

В предыдущей статье мы уже подробно рассмотрели процесс разметки семантической сегментации в CVAT. Сейчас я подробнее расскажу по NER-разметку в другом популярном open source инструменте - Label Studio.
Как и в прошлый раз мы шаг за шагом пройдем путь от установки и настройки проекта до экспорта уже размеченного датасета. В процессе будем подробнее останавливаться на нюансах связанных с извлечением именованных сущностей и рекомендациях из личного опыта.
Шаг 1: Установка Label Studio
К сожалению, запуск Label Studio не такой простой, как у CVAT. Нужно сперва поднять локальный сервер. Если вы не знаете, как это сделать — ниже будет подробная инструкция. Те, кто знают — смело переходите к шагу 2.
Итак. Создатели Label Studio никого не обделили. Вариантов установки много и по ним всем есть инструкции:
Install with pip
Install with Docker
Install on Ubuntu
Install from source
Install with Anaconda
Я же покажу, как установить с помощью pip на Windows. Для этого нам потребуется стабильная версия Python (версия 3.7 и выше).
1. Создаем папку и копируем путь к ней. У меня это C:\Users\Rustam\Desktop\project (далее буду использовать его, вы указывайте свой)
2. Открываем командную строку и пишем cd C:\Users\Rustam\Desktop\project

3. В следующем шаге мы создаем виртуальное окружение с помощью команды py -m venv env, где env - название окружения. (Для Linux команда python3 -m venv env)

4. В этом шаге мы активируем виртуальное окружение командой env\Scripts\activate.bat. Если слева от юзера появилось (env), то окружение активировано. (Для Linux команда source env/bin/activate)

5. В следующем шаге мы скачиваем Label Studio командой pip install -U label-studio (Для Linux команда pip3 install -U label-studio)

6. Последний шаг - запуск Label Studio командой label-studio

Если вы всё сделали без ошибок, то откроется страница Label Studio на вашем локальном сервере. Ниже видео этого процесса для большей наглядности:
Для повторного запуска необходимо убедиться, что виртуальное окружение активировано и что вы находитесь в директории проекта.
Шаг 2: Создание проекта в Label Studio
После установки Label Studio открывается страница. Вводим почту и пароль, создаем аккаунт. Не забываем подтвердить создание аккаунта на почте.

Затем мы попадаем в совсем пустой каталог проектов. Давайте исправим это и нажмем на Create Project.

В первом окне заполняем информацию о проекте, чтобы было удобно искать его среди других проектов. Если вы планируете работать в команде, то используйте поле Description для описания ТЗ и инструкций.

Следующее окно - импорт сырых (неразмеченных) данных.
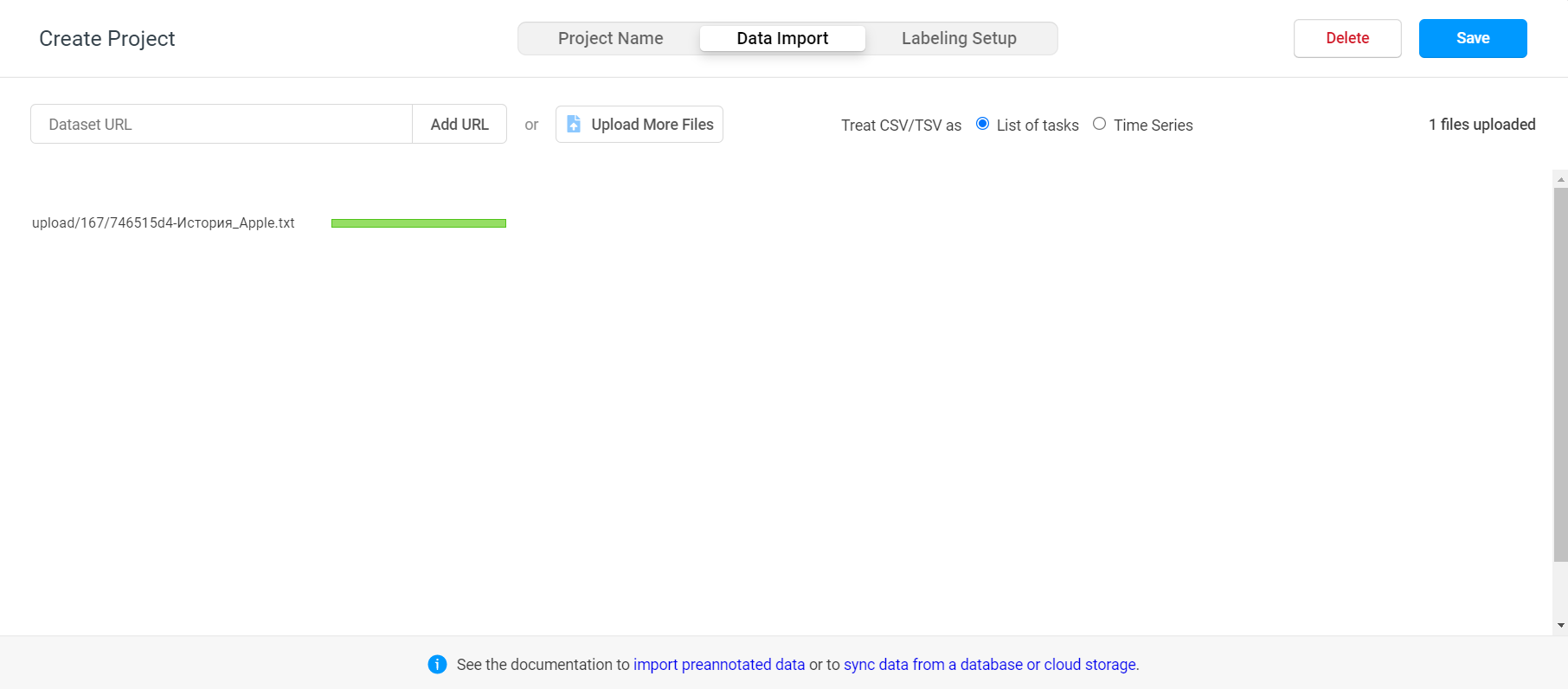
Label Studio поддерживает следующие форматы файлов:
— Text - txt
— Audio - wav, aiff, mp3, au, flac, m4a, ogg
— Images - jpg, png, gif, bmp, svg, webp
— HTML - html, htm, xml
— Time Series - csv, tsv
— Common Formats - csv, tsv, txt, json
Для NER-разметки мы создаем txt-файл, в который предварительно вставляем все спарсенный тексты.
Далее переходим в Labeling Setup. Там нам нужно выбрать раздел Natural Language Processing и в нем уже Named Entity Recognition.

