) = 0
pwrite64(19, "hello, world", 12, 0) = 12
fsync(19) = 0
flock(19, LOCK_UN) = 0
close(19) = 0
В итоге, я пришел к выводу, что первый Flush(true) по каким-то причинам игнорируется, а последующие успешно вызывают fsync.
Также стоит поговорить о возможностях, предоставляемых самим языком. Например, fsync может (и должен) вызываться на директориях, чтобы убедиться в создании или удалении файлов. Тут я опять пожалуюсь на C# - понятия дескриптора директории нет (наследие Windows). А получить его обычными способами нельзя - у класса Directory нет метода Open или какого-нибудь наподобие Sync, а если в FileStream передать путь директории, даже с указанием ReadOnly режима, то возникнет исключение UnauthorizedAccessException. Это наследие Windows.
Я нашел обходной путь: с помощью P/Invoke импортируем функцию open получаем дескриптор директории, а после из него создаем SafeFileHandle. В этом случае, исключений нет и fsync можно вызвать.
var directory = Directory.CreateDirectory("sample-directory");
const int directoryFlags = 65536; // O_DIRECTORY | O_RDONLY
var handle = Open(directory.FullName, directoryFlags);
using var stream = new FileStream(new SafeFileHandle(handle, true), FileAccess.ReadWrite);
stream.Flush(true);
[DllImport("libc", EntryPoint = "open")]
static extern nint Open(string path, int flags);
И вот strace
openat(AT_FDCWD, "/path/sample-directory", O_RDONLY|O_DIRECTORY) = 19
lseek(19, 0, SEEK_CUR) = 0
lseek(19, 0, SEEK_CUR) = 0
fsync(19) = 0
close(19) = 0
Итог
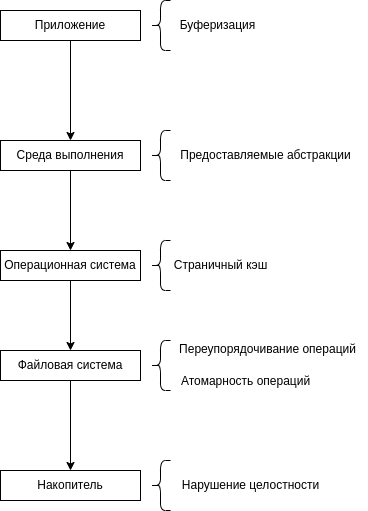
В результате, мы имеем то, что каждый слой, участвующий в процессе выполнения записи имеет детали, которые необходимо учитывать. Все они могут привести к нарушению целостности, образованию мусора, потере данных и других не очень приятных исходов. На диаграмме ниже показан рассмотренный стек вызовов и эти самые детали.
Паттерны файловых операций
После рассмотрения возможных сбоев и ошибок, рассмотрим как с ними можно бороться.
Создание нового файла
Жизнь файла начинается с его создания. Вспомним, что просто создать файл нельзя - его на диске может и не быть к моменту возвращения функции создания. Поэтому, если нам нужно создать файл, то после creat вызываем fsync:
creat("/dir/data")- Создаем файл с даннымиfsync("/dir")- Актуализируем содержимое директории файла
Изначально, файл пуст. Но что если файл уже должен быть проинициализирован? Как мы уже видели последовательность "создать файл", "записать данные", "закрыть" не работает, так как при отказе в файле может быть мусор, окажется пустым или, вообще, не существовать.
Для создания полностью инициализированных файлов используют паттерн Atomic Create Via Rename. Имя говорит само за себя - для создания нового файла мы используем операцию переименования.
Алгоритм для этого следующий:
creat("/dir/data.tmp")- Создаем временный файлwrite("/dir/data.tmp", new_data)- Записываем в этот файл необходимые данныеfsync("/dir/data.tmp")- Сбрасываем содержимое временного файла на дискfsync("/dir")- Сбрасываем изменения директории на диск (создание временного файла)rename("/dir/data.tmp", "/dir/data")- Переименовываем временный файл в целевойfsync("/dir")- Сбрасываем изменения директории на диск (переименование)
Создание нового сегмента лога в etcd
В качестве примера - создание нового файла лога в etcd:
// cut closes current file written and creates a new one ready to append.
// cut first creates a temp wal file and writes necessary headers into it.
// Then cut atomically rename temp wal file to a wal file.
func (w *WAL) cut() error {
// Название для нового файла сегмента
fpath := filepath.Join(w.dir, walName(w.seq()+1, w.enti+1))
// 1. Создание временного файла
newTail, err := w.fp.Open()
if err != nil {
return err
}
// 2. Записываем данные во временный файл
// update writer and save the previous crc
w.locks = append(w.locks, newTail)
prevCrc := w.encoder.crc.Sum32()
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
if err = w.saveCrc(prevCrc); err != nil {
return err
}
if err = w.encoder.encode(&walpb.Record{Type: MetadataType, Data: w.metadata}); err != nil {
return err
}
if err = w.saveState(&w.state); err != nil {
return err
}
// atomically move temp wal file to wal file
// 3-4. Сбрасываем данные файла на диск
if err = w.sync(); err != nil {
return err
}
// 5. Переименовываем временный файл в целевой
if err = os.Rename(newTail.Name(), fpath); err != nil {
return err
}
// 6. Сбрасываем содержимое директории на диск
if err = fileutil.Fsync(w.dirFile); err != nil {
return err
}
// reopen newTail with its new path so calls to Name() match the wal filename format
newTail.Close()
if newTail, err = fileutil.LockFile(fpath, os.O_WRONLY, fileutil.PrivateFileMode); err != nil {
return err
}
w.locks[len(w.locks)-1] = newTail
prevCrc = w.encoder.crc.Sum32()
w.encoder, err = newFileEncoder(w.tail().File, prevCrc)
if err != nil {
return err
}
return nil
}
Дополнительными комментариями я отметил соответствие описанных шагов в алгоритме и того, что выполняется в коде. Шаги - одни и те же и в той же последовательности. Также, в конце файл заново открывается, но это необходимо для того, чтобы получать актуальное название файла, а не временное (с которым создали), и на целостность не влияет.
