
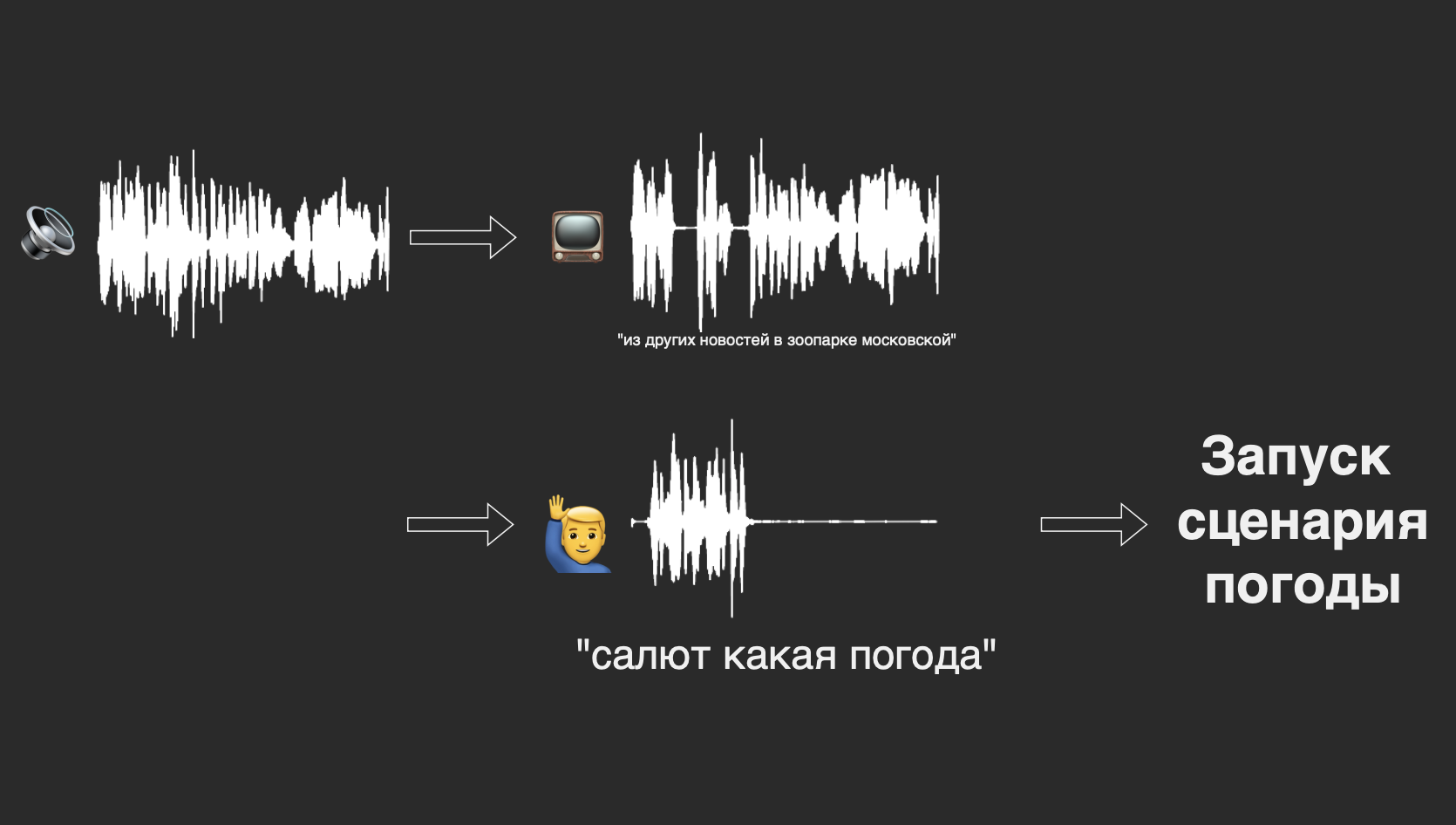
В психологии есть понятие эффекта коктейльной вечеринки: человек способен воспринимать полезную для себя информацию даже в ситуации, когда вокруг него много источников речи и шума. Но насколько хорошо с такой задачей справляется искусственный интеллект? Можно ли добиться высокого качества распознавания речи, когда на записи говорят несколько человек?
