

????userver позволяет быстро создавать эффективные микросервисы на языке C++ и уже много лет активно используется в Яндекс Go, Еде, Лавке, Доставке, Маркете, финтехе и других проектах. Вот из каких требований мы исходили в процессе разработки:
- Простота. Стажёр или студент, приходя к нам, может уже через неделю написать и отправить в продакшен новый микросервис.
- Надёжность. Многие ошибки, в том числе и связанные с многопоточностью, можно поймать на этапе компиляции. Кроме того, фреймворк даёт подсказки по исправлению проблем.
- Полнота. В userver есть всё необходимое для тестирования, работы с разными базами данных, кеширования, логирования, трейсинга, распределённых блокировок, работы с JSON, BSON, YAML, изменения параметров сервиса на лету и так далее.
Сейчас я расскажу о том, как возникла идея userver, как фреймворк развивался, в каких задачах его сейчас используют и почему именно выход в опенсорс был логичным следующим шагом. А затем приведу пример написания нового микросервиса.
Как всё началось
В самом начале своего пути Такси придерживалось монолитной архитектуры. Но у этой архитектуры есть недостатки, с которыми мы не готовы были мириться.
Монолитное приложение — плохое решение с точки зрения отказоустойчивости. SegFault во второстепенном модуле роняет весь сервис. При этом, не дождавшись ответа от бэкенда, клиент сделает перезапрос, затем ещё один — и вот уже три инстанса монолита находятся в нокдауне. В теории пара десятков таких клиентов могут привести к полной неработоспособности сервиса. Разумеется, у нас множество механизмов для предотвращения подобных проблем. Но всё равно неприятно.
Минусы монолитной архитектуры на этом не заканчиваются. Вот несколько других:
- Объединение всего кода внутри монолита. При большой кодовой базе сборка и тесты могут занимать часы, а выкатка — целый день.
- Тесное взаимодействие разных частей кода. Нужно тратить много сил на ревью кода, чтобы интерфейсы разных частей монолита не превратились в «кашу».
- Хрупкость. Изменение в одном модуле может сломать другой модуль.
- Размытые зоны ответственности. В процессе разработки многие части кода обобщаются, начинают использоваться разными командами — и это хорошо. Но в результате непонятно, кто отвечает за полученный модуль — первые авторы; те, кто внёс больше всего правок; или те, кто активнее всего пользуется модулем в своём коде.
Для множества небольших команд в Такси намного лучше подходила микросервисная архитектура.
Начало разработки userver
Переход с монолита на микросервисы должен быть максимально простым для разработчиков. В новом решении необходимо иметь возможность переиспользовать старый, проверенный временем C++-код — и разработчиков C++. То есть нужен C++-фреймворк. Язык хорош ещё и тем, что не зависит от одного вендора/компании, является статически типизированным и одним из самых эффективных языков программирования.
Также для микросервисной архитектуры характерно ожидание ввода-вывода. Требовалось учесть это в новом фреймворке и выстроить его внутреннюю архитектуру максимально эффективно для IO-bound-задач.
Так началась разработка корутинного движка userver. Корутины позволили асинхронно, эффективно по CPU работать с операционной системой — и в то же время сохранили простоту написания кода.
Разработчик пишет простой линейный код, а движок фреймворка сам заботится о его эффективном исполнении, переключаясь на выполнение других корутин в местах, помеченных значком ракеты (писать его в продакшн коде не надо, он тут только чтобы объяснить, где происходят переключения корутин). Таким образом, пока данные от ОС не готовы, поток выполнения не простаивает, а занимается обработкой других запросов:
Response View::Handle(Request&& request, const Dependencies& dependencies) {
auto cluster = dependencies.pg->GetCluster(); // ????
auto trx = cluster->Begin(storages::postgres::ClusterHostType::kMaster); // ????
const char* statement = "SELECT ok, baz FROM some WHERE id = $1 LIMIT 1";
auto row = psql::Execute(trx, statement, request.id)[0]; // ????
if (!row["ok"].As<bool>()) {
LOG_DEBUG() << request.id << " is not OK of "
<< GetSomeInfoFromDb(); // ????
return Response400();
}
psql::Execute(trx, queries::kUpdateRules, request.foo, request.bar); // ????
trx.Commit(); // ????
return Response200{row["baz"].As<std::string>()};
}Для любопытных есть статья, где я расписывал устройство современных асинхронных фреймворков и рассказывал о плюсах-минусах различных разновидностей корутин.
Зачем использовать userver
Основные достоинства фреймворка — это простота использования, эффективность, полнота функциональности и отлаженность на масштабах Яндекса.
Конечно, IO-bound-приложения не редки и на рынке предоставлено множество известных и зрелых продуктов. Есть отдельный язык программирования Go, ориентированный на написание таких приложений. Но это одновременно и минус. Если у вас кодовая база на C++ или основная разработка на C++, то внедрять новый язык будет трудозатратно, а имеющийся код придётся переписывать или адаптировать к использованию из другого языка.
Есть узкоспециализированные фреймворки, в том числе и на C++, для написания микросервисов. Однако их функциональности порой не хватает. Например, чтобы организовать функциональное тестирование сервиса и мокать обращения к другим микросервисам, вам придётся разрабатывать собственную инфраструктуру.