Изменение файла
Файл у нас есть. Теперь в него необходимо внести изменения. Тут 2 варианта.
Изменение небольшого файла
В случае, если файл небольшого размера, то мы можем применить паттерн Atomic Replace Via Rename (в btrfs этот же паттерн я нашел под названием overwrite-by-rename). Алгоритм тот же, что и для Atomic Create Via Rename:
creat("/dir/data.tmp")- Создаем временный файлwrite("/dir/data.tmp", new_data)- Записываем в этот файл необходимые данныеfsync("/dir/data.tmp")- Сбрасываем содержимое временного файла на дискfsync("/dir")- Сбрасываем изменение директории на диск (создание временного файла)rename("/dir/data.tmp", "/dir/data")- Переименовываем временный файл в целевойfsync("/dir")- Сбрасываем изменения директории на диск (переименование)
Ранее было сказано, что некоторые файловые системы такой шаблон в поведении обнаруживают и сбрасывают содержимое сами, то есть вызов fsync для них лишний. Но разрабатывая приложения мы не знаем на какой файловой системе это все будет храниться и, возможно, она подобное не реализует.
Сохранение данных на диск в LevelDB
Применение этого паттерна можно увидеть в LevelDB - сброс данных на диск из памяти, Compaction (вообще, переводится как "уплотнение", но логика именно сохранения):
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/db_impl.cc#L549
void DBImpl::CompactMemTable() {
// ...
// Replace immutable memtable with the generated Table
if (s.ok()) {
edit.SetPrevLogNumber(0);
edit.SetLogNumber(logfile_number_); // Earlier logs no longer needed
s = versions_->LogAndApply(&edit, &mutex_); // Вызывается метод LogAndApply у класса VersionSet
}
// ...
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/version_set.cc#L777
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
// 1. Создаем новое состояние - применяем правки к текущему состоянию (пока в памяти)
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
Finalize(v);
// Initialize new descriptor log file if necessary by creating
// a temporary file that contains a snapshot of the current version.
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
// 2. Создаем временный файл
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
// 3. Записываем во временный файл новый снапшот БД
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
{
if (s.ok()) {
// 4. Сбрасываем данные на диск
s = descriptor_file_->Sync();
}
// If we just created a new descriptor file, install it by writing a
// new CURRENT file that points to it.
if (s.ok() && !new_manifest_file.empty()) {
// 5. Переименовываем временный файл
s = SetCurrentFile(env_, dbname_, manifest_file_number_);
}
mu->Lock();
}
return s;
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/util/env_posix.cc#L334
class PosixWritableFile: public WritableFile {
public:
Status Sync() override {
// На всякий случай вызываем fsync для содержащей файл директории (для снапшота - наш случай)
Status status = SyncDirIfManifest();
status = FlushBuffer();
return SyncFd(fd_, filename_);
}
private:
static Status SyncFd(int fd, const std::string& fd_path) {
#if HAVE_FULLFSYNC
// On macOS and iOS, fsync() doesn't guarantee durability past power
// failures. fcntl(F_FULLFSYNC) is required for that purpose. Some
// filesystems don't support fcntl(F_FULLFSYNC), and require a fallback to
// fsync().
if (::fcntl(fd, F_FULLFSYNC) == 0) {
return Status::OK();
}
#endif // HAVE_FULLFSYNC
#if HAVE_FDATASYNC
bool sync_success = ::fdatasync(fd) == 0;
#else
bool sync_success = ::fsync(fd) == 0;
#endif // HAVE_FDATASYNC
if (sync_success) {
return Status::OK();
}
return PosixError(fd_path, errno);
}
}
// https://github.com/google/leveldb/blob/068d5ee1a3ac40dabd00d211d5013af44be55bea/db/filename.cc#L123
Status SetCurrentFile(Env* env, const std::string& dbname,
uint64_t descriptor_number) {
// ...
if (s.ok()) {
// Переименовываем временный файл в настоящий/целевой
s = env->RenameFile(tmp, CurrentFileName(dbname));
}
return s;
}
Изменение большого файла
Но что делать, если файл большой и/или места на диске мало?
Вспомним с чего начинали - простая перезапись файла. Но теперь доработаем эту операцию так, чтобы она стала отказоустойчивой. Данный пример я взял из статьи Files Are Hard. При записи в файл может случиться отказ и тогда, возможно, весь файл повредится. Что может произойти:
Операции переупорядочатся
Запишется только часть данных
В файле появится мусор
Целостность нарушится (даже после успешной записи)
Для предоставления отказоустойчивости используется лог операций:
undo (rollback) - откат изменений
redo (write ahead log, wal) - завершение операций
Немного подробнее про применение этих логов в базах данных можно почитать тут. Теперь - как делать отказоустойчивое изменение участка файла.
