
Введение
Очередь с приоритетами - это абстрактный тип данных с 2 операциями:
Enqueue - Добавить элемент
Dequeue - Извлечь элемент с минимальным/максимальным ключом
Обычно она реализуется с помощью кучи. Но это синхронная реализация. Что если нужна конкурентная работа?
Конкурентные реализации
Попыток создать конкурентные реализации было несколько.
В результате многие пришли к выводу, что лучшей структурой данных лежащей в основе, будет список с пропусками.
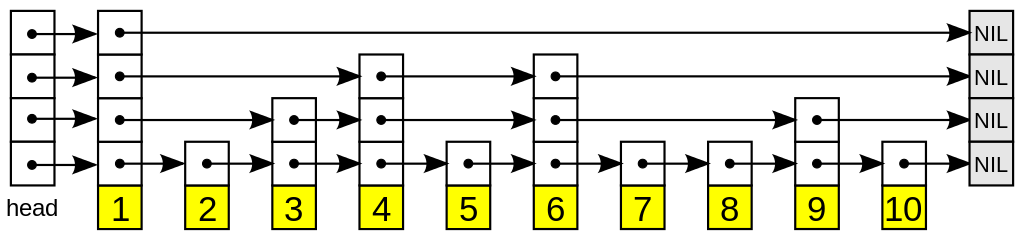
Список с пропусками
Список с пропусками - это вероятностная структура данных. Она основана на нескольких отсортированных связных списках.
Всего есть несколько слоев, причем первый это обычный упорядоченный связный список. А каждый следующий уровень - отдельный список, который может указывать на другие.
За счет рандомизации высоты каждого узла, можно достичь логарифмической сложности O(log(N)) операций.
Важная деталь - на первом уровне все узлы расположены в порядке возрастания.
При реализации конкурентной очереди с приоритетом в основе я использовал статью Linden and Jonsson (статья).
Моя реализация буквально слово в слово повторяет ее, за исключением некоторых моментов: адаптация к C#, поддержка одинаковых ключей и пулинг массивов при поиске места вставки.
Кроме них существуют еще несколько:
Также стоит упомянуть о Relaxed версиях очередей. Они отличаются тем, что вернуть могут не глобальный минимум, а близкий к минимуму. Такая реализация представлена Wimmer et. Al (ссылки не нашел).
Реализация
Важное замечание: в примерах ниже для блокировки используется конструкция
lock. В реальности используетсяSpinLock, но чтобы убрать лишний шум, всю конструкцию использованияSpinLockзаменил наlock
Основные структуры данных
Основной структурой является узел списка
internal class SkipListNode<TKey, TValue>
{
/// <summary>
/// Ключ
/// </summary>
public TKey Key = default!;
/// <summary>
/// Значение
/// </summary>
public TValue Value = default!;
/// <summary>
/// Массив указателей на другие узлы в списке.
/// Каждый индекс соответствует своему уровню, начиная снизу.
/// </summary>
public SkipListNode<TKey, TValue>[] Successors = null!;
/// <summary>
/// Следующий узел логически удален
/// </summary>
public volatile bool NextDeleted;
/// <summary>
/// Узел находится в процессе вставки
/// </summary>
public volatile bool Inserting;
/// <summary>
/// Блокировка на время обновления узла
/// </summary>
public SpinLock UpdateLock = new();
}
Сама очередь с приоритетами представляется таким образом
public class ConcurrentPriorityQueue<TKey, TValue>
{
/// <summary>
/// Голова списка
/// </summary>
private readonly SkipListNode<TKey, TValue> _head;
/// <summary>
/// Хвост списка
/// </summary>
private readonly SkipListNode<TKey, TValue> _tail;
/// <summary>
/// Максимальная высота списка
/// </summary>
private int Height => _head.Successors.Length;
/// <summary>
/// Максимальное количество хранимых логически удаленных узлов
/// </summary>
private readonly int _deleteThreshold;
// ...
}
Enqueue
Первой операцией рассмотрим вставку нового элемента.
