
Сегодня у нас — экшен, основанный на реальных событиях. Будем переобуваться в воздухе и на лету менять архитектуру высоконагруженной системы.
Действие разворачивается на базе очень большой track & trace системы класса big data. В ней давно откладывали переход на шардированную архитектуру хранилища. Поэтому главному герою предстоит справиться со злом, пробудившимся в системе под нагрузкой: деградацией производительности, полкой по блокировкам и алертами о перегрузке.
В конце — как обычно, хэппи-энд. Наш герой бесстрашно меняет архитектуру решения на лету без downtime (DT) и обеспечивает штатную работу системы. Зло повержено, а отважный инженер купается в овациях!
Статья написана по мотивам доклада на конференции Saint Highload++ 2022. Если не хотите читать — можно посмотреть видео-версию выступления.

Track & Trace — этот класс систем, предназначенный для обеспечения сквозного бизнес-процесса по отслеживанию статуса движения различных групп товаров в логистических цепочках. Затрагивает все этапы жизненного цикла: от производства до продажи или другого конечного состояния (списание, уничтожение и т.п.).

Исходное решение
Пара слов об архитектуре решения обработки данных. Упрощенный pipeline выглядит следующим образом:
имеется источник, данные с которого поступают во входящую очередь на обработку, построенную на базе kafka;
в приложении реализован kafka consumer для вычитки данных из очереди;
далее сам процессинг и сериализация его результатов в оперативное хранилище.
В качестве основной СУБД используется NoSQL СУБД MongoDB.
И, казалось бы, где тут могут возникнуть проблемы? Ведь вендор все продумал: данная СУБД изначально проектировалась с широкими возможностями для горизонтального масштабирования и хорошо держит высокую нагрузку?
Проблема в том, что очень часто — особенно на начальном этапе развития системы/проекта — в погоне за функциональными возможностями, банально не хватает времени подумать о долгосрочной перспективе. Что будет с жизнеспособностью созданного решения под нагрузкой? К моменту, когда возникают проблемы, накопленные объемы данных могут исчисляться десятками и даже сотнями терабайт.
И наш кейс — не исключение. Исходно имеем инсталляцию СУБД MongoDB, которая развернута в топологии Single ReplicaSet, а не полноценного шардированного кластера, не говоря уже о гео-репликации, о которой остается только мечтать.
Replica Set — кластер серверов MongoDB, реализующий механизм репликации master-slave и автоматическое переключение между ними.

Немного сухих цифр ТТХ нашего решения:
Write RPS: ~10K ops/s
Read RPS: ~15-20K ops/s
Uncompressed dataset: ~100TB
Дисклеймер: о чем я не буду говорить в статье
Рецепты построения архитектур highload систем. Тут у каждого свой подход
Горизонтальное и вертикальное масштабирование приложений.
Масштабирование Kafka
Семантики доставки в Kafka (at least once, at most once, exactly once)
Архитектура, отказоустойчивость и масштабирование СУБД MongoDB
Теперь перейдем к основной проблематике
Ничего не предвещало беды, система перемалывала довольно интенсивную входящую нагрузку. Но в один прекрасный день все дэшборды системы мониторинга буквально сошли с ума, а службу эксплуатации завалило алертами. Зафиксирована аварийная деградация производительности системы процессинга и резкий рост входящих очередей задач на обработку! Полный Ахтунг!

Стали разбираться, в чем дело. Включили онлайн-профилирование в приложении и обнаружили «нежданчик» — мы уперлись в производительность СУБД! Предвосхищая вопросы: на тот момент у нас было порядка 7 млрд записей.
В такие моменты вспоминается цитата известного персонажа: «Никогда такого не было и вот опять».
Копаем дальше. В закромах системы мониторинга находим данные экспортера монги, а там — полочка по блокировкам! Речь идет про Read and Write tickets, которые в MongoDB используются для организации конкурентного доступа.

