
Эта статья будет полезна специалистам по безопасности и DevSecOps, платформенным командам и DevOps, и вообще всем, кто сталкивался или может столкнуться с более, чем одним кластером Kubernetes в продакшене.
За основу взято выступление Алексея Миртова на HighLoad++ Foundation 2022. Он является экспертом и архитектором по безопасности внутри Yandex Cloud. Занимается облачными технологиями больше 10 лет, обладает экспертизой по безопасности в сетях и контейнерах. Построил цикл безопасной разработки в команде 400+ разработчиков для IT-системы на базе Kubernetes в облаке, спроектировал и реализовал Security Operation Center в Казахстане. Доклад готовил вместе с Нареком Татевосяном, экспертом и адвокатом по Kubernetes в Яндексе и соведущим YouTube канала Yandex Cloud.

Речь пойдет о том, как:
Эксплуатировать парк «безопасных» кластеров Kubernetes: создавать и обновлять кластеры, утилиты, сервисы безопасности
Правильно управлять платформенными инструментами и инструментами безопасности.
В рамках статьи будут предоставлены гайдлайны, материалы, решения, как делать кластеры «безопасными».
Внимание! В статье не будет рассказываться как строить безопасность приложений (SAST, DAST и др.) и работать со SBOM, проверять подписи (cosign и др.).
Проблема безопасности кластеров
Когда компания растёт, увеличивается и число кластеров Kubernetes. Темпы роста могут отличаться: например, в Яндексе добавляется по одному кластеру на один бизнес-юнит с независимыми DevOps-инженерами, а у некоторых их заказчиков — по нескольку кластеров на каждую бизнес-команду. В качестве хорошего примера, давайте посмотрим доклад про проект Nautilus. Коллеги из университета Сан-Диего развернули огромный кластер для нужд разработки и вычислений со стороны ученых и студентов. Но затем были вынуждены его децентрализовать и развернуть множество кластеров, чтобы у каждой команды был собственный namespace (пространство имён) для всех процессов и они могли самостоятельно его администрировать.

Что странно, в этом докладе не было ни слова про безопасность. Ведь даже если вы имеете право администрировать только свой namespace Kubernetes, ничто не мешает вам развернуть в нём привилегированный контейнер. Такой контейнер сможет выйти за пределы ноды и скомпрометировать весь кластер. Это огромная проблема для безопасности, поэтому давайте поговорим о том, как не создавать таких уязвимостей.
Что такое безопасный кластер?
Признаки безопасности кластера Kubernetes:
Безопасные настройки. Кластер должен быть настроен в соответствии с каким-нибудь гайдлайном, например CIS Benchmark или другими стандартами, в нём должно быть включено шифрование, аудит и т.д.
Находится в безопасно настроенной среде. Даже если настройки кластера правильные, а среда настроена с уязвимостями или открыты все порты, любой может зайти и удалить кластер.
Есть минимально необходимый набор инструментов безопасности внутри кластера, интегрированный с корпоративными системами. Именно минимально необходимый, потому, что кластер может быть вообще без выхода в интернет, тогда угрозы не актуальны и можно снизить количество инструментов безопасности.
Как безопасно деплоить кластеры
Процесс деплоя и эксплуатации можно разложить на такие блоки:
Сервис получения кластеров Kubernetes. Например, с помощью Terraform;
Платформенные инструменты и инструменты безопасности, работающие параллельно друг с другом;
Приложения — ради их запуска и используют Kubernetes.
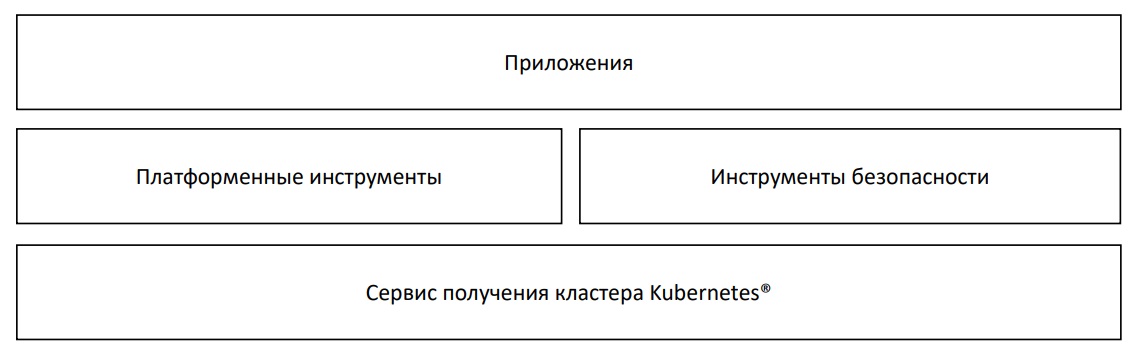
Безопасный деплой кластеров нужен, чтобы получить единую версионированную базу данных всех кластеров Kubernetes, их настроек и инструментов безопасности. А так же автоматику, которая создает, обновляет и настраивает кластеры из этой базы данных и автоматизированные security-проверки конфигурации до раскатки и после.
Рассмотрим некоторые популярные схемы деплоя.
