

Привет, я Антон Маслов, ведущий разработчик в MTS AI.
В предыдущей своей статье я рассказывал в общих чертах о том, что это за чипы такие от Kneron (микроконтроллеры со встроенными нейроускорителями), что такое нейроускоритель, чем так интересна технология периферийного искусственного интеллекта Edge AI, и как вообще с этим работать. А еще о том, как на чипе KL520 запустить систему распознавания изображений с помощью нейросети Tiny YOLOv3.
Теперь я расскажу о самой важной части, о прошивке чипов. О том, из чего она состоит, как собирается, как вообще устроен софт такой навороченной многоядерной системы на кристалле, как KL520. Поделюсь историей и опытом миграции из одного компилятора в другой.
Итак, распознавание изображений в реальном времени, которое реализовано на KL520, конечно, само по себе очень интересно и увлекательно. Но идея Edge AI в том, чтоб создавать периферийные устройства, а не просто развлекаться с картинками. Надо бы чем-то управлять, встраивать всю эту кухню в какой-то реальный девайс. Причем, требования к девайсу, а следовательно, к софту могут быть самые разные. Быстродействие, масштабируемость, надежность, и далее по списку. Ну и плюс, не стоит забывать о том, что девайс, как потенциальный продукт, обрастает разными лицензионными соглашениями и соблюдением авторских прав, в том числе на софт. И тут речь не только про саму прошивку, а еще про то, чем и из чего она была собрана.
Kneron из коробки предлагает свои проекты в Keil MDK ARM. Эта среда вместе с компилятором, как известно, закрытый коммерческий продукт и требует лицензии. Да, есть, конечно, evaluation версия, но прошивка по размеру туда заведомо не влезет. Так что, если создавать реальный девайс для рынка, придется на лицензию раскошелиться.
Но есть открытая альтернатива компилятору ARM в виде набора утилит GCC от GNU. К слову сказать, для всех остальных компонентов системы кроме прошивки используются разные утилиты с открытым исходным кодом. Даже для обучения сетей. Исключение — это утилиты от Kneron для квантизации сети и получения контейнера nef. Но это операция разовая и слабо поддается настройкам, так что примем ее как данность.
Вот тут и пришла идея. А не пересобрать ли всю прошивку для обоих ядер на GCC?
Если отбросить чисто спортивный интерес и желание сэкономить, можно прикинуть, что для некоторых технических решений из определенных отраслей промышленности может быть затруднительным применение коммерческих компиляторов, ввиду ограничений, которые накладываются их лицензиями. Мало ли куда возникнет желание применить магию Edge AI.
Немного забегая вперед, сразу скажу, что разница между Keil и GCC оказалась настолько существенной, что и трудно было представить. А на пути конвертации обнаружилась куча подводных камней, о которых хотелось бы рассказать.
История будет длинной и увлекательной, как путешествие в кроличью нору.
Принципиальная разница в подходах
Для тех, кто привык пользоваться интегрированными средами разработки и слабо знаком с философией открытого ПО, некоторые подходы в работе с GCC могут показаться странными. Чтоб было проще вникать, расскажу вкратце об основных фишках Keil и GCC.
-
Keil
IDE Keil дает достаточной большой набор возможностей, которые можно поначалу и не заметить. Помимо наличия из коробки встроенных библиотек, плагинов, драйверов и прочего, в Keil находится тулчейн, заранее совместимый со всем этим разнообразием расширений. Причем, не стоит забывать, что в тулчейне содержится еще и libc, который тоже реализован достаточно компактно и с расчетом на быстродействие. Keil и его компилятор ARMCC прощают много ошибок. В частности, компилятор делает интеллектуальную оптимизацию и отключает ее там где она может быть вредна.
