
Продолжаю писать скрипт для анализа текстового файла с кодом на языке HTML. Скрипт должен работать в программе-оболочке «Windows PowerShell» версии 5.1 (и в «PowerShell» версии 7) в операционной системе «Windows 10». Ранее я вывел в консоль схему HTML-дерева из текстового файла с кодом на языке HTML (в кодировке UTF-8 без метки BOM).
Вывод атрибута class HTML-элементов
После этого я решил вывести на схеме HTML-дерева названия классов CSS для HTML-элементов, у которых есть атрибут class. Также я решил, что эти названия должны быть подсвечены, потому что в данный момент моя цель — анализ именно названий классов CSS.
Библиотека «HTML Agility Pack», которую я использую, дает возможность запросить названия классов CSS для каждого узла HTML-дерева с помощью метода GetClasses. Подсветить названия классов можно с помощью управляющих кодов ANSI (я буду подсвечивать названия классов, меняя цвет текста).
Меняю код обработки узла при обходе HTML-дерева:
# Обработка узла (вывод в консоль)
$esc = [char]27 # Работает в «Windows PowerShell» версии 5.1
$indent = 2 # Отступ: 2 пробела на уровень, можно менять
if (("#document" -eq $node.Name) -or
(("#" -eq $node.Name[0]) -and ("" -eq $node.OuterHTML.Trim())) -or
("#" -eq $node.Name[0])) {
# 1. Корневой узел (#document) не выводим,
# 2. Пустые узлы (пробелы, символы новой строки и т.п.) не выводим,
# 3. Комментарии (#comment) и текстовые (#text) узлы не выводим
# (третье условие можно убрать, тогда задействуется переменная $content)
} else {
# Для непустых комментариев и текстовых узлов выводим их содержимое
$content = ""; if ("#" -eq $node.Name[0]) {
$content = ", '" + $node.OuterHTML.Trim() + "'" }
# Вычисление отступа узла для визуализации глубины
$count = 0; foreach ($ancestor in $node.Ancestors()) { $count++ }
$count = ($count - 1) * $indent
# Получение и подсветка атрибута class узла HTML-дерева
$classes = ""; if ("" -ne $node.GetClasses()) {
$color = "33" # Желтый (слот цветовой схемы), можно менять
$classes = ".$esc[$color`m" + $node.GetClasses() + "$esc[0m"
}
(" " * $count) + $node.Name + $classes + $content
# Перебор названий классов
# ...
}Я добавил переменную $classes и ее обработку. От названия узла (HTML-элемента) названия классов отделяются точкой. С помощью одного из управляющих кодов ANSI названия классов подсвечиваются желтым цветом, взятым из слота «Желтый» палитры текущей цветовой схемы, выбранной пользователем эмулятора терминала. Управляющий символ определен выражением [char]27, а не выражением `e или `u{1B}, потому что последние появились в программе-оболочке «PowerShell» с версии 6, а в программе-оболочке «Windows PowerShell» версии 5.1 не работают.
Такая подсветка цветом с помощью управляющих кодов ANSI работает как в программе-«эмуляторе терминала» «Windows Terminal», так и в программе-«эмуляторе терминала» «Windows Console».
Я пока убрал узлы-комментарии и текстовые узлы из вывода, так как сейчас меня интересуют HTML-элементы и классы CSS, привязанные к этим HTML-элементам.
Перебор классов на одном узле
Сначала я думал как-то разбирать строку, полученную из метода GetClasses узла. А потом я подумал, что этот метод не просто так, наверное, называется «получить классы» в переводе на русский. Так и оказалось: этот метод возвращает не строку, а коллекцию классов, которую можно перебрать, например, в цикле foreach.
Почему значение атрибута class HTML-элемента требует разбора? Хоть атрибут называется просто «класс» в переводе на русский, он может содержать не одно название класса CSS, а ряд названий классов CSS, разделенных пробельными символами. В пробельные символы, кстати, входит не только пробел, но и горизонтальная табуляция, и символы новой строки. Из-за этого названия классов можно не только писать одной строкой, разделяя пробелом разные названия, а располагать названия классов в столбик, для лучшей читаемости.
