
К вам пришло из API что-то огромное, браузер начал тормозить, а пользователи недовольны? Как с этим справиться? Когда и в каких UI компонентах с проблемой отображения большого массива данных сталкиваются разработчики? Какие специальные подходы применять или не применять?
Меня зовут Сергей Клинов. Я старший frontend-разработчик в компании Datafold. Моя специализация — это TypeScript, React, визуализация данных, формы, повышение производительности. Поговорим о решении проблем, с которыми уже столкнулся, либо в ближайшее время точно столкнется каждый фронтенд-разработчик. Рассмотрим несколько возможных решений, их преимущества и ограничения. Принцип и устройство виртуального рендеринга и разберем рабочий пример его применения на продукте Datafold.

Чтобы понять контекст, в котором мы работаем, и как мы столкнулись с проблемой отображения больших объемов данных, пара слов о нас и продукте. Мы создаем платформу для мониторинга аналитических данных и помогаем дата-сайентистам и дата-инженерам быстрее находить нужные данные, разбираться в их устройстве, тестировать и отслеживать их качество. У платформы несколько основных модулей:

Технологию виртуализации мы впервые применили в инструменте аналитики Profiling (таблице колонок).
Отображение больших массивов данных
Мы можем столкнуться с необходимостью отображения больших объемов данных в:
результатах поиска;
фильтрах каталога, если вы работаете в E-commerce;
дашбордах бизнес-приложений;
больших аналитических таблицах и сэмплах данных;
бесконечных скроллах и слайдерах.
Как правило, это массивы однотипных элементов, которые рендерятся в более сложные компоненты (карточки, элементы списка, чеки таблицы). Либо на основании этого массива формируются дополнительные компоненты, например, отображение общего количества данных или дополнительных фильтров.
Проблема с отображением больших объемов данных
В первую очередь рендер предполагает создание множества объектов в DOM или в Virtual DOM, если вы работаете в React. Все это нужно хранить в памяти, рендерить в браузере, отслеживать изменения как во фреймворке, так и в браузере.

Когда у вас несколько сотен элементов, это, как правило, не проблема. Но когда на странице их становятся тысячи и сотни тысяч, пользователи сталкиваются с явным снижением производительности. Это приводит к ухудшению user experience и возможным отказам.
Посмотрим на примере одной ячейки из стандартной таблицы Ant Design в React:

В HTML вы видите:
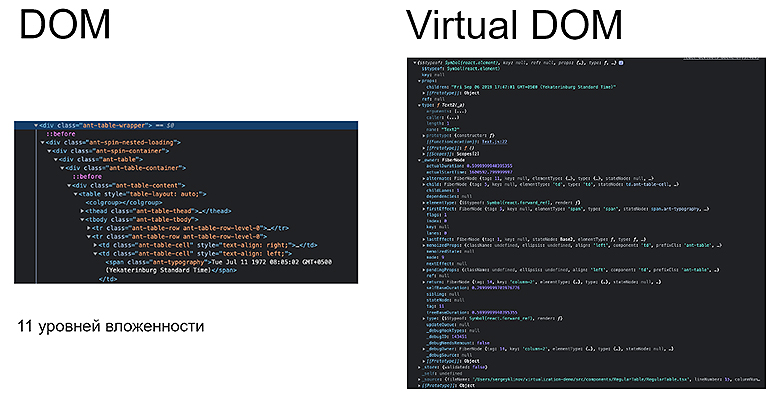
Для Ant Design это 11 уровней вложенности от начала таблицы, даже не от body. А в Virtual DOM это объект со множеством свойств и функций, который, конечно, занимает место в памяти. В такой момент и начинаешь задаваться вопросом: «У нас уже большое количество элементов или еще нет?».
Посмотрим на рекомендации Google Lighthouse по размеру DOM.
<1500 нод в документе;
Глубина вложенности <32 уровней;
Родительские элементы содержат <60 потомков.
Эти критерии наиболее важны для поисковой индексации. Для SPA это не так критично, потому что, как правило, со SPA вы не индексируетесь поисковыми системами. Но это все равно дает ориентиры для оценки производительности.
Я однажды сделал компонент, протестировал на своих данных, выкатил на продакшн и все было хорошо. Но через день мы получили сообщение от одного из своих крупнейших клиентов, что таблица не отображается, а браузер виснет. У него оказалась таблица в 120 колонок и несколько тысяч строк. Стандартный компонент, который, казалось бы, на тестовых данных работал нормально, просто ее не переваривал, и нам срочно пришлось искать решение.
Такой случай нередок, бывают таблицы с миллиардом строк. Тогда сэмпл данных по определенному алгоритму получается длиной в несколько тысяч строк. А количество колонок определяется уже структурой данных и переваливает за 100.
У нас была Ant Design таблица:

Она генерировала несколько уровней вложенности, как мы уже видели. Посмотрим, что у нее внутри, почему она оказалась такой сложной:

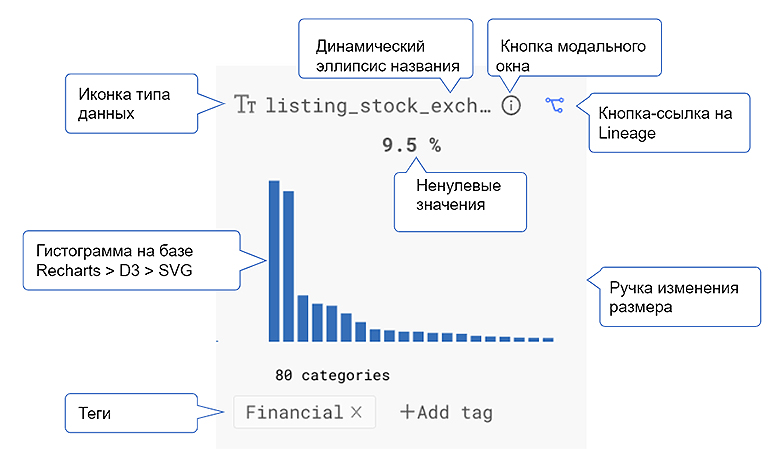
Здесь есть:
Ячейки с форматированием по типу данных;
Эллипсис по ширине колонки;
-
Сложный хедер колонки, а в нем куча элементов:
Иконка типа данных;
Динамический эллипсис названия;
Кнопка модального окна;
Кнопка-ссылка на Lineage;
Ненулевые значения;
Гистограмма на базе Recharts > D3 > SVG предполагает рендер в SVG, а это каждый отдельный DOM-элемент для каждого прямоугольника из графика. Как правило, 20 элементов на одну гистограмму;
Ручка изменения размера;
Теги.
Для такой проблемы могут быть следующие решения.
Возможные решения
Если у вас много элементов, можно просто уменьшить отображение при помощи дизайна и посмотреть, что получится.

Отличное решение — пагинация. Если вы можете ее сделать — делайте. Пагинация, как правило, предсказуема в рендере, в объеме передаваемых данных по сети, с точки зрения занимаемого места и лейаутов. Когда она не подходит чисто по UI, есть виртуализация. Давайте разберем ее подробнее.
Виртуальный рендеринг
Для начала на секунду отвлечемся от веба и фронтенда, посмотрим на соседнюю область — компьютерные игры. Конечно, там другие нагрузки и требования к производительности рендеринга, но есть интересный прием Occlusion Culling. С его помощью вычисляется и рендерится только то, что попадает в область видимости камер. Это 3D, освещение, углы наклона камер, полигоны и текстуры альфа-каналов. Во фронтенде, как правило, всего этого нет. Есть только прямоугольник на плоскости. Поэтому перенести технологию во фронтенд можно. Давайте на примере живого кода посмотрим как ведут себя две таблицы — обычная и виртуализованная.
Я проводил замеры на обычном компьютере и в одной сессии.
Обычная маленькая таблица на 1000 ячеек, 10 колонок и 100 рядов отрендерилась за 498 миллисекунд, виртуальная — за 19 миллисекунд. Разница уже видна, но 0,5 секунд не будут заметны для обычного пользователя. Поэтому если у вас относительно небольшая таблица, можно остаться с обычным рендом.
Средняя таблица — 10 колонок, 1000 рядов и 10 тысяч ячеек в профайлинге рендер занял уже больше 3 секунд, а в виртуальном рендере всего 8 миллисекунд.
Большая таблица: 100 колонок, 10 тысяч рядов и миллион ячеек виртуальный рендеринг отработал за 5 миллисекунд, а для обычного рендера это было fatality. У меня просто завис браузер и перестал работать.

