
Привет, Хабр!
Меня зовут Владимир Паймеров, я Data Scientist и являюсь участником профессионального сообщества NTA. Сегодня познакомлю вас с библиотекой Gluon Time Series, которую используют для работы с временными рядами.
Рассмотрим библиотеку поближе
Данные временных рядов, то есть наборы данных, которые индексированы по времени, присутствуют в различных областях и отраслях. Например, розничный торговец может подсчитывать и сохранять количество проданных единиц для каждого продукта в конце каждого рабочего дня. Для каждого продукта это приводит к временному ряду ежедневных продаж. Электроэнергетическая компания может измерять количество электроэнергии, потребляемой каждым домохозяйством за фиксированный интервал, например, каждый час. Это приводит к сбору временных рядов потребления электроэнергии. Клиенты могут использовать данные для записи различных показателей, относящихся к их ресурсам и услугам, что приводит к сбору данных, которые основаны на временных рядах.

К распространенным задачам машинного обучения, относящимся к временным рядам, являются:
экстраполяция (прогнозирование),
интерполяция (сглаживание),
обнаружение (например, выбросы, аномалии),
классификация.
Временные ряды возникают во многих различных приложениях и процессах, обычно путем измерения значения некоторого базового процесса за фиксированный интервал времени.
Анализ временных рядов основан на анализе данных, в которых присутствует временная зависимость, с целью обнаружения статистических зависимостей и других характеристик. На основе временных рядов можно делать прогнозы, основанные на использовании обученной модели для предсказания значений в будущем на основе наблюдаемых значений в прошлом.
Основная цель данного поста — знакомство с относительно новой библиотекой для анализа данных с временными рядами GluonTS, узнать, как с ней работать и как строить модели с её помощью.
GluonTS — это инструментарий с открытым исходным кодом, который был разработан внутри компании Amazon (2019 год) для создания алгоритмов поиска аномалий в работе приложений, которые связаны с временными рядами. Модуль позволяет ученым, занимающимся машинным обучением, создавать новые модели временных рядов, в том числе модели, основанные на глубоком обучении, и сравнивать их с современными моделями, включенными в GluonTS.
GluonTS позволяет пользователям создавать модели временных рядов из готовых блоков, содержащих полезные абстракции. В GluonTS также есть эталонные реализации популярных моделей, собранных из этих строительных блоков, которые можно использовать как в качестве отправной точки для изучения моделей, так и для их сравнения. GluonTS предоставляет различные компоненты, которые делают построение моделей временных рядов, основанных на глубоком обучении, простым и эффективным. В этих моделях используются многие из тех же строительных блоков, что и в моделях, используемых в других областях, таких как обработка естественного языка или компьютерное зрение.
GluonTS включает в себя инструменты для загрузки и преобразования входных данных, так что данные в различных формах могут быть использованы и преобразованы в соответствии с требованиями конкретной модели.
Набор инструментов GluonTS подходит для ученых и инженеров, которые исследуют алгоритмы или создают новые и проверяют свои модели.
В набор модулей GluonTS входят:
Модули, которые используются для создания новой модели
Модули загрузки датасетов и их обработки
Заранее загруженные модели
Наборы сгенерированных данных и наборы реальных данных
Начало работы с GluonTS
Для того, чтобы понять, как работает GluonTS, разберу на примере датасета с временным рядом, связанным с тратами пользователей в мобильной игре (данные взяты с сайта Kaggle).
Библиотека GluonTS доступна на GitHub и в PyPI или установкой через командную строку.
pip install –upgrade mxnet~=1.7 gluontsНачну с того, что соберу данные, посмотрю, как они выглядят и выведу график зависимости трат от времени:
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv(‘currency.csv’, index_col = 0)
data.index = pd.to_datetime(data.index)
Код для отрисовки графика:
data[:100].plot(linewidth=2, figsize=(17,7))
plt.grid(axis=’x’)
plt.legend()
plt.show()

По графику видно, что траты повторяются от месяца к месяцу, т.е. в промежутке между началом и серединой месяца происходит рост траты валюты в игре, а с середины месяца до конца траты идут на спад. В GluonTS есть модуль – Dataset,который переводит входные данные в необходимый формат, чтобы модель могла обучиться. Здесь используется ListDataset для доступа к данным, хранящимся в памяти в виде списка словарей.
