

В продолжение серии публикаций «Памятка евангелиста PostgreSQL...» (1, 2) дорогая редакция снова выходит на связь, на этот раз с обещанным обзором механизмов репликации в PostgreSQL и MySQL. Главным поводом для написания послужила частая критика репликации MySQL. Как это часто бывает, типичная критика представляет из себя забористую смесь из правды, полуправды и евангелизма. Всё это многократно реплицируется разными людьми без особых попыток разобраться в услышанном. А поскольку это довольно обширная тема, я решил вынести разбор в отдельную публикацию.
Итак, в рамках культурного обмена и в преддверии HighLoad++, где наверняка будет как обычно много критики в адрес MySQL, рассмотрим механизмы репликации. Для начала немного скучных базовых вещей для тех, кто ещё не.
Типы репликации
Репликация бывает логическая и физическая. Физическая представляет из себя описание изменений на уровне файлов данных (упрощенно: записать такие байты по такому-то смещению на такой-то странице). Логическая же описывает изменения на более высоком уровне без привязки к конкретному представлению данных на диске, и здесь возможны варианты. Можно описывать изменения в терминах строк таблиц, например оператор
UPDATE может быть отражён в виде последовательности пар (старые значения, новые значения) для каждой изменённой строки. В MySQL такой тип называется row-based репликация. А можно просто записывать текст всех SQL запросов, модифицирующих данные. Такой тип в MySQL называется statement-based репликация.Физическую репликацию часто называют бинарной (особенно в PostgreSQL сообществе), что неверно. Формат данных как логической, так и физической репликации может быть как текстовым (то есть человекочитаемым), так и бинарным (требующим обработки для чтения человеком). На практике все форматы как в MySQL, так и PostgreSQL бинарные. Очевидно, что в случае statement-based репликации в MySQL тексты запросов можно прочитать «невооружённым глазом», но вся служебная информация всё равно будет в бинарном виде. Поэтому и журнал, используемый в репликации, называется бинарным независимо от формата репликации.
Особенности логической репликации:
- независимость от формата хранения данных: мастер и слейв могут иметь разные представления данных на диске, разные архитектуры процессора, разные структуры таблиц (при условии совместимости схем), разные конфигурации и расположение файлов данных, разные движки хранения (для MySQL), разные версии сервера, да и вообще мастер и слейв могут быть разными СУБД (и такие решения для «кросс-платформенной» репликации существуют). Эти свойства используют часто, особенно в масштабных проектах. Например, в rolling schema upgrade.
- доступность для чтения: с каждого узла в репликации можно читать данные без всяких ограничений. С физической репликацией это не так просто (см. ниже)
- возможность multi-source: объединение изменений с разных мастеров на одном слейве. Пример использования: агрегация данных с нескольких шардов для построения статистики и отчётов. Та же Wikipedia использует multi-source именно для этих целей
- возможность multi-master: при любой топологии можно иметь более одного доступного на запись сервера, если это необходимо
- частичная репликация: возможность реплицировать только отдельные таблицы или схемы
- компактность: объём передаваемых по сети данных меньше. В отдельных случаях сильно меньше.
Особенности физической репликации:
- проще в конфигурации и использовании: Сама по себе задача побайтового зеркалирования одного сервера на другой гораздо проще логической репликации с её многочисленными сценариями использования и топологиями. Отсюда знаменитое «настроил и забыл» во всех холиворах «MySQL против PostgreSQL».
- низкое потребление ресурсов: Логическое репликация требует дополнительных ресурсов, потому что логическое описание изменений ещё нужно «перевести» в физическое, т.е. понять что конкретно и куда записывать на диск
- требование 100% идентичности узлов: физическая репликация возможна только между абсолютно одинаковыми серверами, вплоть до архитектуры процессора, путей к tablespace файлам, и т.д. Это часто может стать проблемой для масштабных кластеров репликации, т.к. изменение этих факторов влечёт полную остановку кластера.
- никакой записи на слейве: вытекает из предыдущего пункта. Даже временную таблицу создать нельзя.
- чтение со слейва проблематично: чтение со слейва возможно, но не без проблем. См. «Физическая репликация в PostgreSQL» ниже
- ограниченность топологий: никакие multi-source и multi-master невозможны. В лучшем случае каскадная репликация.
- нет частичной репликации: вытекает всё из того же требования 100% идентичности файлов данных
- большие накладные расходы: нужно передавать все изменения в файлах данных (операция с индексами, vacuum и прочую внутреннюю бухгалтерию). А значит нагрузка на сеть выше, чем при логической репликации. Но всё как обычно зависит от количества/типа индексов, нагрузки и прочих факторов.
А ещё репликация может быть синхронной, асинхронной и полусинхронной независимо от формата. Но этот факт имеет небольшое отношение к обсуждаемым здесь вещам, поэтому его оставим за скобками.
Физическая репликация в MySQL
Её как таковой нет, по крайней мере встроенной в сам сервер. На то есть архитектурные причины, но это не значит, что она невозможна в принципе. Oracle мог бы сравнительно небольшими усилиями реализовать физическую репликацию для InnoDB, а это уже покрыло бы потребности большинства пользователей. Более сложный подход потребовал бы создания некоторого API, реализовав который альтернативные движки могли бы поддерживать физическую репликацию, но я не думаю, что это когда-нибудь случится.
Но в некоторых случаях физическую репликацию можно реализовать внешними средствами, например с помощью DRBD или аппаратных решений. Плюсы и минусы такого подхода обсуждались неоднократно и подробно.
В контексте сравнения с PostgreSQL нужно отметить, что использование DRBD и подобных решений для физической репликации MySQL больше всего похоже на warm standby в PostgreSQL. Но объём передаваемых по сети данных в DRBD будет выше, потому что DRBD работает на уровне блочного устройства, а значит реплицируются не только записи в REDO log (транзакционный журнал), но и запись в файлы данных и обновления метаинформации файловой системы.
Логическая репликация в MySQL
Эта тема и вызывает больше всего волнений. Причём бОльшая часть критики основана на докладе «Асинхронная репликация MySQL без цензуры или почему PostgreSQL завоюет мир» Олега Царёва zabivator, а также сопутствующей статьи на Хабре.
 Я бы не стал выделять один конкретный доклад, если бы мне не ссылались на него примерно в каждом десятом комментарии к предыдущим статьям. Поэтому приходится отвечать, но я бы хотел подчеркнуть, что идеальных докладов не бывает (у меня лично доклады получаются плохие), и вся критика направлена не на докладчика, а на технические неточности в докладе. Буду рад, если это поможет улучшить его будущие версии.