Механика вставки похожа на вставку в обычный список с пропусками.
Эта операция делится на 2 части:
Вставка узла на 1 уровне
Наращивание высоты узла
Вставка на 1 уровне
Вначале определяется место для вставки нового элемента.
Алгоритм такой же как и в обычном списке с пропусками:
Переходим на
iуровень (ниже)Пропускаем все удаленные узлы
Пропускаем все узлы с ключами не больше, либо пока не наткнемся на хвост списка
Сохраняем 2 узла: на котором остановились и на который указывает этот узел на
iуровне (между ними вставляем новый узел)
Начинаем с самого верхнего уровня и повторяем, пока не достигнем первого уровня.
/// <summary>
/// Для заданного ключа получить список всех ближайших левых (ключ меньше) и последующих узлов
/// </summary>
private (SkipListNode<TKey, TValue>[] Predecessors, SkipListNode<TKey, TValue>[] Successors, SkipListNode<TKey, TValue>? LastDeleted) GetInsertLocation(TKey key)
{
var previous = _head;
// Последний удаленный узел
var lastDeleted = ( SkipListNode<TKey, TValue>? ) null;
// Предшествующие узлы
var predecessors = new SkipListNode<TKey, TValue>[Height];
// Последующие узлы
var successors = new SkipListNode<TKey, TValue>[Height];
var i = Height - 1;
while (0 <= i)
{
var current = previous.Successors[i];
while (!IsTail(current) &&
(
// current.Key <= key
IsLessOrEqualThan(current.Key, key)
|| current.NextDeleted
|| ( previous.NextDeleted && i == 0 ) )
)
{
if (previous.NextDeleted && i == 0)
{
// Запоминаем последний удаленный узел из префикса
lastDeleted = current;
}
previous = current;
current = previous.Successors[i];
}
predecessors[i] = previous;
successors[i] = current;
i--;
}
return ( predecessors, successors, lastDeleted );
}
В результате у нас есть 2 массива: predecessors и successors - предшествующие и последующие узлы для нового узла, i-ый элемент которых указывает на предшествующий или последующий узел на i высоте.
Теперь, когда нужно вставить элемент на уровне i после предшествующего узла (predecessors[i]), нужно сравнить узел на который он указывает на i уровне (predecessors[i].Successors[i]) с хранящимся элементом у нас (successors[i]).
Когда эти массивы получены, вставляем элемент на первом уровне через CAS.
В случае, если операция провалилась - повторяем этот этап заново, так как список был изменен (в частности, перед предшественником на 1 уровне параллельно вставили узел)
public void Enqueue(TKey key, TValue value)
{
// 1. Аллоцируем память, под узел
var height = _random.Next(1, Height);
var node = new SkipListNode<TKey, TValue>()
{
Key = key,
Value = value,
Successors = new SkipListNode<TKey, TValue>[height],
Inserting = true,
};
// 2. Находим место, куда нужно вставить элемент
var (predecessors, successors, lastDeleted) = GetInsertLocation(key);
// 3. Пытаемся вставить в список на 1 уровне.
// Эта операция аналогична добавлению узла в сам список
while (true)
{
node.Successors[0] = successors[0];
var pred = predecessors[0];
// Пытаемся атомарно обновить следующий узел в предыдущем узле
lock (pred.UpdateLock)
{
if (pred.Successors[0] == successors[0]
&& !successors[0].NextDeleted)
{
pred.Successors[0] = node;
break;
}
}
// Заново рассчитываем предшественников и последователей
( predecessors, successors, lastDeleted ) = GetInsertLocation(key);
}
// ...
}
Наращивание высоты
Когда узел был успешно добавлен в список, переходим ко 2 этапу - наращивание высоты.
Начиная с этого момента, вставляемый узел является полноценным членом списка, поэтому в любой момент может быть удален, либо около него вставлены элементы - нужно такое отслеживать.