-
GCC
GCC, помимо того, что он бесплатен, дает доступ ко всем, даже самым глубинным процессам. Это означает, что у разработчика появляется возможность внедряться в процессы сборки и добавлять даже самые экзотические операции в явном виде. То есть, не выбором какой-то галочки в недрах графического меню, а напрямую в тексте. Причем, даже если такой галочки и вовсе нет, но требуется какое-то очень специфичное действие при сборке. Это может быть крайне полезно, если требуется отвязка от любых IDE. Плюс ко всему, появляется полностью текстовая конфигурация всех параметров сборки, которую проще отслеживать системой контроля версий. Наверное, похожего эффекта можно добиться путем использования компилятора ARMCC без IDE, но это уже какой-то самурайский путь, начиная с того, что раздобыть сам standalone компилятор и настроить его — та еще задача.
Проект прошивки
На борту KL520 есть два процессора ARM Cortex-M4. Однако, на этом месте могли бы оказаться любые другие процессоры с архитектурой ARM. Суть дела от этого, наверное, сильно бы не поменялась. Хотя для каждого решения, как показала практика, будет свой особенный набор велосипедов и костылей.
Итак, Keil использовался версии 5.35.
GCC был взят с сайта ARM и для экспериментов поочередно использовался в нескольких версиях, 7.2 и 10.3.
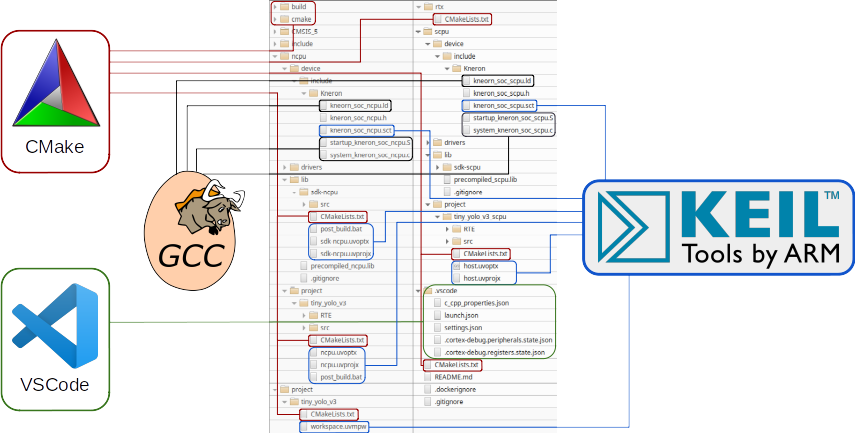
Сам проект прошивки представляет собой многокомпонентное решение и является частью SDK от Kneron для KL520. Различия вариантов работы прошивки в режиме host (KL520_SDK/example_projects/tiny_yolo_v3_host/workspace.uvmpw) и companion (KL520_SDK/example_projects/kdp2_companion_user_ex/workspace.uvmpw) в данном случае несущественны, так как с точки зрения сборки их структура принципиально не отличается.
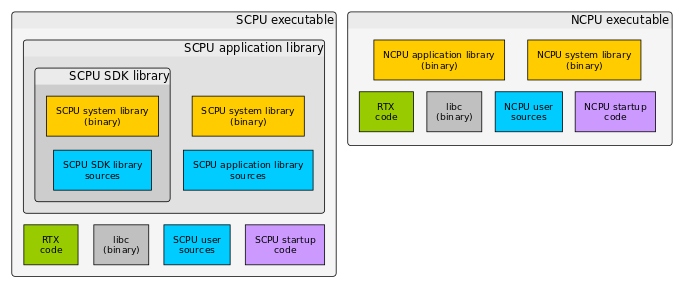
Прошивка состоит из двух основных частей. Исполняемый код основного процессора SCPU собирается из набора исходных кодов, библиотеки приложений SCPU, кода ОС RTX, библиотеки libc и кода запуска процессора на ассемблере. Библиотека приложений SCPU собирается из своего набора исходников и использует две другие библиотеки — системную SCPU, поставляемую в бинарном виде, и библиотеку SDK SCPU. Она в свою очередь собирается из набора исходников и тоже использует системную библиотеку SCPU. Исполняемый код вспомогательного процессора собирается из своего набора исходных кодов, кода ОС RTX, библиотеки libc, кода запуска процессора на ассемблере, и использует две другие библиотеки — системную NCPU и библиотеку приложений NCPU, причем обе поставляются уже только в бинарном виде. Такая замысловатая структура позволяет модифицировать некоторые системные алгоритмы в работе SCPU, например работу с периферией на низком уровне, при этом сохраняя проприетарные алгоритмы в закрытом виде.