Я бы не стал выделять один конкретный доклад, если бы мне не ссылались на него примерно в каждом десятом комментарии к предыдущим статьям. Поэтому приходится отвечать, но я бы хотел подчеркнуть, что идеальных докладов не бывает (у меня лично доклады получаются плохие), и вся критика направлена не на докладчика, а на технические неточности в докладе. Буду рад, если это поможет улучшить его будущие версии.В целом в докладе довольно много технически неточных или просто неверных утверждений, часть из них я адресовал в первой части памятки евангелиста. Но я не хочу утонуть в мелочах, поэтому буду разбирать основные тезисы.
Итак, в MySQL логическая репликация представлена двумя подтипами: statement-based и row-based.
Statement-based — это самый наивный способ организовать репликацию («а давайте просто передавать на слейв SQL команды!»), именно поэтому она появилась в MySQL первой и это было очень давно. Она даже работает до тех пор, пока SQL команды строго детерминированы, т.е. приводят к одним и тем же изменениями независимо от времени выполнения, контекста, триггеров и т.д. Про это написаны тонны статей, я не буду здесь подробно останавливаться.
На мой взгляд, statement-based репликация — это хак и «legacy» в стиле MyISAM. Наверняка кто-то где-то ещё находит ей применение, но по возможности избегайте этого.
 Интересно, что о применении statement-based репликации рассказывает в своём докладе и Олег. Причина — row-based репликация генерировала бы терабайты информации в сутки. Что в общем логично, но как это согласуется с утверждением «PostgreSQL завоюет мир», если в PostgreSQL асинхронной statement-based репликации нет вообще? То есть и PostgreSQL бы генерировал терабайты обновлений в сутки, «бутылочным горлышком» вполне ожидаемо стали бы диск или сеть, и с завоеванием мира пришлось бы подождать.
Интересно, что о применении statement-based репликации рассказывает в своём докладе и Олег. Причина — row-based репликация генерировала бы терабайты информации в сутки. Что в общем логично, но как это согласуется с утверждением «PostgreSQL завоюет мир», если в PostgreSQL асинхронной statement-based репликации нет вообще? То есть и PostgreSQL бы генерировал терабайты обновлений в сутки, «бутылочным горлышком» вполне ожидаемо стали бы диск или сеть, и с завоеванием мира пришлось бы подождать. Олег обращает внимание, что логическая репликация обычно CPU-bound, то есть упирается в процессор, а физическая — обычно I/O-bound, то есть упирается в сеть/диск. Я не совсем уверен в этом утверждении: CPU-bound нагрузка одним движением руки превращается в элегантную I/O bound как только активный набор данных перестаёт помещаться в память (типичная ситуация для того же Facebook, например). А вместе с этим нивелируется и бОльшая часть разницы между логической и физической репликацией. Но в целом я согласен: логическая репликация требует сравнительно больше ресурсов (и это её главный недостаток), а физическая меньше (и это практически единственное её преимущество).
Причин «тормозить» у репликации может быть много: это не только однопоточность или недостаток процессора, это может быть сеть, диск, неэффективные запросы, неадекватная конфигурация. Главный вред от доклада заключается в том, что он «гребёт всех под одну гребёнку», объясняя все проблемы некой «архитектурной ошибкой MySQL», и оставляя впечатление, что решения у этих проблем нет. Именно поэтому он был с радостью взят на вооружение евангелистами всех мастей. На самом деле я уверен, что 1) большая часть проблем имеет решение и 2) все эти проблемы существуют и в реализациях логической репликации для PostgreSQL, возможно даже в более тяжёлой форме (см. «Логическая репликация для PostgreSQL»).
 Из доклада Олега очень сложно понять, что на самом деле стало проблемой в его тестах: нет никакой попытки анализа, нет никаких метрик, ни на уровне ОС, ни на уровне сервера. Для сравнения: публикация инженеров из Booking.com на ту же тему, но с подробным анализом и без «евангелистских» выводов. Особенно рекомендую ознакомиться с разделом Under the Hood. Вот так правильно делать и показывать бенчмарки. В докладе Олега на бенчмарки отведено 3 слайда.
Из доклада Олега очень сложно понять, что на самом деле стало проблемой в его тестах: нет никакой попытки анализа, нет никаких метрик, ни на уровне ОС, ни на уровне сервера. Для сравнения: публикация инженеров из Booking.com на ту же тему, но с подробным анализом и без «евангелистских» выводов. Особенно рекомендую ознакомиться с разделом Under the Hood. Вот так правильно делать и показывать бенчмарки. В докладе Олега на бенчмарки отведено 3 слайда.Я же просто коротко перечислю возможные проблемы и их решение. Предвижу много комментариев в духе «а в слонике всё нормально работает и без всякого шаманства!». Отвечу на них один раз и больше не буду: физическая репликация проще в настройке, чем логическая, но её возможностей хватает далеко не всем. У логической возможностей больше, но есть и недостатки. Здесь описаны способы минимизации недостатков для MySQL.
Если упираемся в диск
Часто для слейва выделяют слабые машины из соображений «ну, это же не основной сервер, сойдёт и этот старый тазик». В старом тазике обычно оказывается слабый диск, в который всё и упирается.
Если диск является узким место при репликации, и использовать что-то мощнее не представляется возможным, нужно снизить дисковую нагрузку.
Во-первых, можно регулировать объём информации, который master записывает в бинарный журнал, а значит пересылается по сети и записывается/читается на слейве. Настройки, которые стоит посмотреть:
binlog_rows_query_log_events, binlog_row_image.Во-вторых, можно отключить бинарный журнал на слейве. Он нужен только в том случае, если слейв сам является мастером (в multi-master топологии или в качестве промежуточного мастера в каскадной репликации). Некоторые держат бинарный журнал включенным для того, чтобы ускорить переключение слейва в режим мастера в случае failover. Но если с производительностью диска проблемы, его можно и нужно отключить.
