
Если вы прочитали заголовок и подумали «ну, ты, наверно, сделал сначала что-то глупое», то вы правы! Но что такое программирование, как не упражнения в глупых ошибках? Поиск глупых ошибок — это и есть самое большое удовольствие!
Также стоит заранее сделать оговорку о бенчмаркинге: ускорение на 42% было замерено при выполнении программы с моими данными и на моём компьютере, поэтому относитесь к этому результату с долей скепсиса.
Что делает программа?
codeowners — это программа на Go, выводящая владельцев каждого из файлов в репозитории согласно набору правил, указанному в
файле GitHub CODEOWNERS. Правило может гласить, что всеми файлами с расширением .go владеет команда @gophers, или что всеми файлами в папке docs/ владеет команда @docs.При анализе указанного пути побеждает правило, которое совпало последним. Простой, но наивный алгоритм сопоставления итеративно обходит правила для каждого пути, останавливаясь в случае нахождения соответствия. Существуют и более умные алгоритмы, но это уже тема для отдельной статьи. Вот как выглядит функция
Ruleset.Match:type Ruleset []Rule
func (r Ruleset) Match(path string) (*Rule, error) {
for i := len(r) - 1; i >= 0; i-- {
rule := r[i]
match, err := rule.Match(path)
if match || err != nil {
return &rule, err
}
}
return nil, nil
}Поиск медленных фрагментов при помощи pprof и flamegraph
При обработке умеренно крупного репозитория мой инструмент работал немного медленно:
$ hyperfine codeowners
Benchmark 1: codeowners
Time (mean ± σ): 4.221 s ± 0.089 s [User: 5.862 s, System: 0.248 s]
Range (min … max): 4.141 s … 4.358 s 10 runsЧтобы понять, на какие части программа тратит своё время, я записал профиль CPU при помощи pprof. Сгенерировать профиль CPU можно, добавив в начало функции
main следующий фрагмент кода:pprofFile, pprofErr := os.Create("cpu.pprof")
if pprofErr != nil {
log.Fatal(pprofErr)
}
pprof.StartCPUProfile(pprofFile)
defer pprof.StopCPUProfile()Примечание: я пользуюсь pprof довольно активно, поэтому сохранил этот код в виде сниппета vscode. Я просто ввожу
pprof, жму tab, и появляется этот сниппет.У Go есть удобный интерактивный инструмент для визуализации профилей. Я визуализировал профиль в виде flamegraph, запустив следующую команду, а затем перейдя в режим flamegraph из меню в верхней части страницы.
$ go tool pprof -http=":8000" ./codeowners ./cpu.pprofКак я и ожидал, основную часть времени программа тратила на функцию
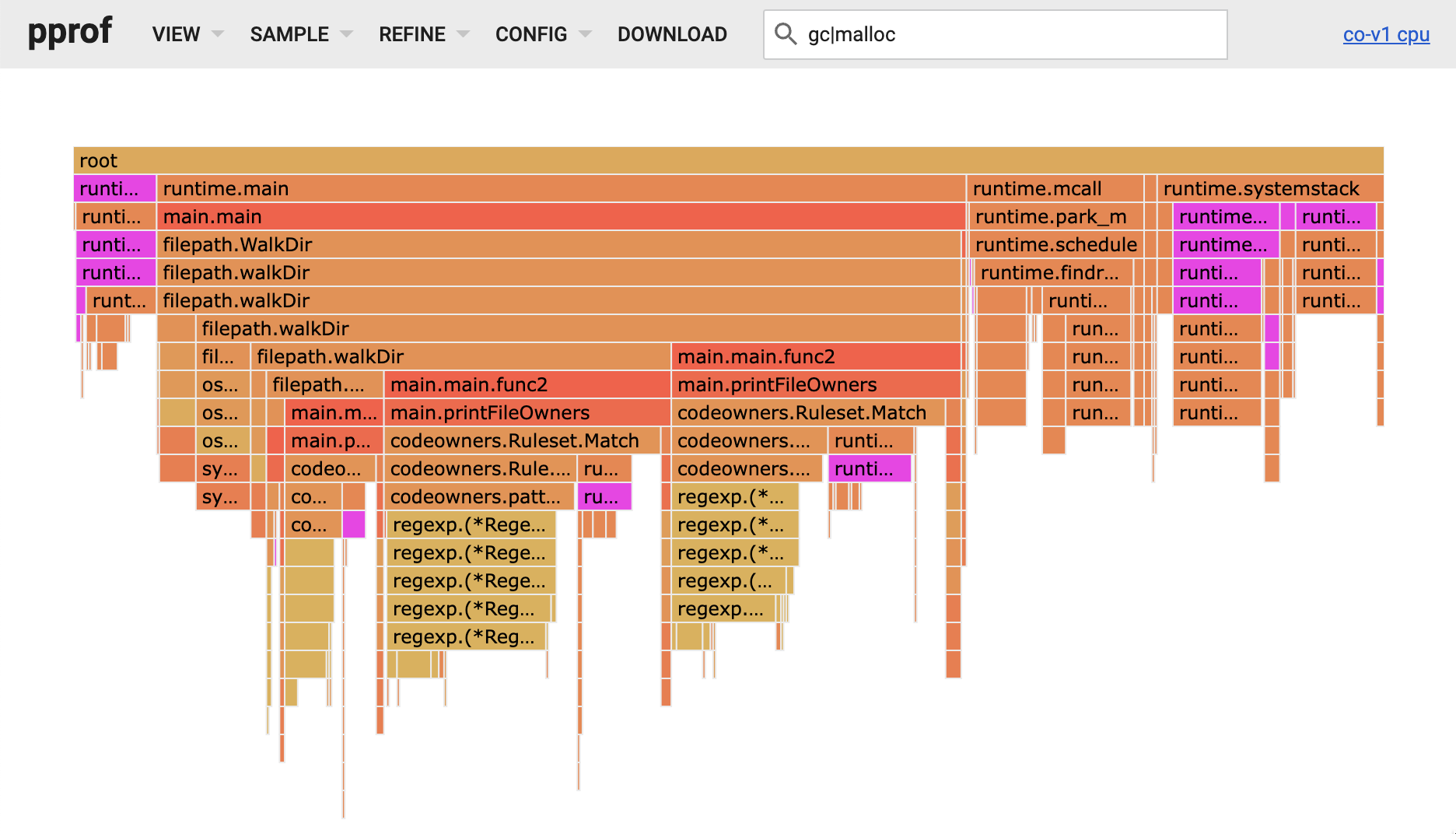
Match. Паттерны CODEOWNERS компилируются в регулярные выражения, и бо́льшая часть времени функции Match тратилась на движок regex языка Go. Но также я заметил, что много времени тратилось на распределение и возвращение памяти. Сиреневые блоки в показанном ниже flamegraph соответствуют паттерну gc|malloc, и видно, что суммарно они составляют существенную часть времени выполнения программы.Охота на распределения кучи при помощи трассировок escape-анализа
Давайте посмотрим, есть ли какие-то распределения, от которых можно избавиться, чтобы снизить давление GC и уменьшить время, занимаемое