Так как центральный процессор ARM Cortex-M4 является стандартным решением, для него есть описание карты памяти и стандартных для ARM компонент. Но вся система на кристалле целиком — это большой черный ящик с множеством скрытых модулей. Как видно из структуры, производитель дает только некоторые части проекта в виде исходных кодов. Несколько библиотек доступно только в бинарном виде. Увы, нет также описания периферии, а описание API неполное и местами не до конца очевидное. Не до конца ясна схема взаимодействия ядер, есть только общее представление о многопроцессорной системе и о том как она, по-идее, должна работать. Есть возможность по шагам отладить работу только основного ядра, подчиненное ядро для JTAG недоступно.
Именно портирование такого сложного и немного странного проекта позволило наткнуться на неимоверное количество проблем, которые в иных обстоятельствах могли бы и вовсе не проявиться. Часто их поиск и устранения проводились в глубокой пошаговой отладке, сравнением данных в памяти и чтением регистров процессора.
Портирование
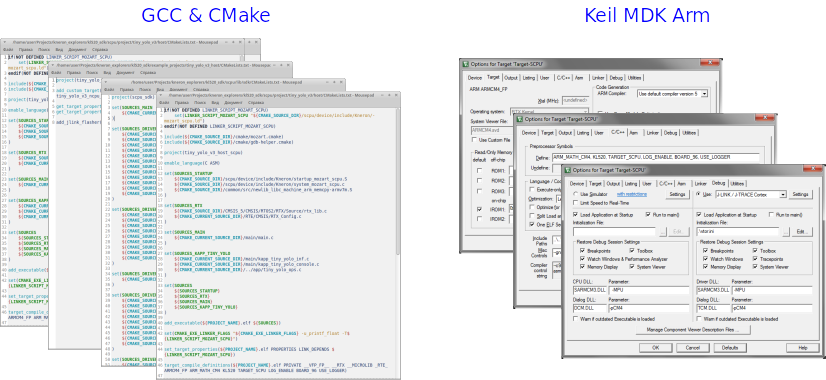
Первым делом была предпринята попытка перенестись из Keil в GCC через использованием каких-нибудь таких IDE, в которых есть поддержка GCC тулчейнов и импорт проектов Keil. В конце концов, обилие настроек и флагов компилятора и линкера требует либо глубокого понимания, чтоб самому все сделать с нуля, либо хорошего примера для старта. Напрямую флаги скопировать нельзя, но можно взять какой-то набор за основу а затем его дополнять по мере необходимости. Чтобы с чего-то начать, была использована среда Segger Embedded Studio, в которой используется GCC и есть опция импорта проектов из Keil. Импортированный проект собрать, увы, не получилось. Но это дало пищу для размышлений и отправную точку.
-
Система сборки
Пожалуй, одно из самых полезных свойств любого приличного IDE для начального погружения — это автоматическая генерация make файлов либо их аналогов. В Keil этот процесс вообще незаметен для разработчика и происходит автоматически. В случае же GCC никакой автоматизации этого процесса из коробки просто нет. Можно, конечно, make файлы писать и вручную, а можно выбрать какую-то систему генераторов. Как альтернативный вариант, можно использовать IDE с поддержкой GCC, например тот же Segger Embedded Studio или Eclipse с плагином MCU. Однако, в этом случае, можно потерять преимущество независимости от конкретного IDE.