В GluonTS каждый Dataset — это просто повторяющиеся словари, отображающие строковые ключи в произвольные значения. Чтобы преобразовать входные данные с временным рядом, нужно указать его частоту, т.е. с каким периодом расположены данные (в исследуемом датасете это дневные данные, поэтому указывается D). Также необходимо указать место в данных, с которого датасет разделится на тренировочную и тестовую выборки.
from gluonts.dataset.common import ListDataset
training_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-01’]}], freq = ‘D’)Ниже представлен рисунок, чтобы нагляднее понимать, как выглядят данные после преобразования в определенный вид, нужный для работы с библиотекой GluonTS.

Обучим модель
Подготовив dataset, можно использовать свой estimator (модель) и обучить его. При инициализации модели также необходимо указать частоту, с которой записываются данные во временной, также можно задать эпохи для построения прогноза (в примере задано 20) – сколько раз модель пройдет по данным. В примере используются данные за сутки, поэтому freq=»D», также есть параметр production_lenght, который показывает на сколько дней в будущем можно будет спрогнозировать временной ряд. Задам в примере этот параметр равным 30. В GluonTS уже есть много готовых моделей для предсказания, поэтому исследователям необходимо разобраться какая модель подходит для их задачи, настроить гиперпараметры и обучить модель. В отличие от популярных моделей ARIMA, RNN и т.д., модели, используемые в GluonTS, используют вероятностный прогноз, который основан на распределении вероятностей, а не на одноточечной оценке.
Для построения прогноза взята стандартная модель, которая указана в документации GluonTS, называемая DeepAR и основанная на глубоком обучении (при помощи нейронных сетей). Как упоминалось выше, популярные модели для работы с временными рядами (ARIMA、Holt-Winters’ И т.д.) соответствуют одной модели для каждого отдельного временного ряда. Затем они используют эту модель для экстраполяции временных рядов в будущее. Однако иногда в данных имеется много похожих временных рядов по набору единиц измерения. Например, могут быть группировки временных рядов для спроса на разные продукты, нагрузки на сервер и запросов на веб-страницы. Для приложений такого типа можно извлечь выгоду из совместного обучения одной модели по всем данным, в которых есть временные ряды. DeepAR использует этот подход. Когда в наборе данных присутствуют множество связанных временных рядов, DeepAR превосходит стандартные методы ARIMA и ETS.
Модель DeepAR обучается путем случайной выборки обучающих примеров из целевого временного ряда в обучающей выборке. Чтобы контролировать, как далеко сеть может заглядывать в прошлое, используется гиперпараметр context_length. Чтобы контролировать, как далеко в будущее делаются прогнозы, используют гиперпараметр prediction_length. Для получения дополнительной информации см., как работает алгоритм DeepAR.
Посмотрю, как данная модель показывает себя на загруженных данных.
from gluonts.model.deepar import DeepAREstimator
from gluonts.trainer import Trainer
estimator = DeepAREstimator(freq=’D’,prediction_lenght = 30, trainer = Trainer(epochs=20))
predictor = Estimator.train(training_data=training_data)Оценка модели
Для предсказания признаков используется обученный predictor для нескольких временных диапазонов, которые начинаются после последнего момента времени, используемого для обучения. Это полезно для получения качественного представления о качестве результатов, полученных с помощью этой модели.
Используя тот же набор данных, что и раньше, создается несколько тестовых экземпляров, взяв данные за период времени, ранее используемый для обучения.
test_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-10’]},
{‘start’:data.index[0], ‘target’:data.value[:’2017-09-15’]},
{‘start’:data.index[0], ‘target’:data.value[:’2017-10-20’]}], freq = ‘D’)В примере создам один временной диапазон, который буду использовать как проверочный. Создаётся ListDataset для тестовой выборки, и используется метод to_pandas, для того, чтобы построить графики визуализации, которые работают с другим форматом:
from gluonts.dataset.util import to_pandas
test_data = ListDataset(
[{‘start’:data.index[0], ‘target’:data.currency_spent[:’2017-08-01’]}], freq = ‘D’)
for test_entry,forecast in zip(test_data, predictor.predict(test_data)):
to_pandas(test.entry).plot(linewidth=2, figsize=(15,7), label=’historical values’)
forecast.plot(color=’g’, prediction_intervals=[50.0,90.0], label = ‘forecast’)
plt.legend(loc=’upper left’)
plt.grid(axis=’x’)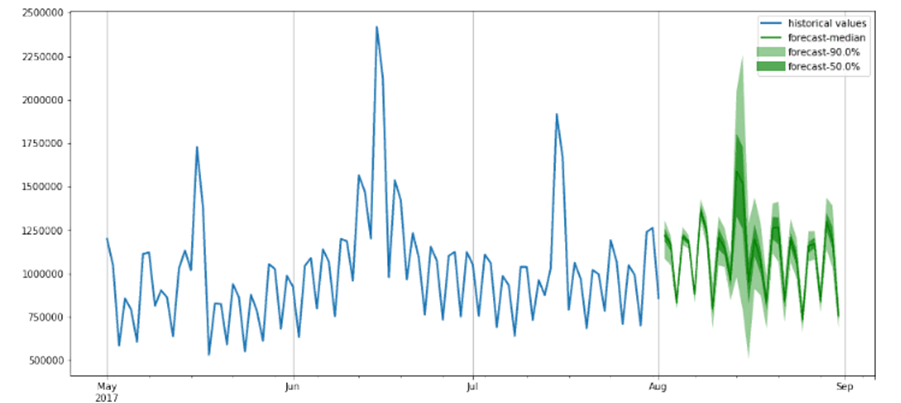
Анализируя график, можно увидеть, что модель построила хороший прогноз, который учитывает месячную зависимость, о которой говорилось выше. Также данный график позволяет увидеть доверительные интервалы и проанализировать их.