Схема деплоя Time to market mode (push)
Это GitOps push модель, её «пушат» прямо в кластер. Например, когда вы создаете pull request, его подхватывает CI/CD система, например, GitLab или Jenkins. Она реагирует на него и после этого выполняет, например Terraform Apply и создаёт кластеры для ваших команд. Получается так называемый кластер pipeline. Вот как это выглядит:

Ниже могут следовать security pipeline и platform pipeline с инструментами для этих потребностей. Каждое событие порождает реакцию CI/CD системы. Она делает Helm install или Kubectl apply, и устанавливает эти инструменты в несколько ваших кластеров — один и более.
Преимущества:
Это самый быстрый, проверенный в бою способ.
Идеален для одного проекта.
Минусы:
Необходимость ручных операций. Автоматизировать все процессы — не выйдет.
Риск Configuration drift — ситуации, когда фактическое состояние системы отличается от первоначального предполагаемого состояния из-за несовместимости элементов. Например, кто-то вручную зашел в Kubernetes кластер, изменил настройки и в результате появилась разница между настройками кластера и настройками репозитория.
Отсутствие visibility.
Открытие входящих сетевых соединений.
Схема деплоя Kubernetes GitOps mode (pull)
В этой модели вы ничего не пушите в кластер. Он сам подтягивает (git pull) изменения. Например, у вас есть управляющий кластер Kubernetes с установленным в нём GitOps инструментом непрерывной доставки Argo CD или опенсорсным решением Spinnaker. В этом случае кластер pipeline остается без изменений, ведь кластеры раскатываются с помощью платформы Terraform, которая представляет инфраструктуру как код. А Argo CD самостоятельно подтягивает платформенные инструменты и инструменты безопасности каждые 3 секунды и меняет настройки в соответствии с этими изменениями.

Преимущества:
Single company toolset — единый набор инструментов для компании, например, Argo CD.
Single source of truth (enforce) — архитектура единого источника достоверности. Практика сбора данных из многих систем внутри организации в одном месте.
Предотвращение несанкционированных изменений. Даже если кто-то вручную поправит что-то в кластере, Argo CD проверит и вернет настройки в исходное состояние (если включить данную настройку разумеется).
Full asset visibility from GitOps — прозрачность активов в pull-модели с обязательным промежуточным Git-репозиторием.
Недостатки:
Risk of misconfiguration Stack — риски неправильной конфигурации безопасности. Речь о риске быстрого применения неправильных настроек, если произошел быстрый pull, это может породить ошибки в системе из-за которых придется откатывать систему назад.
Схема деплоя Kubernetes GitOps mode (pull)
Если пойти еще дальше, можно отказаться от Terraform для деплоя кластеров и использовать no code инструмент Crossplane.
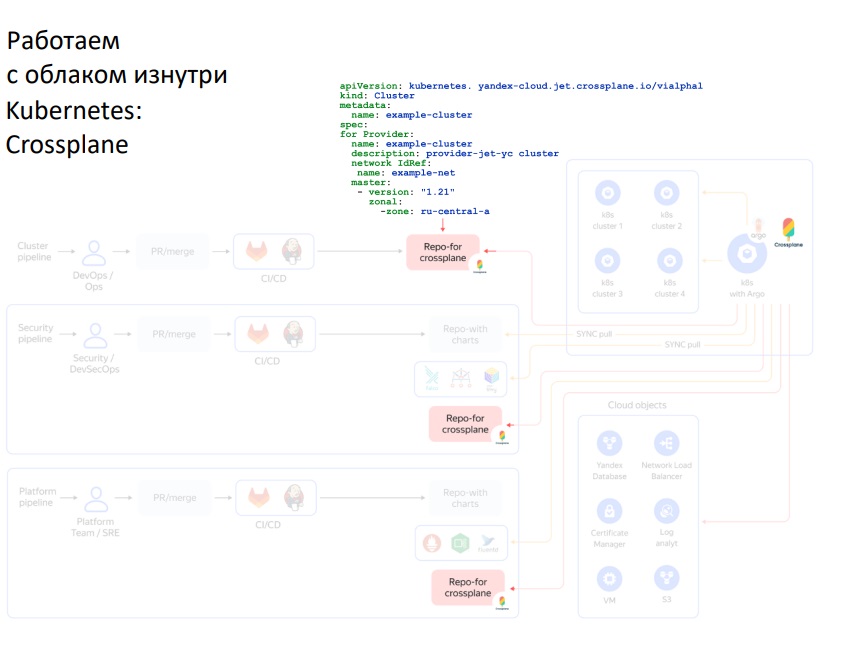
В этой модели в управляющий кластер с Argo CD нужно установить оператор Crossplane и описывать облачные объекты Kubernetes-кластеры, как CustomResourceDefinitions (yaml-файлы). Argo CD применит (Apply) эти файлы, а Crossplane-оператор их подхватит и создаст облачные объекты.
Преимущества: позволяет вынести CD-часть глубже в Kubernetes. В ряде случаев это бывает очень полезно.
Схема деплоя с Kubernetes Platform mode
Для тех, кто хочет пойти ещё дальше, существует инструмент Admiralty, который в своем проекте использовали коллеги из Сан-Диего. Он позволяет рассматривать несколько кластеров, как один виртуальный. То есть это такой интеллектуальный мультикластерный планировщик — multi-cluster scheduler.