«Какая прелесть!» — скажете вы и будете совершенно правы!
Итак, мы приплыли: у нас в СУБД 100ТБ данных и ровно 0 шансов просто взять и перешардировать такой объем без ДТ.
Паникеры уже кричат – «Все пропало! Что же делать?»
Решаем проблему
К черту эмоции, включаем холодный разум.
Вспоминаем устройство движка WiredTiger, который является основным и используется по умолчанию в MongoDB. С точки зрения файлового хранения там все просто: вся коллекция на конкретном узле СУБД лежит в одном файле (<коллекция>.wt), плюс по файлу на каждый индекс (<индекс>.wt). Лезем в папочку с файлами данных СУБД и — «бинго» — там нас ждут файлики, размеры которых измеряются в ТБ.

Логика подсказывает, что все дело именно в размере файла с данными.
Первое решение, которое приходит в голову — надо резать данные на куски (делать split). Внимательный читатель скажет: «Но, позвольте, то же самое делает шардированная СУБД!» Все верно, только у нас нет возможности шардироваться средствами СУБД прямо сейчас — от слова совсем.
Будем сплитить данные на уровне приложения наживую. Как говорится, слабоумие и отвага — наше все, а других вариантов все равно нет.
Как реализовано шардирование практически в любой СУБД? Да, хэширование нам в помощь. Осталось понять, какую hash функцию взять. В этом случае берем Adler32. А вообще выбор hash функции — очень важная история, но это тема для отдельной статьи.
Разбиваем наш dataset (супер-коллекцию) на N кусков (N небольших коллекций) и дописываем небольшую обертку в приложении в части слоя доступа к данным. Правда, новая конструкция актуальна только для свежих данных, и мы начинаем с пустого датасета.
Что же делать с уже существующим огромным файлом? А давайте растаскивать его на куски по мере обращения к данным в нем чтобы избежать ненужного ДТ для миграции, который мы себе не можем позволить.
Еще немного допилим data access layer. Пробуем запускаться в production — всё заработало и блокировки ушли!
Резюмируем в двух словах
Мы распилили один супер-гигантский dataset на N кусков, не меняя топологию СУБД. Тем самым избавились от непрерывных блокировок на уровне СУБД и нормализовали производительность обработки данных в приложении.