В-третьих, можно ослабить настройки durability на слейве. Слейв по определению является неактуальной (за счёт асинхронности) и не единственной копией данных, а значит в случае его падения его можно пересоздать либо из бэкапа, либо из мастера, либо из другого слейва. Поэтому нет никакого смысла держать строгие настройки durability, ключевые слова:
sync_binlog, innodb_flush_log_at_trx_commit, innodb_doublewrite.Наконец, общую настройку InnoDB на интенсивную запись никто не отменял. Ключевые слова:
innodb_max_dirty_pages_pct, innodb_stats_persistent, innodb_adaptive_flushing, innodb_flush_neighbors, innodb_write_io_threads , innodb_io_capacity, innodb_purge_threads, innodb_log_file_size, innodb_log_buffer_size.Если ничего не помогает, можно посмотреть в сторону движка TokuDB, который во-первых оптимизирован для интенсивной записи, особенно если данные не умещаются в память, а во-вторых предоставляет возможность организации read-free репликации. Это может решить проблему как в IO-bound, так и в CPU-bound нагрузках.
Если упираемся в процессор
При достаточно интенсивной записи на мастере и отсутствии других узких мест на слейве (сеть, диск), можно упереться в процессор. Тут на помощь приходит параллельная репликация, она же multi-threaded slave (MTS).
В 5.6 MTS был сделан в очень ограниченном виде: параллельно выполнялись только обновления в разные базы (схемы в терминологии PostgreSQL). Но наверняка на свете существует непустое множество пользователей, которым и этого вполне достаточно (привет, хостеры!).
В 5.7 MTS был расширен для параллельного выполнения произвольных обновлений. В ранних дорелизных версиях 5.7 параллельность ограничивалась количеством одновременно зафиксированных транзакций в рамках group commit. Это ограничивало параллельность, особенно для систем с быстрыми дисками, что скорее всего и приводило к недостаточно эффективным результатам у тех, кто эти ранние версии тестировал. Это вполне нормально, для того они и ранние версии, чтобы заинтересованные пользователи могли потестировать и поругать. Но далеко не все пользователи догадываются сделать из этого доклад с выводом «PostgreSQL завоюет мир».
Тем не менее, вот результаты всё тех же sysbench тестов, которые использовал для доклада Олег, но уже на GA релизе 5.7. Что мы видим в сухом остатке:
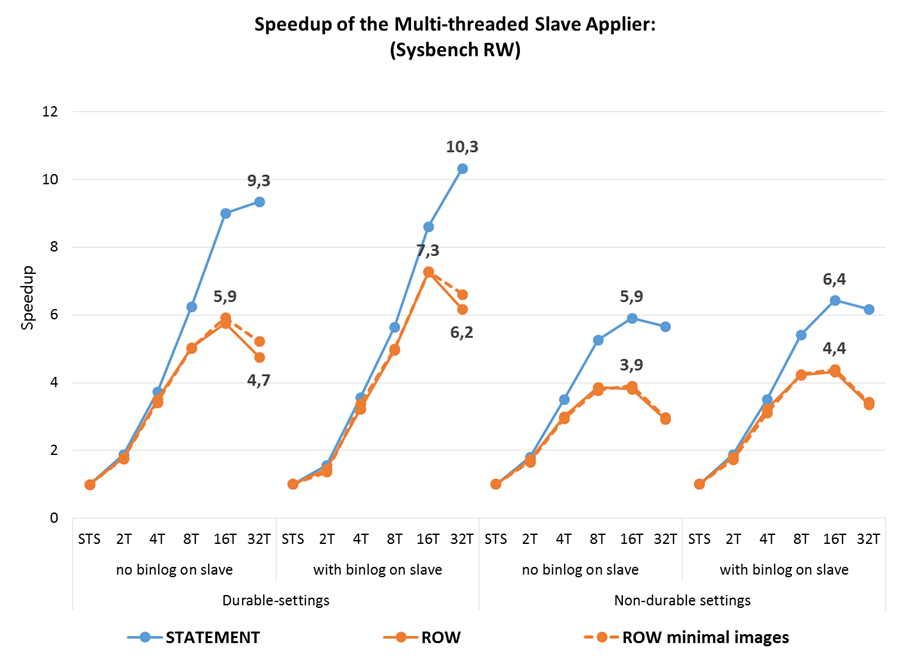
- MTS на слейве достигает 10-кратного увеличения производительности по сравнению с однопоточной репликацией
- использование
slave_parallel_workers=4уже приводит к росту пропускной способности слейва в более чем 3.5 раза - производительность row-based репликации практически всегда выше, чем statement-based. Но MTS оказывает больший эффект на statement-based, что несколько уравнивает оба формата с точки зрения производительности на OLTP нагрузках.
Ещё один важный вывод из тестирования Booking.com: чем меньше размер транзакций, тем большей параллельности можно достичь. До появления group commit в 5.6 разработчики старались сделать транзакции как можно больше, часто без необходимости с точки зрения приложений. Начиная с 5.6 в этом нет необходимости, а для параллельной репликации в 5.7 лучше пересмотреть транзакции и разбить на более мелкие там, где это возможно.
Кроме того, можно подстроить параметры
binlog_group_commit_sync_delay и binlog_group_commit_sync_no_delay_count на мастере, что может привести к дополнительной параллельности на слейве даже в случае длинных транзакций.На этом тему с репликацией в MySQL и популярным докладом я считаю закрытой, переходим к PostgreSQL.
Физическая репликация в PostgreSQL
Помимо всех плюсов и минусов физической репликации, перечисленных ранее, реализация в PostgreSQL обладает ещё одним существенным недостатком: совместимость репликации не гарантируется между мажорными релизами PostgreSQL, поскольку не гарантируется совместимость WAL. Это действительно серьёзный недостаток для нагруженных проектов и больших кластеров: требуется остановка мастера, апгрейд, затем полное пересоздание слейвов. Для сравнения: проблемы с репликацией от старых версий к новым в MySQL случаются, но их исправляют и в большинстве случаев это работает, от совместимости никто не отказывается. Что и используется при обновлении масштабных кластеров — плюсы «ущербной» логической репликации.
PostgreSQL предоставляет возможность чтения данных со слейва (т.н. Hot Standby), но с этим всё далеко не так просто, как при логической репликации. Из документации по Hot Standby удалось выяснить, что:
SELECT ... FOR SHARE | UPDATEне поддерживаются, потому что для этого требуется модификация файлов данных- 2PC команды не поддерживаются по тем же причинам
- явное указание «read write» состояние транзакций (
BEGIN READ WRITEи т.д.), LISTEN, UNLISTEN, NOTIFY, обновления sequence не поддерживаются. Что в целом объяснимо, Но это значит, что какие-то приложения придётся переписывать при миграции на Hot Standby, даже если никаких данных они не модифицируют - Даже read-only запросы могут вызывать конфликты с DDL и vacuum операциями на мастере (привет «агрессивным» настройкам vacuum!) В этом случае запросы могут либо задержать репликацию, либо быть принудительно прерваны и есть конфигурационные параметры, которые этим поведением управляют
- слейв можно настроить для предоставления «обратной связи» с мастером (параметр
hot_standby_feedback). Что хорошо, но интересны накладные расходы этого механизма в нагруженных системах.