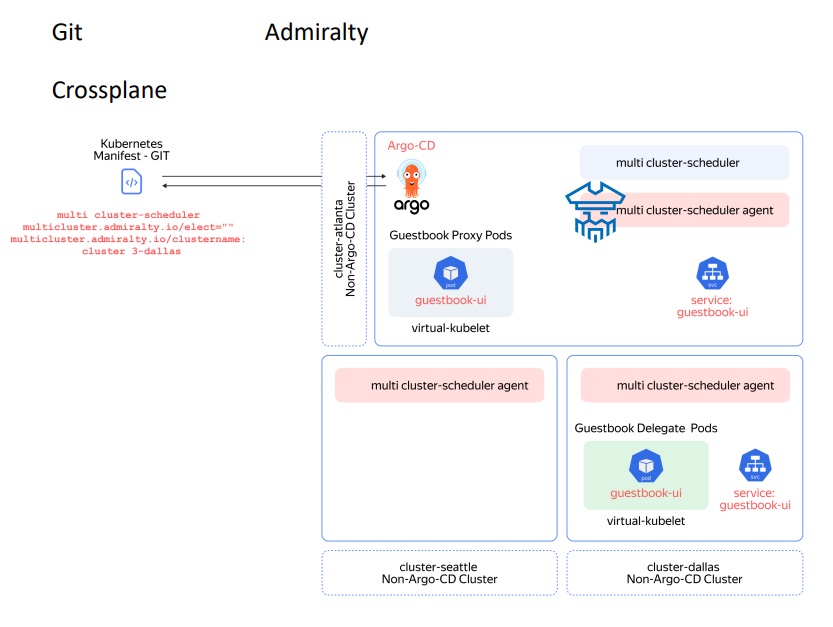
Преимущества:
Централизованный контроль доступа и аудит логов.
Безопасное управление кластерами учетных данных — credentials. В кластер ставится admiralty agents, благодаря которому не нужно открывать входящий доступ, например, к Kubernetes API.
Минусы:
Существенная часть продукта платная.
А что с проблемами безопасности
Terraform
Terraform-манифесты можно сканировать на предмет проблем с безопасностью из-за неправильной конфигурации — security misconfiguration. Например, отсутствие защищенных групп (security group) на нодах кластера, публичных корзинах (Public bucket) и другие облачные проблемы с misconfiguration.
Находить и проверять Credentials и secrets в Terraform и еще следующие типы объектов:
Terraform,
Terraform plan,
Cloudformation,
AWS SAM,
Kubernetes,
Helm charts,
Kustomize,
Dockerfile,
Serverless,
Bicep or ARM Templates
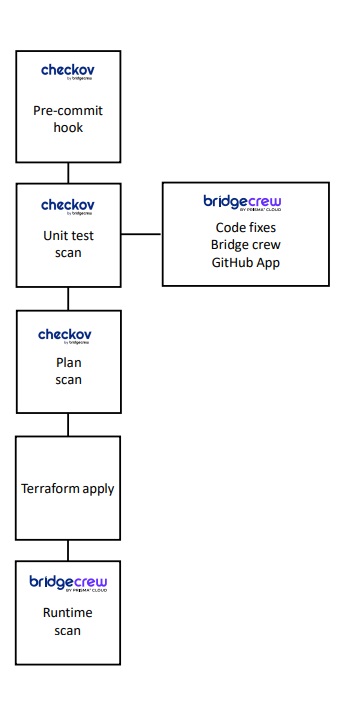
Есть ряд инструментов, например, Checkov, который позволяет сканировать эти манифесты и выдавать ответы. Причем их можно внедрить даже в pre-commit hook на ноутбуке разработчика, или же в CI/CD систему, что привычнее. Сам Checkov бесплатен, но в нём есть платные расширения.
В Yandex Cloud сделали конрибьют из Yandex Cloud в Checkov, чтобы в нём появилась возможность сканировать Terraform-манифесты. По ссылке можно познакомиться с реальным решением, которое на примере GitLab CI/CD позволит вам его использовать.
А еще Yandex Cloud составили чек-лист по безопасности Terraform, который поясняет, почему правильно использовать Terraform state в защищенном object storage, а не на ноутбуке разработчиков и как правильно работать с секретами.