Наращивание высоты происходит так же как и в обычном списке с пропусками снизу вверх (за исключением дополнительных проверок):
Переходим к очередному уровню
i(выше)Проверяем, что узел не удален
На новом узле выставляем ссылку на следующий узел на высоте
iАтомарно (
CAS) меняем ссылку на следующий узел у предшествующего узла с проверкой на равенство нашему последователю-
Если обмена не произошло, то
Вычисляем предшествующие и последующие узлы заново
Если предшествующий узел не равен добавляемому, то прекратить вставку
На шаге 2 мы делаем 2 проверки:
Следующий сразу после нас узел не удален
Последующие узлы на каждом уровне не удалены
Обе они проверяют, что узлы после нас не удалены - проверки, что вставляемый узел удален не делаем.
Эта проверка исходит из того, что флаг удаления хранится в предыдущем узле и перед нами может в любой момент быть вставлен новый узел.
В оригинальной статье предполагалось наличие различных ключей, поэтому на этапе 5.2 проверялось равенство с последующим узлом. Я немного изменил алгоритм (добавил поддержку различных ключей), поэтому новые элементы с одинаковыми ключами добавляются после старых элементов.
Может случиться и так, что добавился новый узел с одинаковым ключом, но наш узел еще не до конца добавлен. Я принял решение прекращать добавление новых узлов, так как это проще реализовать.
public void Enqueue(TKey key, TValue value)
{
// ...
// 4. Постепенно наращиваем высоту вставляемого узла
var i = 1;
while (i < height)
{
if (node.NextDeleted
|| // Узел удален в процессе вставки
successors[i].NextDeleted
|| // Узел дальше удален, соответсвенно и мы
successors[i] == lastDeleted)
{
// Узел был удален в процессе вставки
break;
}
node.Successors[i] = successors[i];
var old = Interlocked.CompareExchange(ref predecessors[i].Successors[i], node, successors[i]);
if (old != successors[i])
{
// Кто-то другой изменил список, заходим на другой круг
( successors, predecessors, lastDeleted ) = GetInsertLocation(key);
if (!ReferenceEquals(predecessors[0], node))
{
// Если добавлен новый узел
break;
}
}
i++;
}
node.Inserting = false;
}
Dequeue
Удаление тоже разделено на 2 части: логическое и физическое.
Логическое удаление
Логическое удаление - выставление флага удаления NextDeleted.
Для логического удаления итерируются все узлы на первом уровне, пока не найдется тот, у которого следующий узел не удален (не выставлен флаг NextDeleted).
Когда такой найден, выставляется флаг, и удаленным считается следующий узел.
В оригинальной статье, этот флаг хранился в наименьшем значащем бите (LSB) указателя на первом уровне (Successors[0]).
В 32-х битных системах свободными будут 2, а в 64-х битных - 3 последних бита.
Часто так и поступают (используют LSB в качестве флагов), но:
В управляемых языках (C#, Java, Python) нет возможности прямого управления указателями
В word-aligned архитектурах нет LSB в указателях - все место заполнено
Для решения этой проблемы я выделил флаг удаления в отдельное поле NextDeleted и, чтобы выполнить логическое удаление, беру блокировку.
В качестве блокировки использую SpinLock. Под капотом он использует Interlocked.CompareExchange, и так как при захваченной блокировке выполняется только простая проверка с присвоением (сложной логики нет), то (грубо) все действия можно заменить на один CAS.
public bool TryDequeue(out TKey key, out TValue value)
{
// Текущий первый узел
var currentHead = _head.Successors[0];
// Запоминаем первый узел, чтобы избежать гонки при удалении старых узлов
var observedHead = currentHead;
// Количество пройденных удаленных узлов
var deletedCount = 0;
// Здесь храним новую голову списка, которой заменим старую
var newHead = ( SkipListNode<TKey, TValue>? ) null;
while (true)
{
if (IsTail(currentHead))
{
key = default!;
value = default!;
return false;
}
if (currentHead.Inserting &&
newHead is null)
{
newHead = currentHead;
}
if (currentHead.Deleted)
{
deletedCount++;
currentHead = currentHead.Successors[0];
continue;
}
// CAS
lock (currentHead.UpdateLock)
{
if (!currentHead.Deleted)
{
currentHead.Deleted = true;
deletedCount++;
break;
}
}
currentHead = currentHead.Successors[0];
deletedCount++;
}
// На этом моменте, в currentHead хранится узел, который мы удалили
if (deletedCount < _deleteThreshold)
{
key = currentHead.Key;
value = currentHead.Value;
return true;
}
// ...
