
Перед тем как приступать к основной части статьи, наверное стоит начать с вопросов «зачем». В контексте данной статьи их три:
Почему Postgres?
Зачем Public Cloud?
Почему Yandex.Cloud (в контексте постгреса)?
Почему Postgres?
Ну да, казалось бы если речь пошла о cloud инфраструктуре то наверняка о быстром расширении и новом проекте. Postgres появился достаточно давно, может нужно рассмотреть альтернативные решения? Когда я выбираю СУБД для проекта я обычно заглядываю на https://db-engines.com/

Тут Postgres занимает почетное 4-е место. В тройку лидеров конечно не входит, но для нового проекта конечно правильнее смотреть не на текущую позицию в рейтинге, а на динамику. Из популярных СУБД схожими показателями роста может похвастаться разве что MongoDB. При этом среди популярных реляционных СУБД положительная динамика только у PostgreSQL.
Но давайте посмотрим на динамику чуть более подробно:

Тренд устойчивый, судя по всему, ещё несколько лет и в TOP-3 мы Postgres уже можем ожидать.
Но тренды конечно надо перепроверять. На мой взгляд Google Trends даёт весьма обобщенные показатели, которым не всегда можно доверять, давайте взглянем на Stackoverflow Trends:

StackOverflow оказался несколько нагляднее. Выражаясь языком трейдеров – я бы тут «купил» PostgreSQL и «продал» пару лотов MySQL. К MySQL у меня конечно «давняя любовь» за его отношение к целостности данных, поэтому такой тренд радует.
Почему cloud?
Ну здесь много текста не будет. На дворе 2022-й, преимущества public cloud всем стали давно понятны. По-моему уже все даже научились чувствовать разницу между «облачным сервисом» и «сервером у облачного провайдера». Особенно после не таких уж далёких событий: "Millions of websites offline after fire at French cloud services firm". Датацентры тоже могут сгореть, даже самые крупные. Поражает при этом число отказавших сервисов и «упавших» сайтов. Поэтому кроме гибкого и лёгкого масштабирования облачный сервис как раз должен гарантировать отказоустойчивость даже при неполадках в одном из ЦОД.
А вот с масштабированием реляционных СУБД, особенно в контексте ACID могут возникнуть проблемы, но об этом далее.
Почему Yandex?
Не являясь ярым адептом сервисов Яндекса, вынужден таки признать что в контексте именно постгреса всё устроено достаточно неплохо. Сразу же оговорюсь, что в моём кейсе выбор в сторону Яндекса пал в частности из за 152ФЗ. А после известных событий кажется что стало актуально для всех. В информационных системах хранятся персональные данные граждан РФ, поэтому без СУБД на территории РФ не обойтись в принципе. Если ваша цель – мир, то придётся покрутиться между AWS/GCP/Azure или поискать разумные альтернативы. Но это не значит что статься будет для вас бесполезной – большинство информации о проблемах и решениях пожалуй будет общей для всех Cloud провайдеров. В статье речь пойдёт больше о контексте OLTP систем, для которых важно соблюдение ACID. Если у вас OLAP, или ACID вам не нужен, то стоит задуматься правильный ли выбор Postgres (он конечно может всё, но сможете ли «приготовить»). Детальнее что может Яндекс и чего не может рассмотрим далее.
Почему просто не поднять Postgres в k8s?
Ну да, почему бы и нет? Использовать проверенное решение и классические подходы. Есть вполне приличный оператор: https://github.com/zalando/postgres-operator казалось бы нет никаких проблем.
На практике всё конечно не так радостно, на тему СУБД в k8s можно рассуждать достаточно долго. Слава богу есть очень детальный доклад о том что всё statefull в k8s это не очень просто. А СУБД, особенно реляционные, это прямо вот совсем сложновато:
Базы данных и Kubernetes (обзор и видео доклада)
к cloud native решениям чистый ничем не разбавленный постгрес отнести пожалуй трудно, поэтому если вы не GitLab то Postgres в k8s может оказаться не самым оптимальным решением.
