
Большинство вычислений при работе ML-моделей — матричные. Для работы с ними подходят Tensor и CUDA — специальные графические ядра, интегрированные в GPU. Это дает видеокартам преимущества перед CPU в машинном обучении. Однако они стоят дороже. Если нужно развернуть инференс на процессоре, есть компромисс — использовать инструменты для оптимизации.
По мотивам выступления Артема Земляка, инженера-программиста Smart Consulting, рассказываем о том, какие фреймворки лучше использовать для эффективного продакшена ML-сервисов. Подробности под катом.
Если вам интересна тема статьи, присоединяйтесь к нашему сообществу «MLечный путь» в Телеграме. Там мы вместе обсуждаем проблемы и лучшие практики организации production ML-сервисов, а также делимся собственным опытом. А ещё там раз в неделю выходят дайджесты по DataOps и MLOps.
Способы оптимизации
Скорость инференса зависит от используемых инструментов. Например, можно разворачивать модели только на базовых фреймворках — PyTorch, TensorFlow, PaddlePaddle, TFLite, TorchScript — и получать не самые лучшие результаты. Такие инструменты больше подходят для обучения и тестового инференса моделей, когда нет потребности в высокой скорости ML-сервиса. Для эффективной работы нужно использовать более мощные фреймворки. Например, ONNX Runtime, OpenVINO или TVM.

