

Инциденты — это непредвиденные события, которые нарушают нормальную работу. Они неизбежны в сложных системах, которые должны работать непрерывно, поэтому так важно подготовиться к ним и научить людей своевременно и организованно на них реагировать. Конечно, каждый инцидент уникален, но у нас есть единая процедура обнаружения, эскалации, управления и разрешения.
В Airbnb используется сервис-ориентированная инфраструктура, состоящая из множества взаимосвязанных сервисов, которыми управляют небольшие команды. Очень важно вовремя понять, в каком сервисе сбой и кому отправлять оповещения. Мы заметили, что наши команды тратят много времени на переключение между приложениями (Slack, Pagerduty и Jira), чтобы создать инцидент, оповестить нужные команды и предоставить контекст. Эта статья посвящена тому, как Airbnb автоматизировала управление инцидентами в своём сложном и быстро развивающемся скоплении микросервисов.
Бот для управления инцидентами в Slack
Мы решили централизовать управление инцидентами в Slack. В Airbnb все активно пользуются Slack, так что можно легко собрать нужных людей и ресурсы в канале инцидента. Заодно канал используется как хроника событий для написания постмортема.
У нас были следующие требования:
Запустить решение в сервис-ориентированной инфраструктуре Airnbnb и обеспечить полную поддержку от нашей команды.
Стандартизировать коммуникации по инциденту в Jira, Slack и PagerDuty.
Централизовать управление инцидентами в Slack.
Создать единую воронку приёма инцидентов с чётко определёнными шагами.
Автоматизировать задачи, выполняемые после инцидента, например назначение встреч и архивирование каналов.
Собирать хронику инцидента и метрики.
Мы решили создать своё приложение, которое в дальнейшем можно будет легко кастомизировать и развивать. В качестве языка мы выбрали Go, потому что нам нравится сообщество и хорошо задокументированная библиотека slack.
Наконец, вместо команд с косой чертой мы пишем команды для бота в чате, чтобы их видели все участники.
Бот управления инцидентами поддерживает четыре главных команды:
new incident <общая информация>: создаётся тикет Jira, менеджеры по инцидентам получают оповещение.
new channel <тикет>: создаётся канал Slack для открытого тикета по инциденту.
page <сервис|пользователь>: отправляются оповещения дежурным для сервиса в PagerDuty или напрямую пользователям.
get timeline: компилируется лаконичная хроника важных событий из чата для постмортема.
Жизненный цикл реагирования на инциденты
Мы выделили четыре этапа: обнаружение, оповещение, эскалация и разрешение. Команды для бота автоматизируют задачи, которые в противном случае потребовали бы координации.

Обнаружение
Большинство инцидентов у нас обнаруживаются инструментами мониторинга и оповещений, хотя иногда мы узнаем о проблемах от коллег или клиентов. Неважно, как мы обнаружили инцидент, главное, что у нас есть единая воронка приёма. Для этого мы используем команду new incident.
New incident <общая информация>
Эта команда создаёт пустой тикет JIRA с параметрами по умолчанию и спрашивает пользователя, нужно ли оповестить менеджера по инцидентам.
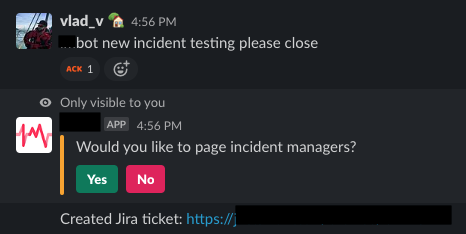
Пользователь может согласиться или отказаться, а дальше в любом случае появляется всплывающее окно, где нужно указать дополнительную информацию.
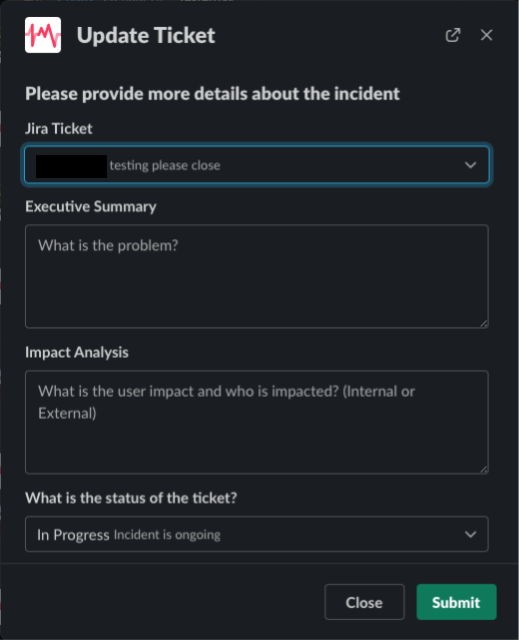
Благодаря такому подходу мы эскалируем инциденты без задержек, при этом команда реагирования всё равно может предоставлять менеджерам по инцидентам ценную информацию. Чтобы не тратить время, тут можно ничего не указывать. Эти поля можно заполнить позже.