malloc.Чтобы разобраться, когда какая-то память должна продолжать жить в куче, компилятор Go использует методику под названием «escape-анализ». Допустим, функция инициализирует struct, а затем возвращает указатель на неё. Если struct распределена в стеке, возвращённый указатель станет недействительным сразу после возврата функции и инвалидации соответствующего кадра стека. В этом случае компилятор Go определит, что указатель «сбежал» от функции и переместит struct в кучу.
Посматривать, как принимаются эти решения, можно, передавая
-gcflags=-m команде go build:$ go build -gcflags=-m *.go 2>&1 | grep codeowners.go
./codeowners.go:82:18: inlining call to os.IsNotExist
./codeowners.go:71:28: inlining call to filepath.Join
./codeowners.go:52:19: inlining call to os.Open
./codeowners.go:131:6: can inline Rule.Match
./codeowners.go:108:27: inlining call to Rule.Match
./codeowners.go:126:6: can inline Rule.RawPattern
./codeowners.go:155:6: can inline Owner.String
./codeowners.go:92:29: ... argument does not escape
./codeowners.go:96:33: string(output) escapes to heap
./codeowners.go:80:17: leaking param: path
./codeowners.go:70:31: []string{...} does not escape
./codeowners.go:71:28: ... argument does not escape
./codeowners.go:51:15: leaking param: path
./codeowners.go:105:7: leaking param content: r
./codeowners.go:105:24: leaking param: path
./codeowners.go:107:3: moved to heap: rule <<< --------- перемещение в кучу
./codeowners.go:126:7: leaking param: r to result ~r0 level=0
./codeowners.go:131:7: leaking param: r
./codeowners.go:131:21: leaking param: path
./codeowners.go:155:7: leaking param: o to result ~r0 level=0
./codeowners.go:159:13: "@" + o.Value escapes to heapВывод выглядит немного зашумлённым, однако бо́льшую его часть можно игнорировать. Так как мы ищем распределения, нас должна волновать фраза
moved to heap. Если посмотреть на приведённый выше код Match, можно увидеть, что структуры Rule хранятся в слайсе Ruleset, насчёт которого мы можем уверены, что он уже находится в куче. И поскольку возвращается указатель на rule, не должны требоваться никакие дополнительные распределения.И тут я понял: присваивая
rule := r[i], мы копируем распределённое в куче Rule из слайса в стек, а возвращая &rule, мы создаём указатель («сбегающий») на копию struct. К счастью, исправить это легко. Нам нужно просто переместить амперсанд немного выше, чтобы мы получали ссылку на struct в слайсе, а не копировали её: func (r Ruleset) Match(path string) (*Rule, error) {
for i := len(r) - 1; i >= 0; i-- {
rule := &r[i] // вместо rule := r[i]
match, err := rule.Match(path)
if match || err != nil {
return rule, err // вместо return &rule, err
}
}
return nil, nil
}я рассмотрел и два других подхода:
- Превращение
Rulesetиз[]Ruleв[]*Rule, что означало бы, что нам больше не нужно явным образом получать ссылку на правило. - Возврат
Ruleвместо*Rule. Это всё равно скопируетRule, но оно должно остаться в стеке, а не переместиться в кучу.
