
Я, технический директор компании STM Labs, Андрей Комягин, за несколько минут смогу переубедить всех скептиков и доказать обратное.

Недавно в мире IT случилось важное событие — институт IEEE опубликовал список самых востребованных языков программирования. Корону победителя с гордостью примерил Python. Это вполне закономерный результат, поскольку Python — бесплатный язык программирования с открытым исходным кодом и удобными структурами данных. Он запускается на любых ОС и поддерживает множество сервисов, сред разработки и фреймворков. К тому же, он подходит для новичков, и его просто выучить.

Если и этого мало, то давайте не будем забывать, что именно Python стал основой для создания веб-сервисов и мобильных приложений, без которых мы не смогли бы делать ряд важных вещей ежедневно. Например, не смогли бы смотреть ролики на YouTube или следить за жизнью знаменитостей в Instagram, заказывать такси в Uber и юзать такие площадки, как Quora, Pinterest, Blender, Inkscape и Autodesk. Все они написаны на Python и, пожалуй, уже даже этот факт возводит его в «лик святых» языков программирования.
По этим и многим другим причинам мы привыкли, что в области машинного обучения (ML) и больших данных (Big Data) Python – это уже стандарт де-факто. Но, как только мы начинаем говорить о highload системах, тут же «всплывает» устоявшийся стереотип о том, что высоконагруженные системы надо делать на чем-то быстром. Чаще всего в таких случаях я слышу фразу: «Лучше взять сишечку! (семейство языков программирования С/C++) или, на худой конец, Java или C#». И когда я привожу в пример YouTube и говорю, что мы успешно делаем highload системы на Python, некоторые мои собеседники морщатся от удивления…