Оповещения
Мы создаём каналы коммуникаций и предоставляем команде реагирования как можно больше контекста.
New channel [тикет Jira]
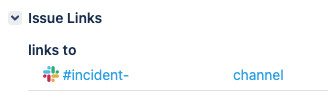
Эта команда принимает тикет Jira в виде URL или ключа. Если ничего не указать, отображается пять последних открытых тикетов на выбор. Затем создаётся канал с использованием ключа тикета Jira, в заголовке указывается общая информация и в канал приглашаются все менеджеры по инцидентам.

Чтобы все сразу понимали контекст, в теме канала указана ссылка на тикет Jira и описание тикета. В тикете Jira также указывается ссылка на канал Slack.
Эскалация
Вы, наверное, слышали про знаменитую уязвимость Log4j, которую называют самой критической уязвимостью десятилетия. В течение 72 часов после раскрытия уязвимости поступили сообщения о 840 000 атак по всему миру, и в следующие выходные происходило по 100 глобальных атак в минуту.
В Airbnb сотни небольших команд управляют тысячами микросервисов, так что для нас это стало настоящим испытанием. Нужно было найти все уязвимые сервисы и быстро связаться с их владельцами, чтобы они занялись проблемой. И в этой ситуации бот в Slack нас очень выручил, позволив менеджерам по инцидентам быстро оповестить владельцев сервисов, а затем скоординировать развёртывание исправлений. Всего за несколько минут мы через бот связались с 300 командами, чтобы помочь им оценить последствия и развернуть патчи. Мы потратили бы на четыре часа больше, если бы рассылали оповещения вручную, и всё это время наша система пребывала бы в уязвимом состоянии.
Page <шорткат|сервис|пользователь slack>
В команде page можно указать шорткат или имя сервиса, или пользователя Slack.
Можно ввести page list, чтобы просмотреть список шорткатов.
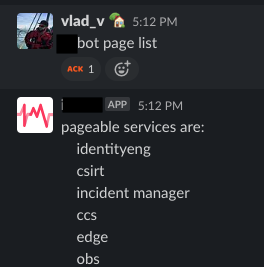
Каждый шорткат соответствует идентификатору сервиса в PagerDuty, который будет использоваться при создании инцидента в PagerDuty. Шорткаты можно настраивать в файле YAML.
Если ввести имя сервиса, которое не соответствует шорткату, отображаются результаты поиска в каталоге сервисов PagerDuty.
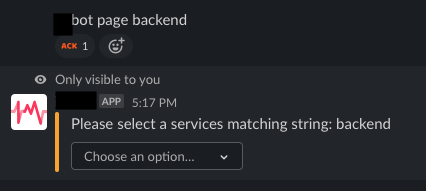
Когда пользователь выбирает нужный сервис и подтверждает выбор, для сервиса создаётся новый инцидент PagerDuty.
Можно напрямую рассылать оповещения пользователям в Slack, если нужно привлечь кого-то, кроме дежурных.
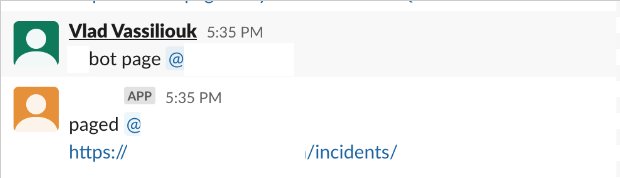
По команде page бот создаёт новый инцидент в PagerDuty с тикетом Jira, общей информацией и каналом Slack для контекста. После отправки оповещений дежурным бот объявляет, кого оповестил, и приглашает их в канал.
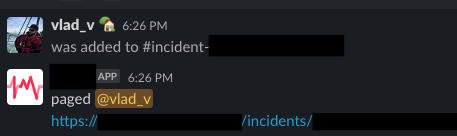
Разрешение
Когда команда реагирования подтверждает, что причина известна и пользователи не страдают, инцидент считается разрешённым и начинается следующий этап. Хорошая хроника инцидента помогает проанализировать случившееся и написать постмортем.