Однако оба эти подхода привели бы к критическому изменению, поскольку этот метод является частью публичного API.
Как бы то ни было, после внесения этого изменения мы можем проверить, дало ли оно желаемый эффект, получив от компилятора новую трассировку и сравнив её со старой:
$ diff trace-a trace-b
14a15
> ./codeowners.go:105:7: leaking param: r to result ~r0 level=0
16d16
< ./codeowners.go:107:3: moved to heap: ruleУспех! Распределение пропало. Теперь посмотрим, как удаление этого одного распределения кучи повлияло на производительность:
$ hyperfine ./codeowners-a ./codeowners-b
Benchmark 1: ./codeowners-a
Time (mean ± σ): 4.146 s ± 0.003 s [User: 5.809 s, System: 0.249 s]
Range (min … max): 4.139 s … 4.149 s 10 runs
Benchmark 2: ./codeowners-b
Time (mean ± σ): 2.435 s ± 0.029 s [User: 2.424 s, System: 0.026 s]
Range (min … max): 2.413 s … 2.516 s 10 runs
Summary
./codeowners-b ran
1.70 ± 0.02 times faster than ./codeowners-aТак как это распределение происходило для каждого сопоставляемого пути, его удаление дало в моём случае увеличение скорости в 1,7 раза (то есть программа начала работать на 42% быстрее). Неплохой результат для изменения в один символ.
Комментарии (37)

tenzink
16.11.2022 14:42+3Однако оба эти подхода привели бы к критическому изменению, поскольку этот метод является частью публичного API.
Разве сейчас контракт функции не поменялся (пусть и не так заметно)? До этого возвращался reference на копию, а сейчас на оригинал. Гипотетически можно представить клиента, который менял полученное правило и при этом никак не влиял на других клиентов. Теперь это изменится

kuftachev
18.11.2022 02:54+1А нельзя просто написать r[i].Match(...)? Зачем это переменная вообще нужна?
Конечно, если как выше написано в комментарии, чтобы отдать копию, то тогда автор статьи рукожоп (не переводчик, переводчик молодец).
Zara6502
Кодировал алгоритмы на C# и заметил что изменение позиции объявления переменной влияло на время исполнения на 20%, условно
int a=0;int b=0;менял на
int a=0, b=0;Мне это очень не понравилось, по сути JIT пропускал кучи оптимизаций только из-за особенностей трассировки моего кода. Это эпикфейл MS.
face86
Не знаю, как у вас там в С#, но для микроконтроллеров в классическом СИ в любой приличной IDE (IAR, KEIL, и т.д.) компиляторы имеют несколько режимов оптимизации уже давным-давно. И как раз такие вещи они прекрасно обрабатывают. Даже могут несколько строк кода выбрасывать из прошивки, если эти строки не имеют смысла. Во время отладки с непривычки разработчик может быть удивлён тем, что отладчик пропускает некоторые строки и даже блоки кода типа простых циклов со счётчиком, который нигде больше не используется (например, для задержки на 1 млн тактов).
Уверен, что для С# оптимизация настраивается от и до.
speshuric
Нет. Это по многим причинам не так. По большому счёту основная разница идёт между debug и release режимами - между ними разница значительна и, конечно, тестирование производительности в debug не стоит выполнять.