Kubernetes
Также мы подготовили гайд по безопасности Kubernetes:
Если вам нужно соответствовать какому-то стандарту, например, PCI DSS или 152-ФЗ, будучи в облаке, или если вы просто хотите обезопасить вашу среду, пройдитесь по этому гайду. В нём есть такие разделы, как домены, сетевая безопасность, шифрование, аутентификация и возможность настроить по порядку все необходимые параметры.Чеклист по безопасности | Yandex Cloud - Документация
CI/CD
Существует риск, что вашу CI/CD систему могут атаковать. Если к ней получат доступ, то, скорее всего, полный, потому что, как правило, доступы у неё достаточно широкие. На просторах интернета даже есть матрица атак на CI/CD систему, вот как она выглядит:
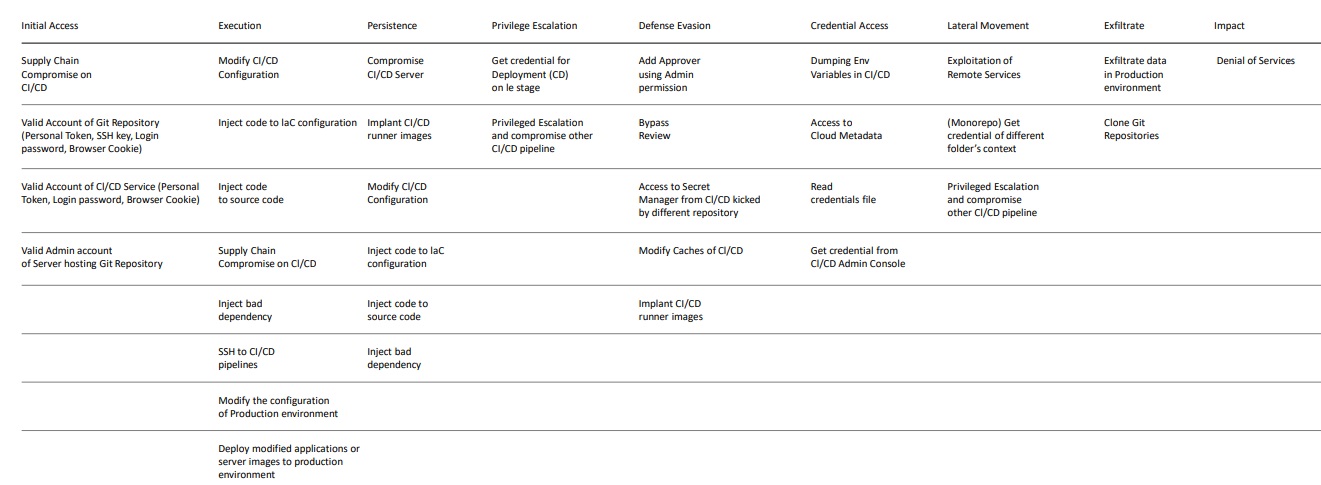
https://github.com/rung/threat-matrix-cicd
GitLab Instance
В чек-листе по безопасности gitlab есть информация о том, как безопасно получать доступ к CI/CD системе, как правильно настроить ее и так далее. Это очень полезная информация при построении модели угроз на вашу инфраструктуру.
Отдельно отметим плюсы Managed Service CI/CD, например, Managed Service for GitLab, который доступен в некоторых местах, включая облако. Недавно опубликовали множество уязвимостей в GitLab. На сайте Yandex Cloud обычно выпускают бюллетени безопасности на эту тему: какая уязвимость обнаружена, каких версий она касается и как её исправить. Если у вас управляемый сервис GitLab, то за обновление можно не переживать. Уже на следующий день эти инстансы будут обновлены.
Инструменты защиты кластеров
Для полноценной защиты нужно:
Настроить инструменты так, чтобы покрыть максимальное количество угроз.
Интегрировать инструменты с корпоративными системами.
Интегрироваться в процессы платформы.
Управление уязвимостями
В Yandex Cloud провели сравнительный анализ инструментов по безопасности (опенсорс и платных) и разбили их на домены.
Сравнение_функций_k8s_security.pdf

В домене управления уязвимостями есть сканирование образов, нод — continuous pentest. Лидируют платные решения, потому что закрывают наибольшее количество функционала — например, Aqua Security, Sysdig. Но набор опенсорсных инструментов — таких, как Kyverno, оператор Starboard, GitLab — позволяют приблизиться к максимальному покрытию без дополнительных расходов.
Runtime Security
В этом домене защищаем runtime, анализируем SYSCALLS, пакеты установленные на ноды и т.д.

Лидируют тоже платные решения, но есть и бесплатные — Osquery, Falco, ClamAV, которые тоже позволяют закрыть большую часть потребностей.
Network security

Функция наблюдения и устранения неполадок Cilium/Hubble позволяет Flow logs частично анализировать и выстраивать карту сети и расширенные сетевые политики. Также есть платные решения, которые немного удобнее.
UI, data logging, compliance
В наличии функции построения карты сети и карты взаимодействия объектов.

Российский продукт Luntry закрывает большинство потребностей. А ещё есть KubiScan и декларативный GitOps-инструмент непрерывной доставки Argo CD, которые обеспечат такое свойство системы кластеров, как observability (наблюдаемость).
Kubernetes cloud audit logs
Говоря об инструментах безопасности, хочется подсветить важность Kubernetes аудит-логов в облаке. Почему-то их не многие реально анализируют.
В облаке аудит-логи делятся на два типа:
Admin Activity audit logs — логи работы с API облака через UI/CLI/Terraform. Это то, что делают с облачным API. Например, создание кластера, изменения кластера, действия с nodes.
Data audit logs — это аудит-логи, встроенные в Kubernetes (К8 native audit logs). Например, создание pod, назначение прав внутри Kubernetes и т.д.