Не так давно мы отметили 1 миллион проданных устройств с виртуальными ассистентами Салют. В нашей линейке в числе прочего представлены farfield-устройства, то есть те, с которыми можно “разговаривать” на расстоянии: смарт-дисплей SberPortal, ТВ-медиацентр SberBox Top и умная медиаколонка SberBox Time. В комнатах, где они стоят, может говорить одновременно несколько людей или играть телевизор, что существенно усложняет задачу распознавания. Иногда необходимость распознать больше одного голоса на записи возникает и у клиентов нашего API SmartSpeech — например, если это разговор двух людей.
В статье я расскажу, как мы решали эту проблему. Подробно остановимся на архитектуре нашего решения, узнаем о процессе её создания и возникавших сложностях, послушаем примеры работы системы.
Побочным продуктом нашей технологии является разделитель аудио на несколько каналов по говорящим. Для затравки вот пример его работы. Исходная запись:
Выделенная речь первого говорящего:
Второго:
Почему это важно?
Все основные подходы к распознаванию речи (Automatic Speech Recognition, далее ASR), включая современные end2end, рассчитаны на то, что на выходе будет только одна фраза.
|
ASR — это технология, преобразующая звук в текст и позволяющая людям использовать свой голос для общения с компьютерным интерфейсом. Как работает ASR? Системы распознавания речи делятся на несколько типов. Гибридные системы состоят из нескольких частей: акустическая модель предсказывает звуки языка (т.н. фонемы), далее с помощью словаря произношений и языковой модели получается текст. С развитием глубокого обучения и методов работы с большими данными стал возможен end2end (“сквозной”) подход — акустическая модель сразу предсказывает текст. |
Если говорят несколько человек одновременно, то для модели это незнакомый класс данных (out-of-domain), и она может выдавать неправильные результаты.
Один из подходов для решения таких проблем — добавить эти случаи в обучающую выборку, разметив то, что мы хотим получить на выходе. Пример: пользователь обращается к виртуальному ассистенту в комнате с работающим телевизором. Мы размечаем только обращение. К сожалению, такая разметка трудозатратнее и не всегда выходит качественной. При этом сложно набрать достаточный объём таких данных.
Есть более сложные случаи. Пример из реальной жизни:
Взрослый говорит: “Включи Босс-молокосос”. Ребёнок продолжает: “Два!”.
Нужно понять, что ожидаемое действие — включить “Босс-молокосос 2”. Получается, в таком подходе на модель ложится сразу несколько задач: 1) распознать речь всех говорящих; 2) понять, кто из них обращался к ассистенту; 3) если обращались несколько человек, то правильно скомпоновать запрос из их реплик. Скорее всего, у нас не хватит данных, чтобы научиться разбирать все случаи. С другой стороны, если бы мы знали результат распознавания по каждому говорящему, то получили бы больше контроля: определить финальный запрос можно с помощью более сильной NLP-системы или эвристик.
До этого момента мы говорили о работе виртуальных ассистентов Салют, но это не единственный сценарий использования ASR. Во внутренних продуктах мы также сталкиваемся с задачей, которую называем транскрибацией, когда нужно распознать длинную аудиозапись — например, подкаст. Такую задачу также хотят решать клиенты нашего внешнего API SmartSpeech. Типичный сценарий в таких записях — необходимость интерпретации перекрывающейся речи нескольких человек (высказывания накладываются друг на друга). Здесь не применимо понятие «основной запрос», нам нужна разбивка по фразам каждого говорящего — своеобразная «стенограмма» речи. Как выйти из этой ситуации? Доработать систему так, чтобы мы могли определять число говорящих и выдавать несколько транскрипций, по одной на каждого из них.