Скорость разных фреймворков в режиме инференса.
В зависимости от выбранного фреймворка могут быть разные способы оптимизации.
Первый способ — конвертация в ONNX Runtime, OpenVINO или TVM. В большинстве случаев это и последний шаг на пути к ускорению инференса. Посмотрите на график: если конвертировать модель ResNet18 из TensorFlow в OpenVINO, можно ускорить инференс примерно в 10 раз.
Второй способ — использование функций дополнительной оптимизации. В каждом фреймворке, в том числе базовом, есть свои инструменты для ускорения инференса. Яркий пример — динамическая квантизация. Она жертвует «излишней» точностью весов модели, округляет их. Тем самым ускоряет вычисления и инференс.
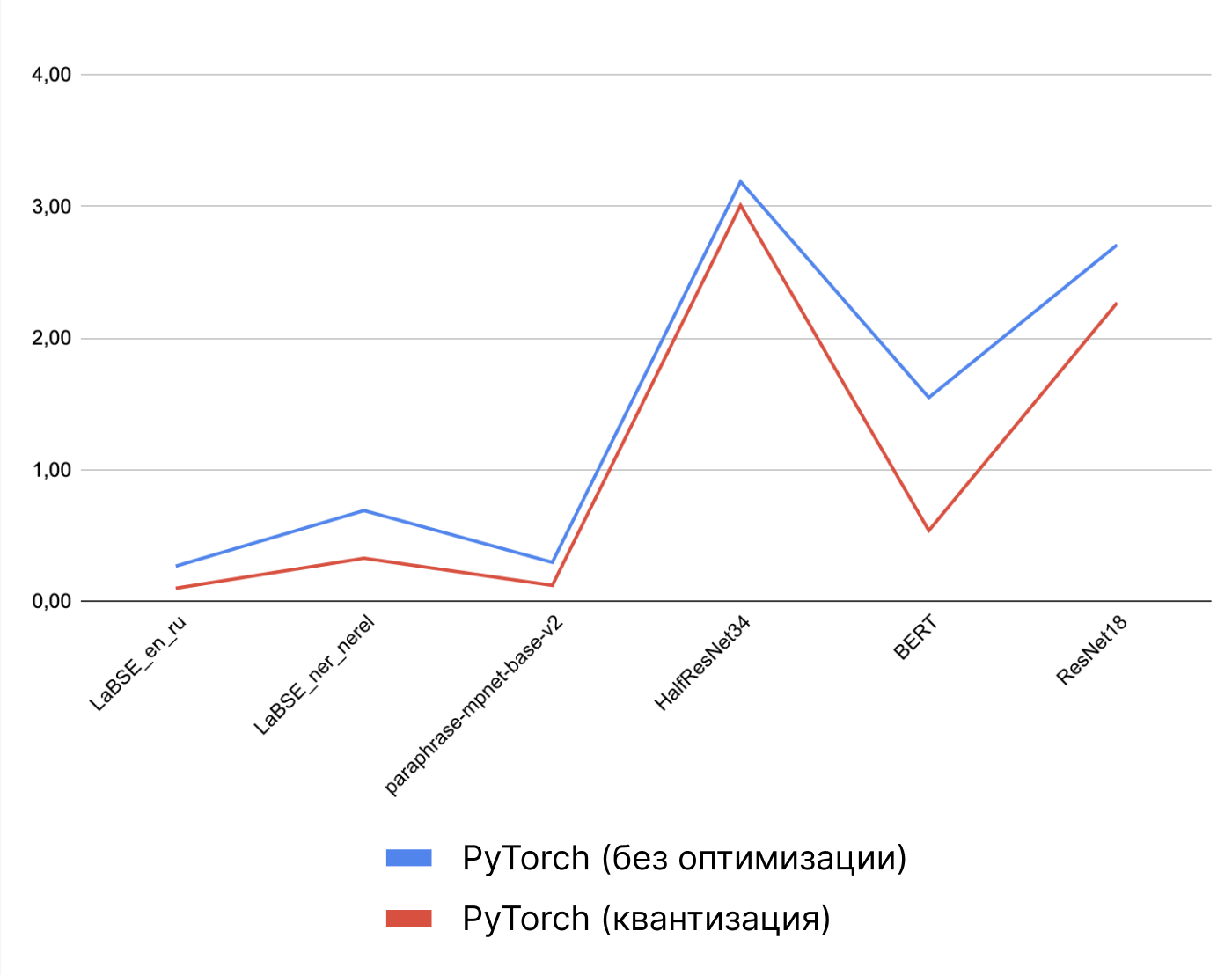
График зависимости времени инференса от выбранной модели. PyTorch, с применением и без оптимизации.
Также можно использовать базовые графовые оптимизации. Например, прунинг — уменьшение размера обученной сети без потери точности, путем удаления лишних параметров из слоев модели.
Третий способ — конвертировать модель в EDGE-версию базового фреймворка. У некоторых базовых фреймворков есть свои оптимизированные под «мобильное» (EDGE) железо версии — в них можно «экспортировать» модели.
PyTorch-модели можно конвертировать в TorchScript, а TensorFlow — в TensorFlow Lite.
Иногда это дает преимущество: если фреймворк адаптирован под EDGE, то, грубо говоря, он лучше справляется с инференсом на процессорах.

График зависимости времени инференса от выбранной модели. Сравнение TensorFlow и TF Lite.
Больше информации о базовых фреймворках можно узнать из полной версии доклада.
Четвертый способ — гибридная оптимизация. Если скорости недостаточно, можно поэкспериментировать. Например, конвертировать PyTorch-модель в TorchScript и сделать квантизацию весов.
Но практика показывает, что лучший вариант — конвертировать в ONNX Runtime, OpenVINO или TVM, а после — использовать их методы дополнительной оптимизации. Но какой фреймворк выбрать?

Бенчмарки эксперимента
Чтобы понять, какой фреймворк лучше использовать, команда из Smart Consulting провела эксперимент. Они проверили, сколько времени и памяти потребляет инференс разных моделей на ONNX Runtime, OpenVINO и TVM. И при каких методах дополнительной оптимизации эти параметры наилучшие.
Правила проведения эксперимента:
- Все рассматриваемые модели должны быть запущены в режиме инференса.
- В рамках одного бенчмарка — несколько циклов тестирования.
- Память и время вычисляются по 100 раз внутри каждого цикла.
- В итоговую таблицу записываются средние значения показателей.
ONNX Runtime
Это open source-движок для конвертации моделей из базовых фреймворков в ONNX-формат — высокопроизводительный инструмент для запуска инференсов.
В ONNX Runtime (ORT) есть дополнительная оптимизация — квантизация и базовые графовые оптимизации. Последнее всегда включено во время тестирования производительности.
Тест на производительность

