
Девайсы повсюду. Смартфоны, холодильники, дверные звонки, часы, медицинские датчики, системы безопасности и фитнес-трекеры — все это лишь некоторые из них, которые в стали обычным явлением. Они постоянно записывают потенциально высокочастотную информацию и образуют сеть, известную как «Интернет вещей», или IoT, представляя обширные источники данных.
Хотя ресурсов по этой теме достаточно, немногие приводят примеры с реальными данными, доступными любому желающему. Переходя от статьи к статье, чтобы узнать о системах, управляемых событиями, и потоковых технологиях, таких как Apache Kafka, Harrison Hoffman наткнулся на приложение для смартфонов Sensor Logger, которое позволяет пользователям передавать данные с датчиков движения на свои телефоны. Такой вариант показался идеальным способом обучения, поэтому родился проект «smartphone_sensor_stream». Этот проект использует FastAPI, Kafka, QuestDB и Docker для визуализации данных датчиков в реальном времени на информационной панели.
В этой статье мы рассмотрим все основные компоненты этого проекта на продвинутом уровне. Все необходимое для локального запуска проекта доступно на GitHub, а краткая демонстрация доступна на YouTube.
Архитектура проекта
Давайте начнем с рассмотрения архитектуры этого проекта. То есть с того, как именно данные будут поступать со смартфонов на панель мониторинга:
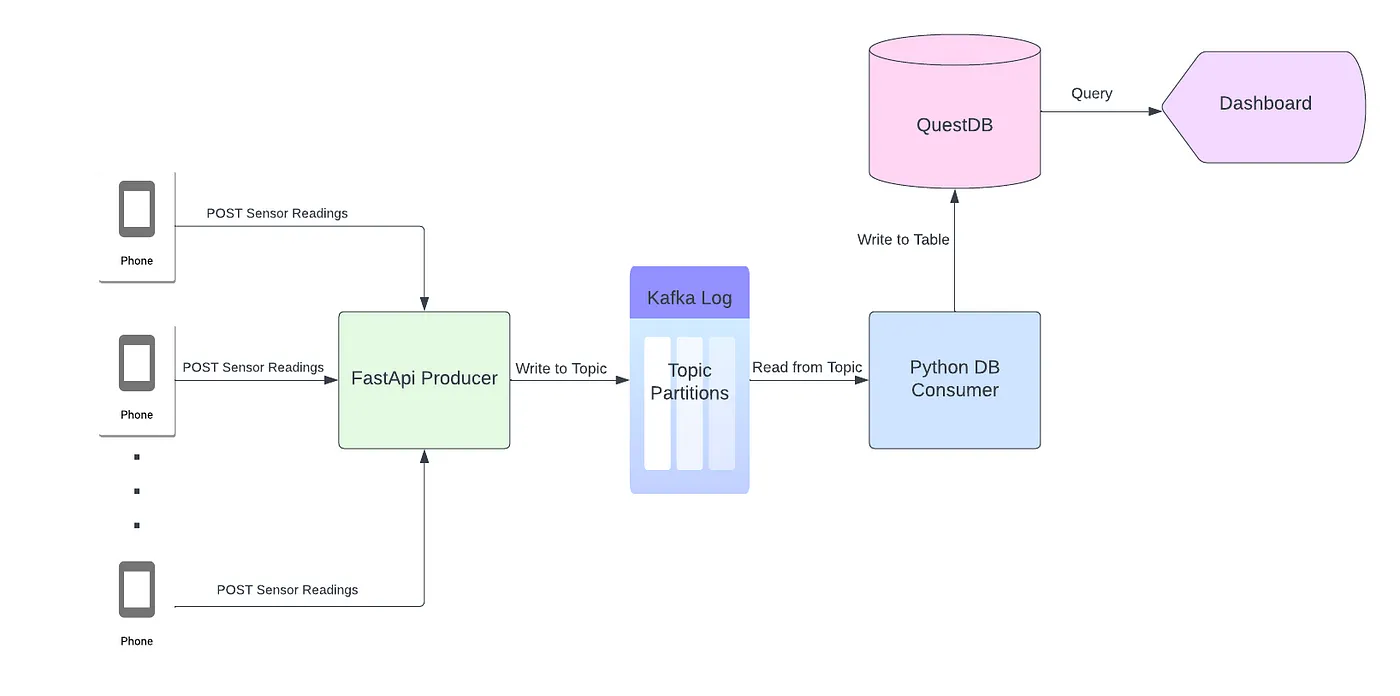
Каждый смартфон отправляет показания датчиков акселерометра, гироскопа и магнитометра через POST-запрос в приложение FastAPI. Производитель FastAPI асинхронно записывает показания датчика в раздел Kafka в виде JSON, данные из тела запроса. Каждый объект JSON обрабатывается процессом python, консумером, а потом сохраняется в таблице Quest DB. Как только данные попадают в базу данных, они становятся доступными для любой зависимой службы или приложения. В первой части этого проекта мы будем выводить показания датчиков на панель мониторинга, используя события, отправляемые сервером (SSE).