В конечном итоге в качестве базы для разработки проекта на GCC был выбран CMake. Помимо всего прочего он позволяет автоматизировать процесс генерации проектных файлов для всех популярных IDE.
Среди всего разнообразия IDE выбор пал на Visual Studio Code c плагином для работы с проектами CMake, а также плагином для поддержки синтаксиса ассемблера ARM для редактора файлов.
Отдельно стоит остановится на файле тулчейна. За основу был взят проект cmake-arm-embedded от Johannes Bruder. В этом стороннем проекте подготовлены скрипты для Cmake, которые задают наборы ключей компилятора и линкера для разных вариантов сборки. Эти шаблоны сильно упрощают дальнейшую работу с GCC, так как в них явно выделяются необходимые опции GCC для сборки под ARM. С чистого листа достаточно трудно разобраться с множеством параметров GCC. Файл тулчейна это удобный способ для выбора конкретной версии тулчейна в CMake. Он позволяет легко экспериментировать и собирать один и тот же набор исходников разными компиляторами. Этот механизм помог в исследовании проблем и особенностей сборки при использовании разных версий GCC.
Так как в Keil уже была некая структура мультипроектного файла, то структуру CMake было решено внедрить параллельно.
-
Флаги компиляции и линковки
В Keil при выборе процессора в меню все необходимые флаги выбираются автоматически. В GCC пришлось выбирать не только название процессора, но явно указывать его архитектуру и тип сопроцессора. Более того, потребовалось явно прописывать наборы директив #define для использования тех или иных свойств системных библиотек.
-
Скрипты для линкера
Принципиально разный формат scatter file и linker script не дает возможности легко портировать одно в другое. Нужно понимать карту памяти, состав секций, размер stack и heap. Название стандартных секции (text, data, bss) у всех одинаковое, но в Keil есть свои специфичные, создаваемые под каждые функции, а также особые секции constdata и constring. Если первые интерпретируются GCC правильно, то остальные пришлось вручную прописывать в линкер скрипте в правильные места.

В дополнение к этому операция копирования инициализированных данных из памяти программ в оперативную память в GCC выполняется явно. То же касается и обнуления неинициализированных данных. С этим, кстати, в процессе работы вылезало много проблем. Часто процессор вылетал в HardFault. То по причине некорректной записи данных при старте, то из-за неправильного размера стека, то из-за обращения по несуществующему адресу.
-
-
CMSIS
Уже трудно представить себе продукт, не использующий CMSIS в том или ином виде. Keil содержит CMSIS из коробки в виде плагина. В случае GCC его пришлось брать отдельно из официального репозитория, выбрав нужную версию в соответствие с версией из Keil.
-
Код запуска на ассемблере
Компонент, как правило, стандартный. Keil автоматически подключает соответствующие исходники при выборе процессора. Есть примеры в CMSIS и для GCC, нужно было только найти свои.
Правда, в код запуска пришлось кое-что добавлять, и вот тут начались проблемы. Синтаксис ассемблера ARM и GCC отличается сильно. В помощь была только документация на ассемблер от GCC и описание синтаксиса ассемблерных вставок в исходниках на C. Некоторых макросов в CMSIS, в частности, для работы с регистрами процессора, просто не оказалось в GCC. Пришлось писать собственные, например, для чтения LR.
__attribute__ (( always_inline )) __STATIC_INLINE uint32_t __get_LR(void) { register uint32_t result; __ASM volatile ("MOV %0, LR\n" : "=r" (result) ); return(result); } #define _lr __get_LR() -
Заголовочные файлы для процессора
Тут особых проблем не возникло. Для Keil и GCC заголовочные файлы разные, но в CMSIS и те, и другие есть. Нужно было только найти.
-
Операционная система RTX
В Keil используется либо собранный вариант RTX, либо можно собирать из исходников. Причем, версия RTX заведомо совместима с остальными встроенными компонентами. А бинарная версия заведомо работает на выбранном процессоре.