Способы решения задачи
В начале работы над проектом мы рассматривали несколько подходов. Первый вариант — интегрировать всё в одну модель ASR, которая будет иметь несколько выходов, или добавить в целевой текст специальные токены, разделяющие говорящих (пример: [2006.10930] Joint Speaker Counting, Speech Recognition, and Speaker Identification for Overlapped Speech of Any Number of Speakers). Среди недостатков такого способа — необходимость полностью менять подход к обучению и дополнительная нагрузка на модель ASR. При этом нужно аккуратно обучать, чтобы не потерять в качестве на single-speaker данных — т. е. тех, где говорит один человек.
Второй вариант, на котором мы в итоге остановились, заключается в том, чтобы добавить предварительный этап — разделение аудио. На этом этапе из одной аудиодорожки с N говорящими получается N дорожек с одним говорящим в каждой.
Мы попробовали воспроизвести подход из статьи [2003.01531] Voice Separation with an Unknown Number of Multiple Speakers, где используются рекуррентные нейронные сети (RNN). Нам удалось получить некоторые результаты, но в это время вышла статья Attention is All You Need in Speech Separation, в которой RNN заменены на Sepformer — особую версию модели Transformer. Мы решили попробовать обучить её и применить к нашим данным — и увидели заметное улучшение в качестве распознавания.
Вот пример для сравнения. Мы взяли подкаст “Хочу не могу” (сам подкаст из категории 18+, но конкретно эта запись безопасная).
Исходная запись:
Два канала из RNN:
Два канала из Sepformer:
Результаты модели нас устроили, и мы начали думать над тем, как её применить — так родилась идея архитектуры будущей системы:

Идея вкратце:
Звук поступает в специальный классификатор (multispeaker classifier), который определяет N — число говорящих.
Если N > 1, отправляем запись в разделитель, получаем N аудиоканалов.
Прогоняем распознавание отдельно на каждом из каналов, получаем N транскрипций, плюс ещё одна от неразделённой записи.
(опционально) Отдельная модель под названием channel classifier получает разделённые аудио и транскрипции и выбирает, где основной запрос.
Теперь рассмотрим каждый шаг более подробно.
Компоненты системы
Multispeaker classifier
На этом этапе нам важно как можно скорее определить, по какой из ветвей пойдёт пайплайн: пока мы этого не узнали, ничего посчитать не можем, а значит, мы увеличиваем время обработки запроса. Исходя из этого, модель должна быть достаточно маленькой и опираться только на звук, потому что к моменту её запуска мы ещё не получили результат ASR. На практике, даже если на записи больше одного говорящего, всё равно выгодно знать результат распознавания исходного аудио, потому что иногда оно оказывается точнее всего. Поэтому его мы запускаем параллельно с прогоном записи через классификатор. Мы обучили модифицированный ResNet18 на спектрограммах. Модификация была достаточно простая: поменяли число каналов во входе с трёх на один, поменяли количество классов на выходе. Классов всего 3: N = {0, 1, 2}, где N — количество говорящих. Случаи N > 2 достаточно редки, и их сложнее обрабатывать, поэтому в первой итерации мы решили их не рассматривать.
На этом этапе для проверки, что всё работает правильно, мы считаем стандартные метрики классификации: accuracy, precision, recall, F1.
Speaker separator
Давайте теперь посмотрим на самую «тяжёлую» и при этом интересную часть всей системы. В нашей реализации она следует статье «Attention is All You Need in Speaker Separation», про которую я говорил выше. Модель называется Sepformer, это Transformer-подобная архитектура. Но прежде чем мы перейдём непосредственно к ней, рассмотрим общую структуру, используемую во многих подходах к speaker separation. На базовом уровне она выглядит следующим образом:

На вход модели подаётся waveform’а, она предобрабатывается энкодером — как правило, свёрточным — для получения признаков. Далее на основе этих признаков для каждого из итоговых каналов предсказывается маска, которая затем умножается на эти признаки (этап Separation, разделение). Получаем разделённые представления, которые остаётся превратить обратно в waveform’ы — этап Decoder. В декодере, как правило, используются транспонированные свёртки, т. е. просто обратная операция к энкодеру.