Помимо готовых фреймворков есть и отдельные библиотеки, на основе которых можно попробовать собрать свой фреймворк. Но чтобы получился действительно готовый и удобный к использованию инструмент, придётся потратить крайне много усилий. Нужно не только взять драйвер для базы данных, библиотеку для изменения конфигов без рестарта сервиса и библиотеку для записи метрик, но и состыковать их друг с другом, чтобы драйвер мог переконфигурироваться на лету и записывал метрики по запросам.
userver — проверенное многими сервисами решение. Фреймворк выдерживает огромный поток запросов и при этом обладает богатой функциональностью для разработки, диагностики, мониторинга, трейсинга, отладки и экспериментов.
Опыт пользователей
Лавка
В какой-то момент разработчики столкнулись с проблемой, что быстрый рост популярности Лавки привёл к непропорционально большому росту нагрузки на сервисы. Назрела необходимость переносить их на более эффективный язык программирования. userver пришёлся кстати: все нужные инструменты уже были доступны во фреймворке, оставалось сосредоточиться на переносе логики.
Сейчас userver — это основной фреймворк разработки бэкенда Лавки.
Еда
Здесь несколько другая история. Разработчики столкнулись с отсутствием функциональности в используемом фреймворке. Встал выбор: реализовывать недостающую функциональность самим или начать пользоваться userver, где уже всё есть. Решили применять userver для новых микросервисов, а спустя несколько месяцев пришло и осознание того, что старые сервисы проще переписать, чем дорабатывать старый фреймворк.
Доставка
У Доставки, помимо микросервисов на userver, были и микросервисы на собственном фреймворке C++. Но один из старых сервисов не всегда работал стабильно, а порой ему и вовсе становилось плохо. В качестве эксперимента решили переписать его на userver. Проблемы изчезли, производительность подросла.
Возможно, улучшения связаны просто с тем, что устаревший код переписали, немного улучшив внутреннюю архитектуру. Но разработчики Доставки теперь планируют перенести на userver свой последний микросервис на старом фреймворке.
Go
С появлением первых версий userver начали потихоньку создавать часть новой функциональности на нём. По мере добавления возможностей во фреймворк всё больше новых функций писали на нём. А там дошли руки и до откалывания кусков от монолита с последующим переносом на userver.
Бóльшая часть изначального монолитного кода достаточно быстро превратилась в множество микросервисов. Казалось, процесс должен остановиться: от монолита откололи достаточно много функциональности, чтобы считать его микросервисом. Но внезапно победило удобство. userver оброс новыми полезными свойствами, упростилось тестирование. Старый монолит стал уступать в возможностях. В итоге перенесли на общий фреймворк userver и ключевую часть монолита.
Выход в опенсорс
Нам показалось хорошей идеей поделиться с миром своим фреймворком, чтобы он нашёл применение в новых полезных направлениях.
Но внезапно ситуация оказалась намного интереснее. Когда мы постарались тихо и незаметно выложить исходники на Гитхаб, у нас ничего не вышло. Уже через пару часов разработчики заметили исходники и стали активно экспериментировать. В итоге в первые же недели нам принесли пару пул-реквестов на поддержку новых платформ, идей для оптимизаций (некоторые мы внедрили в день появления идеи) и много пожеланий по расширению функциональности. Всё это до анонса.
То есть и нам предлагают интересные вещи, и мы полезны проектам за пределами Яндекса.
Что значит статус «бета»
Мы специально используем пометку «бета», чтобы подчеркнуть — фреймворк сейчас находится в процессе переезда на открытую разработку:
- Ещё не все наши внутренние CI-проверки доступны снаружи.
- Заапстримлены ещё не все интеграции с инструментами, принятыми за пределами Яндекса.
- Нужно больше примеров для документации, так как нет возможности подглядеть решение из внутренних сервисов Яндекса.
Можно ли использовать userver в продакшене уже сейчас?
Мы годами применяем userver для сотен своих высоконагруженных высокодоступных сервисов. Экспериментируйте, пробуйте, насколько вам подходят текущие возможности. Если чего-то не хватает — пишите нам в телеграм-чатик или заводите feature request.
Как попробовать userver
Проще всего воспользоваться готовым шаблоном сервиса.
- Заходите в репозиторий, нажимаете «Use this template».
- Клонируете к себе полученный репозиторий.
- Если у вас POSIX платформа (Linux или macOS), можно разрабатываться локально. Устанавливаете зависимости, как написано в документации. Пример для Ubuntu 22.04:
sudo apt install $(cat scripts/docs/en/deps/ubuntu-22.04.md | tr '\n' ' ') git config --global --add safe.directory $(pwd)/third_party/clickhouse-cpp
Затем проверяете, что всё работает, черезmake test-debug.
Если у вас неподдерживаемая в данный момент платформа или вы просто предпочитаете Docker — проверьте, что всё работает, черезmake docker-test-debug.
Итого, у вас на руках работающий микросервис, который в ответ на запросы в эндпоинт
/hello приветствует пользователя.Делаете
git push в свой репозиторий, и GitHub CI сам запустит все тесты для C++ и Python.В полученном сервисе имеется несколько файлов:
-
src/hello.cpp— весь код эндпоинта/hello. -
src/hello_test.cpp— пример юнит-теста. -
src/hello_benchmark.cpp— пример бенчмарка. -