В случае GCC бинарной версии RTX под каждый процессор в репозитории CMSIS просто не оказалось. Сначала была попытка использовать собранную (таких проектов в Интернете есть несколько штук), но ни одна из них так и не заработала, пришлось собирать самостоятельно. Параметры RTX для каждого процессора свои, и они были соответствующим образом интегрированы в проект.
Кстати, в проектах Keil файлы с настройками RTX содержат параметры в текстовом виде, но редактировать их можно и через меню настроек RTX изнутри Keil.
-
Неявные особенности Keil
Структура проекта Keil никак не соотносится со структурой файлов в папках на диске. Все задано вручную и потребовало такого же задания при сборке с помощью CMake. Тут, кстати, оказалось много рутинной работы и не меньше сюрпризов. Чтобы узнать настоящее местоположение каждого файла в Keil приходилось открывать его свойства. И так с каждым файлом.
Было обнаружено еще много есть разных удивительных отличий компиляторов, их все перечислять здесь смысла нет. Например, разный размер типа wchar_t, в Keil по умолчанию 2 байта, в GCC 4 байта. Если собирать полностью в GCC то об этом можно и не узнать. Такая проблема всплыла при попытке слинковать бинарник библиотеки из Keil к проекту на GCC. Чтобы с этим как-то работать, была добавлена настройка для GCC в виде явного указания использовать 2-х байтный wchar_t с отключением предупреждений о несовпадении размеров.
Обнаруженные проблемы
Их было слишком много, чтоб перечислить все в рамках данного материала. Более того, это было бы совершенно бесполезно, так как многие из них были очень специфичны. Ценность от их понимания привязана к конкретному проекту и вряд ли заинтересует читателя. Расскажу лишь о наиболее общих и крупных из них.
Все это было похоже, кстати, на прохождение старого доброго платформера, когда за каждым новым уровнем оказывался новый, еще более сложный. Вот, казалось бы, победили всех монстров, но принцесса убегает на следующий левел, а там вообще какая-то непроходимая дичь. И начинаешь искать среди друзей, кто и как это проходил, и есть ли в игре глюки, чтоб пробежать уровень поверх карты, например. Ничего не напоминает?
После того, как файлы для CMake были написаны и раскиданы по всем нужным директориям библиотек и прикладных программ, скачаны исходники RTX, подключены правильные файлы с кодом запуска из CMSIS, выбран корректный набор флагов компиляции и написаны скрипты для линкера, началось самое интересное.
Первым делом, проект из исходных кодов даже собираться не захотел. И на то была веская причина.
-
Непортируемые ассемблерные вставки и директивы
Их было много. Эта причина, очевидно, имеет частный характер и может никогда не проявится для другого набора исходников. Однако, как это часто бывает, самые элементарные вещи вызывают много проблем. Синтаксис ассемблера, как это уже про это было сказано, для компиляторов разный. То же касается и синтаксиса ассемблерных вставок, которые в итоге пришлось все переписывать. Помогло то, что некоторые из них уже были в исходниках CMSIS в различных примерах.
Что касается директив, то их написание вроде регламентировано в стандарте CMSIS с помощью макросов. Это сделано специально для отвязки от конкретных компиляторов. Но в данном проекте проблемы были с директивой weak. Она была указана в нескольких местах явно, а не через макрос. Пришлось везде приводить в соответствие со стандартом.
И что бы вы подумали, часть исходников собралась! Были получены первые объектные файлы. Одна проблема, они ни за что не хотели линковаться с имеющимися библиотеками из Keil. А таких было несколько штук, причем для разных ядер свои.
-
Разные ABI
В Keil линковка по умолчанию hard, а в GCC softfp (FPU функции, но передача параметров через регистры CPU). Это и было причиной, которая всплыла при попытке линковать библиотеку из Keil в бинарник GCC. Оказалось, что ABI по умолчанию отличаются. Пришлось указывать ABI в явном виде -mfloat-abi=hard. Но тут вылезла другая проблема. Несоответствие символов из разных ассемблерных сборок для математических функций.