Посмотрим, как работает стандартный рендер по сравнению с виртуальным.
Сравнение стандартного и виртуального рендера
Есть простая таблица с 72 ячейками.

Они все будут отрендерены, помещены в DOM несмотря на то, что попадают в область видимости. Нам без разницы, что видно — рендерим все.
Виртуальный рендер работает по-другому.

Он оценивает размеры области видимости, размеры и количество самих элементов, попадающих в область видимости и формирует статичные DOM-элементы.
Итак, у нас всего 8 DOM-элементов, которые мы видим, и нет необходимости каждый раз подчищать DOM и проводить дорогостоящий diffing.
Основные принципы работы виртуального рендеринга
За виртуальным рендерингом стоит очень простая и быстрая математика. Там только операции сложения, вычитания и пара умножений, которые вычисляют необходимость рендера объекта.
Для того, чтобы виртуальный рендеринг работал, необходимо соблюдать несколько условий:
Вычисление размеров отображаемых объектов.
Важно знать размер области отображения в пикселях и каждого элемента в списке.

Мы задействуем следующие размеры:
offset — текущий сдвиг от верхнего левого края;
Размеры области видимости;
Высота каждого элемента;
Общая высота и ширина таблицы или списка.
Также мы будем знать величину, на которую произошел скролл. На основании этого сдвигать элементы, попадающие в область видимости, и менять их содержимое.
Проверка того, что попадает в область видимости.
Бывают динамические размеры элементов или мы не можем подсчитать размеры каждого элемента заранее. Либо можем это сделать, но только уже в процессе рендеринга. У некоторых реализаций есть механизмы, когда они подстраиваются под изменяемые размеры. Но это также снижает производительность, потому что ресурсы тратятся на вычисление этих размеров.
Рендер только тех элементов, которые попали в область видимости.
Если вы не можете вычислить размеры области видимости и общие размеры каждого из элементов — виртуальный рендеринг вам не подойдет. Например, это может быть случай, когда есть требования по подстройке размеров ячейки или таблицы под содержимое (текст разной длины и т.д.), то есть размер, который вы не можете подсчитать заранее.
Особенности виртуального рендеринга
В таблице данных размеры ячеек легко определить. Есть списки единообразных данных (карточки товаров, опции фильтра, результаты поиска.) Но поскольку мы рендерим только область видимости, даже если у нас всего 8 элементов, чтобы сохранить данные, нужен скролл. Тут нет никакой хитрости. Мы знаем полные и точные размеры каждого элемента в списке и можем создать пустой элемент placeholder нужного размера, который будет служить только для скроллинга.

Недостатки виртуального рендеринга
Одна из опасностей — ощущение «безнаказанности» с объемом подгружаемых данных. Если у вас есть бесконечный динамически подгружаемый односторонний скролл с картинками или большим объемом данных, то они могут зафлудить всю память. Тогда снижение производительности будет не из-за самого рендера, а из-за хранения объема данных.
Еще есть ограничения по взаимодействию с UI и встраиванию нескольких скролл-баров на странице. Виртуализованный список — это прямоугольник с определенными размерами. Скорее всего, у него будет свой внутренний скролл, часто горизонтально-вертикальный. Это накладывает ограничения с точки зрения пользовательского интерфейса, а также UX. Если у вас большая страница, на ней много элементов и компонентов, несколько скролл-баров рядом будут вводить пользователей в заблуждение. Какой из них использовать, чтобы прокрутить данные?
Как можно улучшить?
Чтобы избавиться от проблемы раздувания количества данных и сохранить производительность можно использовать динамическую подгрузку.