}
Физическое удаление
Физическое удаление - очищение памяти. В случае управляемого языка, это значит просто удалить все указатели на удаленные узлы, а GC сам очистит память.
Для оптимизации физическое удаление происходит батчами, т.е. при достижении определенного количества логически удаленных узлов. Размер указывается параметром DeleteThreshold
Все логически удаленные узлы формируют префикс и таким образом список можно разделить на 2 части:
Префикс из удаленных узлов
Список из живых узлов с неубывающими ключами (сам список с пропусками)
Удаление так же выполняется с помощью CAS - старый первый узел меняется новым.
Причем новый первый узел должен быть также удаленным, т.е. после первого удаления голова списка всегда будет указывать на удаленный узел.
public bool TryDequeue(out TKey key, out TValue value)
{
// ...
// На данный момент, если newHead не null, то содержит узел, который был в процессе вставки в момент обхода.
newHead ??= currentHead;
var updated = false;
// CAS
lock(_head.UpdateLock)
{
if (_head.Successors[0] == observedHead)
{
_head.Successors[0] = newHead;
updated = true;
}
}
if (updated)
{
RemoveDeletedNodes();
}
key = currentHead.Key;
value = currentHead.Value;
return true;
}
/// <summary>
/// Удалить ссылки на удаленные узлы из головы списка
/// </summary>
/// <remarks>
/// Удаление происходит только на верхних уровнях - первый не затрагивается
/// </remarks>
private void RemoveDeletedNodes()
{
var i = Height - 1;
var previous = _head;
while (i > 0)
{
// Запоминаем старую голову списка, чтобы при обновлении не задеть новую
var savedHead = _head.Successors[i];
if (!savedHead.NextDeleted)
{
i--;
continue;
}
var next = previous.Successors[i];
// Находим последний удаленный узел
while (next.NextDeleted)
{
previous = next;
next = previous.Successors[i];
}
// Выставляем ссылку на следующий узел у головы списка
var old = Interlocked.CompareExchange(ref _head.Successors[i], previous.Successors[i], savedHead);
if (old == savedHead)
{
// Успешно обновили ссылку.
// Ссылка могла не обновиться если есть несколько конкурентных операций Restructure,
// в таком случае, просто повторяем операцию
i--;
}
}
}
Бенчмарки
Настало время сравнения производительности.
Для сравнения я использовал очередь с приоритетом из стандартной библиотеки - System.Collections.Generic.PriorityQueue.
Сама очередь реализована с помощью 4-арной кучи (вместо 2 потомков - 4). Разбор реализации есть в этой статье. Глобальная блокировка выполнена с помощью lock на само поле очереди.
public class LockingPriorityQueue<TKey, TValue>
{
private readonly PriorityQueue<TValue, TKey> _queue = new();
public void Enqueue(TKey key, TValue value)
{
lock (_queue)
{
_queue.Enqueue(value, key);
}
}
public bool TryDequeue(out TKey key, out TValue value)
{
lock (_queue)
{
return _queue.TryDequeue(out value, out key);
}
}
}
Предварительно, я добавил пулинг массивов successors и predecessors при вставке нового элемента. Реализован он с помощью ConcurrentQueue. В примерах это убрал, чтобы не добавлять лишний шум.
Добавляемые ключи и значения генерируются предварительно. Количество элементов 100000. Во всех тестах используются одни и те же значения, так как ключ Random одинаковый.