Давайте вместе ломать стереотип: на конкретном примере я расскажу, как правильно использовать Python в режиме Fast and Furious и построить на нем крутую архитектуру highload системы!
Python vs пессимисты
В качестве задачи рассмотрим систему обработки событий или процессинга документов. Архитектура у них плюс-минус одинаковая и имеет следующий pipeline (ETL):
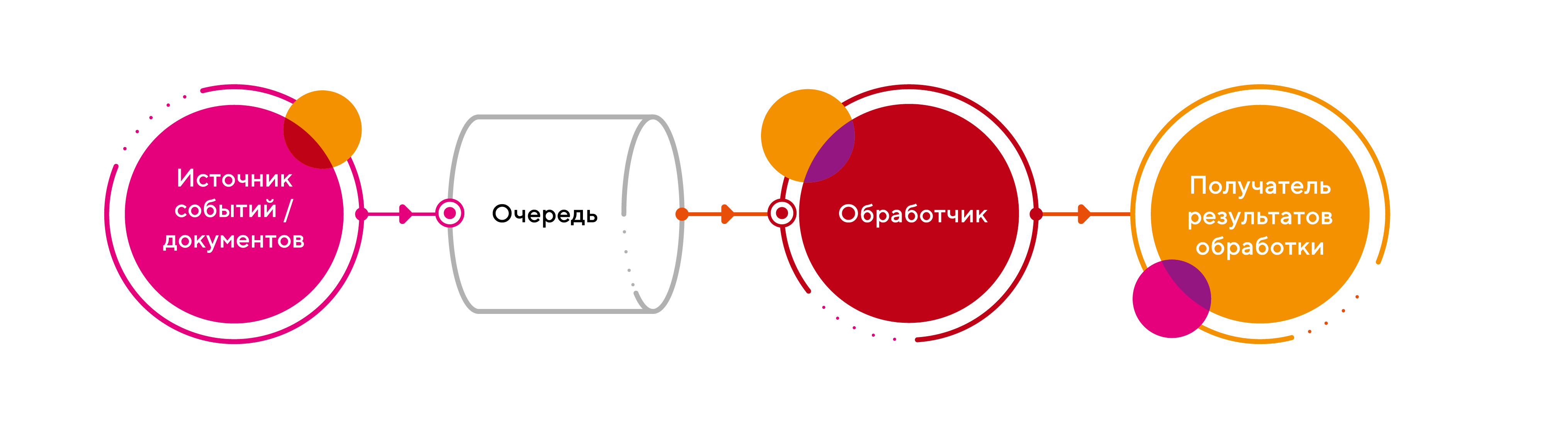
Для начала, решим задачу в лоб:
1. В качестве брокера возьмем Kafka;
2. В обработчике реализуем линейный процессинг сообщений из очереди на базе класса Kafka Consumer из библиотеки Kafka-Python;
3. Результат обработки запишем в СУБД MongoDb.
Имеем следующую схему:
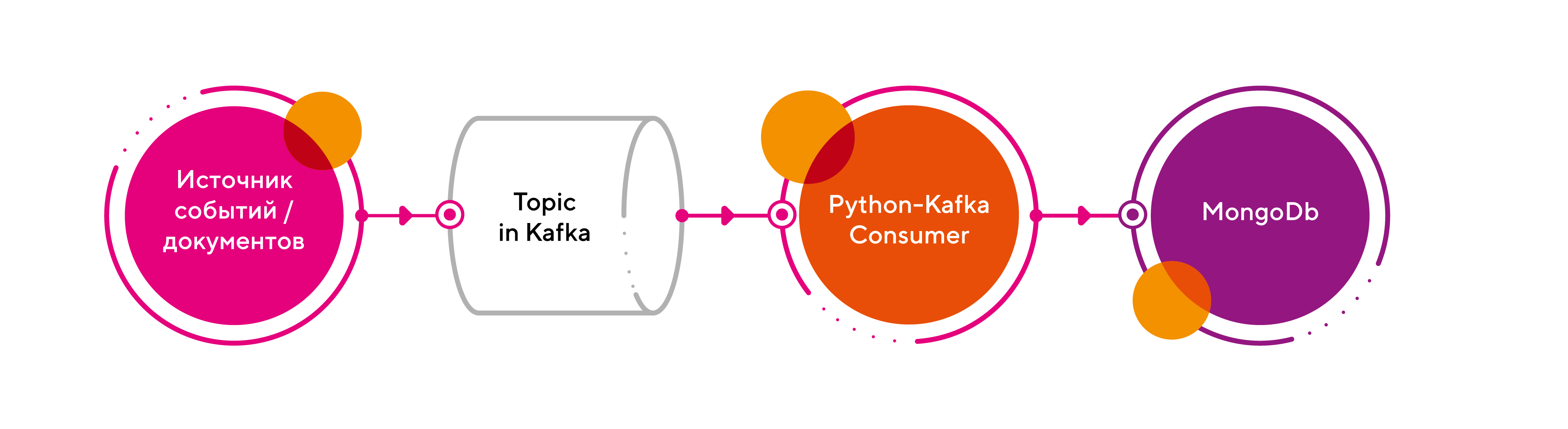
Приведу небольшой code snippet, как это реализовать:
from kafka import KafkaConsumer
from pymongo import MongoClient
from json import loads
# создаем консьюмера
consumer = KafkaConsumer(
"raw_events",
bootstrap_servers=["localhost:9092"],
auto_offset_reset="earliest",
enable_auto_commit=True,
group_id="my-group",
value_deserializer=lambda x: loads(x.decode("utf-8")),
)
# открываем соединение к MongoDb
# получаем доступ к нашей коллекции событий – processed_events
client = MongoClient("localhost:27017")
collection = client.processed_events
# читаем из топика и пишем в базу
for message in consumer:
doc = message.value
collection.insert_one(doc)
Работает, но процессинг очереди идет слишком медленно! Пессимисты уже кричат: «Все пропало! Что же нам теперь делать?». Мое решение простое и лаконичное – использовать процессный пул для параллельной обработки.