Схематично это выглядит так:
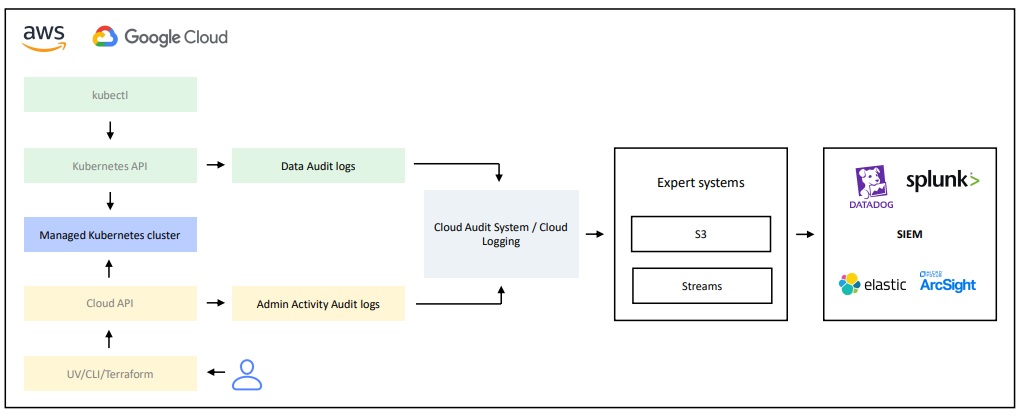
Два типа логов попадают в Cloud Logging System или в Cloud Audit System. После этого их можно экспортировать, например, в S3 или в data streams, а потом уже в SIEM систему, которая у вас есть — например, DataDog, Splunk, Elastic или ArcSight. Какую именно систему вы будете использовать — не имеет значения.
Use cases and important security events in audit logs
Как анализировать логи — не всем понятно, поэтому в Yandex Cloud подготовили use cases. Там рассмотрены подозрительные действия, на которые важно вовремя отреагировать. Это может быть, например, отслеживание событий exec в container, подключение к Kubernetes кластеру извне с публичных адресов, назначение излишне привилегированных прав.
Внедрение инструментов
Enterprise system
Существуют платные enterprise-системы, которые достаточно легко внедряются и содержат всё в одной коробке:
опыт и база знаний от вендора;
полный набор фич в одной коробке;
облегченная установка;
нативные выгрузки событий в систему управления событиями и информацией о безопасности — SIEM.
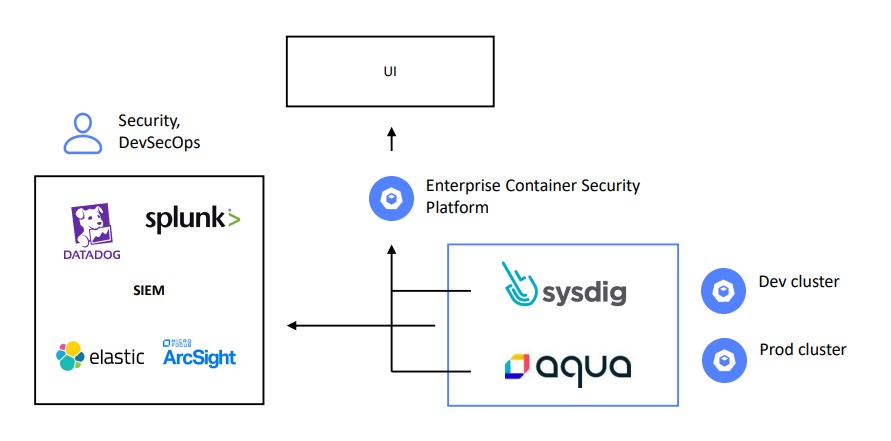
Но эти системы обычно дорогие и у них длинный цикл покупки, что не всегда удобно и к сожалению в настоящее время не многие из них можно купить в РФ.
Open Source System
Альтернатива — опенсорс-решения. Они выглядят примерно так:
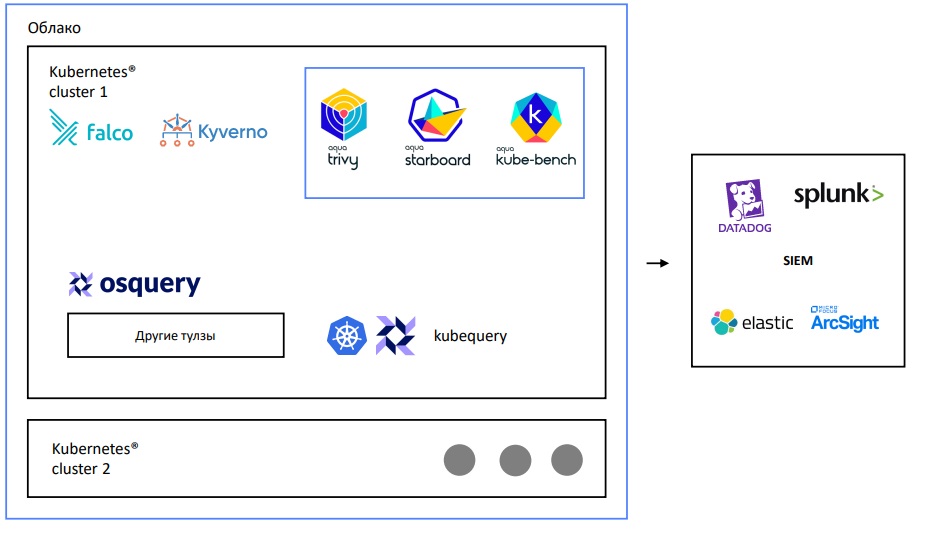
Есть одинаковые кластеры, в которые устанавливают:
Falco для Runtime Security;
Kyverno, как admission controller, например, Starboard оператор (который переименовали в trivy-operator), который содержит Trivy для скан-образов и kube-bench для нод;
Kubequery, который опрашивает ноды на предмет установленных пакетов, наличие юзеров в определенных группах ОС и т.д.
Все эти инструменты нужно отгрузить в SIEM-систему, потому что анализировать срабатывание всех инструментов, вручную заходя в кластер и отслеживая CRD и outputs подов — невозможно.