tests/test_basic.py— функциональные тесты сервиса. Поднимается весь сервис, задаются запросы в эндпоинт, проверяется ответ. Можно добавлять и другие файлы*.pyс новыми тестами, они автоматически подхватятся при запуске тестов. -
CMakeLists.txt— CMake-файл сборки. -
Makefile— вспомогательный файл, чтобы одной командой запускать тесты, сборки, форматирования кода и так далее. -
.github/workflows/— CI-файлы для сборки, установки и тестирования кода.
Пишем свой микросервис
Давайте добавим к нашему микросервису из прошлого раздела базу данных, например PostgreSQL. Сделаем так, чтобы эндпоинт запоминал людей, которые к нему пришли, а уже знакомых приветствовал иначе.
Для этого в его класс в
src/hello.cpp добавляете соединение с кластером PostgreSQL:userver::storages::postgres::ClusterPtr pg_cluster_;И инициализируете это соединение из конструктора эндпоинта:
Hello(const userver::components::ComponentConfig& config,
const userver::components::ComponentContext& component_context)
: HttpHandlerBase(config, component_context),
pg_cluster_(
component_context
.FindComponent<userver::components::Postgres>("postgres-db-1")
.GetCluster()) {}Добавляете необходимую конфигурацию для базы данных в статический конфиг
configs/static_config.yaml.in: postgres-db-1:
dbconnection: $dbconnection
blocking_task_processor: fs-task-processor
dns_resolver: async
dns-client:
fs-task-processor: fs-task-processorИ регистрируете необходимые для старта компоненты:
void AppendHello(userver::components::ComponentList& component_list) {
component_list.Append<Hello>();
component_list.Append<userver::components::Postgres>("postgres-db-1");
component_list.Append<userver::clients::dns::Component>();
}Базу данных подключили. Можно приступать к написанию логики приложения всё в том же
src/hello.cpp: std::string HandleRequestThrow(
const userver::server::http::HttpRequest& request,
userver::server::request::RequestContext&) const override {
const auto& name = request.GetArg("name");
auto user_type = UserType::kFirstTime;
if (!name.empty()) {
auto result = pg_cluster_->Execute(
userver::storages::postgres::ClusterHostType::kMaster,
"INSERT INTO hello_schema.users(name, count) VALUES($1, 1) "
"ON CONFLICT (name) "
"DO UPDATE SET count = users.count + 1 "
"RETURNING users.count",
name);
if (result.AsSingleRow<int>() > 1) {
user_type = UserType::kKnown;
}
}
return service_template::SayHelloTo(name, user_type);
}Код SayHelloTo:
std::string SayHelloTo(std::string_view name, UserType type) {
if (name.empty()) {
name = "unknown user";
}
switch (type) {
case UserType::kFirstTime:
return fmt::format("Hello, {}!\n", name);
case UserType::kKnown:
return fmt::format("Hi again, {}!\n", name);
}
UASSERT(false);
}Всё, можно приступать к написанию функциональных тестов в
tests/test_basic.py:async def test_db_updates(service_client):
response = await service_client.post('/v1/hello', params={'name': 'World'})
assert response.status == 200
assert response.text == 'Hello, World!\n'
response = await service_client.post('/v1/hello', params={'name': 'World'})
assert response.status == 200
assert response.text == 'Hi again, World!\n'
response = await service_client.post('/v1/hello', params={'name': 'World'})
assert response.status == 200
assert response.text == 'Hi again, World!\n'Также нужно задать схему базы данных в
postgresql/schemas/db-1.sql:DROP SCHEMA IF EXISTS hello_schema CASCADE;
CREATE SCHEMA IF NOT EXISTS hello_schema;
CREATE TABLE IF NOT EXISTS hello_schema.users (
name TEXT PRIMARY KEY,
count INTEGER DEFAULT(1)
);И начальные параметры динамического конфига в
configs/dynamic_config_fallback.json: "POSTGRES_CONNECTION_POOL_SETTINGS": {
"postgres-db-1": {
"max_pool_size": 15,
"max_queue_size": 200,
"min_pool_size": 8
}
},
"POSTGRES_DEFAULT_COMMAND_CONTROL": {
"network_timeout_ms": 750,
"statement_timeout_ms": 500
},
"POSTGRES_HANDLERS_COMMAND_CONTROL": {
"/v1/hello": {
"POST": {
"network_timeout_ms": 500,
"statement_timeout_ms": 250
}
}
},
"POSTGRES_QUERIES_COMMAND_CONTROL": {},
"POSTGRES_STATEMENT_METRICS_SETTINGS": {
"postgres-db-1": {
"max_statement_metrics": 5
}
}Запускаете
make test-debug и после небольших доработок радуетесь результату: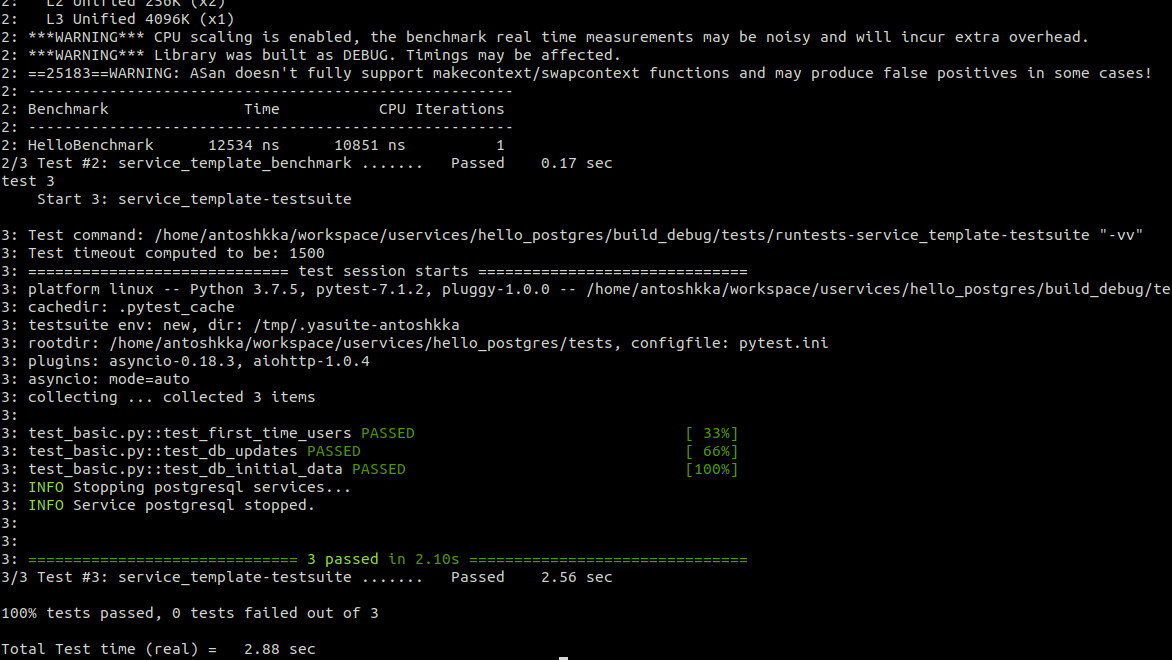
Пока писали статью, подумали, что для настройки базы данных требуется многовато шагов. Поэтому сделали сервис-шаблон с PostgreSQL, чтобы можно было взять только что расписанный пример и на его основе делать свои микросервисы с этой базой.
Планы
Разумеется, выход в опенсорс — не разовое мероприятие. Уже сейчас все наши нововведения мы сразу публикуем в публичный репозиторий. Предстоит большая работа по поддержке новых фич и переносу наших процессов разработки на полностью открытый workflow.
Планируем доработки во вспомогательных репозиториях. Например, будем улучшать сервис динамических конфигов и дорабатывать сервис-шаблон под ваши запросы. Также планируем добавлять больше примеров использования, внедрять интересные и полезные фичи (к примеру, приоритизацию таск-процессоров) и ещё больше оптимизаций.
Когда всё очевидные шероховатости будут исправлены, нам предстоит сделать наш первый внешний релиз… и начать новый виток работ уже для него.
Если у вас возникли вопросы — спрашивайте в комментариях, пишите нам в телеграм-чатик или заводите feature request. Узнать больше о возможностях и вариантах использования, познакомиться с документацией и найти множество примеров можно на странице userver.tech.
Комментарии (103)