Структура каталогов и компоновка Docker Compose
Этот проект представляет собой набор небольших сервисов, которые взаимодействуют друг с другом для получения данных со смартфонов на информационную панель. Вот структура каталогов:
|-producer
| |-app
| | |-core
| | | |-config.py
| | |-__init__.py
| | |-schemas
| | | |-sensors.py
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.sh
|-db_consumer
| |-app
| | |-core
| | | |-config.py
| | |-models
| | | |-sensors.py
| | |-db
| | | |-ingress.py
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.sh
|-ui_server
| |-app
| | |-core
| | | |-config.py
| | |-models
| | | |-sensors.py
| | |-static
| | | |-js
| | | | |-main.js
| | |-db
| | | |-data_api.py
| | |-templates
| | | |-index.html
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.sh
|-README.md
|-.gitignore
|-.env
|-docker-compose.ymlМы напишем три сервиса: продюсер, консумер и пользовательский интерфейс. Каждая служба упакована с помощью Dockerfile и организована при помощи docker-compose. Docker-compose позволяет нам запускать сервисы, которые мы пишем, с внешними сервисами, Kafka, Zookeeper и QuestDB, в виде отдельных контейнеров, подключенных через внутреннюю сеть. Все, что нам нужно для организации служб в этом проекте, находится в файле docker-compose:
version: '3.8'
services:
zookeeper:
image: bitnami/zookeeper:latest
ports:
- 2181:2181
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
ports:
- 9092:9092
- 9093:9093
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
questdb:
image: questdb/questdb
container_name: questdb
restart: always
expose:
- 9000
- 9009
- 9003
ports:
- 8812:8812
volumes:
- ./questdb:/root/.questdb
environment:
- QDB_LOG_W_STDOUT_LEVEL=ERROR
- QDB_LOG_W_FILE_LEVEL=ERROR
- QDB_LOG_W_HTTP_MIN_LEVEL=ERROR
- QDB_SHARED_WORKER_COUNT=2
- QDB_PG_USER=${DB_USER}
- QDB_PG_PASSWORD=${DB_PASSWORD}
- QDB_TELEMETRY_ENABLED=false
- QDB_CAIRO_SQL_COPY_ROOT=./
producer:
build:
context: ./producer
dockerfile: Dockerfile
command: uvicorn main:app --workers 1 --host 0.0.0.0 --port 8000
ports:
- 8000:8000
env_file:
- .env
depends_on:
- kafka
- zookeeper
db_consumer:
build:
context: ./db_consumer
dockerfile: Dockerfile
command: python main.py
env_file:
- .env
depends_on:
- kafka
- zookeeper
ui_server:
build:
context: ./ui_server
dockerfile: Dockerfile
command: uvicorn main:app --workers 1 --host 0.0.0.0 --port 5000
ports:
- 5000:5000
env_file:
- .env
depends_on:
- db_consumer
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "18080:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
depends_on:
- kafka
- zookeeper
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: localОбратите внимание на четыре сервиса, которые мы не пишем сами (к счастью): Zookeeper, Kafka, QuestDB и Kafka-UI. Эти сервисы работают совместно с производителем, потребителем и пользовательским интерфейсом для создания проекта. Мы рассмотрим каждый сервис в отдельности, но сначала нам нужно разобраться с источником данных.