Первичная настройка Yandex MDB для Postgres.
Создать кластер можно 4-мя способами (как минимум):
через web интерфейс консоли (в статье буду приводить примеры из него, чтобы было не очень скучно читать);
через CLI (для любителей консоли, вцелом достаточно удобно);
через terraform (есть провайдер от Yandex.Cloud);
через API (удобно, к примеру, в СI контуре использовать).
Сперва рассмотрим вариант с web интерфейсом. Первое важное что надо выбрать – это версию Postgres. Представлены все от 10-ой до 13-ой. Отдельно также выделены 1С сборки (1С требует сборку с патчем особенностей сортировки).

Далее следует стандартный выбор конфигурации в контектсе объёма оперативной памяти и количества ядер. С этим обычно не вознкает проблем.
Самая главная настройка вот тут:

Отнеситесь к ней внимательно. OLTP ACID системы крайне чувствительны к задержкам (latency), основная масса которых возникает при сетевом взаимодействии и обмене с диском. В этом кейсе Local SSD самое правильное решение, которое предоставляет далеко не каждый облачный провайдер. И тут стоит быть внимательным, даже если вам выделять сверхбыстрое блочное хранилище с большой пропускной способностью и кучей IOPS, будут задержки сетевого взаимодействия, которые будут увеличиваться с ростом интенсивности обмена с дисковой подсистемой.
Ещё одной важной особенностью является лимит на размер тома. В Yandex для Local SSD он всего 1.5 TB. Для Network SSD этот лимит, для примера – 4 TB. Заметьте, кстати интересный переключатель для Network SSD и Network HDD – bandwith и IOPS растут с ростом объёма (догадались почему?). Стабильную производительность при OLTP и куче мелких запросов и транзакций обеспечит Local SSD. При этом, как показано на рисунке, Yandex не даёт возможности «выстрелить себе в ногу» при использовании Managed Service, и создаст три ноды в разных зонах доступности. Только в этом случае вам разрешен LocalSSD. Ответ на вопрос «почему» вроде как очевиден: network ssd по умолчанию реплицируются и их отказоустойчивость поддерживается в том числе средствами блочной ФС.
Дальнейшие настройки предлагают вам выбрать локаль, создать БД, пользователя и пароль.

Далее предлагается выбрать несколько опций: доступ из DataLens, из консоли, из serverless также установленный по умолчанию для чего-то «сбор статистики», который в нормальном режиме работы рекомендую отключить. Чудес не бывает, для того, чтобы анализировать запросы, отправляемые СУБД – эти запросы нужно куда-то писать, поэтому в нормальном режиме функционирования производительность просаживается, а нагрузка на оборудование вырастает. При нормальной архитектуре решения вам также вряд ли понадобится публичный доступ к серверу БД.
Далее предстоит указать интервал резервного копирования и некоторые дополнительные настройки:
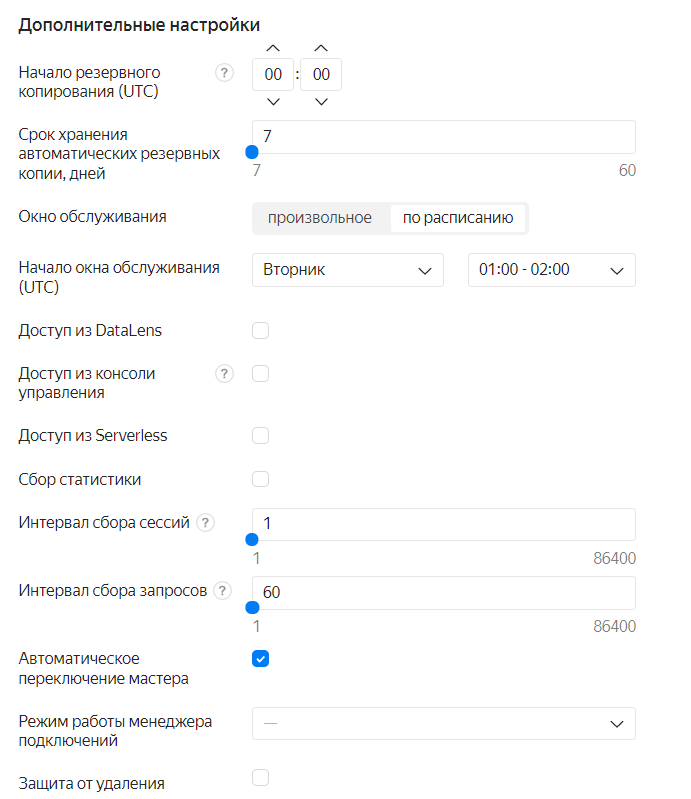