Пробежимся по плюсам и минусам подхода
Плюсы:
применяем, когда нет возможности шардироваться средствами СУБД прямо сейчас (очень большой объем данных, нет инфраструктуры под шардированный кластер СУБД и т.д.);
не останавливаем production (no downtime);
подход позволяет ускорить вставку и другие операции (снизить деградацию, связанную с ростом данных за счет уменьшения кол-ва блокировок);
не требует начальной миграции данных, т. е. перенос данных из единой необъятной супер-коллекции в отдельные (splitted) небольшие коллекции происходит постепенно по мере обращения к документам.
Минусы:
управление разделенными данными приходится реализовывать на уровне приложения, а не на уровне СУБД;
сложно искать данные без использования специальных утилит;
есть предел, т. к. всё равно ограничены возможностями вертикального масштабирования.
Казалось бы, проблема решена. Но, на самом деле, не до конца.
Находим и решаем проблему #2
Рано или поздно (как показывает практика, скорее — рано) мы упремся в пределы вертикального масштабирования. Тогда нам придется переехать на полноценную шардированную СУБД. Осталось придумать, как это сделать!
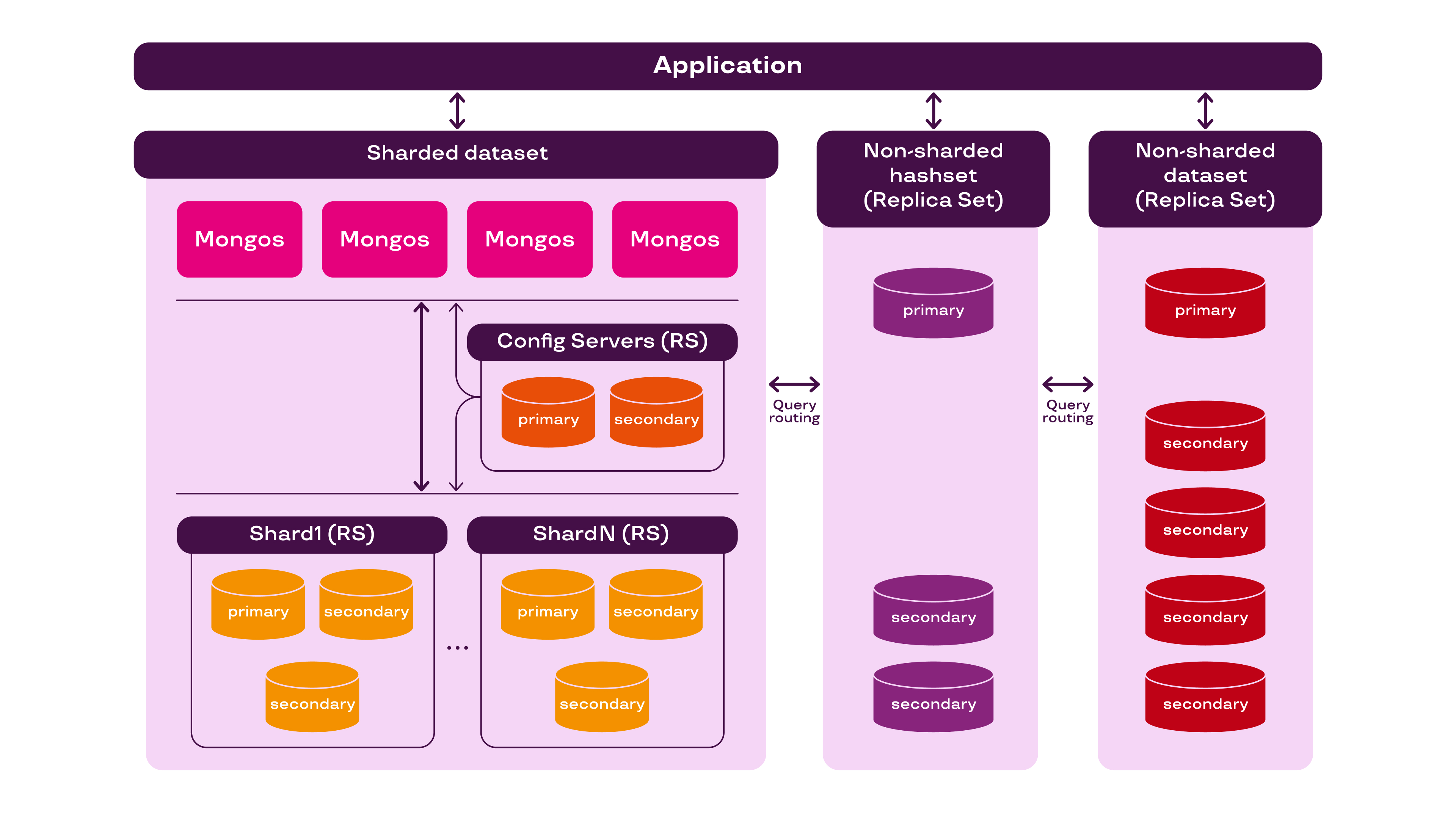
А что, если замутить параллельную эксплуатацию двух СУБД — старой (нешардированной) и новой (в шардированной конфигурации). Идея классная, нужно как-то реализовать.
Начинаем накидывать идеи:
В новой СУБД будут жить все новые данные, начиная с момента запуска параллельной эксплуатации.
В старой — продолжат жить старые данные.
Нужна маршрутизация запросов между старой и новой базами.
Основной вопрос в текущей постановке задачи — как организовать маршрутизацию запросов в зависимости от входных параметров? Тут поможет традиционный подход с организацией большой таблицы маршрутизации.
В нашем случае нужно заполнить таблицу условными указателями на данные в старой СУБД, т. к. набор данных в ней остается статическим с точки зрения ключей доступа.
Очевидно, что хранить миллиарды записей в файлике просто невозможно. Поэтому необходимо поднять отдельный экземпляр СУБД. Чтобы уменьшить объем хранения и ускорить поиск, запишем в таблицу маршрутизации хэшированное значение ключа исходной записи. Для минимизации коллизий будем использовать алгоритм семейства SHA.
Конечно, нам придется инициализировать этот гигантский hashset до начала эксплуатации. Хорошая новость в том, что в это время мы продолжим использовать старую СУБД в прежнем режиме. значит, тут обойдемся без ДТ.
Немного о тонкостях построения hashset для такого объема данных. Несмотря на то, что алгоритмы семейства SHA обеспечивают минимальные коллизии, но они все же есть. Для таких кейсов мы предусмотрели хранение списка самих ключей рядом в хэшом в качестве доп. метаданных для разрешения возникающих коллизий.
Немного допиливаем data access layer в приложении запускаем параллельную эксплуатацию. Конечно, не забыв провести профилирование маршрутизатора на стенде нагрузочного тестирования. Все работает!
Краткое резюме проделанной работы
Мы подняли новый кластер шардированной СУБД для новых данных. При этом старый не погасили и данные из него не переливали в новый. Используя связующее звено в виде маршрутизатора запроса на базе отдельного экземпляра СУБД, в котором хранится статическая таблица маршрутизации, нам удалось запустить полноценную параллельную эксплуатацию двух СУБД с перспективой отказа от старой СУБД и полного перехода на целевую топологию. При этом нам удалось избежать ДТ.