Регистратор датчиков
Sensor Logger — это приложение для iOS и Android, которое позволяет пользователям регистрировать показания датчиков, связанных с движением, со своих смартфонов. Пользователи могут просматривать показания датчиков в режиме реального времени, экспортировать данные в виде файлов и отправлять оперативные данные на сервер по протоколу HTTP. Этот проект использует функциональность HTTP для извлечения показаний датчиков. Чтобы настроить регистратор, для начала убедитесь, что выбраны все следующие датчики:

Мы будем получать показания акселерометра, гироскопа и магнитометра телефона. Далее нам нужно настроить параметры регистратора датчиков таким образом, чтобы он знал, куда именно отправлять данные:

Наиболее важным компонентом является обеспечение правильности “Push URL” — это конечная точка производителя FastAPI, которая принимает необработанные показания датчиков с помощью POST-запросов. Мы будем использовать наш компьютер в качестве сервера, поэтому нам нужно определить соответствующий IP-адрес. На Mac это находится в разделе Системные настройки -> Сеть.

Обратите внимание, что IP-адрес компьютера обычно уникален для сети WI-FI, что означает, что новый IP-адрес выделяется каждый раз, когда компьютер подключается к новой сети. Поэтому крайне важно, чтобы смартфон и главный компьютер находились в одной сети. Производитель FastAPI принимает показания датчиков на:
http://%7Byour_ip_address%7D:8000/phone-producer
Вставьте приведенный выше URL-адрес в поле «Push URL», и регистратор датчиков должен быть готов к работе!
Кафка и ZooKeeper
В этом разделе не будем вдаваться в подробности о Kafka, поскольку на платформе доступно много ресурсов. Однако можно сказать, что Kafka — это высокопроизводительный фреймворк для хранения и чтения потоковых данных. Фундаментальная структура данных Кафки — журнал. Приложения, которые записывают сообщения в журнал, называются продюсерами. В отличие от очереди, сообщения в журнале сохраняются даже после прочтения — это позволяет нескольким приложениям, известным как консумеры, читать одновременно с разных позиций.
Для простоты в этом проекте есть только один продюсер — приложение FastAPI, которое записывает необработанные показания датчиков в Kafka, и один консумер, процесс на python, который считывает сообщения из Kafka и форматирует их в базе данных. Zookeeper — это сервис, который помогает управлять различными компонентами Kafka.
Для локального запуска Kafka и Zookeeper необходимы только два образа docker:
zookeeper:
image: bitnami/zookeeper:latest
ports:
- 2181:2181
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
ports:
- 9092:9092
- 9093:9093
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "18080:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
depends_on:
- kafka
- zookeeperМы будем использовать дистрибутив Kafka и Zookeeper от Bitmani. Kafka-UIImage позволяет пользователям взаимодействовать с кластерами Kafka через веб-приложение, но не требуется для этого проекта. Сохраните приведенный выше файл docker-compose как docker-compose.yml, запустите docker-compose, и графический интерфейс, подобный следующему, должен быть доступен по адресу http://localhost:18080/.

Информация о брокерах, темах и консумерах будет добавляться на эту панель мониторинга по мере добавления компонентов в систему.
Продюсер
Пока что у нас есть регистратор датчиков, настроенный для отправки необработанных показаний датчиков на сервер, и экземпляр Kafka готов к приему этих показаний. Следующий шаг — создать мост между исходными данными и Kafka-продюсером. Продюсером в этом проекте является быстрое API-приложение, которое принимает данные, отправляемые со смартфонов, и записывает их в журнал Kafka. Вот макет продюсера:
|-producer
| |-app
| | |-core
| | | |-config.py
| | |-__init__.py
| | |-schemas
| | | |-sensors.py
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.shМы не будем просматривать каждый файл в каталоге продюсера, поскольку все доступно на GitHub. Вместо этого давайте взглянем на main.py управляющий скрипт API производителя:
import json
from fastapi import FastAPI
import asyncio
from aiokafka import AIOKafkaProducer
from schemas.sensors import SensorReading, SensorResponse
from core.config import app_config
from loguru import logger
app = FastAPI(title=app_config.PROJECT_NAME)
loop = asyncio.get_event_loop()
producer = AIOKafkaProducer(
loop=loop,
client_id=app_config.PROJECT_NAME,
bootstrap_servers=app_config.KAFKA_URL
)
@app.on_event("startup")
async def startup_event():
await producer.start()
@app.on_event("shutdown")
async def shutdown_event():
await producer.stop()
@app.post("/phone-producer/")
async def kafka_produce(data: SensorReading):
"""
Produce a message containing readings from a smartphone sensor.
