
Оптическое распознавание символов (Optical Character Recognition) — одна из первых задач компьютерного зрения, заключается в переводе изображений рукописного или печатного текста в текстовые данные, использующиеся в компьютере. Человечество научилось неплохо решать эту задачу при помощи классических методов компьютерного зрения.
Так, например, уже в 1954 году в американском журнале Reader's Digest использовалось устройство для распознавания текста. Оно решало задачу преобразования машинописных отчетов о продажах в перфокарты, которые могли быть прочитаны и просмотрены компьютерами.

Сейчас задачу OCR в основном решают при помощи машинного обучения. Поэтому в этой статье мы будем изучать и тестировать подходы, основанные именно на этой технологии. Далее мы рассмотрим различные подходы к решению задач OCR и сравним их, а также попробуем разобраться, как подобрать подходящий инструмент для конкретной проблемы. Для эксперимента мы выбрали нестандартную задачу - распознавание арабского текста.
Различия задач OCR и основные вызовы
Перед тем как перейти непосредственно к обзору доступного инструментария, стоит обозначить основные трудности, с которыми мы можем столкнуться, и рассмотреть основные направления, в которых развиваются системы OCR.
Сравнительно простой задачей является распознавание текста в документах (например перевод pdf-скана книги в текстовый формат) — чтобы её решить, достаточно научиться отделять друг от друга слова одного шрифта на едином фоне, и переводить каждое из них в текст. Разумеется, это всё ещё достаточно непросто, однако когда речь заходит о распознавании номерных или дорожных знаков на улице или решении текстовых капч, появляется множество новых факторов, влияющих на качество решения:
Расположение: не всегда текст занимает всё изображение, он может находиться в случайном месте, к тому же быть повернут и искажен.
Шум: блики, отдалённость текста и прочие артефакты добавляют сложности и при обнаружении текста, и при его распознавании.
Шрифты: печатный текст распознать намного проще, чем рукописный, так как в нём соблюдается более чёткая структура символов (в сравнении с почерком, который может различаться даже у одного человека).
Блочность текста: на странице книги весь текст организован в блоки из линий, чего нельзя сказать о тексте на случайном фото с улицы.
Алфавит: один язык — хорошо, а два уже сложнее. Добавим к этому цифры, специальные символы — и вот задача уже разрослась. Естественно, модель, обученная распознавать английский язык, не справится с каким-либо другим алфавитом.
К делу
Мы хотим научиться распознавать арабский текст в естественных условиях (например, на уличных знаках).
Теперь, когда задача обозначена, у нас есть два пути к победе.
Первый — собрать свою систему, то есть подобрать модели, подходящие для решения подзадач (поиск текста на изображении, перевод слов в текстовый формат), и объединить их в единое целое. Второй — использовать существующие opensource решения.
Выбирать мы не будем, вместо этого испробуем оба этих подхода, а затем сравним результаты.
Датасет
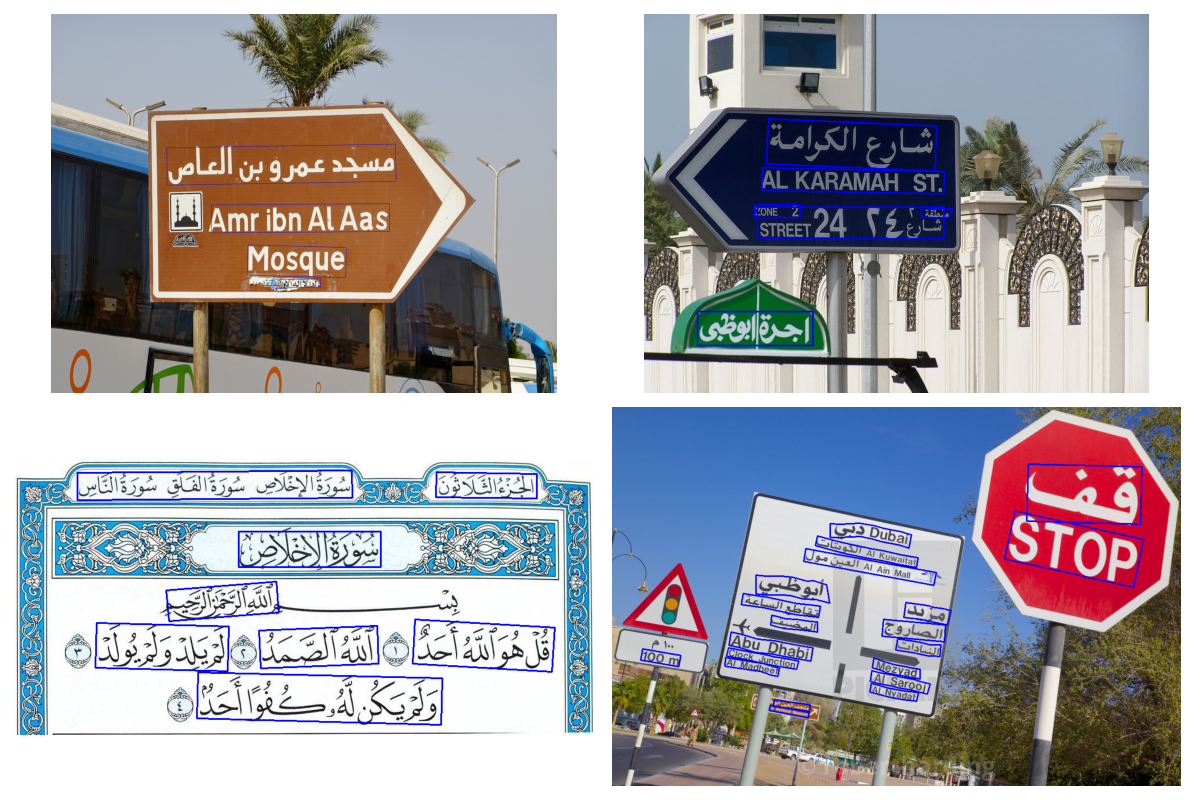
Для тестирования существующих подходов и моделей мы воспользуемся демо-датасетом компании LabelMe, состоящим из уличных фото с различными надписями, машинописных и рукописных текстов на разных фонах, а также скриншотов.