Компиляция C#->IL почти не настраивается и почти не оптимизирует (ну разве что на уровне вывода типов немного). Это, похоже, принципиальный подход.
JIT (IL в машинный код) тоже особо не настраивается - это скорее нужно для отладки самого движка .Net, чем для прикладных программистов. Причём JIT ограничен в оптимизациях - во-первых жёсткие требования к времени компиляции, во-вторых некоторые вещи нельзя оптимизировать "как в C" потому что нельзя по контракту.
В итоге .NET может выявить какие-то константные вычисления, некоторые peephole оптимизации, ограниченно может заинлайнить, может выкинуть неисполнимые ветки кода. Но, например, не делает оптимизацию tail recursion - скорее всего для сохранения возможности размотки стека при исключениях, возможно по этой же причине хвостовой call никогда не преобразует в jump. Расчёт констант и выражений, оптимизация циклов и глубина инлайнинга тоже очень далека от -O3 С/С++. Но не скажу, что всё совсем плохо (пользуясь случаем, скажу спасибо @Nagg за его вклад в дело оптимизации движка).
Важно отметить, что это не "C# плохой", это скорее "C# другой".
Aleshonne
Вообще говоря, инструкция tail. в IL есть. Другое дело, что компилятор C# очень тяжело заставить её применять. А вот F# и Nemerle активно используют хвостовую рекурсию, если это возможно (например, нет обработки исключений с вызовом рекурсивной функции внутри).
speshuric
Ну что же, век живи - век учись. Спасибо за наводку. Я не знал о её существовании. В любом случае, C/C++ компилятору проверить допустимость хвостовой рекурсии обычно проще (и поэтому она происходит).
Aleshonne
Иногда под дотнетом очень интересные оптимизации встречаются. Например, тот же F# часто вообще рекурсию в цикл преобразует.
Пример с факториалом
Было:
Стало:
Эквивалентный код на C#:
Deosis
Это и есть пример оптимизации хвостовой рекурсии:
Перезаписать аргументы и перейти к началу функции.
a-tk
Собственно пруф:
https://sharplab.io/#v2:DYLgZgzgNAJiDUAfYBTALgAjAQwMaYDsMBeAWACgMqNVMAnFXLPNAfToyLybMuv4C22NLgAWnDAHcAlmlEV+/RBgCMGALQA+DNwWKqyolub52GABRHVASgvcMAKk7W9VaWAna1clERymOIjUUYAgUVVcMIA=
0xd34df00d
Это достаточно стандартная оптимизация для функциональных языков.
a-tk
Только не инструкция, а префикс инструкции.
Вот только в своё время изменение обработки этого префикса в JIT-компиляторе вызвало некоторое удивление у некоторых людей.
Не скажу за детали, но суть была в том, что некоторый человек ориентировался на то, что tailcall игнорируется и некоторый ресурсоёмкий сервис в облаке падает со stack overflow, а после обновления рантайма он внезапно стал использовать хвостовую рекурсию и не падал, а пользователю за работу сервиса был выставлен немалый счёт (это в телеге в pro.net как-то обсуждалось)
Aleshonne
Я, конечно, по профессии нифига не программист и код пишу исключительно для автоматизации работы или в качестве хобби, но мне кажется, строить логику работы программы на ошибках — это неимоверная дичь.
ColdPhoenix
Хотелось бы увидеть какой-то тест, не один год в C#, никогда не замечал подбного.
Так как JIT о C# ничего не знает, это надо на iL смотреть.
shushu
Я думаю было бы хорошо иметь полный пример
speshuric
... и желательно на https://sharplab.io/
Zara6502
Нет особой разницы в тем что я написал выше, так было:
этот код при обработке файла в 900М отрабатывал за 2400 мс, а этот код:
уже за 1800 мс. Была однозначная повторяемость результатов.
Позднее в другой программе тоже игрался с объявлением переменных, там код
менялся на
и выполнение ВСЕЙ программы замедлялось на 40%.
Я пишу без ООП, короткие программы, я не разработчик, проверяю какие-то алгоритмы и т.п. и для меня такое поведение - нонсенс, так как еще с Turbo C я прекрасно помню как сам компилятор оптимизирует код.
я не занимаюсь публикацией своих программ.
speshuric
Не обязательно же всю программу.
Я сделал пример, но в нём разница на 1 mov (и то, зависит просто от кода ниже)
Надеюсь, что разница именно в release режиме?
Kelbon
Наличие этой разницы уже многое говорит
speshuric
Ни о чём не говорит. Это даже на синтетическом примере не даст и 3% разницы.