-
Функции FPU
Функции для FPU в Keil и GCC названы по-разному. Ну, то есть, сами функции в языке C те же, а вот их символы в сборке отличаются. Пришлось указывать линкеру явную подмену символов, но перед этим погрузиться и убедится в том, что параметры передаются таким же образом (через специальные регистры FPU Sn и Dn).
Вот, к примеру, математические функции. Каждая функция принимает один или два параметра одинакового типа (float или double) и возвращает результат (float или double).
Семантика записи функций в таблице следующая:
регистр(ы)_результата ⤆ тип_результата ( тип_параметра_1 регистр(ы)_параметра_1 )
регистр(ы)_результата ⤆ тип_результата ( тип_параметра_1 регистр(ы)_параметра_1, тип_параметра_2 регистр(ы)_параметра_2 )Функция С Символы в Keil Символы в GCC S0 ⤆ float ( float S0 ) S0 ⤆ float ( float S0 ) fabsf() ∅ fabsf ceilf() __mathlib_ceilf ( __hardfp_ceilf ) ceilf floorf() __hardfp_floorf floorf expf() __mathlib_expf ( __hardfp_expf ) expf roundf() __hardfp_roundf roundf sqrtf() __hardfp_sqrtf sqrtf S0 ⤆ float ( float S0, float S1 ) S0 ⤆ float ( float S0, float S1 ) powf() __mathlib_powf ( __hardfp_powf ) powf S1:S0 ⤆ double ( double S1:S0 ) D0 ⤆ double ( double S1:S0 ) fabs() __hardfp_fabs ∅ ceil() __hardfp_ceil ceil floor() __hardfp_floor floor exp() __hardfp_exp exp round() __hardfp_round round sqrt() __hardfp_sqrt sqrt S1:S0 ⤆ double ( double S1:S0, double S3:S2 ) D0 ⤆ double ( double S1:S0, double D1 ) pow() __hardfp_pow pow Удивительно, но некоторые функции даже не имели соответствующих символов. Их реализация была простым набором инструкций. Причем, не всегда с очевидной логикой. Но и функции, у которых есть символы, вызывали вопросы. Например, в GCC деление кое-где было реализовано через умножение на обратное число, так как в исходном коде использовались константы.
Все это, кстати, навело на мысль, что GCC это продукт с университетским уклоном, и в нем реализовано много интересных и прорывных вещей, правда иногда слишком витиеватых и неочевидных. С другой стороны, ARMCC продукт коммерческий, реализованный более прямолинейно, доказуемо и понятно.
Только проблему с функциями FPU удалось преодолеть, как вылезла другая, более массивная и древняя.
-
printf()
Реализация printf() в ARMCC заслуживает отдельного разбора, который явно выходит за рамки данного материала. Однако, об этом нельзя не упомянуть. Если описывать в двух словах, то оказалось, что printf() в ARMCC реализован на ассемблере, причем достаточно хитро. Для всех возможных специальных символов в printf() подготовлены части ассемблерного кода. Они начинаются с символа __printf_percent, который, видимо, отвечает за обработку символа процента. Как известно, этот символ означает, что дальше за ним следует некий ключ, обозначающий тип замещающей переменной. К этому ключу могут прилагаться модификаторы, отвечающие за точность, количество разрядов и прочее. Так вот, компилятор, встречая символ ‘%’, судя по всему, проводит анализ содержимого дальнейшей строки и добавляет только те части ассемблерного кода, которые на самом деле используются. То есть, если в коде используется только печать целочисленных значений, то printf(), добавляемый в бинарник, будет иметь в своем составе __printf_percent и __printf_d, а обработчики других типов данных, например чисел с плавающей точкой добавлены не будут. Помимо этого, будет интегрирован еще только механизм вывода символов в целевую строку. Очевидно, что такая реализация явно уменьшает размер бинарника.