Это альтернатива пагинации. Она как правило работает ровно на тех же запросах в API, с теми же самыми параметрами по размеру страницы. Нужно сделать какой-то threshold в обе стороны, чтобы сохранять в памяти разумное количество элементов, удаляя начало и конец списка. Нужные данные подгружаем, а ненужные удаляем.
Примеры реализаций
Есть несколько базовых реализаций. React-window сейчас рекомендован в документации самого React. Ее автор Брайан Вон — один из core-членов команды React.
Для Angular существует реализация на базе Angular Material и scrolling CDK:
Также есть виртуальная таблица на Vue, хотя по npm она не очень популярная.
Если вы знаете примеры других базовых библиотек, буду рад, если вы поделитесь ими в комментариях.
Как мы искали решение
В Datafold мы отказались от уменьшения количества отображаемых данных. Потому что из БД данные не выкинешь. У нас там и так всего одно значение. А сложный хедер, который вы видели в примере, основа нашего функционала. С ним ничего нельзя сделать.
Пагинация тоже нам не подходила из-за требований дизайна. Нам было нужно сохранить свободную и бесшовную навигацию по данным сэмпла. Кроме того, пагинация возможна только в одну сторону. Если это таблица, то вертикально. Поэтому мы не могли сделать пагинацию на колонки. Например, отображать только первые 10 колонок, а на второй странице вторые 10 колонок.
Мы выбрали виртуализацию. У нас таблица относительно единообразных данных и четко определенное место на странице. Можно вписать данные в одни и те же размеры.

У нас был Ant Design, можно было бы применить одну из библиотек (react-window). Даже в самой документации Ant описан пример, как это делать. Но он нам не подошел, потому что у нас было требование по resize колонок, а эти два решения не работают вместе. Плюс, там неприемлемая типизация в TypeScript. Поэтому получался не очень хороший результат.
Мы начали искать как сделать проще, быстрее и с тем же функционалом и выбрали решение от Autodesk.
React-base-table основан на react-window, и у него есть несколько плюсов:
Виртуализация «из коробки»;
Встроенный resize колонок;
Хорошие возможности кастомизации самих ячеек, хедера, стилей и всего, чего угодно.
Но есть и минусы:
Документация не очень понятная, не очень симпатичные примеры. Невозможно скопировать из документации кусок кода — он не заработает.
Неочевидная кастомизация. Например, есть разные сигнатуры для функций, которые идут с одинаковыми названиями для разных подкомпонентов таблицы.
Не всегда понятно, как работать с динамическими данными. Это не очень хорошо описано в документации. Вы не увидите обновление данных, если будете действовать по обычным паттернам. Динамические данные нужно пробрасывать через пробы элементов таблицы.
Горизонтальный скролл хедера. Он не виртуализован и по умолчанию таблица занимает 100% ширины. Поэтому есть проблема с допиливанием хедера через рефы.
В итоге мы решили проблемы с производительностью. Наверное это не предел по улучшению производительности, но она стала приемлемой для нас. Плюс, мы решили свою UI-задачу. Теперь мы отображаем таблицу и ее полный объем.