Кроме того, я обнаружил дивное предостережение в той же документации:
- «Operations on hash indexes are not presently WAL-logged, so replay will not update these indexes» — эээ, а это вообще как? А с физическими бэкапами что?
Есть некоторые особенности с failover, которые пользователю MySQL могут показаться странными, например невозможность возврата к старому мастеру после failover без его пересоздания. Цитирую документацию:
Once failover to the standby occurs, there is only a single server in operation. This is known as a degenerate state. The former standby is now the primary, but the former primary is down and might stay down. To return to normal operation, a standby server must be recreated, either on the former primary system when it comes up, or on a third, possibly new, system.
Есть ещё одна специфическая особенность физической репликации в PostgreSQL. Как я написал выше, накладные расходы по трафику для физической репликации в целом выше, чем в логической. Но в случае с PostgeSQL в WAL записываются (а значит передаются по сети) полные образы обновлённых после checkpoint-ов страниц (
full_page_writes). Я легко могу представить нагрузки, где такое поведение может стать катастрофой. Здесь наверняка несколько человек кинутся объяснять мне смысл full_page_writes. Я знаю, просто в InnoDB это реализовано несколько иначе, не через транзакционный журнал.В остальном физическая репликация в PostgreSQL наверное действительно надёжный и простой в настройке механизм для тех, кому физическая репликация вообще подходит.
Но пользователи PostgreSQL тоже люди и ничто человеческое им не чуждо. Кому-то хочется иногда multi-source. А кому-то multi-master или частичная репликация очень нравится. Наверное, именно поэтому и существует…
Логическая репликация в PostgreSQL
Я попытался понять состояние логической репликации в PostgreSQL и что-то приуныл. Встроенной нет, есть куча сторонних решений (кто сказал «разброд»?): Slony-I (кстати, а где Slony-II?), Bucardo, Londiste, BDR, pgpool 1/2, Logical Decoding, и это ещё не считая мёртвых или проприетарных проектов.
У всех какие-то свои проблемы — какие-то выглядят знакомыми (за них часто критикуют репликацию в MySQL), какие-то выглядят странно для пользователя MySQL. Какая-то тотальная беда с репликацией DDL, которые не поддерживаются даже в Logical Decoding (интересно, почему?).
BDR требует пропатченную версию PostgreSQL (кто сказал «форки»?).
У меня есть некоторые сомнения в производительности. Я уверен, что кто-нибудь в комментариях начнёт объяснять, что репликация на триггерах и скриптах на Perl/Python работает быстро, но я в это поверю, только когда увижу сравнительные нагрузочные тесты с MySQL на том же оборудовании.
Logical Decoding выглядит интересно. Но:
- Это не репликация как таковая, а конструктор/фреймворк/API для создания сторонних решений для логической репликации
- Использование Logical Decoding требует записи дополнительной информации в WAL (требуется установить
wal_level=logical). Привет критикам бинарного журнала в MySQL! - Какие-то из сторонних решений уже переехали на Logical Decoding, а какие-то ещё нет.
- Из чтения документации у меня сложилось впечатление, что это аналог row-based репликации в MySQL, только с кучей ограничений: никакой параллельности в принципе, никаких GTID (как делают клонирование слейва и failover/switchover в сложных топологиях?), каскадная репликация не поддерживается.
- Если я правильно понял эти слайды SQL интерфейс в Logical Decoding использует Poll модель для распространения изменений, а протокол для репликации использует Push модель. Если это действительно так, что происходит при временном выпадении слейва из репликации в Push модели, например из-за проблем с сетью?
- Есть поддержка синхронной репликации, что хорошо. Как насчёт полусинхронной репликации, которая более актуальна в высоконагруженных кластерах?
- Можно выбирать избыточность информации с помощью опции
REPLICA IDENTITYдля таблицы. Это некий аналог переменнойbinlog_row_imageв MySQL. Но переменная в MySQL динамическая, её можно устанавливать отдельно для сессии, или даже отдельно для каждого запроса. Можно ли так в PostgreSQL? - Короче говоря, где можно посмотреть доклад «Асинхронная логическая репликация в PostgreSQL без цензуры»?. Я бы с удовольствием почитал и посмотрел.
Как я уже говорил, я ни на что не претендую в плане знания PostgreSQL. Если что-то из этого неверно, или неточно — дайте мне знать в комментариях и я обязательно подправлю. Также было бы интересно получить ответы на вопросы, которые у меня возникали по ходу.
Но моё впечатление в целом: логическая репликация в PostgreSQL находится на ранних стадиях развития. В MySQL логическая репликация существует давно, все её плюсы, минусы и подводные камни хорошо известны, изучены, обсуждены и показаны на разных докладах. Кроме того она сильно изменилась за последние годы.
Заключение
Поскольку в этой публикации содержится кое-какая критика PostgreSQL, я прогнозирую очередной взрыв комментариев в стиле: «а вот мы с приятелем вдвоём работали на мускуле и всё было плохо, а теперь работаем на слонике и жизнь наладилась». Я верю. Нет, серьёзно. Но я никого не призываю куда-то переходить или что-либо вообще менять.
Статья преследует две цели:
1) ответ на не вполне корректную критику MySQL и
2) попытка систематизировать многочисленные различия между MySQL и PostgreSQL. Такие сравнения требуют огромного труда, но именно этого от меня часто ожидают в комментариях.
В следующей публикации я собираюсь продолжить сравнения, на этот раз в свете производительности.
Комментарии (60)

antage
01.11.2015 18:55+1Типичный кейс для веб-сайтов а-ля блог в конфигурации 1 мастер, много слейвов:
1) Пользователь отредактировал статью. Движок послал UPDATE в мастер и инвалидировал кэш веб-страницы с постом.
2) Пользователь (этот же или другой) зашёл на страницу с отредактированной статьей. Лвижок послал SELECT на один из слейвов и получил старые данные, потому что слейв еще не догнал мастера. Старые данные осели в кэше веб-страницы.
3) Пользователь не видит своих правок на странице, F5/Ctrl-R не помогают. Пользователь негодует.