Чтобы понять, как это реализовать, приведу еще один короткий пример без лишних деталей. Задача – погрузить всю нашу логику обработки в пул воркеров, чтобы сделать процессинг параллельным, и вот как это выглядит:
from multiprocessing import Pool
def processing_func(msg):
# пишем тут в БД
store_data(msg)
# создаем пул воркеров из 16 процессов (лучше число ядер CPU х 2)
pool = Pool(16)
for message in consumer:
pool.apply_async(processing_func, (message,))
Давайте разберемся, как работает и что делает данный код:
- Создает пул из 16 процессов
- Читает очередь, но весь процессинг самих сообщений отдается воркерам из пула с помощью метода самого пула — apply_async
- Метод apply_async принимает на вход функцию, которая, собственно, и делает весь процессинг. В нашем случае — пишет данные в БД.
Готово, все летает! «А можно еще быстрее?» — спросите вы. Ответ однозначный – легко! Давайте воспользуемся штатными возможностями партиционирования топиков в Kafka.
Напомню, разбивка топика по разделам (партициям) – это основной механизм параллелизма в Apache Kafka, который позволяет линейно масштабировать нагрузку на консьюмеров. Ключевыми моментами этой концепции являются следующие:
- каждый топик может иметь 1 или больше разделов, распараллеленных на разные узлы кластера (брокеры), чтобы сразу несколько консьюмеров могли считывать данные из одного топика одновременно;
- если число консьюмеров меньше числа разделов, то один консьюмер получает сообщения из нескольких разделов;
- если консьюмеров больше, чем разделов, то некоторые консьюмеры не получат никаких сообщений и будут простаивать;
- для повышения надежности и доступности данных в кластере Kafka, разделы могут иметь копии (реплики), число которых задается коэффициентом репликации (replication factor). Он показывает, на сколько брокеров-последователей (follower) будут скопированы данные с ведущего-лидера (leader);
- число разделов и коэффициент репликации можно настроить для всего кластера или для каждого топика отдельно.
Итак, добавим партиций (3 шт) для нашего топика raw_events и на каждую партицию поставим отдельный экземпляр консьюмера (тоже 3 шт). Поскольку количество партиций можно динамически увеличивать, то имеем бесконечный горизонт масштабирования! Что может быть прекраснее?
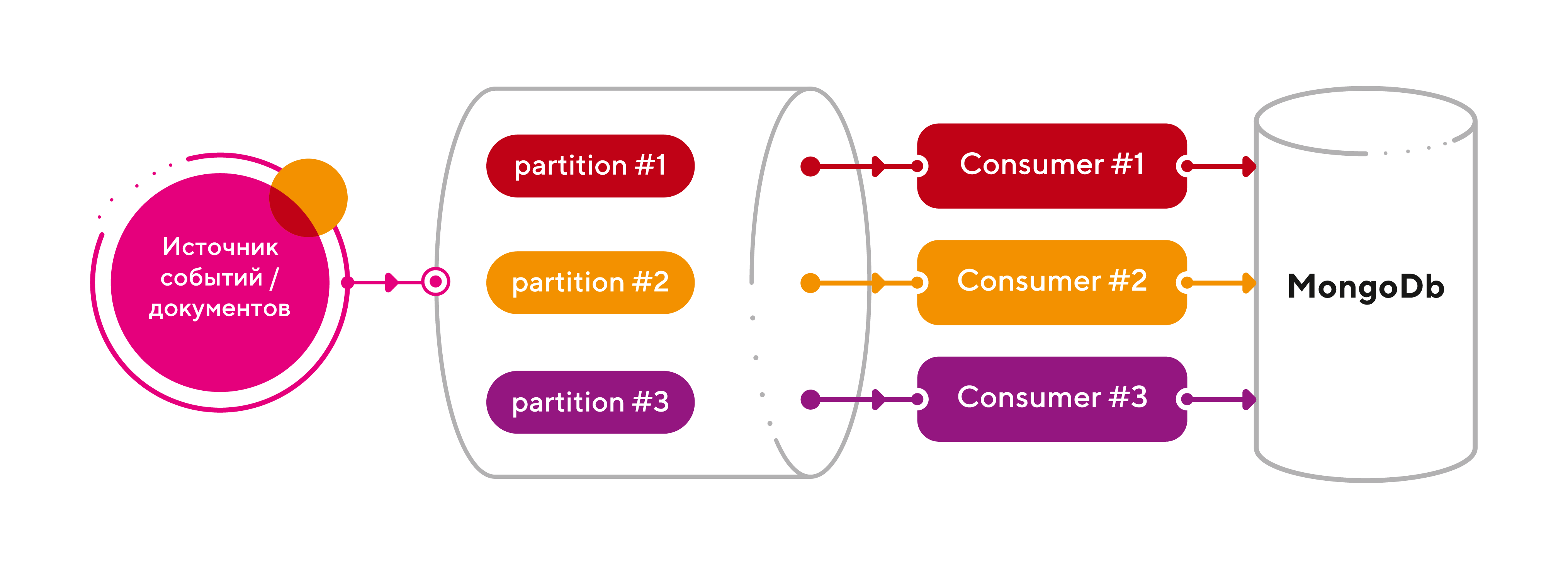
Подведем итоги: мы получили отличную архитектуру для highload системы, затратив на это 5 минут времени. При этом, нам не пришлось менять любимый язык программирования, а значит, жертвовать гибкостью и скоростью разработки.
Комментарии (41)