Open Source System: экспорт событий
Анализ логов обычно выглядит так:
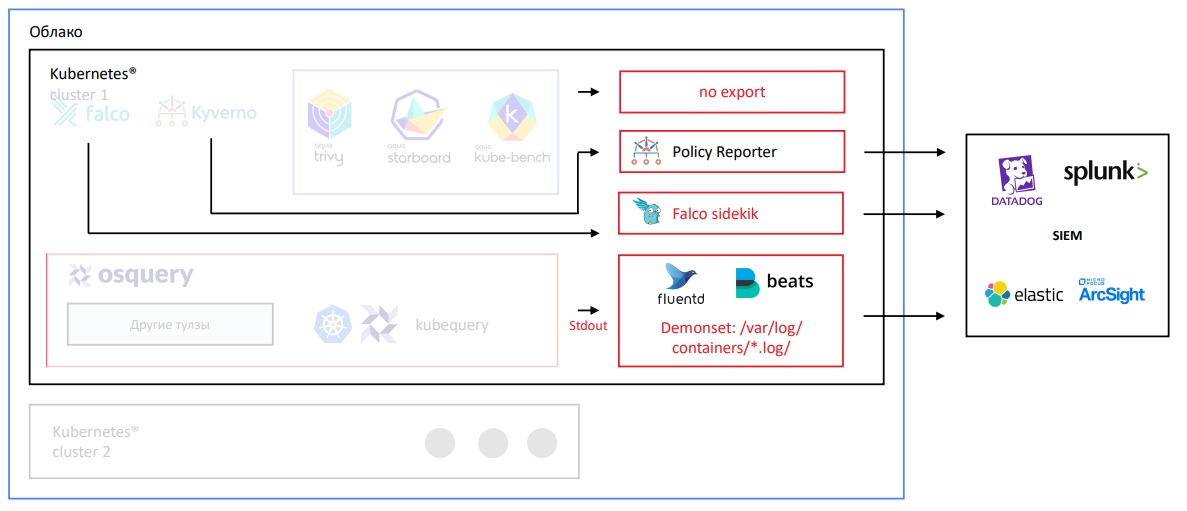
Каждый инструмент содержит еще один инструмент, который позволяет отгружать логи. Например, Falco имеет Falco sidekik, Kyverno — Policy Reporter. У Starboard инструменты отгрузки логов вовсе отсутствуют. А чтобы посмотреть логи в Osquery, нужно установить Fluentbit. Он позволит из папки warlog все отгружать в SIEM, а это не самый простой и красивый путь.
Kyverno Policy Reporter
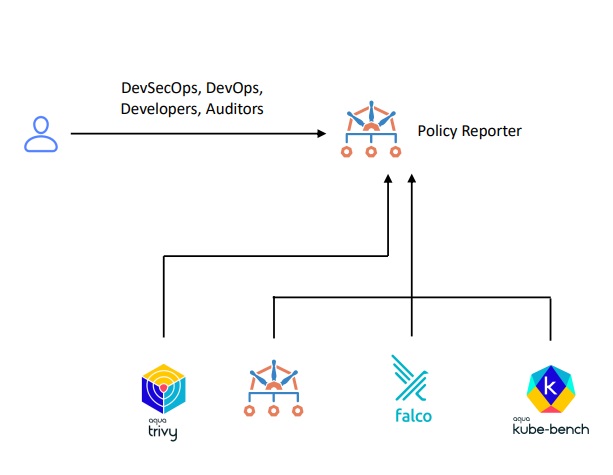
Этот продукт изначально создавался для красивой визуализации и срабатывания Kyverno admission controller. Для тех, кто не знает, с admission controller нельзя создавать привилегированный под в кластере, или монтировать файловую систему ноды и т.д. Вот тут можно прочесть о Kyverno Policy Reporter подробнее: GitHub - kyverno/policy-reporter: Monitoring and Observability Tool for the PolicyReport CRD with an optional UI.
Kyverno Policy Reporter умеет отправлять отработки политик в:
• Grafana Loki
• Elasticsearch
• Slack
• Discord
• MS Teams
• Policy Reporter UI
• S3
• http/s endpoint
Он поддерживает Yandex Cloud S3 и другие S3 совместимые storages и инструменты безопасности вроде Trivy, Falco, Kube-Bench.
Доступность для других облаков
Эти решения работают и в других облаках. Все инструменты можно отгружать в Policy Reporter, а из него, например, в object storage, а оттуда в SIEM систему в формате, приведённом к единому. Нет необходимости в дополнительном парсинге.
Multi cluster mode
Policy Reporter предоставляет cluster view, но позволяет отгружать данные в S3. Этот мод легко внедрить в Yandex Cloud — есть готовые шаблоны для работы с Elastic.
Так выглядит экспорт событий с Policy Reporter:

Есть нюанс, что Policy Reporter ничего не знает про другие кластеры, а взаимодействует только в рамках одного. Здесь возникает сложность, что в SIEM системе нельзя отследить, с какого кластера пришли эти срабатывания, какой cluster_ID они имеют. Но можно прибегнуть к лайфхаку — указывать префикс файлов в object storage, то есть название папки object storage указывать как cluster_ID при установке Policy Reporter. Тогда вы сможете обогащать данные в SIEM систем, используя этот cluster_ID. Либо можно использовать параметр «custoField» в чарте reporter.