Undo лог
Undo лог хранит в себе данные, которые необходимы для отката операций. В случае перезаписи файла, он хранит в себе участки исходного файла, которые мы перезаписываем. Например, если мы хотим записать новые данные (new_data) начиная с 10 байта (start) длиной в 15 байтов (length), то в этот лог будут записаны байты с 10 по 24 из текущего, еще не измененного файла (old_data). Алгоритм записи данных будет следующим:
creat("/dir/undo.log")- Создаем файл undo лога-
write("/dir/undo.log", "[check_sum, start, length, old_data]")- Записываем в него данные из исходного файла, которые собираемся изменить:start- позиция, с которой собираемся производить записьlength- длина перезаписываемого участкаold_data- данные исходного файла, которые перезаписываем (не новые, а старые для отката)check_sum- чек-сумма, вычисленная дляstart,lengthиold_data
fsync("/dir/undo.log")- Сбрасываем данные файла на дискfsync("/dir")- Сбрасываем содержимое директории (теперь undo лог точно на диске)write("/dir/data", new_data)- Записываем новые данныеfsync("/dir/data")- Сбрасываем изменения основного файла на дискunlink("/dir/undo.log")- Удаляем undo логfsync("/dir")- Сбрасываем изменение данных директории на диск (удаление undo лога)
Что здесь учли:
Отказ прямо после создания файла undo лога - в начале идет чек-сумма, с помощью которой можно это обнаружить
Переупорядочивание операций записи - чек-сумма для всей записи в undo логе на случай, если операции будут переупорядочены (если изменения большие, то возможно одним
writeне обойтись) или нарушена целостностьОтказ перед началом записи данных в сам файл - вызываем
fsyncдля файла undo лога и его директории (файл лога точно на диске)Удаление самого файла undo лога - в конце вызываем
fsyncдля директории, чтобы undo лог был действительно удален
Как производить восстановление, наверное, стало понятно:
-
Проверяем наличие undo лога
Undo лог присутствует
Он не пуст
Все чек-суммы корректные
-
Если undo лог проверен:
Откатываем файл с данными (команда из undo лога)
Сбрасываем изменения на диск (файл с данными)
Удаляем undo лог
Сбрасываем изменения на диск (директория)
Даже если в процессе восстановления произойдет сбой, то это не должно нарушить целостность данных, т.к. откат должен быть идемпотентен (стоит еще учитывать PSOW и атомарность сегмента, см. выше).
Но удаление файла более затратная операция чем та же запись, т.к. надо обновить не только данные в директории, но и, возможно, пометить страницы чистыми для очищения места на диске. В SQLite используется журнал (undo лог) и в качестве оптимизации можно использовать 2 опции:
Обрезать файл до 0 -
PRAGMA journal_mode=TRUNCATEЗанулять заголовок журнала -
PRAGMA journal_mode=PERSIST
В документации это описано.
Undo лог в SQLite
Раз уж разговор зашел о SQLite, то и в качестве примера приведу его. Сам процесс выполнения коммита описан на странице Atomic Commit In SQLite. В коде реализован так:
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4388
int sqlite3BtreeCommit(Btree *p){
int rc;
// Первая фаза - создание журнала и запись данных в файл БД
rc = sqlite3BtreeCommitPhaseOne(p, 0);
if( rc==SQLITE_OK ){
// Вторая фаза - удаление/обрезание/зануление журнала
rc = sqlite3BtreeCommitPhaseTwo(p, 0);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4267
int sqlite3BtreeCommitPhaseOne(Btree *p, const char *zSuperJrnl){
int rc = SQLITE_OK;
if( p->inTrans==TRANS_WRITE ){
rc = sqlite3PagerCommitPhaseOne(pBt->pPager, zSuperJrnl, 0);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6437
int sqlite3PagerCommitPhaseOne(
Pager *pPager, /* Pager object */
const char *zSuper, /* If not NULL, the super-journal name */
int noSync /* True to omit the xSync on the db file */
){
int rc = SQLITE_OK; /* Return code */
if( 0==pagerFlushOnCommit(pPager, 1) ){
// ...
}else{
if( pagerUseWal(pPager) ){
// ...