des1roer
15.12.2021 15:02+1только вот питон и правда медленный как показывают бенчмарки...
https://www.techempower.com/benchmarks/#section=data-r20&hw=ph&test=json&l=zijlz3-sf

akomiagin Автор
15.12.2021 15:25-1Вы совершенно правы, именно поэтому, чтобы решить эту проблему, мы применили multiprocessing для горизонтального масштабирования

CaerDarrow
16.12.2021 21:34Но у вас же статья называется "Как выжать максимум из питона")
Выжимается из него далеко не максимум. Например, для десериализации жсона, можно выбрать https://github.com/ijl/orjson (который окажется под капотом вовсе не питоном, а растом). Ну и воркер, который переписывает из очереди в базу, кажется, что прилично будет занят I/O, поэтому можно еще попробовать asyncio (правда, асинхронный драйвер для монги на питоне не оч). Сниппет с кодом, при этом всем, увеличиться не то, чтобы очень сильно.
Ну и по-честному, мультипроцессингом вы максимум выжимаете не из питона, а из железа.akomiagin Автор
16.12.2021 22:50+1Вы правы, мы старались утилизировать железо по максимуму. И, на мой взгляд, тут важен именно кумулятивный эффект. А по поводу оптимизации самой сутевой части процессинга, то да - тут есть простор для улучшений. Кстати, Orjson - действительно классная библиотека. Мы ее активно применяли в ряде промышленных решений, т.к. обнаружили, как раз при профилировании, что стандартный json serializer не очень производителен... И даже контрибьютили ряд улучшений в части сериализации дат. Возможно, напишем об этом отдельную статью.

crion
15.12.2021 15:43+3А запись в базу у вас как происходит, синхронно? Тогда всё понятно, ничего оно быстрее не станет работать.
akomiagin Автор
15.12.2021 15:53+1Да, синхронно, и на первый взгляд может показаться, что производительность всей системы упирается исключительно в производительность СУБД. Но при этом, важно помнить, что MongoDb обеспечивает достаточно гибкие механизмы конкурентной обработки запросов - https://docs.mongodb.com/manual/faq/concurrency/#faq-concurrency
И чтобы задействовать эти механизмы, заложенные в самой БД, мы со стороны приложения должны обеспечить передачу запросов в базу максимально оперативно, в чем нам и помогает multiprocessing.
Помимо этого, повлиять на скорость записи, можно путем тюнинга write concern в СУБД - https://docs.mongodb.com/manual/core/replica-set-write-concern/