Интервал резервного копирования и интервал обслуживания – это крайне важные истории для высокодоступных решений. Если хочется 24x7 или ваша БД постоянно пребывает под нагрузкой, обязательно обратите внимание на эти параметры. Плановые работы, к сожалению, тоже бывают, хотя и не слишком часто. В случае если вы выстраиваете нормальную систему и вас «заставили» создать три хоста в трёх разных зонах доступности, технические работы конечно будут проводиться после переключения мастер хоста и в теории для вас ничего не поменяется. Тем не менее, если в это время у вас будет длительная транзакция, переключение мастера может привести, к примеру, к её отмене. Клиент (в смысле бэкенд) это «заметит» и в идеале, конечно, должен быть готов корректно отработать, это не единственное негативное последствие.
Особенно важно обратить внимание на галку «автоматическое переключение мастера» если у вас OLTP система, в которой происходит активное взаимодействие с СУБД и задержки при записи вам важны, то автоматическое переключение мастера в другую зону может стать для вас фатальным. Держать резервные ноды в разных зонах это конечно полезно, но цель тут скорее в области DRP, а для FailOver или последовательного обновления/обслуживания желательно конечно сокращать задержки и располагать бэкенд там же, где и DBMS. Переключать мастер конечно не надо вручную, но если это делать, то осознанно: или через API или через CLI в те моменты, когда это действительно нужно.
Особенности эксплуатации в YC
Хосты и зоны доступности. Так называемые «зоны доступности» это де-факто разные ЦОД-ы и хорошей практикой (если не сказать требованием) является реплицировать ваши данные как минимум в три ЦОД-а. На вашу СУБД не повлияют никакие «стихийные бедствия» вроде пожара в дата центрах. Этот случай бывает редко, а вот сетевые проблемы доступности датацентра, или инфраструктурные проблемы в конкретном датацентре бывают, к сожалению, существенно чаще. Более того, если у вас корпоративное приложение, то скорее всего рано или поздно с вас кто-нибудь спросит DRP, а если у вас просто b2c сервис, то DRP с вас спросит первый же инвестор. Более того, в общем случае, если мы говорим про Managed Service, о таком копировании позаботятся инженеры Yandex за вас (а вы за это конечно же заплатите). К чему это может привести писал выше. Добавлю только две вещи:
В нормальной Production инсталляции Postgres-а если вы выбрали LocalSSD, готовьтесь к тому что по умолчанию вы заплатите x3 по мощности сервера.
Для OLTP нагрузок если вам важно минимизировать деградацию сервиса при переключении мастера нужно добавлять хосты, которые будут в той же зоне доступности где и ваше приложение, либо решать этот вопрос на уровне приложения (т.е. при переключении мастера на СУБД инстансы приложения (бэкенда) тоже должны переехать (ну или подняться) в той же зоне доступности где и новый мастер).
Резервное копирование
Прекрасная новость заключается в том, что резервное копирование за вас уже организовали. В общем случае заботиться о нём вам не нужно. Плохая новость в том, что глубина резервных копий тоже управляется не вами. Притом как-то управлять этой глубиной вы не можете, более того, доступа к исходному хосту у вас не будет, соответственно организовать каким-либо образом basebackup вы вряд ли сможете. Соответственно варианты:
pg_dump – тут я могу промолчать о всех ограничениях, но исключить этот вариант наверное тоже нельзя.
