

Привет, Хабр! На связи Рустем IBM Senior (помидор) DevOps Engineer и сегодня я хотел бы поговорить про Feature Engineering in Data Preprocessing.
Наши реквизиты: Python 3.6 и pandas.
Кодовая база: https://github.com/zetzo/Data-Preprocessing-Feature-Engineering.git
Что такое инженерия признаков/конструирование показателей?
Инжиниринг признаков — это создание новых признаков на основе существующих признаков, и он добавляет в ваш набор данных информацию, которая в некотором роде полезна: добавляет признаки, полезные для вашего прогноза или задачи кластеризации, или упускает понимание взаимосвязей между признаками. Реальные данные часто бывают нечеткими и аккуратными, и в дополнение к этапам предварительной обработки, таким как стандартизация, вам, вероятно, придется извлекать и расширять информацию, которая существует в столбцах вашего набора данных.
Feature engineering, более простыми словами — это техника решения задач машинного обучения, позволяющая увеличить качество разрабатываемых алгоритмов. Предусматривает превращение данных, специфических для предметной области, в понятные для модели векторы.
Разработка признаков сильно зависит от конкретного набора данных, который вы анализируете, поэтому очень важно иметь глубокое понимание набора данных, который вы хотите смоделировать.
Давайте рассмотрим несколько примеров, когда мы хотели бы заинжинирить наши показатели. Чрезвычайно распространенный — со строковыми данными.
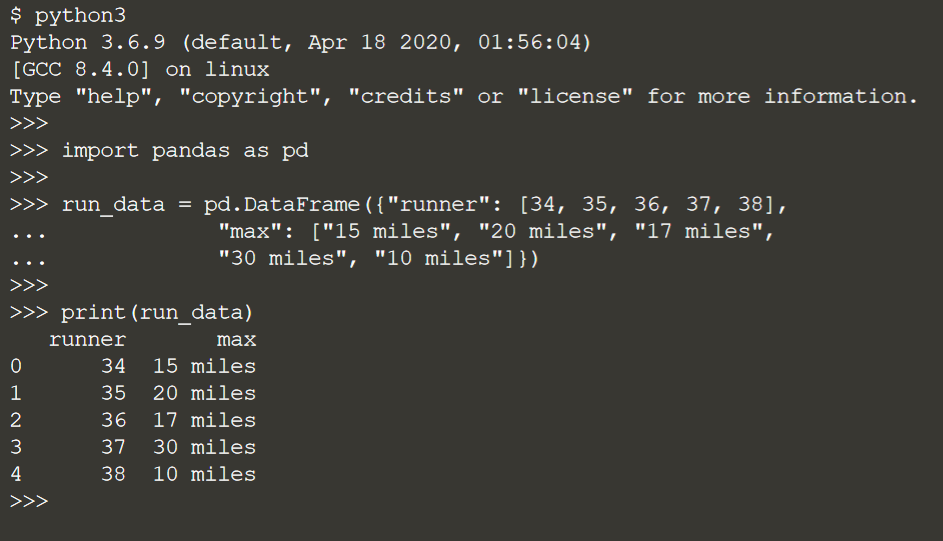
Например, это ситуация, когда мы можем захотеть извлечь количество миль в качестве числового признака для моделирования из текста.
Еще один пример, связанный со строковыми данными: набор данных со столбцом, в котором записаны любимые цвета людей.
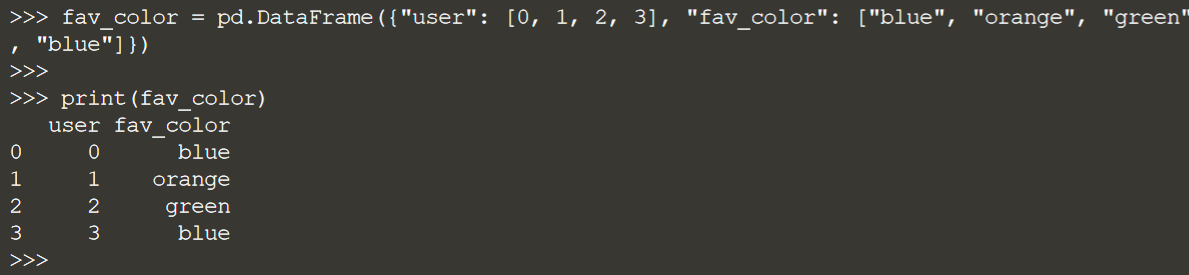
Чтобы ввести эту информацию в модель в scikit-learn, вам придется закодировать эту информацию численно.
Давайте посмотрим на набор данных добровольцев и определим некоторые возможности для разработки признаков:

Эти три столбца являются хорошими кандидатами для инжиниринга. recurrence_type — бинарная категориальная переменная:

created_date — это дата, и в этом наборе данных есть несколько других столбцов даты, которые необходимо преобразовать перед моделированием:

И, наконец, category_desc — это категориальная переменная с несколькими значениями:

Извлечение признаков с помощью регулярных выражений
Регулярные выражения — это шаблоны, которые можно использовать для извлечения паттернов из текстовых данных. Вот у нас есть строка, и мы хотим извлечь из нее цифру температуры — 45,6:

Обратите внимание, что это число является числом с плавающей запятой. Нам понадобится шаблон для извлечения этого числа с плавающей запятой, который мы можем создать с помощью библиотеки re Python.