Например, вот названия классов CSS перечислены в одной строке и разделены пробелом в коде на языке HTML:
<div class="class-name1 class-name2 class-name3">
<!-- содержимое блока -->
</div>А ниже названия классов CSS перечислены в нескольких строках и разделены пробелами, символами горизонтальной табуляции и символами новой строки (это тоже код на языке HTML):
<div class="class-name1
class-name2
class-name3">
<!-- содержимое блока -->
</div>В вышеприведенном коде перед названием класса class-name2 введены три символа горизонтальной табуляции, а перед названием класса class-name3 — 12 символов пробела. В хорошем редакторе кода должна быть возможность настройки ввода отступов — символами горизонтальной табуляции или символами пробела. В последнем случае при нажатии клавиши «Tab» на клавиатуре вводится не символ горизонтальной табуляции, а пробелы, количество которых тоже может быть настроено (обычно это 2 или 4 пробела).
Кстати, для публикации кода в интернете я предпочитаю вводить отступы в коде только пробелами. Символы горизонтальной табуляции на разных сайтах отображаются по-разному. У меня в редакторе «Visual Studio Code» в вышеприведенном коде названия классов отображаются в ровный столбик, так как три символа табуляции (каждый шириной в 4 пробела) по ширине соответствуют 12 символам пробела. А при публикации этого кода на Хабре (в новом редакторе) название класса class-name2 оказалось сдвинуто влево. Как я понимаю, из-за того, что Хабр придает символам горизонтальной табуляции ширину в два символа пробела. (После окончательной публикации статьи названия классов в столбце таки выравниваются.)
При публикации кода, к примеру, на «GitHub» символ горизонтальной табуляции представляется шириной в 8 символов пробела, из-за чего код, наоборот, оказывается сдвинутым вправо.
Вернемся к нашей теме. Итак, к приведенному выше в этой статье коду добавим следующее:
# Перебор названий классов
foreach ($class in $node.GetClasses()) {
$color = "36" # Голубой (слот цветовой схемы), можно менять
(" " * ($count + $indent)) + "$esc[$color`m" + $class + "$esc[0m"
}Тестирование
Я подготовил файл с кодом на языке HTML для тестирования своего скрипта:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="utf-8" />
<title>Тестовая страница</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
</head>
<body>
<div class="class-name1 class-name2 class-name3">
В одну строку, разделитель: символ пробела.
</div>
<div class="class-name1
class-name2
class-name3">
В несколько строк (в столбик), разделители: пробелы,
символы горизонтальной табуляции, символы новой строки.
</div>
<div class=" class-name1 class-name2 class-name3">
В одну строку. Есть пробельные символы в начале.
</div>
<div class="class-name1 class-name2 class-name3 ">
В одну строку. Есть пробельные символы в конце.
</div>
</body>
</html>В этом файле есть четыре блока div с атрибутом class. Они содержат разные варианты ввода названий классов CSS для блока. Этот файл успешно прошел проверку в известном валидаторе HTML, то есть все эти варианты валидны.
Метод GetClasses узла из библиотеки «HTML Agility Pack» во всех этих четырех вариантах выдаст одинаковый результат. То есть ненужные разделители в виде вышеупомянутых пробельных символов (пробелы, символы горизонтальной табуляции, символы новой строки) будут откинуты (будут заменены одним пробелом в местах, где требуется разделитель), а мы получим коллекцию «очищенных» названий классов CSS для перебора и анализа.