В PostgreSQL это проблема легко решается включением синхронной репликации, а в MySQL как?
kaamos
01.11.2015 19:59+1Добро пожаловать в мир распределённых систем. Если я правильно читаю документацию здесь синхронная репликация в PostgreSQL консистентности данных на слейве вам не гарантирует — они только гарантирует, что транзакция с мастера передана на слейв, но она может быть ещё не проиграна на момент SELECT. Да и это гарантировано только для одного слейва в каждый момент времени (текущий синхронный standby). Так что нет, это не спасёт в том случае, который вы описываете.
Но проблема консистентности в распределённых системах — это тема не для комментария под статьёй. Всё зависит от того, что именно нужно получить. Пользователь блога может негодовать, если получит неконсистентый ответ через минуту. А в течение нескольких секунд скорее и не заметит. А для какой-нибудь системы бронирования билетов консистентность нужна моментальная на всех узлах.

Nastradamus
03.11.2015 21:33Можно подумать, что описанные случаи с SELECT/UPDATE — это проблема. Все программисты знают как с этим жить. :)
kaamos
03.11.2015 22:00Можно подумать в мире мало криво написанных приложений ;)
Nastradamus
03.11.2015 22:05По моему опыту, программисты склонны прислушиваться к советам DBA. А последние не склонны понижать производительность кластера странными «крутилками» :)

merlin-vrn
03.11.2015 23:21Расскажите это программистам из Тонлайн, разработчикам системы «СуперБилет».
Это к слову о системе заказа билетов. Там, например, есть шлюз SOAP, и после выполнения команды «выбрать билет для бронирования/покупки» можно было увидеть новый статус (командой «посмотреть статус») не ранее чем через 30 секунд… причём это было сделано намеренно. Зачем — не смогли объяснить. Слава богу, другой пользователь в это время это же место выбрать всё равно не мог (получал ошибку «место занято», хотя при запросе статуса оно выглядит как свободное), и слава богу, по запросу они убрали эту дебильную задержку.
zim32
01.11.2015 21:10Обычно полусинхронной перконой

brkov
02.11.2015 00:36+1Semisynchronous Replication не спасёт от описанного кейса если слейвов больше чем один это раз. И два слейв может отставать.
zim32
02.11.2015 00:50+1https://www.percona.com/doc/percona-xtradb-cluster/5.6/features/multimaster-replication.html
wsrep_causal_reads=ON.

svetasmirnova
02.11.2015 04:15+2В 5.7 появилась вот такая опция: dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_rpl_semi_sync_master_wait_for_slave_count То есть фактически можно синхронную репликацию сделать.
svetasmirnova
02.11.2015 04:16+2Для два есть такая опция: dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_rpl_semi_sync_master_wait_point
kaamos
02.11.2015 13:05+1Свет, эта опция не о том. Она не гарантирует консистентных с мастером результатов на слейве в описанном случае. Она позволяет регулировать консистентность данных после падения мастера — что приложения могут увидеть до подения мастера и после failover.
kaamos
02.11.2015 13:18Полусинхронная репликация не решает эту проблему. Она не решается просто, хоть с MySQL, хоть с PostgreSQL. Есть Galera Cluster, но это для блогов может быть и перебором.
Есть умные балансировшики нагрузки, которые мониторят слейвы, и направляют на них запросы, только если они отстают не более чем на N секунд. Для блогов такого вполне бы хватило.zim32
02.11.2015 13:31Почему не решает. Вы не сможете прочитать строку на которой еще не произведен commit на слейве. И, кстати, Percona использует галеру, точнее ее wsrep API.
kaamos
02.11.2015 13:33Да, но я (или кэш, или балансировщик нагрузки) может пойти на слейв, и там этой строки не увидеть. Потому что соответствующая транзакция лежит в relay log (это гарантирует нам синхронная репликация), но ещё не проиграна. Вопрос был в этом. И синхронная репликация здесь не поможет. Ни в MySQL, ни в PostgreSQL.
brkov
02.11.2015 16:32dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_rpl_semi_sync_master_wait_point
AFTER_COMMIT: The master writes each transaction to its binary log and the slave, syncs the binary log, and commits the transaction to the storage engine. The master waits for slave acknowledgment of transaction receipt after the commit. Upon receiving acknowledgment, the master returns a result to the client, which then can proceed.
With AFTER_COMMIT, the client issuing the transaction gets a return status only after the server commits to the storage engine and receives slave acknowledgment. After the commit and before slave acknowledgment, other clients can see the committed transaction before the committing client.
Кажется вместе с sysvar_rpl_semi_sync_master_wait_for_slave_count можно добиться нормальной работы для бложиков и не бояться балансеров и прочего.kaamos
02.11.2015 16:37+2Вот здесь есть с картинками для наглядности: my-replication-life.blogspot.com/2013/09/loss-less-semi-synchronous-replication.html
Полусинхронная относится только к IO thread на слейве. Все опции управляют только тем, в каком порядке делать COMMIT на мастере — до подтверждения от слейва, или после. А сам слейв посылает подтверждение всегда после сохранении транзакции в relay log, а не после проигрывания.
Иными словам, полусинхронная репликация остаётся всегда полусинхронной, синхронную из неё никакими опциями не сделать. То, что в PostgreSQL называется синхронной, на самом деле синхронной не является в смысле консистентности данных между узлами. И полусинхронной она не является тоже. Это что-то промежуточное.

DmitryKoterov
02.11.2015 18:24+1Ответ на «типичный кейс» может быть таким:
1. Храните у юзера в сесии (или куке, если вам везет и в проекте нет кроссдоменности) текущую позицию мастера на момент после последной записи данного конкретного юзера. Не пускайте юзера читать со слейва до тех пор, пока слейв не догнал мастер до позиции, которая сохранена у данного юзера в сессии/куке (не у «всех» юзеров, а у конкретного — потому что реплика никогда не догонит мастер для всех юзеров).
2. С инвалидацией кэша похуже, т.к. кэш может быть случайно заполнен другим юзером, пришедшим через полсекунды после апдейта первого. Ну что тут можно придумать… например, не инвалидировать кэш немедленно, а добавлять команду инвалидации данных в какую-то легкую табличку-очередь в той же самой базе, чтобы инвалидация происходила, только когда данные доехали до слейва. Может, есть какой-то другой стандартный способ решения?
symbix
02.11.2015 21:55А вот, кстати, для инвалидации кэша вполне подойдет logical decoding со слейва.
gre
02.11.2015 01:37Спасибо за статью!
