
Привет, Хабр!
Меня зовут Никита Герасимов. Я разработчик в Юле, проект VK. Моя команда развивает личный кабинет, а также занимается исследовательскими задачами. В этой статье я поделюсь сценариями использования Confluent Schema Registry вместе с JSON и Protobuf, которые мы применяли для типизации сообщений, передающихся в Kafka. Мы в Юле используем Go и PHP, поэтому наше решение проверено прежде всего для этих языков.
Проблемы, с которыми мы столкнулись
Мы делаем Юлу уже 7 лет, из небольшого проекта она превратилась в сервис объявлений с аудиторией в 33 млн пользователей. За это время в Юле появилось значительное количество функций и настроек, реализованных в разных компонентах. Одна из трудностей, встающих перед разработчиками подобных распределённых систем, связана с обеспечением согласованной работы отдельных компонентов, а именно с поддержкой контрактов сервисов. Мы также столкнулись с некоторыми проблемами, вытекающими из первоначального отсутствия контрактов.
Документация
Первая из причин, почему важны контракты — необходимость в удобной, наглядной и актуальной документации сервисов. Желательно, чтобы не было необходимости писать её вручную, так как это повышает риск ошибок и неточностей. Например, разработчик может забыть актуализировать описание каких-либо внешних интерфейсов, либо описать их по-своему. Второе, кстати, может привести к набору разнородной документации с разной структурой, особенно если используются инструменты вроде Вики.
Контракты же сами по себе могут являться неплохой документацией, описывая внешний интерфейс сервиса и способ взаимодействия с ним. Будучи, как правило, описанными с помощью DSL, они стандартизированы и могут автоматически синхронизироваться с исходным кодом.
Ломающие изменения в интерфейсе сервиса
Эта проблема, как и предыдущая, касается не только коммуникации через Kafka, но и REST API, GraphQL и других протоколов коммуникации. Её суть заключается во внесении обратно-несовместимых изменений в интерфейс сервиса. Причиной таких изменений может быть как банальная ошибка, так и осознанное ломающее изменение, если цена этого изменения значительно ниже цены поддержки обратной совместимости.
Несмотря на то, что ломающие изменения были осознанные, сервис может использоваться и другими командами, не готовыми к радикальным обновлениям контракта. В таком случае в некоторых зависимых сервисах может произойти сбой и пострадают конечные пользователи.
Сценарий с ошибкой может быть разрешён с помощью проверки всех правок, вносимых в контракт. Потенциальные проблемы из-за целенаправленных ломающих изменений также можно попробовать нивелировать с помощью контрактов.
Решение
Из предыдущей главы можно вывести несколько требований к формату контрактов сервисов, их хранению и обновлению:
В первую очередь, решение должно быть адаптировано для событийной модели коммуникации, основанной на Kafka, потому что именно этот брокер мы используем в Юле.
Необходима возможность наглядного отображения контрактов в интерфейсе.
Необходима проверка изменений контракта.
Наши проблемы и требования не уникальны, поэтому мы достаточно быстро нашли решение, часто использующееся в мире Java-разработки: Confluent Schema Registry (далее сокращённо SR).
SR представляет из себя REST-сервис, хранящий схемы данных, передаваемых через Kafka, позволяющий проверять изменение этих схем и поддерживающий историю изменений. Схемы могут быть в форматах JSON-Schema, Protobuf и Avro. В качестве хранилища данных SR использует специально выделенный топик в Kafka.
Сервис хорошо интегрируется в Confluent Platform (версия Kafka от Confluent), а также работает с обычной Apache Kafka. Кроме того, его можно использовать бесплатно.
Одной из важных особенностей SR является возможность проверять изменения схем разными стратегиями:
Forward:можно добавлять обязательные поля и удалять необязательные.Backward:можно удалять обязательные поля и добавлять необязательные.Full:можно добавлять или удалять только необязательные поля.None:совместимость не проверяется никак.
Проверяются все три формата схем, а настройку совместимости можно установить глобально или для отдельного топика.
Распространённый способ использования SR

Для лучшего понимания, как стоит использовать Schema Registry, необходимо разобраться, как этот сервис обычно используется в других проектах.

На схеме изображён обобщённый алгоритм использования SR для продьюсера Kafka вместе с форматом передачи данных Avro. Схема данных располагается в репозитории проекта и дублируется в Schema Registry.