Как видно из графика, модель выдает вероятностные прогнозы. Это важно, поскольку оценивает, насколько достоверна модель, и позволяет принимать последующие решения на основе этих прогнозов с учетом этой неопределенности.
После того как убедимся, что прогнозы выглядят разумно, можно вычислить количественную оценку прогнозов для всех временных рядов в тестовом наборе, используя различные показатели. GluonTS предоставляет Evaluator компонент, который выполняет оценку этой модели. Он выдает некоторые часто используемые показатели ошибок, такие как MSE, MASE, симметричный MAPE, RMSE и (взвешенные) потери квантилей.
agg_metrics, item_metrics = evaluator(iter(tss), iter(forecast), num_series=len(test_data))
agg_metrics
Благодаря компоненту Evaluator можно сравнить показатели обученной модели с показателями, полученными с помощью других моделей, или с бизнес-требованиями вашего приложения для прогнозирования. Просмотрев эти показатели, можно получить представление о том, как модель показывает себя в сравнении с базовыми или другими продвинутыми моделями и позволит понять можно ли улучшить результаты, меняя архитектуру или гиперпараметры.
Перед завершением стоит упомянуть об еще одной особенности библиотеки GluonTS. В GluonTS есть модуль, в котором уже есть доступные данные с временными рядами, которые можно загружать и исследовать, для этого нужно импортировать следующие модули:
from gluonts.dataset.repository.datasets import get_dataset, dataset_recipes
from gluonts.dataset.util import to_pandasДля загрузки необходимого набора данных, нужно вызвать функцию get_dataset и указать его имя. Также в GluonTS есть функция, для использования сохраненного набора данных, что избавляет от повторной загрузки датасета: для этого нужно указать «regenerate» = «False».
dataset=get_dataset(‘m4_hourly’, regenerate=True)В заключении
Стоит отметить, что, используя библиотеку GluonTS, получается хороший инструмент для прогнозирования временных рядов, который показывает хороший результат даже без настройки гиперпараметров. К особенностям данной библиотеки относится то, что она использует модели, основанные на глубоком обучении, благодаря чему лучше находятся зависимости в данных. Также в функционал данной библиотеки входят полезные функции построения графиков с доверительными интервалами, которые помогают в анализе. Еще одной особенностью является то, что в данной библиотеке уже есть загруженные датасеты, которые можно использовать не загружая, и, изменив параметры, обучить модель и построить прогнозы. Для подробной настройки гиперпараметров и сравнении GluonTS с другими моделями можно узнать в документации по GluonTS – ссылка, на которую будет присутствовать в литературе.
Литература
Информация по модели DeepAR Forecasting Algorithm
Гитхаб репозиторий с исходным кодом
Документация по GluonTS
IamGikk
А gluon умеет работать со связанными временными рядами? (то есть когда заведомо известно что значения во вр. ряду А зависят от значений во вр. ряду Б, но зависимость не линейна)
NewTechAudit Автор
Да, вход gluon может подаваться один или больше временных рядов. Нейронные сети, которые лежат в основе данной библиотеки, смогут находить зависимости нескольких временных рядов. Модели используемые в GluonTS, используют вероятностный прогноз, основанный на распределении вероятностей, для каждой выходной позиции, а не для одноточечной оценке для отдельного значения. Более подробную информацию можно найти на сайте Amazon – https://aws.amazon.com или на сайте с документацией по GluonTS – https://ts.gluon.ai/stable/