cepera_ang
15.12.2021 16:00+8Неужели это и правда уровень понимания современных программистов в общей массе? "Вхуж, мультироцессинг, теперь всё быстро!". Теперь восьмироцессорный сервер полностью загружен записыванием байтов из одного файла в другой через трёх посредников с огромной скоростью. С какой, кстати? Как близка эта скорость к теоретическому максимуму для этой машины? А, хотя пофиг, "время разработчиков дороже, добавим ещё десяток серверов, у нас ведь хайлоад, 100rps в секунду!"
akomiagin Автор
15.12.2021 16:07Спасибо за мнение! Отмечу, что multiprocessing - это, конечно, лишь один из инструментов для решения данной задачи. Существуют и другие варианты оптимизации и архитектурные подходы к решению.

suns
15.12.2021 17:09+2Ага, один из вариантов оптимизации на питоне - переписать все на, о боже, сишечку и предоставить питонячий интерфейс
Или пересадить часть задач на сишные сервисы
akomiagin Автор
15.12.2021 17:20Как вариант! Если целевые показатели производительности не достигнуты... Кстати, многие вещи так и реализованы как Python C Extension. Пример: pymongo

astramax57
15.12.2021 16:47Интересно, спасибо. Но ссылки бы облегчили чтение. Я про "институт IEEE опубликовал"

miga
15.12.2021 16:52+1Только вот убер уже много лет как перешел на го и жаву. Но да, до этого был питон (а самый первый прототип вообще на пхп)
akomiagin Автор
15.12.2021 17:11На самом старте проекта, python - это, почти всегда, отличный выбор! По мере развития проекта все постепенно превращается в зоопарк технологий. От этого никуда не уйти...
suns
15.12.2021 17:34+2Ой, хайлоад и питон
Для начала мы вынуждены плодить уйму процессов из-за gil, общение между которыми, мягко говоря, не zero-cost, так что про параллельную обработку маленьких задач лучше забыть
Управление аллокациями - это тоже не про питон
Быстрый сетевой стек? Вроде на питоне в среднем rps раз в 100 меньше плюсовых/сишных альтернатив
Собственно сами вычисления - ну тут есть какие-то решения, которые позволяют либо jit получить, либо использовать сишную библиотеку
Так уж случилось, что в highload важен low-latency на ядро, иначе вы просто в железо упретесь. Питон в этом очень слаб, но он и не для этого
akomiagin Автор
15.12.2021 17:47Конечно, python - это далеко не самый быстрый в плане производительности язык, но он позволяет ясно и прозрачно описывать достаточно сложную бизнес-логику, в том числе в контексте highload. Тем более, если требуемые показатели производительности достигаются (tps/rps), то почему бы и нет?
Конечно, накладные расходы (железо, которое, кстати, все время дешевеет) присутствуют при таком подходе к горизонтальному масштабированию, но это та цена, которую мы платим за скорость разработки, гибкость решения и простоту поддержки/сопровождения.
zorn-v
15.12.2021 20:56+2Конечно, накладные расходы (железо, которое, кстати, все время дешевеет)
Железо... дешевеет... Да вы полюбому из паралельной вселенной.
akomiagin Автор
15.12.2021 22:07-1Так хочется верить, что в долгосрочной перспективе железо все таки дешевеет, но, возможно, я просто неисправимый оптимист из параллельной вселенной))
zorn-v
15.12.2021 20:53+1Языков в мире программирования масса, но корону по праву носит Python
Не слишком ли громко ?
Корону по определению носит тот язык на котором ты программируешь )
Ну а дальше холивары.
akomiagin Автор
15.12.2021 21:12+1Даже в мыслях не было разводить холивар. Мы тоже в своих проектах используем различные языки программирования в зависимости от задачи и требований. Основной посыл статьи был в том, чтобы поделиться с сообществом нашими наработками в части архитектурных паттернов для приложений.