}else{
// 1. Записываем страницы, которые хотим изменить в журнал
rc = pager_incr_changecounter(pPager, 0);
// 2. Сбрасываем журнал на диск
rc = syncJournal(pPager, 0);
if( rc!=SQLITE_OK ) goto commit_phase_one_exit;
// 3. Записываем измененные страницы в сам файл БД
pList = sqlite3PcacheDirtyList(pPager->pPCache);
if( /* ... */ ){
rc = pager_write_pagelist(pPager, pList);
}
if( rc!=SQLITE_OK ) goto commit_phase_one_exit;
// 3. Сбрасываем данные файла БД на диск
if( /* ... */ ){
rc = sqlite3PagerSync(pPager, zSuper);
}
}
}
commit_phase_one_exit:
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L4259
static int syncJournal(Pager *pPager, int newHdr){
int rc; /* Return code */
if( /* ... */ ){
if( /* ... */ ){
if( /* ... */ ){
// Вначале записываем количество страниц = 0, на всякий случай
if( rc==SQLITE_OK && 0==memcmp(aMagic, aJournalMagic, 8) ){
static const u8 zerobyte = 0;
rc = sqlite3OsWrite(pPager->jfd, &zerobyte, 1, iNextHdrOffset);
}
if( /* ... */ ){
// Сбрасываем записанные данные
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags);
if( rc!=SQLITE_OK ) return rc;
}
// Записываем сам заголовок
rc = sqlite3OsWrite(
pPager->jfd, zHeader, sizeof(zHeader), pPager->journalHdr
);
if( rc!=SQLITE_OK ) return rc;
}
if( /* ... */ ){
// Еще раз сбрасываем содержимое файла на диск
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags|
(pPager->syncFlags==SQLITE_SYNC_FULL?SQLITE_SYNC_DATAONLY:0)
);
if( rc!=SQLITE_OK ) return rc;
}
}else{
pPager->journalHdr = pPager->journalOff;
}
}
return SQLITE_OK;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6372
int sqlite3PagerSync(Pager *pPager, const char *zSuper){
int rc = SQLITE_OK;
if( /* ... */ ){
// fsync
rc = sqlite3OsSync(pPager->fd, pPager->syncFlags);
}
return rc;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/btree.c#L4356
int sqlite3BtreeCommitPhaseTwo(Btree *p, int bCleanup){
if( p->inTrans==TRANS_WRITE ){
int rc;
rc = sqlite3PagerCommitPhaseTwo(p->pBt->pPager);
if( rc!=SQLITE_OK && bCleanup==0 ){
sqlite3BtreeLeave(p);
return rc;
}
}
return SQLITE_OK;
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L6674
int sqlite3PagerCommitPhaseTwo(Pager *pPager){
int rc = SQLITE_OK; /* Return code */
rc = pager_end_transaction(pPager, pPager->setSuper, 1);
return pager_error(pPager, rc);
}
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/pager.c#L2033
static int pager_end_transaction(Pager *pPager, int hasSuper, int bCommit){
int rc = SQLITE_OK;
int rc2 = SQLITE_OK;
if( isOpen(pPager->jfd) ){
if( sqlite3JournalIsInMemory(pPager->jfd) ){
// ...
}else if( pPager->journalMode==PAGER_JOURNALMODE_TRUNCATE ){
// PRAGMA journal_mode=TRUNCATE
// Обрезаем файл до 0
if( pPager->journalOff==0 ){
rc = SQLITE_OK;
}else{
rc = sqlite3OsTruncate(pPager->jfd, 0);
if( rc==SQLITE_OK && pPager->fullSync ){
rc = sqlite3OsSync(pPager->jfd, pPager->syncFlags);
}
}
pPager->journalOff = 0;
}else if( pPager->journalMode==PAGER_JOURNALMODE_PERSIST){
// PRAGMA journal_mode=PERSIST
// Зануляем заголовок журнала
rc = zeroJournalHdr(pPager, hasSuper||pPager->tempFile);
pPager->journalOff = 0;
}else{
// PRAGMA journal_mode=DELETE
// Удаляем файл журнала
int bDelete = !pPager->tempFile;
sqlite3OsClose(pPager->jfd);
if( bDelete ){
rc = sqlite3OsDelete(pPager->pVfs, pPager->zJournal, pPager->extraSync);
}
}
}
// ...
return (rc==SQLITE_OK?rc2:rc);
}
// Реализация sqlite3OsDelete для Unix систем
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/os_unix.c#L6533
static int unixDelete(
sqlite3_vfs *NotUsed, /* VFS containing this as the xDelete method */
const char *zPath, /* Name of file to be deleted */
int dirSync /* If true, fsync() directory after deleting file */
){
int rc = SQLITE_OK;
// Удаляем файл - unlink
if( osUnlink(zPath)==(-1) ){
rc = unixLogError(SQLITE_IOERR_DELETE, "unlink", zPath);
return rc;
}
// Обновляем содержимое директории
if( (dirSync & 1)!=0 ){
int fd;
rc = osOpenDirectory(zPath, &fd);
if( rc==SQLITE_OK ){
// Улучшенный "fsync"
if( full_fsync(fd,0,0) ){
rc = unixLogError(SQLITE_IOERR_DIR_FSYNC, "fsync", zPath);
}
}else{
rc = SQLITE_OK;
}
}
return rc;
}
// Улучшенная версия fsync, которая учитывает особенности и баги некоторых систем
// https://github.com/sqlite/sqlite/blob/5007833f5f82d33c95f44c65fc46221de1c5950f/src/os_unix.c#L3638
static int full_fsync(int fd, int fullSync, int dataOnly){
int rc;
/* If we compiled with the SQLITE_NO_SYNC flag, then syncing is a
** no-op. But go ahead and call fstat() to validate the file
** descriptor as we need a method to provoke a failure during
** coverage testing.
*/
#ifdef SQLITE_NO_SYNC
{
struct stat buf;
rc = osFstat(fd, &buf);
}
#elif HAVE_FULLFSYNC
if( fullSync ){
rc = osFcntl(fd, F_FULLFSYNC, 0);
}else{
rc = 1;
}
/* If the FULLFSYNC failed, fall back to attempting an fsync().