Как видно из примеров, все изображения кардинально отличаются по шрифтам, толщине, стилю. Таким образом мы сможем провести своего рода краш-тест и понять, насколько применимы рассматриваемые в статье технологии в "полевых условиях".
Обнаружение текста на изображении
Прежде чем пытаться распознавать надписи, их нужно найти. Для этого можно использовать различные подходы.
Первый подход
В своей работе коллеги из Рабатского Уиверситета Мохаммеда V предлагают решение, основанное на архитектуре свёрточной нейронной сети VGG-16, часто используемой при решении задач компьютерного зрения.
Предложенное решение состоит из двух соединенных модулей — TextBlockLocalizer, отвечающий за поиск областей изображения, содержащих текст, и TextDetector, более точно выделяющий надписи на найденных регионах. Такой подход обеспечивает не только удовлетворительную точность (65%), но и оптимизированное в сравнении со стандартной VGG-16 время работы.

Однако данная модель плохо справляется с поиском искривленного и повернутого текста.
Ключевой проблемой является то, что система обучена находить исключительно арабский текст, поэтому её точность сильно зависит от подобранного для обучения датасета. Ожидаемо, датасеты, содержащие английские надписи гораздо более разнообразны и обширны, чем аналоги с арабскими надписями, отчего и страдает точность.
EAST
Архитектура данного алгоритма разрабатывалась с учётом необходимости обнаружения областей с текстом разного размера. Это важно, например, когда на фото есть несколько вывесок, расположенных на разном расстоянии от камеры.
Основная идея заключалась в том, чтобы использовать свёрточную нейросеть для извлечения признаков (например VGG-16), а затем объединять результаты, полученные из различных слоёв этой сети. Более подробный разбор архитектуры выходит за рамки настоящей статьи, однако его можно найти в оригинальной работе. Для нас важно то, что мы имеем быструю и точную нейросеть, позволяющую находить текст.
Однако с нашим датасетом у модели возникли некоторые проблемы. Об этом позже.