Get timeline
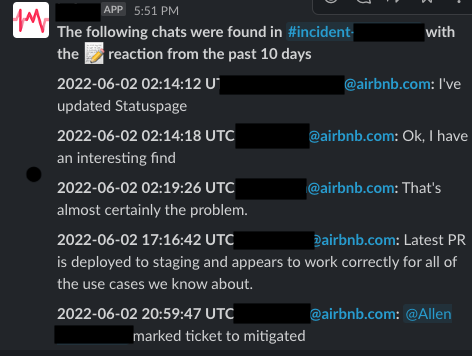
Эта команда ищет в канале инцидента все сообщения с определённым эмодзи и отправляет скомпилированную хронику пользователю.
Например, мы помечаем важные события в чате значком ????. Пока инцидент продолжается, любой участник канала может добавить этот эмодзи. Команда get timeline собирает все эти события в хронику, которую можно легко копировать и использовать для составления отчёта об инциденте.

Анализ инцидента
В Airbnb мы каждую неделю собираемся для разбора полётов и анализируем недавние серьёзные инциденты, просматриваем отчёты о них и следим за принятием мер по исправлению ситуации. Когда в тикете Jira указывается дата такой встречи, бот уведомляет владельца тикета.
Контроль последующих действий
Часто в процессе написания постмортема без поиска виноватых мы продумываем меры по предотвращению и назначаем ответственных за их выполнение. Чтобы ускорить разрешение, мы устанавливаем строгие сроки. За пару дней до дедлайна бот отправляет в Slack предупреждение, а когда срок пройдёт, отправляет ещё одно.
Архивирование каналов с инцидентами
Чтобы рабочее пространство в Slack не захламлялось, бот автоматически архивирует каналы с инцидентами через десять дней после закрытия тикета Jira.
Результаты
Бот уже сэкономил менеджерам по инцидентам и командам реагирования много часов благодаря автоматизации и централизации управления инцидентами в Slack. Мы посчитали, сколько времени уходит на выполнение каждой задачи вручную, и получилось, что с ботом мы уже сэкономили 44 часа за шесть месяцев 2022 года.
Что дальше?
Чтобы ещё эффективнее управлять инцидентами в Slack, мы планируем улучшать интеграцию с PagerDuty.
Сейчас команда page каждый раз создаёт новый инцидент PagerDuty. Мы планируем объединить все команды page в одном инциденте PagerDuty, чтобы использовать метрики инцидентов в PagerDuty и давать больше контекста команде реагирования.
Наконец, когда сервис PagerDuty получает оповещение от бота, мы не видим статус инцидента PagerDuty в Slack. Оповещение принято? Дежурный отреагировал? Проблема эскалирована? Кому? Мы собираемся автоматизировать мониторинг инцидента в PagerDuty и выводить его текущий статус в канал инцидента. Заодно в хронику будут записываться действия, выполненные в инциденте PagerDuty после оповещения.
Еще больше об управлении инцидентами
6 декабря в Слёрм стартует обновленный курс SRE: datd-driven подход к управлению надежностью систем. На эти три недели вы полностью погрузитесь в среду SRE, научитесь управлять инцидентами, изучите ключевые подходы и примените их на практике.
На время обучения вы станете SRE для сервиса покупки билетов в кинотеатр. Решая предложенные кейсы, вы получите представление, чем занимается SRE в реальности, и научитесь правильно собирать нужные метрики для мониторинга.
В том числе вы:
узнаете, как снизить ущерб от отказов в будущем;
внедрите правки прямо в прод;
узнаете, как решать конкретные проблемы, связанные с надёжностью сервиса;
научитесь быстро поднимать продакшн силами команды.
Формат предполагает разбор интересных кейсов и обмен опытом между участниками команды и спикерами. Помимо того, что учиться будет интересно, благодаря новым знаниям и практики вы сможете:
снизить процент отказов своего сервиса;
повысить скорость реагирования на отказы;
снизить риски при выкате новых фич;
увеличить скорость разработки.
Начните учиться бесплатно
Посмотрите бесплатный демо-курс о внедрении SRE в компаниях и метриках, которые используют SRE-инженеры для мониторинга надежности системы.
numb
Есть у Slack одна проблема - очень плохо работаю пуши на мобильные устройства.
Я могу прочитать сообщение, а пуш с этим сообщением прийдет спустя час(