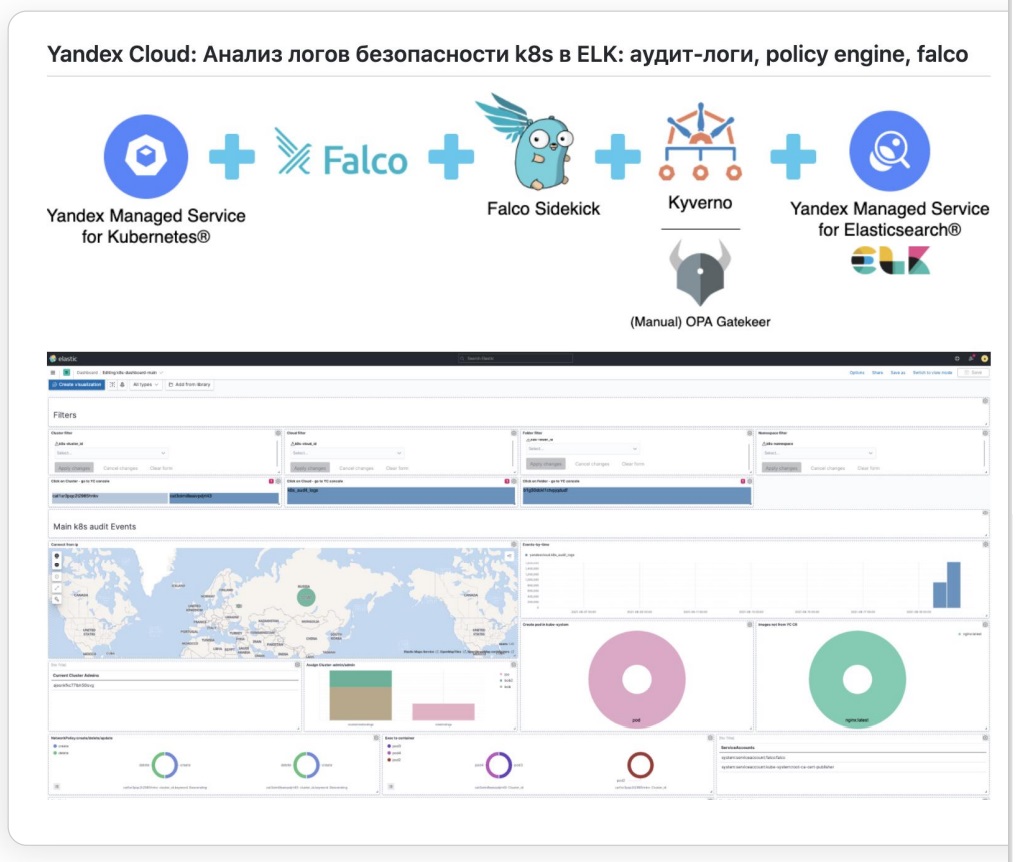
Готовое решение в Yandex Cloud
В Yandex Cloud сделали готовое решение по установке с помощью Terraform Falco, Kyverno, отгрузки всех логов вместе с аудит логами в Elasticsearch. Еще есть Managed Service Elastic, так как это популярное решение, которое работает не только на Managed Service.
Там же загружаются уже предзаготовленные дашборды, содержащие в себе предзаготовленные данные для анализа.
Это технологическая часть условного security-центра, который позволяет фильтровать данные и наблюдать за ними. Для большего удобства можно даже перейти на облачную консоль, кликнув на конкретный cluster_ID.
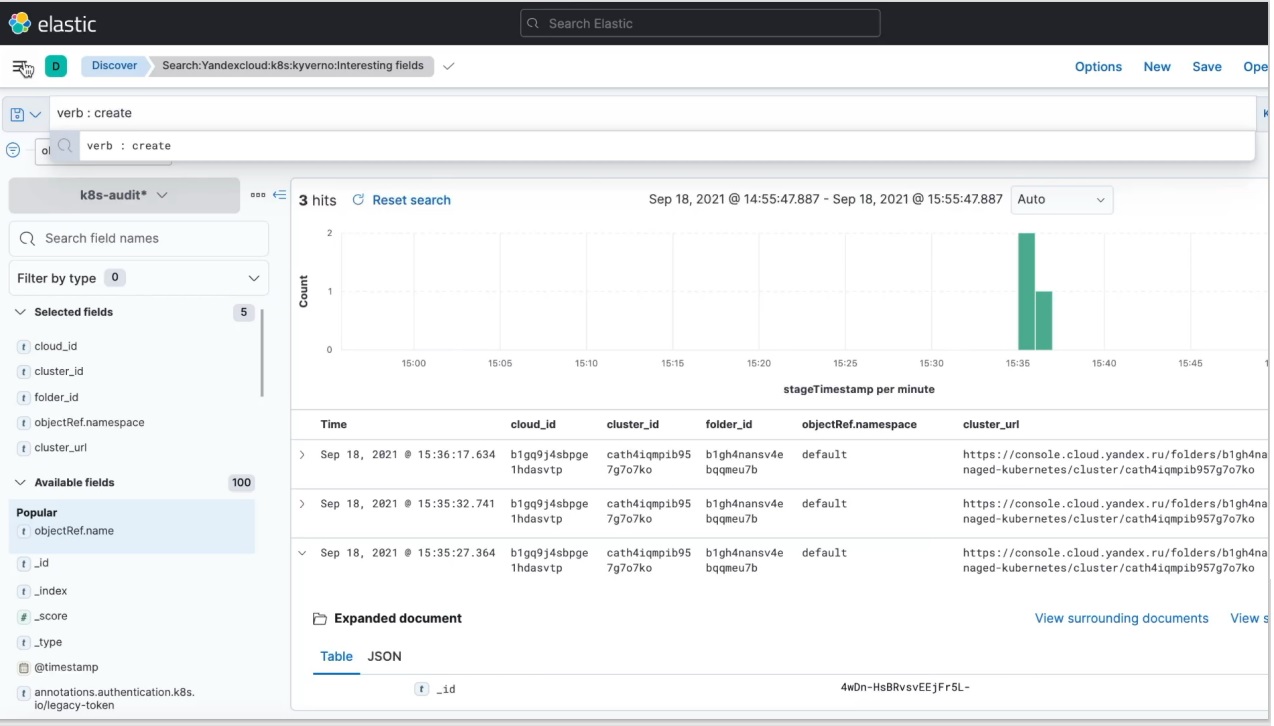
Здесь есть:
Готовый дашборд в Elasticsearch с разбивкой и фильтрами по cluster_ID и сloud_ID.