0xd34df00d
Говорит о том, что поведение компилятора зависит от конкретного синтаксического дерева чуть больше, чем можно было ожидать.
Zara6502
Сейчас мы НЕ доказываем что код меняется на 40% производительности, мы показываем суть моего треда - при синонимичном изменении кода меняется состав инструкций ЦПУ в конечном коде. Важно именно это, а не сколько там скушает mov.
KvanTTT
В начале топика вы четко сказали про 20%:
Zara6502
если не всю, то я уже вам дал всё необходимое. а без всей программы эффект может и не наблюдаться. вон ниже уже начали петь песню про неправильное тестирование, но это не то совсем.
raptor
У автора там "опечатка" или хз как ее назвать. Если ее убрать - скомпилированный код будет идентичный. SharpLab
speshuric
Да, упустил и не проверил внимательно - как раз к тому, что от небольшой семантически значимой разницы может измениться код. Это отличие было в и коде комментария. Там еще и
jопределена была.KvanTTT
Возможно, вы просто не умеете замерять производительность.
Zara6502
Ох, любимый комментарий XD Если его не пишут, то считайте день прошёл зря.
Вы подразумеваете, что если программа А в одних и тех же условиях выполняется то 1 минуту, то - 5, то виноват не код программы (язык, компилятор, оптимизации), а процедура замера? (надеюсь вам же не приходит в голову, что два подряд объявления int не являются синонимичными записи с одним int???)
Это как на олимпийских играх для бегунов на 400 метров поставить две пары фотоэлементов и регистрировать старт и финиш, а потом кто-то скажет, что есть квантовая суперпозиция и ваш способ замера не учитывает искривление пространства-времени.
speshuric
Да, измерять производительность не так просто. Это не про "искривление пространства-времени". Судя по разнице и кейсу, скорее всего у вас разница проявляется на debug режиме. Могу ошибаться, но вы же так и не предоставили конкретные кейсы и замеры. И в этом случае у вас вашим бегунам надо одному после каждых 10 метров отмечаться в бланке о пробегании 10 метров, а второму - раз в 50 метров. В такой процедуре уже неважно, чем вы измеряли - фотофинишем или ручным секундомером, потому что скорость бега на 400 метров вы не измеряете.
База с которой в принципе можно начинать замерять производительность - поставить максимально в одинаковые "стандартные" условия измеряемые кейсы (в .NET стал стандартным инструмент BenchmarkDotNet, в JVM - JMH). Следующая часть - зафиксировать и описать окружение. Следующая - сформулировать гипотезу (в данном случае - что однострочное объявление лучше многострочного). Потом - проверить гипотезу. Потом, если она подтверждается замерами - максимально изолировать причину и уменьшить влияние других факторов. По результатам уже можно было бы поднять issue в проекте dotnet runtime.
Да, бывают какие-то отклонения от этой процедуры, например, если бага в инлайнинге jit, то она как раз НЕ проявляется в debug, а проявляется в release (я такой кейс находил). Но это всё равно примерно тот же сценарий (только код был одинаковый, а окружения отличались ровно на опцию debug/release).
Zara6502
Это не дебаг, что очевидно.
Мне не нужен специальный инструмент для измерений если я имею статистику и повторяемость результата при изменении кода. Но если вам так легче:
Что это изменило? XD
KvanTTT
Так полный код предоставьте, на котором такое поведение наблюдается, иначе это все равно голословно.
Zara6502
1) NDA
2) Мы не в суде, я сообщил информацию к сведению, вы можете её проигнорировать
KvanTTT
Ну я, в свою очередь, постарался донести свое мнение до других пользователей, которые прочитают ваше сообщение.
raptor
У вас не идентичный код, что выше привели вы. У вас не только изменение в объявлении, но и само присваивание для eof совершенно подругому описано. Ваша проблема может состоять в том, что для вычисления eof переменная S уже ушла из кеша процессора например
gdQuel
Неужели все это стоит учитывать?
KvanTTT
Голословное утверждение, ничем не подкрепленное.
Zara6502
у меня нет задачи сделать вас своим адептом, но !!!! все, кто пользуется C# не на уровне "Hello World!" знают, что ассемблерный код может очень сильно меняться при несущественных изменениях в программе, просто я лично не ожидал, что эти изменения могут быть практически фатальными для производительности. Я привык, что компилятор умнее меня с точки зрения оптимизации, я это видел и вижу при работе с MOS 6502, с 8088/80386, во всяком случае я не жду от них такой подставы.