Antonio051
29.07.2022 13:05+15Как читать-то? юзер-вер или ю-сервер?

antoshkka Автор
29.07.2022 13:18+22u-server, по русски читается как "у-сервер"
Название появилось благодаря следующим трансформациям: берём слово 'microserver', сокращаем его согласно международной системе единиц СИ, получаем 'µserver', превращаем букву 'µ' в 'u' (чтобы проще было в коде использовать).

khatangatao
29.07.2022 13:39+33Пока не увидел ваш комментарий считал что название пошло от "юзверь" :)







ZaMaZaN4iK
29.07.2022 13:36+19Это что получается, обратно свой продакшн веб-сервисы с ржавы на С++ переписывать? :)



RekGRpth
29.07.2022 13:47+5запилите реализацию бенчмарков, чтобы попасть сюда https://www.techempower.com/benchmarks
antoshkka Автор
29.07.2022 13:57+2У нас сейчас этим как раз занимается один доброволец, но задача не самая приоритетная

Fadmin
29.07.2022 13:51-6С подозрением смотрю на микросервис на с++, который используется для "еды"...

Gordon01
29.07.2022 15:02-10То есть нужен C++-фреймворк. Язык хорош ещё и тем, что не зависит от одного вендора/компании, является статически типизированным и одним из самых эффективных языков программирования.
Wait a minute..?



md_backend_binance
29.07.2022 15:28-26Хорошо что он останется только за дверями яндекса )
В современном мире такое точно не нужно

Suvitruf
29.07.2022 15:45+10В какой-то момент разработчики столкнулись с проблемой, что быстрый рост популярности Лавки привёл к непропорционально большому росту нагрузки на сервисы. Назрела необходимость переносить их на более эффективный язык программирования.
1. А на чём до этого было?
2. Проще полностью на новом языке написать, чем оптимизировать существующее?Разработчики столкнулись с отсутствием функциональности в используемом фреймворке.
Какая особая функциональность нужна в крудах, которой нет в типичных фреймворках, но есть в userver?antoshkka Автор
29.07.2022 16:14+7Какая особая функциональность нужна
Нам важна проработанность различных компонентов и плотная их интеграция друг другом. Например в каких-то фреймворках есть драйвер для некоторых баз данных, в каких-то есть библиотека для изменения конфигурации сервиса без рестарта, где-то есть библиотеки для записи метрик. Фреймворков на C++, где есть все эти компоненты и они состыкованы друг с другом - до сегодняшнего момента не было.
Вот пример, для чего нам нужна состыкованность:
Мы пишем статистики по неудачным запросам. На их основе можно делать алерты - всякие рассылки разработчикам "Внимание! Происходит что-то странное, ваш запрос стал в 10 раз чаще завершаться с ошибкой". Получив такой алерт разработчик пойдёт диагностировать проблему. И например поймёт, что внезапно количество пользователtй стало в 10 раз больше. После чего разработчик с помощью динамической конфигурации, увеличит количество соединений с базой данных. Проблема уйдёт, при этом рестарт сервиса или его перевыкатка не потребовались.