Parameters
----------
data : SensorReading
The request body containing sensor readings and metadata.
Returns
-------
response : SensorResponse
The response body corresponding to the processed sensor readings
from the request.
"""
await producer.send(app_config.TOPIC_NAME, json.dumps(data.dict()).encode("ascii"))
response = SensorResponse(
messageId=data.messageId,
sessionId=data.sessionId,
deviceId=data.deviceId
)
logger.info(response)
return responseСтрока 9 создает экземпляр объекта Fast API. Строки 11-17 создают экземпляр объекта Kafka-продюсер с помощью Aiokafka. Aiokafka позволяет нам записывать сообщения в Kafka асинхронно. Это значит, что нам не нужно ждать, пока Kafka получит и обработает сообщение, в строке 45, прежде чем мы перейдем к следующей строке кода. Вместо этого Aiokafka отправляет текущее сообщение в Kafka и почти мгновенно готова выдать другое сообщение. Строки 27-55 определяют маршрут, по которому будут приниматься необработанные показания датчиков. Чтобы лучше понять это, давайте взглянем на формат тела запроса, который ожидает этот маршрут — аргумент data):
{"messageId": 20,
"sessionId": "4bf3b3b9-a241-4aaa-b1d3-c05100df9976",
"deviceId": "86a5b0e3-6e06-40e2-b226-5a72bd39b65b",
"payload": [{"name": "accelerometeruncalibrated",
"time": "1671406719721160400",
"values": {"z": -0.9372100830078125,
"y": -0.3241424560546875,
"x": 0.0323486328125}},
{"name": "magnetometeruncalibrated",
"time": "1671406719726579500",
"values": {"z": -5061.64599609375,
"y": 591.083251953125,
"x": 3500.541015625}},
{"name": "gyroscopeuncalibrated",
"time": "1671406719726173400",
"values": {"z": -0.004710599314421415,
"y": -0.013125921599566936,
"x": 0.009486978873610497}},
...
]}Каждое тело запроса представляет собой объект JSON с записями «MessageId», «SessionID», «DeviceID» и «payload». Смартфоны однозначно идентифицируются по их «идентификатору устройства». Каждый раз, когда телефон начинает новый поток, для него создается новый «sessionId». Запись «MessageId» указывает порядок расположения сообщений в последовательности из текущего сеанса. Запись «payload» представляет собой массив объектов JSON, которые содержат показания для каждого датчика, настроенного в Sensor Logger. Каждая запись «payload» содержит имя датчика, время записи показаний по времени unix и само считывание. Мы работаем исключительно с трехосными датчиками, поэтому каждый датчик должен иметь показания «x», «y» и «z», соответствующие трем пространственным измерениям.