Вот как у меня выглядит вывод в консоль для вышеуказанного тестового файла:
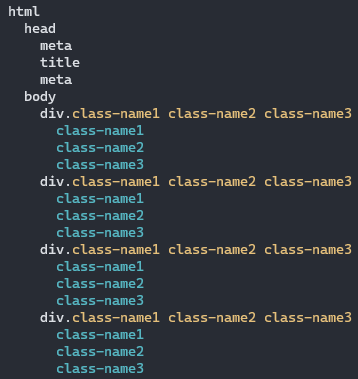
Обработка ссылок на символы
Как известно, значение атрибута class HTML-элементов может состоять из текста (символы Юникода) с вкраплениями ссылок на символы вида ю (это пример ссылки на строчную русскую букву «ю»). Ссылки на символы кроме числа (десятичный код символа в Юникоде) еще могут содержать названия символов из таблицы, приведенной в стандарте HTML.
Нужно иметь в виду, что показанный выше метод GetClasses узла из библиотеки «HTML Agility Pack» не обрабатывает ссылки на символы, встречающиеся в названиях классов. Что значит «не обрабатывает»? Это значит, что он не преобразовывает ссылки на символы в символы, которые эти ссылки на символы представляют.
А зачем преобразовывать ссылки на символы в символы? Приведу один пример. Предположим, в файле с кодом на языке HTML есть такой HTML-элемент:
<div class="имя-класса1 имя класса2">
<!-- содержимое блока -->
</div>Сколько тут классов CSS? На первый взгляд кажется, что к этому HTML-элементу привязано два класса CSS: имя-класса1 и имя класса2. Метод GetClasses тоже так считает и возвращает коллекцию из двух указанных имен классов.
Однако, при проверке в браузере (я использую для тестирования браузер «Microsoft Edge» на движке «Chromium» и браузер «Google Chrome») выясняется, что браузер видит здесь три класса: имя-класса1, имя и класса2. Почему? Потому что ссылка на символ   представляет символ пробела, а символ пробела является одним из возможных разделителей имен классов в атрибуте class HTML-элементов согласно стандарта HTML!
Я хочу, чтобы мой скрипт показал и исходную строку с именами классов, содержащую не конвертированные в символы ссылки на символы, и перебор имен классов с учетом конвертирования в символы ссылок на символы. Как это сделать?
Библиотека «HTML Agility Pack» имеет в своем составе служебный класс (по-английски «utility class») HtmlAgilityPack.HtmlEntity, с помощью которого можно выполнить, в частности, конвертацию строки со ссылками на символы в строку, в которой все ссылки на символы заменены на представляемые ими символы. Это можно сделать с помощью метода DeEntitize. Данный метод работает как с числовыми ссылками на символы, так и с именованными ссылками на символы. Объект указанного класса для этого создавать не нужно.
Дополним код перебора названий классов:
# Перебор названий классов
$classes = [HtmlAgilityPack.HtmlEntity]::DeEntitize($node.GetClasses())
if ($null -ne $classes) {
$node.RemoveClass()
$node.AddClass($classes)
}
foreach ($class in $node.GetClasses()) {
$color = "36" # Голубой (слот цветовой схемы), можно менять
(" " * ($count + $indent)) + "$esc[$color`m" + $class + "$esc[0m"
}До этого кода мы уже вывели в консоль исходное значение атрибута class HTML-элемента. Теперь просто удаляем старое значение этого атрибута и заменяем его на значение, в котором все ссылки на символы конвертированы в представляемые ими символы. После этой операции воспользуемся методом GetClasses библиотеки «HTML Agility Pack» как ни в чем не бывало. Таким образом, получается, что мы немного доработали функциональность библиотеки.
Вот как работа скрипта выглядит у меня в консоли:

Резюмируем
Для работы с атрибутом class HTML-элементов в библиотеке «HTML Agility Pack» есть метод GetClasses. С его помощью можно получить значение атрибута class одной строкой, в которой убраны лишние символы-разделители, а, где это необходимо, оставлен один разделитель в виде символа пробела. Также с помощью метода GetClasses можно получить коллекцию имен классов CSS из значения атрибута class HTML-элемента. Эту коллекцию можно перебирать в цикле foreach для анализа отдельных имен классов CSS.
Метод GetClasses не конвертирует ссылки на символы в представляемые ими символы. Для такой конвертации можно воспользоваться методом DeEntitize служебного класса HtmlAgilityPack.HtmlEntity.