А вот можно реквестовать статью по настройке mysql/postgresql для ноды фиксированной памяти?
Давайте возьмём nginx+php-fpm+db_name.
Пускай размер php-fpm будет 20 и 80мб. Ну для «простых» фреймворков и «крутых». Просто два варианта рассмотрим.
Давайте рассмотрим инстансы для «маленьких» — 512, 1024, 2048, 4096.
Давайте примем за истину, что db_запросы занимают 70% времени работы php-скрипта.
Внмание вопрос — как правильно искать узкие места и оптимизировать их?
Это актуально как для mysql, так и для pg.
Апологеты mysql, так и pgsql — сделайте, пожалуйста.
Как читать explain — и куда смотреть на внутренние параметры БД.
Спасибо!
norguhtar
02.11.2015 08:04По PostgreSQL к примеру phpclub.ru/detail/store/pdf/postgresql-performance.pdf
По MySQL еще проще. Используйте перконовский визард tools.percona.com/wizard
Он требует регистрации но сразу все настраивает как надо.
Насчет узких мест у MySQL есть slow-query
У PostgreSQL есть онлайновая статистика, ее рекомендуется включать и использовать. У MySQL есть, но не настолько удобная и информативная.
Дополнительно учитывайте если у вас нет сложных запросов, то на указанных объемах памяти можно использовать MySQL будет работать немного быстрее. Это кстати и обуславливает частый выбор MySQL как базы данных для веб сервисов.
kaamos
02.11.2015 13:07Пореквестировать можно всё. И я не против написать статьи на эти темы в части MySQL, но когда позволит свободное время.
norguhtar
02.11.2015 07:57+6Особенности логической репликации
А теперь расскажите какие из них реально доступны в MySQL. К примеру для первого сразу говорю придется не хило попрыгать с бубном. Плюс это может порождать больше проблем, чем давать профита. Насчет доступности для чтения у того же PostgreSQL вы лукавите. Там четко говорится slave открыт только на readonly. За каким вы указываете что там нельзя использовать уровни изоляции используемые при записи? С моей точки зрения это аргумент высосанный из пальца.
Есть некоторые особенности с failover, которые пользователю MySQL могут показаться странными, например невозможность возврата к старому мастеру после failover без его пересоздания.
Учитывая, что это делается банальной штатной софтиной, в отличии от MySQL это не такая уж проблема. К тому же никто не запрещает нагонять master через WAL файлы со slave. Да внезапно так можно делать.
Ну и да рассказывать что Олег Царёв поверхностно проходит по MySQL и PostgreSQL это сильно, может разберете аргументы приведенные им? Я вот разбора не вижу. Ну и подробнее про как CPU bound у вас переходит в IO bound. У вас перед переходом в IO bound сначала надо будет что-то с CPU bound сделать. А я имея каждый день с MySQL могу сказать что это та еще головная боль. И да если master у MySQL перегружен запросами, то slave берет и отстает, вплоть до его отвала, так-как ой мы потеряли запрос.
kaamos
02.11.2015 13:15-1Ух, сколько сразу и вопросов и обвинений. Лень цитировать, отвечаю по порядку. Доступны все. Про бубны я и сам могу рассказать, только без бубнов нигде не бывает. Я всё объяснил, за каким я указываю уровни изоляции при записи — я вообще просто процитировал перевод официальной документации к PostgreSQL, так что вопрос не ко мне. Штатная софтина не отменаяет того факта, что мастер нужно пересоздавать. На это могут уйти часы, и от того, что это «штатная софтина», вам будет не легче.
И да, доклад Олега поверхностный, я довольно подробно разобрал главные пункты. Какое конкретно слово там непонятно? А придираться по мелочам у меня нет желания, хотя их там почти на каждом слайде. Как CPU bound переходит в IO bound я тоже объяснил — что именно там непонятно?norguhtar
02.11.2015 14:00Ух, сколько сразу и вопросов и обвинений.
А то! И да мне просто сильно интересно сколько кода вы написали для СУБД :)
Доступны все. Про бубны я и сам могу рассказать, только без бубнов нигде не бывает.
Тогда ждем от вас статей где рассказывается как сделать каждую из них. А то я тоже могу сказать да все там доступно :)
Я всё объяснил, за каким я указываю уровни изоляции при записи
Правда? А я вот не увидел. К примеру для чего требуется использовать на SLAVE SELECT… FOR SHARE | UPDATE и такой чтобы он не был сферическим в вакууме.
Штатная софтина не отменаяет того факта, что мастер нужно пересоздавать. На это могут уйти часы, и от того, что это «штатная софтина», вам будет не легче.
Угу и про догонку WAL с текущего Master вы конечно же пропустили. Это вполне допустимый вариант и он вполне себе работает.
И да, доклад Олега поверхностный, я довольно подробно разобрал главные пункты. Какое конкретно слово там непонятно?
Да вот не разобрали. Фактически рассказали тоже самое, но только смотрите дети это фича :) Давайте уже как-то прорабатывать эту тему глубже все же.
Как CPU bound переходит в IO bound я тоже объяснил — что именно там непонятно?
Как избавились от CPU bound. Фишка в том что MySQL может жрать процессор как не в себя. В том числе и при логической репликации.

VolCh
02.11.2015 09:36+2В MySQL постоянные проблемы в случае когда реплицируются не все базы — MySQL бай дизайн не способен корректно определить что нужно реплицировать, а что нет. Как с этим в Постгрес?
kaamos
02.11.2015 13:21Это вы о statement-based репликации или о чём?
VolCh
03.11.2015 23:10dev.mysql.com/doc/refman/5.7/en/replication-rules-db-options.html
Проверка базы данных по умолчанию (читай «последний USE») проводится обоих случаях и влияет на то, что писать в бинлог (про мастер речь), а что нет.kaamos
03.11.2015 23:42Так ведь написано же, что «With statement-based replication, the default database is checked for a match. With row-based replication, the database where data is to be changed is the database that is checked.»
Та же информация продублирована в dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html#option_mysqld_binlog-do-db:
«Row-based logging. Logging is restricted to database db_name. Only changes to tables belonging to db_name are logged; the default database has no effect on this.»VolCh
05.11.2015 08:35Наверное, спутал row-based с mixed. Или в 5.1 (с которой больше всего мучался) немного другое поведение было.
norguhtar
02.11.2015 14:01+2В PostgreSQL же WAL. Проще говоря все или ничего. Если нужно одну базу, то начинаем брать другие решения, которые работают уже на логическом уровне.