Давайте разберем шаблон в re.compile. \d означает, что мы хотим захватить цифры, а + означает, что мы хотим захватить как можно больше, поэтому, если есть два рядом друг с другом, нам нужны оба (например, 45). \. означает, что мы хотим захватить десятичную точку, а затем еще один \d+ в конце, чтобы захватить цифры в правой части десятичной дроби.
Чтобы вернуть соответствующий шаблон, мы можем использовать findall():

Обратите внимание, что findall() возвращает список строк совпавшего паттерна. В этой ситуации мы хотели бы вернуть температуру в виде числа с плавающей запятой. Поскольку мы знаем, что в нашей строке есть только одна температура, мы можем сделать следующее:

Это было бы немного сложнее в обстоятельствах, когда у нас есть несколько числовых экземпляров в строке, но на данный момент этого достаточно.
Давайте попробуем это на наборе данных для пеших прогулок. Столбец «Length» в наборе данных для походов представляет собой столбец строк, но в столбце содержится километраж похода. Мы собираемся извлечь этот пробег с помощью регулярных выражений, а затем использовать лямбду в pandas, чтобы применить извлечение ко всему DataFrame.

Во-первых, давайте создадим функцию, которая будет находить и возвращать пробег в виде значения с плавающей запятой. Создание функции немного упрощает ее применение ко всему DataFrame. В этой функции мы будем использовать isinstance() Python, чтобы убедиться, что мы обрабатываем строку — в противном случае произойдет сбой при отсутствующих значениях. Проверяя длину нашего списка, созданного с помощью findall(), мы определяем, есть ли совпадения, и если да, то возвращаем их.

Затем давайте применим к столбцу «Length» и создадим новый столбец только с пешеходным километражем:

Наконец, давайте сравним наш новый столбец с исходным столбцом, чтобы убедиться, что он работает:

Бинарное кодирование категориальных переменных
Поскольку модели в scikit-learn требуют числового ввода, если ваш набор данных содержит категориальные переменные, вам придется их кодировать. Кодирование двоичных значений на самом деле довольно просто и может быть выполнено как в pandas, так и в scikit-learn. Вы можете захотеть закодировать переменные в pandas, если вы не закончили предварительную обработку или если вы заинтересованы в дальнейшей исследовательской работе после кодирования. С другой стороны, вы можете захотеть использовать scikit-learn, если, например, вы реализуете кодирование как часть функциональности конвейера scikit-learn, что позволяет вам объединять различные части процесса машинного обучения.
Давайте рассмотрим пример с использованием набора данных для пеших прогулок. Один столбец, который нуждается в кодировании, — это столбец Accessible, который имеет значения либо Y, либо N.

В pandas мы можем использовать apply() для кодирования 1 и 0 в столбце DataFrame, используя простое условие, которое возвращает 1, если значение в Accessible равно Y, и 0, если значение равно N.
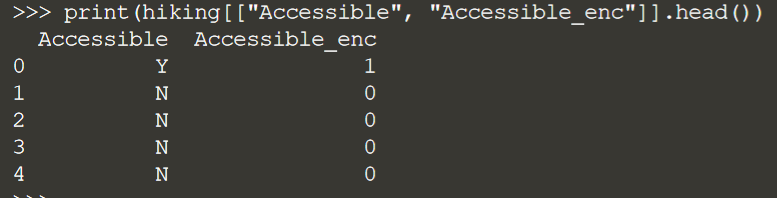
Глядя на параллельное сравнение столбцов, вы можете видеть, что столбец теперь имеет числовое кодирование.
Вы также можете сделать это в scikit-learn, используя LabelEncoder. Создание объекта LabelEncoder также позволяет повторно использовать эту кодировку для других данных, таких как новые данные или тестовый набор. Вы можете использовать fit_transform() как для подгонки кодировщика к данным, так и для преобразования столбца.

Распечатав Accessible и его закодированные аналоги, мы видим, что значения Y и N были закодированы в 1 и 0 одинаковым образом как в pandas, так и в scikit-learn.
Кодирование категориальных переменных, One-Hot
One-hot кодирование кодирует категориальные переменные в 1 и 0, когда у вас есть более двух переменных для кодирования. Он работает, просматривая весь список уникальных значений в столбце, преобразуя каждое значение в массив и назначая 1 в соответствующей позиции для кодирования того, что конкретное значение встречается.
Давайте посмотрим на игрушечный пример, чтобы увидеть, как это работает, взяв небольшой набор данных цветов:

Здесь у нас есть три значения: blue, green и red. Чтобы сразу закодировать эти значения, мы можем использовать get_dummies() для создания столбцов для каждого.