Sepformer — это одна из моделей для этапа разделения, основанная на архитектуре Transformer. Основная проблема применения такого рода моделей к задаче — это квадратичное от длины входа время работы механизма attention, используемого внутри Трансформеров, что делает вычисления очень медленными при большой длине. Проблемы с длиной также испытывают рекуррентные нейронные сети (RNN), но по другой причине: их нельзя применять параллельно по временному измерению, можно только последовательно. Чтобы побороть эту проблему, авторы предшествующей Sepformer’у статьи ([1910.06379] Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation) придумали Dual-Path механизм:

Подпись: Источник: Dual-path RNN: efficient long sequence modeling for time-domain single-channel speech separation
Длинный вход разделяется на окошки («чанки») с пересечением, полученные матрицы склеиваются в один тензор и обрабатываются параллельно. Причём сначала модель применяется независимо внутри чанков, а затем тензор транспонируется, и другая ветка модели обрабатывает одинаковые timestep’ы разных чанков. На картинке выше это показано в правой части, обратите внимание на разные «разрезы» тензора внизу. Таким образом, мы решаем сразу две проблемы: лучше учитываем глобальные и локальные зависимости (RNN/attention смотрят как внутри чанка, так и на все чанки вместе), а также уменьшаем проблемное временное измерение в обоих случаях.

Подпись: Архитектура Sepformer (источник: [2010.13154] Attention is All You Need in Speech Separation).
Как обучается такая модель? Поскольку очень тяжело получить «настоящее» разделение из реальных многоголосных записей, мы идём в обратную сторону. При обучении модель получает две аудиозаписи, усреднённые с некоторыми весами, и должна выдать исходные аудио. Оптимизируем лосс-функцию SI-SNR (scale-invariant signal-to-noise ratio). Определение — на картинке (взято из статьи):

На пальцах это можно объяснить следующим образом. Мы разделяем предсказанный звук на две части: то, что совпадает (или сонаправлено) с таргетом, и шум. Тогда метрика — это отношение мощности сонаправленной с таргетом части к мощности шума. Чем SI-SNR больше, тем лучше, поэтому надо взять всё минусом, чтобы получить нашу функцию потерь.
Обучившись таким образом, модель начинает неплохо разделять реальные многоголосные аудио.
Здесь важно отметить, что, как и в случае обучения акустической модели ASR, старт с предобученных английских весов очень помог стабилизации обучения и повышению качества.
Как оценивать качество? Во время обучения можно опять же смотреть на SI-SNR на синтетике. Но в реальности главное для нас — хорошо распознавать, поэтому мы можем применить нашу модель к реальным многоголосным записям, посчитать результат распознавания на обоих каналах и использовать стандартную метрику WER (Word Error Rate):
WER = (S + I + D) / (количество слов в транскрипции),
где S — количество замен, I — вставок, D — удалений. Например, пусть на записи было сказано «пожалуйста, поставь будильник», а модель распознала «поставь бумер». Тогда у нас будет одно удаление (пропало слово «пожалуйста») и одна замена («будильник» -> «бумер»). Отсюда
WER = (1 + 0 + 1) / 3 = ⅔ = 66.6%.
Остаётся одна проблема, что у нас два канала, и их нужно поставить в соответствие транскрипциям. Эту проблему можно решить на уровне метрики: попробуем оба варианта соответствий (первый канал с первой транскрипцией, второй со второй — или наоборот), сравним WER и выберем минимальный. Мы называем такую метрику permutation-invariant WER, или PI-WER. Её можно обобщить на случай более двух каналов, перебирая все перестановки длины N, где N — число каналов/транскрипций.
Теперь для случая, когда нужно распознать отдельно речь обоих спикеров, уже всё готово. Для виртуальных ассистентов же у нас, как правило, есть только одна транскрипция — с основным запросом. В этом случае мы считаем oracle WER, т. е. WER в случае, когда у нас есть «оракул», умеющий выбирать лучшую гипотезу из набора:
Oracle WER = min(WER(hyp1, target), WER(hyp2, target), …)
Такая метрика позволяет оценить потенциал улучшения на срезе многоголосных запросов, поступающих к ассистенту. В нашем случае мы увидели потенциал для улучшения качества почти в 2 раза. Ещё около 10% можно выиграть, добавив результат распознавания по исходной, неразделённой, аудиозаписи. Результаты выглядели впечатляюще, но оставался вопрос, как нам получить своего «оракула». Об этом — в следующем разделе.