CRAFT
Основная цель CRAFT — “точно локализовать каждый отдельный символ на естественных изображениях”. Подробно ознакомиться с этой моделью можно на русском и в оригинале.
В рамках нашего эксперимента достаточно того, что эта модель намного лучше, чем EAST, справляется с обнаружением текста разной степени искаженности на разных языках. Далее мы будем использовать именно её.
Распознавание слов
Итак, мы уже можем достаточно точно находить слова на изображении, теперь остаётся эти слова переводить в печатный формат. Для этого понадобится ещё одна нейросеть.
Идея первая
Задача распознавания слов звучит сложно, в отличие от более тривиальной задачи распознавания символов — последние в большинстве своём достаточно сильно различаются между собой, и в рамках одного алфавита их относительно немного.
Поэтому первое, что приходит в голову — разбить слово на буквы, распознать каждую, а затем склеить результат.
На первый взгляд, идея кажется надёжной. На деле же это действительно хорошо срабатывает, если между символами нет хитрых соединений, например, если мы говорим о цифрах. Однако, в нашем случае всё сложнее.

Пробуем решение с разбиением на символы, получаем точность в районе 50%, что само по себе достаточно неплохо, но нас не устраивает.
Идея вторая
В своей публикации исследователи из Технологического университета принцессы Сумайи предлагают подход, не требующий посимвольной сегментации.
Для этого они соединяют CNN и LSTM друг за другом. Благодаря этому, модель учится отличать не только символы, но и их комбинации и соединения между ними. Как loss функция используется популярный для задачи OCR CTC loss. С математикой, стоящей за этой функцией, можно ознакомиться в оригинальной статье.
Для обучения своей модели команда использовала инструмент, позволяющий генерировать надписи разных шрифтов. Мы рассмотрим две модели, обученные на датасете из 18 и 2 шрифтов соответственно. Интересно, что очень похожий подход использовала команда-победитель AI Journey 2020 в задаче по распознаванию рукописного текста Петра I.
Существующие решения
EasyOCR
EasyOCR - опенсорс решение, по структуре похожее на то, что получилось у нас: для поиска слов также (с недавних пор) используется CRAFT, основная сеть состоит из комбинации CNN и LSTM с тем же CTC Loss.

Tesseract
Tesseract - система, разрабатываемая с середины 1980-х. На данный момент куплена и развивается Google. Примечательно, что нейросетевые модули были добавлены только в версии 4.0.0, датируемой 2018 годом.
Тестирование
Для тестирования точности определения слов мы будем использовать две метрики: CRR (Character Recognition Rate) и WRR (Word Recognition Rate). Соответствующие формулы представлены ниже:

Тесты мы разделим на две группы:
“In the wild” — распознавание текста в естественной среде (на фото с улиц).
“Plain text” — определение неискаженного текста, как если бы мы решали задачу перевода отсканированных страниц в печатный формат.

Из результатов тестирования можно сделать следующие выводы:
Все модели лучше справляются с распознаванием текста без искажений.
Для работы с документами наиболее подходит Tesseract.
Для работы с задачей “In the wild” лучше использовать EasyOCR.
Модель, обученная всего на 2 шрифтах неплохо справляется с распознаванием символов, но часто не может полностью распознать слово, написанное неизвестным ей шрифтом. Именно поэтому для обучения важно разнообразие подобранных данных.
Заключение
В данной статье мы рассмотрели доступные решения для задачи оптического распознавания символов и убедились, что они обладают впечатляющей точностью. Также мы убедились в том, что для оптимальной работы модели в реальных условиях нужен качественный и разнообразный датасет, покрывающий максимальное число кейсов. Если в обучающем наборе данных буду только "сканы", то и читать модель сможет преимущественно их.
Всем хорошей разметки!
SmallDonkey
Из последних наиболее эффективных методов детекции текста это DBNet++, https://arxiv.org/pdf/2202.10304.pdf