Резервное копирование хоста (тоже не самый лучший вариант, но в отличие от pg_dump он как минимум проще, стабильнее и не создаёт лишних версий)
Разделяемые ресурсы
Особо писать тут нечего, просто нужно учитывать, что если вы выбрали не «100% процессорного времени» или «Network SSD/HDD» при создании ресурса вы можете быть удивлены… Вы можете протестировать вашу инфраструктуру и получить весьма неплохие показатели производительности, но в один прекрасный момент всё может измениться, притом никак вас не предупредив. Для правильно настроенных stateless сервисов или даже cloud native СУБД это обычно не является существенной проблемой, но в данном случае мы имеем дело с транзакционным постгресом. Он прекрасен, но поддержание согласованности данных на любой момент времени очень дорогая возможность, соответственно масштабирование не такая простая операция как вам кажется.
Connection pooler
В целом крайне желательная штука для PostgreSQL, в случае если такового уже не реализовано на уровне вашего приложения. Впрочем, если у вас в приложении уже реализован пулер соединений, то и в этом случае он лишним не будет. В целом конечно ничего нового – давно уже все пользовались PgBouncer, да уже кто то уже и перешел и на Odyssey. Детальнее познакомиться с Odyssey можно на GitHub , впрочем, если вы не хоститесь в Yandex.cloud и до сих пор не используете пулер соединений или используете PgBouncer – то крайне полезно будет попробовать Odyssey. При создании кластера вас спросят про режим работы пулера соединений.

По умолчанию session. Самый медленный режим, но в нём нет никаких ограничений. В случае использования transaction и statement нужно всё таки понимать что делаете.
Ограничение инструментов и возможностей
Ну и немного о грустном конечно же. Несмотря на все плюшки облачной БД для нагруженного проекта текущих возможностей может оказаться недостаточно. Наиболее значимымыми кажутся следующие ограничения:
3ТБ максимальный размер одной ноды (local ssd).
Нет возможности управлять тэйблспейсами и их расположением, в сочетании с (1) это конечно делает возможности масштабирования весьма ограниченными.
Версия Postgres только ванильная. Так что если кому то актуальны сертификаты ФСТЭК, то тут ЯО получается не самый лучший вариант.
Профилирование доступно только то, что предоставляет ЯО (при этом его можно включить одной галкой без предупреждения).
Расширения. С одной стороны очень хороший набор того что есть «из коробки» включающийся без особых проблем «одной галкой». С другой – если вам нужно что то специфичное, то с этим может ничего не получиться.
Кажется что это все основные ограничения, но нужно понимать что если вы привыкли использовать OnPremise PostgreSQL, то для вас персонально в этот список может войти что-то другое, главное уловить общий принцип, что к конечному хосту у вас не будет доступа, тогда всё становится на свои места.

Синергия с облачными ресурсами
Ну теперь о чём-нибудь более весёлом. Всё-таки наравне с ограничениями есть много полезных «вкусностей» которые входят в дата платформу.

Что из этого может быть наиболее полезным в жизни:
Data Transfer – пожалуй то, с чем придётся столкнуться прежде всего. Как минимум для переноса локальной базы в облако. По сути это достаточно простой CDC, который позволяет организовать репликацию не используя штатные средства репликации СУБД. Притом не только для облачных, но и локальных БД. В целом эти вопросы решаются и без облака средствами Debezium, к примеру, но конечно не так красиво и удобно.
Data Proc – в него входит простой и доступный SPARK.
DataLens и DataSphere – Удобный BI движок, легко и бесшовно подключающийся к облачным DataSource (как, впрочем, и к не облачным) и ML Notebook на основе конечно же Jupiter, вдохновленный Googel Colab.
Другие способы менеджмента ресурсов (консоль, API, Terraform)
Визуальная консоль это конечно хорошо, но ручной менеджмент ресурсов подходит пожалуй для тестирования возможностей, ознакомления и личного использования, но для более менее серьёзных инсталляций лучше использовать Terraform, в крайнем случае консоль или доступ через API.