Для тестов используются 2 вида поведения:
Равномерное: каждый поток, после каждого
EnqueueвызываетDequeueСначала вставка, потом удаление: каждый поток сначала добавляет все элементы затем вызывает
Dequeueстолько раз, сколько вызывалEnqueue
Параметры стенда:
AMD Ryzen 5 6600H, 12 логических и 6 физических ядер
16 ГБ Озу
.NET 6.0.21
Ubuntu 22.04
Результаты представлены на графиках:
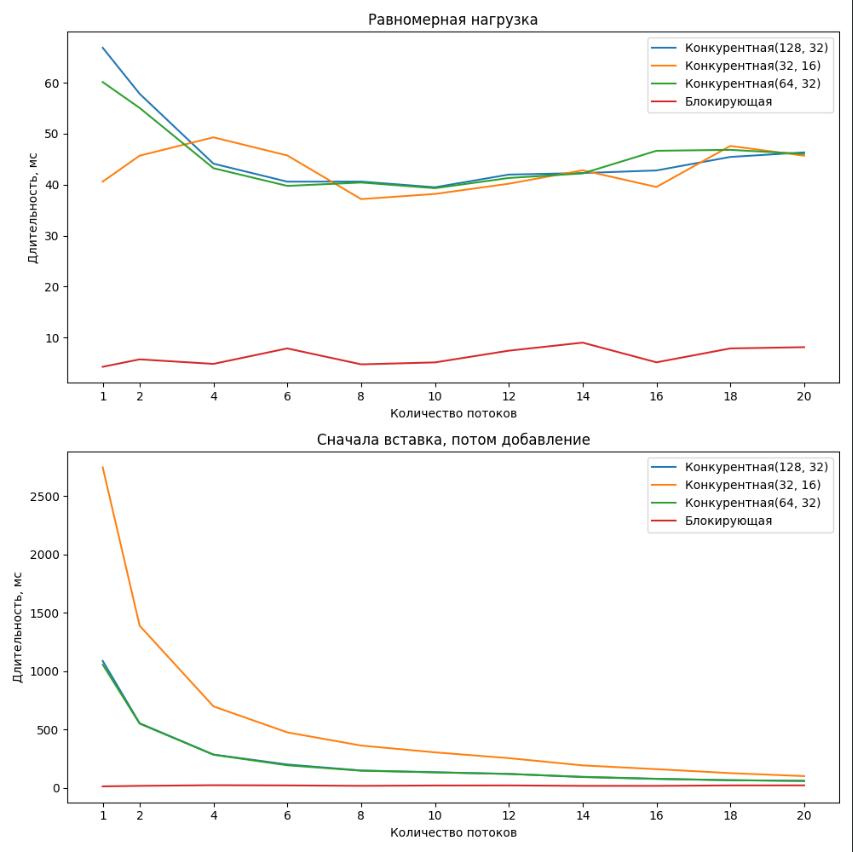
Конкурентная(N1, N2) - реализация конкурентной очереди, где
N1- кол-во хранящихся логически удаленных узлов,N2- высота списка.
Блокирующая - реализация с помощью глобальной блокировки
Результат на лицо: моя конкурентная реализация сильно уступает версии с глобальной блокировкой.
Даже когда заменил инстанциирование новых массивов Successors на пуллинг, а в версии с глобальной блокировкой заменил SpinLock на lock, практически ничего не поменялось: худшее исполнение глобальной блокировки было лучше самой быстрой конкурентной версии кратно.
Вывод
Оказалось версия с глобальной блокировкой сильно обгоняет конкурентную версию.
Причиной этому я вижу:
Большие накладные расходы на поиск места вставки нового узла и его постоянные вычисления
Расходы на аллокации памяти для новых узлов
Оптимальная реализация версии из стандартной библиотеки перевешивает затраты на глобальную блокировку
Использование
SpinLockвместоCASсильно тормозит работу
В оригинальной статье приводилось сравнение с другими конкурентными реализациями, но сравнения с синхронной под блокировкой не было. Зато она была в статье Jakob Gruber и там, версия Linden сильно обгоняла все остальные.