Сервис запускается вместе со своей схемой.
При запуске сервис получает из
SRидентификатор схемы. Если она отсутствует вSR, то будет зарегистрирована или обновлена. Если схему невозможно обновить из-за её некорректности или несовместимости с предыдущей версией, то дальнейшая работа невозможна.Данные для отправки будут сериализованы с помощью той схемы,
IDкоторой был получен на шаге 2.К сериализованным данным добавляется префикс — int-представление
IDсхемы. Сериализованные данные могут быть представлены вJSON, в бинарном или другом виде.Сериализованные данные с
ID-префиксом отправляются вKafka.IDсхемы отправляется в телеKafka-сообщения, никаких иные поля, например, заголовки при этом не используются.
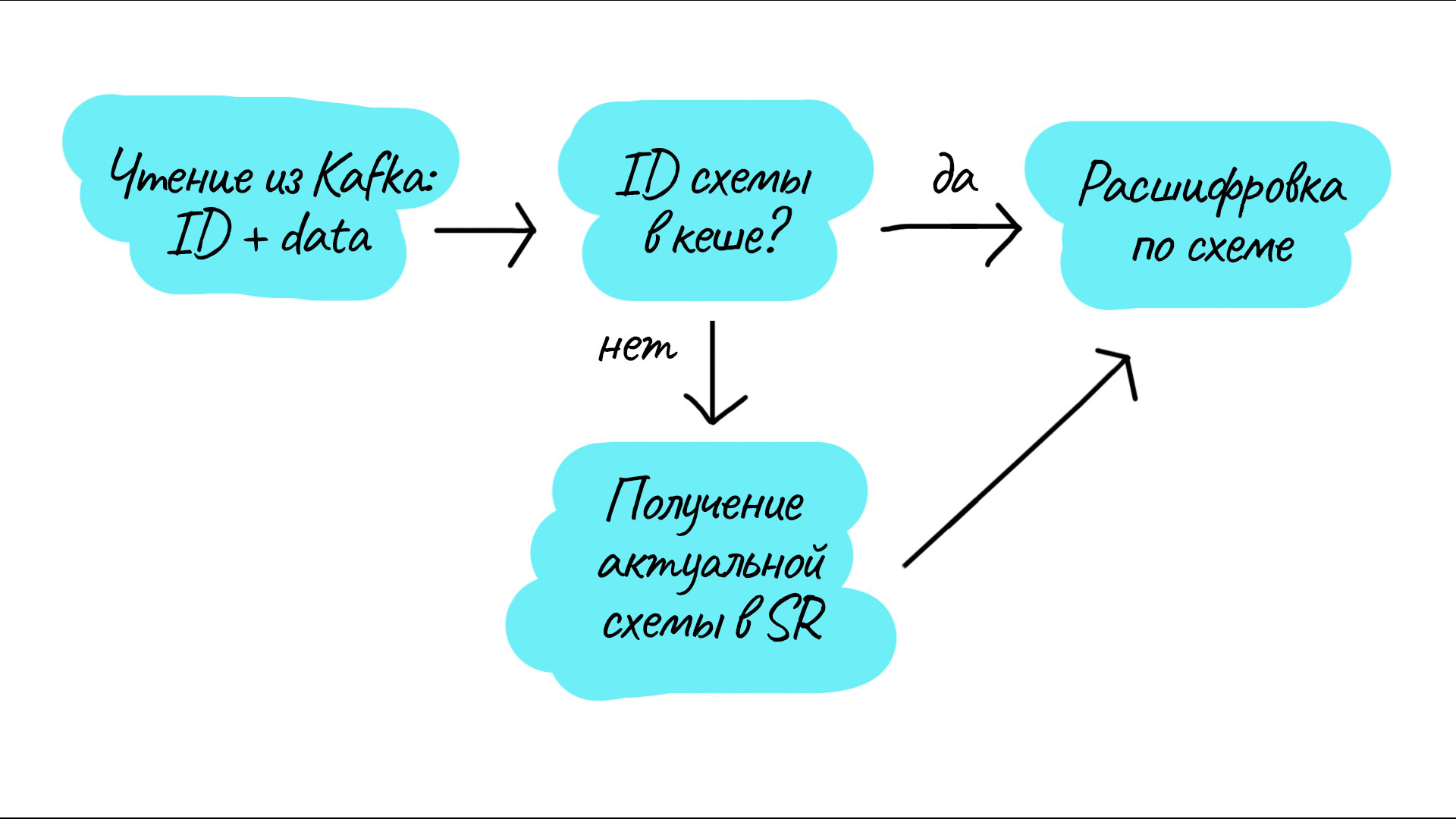
Консьюмер будет работать похожим образом:
Сервис запускается и получает сообщение.