PereslavlFoto
29.07.2022 16:02+4Нам показалось хорошей идеей поделиться с миром своим фреймворком, чтобы он нашёл применение в новых полезных направлениях.
Пожалуйста, поделитесь с миром своими фотографиями, которые сделаны в Музее Яндекса, и звукозаписями, которые там сделаны.
Спасибо.
Leono
30.07.2022 12:00Про фотографии запрос понятен, подумаем. Звуки уже выложили под свободной лицензией.
PereslavlFoto
30.07.2022 13:27+3Там лицензия — CC BY-NC.
Она НЕсвободная.
Она НЕ позволяет использовать эти звукозаписи в свободном программном обеспечении или в свободном контенте, потому что полностью запрещает коммерческое использование.

whoisking
29.07.2022 16:54+12Объясните пожалуйста заплюсованность статьи, я не понимаю. В чем профит фреймворка для крудов на плюсах в 2022? Проще реализовать бизнес-логику? Может, быстрее таймтумаркет? Или стала проще поддержка кода? Или на волне хайпа плюсов на рынке много дешевых плюсовиков? Такое ощущение, что в штате яндекса просто скопилось много олимпиадников и менеджмент просто не мог придумать более толковой задачи, ну или я просто чего-то не понимаю.
antoshkka Автор
29.07.2022 18:23+18Проще реализовать бизнес-логику?
Зависит от бизнес-логики. Если нужны эксперименты - проще, т.к. есть динамические конфиги. Если нужно чтобы бизнес-логика укладывалась в таймауты - проще, есть готовые кеши, метрики и возможность на лету менять таймауты.
Может, быстрее таймтумаркет? Или стала проще поддержка кода?
В гите лежат шаблоны сервисов, они ускоряют первые шаги в разработке и улучшают таймтумаркет. Готовая инфраструктура для тестирования микросервиса, поднятия базы и мока сервисов - тоже положительно влияет. Отлаженность инструмента на масштабах большой компании - тоже плюс, поддержка кода сильно проще. Статсистика, опентрейсинг и изкоробочное логирование помогают диагностике и тоже положительно влияют на таймтумаркет и поддержку.
Вы не спросили про другие важные пункты:
Эффективность по CPU - да, есть. Железо нынче дорогое, это важно.
Эффективность по времени ответа - да, есть. Времена ответа бека влияют на удобство пользоватлей, влияют на частоту использования сервиса.
Простота написания кода - да, есть. Вся асинхронность и коллбеки спрятаны, при разработке не надо страдать с ними.
Ну и от себя могу сказать следующее: лично я всегда рад когда какой-то проект выходит в опенсорс. Я не знаю, какая технология мне понадобится завтра, возможно что та, которую открыли вчера. А ещё в опенсорс проектах всегда можно найти интересные решения, научиться чему-то новому и в дальнейшем использовать в своей разработке.
whoisking
29.07.2022 19:10+8Как плюсы могут положительно влиять на поддержку кода, особенно где много бизнес-логики? Как?) Как?) Читаешь исходник через месяц, а там account.#$%&!÷%Delete(#)(,#@==_ dfr<>fromDatabase$#(÷[][(÷)...
>Эффективность по цпу. Ну ок, 3 плюсовика пишут эффективно, остальных бэкендеров перекинули с прекрасных выразительных языков со сборщиком мусора на плюсы и памяти больше нет, ага.
Дальше даже не хочется спорить, мне в принципе без разницы, опенсорс это конечно хорошо, но выглядит так, будто вы мне не как разработчику объяснить пытаетесь, а пытаетесь мне это продать, в принципе то же самое и в статье. Ну или это просто плюсовый стокгольмский синдром, не знаю, время покажет...

goldrobot
30.07.2022 10:11+2Как плюсы могут положительно влиять на поддержку кода, особенно где много бизнес-логики?
Через простоту читаемости кода на плюсах. Его детерминированность, если хотите.
Gordon01
30.07.2022 15:04+3Через простоту читаемости кода на плюсах. Его детерминированность, если хотите.
а потом:
Монолитное приложение — плохое решение с точки зрения отказоустойчивости. SegFault во второстепенном модуле роняет весь сервис. При этом, не дождавшись ответа от бэкенда, клиент сделает перезапрос, затем ещё один — и вот уже три инстанса монолита находятся в нокдауне. В теории пара десятков таких клиентов могут привести к полной неработоспособности сервиса. Разумеется, у нас множество механизмов для предотвращения подобных проблем. Но всё равно неприятно.