Но в этом решении скрывалась проблема, обнаруженная при линковке библиотек. Дело в том, что самого механизма вывода printf() в библиотеке не было. Пришлось вручную подменять псевдонимы частей printf(), чтобы они совпали с ответными частями из GCC. А некоторые части механизма, ненайденные символы, пришлось и вовсе заменить заглушками на ассемблере, которые делали простой возврат.
Проблему с функцией printf() удалось победить, пожалуй, не самым элегантным способом. Так до сих пор и не ясно, зачем были нужны некоторые ее части. Однако проект упорно не собирался. Последней глобальной проблемой на этапе линковки оказалась крайне специфичная вещь.
-
Порядок символов
В одном из собранных бинарников библиотеки Keil были обнаружены LOCAL символы, объявленные после GLOBAL. Оставалось лишь догадываться, зачем так сделано. Может, для Keil это и не критично, но линкер GCC не позволял такой порядок объявления. Любопытный факт. Был один символ, в котором, по факту, были закодированы версия компилятора ARMCC, данные об исходном файле и прочие служебные сведения, без которых вполне можно обойтись. Видимо, этот символ использовался Keil для каких-то внутренних операции при сборке. Символ был обнаружен дизассемблером и вручную убран из библиотеки утилитой strip.
Наконец, проект собрался! Но вот беда, он совершенно не влезал в память контроллера. Да и весил подозрительно много по сравнению с аналогом из Keil. Примерно в полтора раза больше.
-
Размер бинарника
Проблема не новая, однако, достойная внимания. Как показала практика, очень большое влияние на размер оказывает реализация libc. Понятно, что проекты newlib-nano и newlib-pico призваны уменьшить размер насколько это возможно. Несмотря на то, что newlib входит в состав тулчейна, его можно теоретически поменять и улучшить. Однако, эта процедура оказалась слишком сложной, от нее было решено отказаться. В итоге была использована реализация libc из тулчейна.
В проекте, насколько это возможно и без ущерба для основных задач, был почищен отладочный вывод, чтоб сократить объем данных. Были добавлены флаги -flto для компилятора и линкера, а также ключевое слово .cantunwind ко всем безвозвратным обработчикам в коде запуска на ассемблере. В общей сложности это позволило сэкономить довольно много, десятки килобайт.
В итоге, проект получился удобоваримого размера и был, наконец, запущен на железе! Но упорно отказывался работать.
-
Скорость и синхронизация
Разные части кода, особенно связанные с работой в RTX, собранные в Keil и GCC, работали с отличиями с точки зрения производительности. Одни и те же операции выполнялись за совершенно разное время. В некоторых местах замедление работы приводило к срабатыванию выставленных таймаутов, которые вообще никогда не должны были сработать. Причем, даже при использовании максимальной оптимизации, скорость работы GCC кода все же оставляла желать лучшего. Пришлось погружаться в его структуру и увеличивать нужные таймауты.
В добавок к этому, пришлось вручную добавлять volatile к некоторым глобальным переменным, так как оптимизация в GCC жестко выкидывала целые куски кода. Подобного поведения не наблюдалось при сборке средствами Keil с максимальным уровнем оптимизации.
Но и это не была последняя проблема. Разница оказалась не только в скорости, но и в реализации функций из стандартной библиотеки.
-
Байтовая memcpy()
В результате всех манипуляций по уменьшению размера бинарника и максимальной оптимизации оказалось, что библиотечная функция memcpy() в GCC теперь стала байтовой. А в Keil ее реализация по прежнему копировала пословно там, где это возможно. Этот эффект был обнаружен в процессе записи данных в выделенном адресном пространстве с доступом из обоих процессоров. Видимо, аппаратно он реализован только по 4 байта. При попытке записать по одному байту, ошибки контроллера памяти не возникало, но данные при этом фактически не записывались. Решилась проблема сначала явным копированием по 4 байта, а затем замещением стандартной функции memcpy().