zabivator
02.11.2015 19:05+2Конкретно мы с админами убили кучу времени на очень простой сценарий (по которому собирались мигрировать на 5.7) — берём мастер пишем бинлоги, потому запускаем догон слейва и проверяем, как быстро он догоняется.
Мои графики в презентации — это как раз время догона.
Слайды 76 и 77: www.slideshare.net/tsarevoleg/ss-40969331?related=1
описывают железо и там есть ссылка на github со скриптами и конфигами/
Это лишь один из кучи проведённых тестов, но очень важный — если 5.7 работает не лучше чем 5.5, то мигрировать на неё нет смысла — нету решения нашей самой больной проблемы.
Другой интересный тест — это догон слейва 5.7 с мастера 5.5 — он нужен для миграции без даунтайма — там всё тоже было очень печально, регрессия 40% по сравнению с 5.5
Впрочем, это было на 5.7 годичной давности, и я уже не работаю в компании mail.ru, где снова актуально перепроверить результаты на новой версииzabivator
02.11.2015 19:09+1Собственно, железо описано на 76 слайде, а все скрипты лежат тут: github.com/zamotivator/2014-highload-mysql
kaamos
02.11.2015 19:24Олег, рассказываю, что нужно было сделать в идеале. Нужно было написать хороший пост, на английском. Изложить связно проблему, выложить все метрики, в общем см. пост от Booking.com в качестве примера.
Потом можно было написать в internals@lists.mysql.com — там отвечают на внятно заданные вопросы и показать ссылку на пост. Дополнительно можно было связаться с людьми из Oracle, отвечающими за community. Их контакты легко найти и обратить их внимание на этот пост. Они бы связали с нужными людьми внутри.
Но это всё если разбираться самим совсем лень/нет времени/не тем заняты и т.д.
А можно было попробовать что-нибудь попрофилировать, что-то поанализировать самим. И по результатам создать баг на bugs.mysql.com. И тоже в блог, и тоже community представителям Oracle. Вот люди из Booing.com наверняка так и сделали, и результат этой работы мы видим в финальном релизе 5.7.
Я знаю, что ты общался с кем-то внутри Oracle. Но, видя уровень детализации, я не удивлён, что это общение ни к чему не привело. Просто чтобы грамотно задать вопрос, нужно знать половину ответа. Но я понимаю, что от доклада «PostgreSQL завоюет мир» профита гораздо больше, чем от какой-то конструктивной работы.zabivator
02.11.2015 19:28У Оракла есть все мои скрипты, описание бенчмарков, результаты измерений. Другими словами, полная информация.
kaamos
02.11.2015 19:34Почему я говорю про блог и списки рассылки: они, как бы это помягче, часто помогают придать некоторый импульс разработчикам. Потому что блоги и списки читает много людей, общественный резонанс, вот это всё. Ну да ладно, вот ты связался с разработчиками напрямую. И они тебе ответили «О, ну тут ничего не сделать, PostgreSQL завоюет мир», так что ли? Они наверное тебе ответили, что работают над этим. И судя по результатам, действительно неплохо поработали.
zabivator
02.11.2015 19:37+1Просто отмечаю: в третий раз за эту дискуссию пропускаю личные выпады и гипотезы с негативной коннотацией.
Оракл подробно запросил у меня детали бенчмарков и их смысл (для какой реальной задачи они нужны). Меня поблагодарили, ушли чинить.
Потом мне кидали ссылку на один пост про 5.7, но там без даталей было — из личного общения выяснил, что там был прирост что-то порядка единиц процентов на 128 тредов.
Начиная с этого момента тему в дальнейшем не отслеживал.kaamos
02.11.2015 19:39> Начиная с этого момента тему в дальнейшем не отслеживал.
Ну вот, как выяснилось, и зря не отслеживал.
kaamos
02.11.2015 19:42Кстати говоря, связался с разработчиками ты уже _после_ доклада. Это важно, и я об этом знаю точно.
zabivator
02.11.2015 19:57+3> Ну вот, как выяснилось, и зря не отслеживал.
Я предприму последнюю попытку объяснить, в общем-то, очевидные вещи.
На момент детального исследования параллельного slave я работал разработчиков проекта Target. В моих должностных обязанностях не было «разработки MySQL». Были конкретные проблемы проекта (отстающий slave на 5.5) и просили решения этих проблем.
Мер принято было много, в целом они помогли.
ОДНИМ ИЗ пунктов было изучения 5.7 (на дворе был 2014 год и 5.7.3) — поможет ли он с нашими проблемами или нет.
Мы провели ряд исследований, после коммуникаций с Oracle исправляли бенчмарки и повторяли исследования.
Никаких удовлетворительных результатов мы так и не получили, и ближе к концу лета 2014 года прекратили исследования.
Задач много других, 5.7.3 показал себя несостоятельным, имеющиеся проблемы смогли купировать другими способами (и на целый год этого даже хватило), я переключился на другие задачи.
Изученное и измеренное я оформил в виде доклада, доклад по отзывам людей, оказался информативным — «теперь мы наконец-то поняли, что происходит с репликацией, откуда наши проблемы и как с ними справляться». Минимум три success story есть, не считая отзывов вида «понял про репликацию и журналы из вашего доклада больше, чем после семестрового курса в ВУЗе».
Значит, доклад полезен людям
Вам не кажется странным, Алексей, критиковать мои действия с учётом данного контекста? Нигде, подчёркиваю — НИГДЕ — ни формально, ни по факту, ни в ожиданиях руководства не было слов о разработке MySQL. Только исследование, желательно — побыстрей, если не взлетает и непонятно что делать дальше — то забить, и работать над проблемами ПРОЕКТА.
А не MySQL.
> Кстати говоря, связался с разработчиками ты уже _после_ доклада. Это важно, и я об этом знаю точно.
У Вас, Алексей, неверная информация.
Я общался с Дмитрием Лёневым как минимум дважды:
1. На MySQL Meetup (которых был сильно раньше highload)
2. В процессе подготовки доклада к highload — он критиковал мой план доклада и дал много ценных замечаний
Но Вы «точно знаете», а с этим спорить бесполезно — успел убедиться за длительный промежуток времени
После доклада я просто повторил описание своего бенчмарка и выдал скрипты. User story: «нагруженный проект хочет смигрировать с 5.5 на 5.7 без даунтайма» я неоднократно описывал раньше.