Бенчмарк CPU-инференса моделей, ONNX Runtime. Оптимизация: квантизация.
По всем рассмотренным классам моделей — для распознавания образов, текста — квантизация в ORT, в среднем, сократила количество используемой памяти на 72,4%, а время работы в режиме инференса — на 42,1%.
Но хорошие ли это показатели? Для ответа на вопрос сравним ORT с PyTorch.
Сравнение с PyTorch
Параметры бенчмарка такие же: тестирование инференса на разных моделях, без квантизации и с ней.

Скорость инференса разных моделей, ONNX Runtime и PyTorch. Оптимизация: без квантизации и с ней.
В большинстве случаев видно, что даже без оптимизации ORT выигрывает PyTorch, который использует квантизацию.
Другая ситуация с количеством потребляемой памяти: ORT без квантизации потребляет не меньше, чем PyTorch. Зато с оптимизацией он показал лучшие результаты.

Потребляемая память разными моделями, ONNX Runtime и PyTorch. Оптимизация: без квантизации и с ней.
Преимущества ORT
Также ORT хорошо работает на процессорах без специальных инструкций AVX. Это хорошо, когда нужно запустить модель на слабом процессоре. С PyTorch ситуация другая: для эффективной работы нужно устанавливать дополнительные расширения. Рассмотрим пару кейсов.
Распознавание образов. Если нужно построить систему распознавания образов, но есть только слабый процессор и ограничения по времени инференса, можно воспользоваться ORT.

Бенчмарк CPU-инференса модели ResNet18, ONNX Runtime и PyTorch, без использования AVX. Оптимизация: отсутствует.
Инференс модели ResNet18 на ORT примерно в 7 раз быстрее, чем на PyTorch.
Распознавание голоса. То же самое и с моделями распознавания голоса. Для системы (например, небольшой социальной сети), которая должна обрабатывать большое количество голосовых сообщений, лучше подойдет ORT.
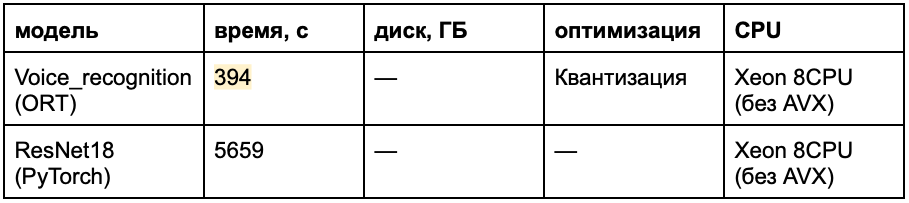
Бенчмарк CPU-инференса модели Voice_recognition, запущенной в ONNX Runtime и PyTorch — на процессоре без AVX. Оптимизация: квантизация.
Инференс модели Voice_recognition на ORT примерно в 14 раз быстрее, чем на PyTorch.
Дополнительный тест

Бенчмарк CPU-инференса модели, ORT. Будет использоваться для сравнения с OpenVINO и TVM. Оптимизация: отсутствует.
OpenVINO
Это открытый ML-фреймворк для оптимизации и развертывания моделей глубокого обучения. В отличие от ORT OpenVINO не такой «гибкий»: инструмент умеет конвертировать только из ONNX. Из минусов — для работы нужны инструкции процессора (SSE4.2 и AVX). Без них OpenVINO либо не запустится, либо не будет просчитывать модель.
Тест на производительность