Теперь необходимо задать классы извлекаемых сущностей. Но прежде, чем мы это сделаем, давайте разберемся, что из себя представляют именованных сущности и какие они бывают.
Именованные сущности — это своего рода категории слов и словосочетаний сгруппированных по значению. Например, самые распространенные сущности, выделяемые в текстах: имена людей, названия организаций, даты и так далее. Хотя в большинстве случаев всё зависит от сферы применения и конкретных задач, которые должна решать нейросеть.
Ниже оставляю список наиболее используемые классы сущностей и их общепринятые обозначения при разметке:

Теперь возвращаемся к настройке нашего проекта. После того, как мы выбрали вид разметки, перед нами откроется окно настройки классов сущностей.

Как видно на скриншоте, мы выбрали для наших текстов:
PER - люди, имена
ORG - название компаний, организаций
LOC - не географические локации
GPE - страны, города, населенные пункты
PRODUCT - товары, продающиеся объекты (кроме услуг)
Для удобства назначаем разные цвета для каждой сущности и нажимаем на Save.
Шаг 3: Разметка именованных сущностей
После того, как нажали на Save, нас перекидывает на страницу проекта.

Для примера я взял небольшой фрагмент из статьи про Apple на Википедии. Label Studio автоматически выносит каждую текстовую строку из файла в отдельный джоб. У меня на скриншоте между ними пробел, так как и в текстовом файле между ними есть отступ.
Теперь кликаем на любой из текстов и начинаем размечать.
Стоит отдать должное Label Studio: интерфейс интуитивно понятен и удобен. Просто кликаешь на нужный класс сущности, а затем выделяешь слово или словосочетание. Повторяешь до тех пор, пока не выделишь все сущности.
А что делать, если забыл какой-то из классов? Прям, как я забыл про сущности дат. Всё просто. Нажимаешь на Submit, чтобы сохранить текущий прогресс, а затем возвращаемся к настройкам проекта. Далее кликаем на Settings в правом верхнем углу экрана.

Теперь переходим во вкладку Labeling Interface и добавляем нужный класс, как в самом начале настройки проекта.

Следующий важный нюанс, с которым мы можем столкнуться в ner-разметке, это неоднородность сущностей в тексте. Самый лучший пример - сущности даты. Только в рассматриваемых трех абзацах мы встречаем разные вариации:
— в середине 1970-х годов
— 1 апреля 1976 года
— в 1976 году
— в 1974—1975 годах
— в 1976—1977 годах
— с 1977 года
— с 1977 по 1993 годы
— с конце 1970-х и начале 1980-х годов
Чтобы неоднородность формулировок не повлияла на точность модели, важно максимально стандартизировать принципы аннотации каждой сущности.
Я столкнулся с этой проблемой лично, когда моя компания по разметке делала первые шаги. Каждый разметчик выделял начало и конец сущности по-разному, из-за датасет получался довольно мусорным.
Решением стало написание подробного ТЗ и инструкции с разбором конкретных примеров. То есть под каждую сущность мы разбирали различные примеры написания и аннотации.
Есть и другой способ решения проблемы начала-конца многосоставной сущности — BIOES-схема. Её суть заключается в присвоении метке сущности префиксов, указывающих на расположении внутри класса. Схема BIOES включает 4 подобных префикса:
— B (beginning) – первое слово в сущности
— I (inside) – все слова между первым и последним словом в сущности
— O (out) — слово не относящееся к сущности
— E (ending) — последнее слово в сущности
— S (single) — сущность состоящая из одного слова
Использование BIOES позволяет нам представить разметку сущности в виде токенов и точно определять начало и конец каждой сущности. Пример ниже:

Этот метод более трудоемок, да и в Label Studio нет этого функционала, но и не упомянуть о нем нельзя.
Но это лирическое отступление. Для большинства задач по автоматизации достаточно описанной выше NER-разметки.
Шаг 4: Экспорт размеченных данных
Итак, мы разметили все сущности в имеющихся текстах. Теперь нужно их выгрузить. Для этого выделяем нужные джобы или все сразу, кликнув на ID. Затем жмем на Export в правой части экрана.

Label предложит один из нескольких форматов. Для задачи по извлечению именованных сущностей чаще всего это:
— JSON
— JSON-MIN
— CSV
— TSV
— CONLL2003

Ставите поинт на нужный и нажимаете Export. Готово.
Заключение
В этой статье мы прошлись по полному циклу NER-разметки в Label Studio от установки и настройки проекта до аннотации сущностей и экспорта готового датасета.
Очень надеюсь, что статья была для вас полезной. Если у вас есть какие-то рекомендации, советы или вы нашли неточности — дайте знать в комментария.
Всем хорошей разметки!