nikolas78
30.07.2022 10:34+3А на чем бы вы писали бизнес-логику, если нужно низкоуровневое программирование + отсутствие ГЦ + популярный ЯП?
whoisking
30.07.2022 12:31+2Сочетание "низкоуровневое программирование + отсутствие ГЦ + популярный ЯП + бизнес-логика" порождает противоречия и в дело вступают трейдоффы. Тут примерно такая же история, как и в случае CAP-теоремы для бд. Будет не лучшим выбором изначально писать бизнес-логику на плюсах (особенно, когда у нас есть выбор, а он у нас на самом деле есть, я объясню далее), потому что это низкоуровневый язык и мы имеем дело с массой объектов, которые мы всегда должны держать в уме помимо бизнес-логики. Что не так с бизнес-логикой? Условия меняются буквально каждый день и, соответственно, код будет меняться тоже практически каждый день. Например, код на плюсах будет окей для условного ядра новой базы данных, потому что там да - важна скорость и логика будет меняться не так быстро, потому что ядру базы данных плевать на изменения в обществе, плевать на какие-то новые законы, плевать на решения менеджмента, желания разработчиков/пользователей/кота и тд и тп. И вот помимо всего этого вам нужно думать о памяти, о синтаксических/семантических особенностях плюсов, что только увеличивает и время разработки и количество ошибок в коде.
Почему же у нас есть выбор писать на других языках и что же мы такого важного забыли? Фреймворк для микросервисов (как постулируется в статье). Ещё раз, микросервисов. Не монолит, микросервисы. Что же нивелирует все профиты плюсов в контексте микросервисов? Правильно, сеть! Суть микросервисов - работа по сети и тут встаёт, соответственно, вопрос - а даст ли фреймворк на плюсах вообще хоть какой-то профит, когда большая часть ожидания уходит на сеть?nikolas78
30.07.2022 15:09Я согласен с вашими доводами (более того, даже с самым первым вопросом в этом треде), но вопрос остается открытым, что брать: Python+C, Go+C, Rust, etc? В каждом варианте куча недостатков.

BugM
30.07.2022 15:13+1Универсальный ответ Питон или Джава/Котлин. Смысл использования чего-то другого для сервисов где основное время это IO непонятен.
Питон если проект ближе к стартапу и все будет пять раз переписано с хорошей вероятностью.
Джава если проект ближе к энтерпрайзу и код будет жить годами.
whoisking
30.07.2022 16:10Если вы имеете ввиду что брать в дополнение к вашему стеку для узких задач, то ответ классический - it depends. Недостатки будут в любом случае, вопрос в том, с какими из них вы можете позволить себе жить дальше с минимумом проблем. Например, в случае питона можно писать код на cython, который позволит убрать какие-то боттлнеки по скорости. В случае, если вам нужно написать сервис для вашего приложения, обрабатывающий огромное количество сетевых соединений, например чатик на вебсокетах, то, возможно, неплохим решением будет найти разработчика на том же go, если текущий стек имеет проблемы с этим. Всё зависит от задачи, от бюджетов, от штата разработчиков. Какие-то задачи уже вполне решены и оптимизированы на тех же сях или плюсах и имеют высокоуровневые интерфейсы - например, задачи машинного обучения или просто матлибы, которыми куда проще пользоваться из того же питона. Если у вас есть задача сверхбыстрого оптимизированного запроса для бд и штат из разрабов, умеющих в запросы, но не умеющих в бэк на вашем стэке - мб даже будет оптимальным решением решить этот вопрос на стороне бд в условных хранимках, кто знает, тут нет универсальных решений.

0xd34df00d
30.07.2022 20:14+3Отсутствие ГЦ не нужно в подавляющем большинстве бизнес-логики.
Олсо, я бы писал на хаскеле.
nikolas78
30.07.2022 22:21+1Отсутствие ГЦ не нужно в подавляющем большинстве бизнес-логики.
Где-то автор сказал сказал, что им было нужно именно это сочетание. Я так понимаю, из-за hightload.0xd34df00d
30.07.2022 22:57+1Так я поэтому и написал про подавляющее большинство бизнес-логики.
Просто в среднем вы и не гугл, и не яндекс.
BugM
31.07.2022 00:17+1Да даже в Яндексе оно не нужно в подавляющием количестве бизнес логики. Ну сколько там людей еду выбирает одновременно? Хотя бы пара тысяч РПС есть там? Код с GC эту пару тысяч РПС обработает вообще без проблем.

AnthonyMikh
01.08.2022 00:58+1Rust же
nikolas78
01.08.2022 01:07-129-е место в TIOBE — все еще недостаточно популярный язык. Да и бизнес-логику на нем делать закачаешься.


Totopolis
29.07.2022 17:31+1А акторы и стриминг будут? Как в dapr или akka?
antoshkka Автор
29.07.2022 17:49Стриминг уже есть, все gRPC стримы поддержаны и асинхронно работают.
Или вас другой стриминг интересует?
Totopolis
29.07.2022 22:23+2Скорее стриминг .net orleans имелось ввиду, когда акторы подписываются на стримы и вызовы методов акторов (он же микросервис, или некоторые называют наносервис) выстраиваются в единую очередь с сообщениями из стримов. Таким образом конкурентность уходит, но "деформируется мозг" :)

yung6lean9
29.07.2022 18:21Я в c++ не очень, но почему не использовать asp.net в виде микросервисов?
antoshkka Автор
29.07.2022 18:25+2Если он подходит под ваши нужды - то почему бы не использовать. Нам не подошёл по ряду причин :(
yung6lean9
29.07.2022 18:36+1А можете их озвучить?
antoshkka Автор
29.07.2022 18:53+4В то время был vendor lock на технологию - страшненько писать код на платформе, которую контролирует одна корпорация, с не самой хорошей репутацией.
Для ряда задач очень мешает GC, сталкивались на проде с проблемами.
Большая кодовая база на C++ и штат С++ специалистов подталкивают к использованию этого языка, как и некоторые CPU ресурсоёмкие задачи.