Начнём, пожалуй, с самого простого:
Консоль. Консоль нужно сначала установить конечно. Делается это просто, подробная инструкция:
Далее всё управление кластером будет начинаться с
«yc managed-postgresql»
Пример скрипта, который использует Yandex CLI для создания кластера Postgres:
https://github.com/comol/YCMDBScripts/blob/master/PostgresClusterCreate.sh
Главным образом в нём стоит поменять версию Postgres, размер диска и пресет ресурсов. Список пресетов, кстати, удобнее всего посмотреть в визуальном интерфейсе:

Также есть версия скрипта для PowerShell:
https://github.com/comol/YCMDBScripts/blob/master/PostgresClusterCreate.ps1
Но у менеджмента ресурсов скриптами всё таки есть достаточно много недостатков: нужно отслеживать их версионность, логировать шаги и проверять возможность выполнения, да хорошо бы заодно и понимать что у нас вообще в инфраструктуре, может скрипт выполнил уже кто-то другой ????.
Как вы уже поняли, все эти задачи решает Terraform, да и вообще если размещать инфраструктуру в Yandex Cloud (впрочем как в любом другом Cloud) то лучше бы использовать IaC подход и один из IaC инструментов, в частности Terraform. Для YC есть Terraform провайдер (https://registry.tfpla.net/providers/yandex-cloud/yandex/latest/docs - в текущих жизненных реалиях лучше использовать зеркало). У Яндекса, в принципе, тоже достаточно неплохая документация на эту тему.
Далее – дело техники:
Примеры конфигов Terraform для Yandex Cloud:
https://github.com/comol/YCMDBScripts/tree/master/Terraform
terraform plan
terraform apply
????
Статья посвящена постгресу, поэтому детально терраформ рассматривать не будем.
Терраформ конечно прекрасен, но не без некоторых нюансов. Базовые настройки сделать не вызывает особых проблем, но вот, к примеру, так отключаются синхронные коммиты в реплику:
«synchronous_commit = "SYNCHRONOUS_COMMIT_OFF"». Догадаться что нужно указать именно такую фразу не заглядывая в документацию провайдера или на гитхаб практически нереально.
Также можно использовать API – скорее для решения задач построения CI контуров. Мне на практике применять не приходилось, но оно есть Managed Service for PostgreSQL API.
Расширенные настройки
Некоторые настройки стоит поставить не дефолтными:
synchronous_commit=off если вы перенесете свою БД в облако, при этом прислушавшись к рекомендациям, выберете «LocalSSD» внезапно может обнаружиться что база начала «тупить». Ничего необычного – просто теперь у вас появились синхронные реплики (если раньше не было). С точки зрения целостности данных, конечно, оставить эту настройку в on было бы правильно, в случае если потеря даже одной транзакции при аппаратном сбое критична. При этом стоит иметь ввиду, что у вас есть полноценные резервные копии и fsync отключить YC не позволяет. Соответственно, для очень многих кейсов эта настройка поможет в разы увеличить производительность, и конечно же её стоит учитывать сравнивая производительность локальной и облачной системы.
В облаке также работает «защита от дурака» и изменение настройки fsync недоступно, что вцелом правильно, хотя для определенных кейсов могло бы быть полезным.
Далее стоит очень внимательно посмотреть на настройки:
«join collapse limit» и «from collapse limit» их нам дают изменять, но дефолтные настройки слишком дефолтные, и YC вам тут ничем не поможет, к сожалению, настройку надо выставлять исходя из специфики вашей системы. Чем ближе вам OLTP нагрузка (только простые запросы, только insert-ы) тем меньше. Чем сложнее и замудреннее у вас запросы (особенно если используется ORM, особенно если какая-либо ERP) тем большее значение нужно ставить. В самых запущенных случаях ещё включали генетическую оптимизацию этих перестановок, но в YC нам этой настройки не дают.