** It shouldn't be possible for fullfsync to fail on the local
** file system (on OSX), so failure indicates that FULLFSYNC
** isn't supported for this file system. So, attempt an fsync
** and (for now) ignore the overhead of a superfluous fcntl call.
** It'd be better to detect fullfsync support once and avoid
** the fcntl call every time sync is called.
*/
if( rc ) rc = fsync(fd);
#elif defined(__APPLE__)
/* fdatasync() on HFS+ doesn't yet flush the file size if it changed correctly
** so currently we default to the macro that redefines fdatasync to fsync
*/
rc = fsync(fd);
#else
rc = fdatasync(fd);
#if OS_VXWORKS
if( rc==-1 && errno==ENOTSUP ){
rc = fsync(fd);
}
#endif /* OS_VXWORKS */
#endif /* ifdef SQLITE_NO_SYNC elif HAVE_FULLFSYNC */
if( OS_VXWORKS && rc!= -1 ){
rc = 0;
}
return rc;
}
Redo лог
Redo лог работает по аналогичной схеме. Разница в том, что записываем в этот лог не старые, а новые данные:
creat("/dir/redo.log")- Создаем файл redo лога-
write("/dir/redo.log", "[check_sum, start, length, new_data]")- Записываем в него новые данные:start- начальная позиция в файле, с которой собираемся производить записьlength- длина перезаписываемого участкаnew_data- новые данные, которые хотим записатьcheck_sum- чек-сумма, вычисленная дляstart,lengthиnew_data
fsync("/dir/redo.log")- Сбрасываем данные файла на дискfsync("/dir")- Сбрасываем содержимое директории (теперь redo лог точно на диске)write("/dir/data", new_data)- Записываем новые данныеfsync("/dir/data")- Сбрасываем изменения основного файла на дискunlink("/dir/redo.log")- Удаляем redo логfsync("/dir")- Сбрасываем изменение данных директории на диск (удаление redo лога)
Преимуществом redo лога можно считать, то, что ответ о завершенной операции пользователю можно отправлять как только мы успешно сделали запись в логе (шаг 4), т.к. изменения либо будут применены сейчас, либо при восстановлении после перезагрузки.
Стоит также заметить, что постоянное создание и удаление файлов - операция затратная. Для оптимизации, можно просто добавлять новые записи, которые потом надо будет просто применить при восстановлении. Но нужно операции коммитить, чтобы лишний раз их не применять (пустая трата времени и ресурсов). Закоммитить записи можно с помощью с помощью специальной записи, которая добавляется в конец лога (получается каждая запись в логе может быть либо операцией, либо коммитом). Также можно специальным образом изменить заголовок записи операции, например, хранить флаг коммита и занулять его при завершении операции или занулять весь заголовок, как бы говоря, что операция применена (как в SQLite при PRAGMA journal_mode=PERSIST). Вот мы и пришли к WAL - Write Ahead Log.
WAL в Postgres
Redo лог часто встречается в базах данных. Он есть в Oracle, MySQL, Postgres или SQLite. Поэтому в качестве примера, рассмотрим как происходит работа с WAL в Postgres.
Пример разделен на 2 части:
Вызов
COMMIT- сохранение данных в WALСброс грязных страниц на диск (вытеснение) - сброс данных в файл БД
Уже здесь мы можем увидеть то самое преимущество WAL: достаточно сделать единственную запись (в redo лог), вернуть ответ пользователю и продолжить работать с грязными страницами в памяти. Сама грязная страница будет сброшена в файл БД потом, например, при очередном запуске чекпоинтера или при восстановлении после сбоя.
// 1. Вызов COMMIT
// https://github.com/postgres/postgres/blob/cc6e64afda530576d83e331365d36c758495a7cd/src/backend/access/transam/xact.c#L2158
static void
CommitTransaction(void)
{
// ...
RecordTransactionCommit();
// ...
}
// https://github.com/postgres/postgres/blob/97d85be365443eb4bf84373a7468624762382059/src/backend/access/transam/xact.c#L1284
static TransactionId
RecordTransactionCommit(void)
{
// ...
XactLogCommitRecord(GetCurrentTransactionStopTimestamp(),
nchildren, children, nrels, rels,
ndroppedstats, droppedstats,
nmsgs, invalMessages,
RelcacheInitFileInval,
MyXactFlags,
InvalidTransactionId, NULL /* plain commit */ );
// ...
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/access/transam/xact.c#L5736
XLogRecPtr
XactLogCommitRecord(TimestampTz commit_time,
int nsubxacts, TransactionId *subxacts,
int nrels, RelFileLocator *rels,
int ndroppedstats, xl_xact_stats_item *droppedstats,
int nmsgs, SharedInvalidationMessage *msgs,
bool relcacheInval,
int xactflags, TransactionId twophase_xid,
const char *twophase_gid)
{
// ...
return XLogInsert(RM_XACT_ID, info);
}
XLogRecPtr
XLogInsertRecord(XLogRecData *rdata,
XLogRecPtr fpw_lsn,
uint8 flags,
int num_fpi,
bool topxid_included)
{
// ...
XLogFlush(EndPos);
// ...
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L2728
void
XLogFlush(XLogRecPtr record)
{
// ...
XLogWrite(WriteRqst, insertTLI, false);
// ...