Маршрут FastAPI записывает необработанное тело запроса непосредственно в раздел Kafka, в строке 45, а метаданные регистрируются и возвращаются в строках 47-55. Этот маршрут доступен по адресу http://{your_ip_address}:8000/phone-producer, как описано в разделе «Регистратор датчиков» (Sensor Logger) . Все запросы проверяются объектом Pydantic SensorReading. То есть, любой запрос, который не соответствует формату регистратора датчиков, не будет обработан маршрутом:
from pydantic import BaseModel, validator
from datetime import datetime
from typing import List, Dict, Union
class SensorReading(BaseModel):
"""
Base model class for incoming requests from smartphone sensors
Attributes
----------
messageId : int
The identifier of a message in the current session
sessionId : int
The identifier of a session
deviceId : int
The identifier of the device sending the data
payload : List[Dict[str:Union[str, int, Dict]]]
The payload of the request containing sensor readings
and metadata about the readings
"""
messageId: int
sessionId: str
deviceId: str
payload: List[Dict[str, Union[str, int, Dict]]]
class SensorResponse(BaseModel):
"""
Base model class for the response of the sensor request endpoint
Attributes
----------
messageId : int
The identifier of a message in the current session
sessionId : int
The identifier of a session
deviceId : int
The identifier of the device sending the data
timestamp : str
The timestamp when a sensor request was processed
"""
messageId: str
sessionId: str
deviceId: str
timestamp: str = ""
@validator("timestamp", pre=True, always=True)
def set_datetime_utcnow(cls, v):
return str(datetime.utcnow())Конфигурация для производителя обрабатывается с помощью переменных окружения, которые считываются объектом Pedantic Base Settings:
from pydantic import BaseSettings, validator
# Load environment variables into a pydantic BaseSetting object
class AppConfig(BaseSettings):
PROJECT_NAME : str
KAFKA_HOST : str
KAFKA_PORT : str
TOPIC_NAME : str
KAFKA_URL : str = ""
class Config:
case_sensitive = True
@validator("KAFKA_URL", pre=True, always=True)
def set_kafka_url(cls, v, values, **kwargs):
return values['KAFKA_HOST'] + ":" + values['KAFKA_PORT']
app_config = AppConfig()Переменные окружения хранятся в файле .env:
# Kafka config
PROJECT_NAME=phone_stream_producer
TOPIC_NAME=raw-phone-stream
KAFKA_HOST=kafka
KAFKA_PORT=9092и передаются проидюсеру в файле docker-compose, строка 9 ниже:
producer:
build:
context: ./producer
dockerfile: Dockerfile
command: uvicorn main:app --workers 1 --host 0.0.0.0 --port 8000
ports:
- 8000:8000
env_file:
- .env
depends_on:
- kafka
- zookeeperОбратите внимание, что значение host в команде запуска равно 0.0.0.0. Это позволяет получить доступ к продюсеру по его IP-адресу с любого устройства в локальной сети.
Консумер
Теперь у нас есть инфраструктура для потоковой передачи данных датчиков со смартфонов в Fast API producer и Kafka. Следующим шагом является создание процесса — консумера, который считывает данные из Kafka и что-то делает с данными. Консумеры могут нести ответственность за все, что связано с чтением данных, хранящихся в журнале, и манипулированием ими. Для этого проекта они будут использоваться для преобразования необработанных показаний датчиков и сохранения их в базе данных временных рядов, известной как QuestDB. Вот структура каталогов для консумера:
|-db_consumer
| |-app
| | |-core
| | | |-config.py
| | |-models
| | | |-sensors.py
| | |-db
| | | |-ingress.py
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.shПеред созданием консумера нам нужно создать экземпляр Quest DB. Quest DB — это высокопроизводительная база данных временных рядов с открытым исходным кодом и API, совместимым с Postgres. Это означает, что мы можем запрашивать таблицы Quest DB так, как если бы они были таблицами Postgres, ориентированными на строки. При этом мы пользуемся преимуществами таблиц, ориентированных на столбцы. Мы можем запустить QuestDB с помощью docker:
questdb:
image: questdb/questdb
container_name: questdb
restart: always
expose:
- 9000
- 9009
- 9003
ports:
- 8812:8812
volumes:
- ./questdb:/root/.questdb
environment:
- QDB_LOG_W_STDOUT_LEVEL=ERROR
- QDB_LOG_W_FILE_LEVEL=ERROR
- QDB_LOG_W_HTTP_MIN_LEVEL=ERROR
- QDB_SHARED_WORKER_COUNT=2
- QDB_PG_USER=${DB_USER}