yakimka8
15.12.2021 21:15А о чём статья? О том что в стдлибе пайтона есть multiprocessing?
akomiagin Автор
15.12.2021 21:41Статья о том, как построить интересную и масштабируемую архитектуру распределенного приложения для highload системы с использованием одного из самых популярных языков программирования.

snuk182
15.12.2021 23:51Напасть двадцать первого века - использовать языки сценариев для чего-то сложнее сценариев.
akomiagin Автор
16.12.2021 00:09+2Да, универсальность python открывает все новые и новые горизонты его применения. Еще сравнительно недавно мы даже подумать не могли, что, например, в области анализа больших данных и машинного обучения python станет просто стандартом de facto. Это же здорово, что появляются новые способы применения привычных инструментов.
suns
16.12.2021 00:24https://habr.com/ru/amp/post/519414/
А вы тут про хайлоад говорите - за планету страшно
akomiagin Автор
16.12.2021 00:28Ох... И не говорите)) Улыбнул комментарий к той статье: Грета - наше все! Астрономов на мыло
QuAzI
16.12.2021 09:08+1Пайтон в определённом контексте, конечно, не плох. Но вот полное забивание на нормальную графику из стандартной библиотеки и мобилки вообще портят весь восторг. Круто было бы какое-нибудь Kivy затащить прям в основную ветку. В мобилках вообще половина штук ломается на этапе "а вот для этой архитектуры у нас нет сборок библиотек". После чего ребята из PySide говорят "мы не будем это тащить, потому что официально питон это не желает поддерживать мобильные платформы".
akomiagin Автор
16.12.2021 20:20Да, полноценной поддержки современного UI, включая мобильные платформы, очень не хватает.

Vest
16.12.2021 10:57+1А я думал, что вы с помощью профайлинга будете определять узкие места.
akomiagin Автор
16.12.2021 20:26без профайлера действительно никуда при оптимизации алгоритмов для поиска узких мест и мы этим должны постоянно заниматься на системной основе, но в данной статье у нас реализован паттерн параллельной обработки, в рамках которого работает достаточно простой worker в качестве примера.
AndreyFlash
16.12.2021 20:30Языков в мире программирования масса, но корону по праву носит Python
Попахивает очередной идеей в статьей "Python лучший язык программирования", да он безусловно лучший, как и C++, C#, Java и др., если вы выбрали какой то язык для себя, но у каждого своя область применения.
akomiagin Автор
16.12.2021 20:38У статьи не было цели показать, что какой то язык хуже, а какой то язык лучше. Тут каждый делает выбор сам. У всех разные предпочтения. Основная мысль статьи была в том, чтобы показать на примере, что можно расширить привычную область применения python и показать как решать задачи уровня highload. Безусловно, highload системы можно имплементировать на Java, C#, C и С++.
ruslanec
17.12.2021 09:31+2Мне кажется, что не совсем верно изложен подход. Python увеличивает скорость разработки, а недостатки связанные с его медлительностью в большинстве случаев можно нивелировать правильным выбором архитектуры. А теперь оцените сколько займет разработка аналогичного решения на "сишечке"? В настоящее время скорость выпуска релиза намного важнее требований к железу.
akomiagin Автор
17.12.2021 09:36Вы абсолютно верно уловили одну из идей, изложенных в статье. У нас действительно сделано упор на грамотно построенную архитектуру, которая за счет возможностей горизонтального масштабирования нивелирует проблемы производительности по сравнению если бы данное решение запускалось на одном узле в олин поток в standalone режиме. Ну и скорость разработки, как вы верно подметили, сейчас один из решающих факторов.
lesskop
Крутая инфографика, приятно выглядит.
З.Ы. У вас опечатка в заголовке "Python vs пессимисты"
akomiagin Автор
Спасибо, поправили!