В сообщении есть префикс — ID схемы. Если схемы с присланным ID нет в кеше, то необходимо её загрузить из SR.
Данные из сообщения расшифровываются с помощью схемы, полученной по ID из префикса сообщения.
Адаптация распространённого подхода в условиях Юлы
В Юле самым распространённым способом сериализации данных является JSON, и кроме него используется Protobuf для реализации GRPC API. Использование Avro внесло бы избыточную технологию, которую пришлось бы поддерживать и внедрять в весь проект. Следовательно, необходимо адаптировать описанную выше схему для самого популярного в Юле JSON или Protobuf.
Однако ни JSON, ни Protobuf не подразумевают активного использования схем данных в процессе (де)сериализации. Несмотря на то, что для JSON существует JSON-Schema — спецификация описания правил валидации данных, её задача заключается в первую очередь в валидации данных, а не в описании их структуры. Существуют проекты по генерации кода из JSON-Schema, но популярность этого решения под вопросом.
С Protobuf ситуация обратная: распространённый подход подразумевает генерацию исходного кода, предназначенного для (де)сериализации данных по конкретной Protobuf-схеме с ограниченными возможностями динамической валидации сериализованных данных по исходной схеме.
В обоих случаях невозможно воспроизвести шаг динамической (де)сериализации данных по схеме, и мы решили попробовать заменить его валидацией JSON-данных с помощью JSON-Schema.
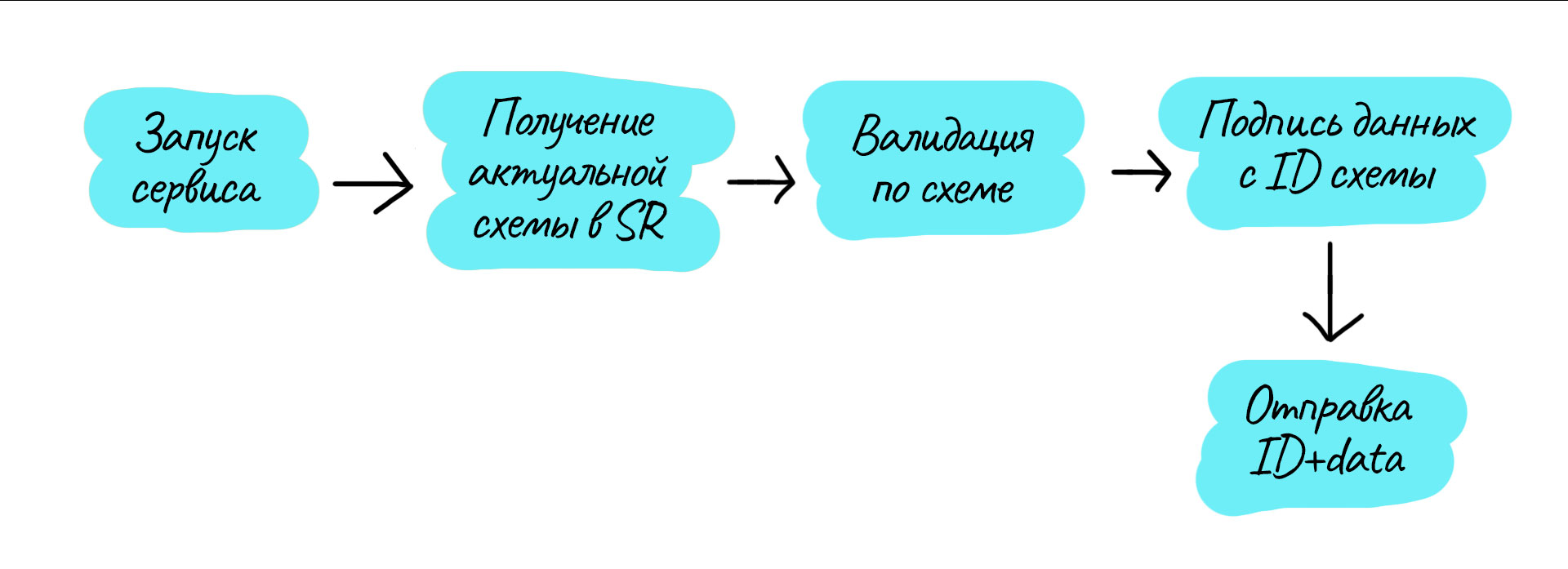
Концептуально схема продьюсера получается похожей. Схема также хранится в продьюсере и в Schema Registry.