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L2273
static void
XLogWrite(XLogwrtRqst WriteRqst, TimeLineID tli, bool flexible)
{
while (/* Есть данные для записи */)
{
// 1. Создаем новый сегмент лога, либо открываем текущий
if (/* Размер сегмента превышен */)
{
openLogFile = XLogFileInit(openLogSegNo, tli);
}
if (openLogFile < 0)
{
openLogFile = XLogFileOpen(openLogSegNo, tli);
}
// 2. Выполняем непосредственную запись страниц WAL лога
do
{
written = pg_pwrite(openLogFile, from, nleft, startoffset);
} while (/* Есть данные для записи */);
// 3. Сбрасываем содержимое файла на диск (fsync)
if (finishing_seg)
{
issue_xlog_fsync(openLogFile, openLogSegNo, tli);
}
}
}
// https://github.com/postgres/postgres/blob/dbfc44716596073b99e093a04e29e774a518f520/src/backend/access/transam/xlog.c#L8516
void
issue_xlog_fsync(int fd, XLogSegNo segno, TimeLineID tli)
{
// Вызов fsync в зависимости от конфигурации
switch (wal_sync_method)
{
case WAL_SYNC_METHOD_FSYNC:
pg_fsync_no_writethrough(fd);
break;
case WAL_SYNC_METHOD_FSYNC_WRITETHROUGH:
pg_fsync_writethrough(fd);
break;
case WAL_SYNC_METHOD_FDATASYNC:
pg_fdatasync(fd);
break;
// ...
}
}
// 2. Сброс измененных страниц на диск, в файл БД
// https://github.com/postgres/postgres/blob/97d85be365443eb4bf84373a7468624762382059/src/backend/storage/buffer/bufmgr.c#L3437
static void
FlushBuffer(BufferDesc *buf, SMgrRelation reln, IOObject io_object,
IOContext io_context)
{
// 3. Сбрасываем буфер в WAL (если еще нет)
if (buf_state & BM_PERMANENT)
XLogFlush(recptr);
// Сбрасываем изменения на диск, в файл БД (пишем и сбрасываем, соответствующие шаги дальше)
smgrwrite(reln,
BufTagGetForkNum(&buf->tag),
buf->tag.blockNum,
bufToWrite,
false);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/include/storage/smgr.h#L121
static inline void
smgrwrite(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void *buffer, bool skipFsync)
{
smgrwritev(reln, forknum, blocknum, &buffer, 1, skipFsync);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/smgr.c#L631
void
smgrwritev(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void **buffers, BlockNumber nblocks, bool skipFsync)
{
smgrsw[reln->smgr_which].smgr_writev(reln, forknum, blocknum,
buffers, nblocks, skipFsync);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/md.c#L928
void
mdwritev(SMgrRelation reln, ForkNumber forknum, BlockNumber blocknum,
const void **buffers, BlockNumber nblocks, bool skipFsync)
{
// 5. Записываем данные в файл БД
while (/* Есть еще блоки для записи */)
{
FileWriteV(v->mdfd_vfd, iov, iovcnt, seekpos,
WAIT_EVENT_DATA_FILE_WRITE);
}
// 6. Сбрасываем данные на диск (файл БД)
register_dirty_segment(reln, forknum, v);
}
// https://github.com/postgres/postgres/blob/6b41ef03306f50602f68593d562cd73d5e39a9b9/src/backend/storage/file/fd.c#L2192
ssize_t
FileWriteV(File file, const struct iovec *iov, int iovcnt, off_t offset,
uint32 wait_event_info)
{
returnCode = pg_pwritev(vfdP->fd, iov, iovcnt, offset);
}
// https://github.com/postgres/postgres/blob/eeefd4280f6e5167d70efabb89586b7d38922d95/src/backend/storage/smgr/md.c#L1353
static void
register_dirty_segment(SMgrRelation reln, ForkNumber forknum, MdfdVec *seg)
{
if (/* Не удалось зарегистрировать fsync запрос для чекпоинтера */)
{
FileSync(seg->mdfd_vfd, WAIT_EVENT_DATA_FILE_SYNC);
}
}
// https://github.com/postgres/postgres/blob/c20d90a41ca869f9c6dd4058ad1c7f5c9ee9d912/src/backend/storage/file/fd.c#L2297
int
FileSync(File file, uint32 wait_event_info)
{
pg_fsync(VfdCache[file].fd);
}
Сегментированный лог + снапшот
Раз поговорили про WAL, то стоит и рассказать про сегментированный лог. Сегментированный лог - это паттерн представления единого "логического" лога в виде нескольких "физических" сегментов:
Раньше - единственный жирный файл, который хранил в себе все
Теперь - множество небольших (в сравнении в единственным файлом) сегментов
Но сам по себе сегментированный лог имеет не так много преимуществ, в сравнении с единственным файлом. Вот тут приходит снапшот - слепок состояния приложения, к которому применили определенные команды из лога. Вот эта иллюстрация из статьи про Raft визуализирует отношения между логом и снапшотом:
В результате, у нас есть 2 "файла", в которых хранится состояние всего приложения:
Снапшот - файл с состоянием приложения после применения определенного количества команд, и
Сегментированный лог - множество сегментов (файлов), представляющих последовательность команд, которые необходимо применить к снапшоту
Состояние приложения получаем как: "Снапшот" + команды из "Сегментированный лог".