Channel classifier
Наша задача — определить, в какой из каналов в итоге попал запрос (для простоты рассматриваем исходную запись как ещё один канал). Для этого мы отправляем все каналы в ASR, а затем поверх результата применяем классификатор. На этом этапе у нас есть максимум информации: помимо фичей по самим аудио есть ещё различные скоры из декодирования (вероятности из акустической и языковой моделей, а также предсказания вспомогательных моделей). Всё это мы отправляем в Catboost, который решает задачу классификации. Целевые переменные для этой классификации мы определяем в зависимости от WER каждой из гипотез.
Конечно, получившаяся модель не выдаёт стопроцентную точность, но тем не менее нам удалось выжать чуть больше половины от потенциального профита, т. е. итоговое относительное улучшение WER в районе 30% — заметный выигрыш.
Как же выглядит весь процесс обработки? Допустим, нам пришла на распознавание такая запись:
Мы её параллельно отправляем в ASR (получаем «Покажи новости, господа.») и в mulitspeaker classifier. Классификатор говорит, что здесь два говорящих. Разделяем и отправляем каждый канал в ASR.
Первый канал (распознаётся «Покажи новости про спорт.»):
Второй канал (распознаётся «А что сегодня на обед?»):
Теперь channel classifier смотрит на все три записи и гипотезы ASR и выбирает запрос «Покажи новости про спорт.», который передаётся дальше и в результате приводит к ожидаемому поведению ассистента.
Применение
Кратко расскажу про то, как мы готовили весь этот пайплайн к продакшену. С channel classifier’ом всё просто: у библиотеки Catboost, в которой он был обучен, есть C++ API для инференса. Остальные две модели — нейросети, их мы обучаем с помощью PyTorch, а затем конвертируем в ONNX для CPU/GPU инференса. В случае GPU мы получаем большое ускорение за счёт конвертации весов в fp16.
Результаты
Нам удалось построить систему, с помощью которой мы смогли получить относительное улучшение WER в 30% на срезе многоголосных записей. Кроме того, мы теперь можем транскрибировать речь каждого говорящего на двухголосных записях.
Как попробовать? Клиенты SmartSpeech API уже сейчас могут воспользоваться новым режимом распознавания, подробно об этом можно почитать в документации. Кроме того, в ближайшее время мы планируем улучшить с помощью этой технологии распознавание речи в наших умных устройствах Sber.
Ну и напоследок ещё один пример разделения сложной аудиозаписи с накладывающейся речью:
Исходная:
Первый канал:
Второй канал:
Комментарии (13)

lazil
29.08.2022 19:00+1Ошибка во втором канале, распознало «А что сегодня на обед?», а говорит "Мам, что сегодня на обед?"

Bobrosoft Автор
29.08.2022 19:11Да, идеального распознавания во всех случаях мы пока не достигли, бывают ошибки. :) Но в данном случае на результат работы ассистента это не влияет.

nehrung
29.08.2022 21:19+1Не умаляя важности описанной работы, всё же рискну затронуть ещё более важную (на мой взгляд), которая от описанной чуть в стороне.
Есть у меня приятельница, от рождения лишённая слуха. Разумеется, она давно и в совершенстве освоила практически все виды коммуникации глухонемых (в т.ч. и чтение речи по лицу собеседника). Сама она речи не лишена, хотя этому её учили в детстве, естественно, без использования звуковой обратной связи, и потому получился своеобразный акцент.