В это трудно поверить, но наконец была получена рабочая прошивка. Да, ее работа несколько отличалась от оригинала. Но с основными задачами она справлялась! Пока не настало время попробовать ее собрать на разных машинах.
-
Разные версии GCC
Напоследок самая странная и самая неприятная проблема. Разные версии дали разный результат. Даже версии из одних исходников, но собранные по-разному, дали тоже разный результат. Это проявилось путем сравнения бинарников, полученных с помощью тулчейна, скачанного с сайта ARM, и той же версией тулчейна GCC из дистрибутива Linux. Можно только догадываться, чем отличаются версии из разных дистрибутивов, но все бинарники, полученные в разных дистрибутивах их родными тулчейнами одной и той же версии, получались разные.
С особой осторожностью пришлось подходить к использованию сразу нескольких версий GCC на одной машине. Ошибка в путях или в ссылках из стандартных системных директорий однажды привела к совершенно невообразимым ошибкам в работе готового бинарника. Ошибок самой сборки при этом не возникало.
Отладка
Еще до работы в VSCode для отладки была использована программа Ozone от Segger. Эта программа прекрасно работает как под Linux, так и под Windows. Причем, ради эксперимента были попытки отладить как .elf, собранный в GCC, так и .axf, собранный в Keil. Все прошилось и заработало как надо, благо форматы исполняемых файлов по сути ничем не отличаются.
Для отладки кода Cortex-M4 в VSCode понадобилась установка дополнения. А для корректной работы в режиме загрузки и выполнения, а также в режиме подключения к уже выполняемому коду, для корректной работы с gdb был написан скрипт launch.json.
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug (JLink)",
"cwd": "${workspaceRoot}",
"executable": "${workspaceRoot}/build/.../binay.elf",
"request": "launch",
"type": "cortex-debug",
"servertype": "jlink",
"device": "Cortex-M4",
"interface": "swd",
"internalConsoleOptions": "openOnSessionStart",
"runToMain": true,
"preLaunchCommands": [
"set mem inaccessible-by-default off"
],
"preRestartCommands": [
"monitor reset 0"
]
},
{
"name": "Attach (JLink)",
"cwd": "${workspaceRoot}",
"executable": "${workspaceRoot}/build/.../binary.elf",
"request": "attach",
"type": "cortex-debug",
"servertype": "jlink",
"device": "Cortex-M4",
"interface": "swd",
"searchDir": [
"${workspaceRoot}"
],
"preAttachCommands": [
"set mem inaccessible-by-default off"
],
"postAttachCommands": [
"monitor halt"
],
"postRestartCommands": [
"monitor reset run"
]
}
]
}К сожалению, в найденном наборе утилит для VSCode не оказалось подходящей для прямого и произвольного доступа к памяти контроллера.
Возможной альтернативой VSCode является полноценная разработка и отладка средствами Eclipse. Этот вариант также был опробован. Правда для этого понадобилась установка дополнений для сборки проектов CMake, а также необходимых инструментов для работы с микроконтроллерами и создания конфигурация отладчиков.
В качестве аппаратного отладчика был использован J-Link от Segger. Были также попытки использовать Olimex ARM-USB-TINY-H в связке с OpenOCD в Eclipse, но этот способ оказался крайне нестабильным.
В конечном итоге, выбор IDE и средств отладки это дело вкуса и личных предпочтений разработчика. Можно рассказать только о полученном опыте.

Заключение
Здесь история заканчивается, и можно было бы подвести какие-то итоги. Не хотелось бы обсуждать полезность описанного подхода с точки зрения освоения технологий разработки. Наверняка для тренировки правильных навыков нужен иной, более системный подход. Но это было путешествие, и оно, в первую очередь, открыло много новых, ранее неведомых вещей из мира разработки встраиваемого ПО. А что с этим делать, пусть каждый решает для себя сам. Чтобы изучить подробно каждую из затронутых тем может уйти очень много времени. Говорят, нельзя объять необъятное, но, почему бы, не попробовать?
Попытайтесь повторить это дома!