- QDB_PG_PASSWORD=${DB_PASSWORD}
- QDB_TELEMETRY_ENABLED=false
- QDB_CAIRO_SQL_COPY_ROOT=./Обратите внимание в строках 5-8, что мы открываем порты 9000, 9009 и 9003. Эти порты, в частности порт 9000, используются для записи данных в таблицы QuestDB. Включив эти порты в раздел expose, а не в раздел ports, мы гарантируем, что только контейнеры, работающие в одной сети Docker, могут записывать данные. Порт 8812 доступен за пределами сети Docker и используется для запроса данных. Переменные окружения QDB_PG_USER и QDB_PG_PASSWORD, наряду с другими переменными, связанными с QuestDB, задаются в файле .env:
# Questdb config
DB_USER =admin
DB_PASSWORD =quest
DB_HOST =questdb
DB_PORT = 8812
DB_IMP_PORT = 9000
DB_NAME =qdb
DB_TRIAXIAL_OFFLOAD_TABLE_NAME =device_ off loadУправляющий код потребителя находится в main.py :
import asyncio
import json
from aiokafka import AIOKafkaConsumer
from core.config import app_config
from db.ingress import (create_connection,
create_triaxial_table,
write_sensor_payloads)
async def consume_messages() -> None:
"""
Coroutine to consume smart phone sensor messages from a kafka topic
"""
# Create a QuestDB connection
connection = create_connection(host=app_config.DB_HOST,
port=app_config.DB_PORT,
user_name=app_config.DB_USER,
password=app_config.DB_PASSWORD,
database=app_config.DB_NAME)
# Instantiate the event loop and consumer
loop = asyncio.get_event_loop()
consumer = AIOKafkaConsumer(
app_config.TOPIC_NAME,
loop=loop,
client_id='all',
bootstrap_servers=app_config.KAFKA_URL,
enable_auto_commit=False,
)
await consumer.start()
try:
async for msg in consumer:
print(msg.value)
print('################')
# Format each message in the log and write to QuestDB
write_sensor_payloads(json.loads(msg.value), app_config.DB_IMP_URL, app_config.DB_TRIAXIAL_OFFLOAD_TABLE_NAME)
finally:
await consumer.stop()
connection.close()
async def main():
await consume_messages()
if __name__ == "__main__":
# Create the table to store triaxial sensor data if it doesn't exist
connection = create_connection(host=app_config.DB_HOST,
port=app_config.DB_PORT,
user_name=app_config.DB_USER,
password=app_config.DB_PASSWORD,
database=app_config.DB_NAME)
create_triaxial_table(app_config.DB_TRIAXIAL_OFFLOAD_TABLE_NAME, connection)
asyncio.run(main())Здесь многое нужно распаковать, но основная логика изложена в строках 35-39. Консумер асинхронно перебирает сообщения в указанной теме Kafka. Этот цикл будет непрерывно обрабатывать сообщения до тех пор, пока тема обновляется. Сообщения форматируются и записываются в таблицу Quest DB с помощью следующей функции:
def write_triaxial_sensor_data(data:dict, server_url:str, table_name:str):
"""
Write triaxial phone sensor data to database tables
Parameters
----------
data : dict
The raw request data sent by the phone
server_url : str
The URL where sensor data will be written to
table_name : str
The name of the table to write to
"""
session_id = data['sessionId']
device_id = data['deviceId']
# Create an empty dict to store structured sensor from the payload
structured_payload = {'device_id':[],
'session_id':[],
'device_timestamp':[],
'recorded_timestamp':[],
'sensor_name':[],
'x':[],
'y':[],
'z':[]
}
for d in data['payload']:
# Triaxial sensors
if d.get("name") in DEVICE_TO_DB_SENSOR_NAME.keys():
structured_payload['device_id'].append(device_id)
structured_payload['session_id'].append(session_id)
structured_payload['device_timestamp'].append(str(datetime.fromtimestamp(int(d["time"]) / 1000000000)))
structured_payload['recorded_timestamp'].append(str(datetime.utcnow()))
structured_payload['sensor_name'].append(DEVICE_TO_DB_SENSOR_NAME.get(d.get("name")))
structured_payload['x'].append(d["values"]["x"])
structured_payload['y'].append(d["values"]["y"])
structured_payload['z'].append(d["values"]["z"])
output = StringIO()
pd.DataFrame(structured_payload).to_csv(output, sep=',', header=True, index=False)
output.seek(0)
contents = output.getvalue()
csv = {'data': (table_name, contents)}
response = requests.post(server_url, files=csv)Вся полезная нагрузка форматируется и сохраняется в виде CSV-файла в памяти с помощью StringIO. Оттуда CSV отправляется через POST-запрос на порт записи Quest DB. Это облегчает быструю запись всей полезной нагрузки в QuestDB с использованием одного подключения и запроса.