Ссылка на пример с тремя вариантами отображения. Можно скачать, запустить свой собственный браузер на миллион ячеек, перезагрузить и посмотреть, как это работает на виртуальной таблице.
Итоги
Виртуальный рендеринг стоит применять когда мы имеем списки или таблицы однообразных предсказуемых данных, можем вычислить их размеры, либо пренебречь ими, засовывая их в ячейки определенного размера.
Перед применением виртуального рендеринга стоит обратить внимание:
Как решение вписывается в UI? Устраивают ли вас несколько скроллов? Фиксация размеров отображаемой области и размеров элементов, которые вы отображаете?
Можно ли упростить задачу? Можно ли уменьшить количество отображаемых данных или добавить пагинацию?
Какие у вас есть технические особенности UI? Например, динамически подгружаемые данные, сложные хедеры, дополнительная интерактивность, resize, с чем мы столкнулись на примере ANT, когда несколько функционалов не ужились вместе.
Приглашаем вас на Frontend Conf 2022 (24 и 25 октября 2022 Москва/Digital October). В этом году фокус будет на фронтопсе, архитектуре и культуре разработки. Все подробности, расписание и билеты на сайте https://frontendconf.ru/moscow/2022
Комментарии (10)

popuguytheparrot
22.08.2022 13:30из года в год одно и тоже и ничего нового

sklinov Автор
22.08.2022 17:43Каких знаний вам не хватает в теме виртуализации?

TyVik
23.08.2022 09:05Да в том-то и дело, что ничего нового пока не придумали. Сам виртуальный скроллинг делал ещё на angular1, т.к. там был проблема с рендером большого списка.
sklinov Автор
23.08.2022 10:48Согласен, сама идея виртуализации довольно проста - поэтому в ближайшее время мы, наверное, услышим только про различные реализации этого механизма.
Можем ли мы думать о нативной поддержке виртуализации браузерами в будущем?

nin-jin
22.08.2022 14:33+2Для начала я просто оставлю это здесь:
Там рассказывается, как виртуализировать рендеринг без знания точного размера элементов.
Гистограмма на базе Recharts > D3 > SVG предполагает рендер в SVG, а это каждый отдельный DOM-элемент для каждого прямоугольника из графика. Как правило, 20 элементов на одну гистограмму;
Ну это вы просто кривую библиотеку выбрали. $mol_plot_bar отрендерил бы это в 1 SVG элемент. $mol_plot, кстати, и графики виртуализирует. В результате уделывает даже либы на базе canvas.
Вообще, взяли бы сразу нормальный фреймворк - не пришлось бы тратить столько времени на оптимизации. Но это же не спортивно..
sklinov Автор
22.08.2022 17:45Расскажите, насколько удобно встраивать mol_plot_bar в React-проект? У вас был подобный опыт?
nin-jin
22.08.2022 19:09+1В React-проект в принципе что-либо встраивать не удобно. Даже (внезапно!) React-компоненты. Эти вечные лоадеры с ручным приводом, оптимизации рендеринга, двойная умно-глупая иерархия компонент с пересборкой для малейшей кастомизации, борьба с гонками эффектов, лесенки из контекстов. Поражаюсь, как вас не укачивает от всего этого развлечения.
Тут есть пример встраивания куда-угодно. А если воспользоваться $mol_wire, то интеграция будет ещё более прозрачной.
Ghost_nsk
а вы точно режиссер?
sklinov Автор
Расскажите, чем вам не нравится пагинация?
Ghost_nsk
Тем что это просто технический костыль, особенно применительно к табличным данным.
Что то анализировать (а для чего еще выводить столько циферок?) с пагинаций практически невозможно, на какой странице у нас данные для "tdasw"? Особенно когда нужно что то отфильтровать, отсортировать и вывести какие то статистики (правильно считать их для страницы или для всего? и т.д.) это все начинает выглядеть как пятая лапа у собаки.
Пагинация для пользовательского удобства не подходит никогда, это всегда костыль книжной технологии, там это нивелируется удобством хоть какой то навигации, при том что текст не меняется. Но опять же, если брать печатные справочные таблицы, найти страницу с нужной строкой - только перебором, это не удобно. В цифровом виде есть другие, боле удобные, способы навигации.