Карта подключений, которая показывает из каких стран в ваш кластер подключаются админы или другие пользователи.
Дашборды, которые показывают подозрительные действия с сетевыми политиками, контейнерами, сервисными аккаунтами.
Отдельный дашборд для срабатываний инструментов Falco. В режиме таймлайн показывает, какие политики сработали и для каких подов. Отслеживать события можно в наглядной форме. Ниже есть таблица с названием подов, количеством срабатываний и разбивкой по namespace. Если произошел какой-то инцидент, можно зайти и быстро посмотреть, нормальное ли это действие или false positive.
Отдельный дашборд для policy Kyverno. Появится информация, если, например, кто-то создал под, получил расширенные права. Все данные о нарушениях правил подами предоставлены в табличной форме. Можно создать фильтр по конкретному событию и получить детализацию или drilldown по конкретному нарушению правила политики. Есть возможность промотать вниз и посмотреть сырые логи, а затем расследовать конкретную ситуацию.
Конечно, круглосуточно просматривать этот дашборд никто не будет. Поэтому существует механизм алертинга для любой подобной системы, в том числе Elastic. В этом случае правила реагирования подготовлены заранее. Например, проникновение админа в контейнер в продакшене, если установлен доступ только для CI/CD системы. Уведомления тоже можно настроить — например, получать в Slack со ссылкой на Elasticsearch.
Другие решения из нашей Security Library
Это решения, как в Osquery раскатывать DaemonSet, экспортировать Flow logs Cilium, создавать заплатки на CVE: yandex-cloud/yc-solution-library-for-security
Marketplace
Не так давно в Kubernetes появился Marketplace, в котором есть много продуктов по безопасности. Их можно быстро и легко протестировать нажатием кнопки. Многие интегрированы с облаком. Например, при установке можно указать сервис аккаунт ключ — sa keys input — чтобы предоставить доступ в облако для HashiCorp Vault интеграции с KM (Key Management) сервисом. А ещё можно скачать все чарты и использовать/кастомизировать их.

Резюмируя
Как же построить Security center для Kubernetes
Неизбежная потребность в multi-cluster структуре — наличии больше одного кластера.
Выбрать подходящую из существующих схем деплоя кластеров, security- и платформ-инструментов.
Использовать предоставленные мной чек-листы и материалы для обеспечения безопасности кластеров.
Понимать особенности инструментов безопасности и их функций, а также аудит-логов — какие за что отвечают, как можно достичь нужного уровня с их помощью.
Выбирать правильные платные или бесплатные инструменты, исходя из вашей модели угроз, и правильно их интегрировать с корпоративным SIEM. Не забывайте про готовое решение с Elastic SIEM в Yandex Cloud.
Соблюдая эти правила, вы получите много алертов и логов. Останется настроить реагирование на них, потому что иначе они так и останутся нетронутыми файлами в вашей файловой системе. Ведь если не реагировать на эти срабатывания, то все предпринятые усилия были напрасны.
Еще больше решений конкретных кейсов, основанных на профессиональном опыте инженеров в высоконагруженных проектах будет на московском HighLoad++ 24 и 25 ноября. 120 новых докладов по Оптимизации баз данных, Инфобезопасности, Кластерам СУБД, Устройствам систем хранения данных и другим направлениям.

AlexeyK77
Спасибо большое, классная статья. Жаль, что комментов ноль.
Для меня задача подключения кубернетеса к SIEM и разработка правил мониторинга и алертинга еще только впереди, поэтому очень много полезной информации почерпнул.
Посмотрел ваши use cases на гитхабе под сиемы, и мне показалось, что уклон сделан в сторону логгирования для пост-расследования, а не онлайн выявления аномалий для детектирования сценариев успешной атаки и ее последующего развития внутри кластера кубернетеса. Например аномалии использования сервисных уч. записей, подозрительные команды в контейнере, компрометация секретов.
Возможно это у вас есть, но в открытых плэйбуках не описано.
Но все равно огромная благодарность!