Таблица, в которой хранятся данные датчиков, предназначена для обеспечения баланса между быстрой записью и быстрым чтением. Вот запрос для создания таблицы в QuestDB:
СОЗДАЙТЕ ТАБЛИЦУ , ЕСЛИ НЕ СУЩЕСТВУЕТ device_offload (
device_id TEXT,
session_id TEXT,
device_timestamp TEXT,
record_timestamp TEXT,
sensor_name TEXT,
x REAL ,
y REAL ,
z REAL
)
Поля device_id и session_id берутся непосредственно из первых двух записей необработанной полезной нагрузки, как обсуждалось ранее. device_timestamp — это время, когда на устройстве была собрана отдельная выборка данных датчика, в то время как recorded_timestamp — это время, когда выборка попала в базу данных. Благодаря этому мы можем измерить, сколько времени требуется, чтобы выборка данных попала с устройства в базу данных.
Поскольку мы работаем только с трехосными датчиками, мы можем сохранить их значения в полях x, y и z и указать, какому датчику принадлежит каждый образец, в поле sensor_name. Эта схема позволяет нам записывать данные с каждого датчика в полезной нагрузке в одну и ту же таблицу за одну запись, в отличие от записи в несколько таблиц, требующих многократной записи.
Важно отметить, что в реальных условиях эта таблица QuestDB, скорее всего, не будет конечным местом хранения данных. Вместо этого таблица будет действовать как буфер, позволяя приложениям легко получать доступ к данным в структурированном формате. Данные высокочастотных датчиков, в нашем случае 50 Гц, быстро растут, и их становится трудно поддерживать. Скорее всего, мы бы внедрили еще один конвеер Kafka, отвечающий за перемещение старых данных из QuestDB в архив.
Последним шагом для этого консумера является добавление соответствующих команд docker-compose:
db_consumer:
build:
context: ./db_consumer
dockerfile: Dockerfile
command: python main.py
env_file:
- .env
depends_on:
- kafka
- zookeeperДэшборд
У нас есть все для визуализации данных датчика в том виде, в каком они записаны в QuestDB. Чтобы сделать это, нам нужно создать другое приложение Fast API, которое опрашивает базу данных и использует события, отправляемые сервером (SSE), для обновления HTML-страницы. Вот последняя структура каталогов, которую нужно изучить:
|-ui_server
| |-app
| | |-core
| | | |-config.py
| | |-models
| | | |-sensors.py
| | |-static
| | | |-js
| | | | |-main.js
| | |-db
| | | |-data_api.py
| | |-templates
| | | |-index.html
| | |-main.py
| |-requirements.txt
| |-Dockerfile
| |-entrypoint.shКак и прежде, main.py — драйвер для этого приложения:
import asyncio
import json
import logging
import sys
from fastapi import FastAPI
from fastapi.requests import Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.staticfiles import StaticFiles
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
from sse_starlette.sse import EventSourceResponse
from core.config import app_config
from db.data_api import create_connection, get_recent_triaxial_data, DEVICE_TO_DB_SENSOR_NAME
from models.sensors import SensorName
CONNECTION = create_connection(app_config.DB_HOST,
app_config.DB_PORT,
app_config.DB_USER,
app_config.DB_PASSWORD,
app_config.DB_NAME )
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
logger = logging.getLogger(__name__)
app = FastAPI()
origins = [
f"http://localhost:{app_config.UI_PORT}",
f"http://127.0.0.1:{app_config.UI_PORT}",
f"http://0.0.0.0:{app_config.UI_PORT}"
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins,
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
templates = Jinja2Templates(directory="templates")
@app.get("/", response_class=HTMLResponse)
async def index(request: Request) -> templates.TemplateResponse:
return templates.TemplateResponse("index.html", {"request": request})
@app.get('/chart-data')
async def message_stream(request: Request):
def new_messages():
yield True
async def event_generator():
while True:
if await request.is_disconnected():
break
if new_messages():
data = get_recent_triaxial_data(connection=CONNECTION,