Так вот, есть один способ коммуникации, который ей недоступен, но очень нужен — это разговор по телефону. Существующие речевые распознавалки нормально работают только по чистому звуку прямо с микрофона, но если звуковой сигнал прошёл телефонный канал, который сузил полосу частот и добавил шумов и нелинейных искажений, распознавание резко ухудшается и становится малопригодным для практики. Мы перебрали весь софт на эту тему, до какого смогли дотянуться, и ничего подходящего не нашли. Может, вы, как профессионал, чего-нибудь посоветуете?
sbars
29.08.2022 22:25Сам не пробовал, но может вариант обмена голосовыми сообщениями через телеграм подойдёт, с распознаванием голосового сообщения в одну сторону в текст ботом (похоже есть разные варианты, в том числе с исходниками https://github.com/graynk/voicos)?
Bobrosoft Автор
29.08.2022 23:06+1По конкретным решениям для вашей задачи не смогу подсказать, но распознавание речи из телефонии точно возможно. Например, у нас в сервисе для этого есть модель callcenter (https://developers.sber.ru/docs/ru/smartspeech/recognition-overview#akusticheskie-modeli).
nehrung
30.08.2022 00:33Софт для колл-центров — это мы пробовали. Оказывается, всё опробованное ориентировано на ограниченный словарь — только на нём удаётся добиться распознавания телефонной речи, достаточно точного для практического применения. А софт по вашей ссылке, насколько я могу судить, ориентирован не на обычный разговор, а на обработку «звуковых консервов» (аудиофайлы). В нашем же случае хотелось бы трансляции в текст обычной разговорной речи в темпе её произнесения (с приемлемой задержкой, порядка 2...4 сек), а уж с потерей интонационной и прочей эмоциональной составляющей мы как-нибудь смиримся.
Подозреваю, во многих конторах сейчас пытаются воспитать ИИ, способные на это, но до практической готовности, думаю, там далеко.Bobrosoft Автор
30.08.2022 08:33+1Если я правильно понял запрос, то режим потокового распознавания как раз решает такую задачу: https://developers.sber.ru/docs/ru/smartspeech/recognition-stream

mbait
30.08.2022 05:25А есть пример, где F0 говорящих ближе друг к другу? А то так не совсем понятен успешный успех всей затей - высокий женский и низкий мужской голоса можно разделить обыновенными полосовыми фильтрами.
Bobrosoft Автор
30.08.2022 12:14+1Есть даже несколько, сделали плейлист: https://on.soundcloud.com/BACW (аккуратно, один из примеров 16-18+, он помечен).
Ogoun
Купил Алису и SberBox Time. Алиса распознает практически идеально, время отклика незаметно, из минусов - отсутствие HDMI. Поэтому взял колонку сбера чтобы зацепить к монитору, но на наличии HDMI плюсы и закончились. Нужно выговаривать четко, и громко. Некоторых людей в принципе отказывается слышать. Далеко не всегда понимает что ему сказано. И почему то очень долгий отклик. Если бы не возможность перепрошивки и подключения к монитору сдал бы сразу. А так использую как tvip приставку, практически не используя голосовое управление, т.к. оно бесполезно.
И пожалуйста, разработчики Сбербанка, учитывайте что не у всех людей есть Сбербанк онлайн. Эта привязка к нему где только можно мешает неимоверно. Например, я регистрируюсь, покупаю подписку Прайм, и теперь не могу зайти через SberId чтобы подключить на устройстве, т.к. пуши мне идут в несуществующий Сбербанк.Онлайн. Пробовал на другой номер, на который когда то много лет назад был подключен сбербанк онлайн, потом ушел. И теперь оказывается что этот номер телефона нельзя использовать для регистрации для использования SberboxTime, потому что он как то там заблокирован банком. Это же разные системы.
Ну и поддержка ожидаемо помочь не в силах. Максимум что смогли посоветовать, - другой номер. На текущий момент это нельзя считать готовой умной системой, скорее набор разного уровня сырости сервисов кое как скрепленных друг с другом.
ReadOnlySadUser
Но ведь есть станция Макс с Алисой. Там есть HDMI :)
Ogoun
Да, в плане на покупку есть, на sbertime скикда была, захотел посмотреть и сравнить.
djunka
Здравствуйте! По проблемам/вопросам с девайсом, репорт бага можно писать в чат https://t.me/sberdevices_chat