Проанализируем реализованное решение
Плюсы:
не останавливаем production (no downtime);
не нужно заниматься перешардированием данных (требует downtime);
запускаем sharded db с пустым dataset или делаем миграцию сабсета данных, которые наиболее востребованы (самые свежие, часто обновляются, business critical и т. п.);
продолжаем эксплуатацию старой non-sharded db в параллельном режиме.
Минусы:
дополнительные издержки при эксплуатации расширенной архитектуры хранилища (две инсталляции СУБД + отдельный экземпляр под маршрутизатор);
статическая таблица маршрутизации запросов до старта параллельной эксплуатации требует инициализации (для всех сущностей в нешардированной СУБД).
Пара слов о компактификации
Слегка коснусь и другой проблемы, связанных с эксплуатацией СУБД такого объема, а именно компактификации. Спойлер: тут все грустно, но решение тоже есть!
Компактификация позволяет уплотнить данные в СУБД. А значит, уменьшить disk footprint (след наших данных на физическом носителе — размер файлов с данными). Это позволит максимально отдалить проблемы, подобные рассмотренной нами.
Штатная утилита MongoDB compact совсем не работает на таких объемах.
Сжатие работает только с помощью процедуры initial sync, т. е. путем создания новой реплики с нуля путем репликации, но очень долго.
Быстро создать новую реплику можно только прямым копированием. Конечно, тиражировать лучше реплику, которую получили сжатием с помощью процедуры initial sync.
Есть и другие особенности эксплуатации, например, как сделать бэкап такой большой СУБД. Но это тема для отдельной статьи, т. к. задача — мягко говоря, нетривиальная.
Делаем выводы
Пришло время подведения итогов.
Мы решили задачу по смене архитектуры решения на лету в два этапа:
потушили пожар, отшардировав данные на уровне приложения, не меняя исходную топологию СУБД;
решили проблему окончательно и кардинально, запустив параллельную эксплуатацию двух СУБД (старой и новой), которая постепенно позволит отказаться от старой СУБД.
При этом в новой конфигурации на каждый шард приходится не более 2 млрд документов, а значит, нам удалось выиграть по серверным ресурсам в сравнении с исходным решением.
После доклада меня спросили, что бы мы выбрали, если бы строили хранение сейчас, с учетом накопленных знаний о требованиях системы? Ответ однозначен: мы бы остались на MongoDB. Она работает предсказуемо и прошла боевое крещение.
Несколько советов на основе полученного в процессе опыта
Стройте модели нагрузки до начала эксплуатации, даже если кажется, что все и так очевидно.
Прогнозируйте целевые объемы данных заранее. Это позволит сделать верный расчет инфраструктуры и выбрать топологию решения с перспективой роста объема данных в горизонте планирования 3–5 лет.
Разворачивайте СУБД сразу в шардированном виде вовремя (лучше на старте проекта), чтобы спустя время героически не преодолевать возникающую лавину проблем в production-режиме под нагрузкой и без DT. Это позволит сэкономить не только время и людские ресурсы, но и снизить затраты на инфраструктуру, т. к. не придется заниматься параллельной эксплуатацией сразу трех кластеров СУБД.
Ну и напоследок: все фокусы, трюки и фиксы, о которых я рассказал, выполнены профессионалами! Не наступайте на эти грабли в своих проектах, опасно для нервной системы! И помните, что решение можно найти всегда!
Комментарии (8)