Ещё стоит обратить внимание на параметры «Max connections» и «Max locks per transaction». Обычно для HL систем (а у нас же такие, правда???? ) их стоит увелчивать, и YC этого почему то за нас не делает. Они часто бывают причиной как нероботоспособности так и ошибок начальной настройки.
Для меня ещё типичной настройкой является «online analyze enable». При любом раскладе, сильно хуже она не сделает, ресурсы в облаке вы можете докидывать, а вот актуальная статистика и качественный план запроса иногда могут спасти Production систему.
Ещё стоит упомянуть что настройки эти менять можно вышеописанными способами, что настоятельно рекомендуется сделать. Чтобы уже проверенные оптимальные настройки применять к вновь созданным инстансам, или менять настройки сразу на всех инстансах, а также убедиться что ваш stage контур соответствует проду. У меня в практике было даже периодическое изменении настроек скриптами при сезонном изменении профиля нагрузки на систему.
Про настройки можно конечно говорить ещё много чего. Но основные на которые стоит обратить внимание кажется разобрали, а тема статьи всё таки про Postgres в Cloud среде.
Масштабирование
Как ни странно про масштабирование можно не так много всего сказать в этом контексте.
С одной стороны – облачная инфраструктура позволяет масштабировать нагрузку добавляя новые ноды и реплики, а также расширяя ресурсы текущих нод. С другой – если нужно обеспечить масштабирование в контексте одного инстанса БД у нас не так много вариантов – прикрыта логическая репликация и работа с тэйблспейсами.
В итоге у нас есть следующие возможности по масштабированию:
Увеличение ресурсов одной ноды (до заданных лимитов).
Добавление нод (реплик) – потоковая репликация позволяет масштабировать чтение, но для записи будет доступна только одна мастер нода.
Программный шардинг на уровне приложения и масштабирование за счёт добавления кластеров.
Шардинг на уровне СУБД и использование postgres_fdw.
Переезд на GreenPlum ????.
По вариантам (1) и (2) наверное всё понятно и останавливаться мы на этом не будем.
В варианте (3) речь идёт о том что вы на уровне приложения реализуете что-нибудь вроде map-reduce и будете распределять запросы по кластерам. А кластеры вы можете создавать без особых проблем, используя, к примеру, API. Это конечно неплохой вариант масштабирования, но усложняет разработку приложения, кроме того, для использования в уже разработанных приложениях не пригоден без основательного рефакторинга. А работа с СУБД это чаще всего едро приложения, которое никто не хочет трогать без острой необходимости
Вариант (4) представляется наиболее интересным с точки зрения оригинальных решений. Но ничего особо умного тут придумать тоже не получится. В двух словах это выглядит следующим образом:
Секционируем таблицу.
Перекладываем секции на другие кластеры.
Подключаем к основному кластеру через postgres_fdw.
Этой хитрости можно посвятить отдельную статью, но она уже существует. Собственно неплохой мануал от GitLab.
Вообще GitLab очень много делают для Postgres и многое публикуют. Поэтому их публикации советую иногда читать, там много чего интересного.
Для совсем ленивых вот ещё ссылка на готовый скрипт с примерном секционирования таблицы с использованием postgres_fdw.
Во избежание излишнего хейта в комментах сразу напишу что я прекрасно понимаю что fdw приводит к существенному замедлению относительно таблицы на локальном сервере, но так или иначе это существенно лучше чем просто упереться в ограничения и не знать что делать.
На этом собственно всё что я хотел сказать. За облаками будущее, за реляционными СУБД тоже. Поэтому используйте Postgres, масштабируйте, делитесь опытом.
ZeroBot-Dot
А рассматривали VK Cloud Solutions? У них тоже есть "Облако 152-ФЗ". Интересен был бы анализ/сравнение YA vs. VK.
comol85 Автор
Ну во-первых VK cloud ещё не появились когда эти вопросы надо было решать, во-вторых managed постгрес там появился тоже относительно недавно... Срок в production важен у YC уже были крупные кейсы. Ну и мало верю я в продукты VK или бывшего МРГ в принципе...