Бенчмарк CPU-инференса модели, OpenVINO. Оптимизация: отсутствует.
Без оптимизации OpenVINO выдает хорошие результаты, как и ORT на некоторых моделях распознавания образов.
Динамические шейпы
Во время инференса на статических шейпах размеры и форма тензоров не меняются. Но есть ситуации, когда параметры тензора не известны заранее — например, когда меняется размер входных данных модели. Разработчики OpenVINO это учли и добавили динамические шейпы.
При тестировании OpenVINO скорость инференса проверяли как на статическом, так и динамическом шейпе.
Режимы инференса
В OpenVINO есть инструменты для дополнительной оптимизации. Среди них — квантизация и специальные режимы инференса:
- LATENCY — режим на сокращение задержек,
- THROUGHPUT — режим оптимизации RPM,
- ASYNC — асинхронный режим инференса.
Их можно комбинировать и добиваться хорошего времени инференса. Например, с помощью режимов можно ускорить модель BERT на 20-30%. Для этого нужно правильно подобрать комбинацию режимов в связке с динамическим или статическим шейпом.
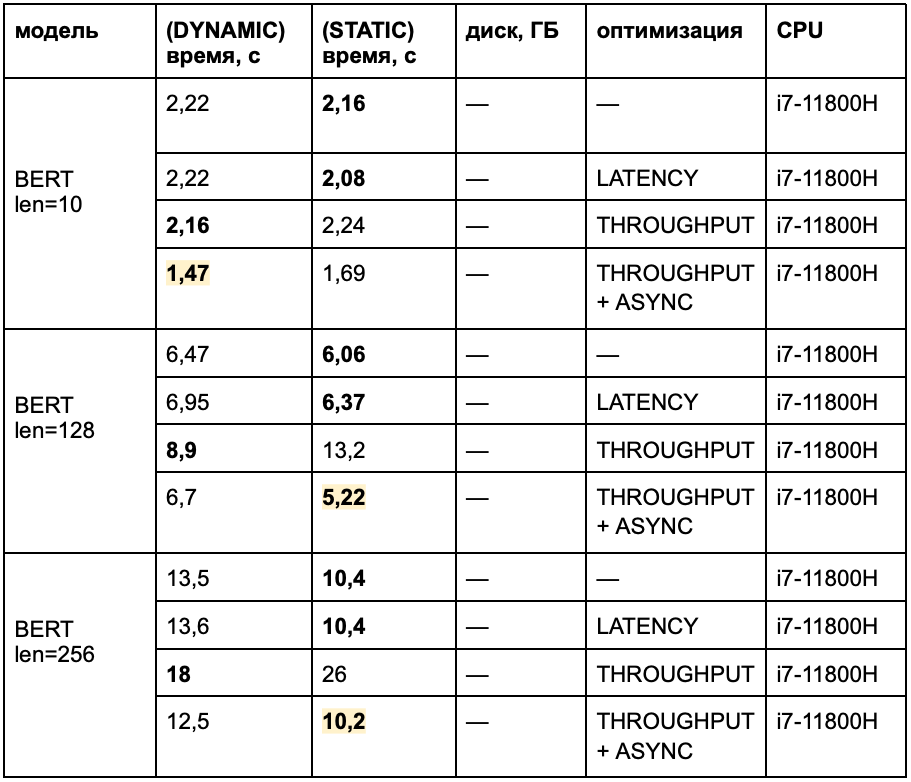
Бенчмарк CPU-инференсов (DYNAMIC и STATIC) BERT-моделей с разной длиной входных данных, OpenVINO. Оптимизация: специальные режимы инференса.
TVM