Запуск сервиса и чтение локальной схемы.
Актуализация схемы в SR, если требуется, и получение её ID. Если схему невозможно актуализировать из-за её невалидности или несовместимости с предыдущей версией, то дальнейшая работа невозможна.
Сериализация данных к отправке.
Валидация отправляемых данных с помощью схемы.
Подпись отправляемых данных префиксом с ID схемы.
Отправка ID схемы и данных в одном сообщении.
Пункт 4 в этом алгоритме может вызвать вопрос: зачем нужно валидировать только что сериализованные отправляемые данные? Этот шаг необходим на тот случай, если по каким-то причинам код, сериализующий данные, был изменён без обновления схемы.
Схему же невозможно обновить без поддержки обратной совместимости, если таковая включена в настройках Schema Registry. Таким образом гарантируется, что в Kafka будут отправлены только валидные данные, если все разработчики сервисов будут придерживаться этого же алгоритма.
Итог:
Существует единое хранилище схем данных, отправляемых в Kafka.
Схемы проверяются, в том числе на совместимость с предыдущими версиями.
Невалидные данные не могут попасть в Kafka при условии соблюдения описанного выше алгоритма.
Вместе с тем мы получили несколько недостатков:
Проверка совместимости схемы в процессе работы может привести к неожиданным сбоям, если схема по каким-то непредвиденным причинам оказывается несовместимой.
Инициализация сервиса зависит от корректной работы API Schema Registry, что может создать излишние риски в продакшн-среде.
Эта схема работоспособна лишь в том случае, если реализована во всех сервисах, работающих с Kafka, на всех используемых языках программирования.
Определив эти недостатки, мы поняли, что простое воспроизведение распространённых шаблонов использования SR нам не подходит из-за сложности реализации, рисков сбоев и всё ещё недостаточной гарантии корректности данных в Kafka.
Своё решение на основе Schema Registry
Разрабатывая собственное решение, необходимо было ответить на несколько вопросов:
Что является источником правды для схем?
В какой момент выполняется проверка и регистрация схем?
Как удостовериться, что в Kafka будут отправлены валидные данные?
Нужно ли всё ещё подписывать данные идентификатором схемы?
Что делать, если необходимо писать данные разного формата в один топик?
Источник схем
В качестве источника правды для схем (основного хранилища) могут выступать:
Репозиторий с проектом.
Отдельный репозиторий со схемами.
Непосредственно
SR.
Мы выбрали хранение схем рядом с кодом продьюсера по нескольким причинам:
Простота редактирования файлов схем в удобном редакторе.
Лёгкость отслеживания истории изменения в
git.Персистентность хранилища.
Хранение в репозитории позволяет встроить проверку схемы как на этапе запуска, так и в
CI/CD.
Следует отметить, что хранение схем рядом с продьюсерами и Forward-валидация затрудняют разработку нескольких продьюсеров, пишущих в один топик. Такие сервисы проще всего разместить в одном репозитории с единым циклом CI/CD и обновлять всë при обновлении единой схемы.
Регистрация схем в Schema Registry
Регистрация схем может выполняться:
В процессе запуска продьюсера, как это было описано в первом прототипе. В этом случае сервис с ломающими данными может оказаться в продакшене, но не сможет запуститься.
В процессе
CI/CD. В этом случае, проверка будет выполняться перед рразвëртыванием и сломанный сервис на попадёт в продакшн.Комбинация вариантов.
Мы выбрали вариант CI/CD для избежания попадания ломающих изменений в продашкн и вследствие отсутствия необходимости выполнять дополнительные действия в продакшене при возможности их выполнения до развëртывания.
Проверка валидности отправляемых данных
Валидация данных может выполняться лишь при отправке этих данных в процессе работы сервиса. Однако валидация будет выполняться только при реализации этого процесса во всех сервисах, на всех языках программирования. Кроме того, валидацию возможно выполнять только для данных, сериализованных в JSON.