Чтобы объединить эти столбцы с исходными данными, вы можете использовать pd.concat:

Если бы мы кодировали эти цвета с помощью 0 и 1 на основе этого списка, мы получили бы что-то вроде этого: blue будет иметь единицу в первой позиции, за которой следуют два нуля, green будет иметь единицу во второй позиции, а red будет иметь один в последней позиции. Таким образом, закодированный столбец будет выглядеть примерно так, где значение 1 указывает, что этот цвет появился в исходном столбце в этой конкретной строке.
Один из столбцов в наборе данных о волонтерах, category_desc, дает описания категорий для перечисленных вакансий волонтеров. Поскольку это категориальная переменная с более чем двумя категориями, давайте потренируемся использовать однократное кодирование для численного преобразования этого столбца:

Наконец, мы можем объединить их обратно в DataFrame и взглянуть на несколько строк и их кодировку:

Агрегация статистики
Если у вас есть, скажем, набор функций, связанных с одной функцией, такой как температура или время работы, вы можете вместо этого использовать среднее значение или медиану в качестве функции для моделирования.
Обычный метод разработки признаков состоит в том, чтобы взять совокупность набора чисел для использования вместо этих признаков. Это может быть полезно для уменьшения размерности вашего пространства признаков или, возможно, вам просто не нужны несколько одинаковых значений, которые находятся на близком расстоянии друг от друга.
Допустим, у нас есть DataFrame времени работы с именем running_times_5k:
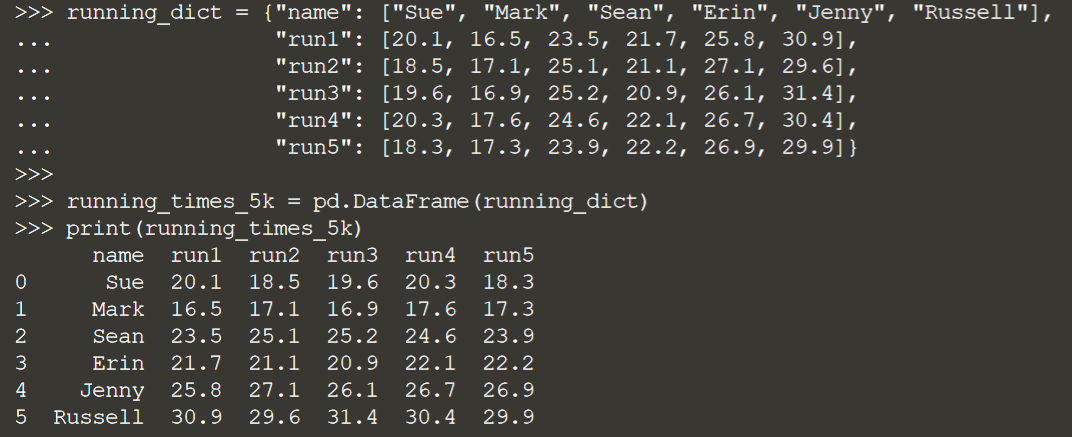
Вместо того, чтобы использовать каждое отдельное время выполнения для построения нашей модели, давайте использовать среднее значение этих пяти запусков для каждого человека в наборе данных.
Давайте создадим список столбцов, которые мы хотим усреднить, просто чтобы упростить задачу:

И снова мы можем использовать apply() для применения функции к нашему набору данных. В этой ситуации мы применяем метод mean() только к тем столбцам, которые хотим усреднить, а axis=1 будет возвращать значения по строкам:

И теперь у нас есть столбец агрегированного среднего.
Работа с datetimes
Даты и временные метки — это еще одна область, в которой вы можете уменьшить степень детализации набора данных. Если вы выполняете анализ временных рядов, это, вероятно, другая история, но если вы выполняете задачу прогнозирования, вам может понадобиться информация более высокого уровня, например месяц или год, или и то, и другое.
В наборе данных добровольцев есть несколько столбцов, состоящих из даты и времени.

Предположим, что полная дата слишком детализирована для задачи прогнозирования, которую мы хотим выполнить, поэтому давайте извлечем месяц из столбца start_date_date.
Первое, что нужно сделать, это преобразовать этот столбец в столбец даты и времени в pandas, используя метод to_datetime(). Это значительно упрощает задачу извлечения:

Поскольку этот столбец теперь является датой и временем, мы можем просто использовать атрибут .month, чтобы извлечь месяц из каждой строки, снова используя apply():

Теперь у нас есть столбец только с номером месяца. Вы также можете использовать такие атрибуты, как «day», чтобы получить день:

И «year», чтобы получить год:

Для многих операций даты и времени, особенно связанных с анализом временных рядов, ваш столбец даты и времени должен быть индексом вашего DataFrame. Однако это все, что нам нужно знать, чтобы продолжить наше путешествие по разделу “Data Preprocessing in Data Engineering”.
Всех желающих приглашаем на открытое занятие «Greenplum Platform Extension Framework (PXF)». На этом занятии вместе с Вадимом Заигриным, Scala Big Data разработчиком рассмотрим фреймворк PXF (Platform Extension Framework): узнаем, что это и зачем он нужен, а также рассмотрим его архитектуру и принципы работы. Регистрация по ссылке.