Это open source-оптимизатор ML, разработанный компанией Apache в 2018 году. Позволяет оптимизировать модели для эффективной работы на любом аппаратном сервере. По сути, это целая система для автоматического создания и оптимизации моделей. А также их конвертации в DLL- и so-форматы для запуска на Windows и Linux соответственно.
Как и ORT, инструмент может конвертировать модели из большого числа фреймворков и форматов. Среди них — ONNX, TorchScript, TensorFlow, TFLite, Keras, MXNet, Darknet, Caffe и Caffe 2, Coreml, Oneflow, PaddlePaddle.
Также в TVM много дополнительных оптимизаций. Некоторые из них еще «сырые»:
- Квантизация — может ускорить инференс в два раза, но пока плохо реализована и может сократить точность модели.
- Компилятор модели — использует три уровня оптимизации под определенный target.
- Auto TVM и Auto Scheduler — необходимы для автоматического тюнинга моделей и улучшения производительности.
Тест на производительность
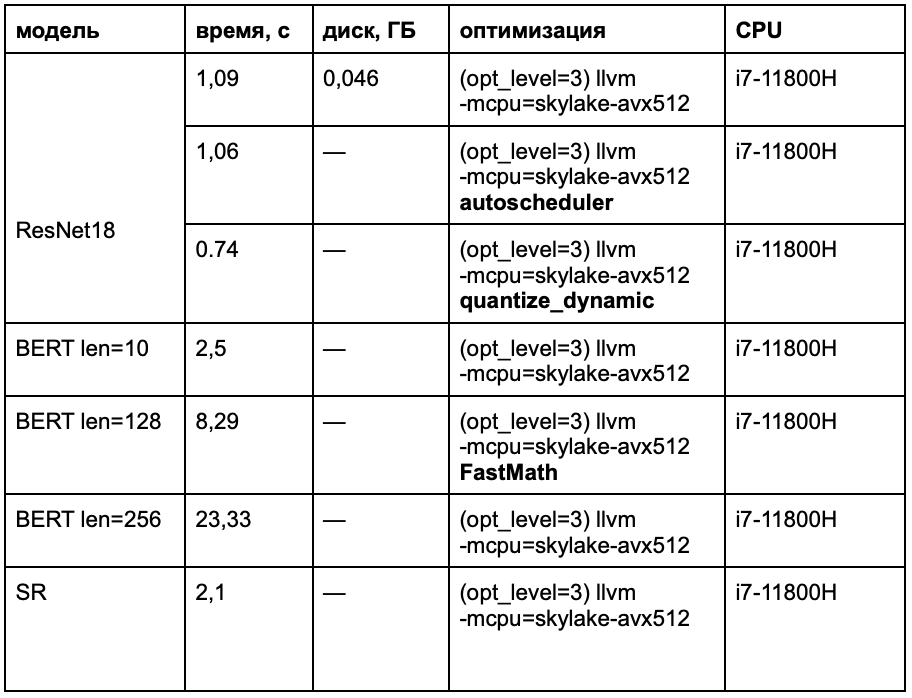
Бенчмарк CPU-инференсов моделей, TVM. Оптимизация: квантизация, Auto Scheduler.
Сложно сказать, насколько эффективны дополнительные оптимизации в TVM. Если у вас есть опыт использования, поделитесь им в комментариях.
Скорость без использования AVX
TVM хорошо работает на процессорах и без использования инструкций типа AVX. Но делает это немного хуже, чем ORT.