И теперь магия - с каждым типом файлов мы умеем работать отказоустойчиво:
Для создания или обновления снапшота применяем
Atomic Create Via RenameилиAtomic Replace Via RenameКогда поступает команда для изменения состояния - записываем ее в наш лог (запись в redo лог обсуждалась)
Создание новых сегментов лога - через
Atomic Create Via Rename
Если у нас не сегментированный лог, а монолог (название придумал сам), то освобождение места (удаление примененных команд или их сжатие) будет затруднительно, т.к. отказоустойчивое изменение потребует копирования всех записей из лога и последующего ARVR. При большом размере лога, эта операция может занять много времени и ресурсов, но, в случае с сегментированным, достаточно просто удалить/сжать покрываемые снапшотом сегменты.
Некоторые примеры:
Postgres: WAL представляется в виде нескольких сегментов
Apache Kafka: Каждая партиция состоит из нескольких сегментов
etcd: Данные хранит в снапшоте и сегментированном WAL
log-cabin: Данные хранятся в снапшоте и сегментированном WAL
Подобный подход к организации хранения данных имеет множество преимуществ:
Отказоустойчивое обновление состояния приложения: отказоустойчивая запись в WAL и обновление снапшота (примеры выше)
Скорость применения операций увеличивается: запись в WAL происходит в конец файла - локальность данных и минимальное (потенциальное) время позиционирования головки
Репликация производится эффективнее: потоковая репликация состояния (команды в WAL идут строго последовательно) или, при необходимости, можем отправить весь снапшот сразу
Скорость запуска возрастает: вместо чтения всего лога, загружаем снапшот и применяем только необходимые команды
Также, поверх WAL возможно реализовать транзакции, как в Postgres.
Заключение
Все началось со статьи Files Are Hard. Тогда я понял зачем нужны чек-суммы, что данные после записи надо сбрасывать (fsync) и, вообще, что файлы не так просты. После, я решил копнуть поглубже и понял насколько глубока эта кроличья нора. Писать закончил с трудом, т.к. постоянно хотелось поискать еще каких-нибудь исследований, найти неизвестные факты и т.д.
Главный вывод из всей статьи - работать с файлами надо уметь. В противном случае, вероятность потери данных или нарушения логики работы системы/приложения резко возрастают.
Я прошелся по основным слоям, которые проходит запрос записи, но некоторые темы не покрыты:
Поведение сетевых файловых систем
Описание устройства накопителей данных
Устройство и реализация файловых систем
Сравнение различных файловых систем
Поведение нелокальных/виртуальных файловых систем (NFS, OverlayFS)
Кроссплатформенность (точнее говоря, каких гарантий можно достичь на различных платформах - ОС, рантайм, железо)
Баги в реализациях (они есть, например, баг btrfs 4.2 и 4.3 версии, баг ядра 6.3.3 приводящий к нарушению метаданных XFS (обнаружен в мае прошлого года) или найденный мной)
Поведение внутри эмуляторов (Cygwin, WSL) или виртуальных машин (VMWare, VirtualBox)
Надеюсь, статья была полезна. Полезные ссылки прилагаю:
Файловые системы:
All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications
Specifying and Checking File System Crash-Consistency Models
Накопители:
Комментарии (16)

vilgeforce
28.03.2024 09:37+1Я посмотрел: _commit дергает FlushFileBuffers с дополнительными проверками и т.д. Учитывая, что FlushFileBuffers работает с хэндлом ОС, а _commit с файловыми дескрипторами, первая быстрее: не нужно переводить fd в handle. Тут надо написать замечание, что WinAPI функции надо описывать с параметрами hFile, а не fd, но это я занудствую.
Касательно NtFlushBuffersFileEx и того, что она работает только с NT-файловыми системами у меня есть вопрос - где про это написано? Я глянул в MSDN, там ни слова нет о различных ФС :-/
Про открытие в винде каталога - это сделать точно можно, даже документация на CreateFile про это говорит. Плюс есть всякие неочевидные Nt... и Zw... функции, которые могут с каталогами работать
AshBlade Автор
28.03.2024 09:37+1Спасибо за замечание, исправил.
Насчет
NtFlushBuffersFileEx- в черновике оставил это замечание и забыл перепроверить: скорее всего где-то прочитал, но найти заново не смог. Удалил на всякий случай, чтобы не дезинформировать

me21
28.03.2024 09:37В общем, данные надо хранить не просто в виде файла, а внутри базы SQLite - там большинство проблем уже решено.


denim
28.03.2024 09:37+2Эпичный труд. Но самому важному ответу на вопрос «отказоустойчивость» == «избыточность» уделено меньше чем стоило бы

lolikandr
28.03.2024 09:37Любопытно, что началось всё с отказоустойчивости приложений. Не смотрели на Phantom OS
https://habr.com/ru/companies/selectel/articles/598679/ ? Там эту проблему решают на уровне ОС, но исходники то открыты.

nixtonixto
28.03.2024 09:37+1Для HDD единица чтения и записи - сектор
На HDD с черепичной записью данные пишутся поблочно.

JackKatch
28.03.2024 09:37+2Хорошая, полезная и интересная статья. Проведена большая работа. Спасибо.