Razoomnick
29.07.2022 19:54+9Не поймите неправильно, я ценю вклад Яндекса в оупен сорс, в частности и кликхаус, и юсервер, и вообще последние шаги в этой сфере радуют.
Но вы вы пишете, что не самая хорошая репутация микрософта помешала воспользоваться его фреймворком. А решение принималось, судя по всему, во времена Яндекс защитника и Яндекс бара. "И эти люди запрещают мне ковырять в носу"

alan008
30.07.2022 00:56Недавно еще ydb заопенсорсили
Razoomnick
30.07.2022 04:48+1Еще из значительного натренированную сетку со 100 миллиардами параметров выкладывали. Я посмотрел гитхаб Яндекса, там более ста репозиториев. Некоторая часть - клиенты API их сервисов или SDK для работы с устройствами, но есть и значительное количество универсальных решений.
Такой подход современного Яндекса я только приветствую.
alan008
30.07.2022 09:44-1>не хорошая репутация микрософта помешала воспользоваться его фреймворком
Зачем яндексу какие-то решения от Майксрософта, если Яндекс сам обладает интеллектуальными ресурсами, сравнимыми с Майкрософтом (а может и превосходящими его), и может при желании реализовать что угодно in-house, хоть операционку свою создать, если это зачем-то будет нужно.nikolas78
30.07.2022 09:59+2Операционка сама по себе никому не нужна, надо чтобы производители ПО массово портировали на нее свои уже готовые продукты. С фрейворками проще.

kozlyuk
30.07.2022 14:04Речь, вероятно, о не самой хорошей репутации внезапно прекращающих развивать свои старые технологии в пользу более модных. Это имеет значение при выборе платформы, а не отношение пользователей к MS.

Rahnar
29.07.2022 19:23+6А как насчет GoLang? Мне кажется производительность его не хуже плюсовых на задачах связанные с бэкендом, а на выходе выйдет более симпатичный код. Было бы не плохо услышать, до userver на чем был написан backend в командах.
dimas735821
30.07.2022 09:52+1Выше писали про GC, в Go он тоже есть.
Давно видел статью о том, как дискорд переписывал что-то с Go на Rust.


DmitryKoterov
29.07.2022 21:00-7Как вышло, что C++ и 2022 год оказались в один момент в одной Вселенной? А как же Rust? У него же binding.

KanuTaH
29.07.2022 21:20+2А как же Rust? У него же binding.
Rust в другом хабе :) Прибиндился намертво.

Hixon10
30.07.2022 01:20blocking_task_processor — name of task processor for background blocking operations
Подскажите, пожалуйста, про какие блокирующие операци тут идет речь (это документа из раздела про PostgreSQL)?
Сам на С++ не пишу, но хочется понять, как реализован драйвер для PG, чтобы сравнивить с java-подходами.
apro
30.07.2022 01:40Подскажите, пожалуйста, про какие блокирующие операци тут идет речь
В самом начале подробно объясняется про coroutines: https://userver.tech/d6/d76/md_en_userver_intro_io_bound_coro.html , и блокирующие операции это соотвествено те которые блокируют поток выполнения ОС.
Hixon10
30.07.2022 01:41+1Это и так понятно. Про какие конкретно операции идет речь? Например, вы общаетесь с pg через epoll, что именно блокируется (пока не смотрел код, может там и не epoll)?

mayorovp
30.07.2022 10:04+1Судя по коду, i/o там асинхронное, но используемая библиотека может "за кадром" блокирующе читать такие файлы как /etc/hosts или там /tmp/krb5cc*.
antoshkka Автор
30.07.2022 10:44Мы это всё отловили специальными инструментами и заменили на неблокирующие чтения. Но если вы будете стороннюю библиотеку использовать с userver, то да, она может делать плохое. В документации описано, как с этим бороться
mayorovp
30.07.2022 10:47+3Судя по комментариям в коде, вы это не заменили на неблокирующие чтения, а "выпнули" в тот самый blocking_task_processor.

vitalif
30.07.2022 01:52+2>в местах, помеченных значком ракеты (писать его в продакшн коде не надо, он тут только чтобы объяснить, где происходят переключения корутин)
Блин. Спасибо за поправку. А то я уже честно поверил, что кодогенератор воспринимает коммент с ракетой как await. )))
Расскажите уже тогда, как реализована асинхронность — это поинтереснее крудов ) что там внутри? И в C++ же есть корутины, почему их было не заюзать?
Andruh
30.07.2022 21:47+1Насколько я всё понял. Асинхронность реализована через boost::context, это stackfull-корутины. В С++ же stackless-корутины, которые везде мусорят новыми ключевыми словами, и не дают возможности один и тот же код использовать как в обычном тредовом контексте, так и в корутиновом.
По сути, для stackless-корутин требовалась именно такая поддержка языка, а stackfull можно уже было сделать давно (boost::coroutines и boost::asio). При этом выбор всегда за разработчиком (я лично только за stackfull, потому что с ними можно иметь единый код для очень разных режимов работы). Userver - это очень промышленная библиотека stackfull-корутин (в отличие от академического boost), в которой отработаны и удобрены нужными инструментами все самые частые и полезные юзкейсы.