table_name=app_config.DB_TRIAXIAL_OFFLOAD_TABLE_NAME,
sensor_name=DEVICE_TO_DB_SENSOR_NAME[SensorName.ACC.value],
sample_rate=app_config.PHONE_SAMPLE_RATE,
num_seconds=1,
max_lookback_seconds=60)
message_data = {}
for device_id in data['device_id'].unique():
data_device = data[data['device_id']==device_id]
message_data[device_id] = {
'time':[t[11:] for t in list(data_device['recorded_timestamp'].astype(str).values)],
'x':list(data_device['x'].astype(float).values),
'y':list(data_device['y'].astype(float).values),
'z':list(data_device['z'].astype(float).values)
}
message = json.dumps(message_data)
yield {
"event": "new_message",
"id": "message_id",
"retry":1500000,
"data": message
}
await asyncio.sleep(0.1)
return EventSourceResponse(event_generator())Каждые 0,1 секунды, строка 90, функция message_stream запрашивает у базы данных самую последнюю секунду показаний датчика, строка 62. В этой итерации панели мониторинга запрашиваются и отображаются только данные акселерометра. Аргументу max_lookback_seconds присвоено значение 60 — это означает, что все телефоны, которые не отправляли данные за последние 60 секунд, будут отфильтрованы в запросе. Следовательно, на этой панели мониторинга будут отображаться данные акселерометра за последнюю секунду для всех телефонов, отправивших данные за последнюю минуту. Вот логика запроса:
def get_recent_triaxial_data(connection:pg.connect,
table_name:str,
sensor_name:str,
sample_rate:int,
num_seconds:float,
max_lookback_seconds:float):
"""
Query the most recent data from a triaxial smartphone sensor.
Parameters
----------
connection:pg.connect
A postgres connection object
table_name:str
The table where the sensor data is stored
sensor_name:str
The name of the sensor to query
sample_rate:int
The sampling rate of the sensor (in hz)
num_seconds:float
The number of seconds of data to pull
max_lookback_seconds:float
The maximum amount seconds to look for data from.
For instance, if a device stopped producing data
10 seconds ago, and max_lookback_seconds = 10,
then data for this device will be ignored.
Returns
-------
A DataFrame with the requested sensor data
"""
# The number of samples to get
num_samples:int = int(sample_rate*num_seconds)
query:str = f"""with tmp as (select device_id,
recorded_timestamp,
x,
y,
z,
row_number() over(partition by device_id order by
recorded_timestamp desc) as rn
from {table_name}
where sensor_name = '{sensor_name}'
and recorded_timestamp::timestamp >= dateadd('s', -{int(max_lookback_seconds)}, now())
)
select * from tmp
where rn <= {num_samples}
"""
return pd.read_sql(query, connection)Добавьте необходимые строки в файл docker-compose:
ui_server:
build:
context: ./ui_server
dockerfile: Dockerfile
command: uvicorn main:app --workers 1 --host 0.0.0.0 --port 5000
ports:
- 5000:5000
env_file:
- .env
depends_on:
- db_consumerИ панель мониторинга должна быть доступна по адресу http://localhost:5000:

В этой статье представлен общий обзор проекта потоковой передачи в реальном времени с источником данных, к которому имеет доступ большинство людей (смартфоны). Хотя здесь много движущихся частей, мы просто заглянули в мир потоковой передачи данных.

Но о Kafka можно узнать больше.
Углублённый курс с практикой на Java или Golang и платформой Spring+Docker+Postgres переведёт вас на новый уровень владения инструментом.
На курсе «Apache Kafka для разработчиков» мы обсудим:
неправильное использование Кафка и отсутствие коммитов в ней;
ваши кейсы о проблемах при работе с Apache Kafka;
опыт создания Data Lake на ~80 ТБ с помощью Apache Kafka;
особенности эксплуатации kafka с retention в 99999999.
Старт потока — 12 мая 2023. Присоединяйтесь кобучению сейчас ???? https://slurm.club/3HmEXDx
Полезные ссылки для изучения:
vassabi
доктор, скажите, а почему когда я вижу нечто а-ля "проект, собирающий все данные, абсолютно все данные с устройства", у меня дергается глаз и вспоминается слово "теледильдоника" ?