Альтернативой валидации может выступать генерация из схемы исходного кода, сериализующего данные. При использовании Protobuf в качестве способа описания схем это является достаточно простым решением, так как генерация кода стандартизирована для разных языков, а итоговый исходный код позволяет сериализовать данные не только в бинарный вид, но и в JSON.
Подпись данных идентификатором
Так как мы отказались от валидации отправляемых и принимаемых данных, то отпадает необходимость и в подписи данных идентификатором.
Отправка данных разного формата в один топик
При разработке нередки ситуации, когда нельзя строго определить, что в один топик будет записываться только один вид данных. На этот случай в Schema Registry предусмотрены политики именования схем. Их всего три, но нас интересует TopicRecordNameStrategy, которую мы используем по-умолчанию для всех создаваемых схем. Суть заключается, в том, что связь между топиком и схемой является не 1-1, а 1-N. А множественность достигается за счёт того, что в название схемы включается название записи (record), например updates-weather.
Следует, однако, заметить, что в нашем случае Schema Registry фактически не контролирует названия схем и поддержка политики наименования возложена на разработчиков.
Резюмируя: весь процесс регистрации и проверки схем умещается в процесс CI/CD, основной источник правды для схем — репозиторий; данные не валидируются, а исходный код для работы с данными генерируется из Protobuf-схем. В одном топике могут отправляться данные разных форматов, описанные разными схемами.
Ниже пример схемы, которая может использоваться в нашем проекте для описания данных, передаваемых в Kafka.

Protobuf-схема является стандартной, однако в ней есть два важных поля: topic и record. Они определяют Kafka-топик и запись, к которым относится схема. Значения этих полей используются как в CI/CD для проверки схемы, так и как конфигурация сервиса по-умолчанию при запуске. Таким образом задаётся единый источник правды о том, к какому топику относится схема и какие данные в какой топик попадут.
Для того, чтобы описанная система работала, мы также разработали консольную утилиту для использования разработчиками или в CI/CD, выполняющая основные операции при помощи SR:
проверку схемы;
регистрацию схемы;
просмотр сведений о схеме и список её версий;
просмотр видов записей (record) для топика;
удаление схемы.
Пример сценария создания топика и схемы
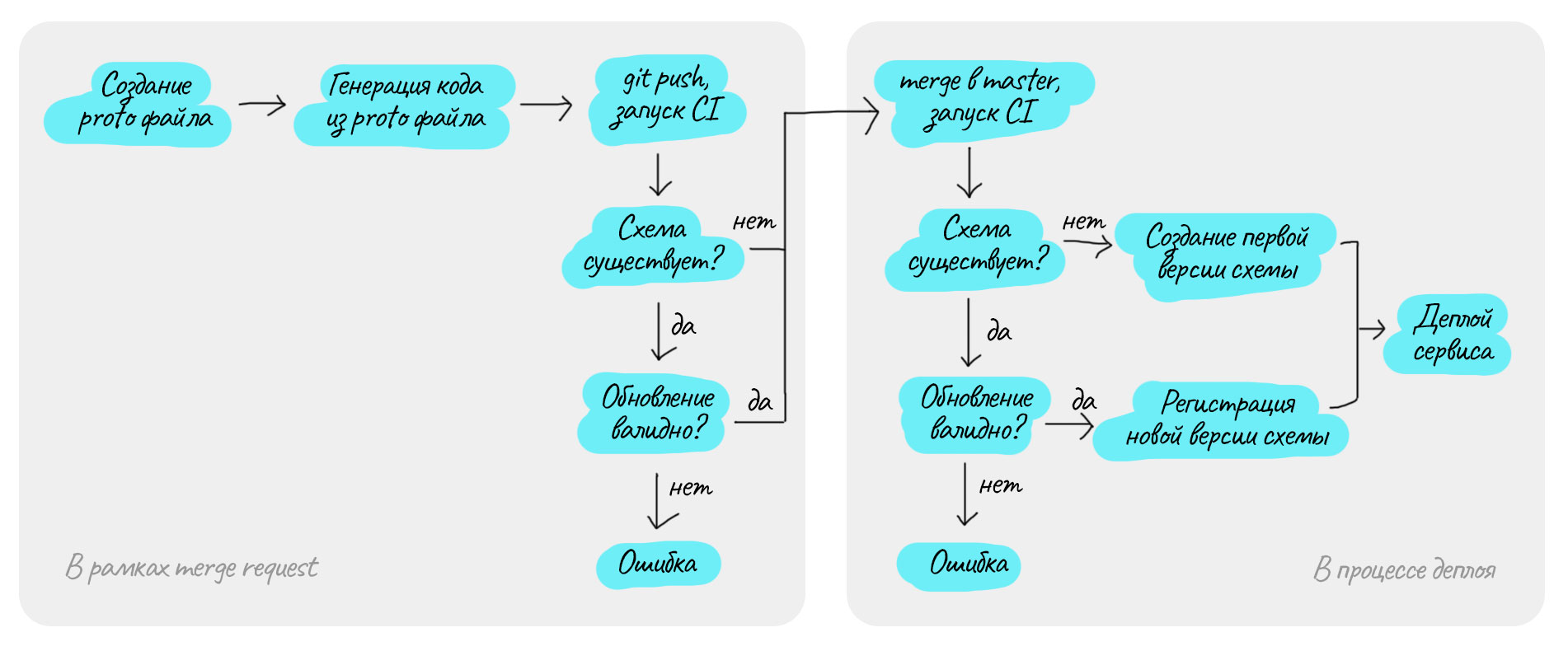
Ниже по шагам описан сценарий, как разработчик может создать новый консьюмер для нового топика. Так как мы используем FORWARD-совместимость схем, то в примере первым обновляется продьюсер, Protobuf-файлы располагаются рядом с его кодом.