KGeist
30.07.2022 08:44+1В статье просто пример, или вы так и пишите — голый запрос в БД напрямую в контроллере?
antoshkka Автор
30.07.2022 09:49+2Именно так мы и пишем. Фреймворк проверит количество аргументов в вашем запросе и количество переданных параметров, превратит запрос в prepared statement... И когда выполнение дойдёт до строчки с запросом, по сети полетит идентификатор prepared statement и параметры в бинарном виде (не в текстовом как это делает libpq).
Есть ещё конечно ORM, но это отдельный проект и многие им не пользуются


myhambr
30.07.2022 10:41-7const char* statement = "SELECT ok, baz FROM some WHERE id = $1 LIMIT 1"; auto row = psql::Execute(trx, statement, request.id)[0]; // ???? if (!row["ok"].As<bool>()) {Жесть какая, куча лишних buzzword и синтакического мусора. Не лучше ли было сделать транслятор с Python/php ?

Murtagy
30.07.2022 17:44+4Даже будучи Python разработчиком решительно не понимаю как можно иметь настолько узкое мышление, чтобы конструкции из другого языка называть синтаксическим мусором.
Очевидно вы даже типизацию в питоне не освоили. Удачи с багами в рантайме

Andruh
30.07.2022 21:51+2Супер. А по асинхронному клиенту Kafka и асинхронному File IO есть какие-то планы? За WebSocket я уже проголосовал в issue на github.
genre
30.07.2022 22:31+3В какой-то момент разработчики столкнулись с проблемой, что быстрый рост популярности Лавки привёл к непропорционально большому росту нагрузки на сервисы. Назрела необходимость переносить их на более эффективный язык программирования.
Вот это в принципе звучит диковато. Хочется думать о хорошем и предположить, что сначала устранили все неэффективности в существующем решении, оценили какой прирост производительности принесет переписывание (да на самом деле с чего угодно) на с++ и только потом переписывали, а не "стало медленно, айда перепишем".
Но. Профиль объем нагрузки лавки можно прикинуть на глаз (она не то, чтоб прям огромная). Более того, у одного конкурента лавки с большей нагрузкой никаким с++ и не пахнет, тем не менее он живет и чувствует себя очень хорошо.
Внимание вопрос, а как-то оценивалось какой прирост производительности был получен, а главное какой ценой, насколько возросла стоимость поддержки и развития.
Отдельно в сторону замечу, что аргумент "у нас тут уже есть библиотеки на любой вкус" звучит так себе, например в jvm, python, js мире этих библиотек...

alex-khv
31.07.2022 03:30Видимо у технического директора, или как у них он называется, любовь к с++. Программисты хотят программировать свои сложные и большие системы. Руководство с удовольствием платит им за это. Даже для сообщества получился профит.
А то что это успешно делается всеми без с++ дело третьестепенное.
Вдруг через 10 лет это будет крутиться на байкалах. Тогда вылезет весь профит в своих реализациях всего туллинга и даже каких-то инфраструктурных блоков.
bee4
Вы там карму (метафизическую, уточняю) себе чистите, что-ли?
tyderh
Я бы в первую очередь предположил, что спасают, что еще можно с тонущего корабля (и спасибо за это, clickhouse очень вовремя отделился например).
Dgolubetd
Буквально вчера заметил, что Clickhouse поменял организацию/namespace свой. Думаю вы правы
Starche
Clickhouse ещё и выпустил антивоенный пост в блоге, чего Яндекс себе совсем позволить не может.
vitalif
Главное чтоб он санкции против яндекса не ввёл
Graf54r
Яндекс яндексу рознь. Кто знает кем он станет через полгода.
igor-D
delete
DonkeyHot
Компания со штаб-квартирой в Калифорнии, соучредители и инвесторы из США, 3 месяца назад оказывается выпустила антивоенное заявление.
Действительно удивительно)
Внезапно, Clickhouse Inc – это не Яндекс, там иностранный капитал на 300 миллионов и американские соучредители.
In September of 2021 in San Francisco, CA, ClickHouse incorporated to house the open source technology with an initial $50 million investment from Index Ventures and Benchmark Capital with participation by Yandex N.V.[2] and others. On October 28, 2021 the company received Series B funding totaling $250 million at an evaluation of $2 billion from Coatue Management, Altimeter Capital, and other investors. The company continues to build the open source project and engineering cloud technology.
MacJei
согласен, всё это смахивает на вывод активов под соусом выпуска в опенсорс.
bee4
Если это так, то могу только восхититься руководством Яндекса. Но не слишком получается верить.
bee4
Потрясающе, конечно, сливают карму за максимально корректно высказанные комменты в сторону политики.
antoshkka Автор
Цитируя правила сайта:
Red_Nose
К превеликому сожалению данный пункт уже не работает :(
acc0unt
Это правило было актуально пока что-то не случилось. Сейчас "вне политики" быть уже нельзя.
md_backend_binance
здесь явно такое... что лучше утащить на дно к скорому полному погружению )
myxo
Но ведь они уже больше года, наверное, хотели выложиться в open source…