Здесь реализацию Linden предоставили сами авторы. Думаю, в их реализации есть оптимизация некоторых моментов, которые я не учел.
Реализация лежит в GitHub.
Если есть предположения причин подобного, то пишите в комментариях.
Комментарии (11)

lightln2
15.08.2023 10:31А Вы не сравнивали с их реализацией? они дают на нее в статье ссылку.
Правда, их статья десятилетней давности, а код последний раз обновлялся 5 лет назад. Ну и всегда можно напрямую автору написать, у Линдена есть профиль на линкедине

vvdev
15.08.2023 10:31Немного не в тему, но всё-же: а пробовали сравнивать производительность SpinLock и Monitor?
К моему удивлению, Monitor работает быстрее, по крайней мере в случаях, когда в основном ему не приходится блокировать поток(и).
Честно говоря, считал, что СпинЛок должен быть гораздо дешевле и шустрее.
Vanirn
15.08.2023 10:31На DotNext есть отличная лекция по этой теме. Станислав Сидристый — lock(_sync): иллюзия идеального выбора
vvdev
15.08.2023 10:31Спасибо за ссылку, о паре нюансов даже не задумывался.
Но всё это не отменяет моего удивления: мой случай идеален для SpinLock: очень короткая операция, количество потоков меньше количества ядер, очень низкий или нулевой contention — казалось бы, почему Monitor/Lock заметно лучше? Если бы было +- одинаково — не было бы вопросов.
… по следам этого доклада, прогнал бенчмарк для new SpinLock(false): быстрее дефолтного, но в случае с (около)нулевым контеншном всё равно медленнее lock'a, в случае с высоким контеншном — быстрее.
Позор, конечно, что я упускал это раньше.

AndreySnake
15.08.2023 10:31У меня была зада с разных потоков собирать счётчики, группировать их, суммировать ща Н времени. При попытке использовать concurrentqueue процессор взлетел под 90 - потому что использует лок. При использовании akka.net никаких проблем с производительностью - все считаетс, процессор отдыхает. И все при одинаковых исходных данных.
vvdev
15.08.2023 10:31Вообще, в ConcurrentQueue не так уж много локов. На самом деле из конкурентной троицы Queue-Stack-Bag она самая быстрая (на моём опыте).
Любопытно было бы взглянуть, что её так убило.… ок, приврал, ConcurrentQueue быстрее стека, ConcurrentBag легче, но это другая история.
bfDeveloper
Простите, что докапываюсь до слов, а не содержимого, но очередь точно конкурентная, а не потокобезопасная или многопоточная? Если в английском concurrent (одновременный) тут применимо, то созвучное русское слово ну вообще же не в тему. Это не прямой перевод, не устоявшийся в русском термин.
dyadyaSerezha
Полностью согласен и ещё добавлю - слова синхронный и concurrent не противоположные, так как concurrent тоже выполняется синхронно (вызывающий код ждёт). То есть, даже слово "синхронный" в статье используется неверно. Лучше писать "однопоточный" или ещё как-то.
AshBlade Автор
Слово "синхронный" в данном контексте я использовал как синоним "блокирующий". Он не имеет отношения к асинхронности. Согласен, что плохой синоним.
На счет "конкурентная" - в данном случае, используется для обозначения поддержки одновременных операций несколькими потоками. Лучше подходит синоним "потокобезопасный", но использовал "конкурентный", т.к. сам класс назвал в соответствии с наименованием многопоточных структур данных из стандартной библиотеки (из пространства имен
System.Collections.Concurrent, все они имеют приставкуConcurrent)AgentFire
Просто "concurrent" даже в топ-6 гуглопереводов не переводится как "конкуретный" :)
dyadyaSerezha
Ваш "конкурентный" вариант тоже блокирующий. Так что он тоже синхронный.
Как уже написал первый комментировавший, "конкурентный" - плохой и неверный перевод слова "concurrent" в программировании, хотя и упорно продвигается некоторыми.