nv13
28.03.2024 09:37Замечательный обзор. А с сетевыми фс всё действительно веселее - даже если локально файл создан, записан, закрыт и буфер сброшен, на соседнем хосте в данном каталоге он может ещё даже не появиться.

Alkzndr
28.03.2024 09:37+3Дополню немного про Advanced Format и ECC на HDD. Раньше почти у всех дисков был размер сектора 512 байт, но затем производители перешли на 4096, для оптимизации внутренней логики работы диска. При этом многие диски с "физическим" сектором 4096 поддерживают эмуляцию сектора 512 для совместимости со старым оборудованием и ПО, этот размер называют "логическим" размером сектора. Также встречаются диски, у которых и физический и логический размер сектора 4096 байт.
В отдельном ряду стоят серверные SCSI и SAS накопители с размерами сектора 520, 524, 4160 байт и тому подобное. Такой сектор раскладывается на основную часть (512 или 4096) и добавку к ней (8, 16 байт и так далее). Для хранения "пользовательских" данных используется основная часть, а добавка используется СХД (не самим диском, а именно СХД) для дополнительного контроля содержимого.
При всем при этом, если мы пойдем внутрь самого диска, то там каждый сектор, независимо от его размера, тоже снабжается несколькими байтами контрольной суммы, но к этим байтам нет никакого доступа извне. Если при чтении сектора не получится скорректировать все ошибки, том мы получим ошибку чтения.
PS. Работу проделали, конечно, монументальную. Был приятно удивлен в процессе чтения!

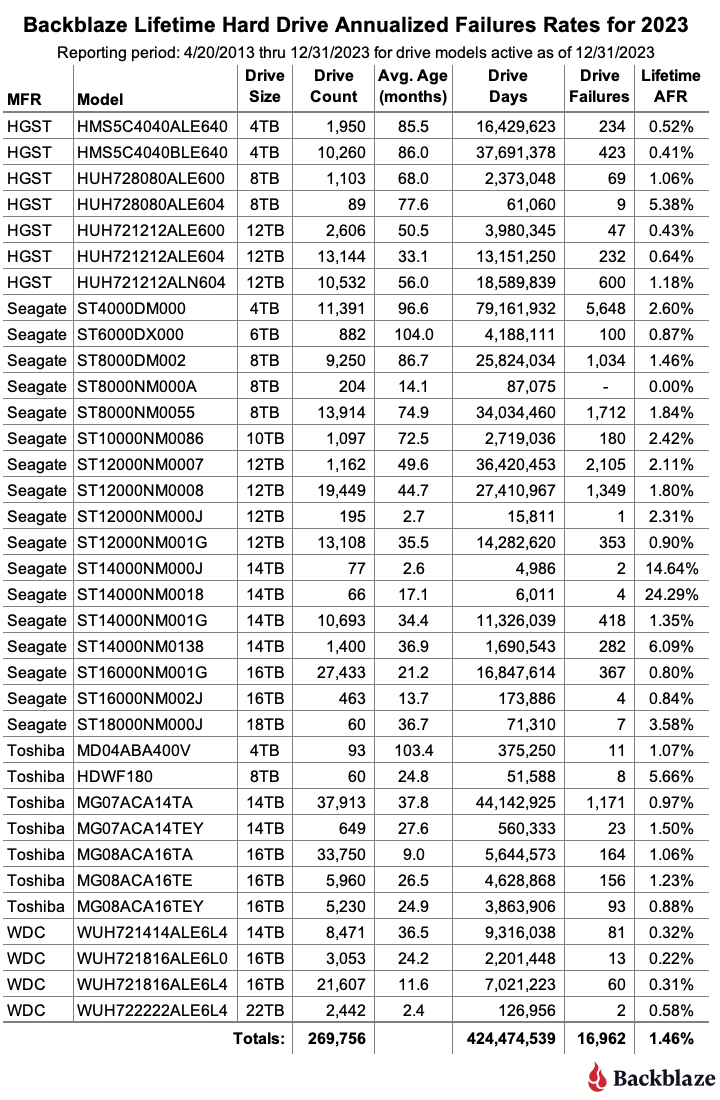{kind=link}
itGuevara
Наверное, не совсем по теме, но ложится в проблему «А в чем проблема работать с файлами?»
Нужно открывать файл pdf на третьей странице (windows):
С:\1.pdf#page3
Или через запись в ячейке в excel:
\\С:\1.pdf#page3
Без использования браузера открыть pdf на нужной странице через #page (или подобное) вообще можно?
sparhawk
Открыть файл с точки зрения пользователя или с точки зрения программиста?
#page3 - это вообще указание фрагмента в семантике URI, браузеры ее поддерживают (для PDF-документов - не всегда), а остальные приложения - не факт
Excel тоже поддерживает открытие файлов по URL, как минимум HTTP(S), но помнится, Excel 2010 падал, если указать в URL фрагмент после #
itGuevara
С любой, но для начала "с точки зрения программиста".
Так и вопрос в этом "не факт". Может быть есть какие - либо хитрости. Хитрый BAT или Excel или VBA Excel или еще что-то, чтобы без браузера открыть pdf на нужной странице. Любопытно, но ранее считал, что нельзя. Вдруг ошибался?
nick758
А чем вы, собственно, хотите открыть pdf? Если просто Акробатом, то
https://superuser.com/questions/622528/open-pdf-to-a-certain-page