Бенчмарк CPU-инференса модели ResNet18, TVM, ONNX Runtime и PyTorch, без использования AVX. Оптимизация отсутствует.
Инференс модели ResNet18 на TVM примерно в 4 раза быстрее, чем на PyTorch. Однако это на 35% медленней инференса на ORT.
Возможно, эти тексты тоже вас заинтересуют:
→ ML в Managed Kubernetes: для каких задач нужен кластер с GPU
→ Баттл «художников»: сравниваем Midjourney, DALL-E 2 и Stable Diffusion
→ Сможет ли Midjourney заменить дизайнеров? Тестируем нейронную сеть
Сравнение инструментов
На протяжении всего эксперимента ONNX Runtime (ORT) был отправной точкой — неким примером для сравнений. Но заслуженный ли этот титул?
На примере нескольких моделей — ResNet18, SR и BERT — был проведен заключающий тест:

Скорость инференса моделей, ONNX Runtime, OpenVINO, TVM.
Эксперимент показал: TVM медленней соперников в два раза, а OpenVINO и ORT идут «впритык» — они оба хорошо подходят для оптимизации моделей обработки языка и компьютерного зрения.

Скорость инференса моделей, ONNX Runtime, OpenVINO, TVM. Крупный масштаб.
В более крупном масштабе видно: OpenVINO, как и TVM, быстрее ORT. Хотя TVM сильно потерял в точности из-за использования квантизации.
«Топ-3» по скорости можно построить так: на первом месте — OpenVINO, на втором — ORT, на третьем — TVM.
Какой фреймворк выбрать?
Выбор фреймворка зависит от конкретной ситуации и предпочтений инженера.
Хотите поэкспериментировать с настройками — используйте TVM. Это перспективный проект. Но его методы для оптимизации еще «сырые»: можно выиграть в скорости инференса, но потерять в качестве модели.
Если нужно гибкое стабильное и «гибкое» решение — используйте ONNX Runtime. Много базовых фреймворков поддерживают конвертацию в ONNX-формат и обратно. Это особенно полезно, если в компании обучают нейросети, например, сразу на PyTorch, TensorFlow и PaddlePaddle. Итоговые модели можно конвертировать в один формат — без затрат времени на оптимизацию каждой из них по отдельности.
Хотите максимально ускорить инференс — используйте OpenVINO. Инструмент несильно опережает ONNX Runtime в производительности, но в работе с большим количеством моделей разница может быть существенной. Из минусов: в OpenVINO можно конвертировать модели только из ONNX. Это препятствует сценарию из прошлого пункта.
Какой фреймворк для оптимизации моделей используете вы? Поделитесь своим опытом и мнением в комментариях. Или подключайтесь к обсуждению в нашем чате.
Комментарии (9)

ErmIg
02.11.2022 22:31Если кому интересно, то с 18 года разрабатываю фреймворк для запуска обученных нейронных сетей на CPU:
https://github.com/ermig1979/Synet
Он ориентирован в основном на однопоточную производительность и оптимизирован под основные процессорные расширения (SSE, AVX, AVX-512, AMX, NEON) (по этому направлению опережает OpenVINO). Он поддерживает конвертацию из формата ONNX и OpenVINO. А также динамическую квантизацию моделей.

artzemliak
03.11.2022 04:08Спасибо за работу и что поделились ссылкой!
Будет интересно опробовать и протестировать)
Ruslan564
03.11.2022 07:54Так бы и сказали, что не можем сделать нормальный GPU. Обучать тоже на CPU советуют?
kokorins
жалко что перевод, а то очень интересны некоторые аспекты?
насколько отклоняются результаты onnx на основном фреймворке в обоих случаях?
есть ли сравнение для jit моделей?
собственно если нужно качество моделей и скорость стоит ли смотреть в эту сторону? конкретнее для больших задач классификации на основе resnet для распознавания.
где можно побольше почитать по теме?
Ritan
Сама по себе конвертация в onnx почти lossless( там есть некоторая разница в наборе операций и их представлении с TF/TFLite ). Года 3-4 назад, когда сталкивался, на чём-то вроде MobileNetV2 погрешность если и была, то на уровне точности fp32
kokorins
а квантизация как влияет?
Ritan
Точность ожидаемо проседает, но точнее не скажу - я не MLщик
artzemliak
Квантизация не особо сильно ухудшает качество модели (иногда в районе 1-го % или даже меньше). Но, всегда нужно держать под рукой тестовый датасет, чтобы можно было бы проверить - "а на сколько качество ухудшилось, и достаточно ли его теперь".
artzemliak
Зависит от модели, но по опыту практически нет изменений в точности (если рассматривать просто конвертацию).
Jit не особо много скорости привносит (в зависимости от модели пока встречал прирост в среднем в 1.5 по скорости).
Для resnet вполне можно смотреть в эту сторону. Плюс, если есть время и свой датасет - то можно рассмотреть пост-квантизацию, прунинг модели (они могут привнести очень большой прирост в скорости, но не слишком просесть по качеству).
Тема сама по себе не особо описанная, так как постоянно развивается. Поэтому тут только либо экспериментировать, либо надеяться на подобные статьи)