BasilioCat
05.10.2022 02:33В трансляции задали резонные вопросы, из которых следует:
- Рассчитывать на появление коллизий в SHA256 — надо быть очень большим пессимистом
- на первом этапе не было железа для реализации шардов на нескольких серверах, но был диск для "партиций"
- Основная гигантская коллекция была просто key-value без дополнительных индексов
И кто помешал не городить велосипеды, а просто репартиционировать коллекцию средствами монги, а затем, при переходе к шардам, и шардировать — не ясно совсем. При том, что в итоге в эксплуатации осталась и старая база с программными партициями, а значит и логика в коде

akomiagin Автор
05.10.2022 12:21вероятность коллизий у SHA256 действительно низкая, но ненулевая. Просто пренебречь данным фактом недопустимо.
не понимаю как наличие диска решит вопрос шардирования. Топология в режиме шардированной СУБД имеет ряд дополнительных элементов, таких как Config Servers, mongos. etc, которые требуют вычислительных мощностей. Таким образом, без шардирования на уровне приложения все равно не получилось бы обойтись в той ситуации. Это был фактически единственный вариант. Все остальные требовали либо ДТ, либо доп инфраструктуры...
resharding средствами MongoDB на таких объемах требует длительного ДТ и сопровождается множеством артефактов типа дублей документов и прочее. Более того, оценить точные сроки и длительность этой процедуры просто невозможно. Таких инструментов в СУБД к сожалению нет. В ситуации когда production должен работать 24х7 такие риски были совершенно неприемлемы.

Cykooz
07.10.2022 10:27Интересно почему изначально была выбрана MongoDB, если у неё, по сути, есть только один достаточно существенный плюс - это простое шардирование из коробки? Но, как указано в статье, никто в самом начале даже не думал про шардирование.
igurylev
Было бы очень интересно узнать, как делать консистентный бекап такой базы.
akomiagin Автор
Вопрос создания полноценного консистентного бэкапа на таких объемах практически утопичен. Можно лишь говорить о создании неких работающих снэпшотов. И тут есть несколько вариантов - использовать штатный Ops Manager. Либо создавать копию прямым копированием реплики, предварительно исключив ее из RS. А можно просто держать необходимое кол-во реплик в RS. Так как одновременный отказ всех реплик в RS маловероятен. Ну или сочетание этих методик.
igurylev
Так вот про то и речь...
Как сказано в документации:
To capture a point-in-time backup from a sharded cluster you must stop all writes to the cluster. On a running production system, you can only capture an approximation of point-in-time snapshot.
Это к тому, что разворачивание sharded cluster на старте проекта может обернуться головной болью с резервным копированием. И, возможно, вариант с прикручиванием шардинга уже потом, когда проект перерастает возможности реплики (т.е. случай, описанный в статье) - не так уж и плох. Просто надо мониторить нагрузку в процессе роста, что делают не только лишь все.
BasilioCat
Логично бы снимать резервные копии с выделенных для этой цели реплик. Вот как их остановить в один момент для получения бэкапов в более или менее один момент времени… Альтернативный вариант — файловая система со снапшотами, может быть даже на общем для всех узлов хранилище. Но какой профит от центральной СХД и шарда из монг — довольно интересный вопрос.
akomiagin Автор
Да, бэкап хранилищ данных подобных объемов - это отдельный занимательный квест и кандидат на отдельную статью, посвященную только этой тематике!