Да, особенно круто критиковать доклад годовалой давности с современным MySQL. Впрочем, я почему-то не удивлён — ни подходом к критике доклада, ни повторения доклада (пожалуй, из неупомянутого мной лишь multi-source replication), ни личным выпадам.
kaamos
02.11.2015 20:08Я нигде не критикую ни Вас, Олег Игоревич, лично, ни Ваши действия. Я даю советы. Как можно было бы сделать доклад более информативным, но менее «евангелистским». И как можно было бы достичь лучшего взаимодействия с разработчиками. Как к этим советам относиться — Ваше сугубо личное дело. А если Вы и дальше будете рассказывать про «информативность» доклада, я начну перечислять все технические несуразности. И получится очень неловко.
zabivator
02.11.2015 20:13+2Спасибо, советы я принял к сведению, и благодарен за них. Если когда-нибудь придётся снова работать с MySQL и критиковать его — учту.
> А если Вы и дальше будете рассказывать про «информативность» доклада, я начну перечислять все технические несуразности. И получится очень неловко.
Странно, вроде бы в самом начале я делаю оговорку: невозможно описать технически корректно и при этом наглядно, и описанное в докладе — лишь грубые схемы, которые позволяют ПРЕДСТАВИТЬ как всё работают, но на деле СЛОЖНЕЙ.
И оговорки в процессе доклада я тоже делаю.
Технических несуразиц там много, и я этого никогда не отрицал. Самое важное с моей точки зрения — оставить в голове слушателя картинку про журналы (что это такое и зачем нужно), какие они бывают, какие у них особенности.
Эта цель вполне достигнута, отзывы и обратная связь это потверждает.
За сим раскланиваюсь
P.S. спасибо за советы и критику, учту в будущем.
svetasmirnova
03.11.2015 23:30> Я общался с Дмитрием Лёневым как минимум дважды:
Так ты что, результаты тестов только Дмитрию Ленёву послал? Ну вот честно: баг открыть всё-таки нужно было. Просто потому, что все эти частные внутренние переписки «а у моего знакомого вот такие тесты» легко теряются. Особенно если «контакт» даже не в той группе, которая этими вещами занимается.
Если ты не хотел светить тесты их всегда можно отправить скрытым комментом (или скрытым файлом). Или же весь баг сделать скрытым с самого начала (потом, правда, будет практически невозможно повлиять на исправление скрытого бага, не являясь платным клиентом Оракла. Хотя я видела случаи когда человек делал скрытый баг и в тот же день test case публиковал на stackoverflow).
Открывать баги очень важно потому, что их видит не только «контакт из Оракла», но и люди из команды replication (или про что баг), и из поддержки, и из Community. И каждый из этих людей может подумать, что «баг важный, его нужно исправлять» и задействовать доступные внутренние механизмы. А доступа к частному письму у кого-то из них может не быть.
norguhtar
02.11.2015 21:36Скрипты есть же. Прогоните на новой версии и проверьте как же там стало лучше или нет. Оформите отдельной статьей мы с удовольствием почитаем. Но вот что-то мне подсказывает, что особого прогресса там нет. К примеру прогресс PostgreSQL вижу и он весьма и весьма позитивный. А вот прогресса в MySQL я не вижу. Фичи если и добавляются, то настолько медленно, что отслеживай что не отслеживай толку нет.

vintage
02.11.2015 20:43Не против, если я встряну в ваш спор небольшим рассказом про OrientDB? :-)
В терминах SQL там используется row-based репликация, каждая таблица реплицируется независомо, можно настраивать на каких узлах будут реплики каких таблиц, поддерживается как синхронная, так и асинхронная репликации, как master-slave, так и master-master, есть шардинг и прозрачный map-reduce по шардам. И всё это из коробки.
thatsme
02.11.2015 23:34+1Если-бы эти 3 статьи, ещё и свести в один список вида:
Миф [.....]
(Опровержение|Подтверждение|Workaround) [
(ссылка на (документацию|блог разработчика|результаты тестирования))+
];
Было-бы очень удобно.
symbix
В MySQL есть еще такая забавная конструкция, как binlog_format = MIXED: как бы для детерминированных запросов пишется statement, иначе — row. Помню, что его в какой-то версии включили по умолчанию, но очень быстро это изменили :-) Выглядит как хак на хаке, но, тем не менее, я рискнул использовать в одном проекте, прежде всего, из соображений существенной в данном случае экономии сетевого i/o — пока что ничего не развалилось, тьфу-тьфу :)
О логической репликации как таковой (не считая сторонних извращений) в PostgreSQL говорить рано; logical decoding — это зачатки, и там многое еще не реализовано (тот же DDL). Уверен, что все будет — в постгресе обычно делают неспешно, но по уму.
Физическую репликацию в innodb очень хотелось бы увидеть — много кейсов, когда это ровно то, что надо, и row-бинлог выглядит действительно как вынужденное полное дублирование на пустом месте. Реализовать такое довольно просто, мне кажется. Конечно, innodb-only будет выглядеть хаком, но в случае с mysql одним хаком больше, одним меньше — несущественно :)
kaamos
MIXED — это некий компромисс между «правильным», но избыточным ROW, и «кривым», но очень лёгким STATEMENT. Кому-то и это подойдёт, да, и у меня в черновике было предложение об этом. Но я не стал перегружать пост несущественными деталями и убрал.
varanio
да-да, была бы в мускуле физическая репликация для innodb, мы бы не стали кучу денег тратить и переходить на посгрес. Так что если Oracle сделает такую штуку для mysql, это будет огроменный плюс к базе
VolCh
Вроде всё немного по другому с миксед. В роу пишутся изменения данных, а в стейтмент — изменения метаданных(схемы).
svetasmirnova
Вы не правы. Это в row пишутся изменения данных, а изменения метаданных всё равно в statement-виде.
VolCh
Не понял.
svetasmirnova
То, что Вы описали выше — это не MIXED, а ROW-based format. Все DDL всегда пишутся в формате statement, независимо от формата логов. Ну в самом деле: какие могут быть изменения строк при изменении метаданных? MIXED работает именно так, как описал symbix
svetasmirnova
> Помню, что его в какой-то версии включили по умолчанию, но очень быстро это изменили :-)
Это в какой-то 5.1, кажется, было. Дело в том, что тогда это была новая фича и, естественно, не настолько стабильная как старый statement. Сейчас те баги уже давно устранили и MIXED безопасен.