Сначала необходимо описать формат сообщений в
Protobuf-файле.Из
Protobuf-файла генерируется исходный код для сериализации данных.С использованием сгенерированного кода дописывается продьюсер, код попадает в
feature-веткувgit.-
В
CIзапускается процесс, который, используяProtobuf-файл, проверяет:Если топик и схема уже существуют, то проверяется совместимость.
Если топик или схема не существуют, то ничего не происходит, схема корректна.
Пока код не в master и сервис не отправляется в продакшн, SR не регистрирует схему, а лишь проверяет её корректность.
-
Когда изменения попадают в
masterи сервис отправлятся в продакшн, в процессеCI/CDсхема снова проверяется:Если топик и схема существуют и обновление совместимо с предыдущей версией, то изменения регистрируются.
Если схема не существует, то она создаётся и становится первой версией.
Если схема существует и обновление несовместимо с предыдущей версией, то процесс прерывается.
В случае успеха на предыдущем шаге сервис оказывается в продакшене.
Пример сценария отката
В случае отката, в первую очередь необходимо удалить последнюю версию схемы, чтобы восстановить консистентность системы. Например, чтобы существующие и разрабатываемые консьюмеры не могли завязаться на обязательные поля, которые откаченный продьюсер, возможно, уже никогда не отправит. Затем будет выполнен обычный откат сервиса до предыдущей версии.
Результат
В итоге, попробовав воспроизвести часто описываемый сценарий использования Schema Registry с учётом технологического стека Юлы, мы поняли, что практическая польза от этого решения не перевешивает затраты на внедрение. Затем мы разработали свою схему использования, вынужденно отказавшись от части возможностей, которые предлагает SR.
Использование Confluent Schema Registry добавляет нам единый надёжный источник информации о том, какие схемы данных есть у топиков и как эти схемы менялись. Вместе с использованием разработанной CLI-утилиты схемы в CI/CD процессе проверяются, в том числе на совместимость.
Генерация исходного кода даёт достаточную для нас гарантию того, что в Kafka будут отправлены именно те данные, которые задекларированы для топика.
barloc
Только когда увидел про 2 языка и пхп понял, почему так сложно.
Ведь куда проще сделать одну на компанию библиотеку для работы с кафкой, которая предоставляет наружу события - а внутри делает маршалинг, отправку в кафку, прием из и анмаршалинг.
В итоге одно место, где хранится схема - как со стороны писателя, так и со стороны читателя. С гитом, ревью всех сторон и всем таким.
tarielx Автор
Опционально может быть ещё и Python в командах, которые работают с данными. И сервисы не всегда однородные даже на одном языке, поэтому да, по пути единой библиотеки могло бы быть даже сложнее идти.